
Ein vollständiger Überblick über künstliche neuronale Netze (KNN)
Veröffentlicht: 2020-07-17Selbst wenn Sie nicht im Bereich Data Science oder Software Engineering arbeiten, ist es schwierig, den Begriff künstliche neuronale Netze zu vermeiden.
Künstliche neuronale Netze (KNN) sind allgegenwärtig. Sie werden in Chatbots, medizinischer Bildgebung, Medienplanung und einer Menge anderer Bereiche verwendet. Aber haben wir mit tiefer Neugier gefragt: Was ist ein künstliches neuronales Netz und was kann es wirklich leisten?
Wir sind alle auf die gemeinsame Definition gestoßen, dass künstliche neuronale Netze die Funktionsweise des menschlichen neuronalen Systems nachbilden. Das erklärt das Funktionsprinzip, aber die meisten von uns wissen immer noch nicht, was ein KNN so besonders macht oder für welche Problemstellungen es ideal ist. Um die Luft zu reinigen, hier ist der umfassendste und dennoch zugänglichste Leitfaden, den Sie zu künstlichen neuronalen Netzen finden werden.
Was ist ein künstliches neuronales Netz?
Bei einem Dutzend Begriffe wie künstliche Intelligenz, maschinelles Lernen, Deep Learning und neuronale Netze kommt man leicht durcheinander. Die eigentliche Gabelung zwischen diesen Vertikalen ist nicht so kompliziert.
KI ist die universelle Menge, um die es geht. Es ist die systematische Untersuchung, wie intelligente Programme funktionieren und erstellt werden. Maschinelles Lernen ist eine Teilmenge der KI, die sich darauf konzentriert, wie Maschinen selbst lernen können. Deep Learning ist eine weitere Untergruppe von ML, die sich darauf konzentriert, wie Schichten neuronaler Netze verwendet werden können, um Ausgaben zu generieren. Sie können diese Visualisierung verwenden, um in der Hierarchie zu navigieren:
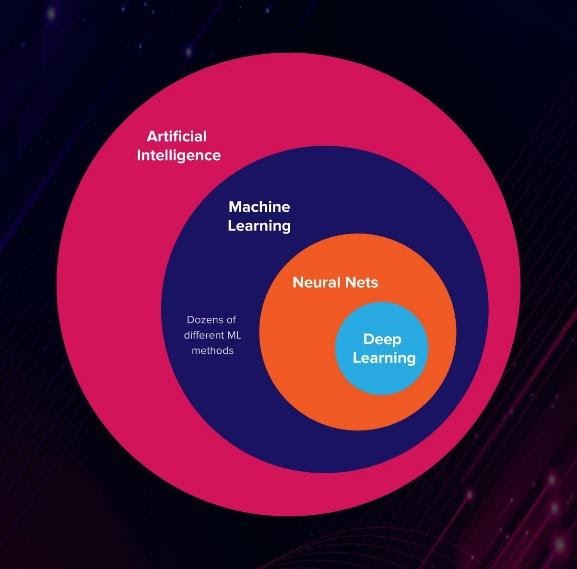
Was ist also ein künstliches neuronales Netz? Die Antwort ist genau so, wie die populären Medien sie anpreisen. Es ist ein System zur Datenverarbeitung und Ausgabegenerierung, das das neuronale System repliziert, um nichtlineare Beziehungen in einem großen Datensatz aufzudecken. Die Daten können von sensorischen Routen stammen und in Form von Text, Bildern oder Audio vorliegen.
Der beste Weg, um zu verstehen, wie ein künstliches neuronales Netzwerk funktioniert, besteht darin, zu verstehen, wie ein natürliches neuronales Netzwerk im Gehirn funktioniert, und eine Parallele zwischen ihnen zu ziehen. Neuronen sind die grundlegende Komponente des menschlichen Gehirns und für das Lernen und Speichern von Wissen und Informationen, wie wir sie kennen, verantwortlich. Sie können sie als Verarbeitungseinheit im Gehirn betrachten. Sie nehmen die sensorischen Daten als Eingabe, verarbeiten sie und geben die Ausgabedaten aus, die von anderen Neuronen verwendet werden. Die Informationen werden verarbeitet und weitergegeben, bis ein entscheidendes Ergebnis erzielt wird.
Das grundlegende neuronale Netzwerk im Gehirn ist durch Synapsen verbunden. Sie können sie sich als Endknoten einer Brücke vorstellen, die zwei Neuronen verbindet. Die Synapse ist also der Treffpunkt zweier Neuronen. Synapsen sind ein wichtiger Teil dieses Systems, da die Stärke einer Synapse die Tiefe des Verständnisses und die Speicherung von Informationen bestimmen würde.
Wenn Sie eine Aktivität ausüben, stärken Sie diese synaptischen Beziehungen. So können Sie sich das neuronale Netzwerk in Ihrem Gehirn vorstellen:
Alle sensorischen Daten, die Ihr Gehirn in Echtzeit sammelt, werden durch diese neuronalen Netze verarbeitet. Sie haben einen Ausgangspunkt im System. Und während sie von den ursprünglichen Neuronen verarbeitet werden, wird die verarbeitete Form eines elektrischen Signals, das aus einem Neuron kommt, zur Eingabe für ein anderes Neuron. Diese Mikroinformationsverarbeitung auf jeder Schicht von Neuronen macht dieses Netzwerk effektiv und effizient. Durch die Replikation dieses wiederkehrenden Themas der Verarbeitung von Daten über das neuronale Netzwerk sind KNNs in der Lage, überlegene Ergebnisse zu erzeugen.
In einem KNN ist alles darauf ausgelegt, genau diesen Prozess zu replizieren. Mach dir keine Sorgen über die mathematische Gleichung. Das ist nicht die Schlüsselidee, die es jetzt zu verstehen gilt. Alle Daten, die mit dem Etikett „X“ in das System eingehen, haben eine Gewichtung von „W“, um ein gewichtetes Signal zu erzeugen. Dies repliziert die Rolle der Stärke eines synaptischen Signals im Gehirn. Die Bias-Variable wird angehängt, um die Ergebnisse der Ausgabe der Funktion zu steuern.
All diese Daten werden also in der Funktion verarbeitet und Sie erhalten am Ende eine Ausgabe. So würde ein einschichtiges neuronales Netz oder ein Perzeptron aussehen. Die Idee eines künstlichen neuronalen Netzes dreht sich darum, mehrere Kombinationen solcher künstlicher Neuronen zu verbinden, um leistungsfähigere Ergebnisse zu erzielen. Aus diesem Grund sieht der konzeptionelle Rahmen eines typischen künstlichen neuronalen Netzes ungefähr so aus:
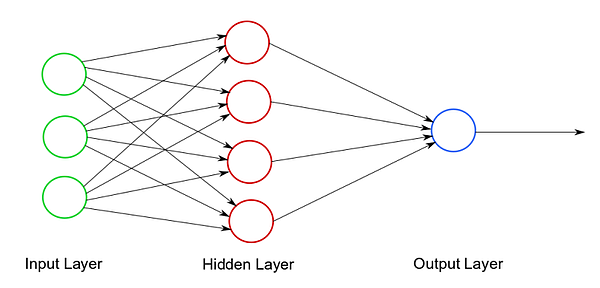
Wir werden bald die verborgene Schicht definieren, während wir tief in die Funktionsweise eines künstlichen neuronalen Netzwerks eintauchen. Aber was ein rudimentäres Verständnis eines künstlichen neuronalen Netzes angeht, kennst du jetzt die ersten Prinzipien.
Dieser Mechanismus wird verwendet, um große Datensätze zu entschlüsseln. Das Ergebnis ist im Allgemeinen eine Feststellung der Kausalität zwischen den als Eingabe eingegebenen Variablen, die für Prognosen verwendet werden können. Jetzt, da Sie den Prozess kennen, können Sie die technische Definition hier vollständig einschätzen:
„Ein Netzwerk, das dem menschlichen Gehirn nachempfunden ist, indem ein künstliches neuronales System über einen mustererkennenden Computeralgorithmus geschaffen wird, der aus sensorischen Daten lernt, sie interpretiert und klassifiziert.“
Wie arbeiten und lernen künstliche neuronale Netze?
Machen Sie sich bereit, hier wird es gleich interessant. Und keine Sorge – Sie müssen jetzt nicht viel rechnen.
Die Magie passiert zuerst bei der Aktivierungsfunktion. Die Aktivierungsfunktion führt eine anfängliche Verarbeitung durch, um zu bestimmen, ob das Neuron aktiviert wird oder nicht. Wenn das Neuron nicht aktiviert ist, ist seine Ausgabe dieselbe wie seine Eingabe. Da passiert nichts. Dies ist im neuronalen Netzwerk von entscheidender Bedeutung, da das System sonst gezwungen ist, eine Menge Informationen zu verarbeiten, die keinen Einfluss auf die Ausgabe haben. Sie sehen, das Gehirn hat eine begrenzte Kapazität, aber es wurde optimiert, um es optimal zu nutzen.
Eine zentrale Eigenschaft, die allen künstlichen neuronalen Netzen gemeinsam ist, ist das Konzept der Nichtlinearität. Die meisten Variablen, die untersucht werden, besitzen im wirklichen Leben eine nichtlineare Beziehung.
Nehmen Sie zum Beispiel den Preis von Schokolade und die Anzahl der Pralinen. Angenommen, eine Schokolade kostet 1 $. Wie viel würden 100 Pralinen kosten? Wahrscheinlich 100 Dollar. Wie viel würden 10.000 Pralinen kosten? Nicht 10.000 $; weil entweder der Verkäufer die Kosten für die Verwendung zusätzlicher Verpackungen hinzufügt, um alle Pralinen zusammenzustellen, oder sie die Kosten senkt, da Sie ihr so viel von ihrem Inventar auf einmal abnehmen. Das ist das Konzept der Nichtlinearität.
Eine Aktivierungsfunktion bestimmt anhand grundlegender mathematischer Prinzipien, ob die Informationen verarbeitet werden sollen oder nicht. Die gebräuchlichsten Formen von Aktivierungsfunktionen sind binäre Schrittfunktion, logistische Funktion, hyperbolische Tangensfunktion und gleichgerichtete lineare Einheiten. Hier ist die grundlegende Definition von jedem davon:
- Binäre Schrittfunktion: Diese Funktion aktiviert ein Neuron auf der Grundlage einer Schwelle. Wenn die Funktion das Endergebnis hat, das über oder unter einem Vergleichswert liegt, wird das Neuron aktiviert.
- Logistische Funktion: Diese Funktion hat ein mathematisches Endergebnis in Form einer „S“-Kurve und wird verwendet, wenn Wahrscheinlichkeiten das Schlüsselkriterium sind, um zu bestimmen, ob das Neuron aktiviert werden sollte. Sie können also jederzeit die Steigung dieser Kurve berechnen. Der Wert dieser Funktion liegt zwischen 0 und 1.
Die Steigung wird unter Verwendung einer Differentialfunktion berechnet. Das Konzept wird verwendet, wenn zwei Variablen keine lineare Beziehung haben. Die Steigung ist der Wert einer Tangente, die die Kurve genau an dem Punkt berührt, an dem die Nichtlinearität eintritt. Das Problem mit der logistischen Funktion besteht darin, dass sie nicht gut für die Verarbeitung von Informationen mit negativen Werten geeignet ist. - Funktion des hyperbolischen Tangens: Sie ist der logistischen Funktion ziemlich ähnlich, außer dass ihre Werte zwischen -1 und +1 liegen. Damit entfällt das Problem, dass ein negativer Wert im Netzwerk nicht verarbeitet wird.
- Gleichgerichtete lineare Einheiten (ReLu): Die Werte dieser Funktion liegen zwischen 0 und positiv unendlich. ReLu vereinfacht ein paar Dinge – wenn die Eingabe positiv ist, gibt es den Wert von 'x'. Für alle anderen Eingänge wäre der Wert '0'. Sie können ein Leaky ReLu verwenden, das Werte zwischen negativ unendlich und positiv unendlich hat. Es wird verwendet, wenn die Beziehung zwischen den verarbeiteten Variablen sehr schwach ist und von der Aktivierungsfunktion möglicherweise vollständig weggelassen wird.
Jetzt können Sie sich auf dieselben zwei Diagramme eines Perzeptrons und eines neuronalen Netzwerks beziehen. Was ist der Unterschied, abgesehen von der Anzahl der Neuronen? Der Hauptunterschied ist die verborgene Schicht. Eine verborgene Schicht befindet sich direkt zwischen der Eingabeschicht und der Ausgabeschicht in einem neuronalen Netzwerk. Die Aufgabe der verborgenen Schicht besteht darin, die Verarbeitung zu verfeinern und Variablen zu eliminieren, die sich nicht stark auf die Ausgabe auswirken.
Wenn die Anzahl der Fälle in einem Datensatz, in denen die Auswirkung der Änderung des Werts einer Eingabevariablen auf die Ausgabevariable spürbar ist, zeigt die verborgene Schicht diese Beziehung. Die verborgene Schicht macht es dem ANN leicht, stärkere Signale an die nächste Verarbeitungsschicht auszugeben.
Selbst nachdem Sie all diese Berechnungen durchgeführt und verstanden haben, wie die verborgene Schicht funktioniert, fragen Sie sich vielleicht, wie ein künstliches neuronales Netzwerk eigentlich lernt? Beginnen wir mit der grundlegenden Frage, was Lernen ist. Einfach ausgedrückt bedeutet Lernen, eine Kausalität zwischen zwei Dingen (Aktivitäten, Prozessen, Variablen usw.) herzustellen. Wenn Sie „lernen“, wie man einen Curveball wirft, stellen Sie eine Kausalität her zwischen der physikalischen Aktion, den Ball auf eine bestimmte Weise zu werfen, und dem Bewirken, dass die Flugbahn des Balls auf eine bestimmte Weise gekrümmt wird.

Nun, diese Kausalität ist sehr schwierig festzustellen. Erinnern Sie sich an das Sprichwort Korrelation ist nicht gleich Kausalität? Es ist ziemlich einfach festzustellen, wann sich zwei Variablen in die gleiche Richtung bewegen. Es ist sehr schwierig, mit absoluter Sicherheit zu sagen, welche Variable die Bewegung in welcher Variable verursacht. Offensichtlich können wir dies oft intuitiv feststellen; Aber wie bringt man einen Algorithmus dazu, Intuition zu verstehen?
Sie verwenden eine Kostenfunktion. Mathematisch ist es die quadrierte Differenz zwischen dem tatsächlichen Wert des Datensatzes und dem Ausgabewert des Datensatzes. Sie können auch den Grad des Fehlers berücksichtigen. Wir quadrieren es, weil die Differenz manchmal negativ sein kann.
Sie können jeden Zyklus der Eingabe-zu-Ausgabe-Verarbeitung mit der Kostenfunktion kennzeichnen. Ihre und die Aufgabe von ANN besteht darin, die Kostenfunktion auf den geringstmöglichen Wert zu minimieren. Sie erreichen dies, indem Sie die Gewichte im ANN anpassen. (Erinnern Sie sich an die synaptischen Beziehungen, auch bekannt als die Gewichte? Darüber sprechen wir). Es gibt mehrere Möglichkeiten, dies zu tun, aber soweit Sie das Prinzip verstehen, würden Sie nur verschiedene Tools verwenden, um es auszuführen.
Mit jedem Zyklus zielen wir darauf ab, die Kostenfunktion zu minimieren. Der Prozess vom Eingang zum Ausgang wird als Vorwärtsausbreitung bezeichnet. Und der Prozess der Verwendung von Ausgabedaten zur Minimierung der Kostenfunktion durch Anpassung der Gewichtung in umgekehrter Reihenfolge von der letzten verborgenen Schicht zur Eingabeschicht wird als Rückwärtsausbreitung bezeichnet.
Sie können diese Gewichtungen entweder mit der Brute-Force-Methode, die ineffizient wird, wenn der Datensatz zu groß ist, oder mit Batch-Gradient Descent, einem Optimierungsalgorithmus, weiter anpassen. Jetzt haben Sie ein intuitives Verständnis dafür, wie ein künstliches neuronales Netzwerk lernt.
Rekurrente neuronale Netze (RNN) vs. Convolutional Neural Networks (CNN)
Das Verständnis dieser beiden Formen neuronaler Netze kann auch Ihre Einführung in zwei verschiedene Facetten der KI-Anwendung sein – Computer Vision und Verarbeitung natürlicher Sprache. In der einfachsten Form helfen diese beiden Zweige der KI einer Maschine, Objekte visuell zu identifizieren und den Kontext sprachlicher Daten zu verstehen. Wie Sie sich vorstellen können, gibt es bereits Anwendungen dieser Branchen in selbstfahrenden Autos und virtuellen Assistenten wie Siri.
Nun hat jeder dieser Zweige sein eigenes etabliertes neuronales Netzwerk. NLP ist stark abhängig von wiederkehrenden neuronalen Netzen. Der Unterschied zwischen einem RNN und einem ANN besteht darin, dass bei einem ANN jedes Eingangssignal als unabhängig vom nächsten Eingangssignal betrachtet wird. Die Eingabedaten, die zwischen zwei Knoten vorhanden sind, haben an und für sich keine Beziehung.
In Wirklichkeit ist das nicht der Fall. Wenn wir kommunizieren, macht jedes Wort den kontextuellen Weg frei für das nächste Wort. Daher besteht die grundlegende Natur der Sprache darin, dass sie Wechselbeziehungen zwischen Informationen, die früher eingegeben werden, und den Informationen, die später eingegeben werden, herstellt. RNNs reagieren darauf empfindlich, indem sie einen parallelen Speicher ausführen, der die Beziehung zwischen diesen Eingaben herstellt, um den Kontext zu löschen.
Convolutional Neural Networks werden idealerweise für Computer Vision verwendet. Neben den allgemein verwendeten Aktivierungsfunktionen fügen sie eine Pooling-Funktion und eine Faltungsfunktion hinzu. Einfacher ausgedrückt würde eine Faltungsfunktion zeigen, wie die Eingabe eines Bildes und die Eingabe eines zweiten Bildes (eines Filters) zu einem dritten Bild (dem Ergebnis) führen. Sie können sich dies vorstellen, indem Sie es als gefiltertes Bild (ein neuer Satz von Pixelwerten) visualisieren, das über Ihrem Eingabebild (ursprünglicher Satz von Pixelwerten) sitzt, um ein resultierendes Bild (geänderte Pixelwerte) zu erhalten.
Eine Pooling-Funktion nimmt je nach hinzugefügter Funktion den maximalen oder minimalen Wert, um die Verarbeitung dieses Informationssatzes zu vereinfachen. So können Sie sie visualisieren:
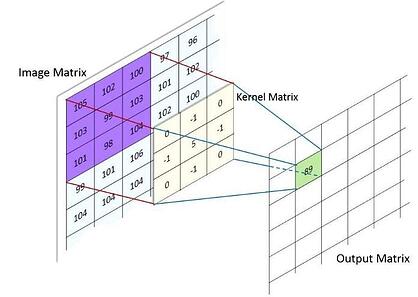
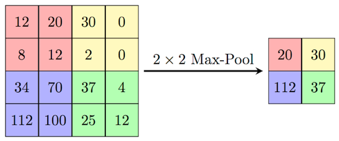
Pooling-Funktion
5 Anwendungen künstlicher neuronaler Netze
Worüber wir bisher gesprochen haben, geschah alles unter der Motorhaube. Jetzt können wir herauszoomen und diese ANNs in Aktion sehen, um ihre Verbundenheit mit unserer sich entwickelnden Welt voll und ganz zu würdigen:
1. Personalisieren Sie Empfehlungen auf E-Commerce-Plattformen
Eine der frühesten Anwendungen von ANNs war die Personalisierung von E-Commerce-Plattformerfahrungen für jeden Benutzer. Erinnern Sie sich an die wirklich effektiven Empfehlungen auf Netflix? Oder die genau passenden Produktvorschläge von Amazon? Sie sind ein Ergebnis der ANN.
Hier werden eine Menge Daten verwendet: Ihre vergangenen Einkäufe, demografische Daten, geografische Daten und die Daten, die zeigen, was Personen, die dasselbe Produkt gekauft haben, als Nächstes gekauft haben. All dies dient als Input, um zu bestimmen, was für Sie funktionieren könnte. Gleichzeitig hilft das, was Sie wirklich kaufen, dem Algorithmus, optimiert zu werden. Mit jedem Kauf bereichern Sie das Unternehmen und den Algorithmus, der das ANN unterstützt. Gleichzeitig verbessert jeder neue Kauf auf der Plattform auch die Fähigkeit des Algorithmus, Ihnen die richtigen Produkte zu empfehlen.
2. Nutzung der Verarbeitung natürlicher Sprache für Konversations-Chatbots
Vor nicht allzu langer Zeit begannen Chatboxen auf Websites an Fahrt aufzunehmen. Ein Agent würde auf einer Seite sitzen und Ihnen bei Ihren in das Feld eingegebenen Fragen helfen. Dann wurde ein Phänomen namens Natural Language Processing (NLP) bei Chatbots eingeführt und alles änderte sich.
NLP verwendet im Allgemeinen statistische Regeln, um menschliche Sprachfähigkeiten zu replizieren, und wird wie andere ANN-Anwendungen mit der Zeit besser. Ihre Interpunktion, Intonation und Aussprache, grammatikalische Entscheidungen, syntaktische Entscheidungen, Wort- und Satzreihenfolge und sogar die Sprache Ihrer Wahl können als Eingaben zum Trainieren des NLP-Algorithmus dienen.
Der Chatbot wird dialogorientiert, indem er diese Eingaben verwendet, um sowohl den Kontext Ihrer Fragen zu verstehen als auch Antworten auf eine Weise zu formulieren, die Ihrem Stil am besten entspricht. Dasselbe NLP wird auch für die Audiobearbeitung in Musik- und Sicherheitsüberprüfungszwecken verwendet.
3. Vorhersage der Ergebnisse eines hochkarätigen Ereignisses
Die meisten von uns verfolgen die Ergebnisvorhersagen, die von KI-gestützten Algorithmen während der Präsidentschaftswahlen und der FIFA Fussball-Weltmeisterschaft getroffen werden. Da beide Ereignisse in Phasen ablaufen, hilft dies dem Algorithmus, seine Wirksamkeit schnell zu verstehen und die Kostenfunktion zu minimieren, wenn Teams und Kandidaten eliminiert werden. Die eigentliche Herausforderung in solchen Situationen ist die Höhe der Eingangsvariablen. Von Kandidaten über Spielerstatistiken bis hin zu Demografien und anatomischen Fähigkeiten – alles muss berücksichtigt werden.
An den Aktienmärkten gibt es schon seit einiger Zeit prädiktive Algorithmen, die KNNs verwenden. Nachrichtenaktualisierungen und Finanzkennzahlen sind die wichtigsten verwendeten Eingabevariablen. Dank dessen sind die meisten Börsen und Banken problemlos in der Lage, Vermögenswerte im Rahmen von Hochfrequenzhandelsinitiativen mit Geschwindigkeiten zu handeln, die die menschlichen Fähigkeiten bei weitem übersteigen.
Das Problem mit Aktienmärkten ist, dass die Daten immer verrauscht sind. Die Zufälligkeit ist sehr hoch, da der Grad der subjektiven Beurteilung, die sich auf den Preis eines Wertpapiers auswirken kann, sehr hoch ist. Nichtsdestotrotz werden ANNs heutzutage von jeder führenden Bank für Market-Making-Aktivitäten verwendet.
4. Kreditsanktionen
Versicherungsmathematische Tafeln wurden bereits verwendet, um die mit jedem Versicherungsbewerber verbundenen Risikofaktoren zu bestimmen. ANNs haben all diese Daten noch eine Stufe höher gelegt.
Alle Kreditgeber können die jahrzehntelangen Daten, die sie besitzen, mit den stark etablierten Gewichtungen im System durchgehen und Ihre Informationen als Eingabe verwenden, um das mit Ihrem Kreditantrag verbundene angemessene Risikoprofil zu bestimmen. Ihr Alter, Geschlecht, Wohnort, Abschlussschule, Branche des Engagements, Gehalt und Sparquote werden alle als Eingaben zur Bestimmung Ihrer Kreditrisikobewertung verwendet.
Was früher stark von Ihrer individuellen Kreditwürdigkeit abhängig war, ist heute ein viel umfassenderer Mechanismus geworden. Aus diesem Grund sind mehrere private Fintech-Unternehmen in den Bereich der Privatkredite gesprungen, um dieselben ANNs zu betreiben und Kredite an Personen zu vergeben, deren Profile von Banken als zu riskant angesehen werden.
5. Selbstfahrende Autos
Tesla, Waymo und Uber verwenden ähnliche ANNs. Die Eingaben und die Produktentwicklung mögen unterschiedlich gewesen sein, aber sie setzten ausgeklügeltes visuelles Computing ein, um selbstfahrende Autos Wirklichkeit werden zu lassen.
Ein Großteil des autonomen Fahrens hat mit der Verarbeitung von Informationen zu tun, die aus der realen Welt in Form von Fahrzeugen in der Nähe, Verkehrszeichen, natürlichen und künstlichen Lichtern, Fußgängern, Gebäuden usw. stammen. Offensichtlich sind die neuronalen Netze, die diese selbstfahrenden Autos antreiben, komplizierter als die hier besprochenen, aber sie funktionieren nach denselben Prinzipien, die wir erläutert haben.
Fazit
ANNs werden von Tag zu Tag immer ausgefeilter. NLPs helfen jetzt bei der frühen Diagnose von psychischen Problemen, Computer Vision wird in der medizinischen Bildgebung eingesetzt und ANNs treiben die Lieferung von Drohnen an. Je komplexer und vielschichtiger KNNs werden, desto geringer wird der Bedarf an menschlicher Intelligenz in diesem System. Sogar Bereiche wie das Design haben begonnen, KI-Lösungen mit generativem Design einzusetzen.
Die letztendliche Entwicklung aller KNNs zusammengenommen wäre die allgemeine Intelligenz – eine Form der Intelligenz, die so hoch entwickelt ist, dass sie alle der Menschheit bekannten und unbekannten Informationen lernen und wahrnehmen kann. Obwohl es eine sehr ferne Realität ist, wenn überhaupt möglich, ist es dank der breiten Akzeptanz von ANN zu einem denkbaren Konzept geworden.