
トップ機械学習モデルの説明
公開: 2022-11-24機械学習 (ML) は、多くの分野でその価値を証明し続けている技術革新です。
機械学習は、人工知能や深層学習と関連しています。 私たちは絶え間なく進歩するテクノロジーの時代に生きているため、次に来るものを予測し、ML を使用してアプローチを変更する方法を知ることができるようになりました。
したがって、手動の方法に限定されません。 現在、ほとんどすべてのタスクが自動化されています。 さまざまな作業用に設計されたさまざまな機械学習アルゴリズムがあります。 これらのアルゴリズムは、複雑な問題を解決し、業務時間を節約できます。
この例としては、チェスをする、データを入力する、手術を行う、買い物リストから最適なオプションを選択するなどがあります。
この記事では、機械学習のアルゴリズムとモデルについて詳しく説明します。
どうぞ!
機械学習とは

機械学習とは、機械 (コンピューターなど) が、高度にプログラミングされていなくても、統計モデルとアルゴリズムを使用して学習および適応する能力を構築する必要があるスキルまたはテクノロジです。
その結果、機械は人間と同じように振る舞います。 これは、ソフトウェア アプリケーションがデータを活用してそれ自体を改善することにより、予測やさまざまなタスクの実行をより正確にすることを可能にする人工知能の一種です。
コンピューティング技術は急速に成長しているため、今日の機械学習は過去の機械学習と同じではありません。 機械学習は、パターン認識から特定のタスクを実行するための学習理論まで、その存在を証明しています。
機械学習を使用すると、コンピューターは以前の計算から学習して、反復可能で信頼性の高い決定と結果を生成します。 つまり、機械学習は新たな勢いを得た科学です。
多くのアルゴリズムが長い間使用されてきましたが、複雑な計算をビッグ データに自動的に適用する機能が、より速く、より速く、何度も繰り返されるようになったのは、最近の開発です。
公開されている例としては、次のようなものがあります。
- Netflix や Amazon などのオンライン推奨割引やオファー
- 自動運転で大々的に宣伝されている Google の車
- 詐欺の検出とそれらの問題を回避する方法の提案
などなど。
なぜ機械学習が必要なのですか?

機械学習は、顧客の行動やビジネスの運用パターンなどを知るために、すべてのビジネス オーナーがソフトウェア アプリケーションに実装する重要な概念です。 最新の製品開発をサポートします。
Google、Uber、Instagram、Amazon などの多くの大手企業は、機械学習を業務の中心に据えています。 ただし、大量のデータを扱う業界は、機械学習モデルの重要性を認識しています。
組織は、このテクノロジを使用して効率的に作業できます。 金融サービス、政府、ヘルスケア、小売、運輸、石油ガスなどの業界では、機械学習モデルを使用して、より価値のある顧客結果を提供しています。
機械学習を使用しているのは誰ですか?

現在、機械学習は多くのアプリケーションで使用されています。 最もよく知られている例は、Instagram、Facebook、Twitter などのレコメンデーション エンジンです。
Facebook は、機械学習を使用して、ニュース フィードでのメンバーのエクスペリエンスをパーソナライズしています。 ユーザーが頻繁に同じカテゴリの投稿をチェックするのをやめると、レコメンデーション エンジンは同じカテゴリの投稿をより多く表示し始めます。
画面の背後では、レコメンデーション エンジンがメンバーのオンライン行動をパターンから調査しようとします。 ユーザーがアクションを変更すると、ニュース フィードは自動的に調整されます。
レコメンデーション エンジンに関連して、多くの企業が同じ概念を使用して重要なビジネス プロシージャを実行しています。 彼らです:
- カスタマー リレーションシップ マネジメント (CRM) ソフトウェア: 機械学習モデルを使用して訪問者のメールを分析し、最も重要なメッセージからすぐに返信するよう営業チームに指示します。
- ビジネス インテリジェンス (BI) : 分析および BI ベンダーは、このテクノロジを使用して、重要なデータ ポイント、パターン、および異常を特定します。
- 人事情報システム (HRIS) : ソフトウェアで機械学習モデルを使用してアプリケーションをフィルタリングし、必要なポジションに最適な候補者を認識します。
- 自動運転車: 機械学習アルゴリズムにより、自動車製造会社は物体を識別したり、ドライバーの行動を感知したりして、事故を防ぐために即座に警告を発することができます。
- 仮想アシスタント: 仮想アシスタントは、教師ありモデルと教師なしモデルを組み合わせて音声を解釈し、コンテキストを提供するスマート アシスタントです。
機械学習モデルとは?

ML モデルは、いくつかのパターンを判断して認識するように訓練されたコンピューター ソフトウェアまたはアプリケーションです。 データを使用してモデルをトレーニングし、そのデータから学習するようにアルゴリズムを提供できます。
たとえば、ユーザーの表情に基づいて感情を認識するアプリケーションを作成したいとします。 ここでは、さまざまな感情でラベル付けされた顔のさまざまな画像をモデルに供給し、モデルを適切にトレーニングする必要があります。 これで、アプリケーションで同じモデルを使用して、ユーザーの気分を簡単に判断できます。
簡単に言えば、機械学習モデルは簡略化されたプロセス表現です。 これは、何かを判断したり、消費者に何かを勧めたりする最も簡単な方法です。 モデル内のすべてが近似値として機能します。
たとえば、地球儀を描いたり、製造したりするときは、球体の形にします。 しかし、私たちが知っているように、実際の地球は球形ではありません。 ここでは、何かを構築するための形状を想定しています。 ML モデルも同様に機能します。
さまざまな機械学習モデルとアルゴリズムを見ていきましょう。
機械学習モデルの種類

すべての機械学習モデルは、教師あり、教師なし、強化学習に分類されます。 教師あり学習と教師なし学習は、さらに別の用語として分類されます。 それぞれについて詳しく説明しましょう。
教師あり学習
教師あり学習は、基本的な関数の学習を含む単純な機械学習モデルです。 この関数は、入力を出力にマップします。 たとえば、年齢を入力として、身長を出力として、2 つの変数で構成されるデータセットがあるとします。
教師あり学習モデルを使用すると、年齢に基づいてその人の身長を簡単に予測できます。 この学習モデルを理解するには、サブカテゴリを確認する必要があります。
#1。 分類
分類は、特定の入力データに対してラベルが予測される機械学習の分野で広く使用されている予測モデリング タスクです。 モデルが学習する入力と出力の幅広いインスタンスを含むトレーニング データ セットが必要です。
トレーニング データ セットは、入力データ サンプルを指定されたクラス ラベルにマッピングするための最小限の方法を見つけるために使用されます。 最後に、トレーニング データ セットは、多数の出力サンプルを含む問題を表します。

スパム フィルタリング、ドキュメント検索、手書き文字認識、不正検出、言語識別、感情分析に使用されます。 この場合、出力は離散的です。
#2。 回帰
このモデルでは、出力は常に連続的です。 回帰分析は本質的に、独立した 1 つ以上の変数とターゲット変数または従属変数との間の関係をモデル化する統計的アプローチです。
回帰を使用すると、従属変数の数が独立変数に関連してどのように変化するかを確認できますが、他の独立変数は一定です。 給与、年齢、温度、価格、およびその他の実際のデータを予測するために使用されます。
回帰分析は、一連のデータから予測を生成する「最良の推測」方法です。 簡単に言えば、最も正確な値を得るために、データのさまざまなポイントをグラフに当てはめることです。
例: 航空券の価格を予測することは、一般的な回帰作業です。
教師なし学習
教師なし学習は、ラベル付けされた結果を参照せずに、入力データから推論を導き、パターンを見つけるために基本的に使用されます。 この手法は、人間の介入を必要とせずに、隠されたデータのグループとパターンを発見するために使用されます。
情報の相違点と類似点を発見できるため、この手法は顧客セグメンテーション、探索的データ分析、パターンと画像の認識、およびクロスセル戦略に最適です。
教師なし学習は、特異値分解と主成分分析の 2 つのアプローチを含む次元削減プロセスを使用して、モデルの有限数の機能を削減するためにも使用されます。

#1。 クラスタリング
クラスタリングは、データ ポイントのグループ化を含む教師なし学習モデルです。 不正行為の検出、ドキュメントの分類、および顧客のセグメンテーションに頻繁に使用されます。

最も一般的なクラスタリングまたはグループ化アルゴリズムには、階層クラスタリング、密度ベースのクラスタリング、平均シフト クラスタリング、および k-means クラスタリングが含まれます。 クラスターを見つけるために使用されるアルゴリズムはそれぞれ異なりますが、目的はすべての場合で同じです。
#2。 次元削減
主変数の集合を得るために検討中のさまざまな確率変数を削減する方法です。 つまり、特徴セットの次元を減らすプロセスは、次元削減と呼ばれます。 このモデルの一般的なアルゴリズムは、主成分分析と呼ばれます。
これの呪いは、予測モデリング活動により多くの入力を追加するという事実を指しており、モデル化がさらに困難になります。 通常、データの視覚化に使用されます。
強化学習
強化学習は、エージェントが環境と対話することを学習する学習パラダイムであり、正しい一連のアクションに対して、時折報酬を受け取ります。
強化学習モデルは試行錯誤しながら学習を進めていきます。 一連の成功した結果により、モデルは特定の問題に対する最適な推奨事項を作成する必要がありました。 これは、ゲーム、ナビゲーション、ロボット工学などでよく使用されます。
機械学習アルゴリズムの種類

#1。 線形回帰
ここでのアイデアは、必要なデータに最適な方法で適合する行を見つけることです。 線形回帰モデルには、多重線形回帰と多項式回帰を含む拡張機能があります。 これは、データに適合する最適な平面と、データに適合する最適な曲線をそれぞれ見つけることを意味します。
#2。 ロジスティック回帰
ロジスティック回帰は線形回帰アルゴリズムに非常に似ていますが、基本的に有限数の結果 (たとえば 2 つ) を取得するために使用されます。 結果の確率をモデル化する際には、線形回帰よりもロジスティック回帰が使用されます。
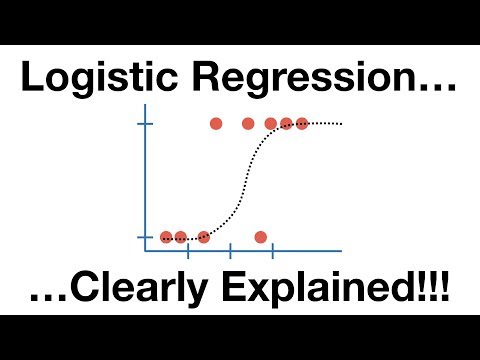
ここでは、出力変数が 0 と 1 の間になるようにロジスティック方程式が見事に構築されています。
#3。 ディシジョン ツリー
デシジョン ツリー モデルは、戦略計画、機械学習、運用調査で広く使用されています。 ノードで構成されています。 ノードが多いほど、より正確な結果が得られます。 意思決定ツリーの最後のノードは、意思決定を迅速に行うのに役立つデータで構成されています。
したがって、最後のノードはツリーの葉とも呼ばれます。 デシジョン ツリーは簡単かつ直感的に構築できますが、精度の点では不十分です。
#4。 ランダムフォレスト
アンサンブル学習法です。 簡単に言えば、決定木から構築されます。 ランダム フォレスト モデルには、真のデータのブートストラップされたデータセットを使用することにより、複数の決定木が含まれます。 ツリーの各ステップで、変数のサブセットをランダムに選択します。
ランダム フォレスト モデルは、すべての決定木の予測モードを選択します。 したがって、「多数決」モデルに依存することで、エラーのリスクが軽減されます。
たとえば、個々の決定木を作成し、モデルが最後に 0 を予測した場合、何もありません。 しかし、一度に 4 つの決定木を作成すると、値 1 が得られる可能性があります。これがランダム フォレスト学習モデルの能力です。
#5。 サポート ベクター マシン
サポート ベクター マシン (SVM) は、教師ありの機械学習アルゴリズムであり、複雑ですが、最も基本的なレベルについて言えば直感的です。
たとえば、2 種類のデータまたはクラスがある場合、SVM アルゴリズムはそのデータ クラス間の境界または超平面を見つけ、2 つの間のマージンを最大化します。 2 つのクラスを分離する平面または境界は多数ありますが、1 つの平面でクラス間の距離またはマージンを最大化できます。
#6。 主成分分析 (PCA)
主成分分析とは、3 次元などの高次元の情報を 2 次元などの小さな空間に射影することを意味します。 これにより、データの次元が最小になります。 このようにして、位置を妨げずに寸法を縮小することなく、モデルの元の値を維持できます。
簡単に言えば、これは、データセットに存在する複数の変数を最小の変数にするために特に使用される次元削減モデルです。 これは、測定スケールが同じで、他の変数よりも相関が高い変数をまとめることで実行できます。
このアルゴリズムの主な目的は、変数の新しいグループを表示し、作業を完了するのに十分なアクセスを提供することです。
たとえば、PCA は、幸福、研究文化、または行動に関する調査など、多くの質問や変数を含む調査を解釈するのに役立ちます。 PCA モデルを使用すると、この最小変数を確認できます。
#7。 単純ベイズ
Naive Bayes アルゴリズムはデータ サイエンスで使用され、多くの業界で使用されている一般的なモデルです。 この考え方は、「与えられた P で Q (出力変数) の確率はどうなるか」のような確率方程式を説明するベイズの定理から取られています。
これは、今日のテクノロジー時代に使用されている数学的説明です。
これらとは別に、決定木、ニューラル ネットワーク、ランダム フォレストなど、回帰の部分で言及されている一部のモデルも分類モデルに分類されます。 用語間の唯一の違いは、出力が連続ではなく離散であることです。
#8。 神経網
ニューラル ネットワークは、業界で最も使用されているモデルです。 それは本質的に、さまざまな数式のネットワークです。 まず、1 つ以上の変数を入力として取り、方程式のネットワークを通過します。 最終的に、1 つ以上の出力変数で結果が得られます。

つまり、ニューラル ネットワークは入力のベクトルを受け取り、出力のベクトルを返します。 数学の行列に似ています。 線形関数と活性化関数の両方を表す入力層と出力層の中間に隠れ層があります。
#9。 K 最近傍 (KNN) アルゴリズム
KNN アルゴリズムは、分類問題と回帰問題の両方に使用されます。 分類問題を解決するために、データ サイエンス業界で広く使用されています。 さらに、利用可能なすべてのケースを保存し、k 個の近隣の投票を取得して、今後のケースを分類します。
距離機能が測定を実行します。 たとえば、ある人物に関するデータが必要な場合は、その人物に最も近い人物 (友人、同僚など) と話す必要があります。同様に、KNN アルゴリズムが機能します。
KNN アルゴリズムを選択する前に、3 つのことを考慮する必要があります。
- データは前処理する必要があります。
- 変数を正規化する必要があります。そうしないと、変数が大きいほどモデルにバイアスがかかる可能性があります。
- KNN は計算コストが高くなります。
#10。 K-Means クラスタリング
これは、クラスタリング タスクを解決する教師なし機械学習モデルの下にあります。 ここで、データセットはいくつかのクラスター (K としましょう) に分類および分類されるため、クラスター内のすべてのポイントはデータから異質および同質になります。
K-Means は次のようなクラスターを形成します。
- K-Means は、クラスタごとに重心と呼ばれる K 個のデータ ポイントを選択します。
- すべてのデータ ポイントは、最も近いクラスター (重心) を持つクラスター、つまり K 個のクラスターを形成します。
- これにより、新しい重心が作成されます。
- 次に、各ポイントの最も近い距離が決定されます。 このプロセスは、重心が変化しなくなるまで繰り返されます。
結論
機械学習モデルとアルゴリズムは、重要なプロセスにとって非常に重要です。 これらのアルゴリズムは、私たちの日常生活を簡単かつシンプルにします。 このようにして、最も巨大なプロセスを数秒で簡単に実行できるようになります。
このように、ML は現在多くの業界で使用されている強力なツールであり、その需要は継続的に増加しています。 そして、複雑な問題に対してさらに正確な答えが得られる日もそう遠くありません。