
อธิบายโมเดลการเรียนรู้ของเครื่องยอดนิยม
เผยแพร่แล้ว: 2022-11-24แมชชีนเลิร์นนิง (ML) เป็นนวัตกรรมทางเทคโนโลยีที่พิสูจน์คุณค่าอย่างต่อเนื่องในหลายภาคส่วน
การเรียนรู้ของเครื่องเกี่ยวข้องกับปัญญาประดิษฐ์และการเรียนรู้เชิงลึก เนื่องจากเราอยู่ในยุคเทคโนโลยีที่มีความก้าวหน้าอย่างต่อเนื่อง ตอนนี้จึงเป็นไปได้ที่จะคาดการณ์สิ่งที่จะเกิดขึ้นต่อไปและรู้วิธีเปลี่ยนแนวทางของเราโดยใช้ ML
ดังนั้น คุณไม่ได้จำกัดอยู่แค่วิธีการด้วยตนเองเท่านั้น แทบทุกงานในปัจจุบันเป็นแบบอัตโนมัติ มีอัลกอริธึมการเรียนรู้ของเครื่องที่แตกต่างกันซึ่งออกแบบมาสำหรับการทำงานที่แตกต่างกัน อัลกอริทึมเหล่านี้สามารถแก้ปัญหาที่ซับซ้อนและประหยัดเวลาในการทำธุรกิจได้
ตัวอย่างนี้อาจเป็นการเล่นหมากรุก กรอกข้อมูล ทำการผ่าตัด เลือกตัวเลือกที่ดีที่สุดจากรายการช้อปปิ้ง และอื่นๆ อีกมากมาย
ฉันจะอธิบายอัลกอริทึมการเรียนรู้ของเครื่องและแบบจำลองโดยละเอียดในบทความนี้
ไปเลย!
แมชชีนเลิร์นนิงคืออะไร

การเรียนรู้ของเครื่องเป็นทักษะหรือเทคโนโลยีที่เครื่องจักร (เช่น คอมพิวเตอร์) จำเป็นต้องสร้างความสามารถในการเรียนรู้และปรับตัวโดยใช้แบบจำลองทางสถิติและอัลกอริทึมโดยไม่ต้องตั้งโปรแกรมไว้สูง
ด้วยเหตุนี้เครื่องจักรจึงมีพฤติกรรมคล้ายกับมนุษย์ เป็นปัญญาประดิษฐ์ประเภทหนึ่งที่ช่วยให้แอปพลิเคชันซอฟต์แวร์มีความแม่นยำมากขึ้นในการคาดการณ์และปฏิบัติงานต่างๆ โดยใช้ประโยชน์จากข้อมูลและปรับปรุงตัวเอง
เนื่องจากเทคโนโลยีคอมพิวเตอร์เติบโตอย่างรวดเร็ว การเรียนรู้ของเครื่องในปัจจุบันจึงไม่เหมือนกับการเรียนรู้ของเครื่องในอดีต แมชชีนเลิร์นนิงพิสูจน์การมีอยู่ของมันตั้งแต่การจดจำรูปแบบไปจนถึงทฤษฎีการเรียนรู้เพื่อดำเนินการบางอย่าง
ด้วยการเรียนรู้ของเครื่องคอมพิวเตอร์จะเรียนรู้จากการคำนวณก่อนหน้านี้เพื่อสร้างการตัดสินใจและผลลัพธ์ที่ทำซ้ำได้และเชื่อถือได้ กล่าวอีกนัยหนึ่ง แมชชีนเลิร์นนิงเป็นวิทยาศาสตร์ที่ได้รับแรงผลักดันใหม่
แม้ว่าจะมีการใช้อัลกอริธึมจำนวนมากมาเป็นเวลานาน แต่ความสามารถในการใช้การคำนวณที่ซับซ้อนโดยอัตโนมัติกับข้อมูลขนาดใหญ่ เร็วขึ้น เร็วขึ้น ซ้ำแล้วซ้ำเล่า คือการพัฒนาล่าสุด
ตัวอย่างที่เผยแพร่บางส่วนมีดังนี้:
- ส่วนลดและข้อเสนอแนะนำออนไลน์ เช่น จาก Netflix และ Amazon
- รถ Google ที่ขับเคลื่อนด้วยตนเองและตื่นเต้นอย่างมาก
- การตรวจจับการฉ้อโกงและแนะนำวิธีการข้ามปัญหาเหล่านั้น
และอื่น ๆ อีกมากมาย.
ทำไมคุณถึงต้องการการเรียนรู้ของเครื่อง

แมชชีนเลิร์นนิงเป็นแนวคิดสำคัญที่เจ้าของธุรกิจทุกคนนำไปใช้ในแอปพลิเคชันซอฟต์แวร์ของตนเพื่อทราบพฤติกรรมของลูกค้า รูปแบบการดำเนินงานทางธุรกิจ และอื่นๆ รองรับการพัฒนาผลิตภัณฑ์ใหม่ล่าสุด
บริษัทชั้นนำหลายแห่ง เช่น Google, Uber, Instagram, Amazon เป็นต้น กำหนดให้การเรียนรู้ด้วยเครื่องเป็นส่วนสำคัญของการดำเนินงาน อย่างไรก็ตาม อุตสาหกรรมที่ทำงานเกี่ยวกับข้อมูลจำนวนมากทราบดีถึงความสำคัญของโมเดลแมชชีนเลิร์นนิง
องค์กรสามารถทำงานได้อย่างมีประสิทธิภาพด้วยเทคโนโลยีนี้ อุตสาหกรรมต่างๆ เช่น บริการทางการเงิน รัฐบาล การดูแลสุขภาพ การค้าปลีก การขนส่ง และน้ำมัน-ก๊าซ ใช้โมเดลแมชชีนเลิร์นนิงเพื่อส่งมอบผลลัพธ์ที่มีคุณค่าให้กับลูกค้า
ใครใช้แมชชีนเลิร์นนิงบ้าง

การเรียนรู้ของเครื่องในปัจจุบันถูกนำมาใช้ในแอพพลิเคชั่นมากมาย ตัวอย่างที่เป็นที่รู้จักมากที่สุดคือเครื่องมือแนะนำบน Instagram, Facebook, Twitter เป็นต้น
Facebook กำลังใช้แมชชีนเลิร์นนิงเพื่อปรับแต่งประสบการณ์ของสมาชิกในฟีดข่าวของพวกเขา หากผู้ใช้หยุดตรวจสอบโพสต์ประเภทเดียวกันบ่อยๆ เครื่องมือแนะนำจะเริ่มแสดงโพสต์ประเภทเดียวกันมากขึ้น
เบื้องหลังหน้าจอ เครื่องมือแนะนำพยายามศึกษาพฤติกรรมออนไลน์ของสมาชิกผ่านรูปแบบของพวกเขา ฟีดข่าวจะปรับโดยอัตโนมัติเมื่อผู้ใช้เปลี่ยนการกระทำ
ที่เกี่ยวข้องกับเครื่องมือแนะนำ องค์กรหลายแห่งใช้แนวคิดเดียวกันเพื่อดำเนินขั้นตอนทางธุรกิจที่สำคัญของตน พวกเขาคือ:
- ซอฟต์แวร์การจัดการลูกค้าสัมพันธ์ (CRM) : ใช้โมเดลการเรียนรู้ของเครื่องเพื่อวิเคราะห์อีเมลของผู้เยี่ยมชมและกระตุ้นให้ทีมขายตอบกลับข้อความที่สำคัญที่สุดในทันที
- ระบบข่าวกรองธุรกิจ (BI) : ผู้ให้บริการ Analytics และ BI ใช้เทคโนโลยีเพื่อระบุจุดข้อมูล รูปแบบ และความผิดปกติที่สำคัญ
- ระบบสารสนเทศทรัพยากรมนุษย์ (HRIS) : ใช้โมเดลการเรียนรู้ของเครื่องในซอฟต์แวร์เพื่อกรองผ่านแอปพลิเคชันและจำแนกผู้สมัครที่ดีที่สุดสำหรับตำแหน่งที่ต้องการ
- รถยนต์ขับเอง : อัลกอริธึมการเรียนรู้ของเครื่องทำให้บริษัทผลิตรถยนต์สามารถระบุวัตถุหรือตรวจจับพฤติกรรมของคนขับเพื่อแจ้งเตือนทันทีเพื่อป้องกันอุบัติเหตุ
- ผู้ช่วย เสมือน : ผู้ช่วยเสมือนเป็นผู้ช่วยอัจฉริยะที่รวมโมเดลที่มีการควบคุมและไม่ได้รับการดูแลเพื่อตีความคำพูดและบริบทของการจัดหา
โมเดลการเรียนรู้ของเครื่องคืออะไร

โมเดล ML เป็นซอฟต์แวร์หรือแอปพลิเคชันคอมพิวเตอร์ที่ได้รับการฝึกฝนให้ตัดสินและจดจำรูปแบบบางอย่าง คุณสามารถฝึกโมเดลด้วยความช่วยเหลือของข้อมูลและจัดเตรียมอัลกอริทึมเพื่อให้เรียนรู้จากข้อมูลนั้น
ตัวอย่างเช่น คุณต้องการสร้างแอปพลิเคชันที่จดจำอารมณ์ตามการแสดงสีหน้าของผู้ใช้ ที่นี่ คุณต้องให้อาหารนางแบบด้วยภาพใบหน้าต่างๆ ที่มีป้ายแสดงอารมณ์ต่างๆ และฝึกนางแบบของคุณให้ดี ตอนนี้ คุณสามารถใช้โมเดลเดียวกันในแอปพลิเคชันของคุณเพื่อกำหนดอารมณ์ของผู้ใช้ได้อย่างง่ายดาย
กล่าวง่ายๆ โมเดลแมชชีนเลิร์นนิงคือการนำเสนอกระบวนการที่ง่ายขึ้น นี่เป็นวิธีที่ง่ายที่สุดในการพิจารณาบางสิ่งหรือแนะนำบางสิ่งให้กับผู้บริโภค ทุกอย่างในแบบจำลองทำงานเป็นค่าประมาณ
ตัวอย่างเช่น เมื่อเราวาดหรือผลิตลูกโลก เราจะให้มันเป็นทรงกลม แต่โลกที่แท้จริงไม่ได้เป็นทรงกลมอย่างที่เรารู้ ที่นี่เราถือว่ารูปร่างเพื่อสร้างบางสิ่งบางอย่าง โมเดล ML ทำงานคล้ายกัน
เรามาเริ่มกันเลยกับโมเดลการเรียนรู้ของเครื่องและอัลกอริทึมต่างๆ
ประเภทของโมเดลการเรียนรู้ของเครื่อง

โมเดลแมชชีนเลิร์นนิงทั้งหมดจัดอยู่ในประเภทการเรียนรู้ภายใต้การดูแล ไม่มีผู้ดูแล และการเรียนรู้เสริม การเรียนรู้ภายใต้การดูแลและการเรียนรู้ที่ไม่มีผู้ดูแลนั้นถูกจัดประเภทเป็นเงื่อนไขที่แตกต่างกัน เรามาพูดถึงรายละเอียดแต่ละข้อกัน
การเรียนรู้ภายใต้การนิเทศ
การเรียนรู้ภายใต้การดูแลเป็นรูปแบบการเรียนรู้ของเครื่องที่ไม่ซับซ้อนซึ่งเกี่ยวข้องกับการเรียนรู้ฟังก์ชันพื้นฐาน ฟังก์ชันนี้แมปอินพุตกับเอาต์พุต ตัวอย่างเช่น หากคุณมีชุดข้อมูลที่ประกอบด้วยตัวแปรสองตัว อายุเป็นอินพุตและความสูงเป็นเอาต์พุต
ด้วยโมเดลการเรียนรู้แบบมีผู้สอน คุณสามารถคาดการณ์ความสูงของบุคคลตามอายุของบุคคลนั้นได้อย่างง่ายดาย เพื่อให้เข้าใจรูปแบบการเรียนรู้นี้ คุณต้องผ่านหมวดหมู่ย่อย
#1. การจำแนกประเภท
การจำแนกประเภทเป็นงานสร้างแบบจำลองเชิงทำนายที่ใช้กันอย่างแพร่หลายในด้านการเรียนรู้ของเครื่อง โดยจะมีการคาดคะเนฉลากสำหรับข้อมูลอินพุตที่กำหนด จำเป็นต้องมีชุดข้อมูลการฝึกอบรมที่มีอินสแตนซ์อินพุตและเอาต์พุตที่หลากหลายซึ่งโมเดลเรียนรู้
ชุดข้อมูลการฝึกใช้เพื่อหาวิธีขั้นต่ำในการแมปตัวอย่างข้อมูลอินพุตกับป้ายกำกับคลาสที่ระบุ สุดท้าย ชุดข้อมูลการฝึกอบรมแสดงถึงปัญหาที่มีตัวอย่างเอาต์พุตจำนวนมาก

ใช้สำหรับการกรองสแปม ค้นหาเอกสาร การจดจำอักขระที่เขียนด้วยลายมือ การตรวจจับการฉ้อโกง การระบุภาษา และการวิเคราะห์ความรู้สึก เอาต์พุตจะไม่ต่อเนื่องในกรณีนี้
#2. การถดถอย
ในรุ่นนี้ เอาต์พุตจะต่อเนื่องเสมอ การวิเคราะห์การถดถอยโดยพื้นฐานแล้วเป็นวิธีการทางสถิติที่จำลองความสัมพันธ์ระหว่างตัวแปรหนึ่งตัวหรือมากกว่าที่เป็นอิสระต่อกันและเป้าหมายหรือตัวแปรตาม
การถดถอยช่วยให้เห็นว่าจำนวนของตัวแปรตามเปลี่ยนแปลงไปอย่างไรเมื่อเทียบกับตัวแปรอิสระในขณะที่ตัวแปรอิสระตัวอื่นมีค่าคงที่ ใช้ในการทำนายเงินเดือน อายุ อุณหภูมิ ราคา และข้อมูลจริงอื่นๆ
การวิเคราะห์การถดถอยเป็นวิธีการ "คาดเดาที่ดีที่สุด" ที่สร้างการคาดการณ์จากชุดข้อมูล พูดง่ายๆ ก็คือ การใส่จุดต่างๆ ของข้อมูลลงในกราฟเพื่อให้ได้ค่าที่แม่นยำที่สุด
ตัวอย่าง : การทำนายราคาตั๋วเครื่องบินเป็นงานถดถอยทั่วไป
การเรียนรู้แบบไม่มีผู้ควบคุม
โดยพื้นฐานแล้วการเรียนรู้แบบไม่มีผู้สอนจะใช้เพื่อสรุปผลและค้นหารูปแบบจากข้อมูลที่ป้อนเข้าโดยไม่มีการอ้างอิงถึงผลลัพธ์ที่มีป้ายกำกับ เทคนิคนี้ใช้เพื่อค้นหาการจัดกลุ่มและรูปแบบข้อมูลที่ซ่อนอยู่โดยไม่จำเป็นต้องมีการแทรกแซงจากมนุษย์
สามารถค้นพบความแตกต่างและความคล้ายคลึงกันในข้อมูล ทำให้เทคนิคนี้เหมาะสำหรับการแบ่งกลุ่มลูกค้า การวิเคราะห์ข้อมูลเชิงสำรวจ การจดจำรูปแบบและรูปภาพ และกลยุทธ์การขายต่อเนื่อง

การเรียนรู้แบบไม่มีผู้ดูแลยังใช้เพื่อลดจำนวนคุณลักษณะที่จำกัดของแบบจำลองโดยใช้กระบวนการลดขนาดที่มีสองวิธี: การสลายตัวของค่าเอกพจน์และการวิเคราะห์องค์ประกอบหลัก
#1. การรวมกลุ่ม
การทำคลัสเตอร์เป็นรูปแบบการเรียนรู้แบบไม่มีผู้ดูแลซึ่งรวมถึงการจัดกลุ่มของจุดข้อมูล มีการใช้บ่อยครั้งสำหรับการตรวจจับการฉ้อโกง การจัดประเภทเอกสาร และการแบ่งส่วนลูกค้า

อัลกอริทึมการจัดกลุ่มหรือการจัดกลุ่มที่พบมากที่สุด ได้แก่ การจัดกลุ่มแบบลำดับชั้น การจัดกลุ่มตามความหนาแน่น การจัดกลุ่มแบบกะเฉลี่ย และการจัดกลุ่มแบบค่าเฉลี่ย k ทุกอัลกอริทึมใช้เพื่อค้นหาคลัสเตอร์ต่างกัน แต่จุดมุ่งหมายจะเหมือนกันในทุกกรณี
#2. การลดขนาด
เป็นวิธีการลดตัวแปรสุ่มต่างๆ ที่อยู่ระหว่างการพิจารณาเพื่อให้ได้ชุดของตัวแปรหลัก กล่าวอีกนัยหนึ่ง กระบวนการลดมิติของชุดคุณลักษณะเรียกว่าการลดมิติ อัลกอริทึมยอดนิยมของแบบจำลองนี้เรียกว่าการวิเคราะห์องค์ประกอบหลัก
คำสาปนี้หมายถึงข้อเท็จจริงของการเพิ่มข้อมูลมากขึ้นในกิจกรรมการสร้างแบบจำลองเชิงทำนาย ซึ่งทำให้การสร้างแบบจำลองยากยิ่งขึ้น โดยทั่วไปจะใช้สำหรับการแสดงข้อมูล
การเรียนรู้การเสริมแรง
การเรียนรู้แบบเสริมแรงเป็นกระบวนทัศน์การเรียนรู้ที่ตัวแทนเรียนรู้ที่จะโต้ตอบกับสภาพแวดล้อมและสำหรับชุดของการกระทำที่ถูกต้อง บางครั้งตัวแทนจะได้รับรางวัล
รูปแบบการเรียนรู้แบบเสริมแรงจะเรียนรู้ในขณะที่เดินหน้าด้วยวิธีลองผิดลองถูก ลำดับของผลลัพธ์ที่สำเร็จทำให้โมเดลต้องพัฒนาคำแนะนำที่ดีที่สุดสำหรับปัญหาที่กำหนด มักใช้ในการเล่นเกม การนำทาง วิทยาการหุ่นยนต์ และอื่นๆ
ประเภทของอัลกอริทึมการเรียนรู้ของเครื่อง

#1. การถดถอยเชิงเส้น
ในที่นี้ แนวคิดคือการหาบรรทัดที่เหมาะกับข้อมูลที่คุณต้องการด้วยวิธีที่ดีที่สุดเท่าที่จะเป็นไปได้ มีส่วนขยายในแบบจำลองการถดถอยเชิงเส้นที่ประกอบด้วยการถดถอยเชิงเส้นพหุคูณและการถดถอยพหุนาม ซึ่งหมายถึงการหาระนาบที่ดีที่สุดที่เหมาะกับข้อมูลและเส้นโค้งที่ดีที่สุดที่เหมาะกับข้อมูลตามลำดับ
#2. การถดถอยโลจิสติก
การถดถอยโลจิสติกนั้นคล้ายกับอัลกอริทึมการถดถอยเชิงเส้นมาก แต่โดยพื้นฐานแล้วจะใช้เพื่อให้ได้ผลลัพธ์จำนวนจำกัด สมมุติว่าสอง การถดถอยโลจิสติกถูกใช้เหนือการถดถอยเชิงเส้นในขณะที่จำลองความน่าจะเป็นของผลลัพธ์
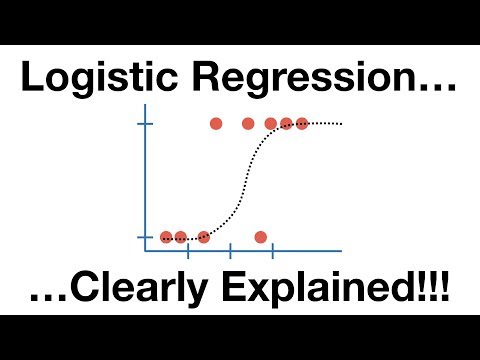
ที่นี่ สมการโลจิสติกถูกสร้างขึ้นด้วยวิธีที่ยอดเยี่ยมเพื่อให้ตัวแปรเอาต์พุตอยู่ระหว่าง 0 ถึง 1
#3. ต้นไม้แห่งการตัดสินใจ
โมเดลแผนผังการตัดสินใจใช้กันอย่างแพร่หลายในการวางแผนเชิงกลยุทธ์ การเรียนรู้ของเครื่อง และการวิจัยการดำเนินงาน ประกอบด้วยโหนด หากคุณมีโหนดมากขึ้น คุณจะได้ผลลัพธ์ที่แม่นยำยิ่งขึ้น โหนดสุดท้ายของแผนผังการตัดสินใจประกอบด้วยข้อมูลที่ช่วยให้ตัดสินใจได้เร็วขึ้น
ดังนั้นโหนดสุดท้ายจึงเรียกว่าใบไม้ของต้นไม้ ต้นไม้การตัดสินใจนั้นง่ายและไม่ซับซ้อนในการสร้าง แต่ขาดความแม่นยำ
#4. ป่าสุ่ม
เป็นเทคนิคการเรียนรู้ทั้งมวล พูดง่ายๆ ก็คือ มันถูกสร้างขึ้นจากต้นไม้การตัดสินใจ แบบจำลองฟอเรสต์แบบสุ่มเกี่ยวข้องกับแผนผังการตัดสินใจหลายรายการโดยใช้ชุดข้อมูลที่บู๊ตสแตรปของข้อมูลจริง มันสุ่มเลือกชุดย่อยของตัวแปรในทุกขั้นตอนของต้นไม้
แบบจำลองฟอเรสต์สุ่มเลือกโหมดการทำนายของแผนผังการตัดสินใจทั้งหมด ดังนั้น การใช้โมเดล "ส่วนใหญ่ชนะ" จึงช่วยลดความเสี่ยงของข้อผิดพลาด
ตัวอย่างเช่น หากคุณสร้างแผนผังการตัดสินใจแต่ละรายการและแบบจำลองทำนายว่า 0 ในตอนท้าย คุณจะไม่มีอะไรเลย แต่ถ้าคุณสร้างแผนผังการตัดสินใจ 4 ตัวพร้อมกัน คุณอาจได้ค่า 1 นี่คือพลังของโมเดลการเรียนรู้ป่าแบบสุ่ม
#5. สนับสนุนเครื่องเวกเตอร์
Support Vector Machine (SVM) เป็นอัลกอริธึมการเรียนรู้ของเครื่องภายใต้การดูแลที่ซับซ้อนแต่ใช้งานง่ายเมื่อเราพูดถึงระดับพื้นฐานที่สุด
ตัวอย่างเช่น หากมีข้อมูลหรือคลาสอยู่สองประเภท อัลกอริทึม SVM จะค้นหาขอบเขตหรือไฮเปอร์เพลนระหว่างคลาสของข้อมูลนั้น และเพิ่มระยะขอบระหว่างทั้งสองให้สูงสุด มีระนาบหรือขอบเขตมากมายที่แยกสองคลาส แต่ระนาบเดียวสามารถเพิ่มระยะห่างหรือระยะขอบระหว่างคลาสได้สูงสุด
#6. การวิเคราะห์องค์ประกอบหลัก (PCA)
การวิเคราะห์องค์ประกอบหลักหมายถึงการฉายข้อมูลมิติที่สูงขึ้น เช่น 3 มิติ ไปยังพื้นที่ที่เล็กกว่า เช่น 2 มิติ ส่งผลให้ข้อมูลมีมิติน้อยที่สุด ด้วยวิธีนี้ คุณสามารถคงค่าเดิมไว้ในโมเดลโดยไม่ขัดขวางตำแหน่งแต่ลดขนาดลง
พูดง่ายๆ ก็คือ มันคือโมเดลการลดขนาดซึ่งใช้โดยเฉพาะเพื่อนำตัวแปรหลายตัวที่มีอยู่ในชุดข้อมูลลงไปให้เหลือตัวแปรน้อยที่สุด ทำได้โดยนำตัวแปรเหล่านั้นมารวมกันซึ่งมีมาตราส่วนการวัดเท่ากันและมีความสัมพันธ์กันสูงกว่าตัวแปรอื่นๆ
เป้าหมายหลักของอัลกอริทึมนี้คือการแสดงกลุ่มตัวแปรใหม่และให้คุณเข้าถึงได้มากพอที่จะทำงานให้เสร็จ
ตัวอย่างเช่น PCA ช่วยตีความแบบสำรวจที่มีคำถามหรือตัวแปรมากมาย เช่น แบบสำรวจเกี่ยวกับความเป็นอยู่ที่ดี การศึกษาวัฒนธรรม หรือพฤติกรรม คุณสามารถดูตัวแปรขั้นต่ำนี้ได้ด้วยโมเดล PCA
#7. ไร้เดียงสา Bayes
อัลกอริทึม Naive Bayes ใช้ในวิทยาการข้อมูลและเป็นโมเดลที่นิยมใช้ในหลายอุตสาหกรรม แนวคิดนี้นำมาจากทฤษฎีบทเบย์ที่อธิบายสมการความน่าจะเป็น เช่น "ความน่าจะเป็นของ Q (ตัวแปรเอาต์พุต) เป็นเท่าใดเมื่อให้ P
เป็นคำอธิบายทางคณิตศาสตร์ที่ใช้ในยุคเทคโนโลยีปัจจุบัน
นอกเหนือจากนี้ แบบจำลองบางส่วนที่กล่าวถึงในส่วนของการถดถอย รวมถึงแผนผังการตัดสินใจ โครงข่ายประสาทเทียม และฟอเรสต์แบบสุ่ม ยังอยู่ภายใต้แบบจำลองการจำแนกประเภทอีกด้วย ข้อแตกต่างเพียงอย่างเดียวระหว่างคำศัพท์คือเอาต์พุตเป็นแบบแยกส่วนแทนที่จะเป็นแบบต่อเนื่อง
#8. โครงข่ายประสาทเทียม
โครงข่ายประสาทเทียมเป็นรูปแบบที่ใช้มากที่สุดในอุตสาหกรรมอีกครั้ง โดยพื้นฐานแล้วเป็นเครือข่ายของสมการทางคณิตศาสตร์ต่างๆ ประการแรก ต้องใช้ตัวแปรอย่างน้อยหนึ่งตัวเป็นอินพุตและผ่านเครือข่ายของสมการ ในท้ายที่สุด จะให้ผลลัพธ์เป็นตัวแปรเอาต์พุตตั้งแต่หนึ่งตัวขึ้นไป

กล่าวอีกนัยหนึ่ง โครงข่ายประสาทเทียมใช้เวกเตอร์ของอินพุตและส่งกลับเวกเตอร์ของเอาต์พุต มันคล้ายกับเมทริกซ์ในวิชาคณิตศาสตร์ มันมีเลเยอร์ที่ซ่อนอยู่ตรงกลางของเลเยอร์อินพุตและเอาท์พุตซึ่งเป็นตัวแทนของทั้งฟังก์ชันเชิงเส้นและการเปิดใช้งาน
#9. อัลกอริทึม K-เพื่อนบ้านที่ใกล้ที่สุด (KNN)
อัลกอริทึม KNN ใช้สำหรับปัญหาการจำแนกประเภทและการถดถอย มีการใช้กันอย่างแพร่หลายในอุตสาหกรรมวิทยาศาสตร์ข้อมูลเพื่อแก้ปัญหาการจำแนกประเภท ยิ่งไปกว่านั้น มันจัดเก็บเคสที่มีอยู่ทั้งหมดและจำแนกเคสที่กำลังจะมาถึงโดยการโหวตจากเพื่อนบ้าน
ฟังก์ชันระยะทางจะทำการวัด ตัวอย่างเช่น ถ้าคุณต้องการข้อมูลเกี่ยวกับบุคคล คุณต้องพูดคุยกับคนที่อยู่ใกล้ที่สุดกับบุคคลนั้น เช่น เพื่อน เพื่อนร่วมงาน ฯลฯ อัลกอริทึม KNN ก็ทำงานในลักษณะเดียวกัน
คุณต้องพิจารณาสามสิ่งก่อนที่จะเลือกอัลกอริทึม KNN
- ข้อมูลจำเป็นต้องได้รับการประมวลผลล่วงหน้า
- ตัวแปรจำเป็นต้องได้รับการทำให้เป็นมาตรฐาน ไม่เช่นนั้นตัวแปรที่สูงกว่าอาจทำให้โมเดลมีอคติได้
- KNN มีราคาแพงในการคำนวณ
#10. K-หมายถึงการรวมกลุ่ม
มันมาภายใต้โมเดลการเรียนรู้ของเครื่องที่ไม่มีผู้ดูแลซึ่งช่วยแก้ปัญหาการทำคลัสเตอร์ ที่นี่ชุดข้อมูลถูกจัดประเภทและจัดหมวดหมู่เป็นกลุ่มต่างๆ (เช่น K) เพื่อให้จุดทั้งหมดภายในกลุ่มนั้นต่างกันและเป็นเนื้อเดียวกันจากข้อมูล
K-Means ก่อตัวเป็นกลุ่มดังนี้:
- K-Means เลือกจำนวน K ของจุดข้อมูลที่เรียกว่า centroids สำหรับทุกคลัสเตอร์
- จุดข้อมูลทุกจุดสร้างคลัสเตอร์ที่มีคลัสเตอร์ใกล้เคียงที่สุด (เซนทรอยด์) เช่น คลัสเตอร์ K
- สิ่งนี้สร้างเซนทรอยด์ใหม่
- จากนั้นจึงกำหนดระยะทางที่ใกล้ที่สุดของแต่ละจุด กระบวนการนี้ทำซ้ำจนกว่าเซนทรอยด์จะไม่เปลี่ยนแปลง
บทสรุป
โมเดลการเรียนรู้ของเครื่องและอัลกอริทึมมีความสำคัญอย่างมากสำหรับกระบวนการที่สำคัญ อัลกอริธึมเหล่านี้ทำให้ชีวิตประจำวันของเราสะดวกและเรียบง่าย ด้วยวิธีนี้ การนำกระบวนการขนาดมหึมาออกมาทำได้ง่ายขึ้นในไม่กี่วินาที
ดังนั้น ML จึงเป็นเครื่องมืออันทรงพลังที่หลายอุตสาหกรรมใช้ในปัจจุบัน และความต้องการก็เพิ่มขึ้นอย่างต่อเนื่อง และวันนั้นก็อยู่ไม่ไกลที่เราจะได้คำตอบที่แม่นยำยิ่งขึ้นสำหรับปัญหาที่ซับซ้อนของเรา