
解釋頂級機器學習模型
已發表: 2022-11-24機器學習 (ML) 是一項技術創新,不斷在許多領域證明其價值。
機器學習與人工智能和深度學習有關。 由於我們生活在一個不斷進步的技術時代,現在可以預測接下來會發生什麼,並知道如何使用 ML 改變我們的方法。
因此,您不僅限於手動方式; 現在幾乎所有任務都是自動化的。 針對不同的工作設計了不同的機器學習算法。 這些算法可以解決複雜的問題並節省數小時的業務時間。
這方面的示例可能是下棋、填寫數據、進行手術、從購物清單中選擇最佳選項等等。
我將在本文中詳細解釋機器學習算法和模型。
開始了!
什麼是機器學習?

機器學習是一種技能或技術,機器(例如計算機)需要通過使用統計模型和算法來構建學習和適應能力,而無需高度編程。
因此,機器的行為與人類相似。 它是一種人工智能,允許軟件應用程序通過利用數據和改進自身來更準確地預測和執行不同的任務。
由於計算技術發展迅速,今天的機器學習與過去的機器學習不同。 從模式識別到學習執行某些任務的理論,機器學習證明了它的存在。
通過機器學習,計算機可以從以前的計算中學習,以產生可重複、可靠的決策和結果。 換句話說,機器學習是一門獲得新動力的科學。
儘管許多算法已經使用了很長時間,但能夠自動將復雜計算應用於大數據,而且越來越快,一遍又一遍,這是最近的發展。
一些公開的例子如下:
- 在線推薦折扣和優惠,例如來自 Netflix 和亞馬遜
- 自動駕駛和大肆宣傳的谷歌汽車
- 檢測欺詐並提出一些跳過這些問題的方法
還有很多。
為什麼需要機器學習?

機器學習是每個企業所有者在其軟件應用程序中實施的一個重要概念,以了解他們的客戶行為、業務運營模式等。 它支持最新產品的開發。
許多領先的公司,如穀歌、優步、Instagram、亞馬遜等,都將機器學習作為其運營的核心部分。 但是,處理大量數據的行業都知道機器學習模型的重要性。
組織能夠利用這項技術高效地工作。 金融服務、政府、醫療保健、零售、運輸和石油天然氣等行業使用機器學習模型來提供更有價值的客戶結果。
誰在使用機器學習?

如今,機器學習被用於許多應用程序中。 最著名的例子是 Instagram、Facebook、Twitter 等上的推薦引擎。
Facebook 正在使用機器學習來個性化會員在他們的新聞提要上的體驗。 如果用戶經常停下來查看同一類別的帖子,推薦引擎就會開始顯示更多相同類別的帖子。
在屏幕背後,推薦引擎試圖通過會員的模式來研究他們的在線行為。 當用戶更改其操作時,新聞提要會自動調整。
與推薦引擎相關,許多企業使用相同的概念來運行他們的關鍵業務流程。 他們是:
- 客戶關係管理 (CRM) 軟件:它使用機器學習模型來分析訪問者的電子郵件,並提示銷售團隊首先立即響應最重要的消息。
- 商業智能 (BI) :分析和 BI 供應商使用該技術來識別基本數據點、模式和異常。
- 人力資源信息系統 (HRIS) :它在其軟件中使用機器學習模型來篩選其應用程序並識別所需職位的最佳人選。
- 自動駕駛汽車:機器學習算法使汽車製造公司能夠識別物體或感知駕駛員的行為以立即發出警報以防止事故發生。
- 虛擬助手:虛擬助手是結合監督和非監督模型來解釋語音和提供上下文的智能助手。
什麼是機器學習模型?

ML 模型是經過訓練以判斷和識別某些模式的計算機軟件或應用程序。 您可以在數據的幫助下訓練模型並為其提供算法,以便它從該數據中學習。
例如,您想要製作一個根據用戶的面部表情識別情緒的應用程序。 在這裡,您需要為模型提供標有不同情緒的不同面部圖像,並訓練好您的模型。 現在,您可以在您的應用程序中使用相同的模型來輕鬆確定用戶的心情。
簡單來說,機器學習模型是一種簡化的過程表示。 這是確定某物或向消費者推薦某物的最簡單方法。 模型中的所有內容都是近似值。
例如,當我們繪製或製造地球儀時,我們將其賦予球體形狀。 但實際的地球並不是我們所知道的球形。 在這裡,我們假設形狀來構建一些東西。 ML 模型的工作方式類似。
讓我們繼續討論不同的機器學習模型和算法。
機器學習模型的類型

所有機器學習模型都分為監督學習、非監督學習和強化學習。 監督學習和非監督學習被進一步分類為不同的術語。 讓我們詳細討論它們中的每一個。
監督學習
監督學習是一種簡單的機器學習模型,涉及學習基本功能。 此函數將輸入映射到輸出。 例如,如果您有一個包含兩個變量的數據集,年齡作為輸入,身高作為輸出。
使用監督學習模型,您可以輕鬆地根據一個人的年齡預測一個人的身高。 要了解此學習模型,您必須瀏覽子類別。
#1。 分類
分類是機器學習領域中廣泛使用的預測建模任務,其中為給定的輸入數據預測標籤。 它需要訓練數據集具有廣泛的輸入和輸出實例,模型可以從中學習。
訓練數據集用於找到將輸入數據樣本映射到指定類標籤的最小方法。 最後,訓練數據集表示包含大量輸出樣本的問題。

它用於垃圾郵件過濾、文檔搜索、手寫字符識別、欺詐檢測、語言識別和情感分析。 在這種情況下輸出是離散的。
#2。 回歸
在這個模型中,輸出總是連續的。 回歸分析本質上是一種統計方法,它模擬一個或多個獨立變量與目標或因變量之間的聯繫。
回歸允許查看因變量的數量如何相對於自變量發生變化,而其他自變量保持不變。 用於預測工資、年齡、溫度、物價等真實數據。
回歸分析是一種“最佳猜測”方法,可根據數據集生成預測。 簡單來說,將不同的數據點擬合成一個圖表,以獲得最精確的值。
示例:預測機票價格是一項常見的回歸工作。
無監督學習
無監督學習本質上用於在不參考標記結果的情況下從輸入數據中得出推論和尋找模式。 該技術用於在無需人工干預的情況下發現隱藏的數據分組和模式。
它可以發現信息中的差異和相似之處,使該技術成為客戶細分、探索性數據分析、模式和圖像識別以及交叉銷售策略的理想選擇。
無監督學習還用於使用包括兩種方法的降維過程來減少模型的有限數量的特徵:奇異值分解和主成分分析。

#1。 聚類
聚類是一種無監督學習模型,包括數據點的分組。 它經常用於欺詐檢測、文檔分類和客戶細分。

最常見的聚類或分組算法包括層次聚類、基於密度的聚類、均值偏移聚類和 k 均值聚類。 每種算法用於查找聚類的方式都不同,但每種情況下的目標都是相同的。
#2。 降維
它是一種減少正在考慮的各種隨機變量以獲得一組主變量的方法。 換句話說,將特徵集降維的過程稱為降維。 該模型的流行算法稱為主成分分析。
這個詛咒指的是向預測建模活動添加更多輸入,這使得建模更加困難。 一般用於數據可視化。
強化學習
強化學習是一種學習範式,在這種範式中,代理學習與環境交互,並且對於正確的動作集,它偶爾會獲得獎勵。
強化學習模型通過試錯法不斷學習。 成功結果的順序迫使模型針對給定問題制定最佳建議。 這通常用於遊戲、導航、機器人等領域。
機器學習算法的類型

#1。 線性回歸
在這裡,我們的想法是以盡可能最好的方式找到一條適合您需要的數據的線。 線性回歸模型有一些擴展,包括多元線性回歸和多項式回歸。 這意味著分別找到擬合數據的最佳平面和擬合數據的最佳曲線。
#2。 邏輯回歸
邏輯回歸與線性回歸算法非常相似,但本質上用於獲得有限數量的結果,比方說兩個。 在對結果概率建模時,邏輯回歸用於線性回歸。
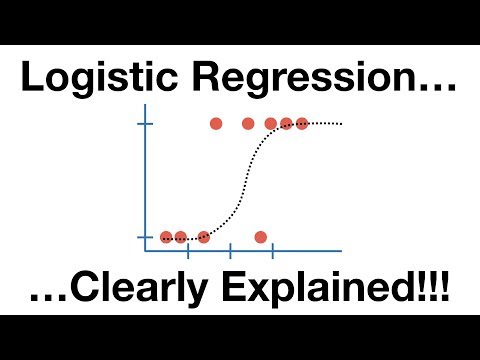
在這裡,邏輯方程以一種絕妙的方式構建,因此輸出變量將介於 0 和 1 之間。
#3。 決策樹
決策樹模型廣泛應用於戰略規劃、機器學習和運籌學。 它由節點組成。 如果你有更多的節點,你會得到更準確的結果。 決策樹的最後一個節點包含有助於更快做出決策的數據。
因此,最後的節點也稱為樹的葉子。 決策樹易於構建且直觀,但在準確性方面存在不足。
#4。 隨機森林
這是一種集成學習技術。 簡單來說,它是建立在決策樹之上的。 隨機森林模型通過使用真實數據的引導數據集涉及多個決策樹。 它在樹的每一步隨機選擇變量的子集。
隨機森林模型選擇每個決策樹的預測模式。 因此,依靠“多數獲勝”模型可以降低出錯的風險。
例如,如果您創建一個單獨的決策樹,而模型在最後預測為 0,那麼您將一無所有。 但是如果你一次創建 4 棵決策樹,你可能會得到值 1。這就是隨機森林學習模型的強大之處。
#5。 支持向量機
支持向量機 (SVM) 是一種受監督的機器學習算法,當我們談論最基本的層面時,它很複雜但很直觀。
例如,如果有兩種類型的數據或類,SVM 算法將找到該類數據之間的邊界或超平面,並最大化兩者之間的間隔。 有許多平面或邊界將兩個類分開,但一個平面可以最大化類之間的距離或邊距。
#6。 主成分分析 (PCA)
主成分分析意味著將更高維度的信息(例如 3 維)投影到更小的空間(例如 2 維)。 這導致數據的最小維度。 這樣,您可以在不影響位置的情況下保留模型中的原始值,但會減小尺寸。
簡單來說,它是一種降維模型,專門用於將數據集中存在的多個變量降為最少的變量。 可以通過將那些測量尺度相同且相關性高於其他變量的變量放在一起來完成。
該算法的主要目標是向您展示新的變量組並為您提供足夠的訪問權限來完成您的工作。
例如,PCA 有助於解釋包含許多問題或變量的調查,例如關於幸福感、學習文化或行為的調查。 您可以使用 PCA 模型看到其中的最小變量。
#7。 樸素貝葉斯
樸素貝葉斯算法用於數據科學,是許多行業中使用的流行模型。 這個想法取自貝葉斯定理,該定理解釋了概率方程,例如“給定 P 的 Q(輸出變量)的概率是多少。
這是當今技術時代使用的數學解釋。
除此之外,回歸部分提到的一些模型,包括決策樹、神經網絡和隨機森林,也屬於分類模型。 這兩項之間的唯一區別是輸出是離散的而不是連續的。
#8。 神經網絡
神經網絡再次成為行業中最常用的模型。 它本質上是各種數學方程式的網絡。 首先,它採用一個或多個變量作為輸入並通過方程網絡。 最後,它會為您提供一個或多個輸出變量的結果。

換句話說,神經網絡採用輸入向量並返回輸出向量。 它類似於數學中的矩陣。 它在輸入和輸出層中間有隱藏層,代表線性和激活函數。
#9。 K 最近鄰 (KNN) 算法
KNN 算法用於分類和回歸問題。 它廣泛用於數據科學行業以解決分類問題。 此外,它存儲所有可用案例並通過其 k 個鄰居的投票對即將到來的案例進行分類。
距離函數執行測量。 例如,如果你想要一個人的數據,你需要與離那個人最近的人交談,比如朋友、同事等。以類似的方式,KNN 算法起作用。
在選擇 KNN 算法之前,您需要考慮三件事。
- 需要對數據進行預處理。
- 變量需要歸一化,否則更高的變量會使模型產生偏差。
- KNN 的計算成本很高。
#10。 K-均值聚類
它屬於解決聚類任務的無監督機器學習模型。 在這裡,數據集被分類並分為幾個集群(假設為 K),以便集群中的所有點都是異質的,並且與數據同質。
K-Means 像這樣形成集群:
- K-Means 為每個集群選擇 K 個數據點,稱為質心。
- 每個數據點與最近的簇(質心)形成一個簇,即K個簇。
- 這會創建新的質心。
- 然後確定每個點的最近距離。 重複此過程,直到質心不發生變化。
結論
機器學習模型和算法對於關鍵過程非常具有決定性。 這些算法使我們的日常生活變得輕鬆簡單。 這樣,就可以更輕鬆地在幾秒鐘內完成最龐大的流程。
因此,ML 是當今許多行業都在使用的強大工具,並且其需求在不斷增長。 離我們能夠對複雜問題獲得更精確答案的日子不遠了。