
En İyi Makine Öğrenimi Modelleri Açıklandı
Yayınlanan: 2022-11-24Makine Öğrenimi (ML), birçok sektörde değerini kanıtlamaya devam eden teknolojik bir yeniliktir.
Makine öğrenimi, yapay zeka ve derin öğrenme ile ilgilidir. Sürekli ilerleyen bir teknolojik çağda yaşadığımız için, şimdi ne olacağını tahmin etmek ve makine öğrenimi kullanarak yaklaşımımızı nasıl değiştireceğimizi bilmek mümkün.
Böylece manuel yollarla sınırlı kalmıyorsunuz; günümüzde neredeyse her görev otomatikleştirilmiştir. Farklı işler için tasarlanmış farklı makine öğrenimi algoritmaları vardır. Bu algoritmalar karmaşık sorunları çözebilir ve saatlerce çalışma süresinden tasarruf sağlayabilir.
Buna örnek olarak satranç oynamak, veri doldurmak, ameliyat yapmak, alışveriş listesinden en iyi seçeneği seçmek ve daha birçok şey verilebilir.
Bu yazıda makine öğrenimi algoritmalarını ve modellerini detaylı bir şekilde anlatacağım.
İşte başlıyoruz!
Makine Öğrenimi Nedir?

Makine öğrenimi, bir makinenin (bilgisayar gibi) yüksek düzeyde programlanmadan istatistiksel modeller ve algoritmalar kullanarak öğrenme ve uyum sağlama yeteneği oluşturması gereken bir beceri veya teknolojidir.
Bunun bir sonucu olarak, makineler insanlara benzer şekilde davranır. Yazılım uygulamalarının verilerden yararlanarak ve kendini geliştirerek tahminlerde ve farklı görevleri gerçekleştirmede daha doğru hale gelmesini sağlayan bir Yapay Zeka türüdür.
Bilgi işlem teknolojileri hızla büyüdüğünden, günümüzün makine öğrenimi geçmişteki makine öğrenimi ile aynı değildir. Makine öğrenimi, örüntü tanımadan belirli görevleri gerçekleştirmeyi öğrenme teorisine kadar varlığını kanıtlar.
Makine öğrenimi ile bilgisayarlar, tekrarlanabilir, güvenilir kararlar ve sonuçlar üretmek için önceki hesaplamalardan öğrenir. Başka bir deyişle, makine öğrenimi yeni bir ivme kazanmış bir bilim dalıdır.
Birçok algoritma uzun süredir kullanılmasına rağmen, karmaşık hesaplamaları otomatik olarak büyük veriye daha hızlı ve daha hızlı, tekrar tekrar uygulayabilme yeteneği yeni bir gelişmedir.
Kamuya duyurulan bazı örnekler aşağıdaki gibidir:
- Netflix ve Amazon gibi çevrimiçi öneri indirimleri ve teklifleri
- Kendi kendine giden ve çok abartılı Google arabası
- Dolandırıcılığın tespiti ve bu sorunları atlamanın bazı yollarını önermek
Ve daha fazlası.
Neden Makine Öğrenimine ihtiyacınız var?

Makine öğrenimi, her işletme sahibinin müşteri davranışlarını, iş operasyon modellerini ve daha fazlasını bilmek için yazılım uygulamalarında uyguladığı önemli bir kavramdır. En son ürünlerin geliştirilmesini destekler.
Google, Uber, Instagram, Amazon vb. gibi birçok önde gelen şirket, makine öğrenimini operasyonlarının merkezi parçası haline getiriyor. Ancak, büyük miktarda veri üzerinde çalışan sektörler, makine öğrenimi modellerinin önemini biliyor.
Kuruluşlar bu teknoloji ile verimli bir şekilde çalışabilmektedir. Finansal hizmetler, devlet, sağlık, perakende, ulaşım ve petrol-gaz gibi sektörler, daha değerli müşteri sonuçları sunmak için makine öğrenimi modellerini kullanır.
Makine Öğrenimini kimler kullanıyor?

Günümüzde makine öğrenimi çok sayıda uygulamada kullanılmaktadır. En iyi bilinen örnek, Instagram, Facebook, Twitter vb.'deki öneri motorudur.
Facebook, üyelerin haber akışlarındaki deneyimlerini kişiselleştirmek için makine öğrenimini kullanıyor. Bir kullanıcı sık sık aynı kategorideki gönderileri kontrol etmeyi bırakırsa, öneri motoru aynı kategorideki gönderilerden daha fazlasını göstermeye başlar.
Ekranın arkasında, öneri motoru, üyelerin çevrimiçi davranışlarını kalıpları aracılığıyla incelemeye çalışır. Kullanıcı eylemini değiştirdiğinde haber akışı otomatik olarak ayarlanır.
Tavsiye motorlarıyla ilgili olarak, birçok kuruluş kritik iş prosedürlerini yürütmek için aynı konsepti kullanır. Bunlar:
- Müşteri İlişkileri Yönetimi (CRM) yazılımı : Ziyaretçilerin e-postalarını analiz etmek ve satış ekibinden en önemli mesajlara hemen yanıt vermesini istemek için makine öğrenimi modellerini kullanır.
- İş Zekası (BI) : Analitik ve BI sağlayıcıları, teknolojiyi temel veri noktalarını, kalıpları ve anormallikleri belirlemek için kullanır.
- İnsan Kaynakları Bilgi Sistemleri (HRIS) : Yazılımlarında makine öğrenimi modellerini kullanarak uygulamaları üzerinden filtreleme yapar ve gerekli pozisyon için en iyi adayları belirler.
- Kendi kendine giden arabalar : Makine öğrenimi algoritmaları, araba imalat şirketlerinin kazaları önlemek için nesneyi tanımlamasını veya sürücünün davranışını anında uyararak algılamasını mümkün kılar.
- Sanal asistanlar : Sanal asistanlar, konuşmayı yorumlamak ve bağlam sağlamak için denetimli ve denetimsiz modelleri birleştiren akıllı yardımcılardır.
Makine Öğrenimi Modelleri nelerdir?

Makine öğrenimi modeli, bazı kalıpları yargılamak ve tanımak için eğitilmiş bir bilgisayar yazılımı veya uygulamasıdır. Modeli veriler yardımıyla eğitebilir ve bu verilerden öğrenmesi için algoritmayı sağlayabilirsiniz.
Örneğin, kullanıcının yüz ifadelerine dayalı olarak duyguları tanıyan bir uygulama yapmak istiyorsunuz. Burada farklı duygularla etiketlenmiş farklı yüz görselleri ile modeli beslemeniz ve modelinizi iyi eğitmeniz gerekiyor. Artık, kullanıcının ruh halini kolayca belirlemek için aynı modeli uygulamanızda kullanabilirsiniz.
Basit bir ifadeyle, bir makine öğrenimi modeli, basitleştirilmiş bir süreç temsilidir. Bu, bir şeyi belirlemenin veya bir tüketiciye bir şey önermenin en kolay yoludur. Modeldeki her şey bir yaklaşım olarak çalışır.
Örneğin bir küre çizdiğimizde ya da ürettiğimizde ona küre şeklini vermiş oluruz. Ama gerçek dünya bildiğimiz gibi küresel değil. Burada bir şey inşa etmek için şekil alıyoruz. Makine öğrenimi modelleri benzer şekilde çalışır.
Farklı makine öğrenimi modelleri ve algoritmalarıyla devam edelim.
Makine Öğrenimi Modellerinin Türleri

Tüm makine öğrenimi modelleri denetimli, denetimsiz ve pekiştirmeli öğrenme olarak kategorize edilir. Denetimli ve denetimsiz öğrenme ayrıca farklı terimler olarak sınıflandırılır. Her birini ayrıntılı olarak tartışalım.
Denetimli Öğrenme
Denetimli öğrenme, temel bir işlevi öğrenmeyi içeren basit bir makine öğrenimi modelidir. Bu işlev, bir girdiyi çıktıya eşler. Örneğin, girdi olarak yaş ve çıktı olarak boy olmak üzere iki değişkenden oluşan bir veri kümeniz varsa.
Denetimli öğrenme modeliyle, bir kişinin boyunu o kişinin yaşına göre kolayca tahmin edebilirsiniz. Bu öğrenme modelini anlamak için alt kategorileri gözden geçirmelisiniz.
1 numara. sınıflandırma
Sınıflandırma, belirli bir girdi verisi için bir etiketin tahmin edildiği, makine öğrenimi alanında yaygın olarak kullanılan bir tahmine dayalı modelleme görevidir. Modelin öğrendiği çok çeşitli girdi ve çıktı örnekleri içeren eğitim veri setini gerektirir.
Eğitim veri seti, girdi verisi örneklerini belirtilen sınıf etiketlerine eşlemenin minimum yolunu bulmak için kullanılır. Son olarak, eğitim veri seti, çok sayıda çıktı örneğini içeren sorunu temsil eder.

Spam filtreleme, belge arama, el yazısı karakter tanıma, dolandırıcılık tespiti, dil tanımlama ve duygu analizi için kullanılır. Bu durumda çıktı ayrıktır.
2 numara. gerileme
Bu modelde çıktı daima süreklidir. Regresyon analizi, temelde bağımsız olan bir veya daha fazla değişken ile bir hedef veya bağımlı değişken arasındaki bağlantıyı modelleyen istatistiksel bir yaklaşımdır.
Regresyon, diğer bağımsız değişkenler sabitken bağımlı değişken sayısının bağımsız değişkene göre nasıl değiştiğini görmemizi sağlar. Maaş, yaş, sıcaklık, fiyat ve diğer gerçek verileri tahmin etmek için kullanılır.
Regresyon analizi, veri kümesinden bir tahmin oluşturan bir “en iyi tahmin” yöntemidir. Basit bir ifadeyle, en kesin değeri elde etmek için çeşitli veri noktalarını bir grafiğe sığdırmak.
Örnek : Bir uçak biletinin fiyatını tahmin etmek yaygın bir regresyon işidir.
Denetimsiz Öğrenme
Denetimsiz öğrenme, esasen çıkarımlar yapmak ve etiketli sonuçlara herhangi bir referans olmaksızın girdi verilerinden kalıplar bulmak için kullanılır. Bu teknik, insan müdahalesine ihtiyaç duymadan gizli veri gruplarını ve kalıplarını keşfetmek için kullanılır.

Bilgilerdeki farklılıkları ve benzerlikleri keşfederek bu tekniği müşteri segmentasyonu, keşif amaçlı veri analizi, model ve görüntü tanıma ve çapraz satış stratejileri için ideal hale getirir.
Denetimsiz öğrenme, iki yaklaşımı içeren boyutluluk azaltma sürecini kullanarak bir modelin sınırlı sayıda özelliğini azaltmak için de kullanılır: tekil değer ayrıştırma ve temel bileşen analizi.
1 numara. Kümeleme
Kümeleme, veri noktalarının gruplandırılmasını içeren denetimsiz bir öğrenme modelidir. Dolandırıcılık tespiti, belge sınıflandırması ve müşteri segmentasyonu için sıklıkla kullanılır.

En yaygın kümeleme veya gruplama algoritmaları arasında hiyerarşik kümeleme, yoğunluğa dayalı kümeleme, ortalama kaydırmalı kümeleme ve k-ortalama kümeleme yer alır. Her algoritma, kümeleri bulmak için farklı şekilde kullanılır, ancak amaç her durumda aynıdır.
2 numara. Boyutsal küçülme
Bir dizi temel değişken elde etmek için incelenmekte olan çeşitli rasgele değişkenleri azaltma yöntemidir. Başka bir deyişle, özellik setinin boyutunu küçültme işlemine boyut küçültme denir. Bu modelin popüler algoritmasına Temel Bileşen Analizi denir.
Bunun laneti, modellemeyi daha da zorlaştıran tahmine dayalı modelleme faaliyetlerine daha fazla girdi eklenmesi gerçeğine atıfta bulunur. Genellikle veri görselleştirme için kullanılır.
Takviyeli Öğrenme
Takviyeli öğrenme, bir aracının çevre ile etkileşim kurmayı öğrendiği ve doğru eylemler dizisi için ara sıra bir ödül aldığı bir öğrenme paradigmasıdır.
Takviyeli öğrenme modeli, deneme yanılma yöntemiyle ilerledikçe öğrenir. Başarılı sonuçlar dizisi, modeli belirli bir problem için en iyi tavsiyeyi geliştirmeye zorladı. Bu genellikle oyun, navigasyon, robotik ve daha fazlasında kullanılır.
Makine Öğrenimi Algoritma Türleri

1 numara. Doğrusal Regresyon
Buradaki fikir, ihtiyacınız olan verilere mümkün olan en iyi şekilde uyan bir satır bulmaktır. Çoklu doğrusal regresyon ve polinom regresyon içeren doğrusal regresyon modelinde uzantılar vardır. Bu, sırasıyla verilere uyan en iyi düzlemi ve verilere uyan en iyi eğriyi bulmak anlamına gelir.
2 numara. Lojistik regresyon
Lojistik regresyon, lineer regresyon algoritmasına çok benzer, ancak esas olarak sınırlı sayıda sonuç elde etmek için kullanılır, hadi iki diyelim. Sonuçların olasılığını modellerken doğrusal regresyon yerine lojistik regresyon kullanılır.
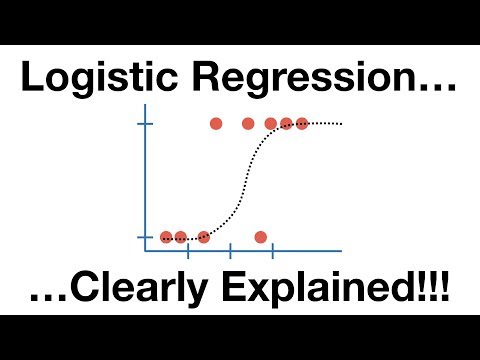
Burada, çıktı değişkeninin 0 ile 1 arasında olması için zekice bir lojistik denklem oluşturulmuştur.
3 numara. Karar ağacı
Karar ağacı modeli, stratejik planlama, makine öğrenimi ve yöneylem araştırmasında yaygın olarak kullanılmaktadır. Düğümlerden oluşur. Daha fazla düğümünüz varsa, daha doğru sonuçlar alırsınız. Karar ağacının son düğümü, kararların daha hızlı alınmasına yardımcı olan verilerden oluşur.
Böylece son düğümler ağaçların yaprakları olarak da anılır. Karar ağaçlarının oluşturulması kolay ve sezgiseldir, ancak doğruluk açısından yetersizdirler.
#4. Rastgele Orman
Bir topluluk öğrenme tekniğidir. Basit bir ifadeyle, karar ağaçlarından inşa edilmiştir. Rastgele ormanlar modeli, gerçek verilerin önyüklemeli veri kümelerini kullanarak birden fazla karar ağacı içerir. Ağacın her adımında değişkenlerin alt kümesini rastgele seçer.
Rastgele orman modeli, her karar ağacının tahmin modunu seçer. Bu nedenle, “çoğunluk kazanır” modeline güvenmek hata riskini azaltır.
Örneğin, bireysel bir karar ağacı oluşturursanız ve model sonunda 0 öngörürse, hiçbir şeyiniz olmaz. Ancak aynı anda 4 karar ağacı oluşturursanız, 1 değerini elde edebilirsiniz. Bu, rastgele orman öğrenme modelinin gücüdür.
# 5. Destek Vektör Makinesi
Bir Destek Vektör Makinesi (SVM), en temel seviyeden bahsettiğimizde karmaşık ama sezgisel olan denetimli bir makine öğrenimi algoritmasıdır.
Örneğin, iki tür veri veya sınıf varsa, DVM algoritması bu veri sınıfları arasında bir sınır veya hiperdüzlem bulur ve ikisi arasındaki marjı maksimize eder. İki sınıfı ayıran birçok düzlem veya sınır vardır, ancak bir düzlem, sınıflar arasındaki mesafeyi veya marjı maksimize edebilir.
#6. Temel Bileşen Analizi (PCA)
Temel bileşen analizi, 3 boyut gibi daha yüksek boyutlu bilgileri 2 boyut gibi daha küçük bir alana yansıtmak anlamına gelir. Bu, minimum veri boyutuyla sonuçlanır. Bu sayede pozisyonu bozmadan ama boyutları küçültmeden modeldeki orijinal değerleri koruyabilirsiniz.
Basit bir ifadeyle, özellikle veri setinde bulunan çoklu değişkenleri en az değişkene indirgemek için kullanılan bir boyut indirgeme modelidir. Ölçüm ölçeği aynı olan ve diğerlerinden daha yüksek korelasyona sahip olan değişkenleri bir araya getirerek yapılabilir.
Bu algoritmanın birincil amacı, size yeni değişken gruplarını göstermek ve işinizi yapmanız için yeterli erişim sağlamaktır.
Örneğin PCA, refah, çalışma kültürü veya davranış anketleri gibi birçok soru veya değişken içeren anketlerin yorumlanmasına yardımcı olur. Bunun minimum değişkenlerini PCA modeli ile görebilirsiniz.
#7. Naif bayanlar
Naive Bayes algoritması veri biliminde kullanılır ve birçok sektörde kullanılan popüler bir modeldir. Fikir, "P verildiğinde Q'nun (çıkış değişkeni) olasılığı nedir" gibi olasılık denklemini açıklayan Bayes Teoreminden alınmıştır.
Günümüz teknolojik çağında kullanılan matematiksel bir açıklamadır.
Bunların dışında regresyon bölümünde bahsedilen karar ağacı, sinir ağı ve rastgele orman gibi bazı modeller de sınıflandırma modeli kapsamına girmektedir. Terimler arasındaki tek fark, çıktının sürekli yerine ayrık olmasıdır.
# 8. Sinir ağı
Bir sinir ağı yine endüstrilerde en çok kullanılan modeldir. Temelde çeşitli matematiksel denklemlerin bir ağıdır. İlk olarak, bir veya daha fazla değişkeni girdi olarak alır ve denklemler ağından geçer. Sonunda, size bir veya daha fazla çıktı değişkeninde sonuç verir.

Başka bir deyişle, bir sinir ağı bir girdi vektörü alır ve çıktı vektörünü döndürür. Matematikteki matrislere benzer. Girdi ve çıktı katmanlarının ortasında hem lineer hem de aktivasyon fonksiyonlarını temsil eden gizli katmanlara sahiptir.
# 9. K-En Yakın Komşular (KNN) Algoritması
KNN algoritması hem sınıflandırma hem de regresyon problemleri için kullanılır. Veri bilimi endüstrisinde sınıflandırma problemlerini çözmek için yaygın olarak kullanılmaktadır. Ayrıca, mevcut tüm vakaları saklar ve k komşusunun oylarını alarak gelen vakaları sınıflandırır.
Mesafe fonksiyonu ölçümü gerçekleştirir. Örneğin, bir kişi hakkında veri istiyorsanız, o kişiye en yakın olan arkadaşlar, iş arkadaşları vb. kişilerle konuşmanız gerekir. KNN algoritması da benzer şekilde çalışır.
KNN algoritmasını seçmeden önce üç şeyi göz önünde bulundurmanız gerekir.
- Verilerin önceden işlenmesi gerekir.
- Değişkenlerin normalleştirilmesi gerekir veya daha yüksek değişkenler modeli saptırabilir.
- KNN hesaplama açısından pahalıdır.
# 10. K-Kümeleme anlamına gelir
Kümeleme görevlerini çözen denetimsiz bir makine öğrenimi modeli kapsamında gelir. Burada veri kümeleri sınıflandırılır ve birkaç küme (diyelim ki K) halinde kategorize edilir, böylece bir küme içindeki tüm noktalar verilerden heterojen ve homojen olur.
K-Means şu şekilde kümeler oluşturur:
- K-Means, her küme için centroid adı verilen K veri noktası sayısını seçer.
- Her veri noktası, en yakın kümeye (merkezi merkezler), yani K kümesine sahip bir küme oluşturur.
- Bu, yeni merkezler oluşturur.
- Daha sonra her nokta için en yakın mesafe belirlenir. Bu işlem merkezler değişmeyene kadar tekrarlanır.
Çözüm
Makine öğrenimi modelleri ve algoritmaları kritik süreçler için çok belirleyicidir. Bu algoritmalar günlük hayatımızı kolay ve basit hale getiriyor. Bu sayede en devasa süreçleri saniyeler içinde ortaya çıkarmak daha kolay hale geliyor.
Bu nedenle Makine Öğrenimi, günümüzde birçok endüstrinin kullandığı güçlü bir araçtır ve talebi sürekli olarak artmaktadır. Ve karmaşık sorunlarımıza daha kesin yanıtlar alabileceğimiz günler de uzak değil.