
Uma visão geral completa das redes neurais artificiais (ANN)
Publicados: 2020-07-17Mesmo que você não esteja trabalhando na área de ciência de dados ou engenharia de software, é difícil evitar o termo redes neurais artificiais.
As redes neurais artificiais (RNA) são onipresentes. Eles são usados em chatbots, imagens médicas, planejamento de mídia e muitas outras áreas. Mas perguntamos com uma profunda curiosidade: o que é uma rede neural artificial e o que ela pode realmente alcançar?
Todos nós já nos deparamos com a definição comum de que as redes neurais artificiais replicam o funcionamento do sistema neural humano. Isso explica o princípio de funcionamento, mas a maioria de nós ainda não sabe o que torna uma RNA tão especial ou para quais conjuntos de problemas ela é ideal. Para limpar o ar, aqui está o guia mais abrangente e acessível que você encontrará sobre redes neurais artificiais.
O que é uma rede neural artificial?
Quando uma dúzia de termos como inteligência artificial, aprendizado de máquina, aprendizado profundo e redes neurais, é fácil ficar confuso. A bifurcação real entre essas verticais não é tão complicada.
AI é o conjunto universal que é o assunto em mãos. É o estudo sistemático de como os programas inteligentes operam e são feitos. O aprendizado de máquina é um subconjunto da IA que se concentra em como as máquinas podem aprender por si mesmas. O aprendizado profundo é um subconjunto adicional de ML que se concentra em como as camadas de redes neurais podem ser usadas para gerar saídas. Você pode usar esta visualização para navegar na hierarquia:
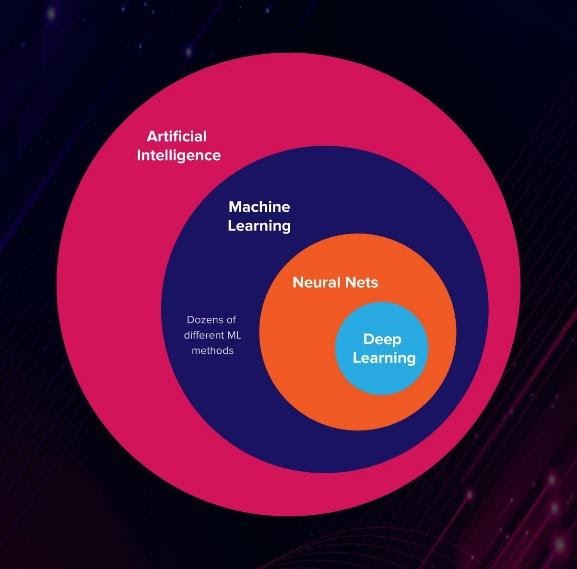
Então, o que é uma rede neural artificial? A resposta é exatamente como a mídia popular a divulga. É um sistema de processamento de dados e geração de saída que replica o sistema neural para desvendar relações não lineares em um grande conjunto de dados. Os dados podem vir de rotas sensoriais e podem estar na forma de texto, imagens ou áudio.
A melhor maneira de entender como uma rede neural artificial funciona é entender como funciona uma rede neural natural dentro do cérebro e traçar um paralelo entre elas. Os neurônios são o componente fundamental do cérebro humano e são responsáveis pelo aprendizado e retenção do conhecimento e da informação como a conhecemos. Você pode considerá-los a unidade de processamento no cérebro. Eles pegam os dados sensoriais como entrada, os processam e fornecem os dados de saída usados por outros neurônios. A informação é processada e passada até que um resultado decisivo seja alcançado.
A rede neural básica no cérebro é conectada por sinapses. Você pode visualizá-los como os nós finais de uma ponte que conecta dois neurônios. Assim, a sinapse é o ponto de encontro de dois neurônios. As sinapses são uma parte importante desse sistema porque a força de uma sinapse determinaria a profundidade da compreensão e a retenção de informações.
Quando você está praticando uma atividade, você está fortalecendo essas relações sinápticas. É assim que você pode visualizar a rede neural em seu cérebro:
Todos os dados sensoriais que seu cérebro está coletando em tempo real são processados por meio dessas redes neurais. Eles têm um ponto de origem no sistema. E à medida que são processados pelos neurônios iniciais, a forma processada de um sinal elétrico que sai de um neurônio torna-se a entrada para outro neurônio. Esse processamento de microinformações em cada camada de neurônios é o que torna essa rede efetiva e eficiente. Ao replicar esse tema recorrente de processamento de dados na rede neural, as RNAs são capazes de produzir resultados superiores.
Em uma RNA, tudo é projetado para replicar esse mesmo processo. Não se preocupe com a equação matemática. Essa não é a ideia-chave a ser compreendida agora. Todos os dados que entram com o rótulo 'X' no sistema estão tendo um peso de 'W' para gerar um sinal ponderado. Isso replica o papel da força de um sinal sináptico no cérebro. A variável de polarização é anexada para controlar os resultados da saída da função.
Então, todos esses dados são processados na função e você acaba com uma saída. É assim que uma rede neural de uma camada ou um perceptron se pareceria. A ideia de uma rede neural artificial gira em torno de conectar várias combinações desses neurônios artificiais para obter saídas mais potentes. É por isso que a estrutura conceitual típica da rede neural artificial se parece muito com isso:
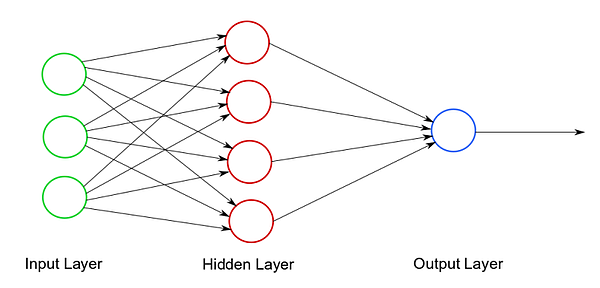
Em breve, definiremos a camada oculta, à medida que nos aprofundamos no funcionamento de uma rede neural artificial. Mas no que diz respeito a uma compreensão rudimentar de uma rede neural artificial, você conhece os primeiros princípios agora.
Esse mecanismo é usado para decifrar grandes conjuntos de dados. A saída geralmente tende a ser um estabelecimento de causalidade entre as variáveis inseridas como entrada que pode ser usada para previsão. Agora que você conhece o processo, pode apreciar completamente a definição técnica aqui:
“Uma rede modelada após o cérebro humano, criando um sistema neural artificial por meio de um algoritmo de computador de reconhecimento de padrões que aprende, interpreta e classifica dados sensoriais”.
Como as redes neurais artificiais funcionam e aprendem?
Prepare-se, as coisas estão prestes a ficar interessantes aqui. E não se preocupe – você não precisa fazer muita matemática agora.
A mágica acontece primeiro na função de ativação. A função de ativação faz o processamento inicial para determinar se o neurônio será ativado ou não. Se o neurônio não estiver ativado, sua saída será a mesma que sua entrada. Nada acontece então. Isso é fundamental para ter na rede neural, caso contrário, o sistema será forçado a processar uma tonelada de informações que não têm impacto na saída. Você vê, o cérebro tem capacidade limitada, mas foi otimizado para usá-lo da melhor maneira.
Uma propriedade central comum em todas as redes neurais artificiais é o conceito de não linearidade. A maioria das variáveis estudadas possui uma relação não linear na vida real.
Tomemos por exemplo o preço do chocolate e o número de chocolates. Suponha que um chocolate custe $ 1. Quanto custaria 100 chocolates? Provavelmente $100. Quanto custaria 10.000 chocolates? Não $ 10.000; porque ou o vendedor adicionará o custo de usar embalagens extras para juntar todos os chocolates ou reduzirá o custo, já que você está tirando muito do estoque de suas mãos de uma só vez. Esse é o conceito de não linearidade.
Uma função de ativação usará princípios matemáticos básicos para determinar se a informação deve ser processada ou não. As formas mais comuns de funções de ativação são a Função Degrau Binária, Função Logística, Função Tangente Hiperbólica e Unidades Lineares Retificadas. Aqui está a definição básica de cada um deles:
- Função de degrau binário: Esta função ativa um neurônio com base em um limiar. Se a função tiver o resultado final acima ou abaixo de um valor de referência, o neurônio é ativado.
- Função logística: Esta função tem um resultado final matemático na forma de uma curva 'S' e é usada quando as probabilidades são o critério chave para determinar se o neurônio deve ser ativado. Então, em qualquer ponto, você pode calcular a inclinação dessa curva. O valor desta função está entre 0 e 1.
A inclinação é calculada usando uma função diferencial. O conceito é usado quando duas variáveis não têm uma relação linear. A inclinação é o valor de uma tangente que toca a curva no ponto exato em que a não linearidade entra em ação. O problema com a função logística é que ela não é boa para processar informações com valores negativos. - Função tangente hiperbólica: É bastante semelhante à função logística, exceto que seus valores ficam entre -1 e +1. Assim, o problema de um valor negativo não ser processado na rede desaparece.
- Unidades lineares retificadas (ReLu): Os valores desta função estão entre 0 e infinito positivo. ReLu simplifica algumas coisas – se a entrada for positiva, dará o valor de 'x'. Para todas as outras entradas, o valor seria '0'. Você pode usar um Leaky ReLu que tenha valores entre infinito negativo e infinito positivo. É usado quando a relação entre as variáveis que estão sendo processadas é muito fraca e pode ser omitida pela função de ativação.
Agora você pode consultar os mesmos dois diagramas de um perceptron e uma rede neural. Qual é a diferença, além do número de neurônios? A principal diferença é a camada oculta. Uma camada oculta fica bem entre a camada de entrada e a camada de saída em uma rede neural. O trabalho da camada oculta é refinar o processamento e eliminar variáveis que não terão um forte impacto na saída.
Se o número de instâncias em um conjunto de dados em que o impacto da mudança no valor de uma variável de entrada for perceptível na variável de saída, a camada oculta mostrará esse relacionamento. A camada oculta torna mais fácil para a RNA emitir sinais mais fortes para a próxima camada de processamento.
Mesmo depois de fazer toda essa matemática e entender como a camada oculta funciona, você pode estar se perguntando como uma rede neural artificial realmente aprende? Vamos começar com a questão básica do que é aprender. Aprender, nos termos mais simples, é estabelecer causalidade entre duas coisas (atividades, processos, variáveis, etc.). Quando você 'aprende' como jogar uma bola curva, você está estabelecendo causalidade entre a ação física de jogar a bola de uma certa maneira e fazer a trajetória da bola se curvar de uma certa maneira.
Agora, essa causalidade é muito difícil de estabelecer. Lembre-se do ditado correlação não é igual a causalidade? É bastante fácil determinar quando duas variáveis estão se movendo na mesma direção. É muito difícil dizer com absoluta certeza qual variável está causando o movimento em qual variável. Obviamente, muitas vezes somos capazes de estabelecer isso intuitivamente; mas como você faz um algoritmo entender a intuição?

Você usa uma função de custo. Matematicamente, é a diferença quadrada entre o valor real do conjunto de dados e o valor de saída do conjunto de dados. Você também pode considerar o grau de erro. Nós elevamos ao quadrado porque às vezes a diferença pode ser negativa.
Você pode marcar cada ciclo de processamento de entrada para saída com a função de custo. Seu trabalho e o da RNA é minimizar a função de custo para o menor valor possível. Você consegue isso ajustando os pesos na RNA. (Lembra das relações sinápticas, também conhecidas como pesos? É disso que estamos falando). Existem várias maneiras de fazer isso, mas até onde você entende o princípio, você estaria apenas usando ferramentas diferentes para executá-lo.
A cada ciclo, buscamos minimizar a função custo. O processo de ir da entrada para a saída é chamado de propagação direta. E o processo de usar dados de saída para minimizar a função de custo ajustando o peso em ordem inversa da última camada oculta para a camada de entrada é chamado de propagação regressiva.
Você pode continuar ajustando esses pesos usando o método Brute Force, que se torna ineficiente quando o conjunto de dados é muito grande, ou Batch-Gradient Descent, que é um algoritmo de otimização. Agora você tem uma compreensão intuitiva de como uma rede neural artificial aprende.
Redes neurais recorrentes (RNN) vs. redes neurais convolucionais (CNN)
Compreender essas duas formas de redes neurais também pode ser sua introdução a duas facetas diferentes do aplicativo de IA – visão computacional e processamento de linguagem natural. Na forma mais simples, esses dois ramos da IA ajudam uma máquina a identificar visualmente objetos e entender o contexto dos dados linguísticos. Como você pode imaginar, já existem aplicativos usados desses ramos em carros autônomos e assistentes virtuais como o Siri.
Agora, cada um desses ramos tem sua própria rede neural estabelecida. A PNL é altamente dependente de redes neurais recorrentes. A diferença entre uma RNN e uma ANN é que em uma ANN, cada sinal de entrada é considerado independente do próximo sinal de entrada. Assim, os dados de entrada que existem entre dois nós, por si só, não possuem nenhum relacionamento.
Na realidade, esse não é o caso. Quando estamos nos comunicando, cada palavra limpa o caminho contextual para a próxima palavra. Portanto, a natureza fundamental da linguagem é que ela cria interdependências entre as informações que são inseridas anteriormente e as informações que são inseridas posteriormente. As RNNs são sensíveis a isso executando uma memória paralela que estabelece a relação entre essas entradas para limpar o contexto.
As redes neurais convolucionais são idealmente usadas para visão computacional. Além das funções de ativação geralmente usadas, eles adicionam uma função de agrupamento e uma função de convolução. Uma função de convolução, em termos mais simples, mostraria como a entrada de uma imagem e a entrada de uma segunda imagem (um filtro) resultariam em uma terceira imagem (o resultado). Você pode imaginar isso visualizando-a como uma imagem filtrada (um novo conjunto de valores de pixel) em cima de sua imagem de entrada (conjunto original de valores de pixel) para obter uma imagem resultante (valores de pixel alterados).
Uma função de agrupamento terá o valor máximo ou mínimo, dependendo da função adicionada, para facilitar o processamento desse conjunto de informações. Veja como você pode visualizá-los:
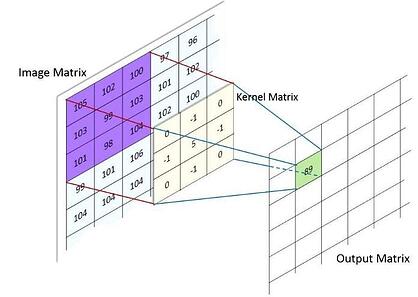
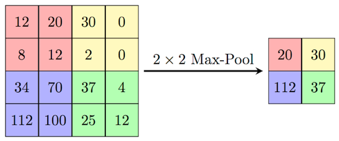
Função de agrupamento
5 aplicações de redes neurais artificiais
O que falamos até agora estava acontecendo debaixo do capô. Agora podemos diminuir o zoom e ver essas RNAs em ação para apreciar plenamente seu vínculo com nosso mundo em evolução:
1. Personalize recomendações em plataformas de comércio eletrônico
Uma das primeiras aplicações das RNAs foi personalizar as experiências da plataforma de comércio eletrônico para cada usuário. Você se lembra das recomendações realmente eficazes na Netflix? Ou as sugestões de produtos da Amazon? Eles são um resultado da RNA.
Há uma tonelada de dados sendo usados aqui: suas compras anteriores, dados demográficos, dados geográficos e os dados que mostram o que as pessoas que compraram o mesmo produto compraram em seguida. Todos estes servem como entradas para determinar o que pode funcionar para você. Ao mesmo tempo, o que você realmente compra ajuda o algoritmo a ser otimizado. A cada compra, você está enriquecendo a empresa e o algoritmo que capacita a RNA. Ao mesmo tempo, cada nova compra feita na plataforma também melhorará a habilidade do algoritmo em recomendar os produtos certos para você.
2. Aproveitando o processamento de linguagem natural para chatbots de conversação
Não muito tempo atrás, os chatboxes começaram a ganhar força em sites. Um agente se sentaria de um lado e o ajudaria com suas perguntas digitadas na caixa. Então, um fenômeno chamado processamento de linguagem natural (NLP) foi introduzido nos chatbots e tudo mudou.
A PNL geralmente usa regras estatísticas para replicar as capacidades da linguagem humana e, como outras aplicações de RNA, melhora com o tempo. Suas pontuações, entonações e enunciados, escolhas gramaticais, escolhas sintáticas, ordem de palavras e frases e até mesmo a linguagem de escolha podem servir como entradas para treinar o algoritmo de PNL.
O chatbot se torna conversacional usando essas entradas para entender o contexto de suas consultas e para formular respostas de uma maneira que melhor se adapte ao seu estilo. O mesmo PNL também está sendo usado para edição de áudio em música e para fins de verificação de segurança.
3. Previsão de resultados de um evento de alto nível
A maioria de nós segue as previsões de resultados feitas por algoritmos com inteligência artificial durante as eleições presidenciais e a Copa do Mundo da FIFA. Como ambos os eventos são faseados, isso ajuda o algoritmo a entender rapidamente sua eficácia e minimizar a função de custo à medida que equipes e candidatos são eliminados. O verdadeiro desafio em tais situações é o grau de variáveis de entrada. De candidatos a estatísticas de jogadores, demografia a capacidades anatômicas - tudo tem que ser incorporado.
Nos mercados de ações, os algoritmos preditivos que usam RNAs já existem há algum tempo. Atualizações de notícias e métricas financeiras são as principais variáveis de entrada usadas. Graças a isso, a maioria das bolsas e bancos são facilmente capazes de negociar ativos em iniciativas de negociação de alta frequência em velocidades que excedem em muito as capacidades humanas.
O problema com os mercados de ações é que os dados são sempre barulhentos. A aleatoriedade é muito alta porque o grau de julgamento subjetivo que pode afetar o preço de um título é muito alto. No entanto, as RNAs estão sendo usadas em atividades de criação de mercado por todos os principais bancos atualmente.
4. Sanções de crédito
As tabelas atuariais já estavam sendo utilizadas para determinar os fatores de risco associados a cada solicitante de seguro. As RNAs levaram todos esses dados a um nível superior.
Todos os credores podem percorrer as décadas de dados que possuem com os pesos fortemente estabelecidos no sistema e usar suas informações como entrada para determinar o perfil de risco apropriado associado ao seu pedido de empréstimo. Sua idade, sexo, cidade de residência, escola de graduação, setor de engajamento, salário e índice de poupança são usados como entradas para determinar suas pontuações de risco de crédito.
O que antes era fortemente dependente de sua pontuação de crédito individual agora se tornou um mecanismo muito mais abrangente. Essa é a razão pela qual vários players privados de fintech entraram no espaço de empréstimos pessoais para administrar as mesmas ANNs e emprestar para pessoas cujos perfis são considerados muito arriscados pelos bancos.
5. Carros autônomos
Tesla, Waymo e Uber têm usado ANNs semelhantes. Os insumos e a engenharia de produto podem ter sido diferentes, mas eles estavam implantando computação visual sofisticada para tornar realidade os carros autônomos.
Grande parte da condução autônoma tem a ver com o processamento de informações que vêm do mundo real na forma de veículos próximos, sinais de trânsito, luzes naturais e artificiais, pedestres, edifícios e assim por diante. Obviamente, as redes neurais que alimentam esses carros autônomos são mais complicadas do que as que discutimos aqui, mas operam com os mesmos princípios que expusemos.
Conclusão
As RNAs estão ficando cada vez mais sofisticadas a cada dia. Os NLPs agora estão ajudando no diagnóstico precoce de problemas de saúde mental, a visão computacional está sendo usada em imagens médicas e as ANNs estão alimentando a entrega de drones. À medida que as RNAs se tornam mais complexas e em camadas, a necessidade de inteligência humana nesse sistema se tornaria menor. Até áreas como design começaram a implantar soluções de IA com design generativo.
A eventual evolução de todas as RNAs juntas seria a Inteligência Geral – uma forma de inteligência tão sofisticada que pode aprender e perceber todas as informações conhecidas e desconhecidas pela humanidade. Embora seja uma realidade muito distante, se possível, tornou-se um conceito concebível graças à ampla adoção da RNA.