
Model Pembelajaran Mesin Teratas Dijelaskan
Diterbitkan: 2022-11-24Machine Learning (ML) adalah inovasi teknologi yang terus membuktikan keampuhannya di banyak sektor.
Pembelajaran mesin terkait dengan kecerdasan buatan dan pembelajaran mendalam. Karena kita hidup di era teknologi yang terus berkembang, sekarang kita dapat memprediksi apa yang akan terjadi selanjutnya dan mengetahui cara mengubah pendekatan kita menggunakan ML.
Dengan demikian, Anda tidak terbatas pada cara manual; hampir setiap tugas saat ini otomatis. Ada berbagai algoritme pembelajaran mesin yang dirancang untuk pekerjaan berbeda. Algoritme ini dapat memecahkan masalah kompleks dan menghemat waktu bisnis.
Contohnya bisa bermain catur, mengisi data, melakukan operasi, memilih opsi terbaik dari daftar belanja, dan masih banyak lagi.
Saya akan menjelaskan algoritme dan model pembelajaran mesin secara mendetail di artikel ini.
Ini dia!
Apa itu Pembelajaran Mesin?

Pembelajaran mesin adalah keterampilan atau teknologi di mana mesin (seperti komputer) perlu membangun kemampuan untuk belajar dan beradaptasi dengan menggunakan model statistik dan algoritme tanpa terlalu diprogram.
Akibatnya, mesin berperilaku mirip dengan manusia. Ini adalah jenis Kecerdasan Buatan yang memungkinkan aplikasi perangkat lunak menjadi lebih akurat dalam prediksi dan melakukan berbagai tugas dengan memanfaatkan data dan meningkatkan dirinya sendiri.
Karena teknologi komputasi berkembang pesat, pembelajaran mesin saat ini tidak sama dengan pembelajaran mesin di masa lalu. Pembelajaran mesin membuktikan keberadaannya mulai dari pengenalan pola hingga teori pembelajaran untuk melakukan tugas tertentu.
Dengan pembelajaran mesin, komputer belajar dari perhitungan sebelumnya untuk menghasilkan keputusan dan hasil yang dapat diulang dan dapat diandalkan. Dengan kata lain, pembelajaran mesin adalah ilmu yang mendapatkan momentum baru.
Meskipun banyak algoritme telah digunakan sejak lama, kemampuan untuk menerapkan perhitungan kompleks secara otomatis ke data besar, lebih cepat dan lebih cepat, berulang kali, merupakan perkembangan terkini.
Beberapa contoh yang dipublikasikan adalah sebagai berikut:
- Diskon dan penawaran rekomendasi online, seperti dari Netflix dan Amazon
- Mobil Google yang dapat mengemudi sendiri dan sangat digemari
- Deteksi penipuan dan menyarankan beberapa cara untuk melewati masalah tersebut
Dan masih banyak lagi.
Mengapa Anda membutuhkan Pembelajaran Mesin?

Pembelajaran mesin adalah konsep penting yang diterapkan oleh setiap pemilik bisnis dalam aplikasi perangkat lunak mereka untuk mengetahui perilaku pelanggan, pola operasional bisnis, dan lainnya. Ini mendukung pengembangan produk terbaru.
Banyak perusahaan terkemuka, seperti Google, Uber, Instagram, Amazon, dll., menjadikan pembelajaran mesin sebagai bagian utama dari operasi mereka. Namun, industri yang mengerjakan data dalam jumlah besar mengetahui pentingnya model pembelajaran mesin.
Organisasi dapat bekerja secara efisien dengan teknologi ini. Industri seperti layanan keuangan, pemerintah, perawatan kesehatan, ritel, transportasi, dan minyak-gas menggunakan model pembelajaran mesin untuk memberikan hasil pelanggan yang lebih berharga.
Siapa yang menggunakan Pembelajaran Mesin?

Pembelajaran mesin saat ini digunakan dalam banyak aplikasi. Contoh paling terkenal adalah mesin rekomendasi di Instagram, Facebook, Twitter, dll.
Facebook menggunakan pembelajaran mesin untuk mempersonalisasi pengalaman anggota di umpan berita mereka. Jika pengguna sering berhenti untuk memeriksa kategori postingan yang sama, mesin rekomendasi mulai menampilkan lebih banyak postingan kategori yang sama.
Di belakang layar, mesin rekomendasi mencoba mempelajari perilaku online para anggota melalui pola mereka. Umpan berita menyesuaikan secara otomatis saat pengguna mengubah tindakannya.
Terkait dengan mesin rekomendasi, banyak perusahaan menggunakan konsep yang sama untuk menjalankan prosedur bisnis penting mereka. Mereka:
- Perangkat lunak Manajemen Hubungan Pelanggan (CRM) : Menggunakan model pembelajaran mesin untuk menganalisis email pengunjung dan mendorong tim penjualan untuk segera menanggapi pesan yang paling penting terlebih dahulu.
- Business Intelligence (BI) : Analisis dan vendor BI menggunakan teknologi untuk mengidentifikasi poin data penting, pola, dan anomali.
- Sistem Informasi Sumber Daya Manusia (HRIS) : Ini menggunakan model pembelajaran mesin dalam perangkat lunaknya untuk menyaring aplikasinya dan mengenali kandidat terbaik untuk posisi yang dibutuhkan.
- Mobil self-driving : Algoritme pembelajaran mesin memungkinkan perusahaan manufaktur mobil untuk mengidentifikasi objek atau merasakan perilaku pengemudi untuk segera waspada guna mencegah kecelakaan.
- Asisten virtual : Asisten virtual adalah asisten cerdas yang menggabungkan model yang diawasi dan tidak diawasi untuk menginterpretasikan ucapan dan menyediakan konteks.
Apa itu Model Pembelajaran Mesin?

Model ML adalah perangkat lunak atau aplikasi komputer yang dilatih untuk menilai dan mengenali beberapa pola. Anda dapat melatih model dengan bantuan data dan melengkapinya dengan algoritme sehingga model dapat belajar dari data tersebut.
Misalnya, Anda ingin membuat aplikasi yang mengenali emosi berdasarkan ekspresi wajah pengguna. Di sini, Anda perlu memberi makan model dengan gambar wajah berbeda yang diberi label emosi berbeda dan melatih model Anda dengan baik. Sekarang, Anda dapat menggunakan model yang sama di aplikasi Anda untuk menentukan suasana hati pengguna dengan mudah.
Secara sederhana, model pembelajaran mesin adalah representasi proses yang disederhanakan. Ini adalah cara termudah untuk menentukan sesuatu atau merekomendasikan sesuatu kepada konsumen. Segala sesuatu dalam model berfungsi sebagai perkiraan.
Misalnya, saat kita menggambar bola dunia atau membuatnya, kita memberinya bentuk bola. Tapi dunia sebenarnya tidak bulat seperti yang kita tahu. Di sini, kami menganggap bentuk untuk membangun sesuatu. Model ML bekerja dengan cara yang sama.
Mari kita lanjutkan dengan berbagai model dan algoritme pembelajaran mesin.
Jenis Model Pembelajaran Mesin

Semua model pembelajaran mesin dikategorikan sebagai pembelajaran terawasi, tidak terawasi, dan penguatan. Pembelajaran yang diawasi dan tidak diawasi selanjutnya diklasifikasikan sebagai istilah yang berbeda. Mari kita bahas masing-masing secara rinci.
Pembelajaran yang Diawasi
Pembelajaran yang diawasi adalah model pembelajaran mesin langsung yang melibatkan pembelajaran fungsi dasar. Fungsi ini memetakan input ke output. Misalnya, jika Anda memiliki dataset yang terdiri dari dua variabel, umur sebagai input dan tinggi sebagai output.
Dengan model pembelajaran terawasi, Anda dapat dengan mudah memprediksi tinggi badan seseorang berdasarkan usia orang tersebut. Untuk memahami model pembelajaran ini, Anda harus melalui sub-kategori.
#1. Klasifikasi
Klasifikasi adalah tugas pemodelan prediktif yang banyak digunakan di bidang pembelajaran mesin di mana label diprediksi untuk data input yang diberikan. Ini membutuhkan set data pelatihan dengan berbagai macam contoh input dan output dari mana model belajar.
Kumpulan data pelatihan digunakan untuk menemukan cara minimum untuk memetakan sampel data input ke label kelas yang ditentukan. Terakhir, kumpulan data pelatihan mewakili masalah yang berisi sejumlah besar sampel keluaran.

Ini digunakan untuk penyaringan spam, pencarian dokumen, pengenalan karakter tulisan tangan, deteksi penipuan, identifikasi bahasa, dan analisis sentimen. Outputnya diskrit dalam kasus ini.
#2. Regresi
Dalam model ini, keluarannya selalu kontinu. Analisis regresi pada dasarnya adalah pendekatan statistik yang memodelkan hubungan antara satu atau lebih variabel yang independen dan target atau variabel dependen.
Regresi memungkinkan untuk melihat bagaimana jumlah variabel dependen berubah dalam hubungannya dengan variabel independen sementara variabel independen lainnya konstan. Ini digunakan untuk memprediksi gaji, usia, suhu, harga, dan data nyata lainnya.
Analisis regresi adalah metode "tebakan terbaik" yang menghasilkan perkiraan dari sekumpulan data. Dengan kata sederhana, paskan berbagai titik data ke dalam grafik untuk mendapatkan nilai yang paling tepat.
Contoh : Memprediksi harga tiket pesawat adalah pekerjaan regresi yang umum.
Pembelajaran Tanpa Pengawasan
Pembelajaran tanpa pengawasan pada dasarnya digunakan untuk menarik kesimpulan serta menemukan pola dari data input tanpa referensi apa pun ke hasil berlabel. Teknik ini digunakan untuk menemukan pengelompokan dan pola data tersembunyi tanpa perlu campur tangan manusia.

Itu dapat menemukan perbedaan dan kesamaan dalam informasi, menjadikan teknik ini ideal untuk segmentasi pelanggan, analisis data eksplorasi, pengenalan pola dan citra, dan strategi penjualan silang.
Pembelajaran tanpa pengawasan juga digunakan untuk mengurangi jumlah fitur model yang terbatas menggunakan proses reduksi dimensi yang mencakup dua pendekatan: dekomposisi nilai singular dan analisis komponen utama.
#1. Kekelompokan
Clustering adalah model pembelajaran tanpa pengawasan yang mencakup pengelompokan titik data. Ini sering digunakan untuk deteksi penipuan, klasifikasi dokumen, dan segmentasi pelanggan.

Algoritma pengelompokan atau pengelompokan yang paling umum termasuk pengelompokan hierarkis, pengelompokan berbasis kepadatan, pengelompokan pergeseran rata-rata, dan pengelompokan k-means. Setiap algoritma digunakan secara berbeda untuk menemukan cluster, tetapi tujuannya sama dalam setiap kasus.
#2. Pengurangan Dimensi
Ini adalah metode pengurangan berbagai variabel acak yang sedang dipertimbangkan untuk mendapatkan satu set variabel utama. Dengan kata lain, proses penurunan dimensi set fitur disebut reduksi dimensi. Algoritma populer dari model ini disebut Analisis Komponen Utama.
Kutukan ini mengacu pada fakta menambahkan lebih banyak input ke aktivitas pemodelan prediktif, yang membuatnya semakin sulit untuk dimodelkan. Umumnya digunakan untuk visualisasi data.
Pembelajaran Penguatan
Pembelajaran penguatan adalah paradigma pembelajaran di mana agen belajar berinteraksi dengan lingkungan dan untuk serangkaian tindakan yang benar, kadang-kadang mendapat hadiah.
Model pembelajaran penguatan belajar sambil bergerak maju dengan metode trial and error. Urutan hasil yang sukses memaksa model untuk mengembangkan rekomendasi terbaik untuk masalah yang diberikan. Ini sering digunakan dalam permainan, navigasi, robotika, dan banyak lagi.
Jenis Algoritma Pembelajaran Mesin

#1. Regresi linier
Di sini, idenya adalah menemukan garis yang sesuai dengan data yang Anda butuhkan dengan cara terbaik. Ada perluasan dalam model regresi linier yang mencakup regresi linier berganda dan regresi polinomial. Ini berarti menemukan bidang terbaik yang sesuai dengan data dan kurva terbaik yang sesuai dengan data.
#2. Regresi logistik
Regresi logistik sangat mirip dengan algoritma regresi linier tetapi pada dasarnya digunakan untuk mendapatkan jumlah hasil yang terbatas, katakanlah dua. Regresi logistik digunakan di atas regresi linier sambil memodelkan probabilitas hasil.
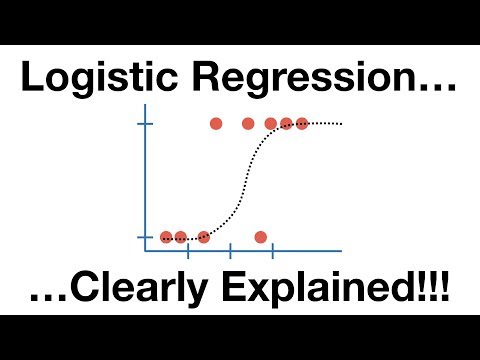
Di sini, persamaan logistik dibangun dengan cara yang brilian sehingga variabel keluaran akan berada di antara 0 dan 1.
#3. Pohon Keputusan
Model pohon keputusan banyak digunakan dalam perencanaan strategis, pembelajaran mesin, dan riset operasi. Ini terdiri dari node. Jika Anda memiliki lebih banyak node, Anda akan mendapatkan hasil yang lebih akurat. Node terakhir dari pohon keputusan terdiri dari data yang membantu membuat keputusan lebih cepat.
Jadi, simpul terakhir juga disebut sebagai daun pohon. Pohon keputusan mudah dan intuitif untuk dibangun, tetapi kurang akurat dalam hal akurasi.
#4. Hutan Acak
Ini adalah teknik pembelajaran ansambel. Secara sederhana, itu dibangun dari pohon keputusan. Model hutan acak melibatkan banyak pohon keputusan dengan menggunakan kumpulan data bootstrap dari data sebenarnya. Itu secara acak memilih subset dari variabel di setiap langkah pohon.
Model hutan acak memilih mode prediksi dari setiap pohon keputusan. Oleh karena itu, mengandalkan model “kemenangan mayoritas” mengurangi risiko kesalahan.
Misalnya, jika Anda membuat pohon keputusan individual dan model memprediksi 0 pada akhirnya, Anda tidak akan memiliki apa pun. Tetapi jika Anda membuat 4 pohon keputusan sekaligus, Anda mungkin mendapatkan nilai 1. Inilah kekuatan model pembelajaran hutan acak.
#5. Mendukung Mesin Vektor
Support Vector Machine (SVM) adalah algoritme pembelajaran mesin terawasi yang rumit tetapi intuitif ketika kita berbicara tentang level paling mendasar.
Misalnya, jika ada dua jenis data atau kelas, maka algoritma SVM akan mencari batas atau hyperplane antara kelas data tersebut dan memaksimalkan margin antara keduanya. Ada banyak bidang atau batas yang memisahkan dua kelas, tetapi satu bidang dapat memaksimalkan jarak atau margin antar kelas.
#6. Analisis Komponen Utama (PCA)
Analisis komponen utama berarti memproyeksikan informasi dimensi yang lebih tinggi, seperti 3 dimensi, ke ruang yang lebih kecil, seperti 2 dimensi. Ini menghasilkan dimensi data yang minimal. Dengan cara ini, Anda dapat mempertahankan nilai asli dalam model tanpa menghambat posisi tetapi mengurangi dimensi.
Dengan kata sederhana, ini adalah model pengurangan dimensi yang secara khusus digunakan untuk membawa banyak variabel yang ada dalam kumpulan data ke variabel terkecil. Hal itu dapat dilakukan dengan cara menggabungkan variabel-variabel yang skala pengukurannya sama dan memiliki korelasi yang lebih tinggi dari yang lain.
Tujuan utama algoritme ini adalah untuk menunjukkan kepada Anda grup variabel baru dan memberi Anda akses yang cukup untuk menyelesaikan pekerjaan Anda.
Misalnya, PCA membantu menginterpretasikan survei yang menyertakan banyak pertanyaan atau variabel, seperti survei tentang kesejahteraan, budaya belajar, atau perilaku. Anda dapat melihat variabel minimal ini dengan model PCA.
#7. Naif Bayes
Algoritma Naive Bayes digunakan dalam ilmu data dan merupakan model populer yang digunakan di banyak industri. Idenya diambil dari Teorema Bayes yang menjelaskan persamaan probabilitas seperti “berapa probabilitas Q (variabel output) diberikan P.
Ini adalah penjelasan matematis yang digunakan di era teknologi saat ini.
Selain itu, beberapa model yang disebutkan di bagian regresi, termasuk pohon keputusan, jaringan saraf, dan hutan acak, juga termasuk dalam model klasifikasi. Satu-satunya perbedaan antara istilah-istilah tersebut adalah bahwa keluarannya diskrit, bukan kontinu.
#8. Jaringan syaraf
Jaringan saraf sekali lagi merupakan model yang paling banyak digunakan di industri. Ini pada dasarnya adalah jaringan dari berbagai persamaan matematika. Pertama, dibutuhkan satu atau lebih variabel sebagai input dan melewati jaringan persamaan. Pada akhirnya, ini memberi Anda hasil dalam satu atau lebih variabel keluaran.

Dengan kata lain, jaringan saraf mengambil vektor input dan mengembalikan vektor output. Ini mirip dengan matriks dalam matematika. Ini memiliki lapisan tersembunyi di tengah lapisan input dan output yang mewakili fungsi linier dan aktivasi.
#9. Algoritma K-Nearest Neighbors (KNN).
Algoritma KNN digunakan untuk masalah klasifikasi dan regresi. Ini banyak digunakan dalam industri ilmu data untuk memecahkan masalah klasifikasi. Selain itu, ia menyimpan semua kasus yang tersedia dan mengklasifikasikan kasus yang datang dengan mengambil suara dari k tetangganya.
Fungsi jarak melakukan pengukuran. Misalnya, jika Anda menginginkan data tentang seseorang, Anda perlu berbicara dengan orang terdekat orang tersebut, seperti teman, kolega, dll. Dengan cara yang sama, algoritma KNN bekerja.
Anda perlu mempertimbangkan tiga hal sebelum memilih algoritma KNN.
- Data perlu diproses terlebih dahulu.
- Variabel perlu dinormalisasi, atau variabel yang lebih tinggi dapat membiaskan model.
- KNN mahal secara komputasi.
#10. Pengelompokan K-Means
Muncul di bawah model pembelajaran mesin tanpa pengawasan yang menyelesaikan tugas pengelompokan. Di sini kumpulan data diklasifikasikan dan dikategorikan menjadi beberapa cluster (misalkan K) sehingga semua titik dalam cluster bersifat heterogen dan homogen dari data.
K-Means membentuk cluster seperti ini:
- K-Means memilih jumlah K dari titik data, yang disebut centroid, untuk setiap cluster.
- Setiap titik data membentuk klaster dengan klaster terdekat (centroid), yaitu K klaster.
- Ini menciptakan centroid baru.
- Jarak terdekat untuk setiap titik kemudian ditentukan. Proses ini berulang sampai centroid tidak berubah.
Kesimpulan
Model dan algoritme pembelajaran mesin sangat menentukan untuk proses kritis. Algoritme ini membuat kehidupan kita sehari-hari menjadi mudah dan sederhana. Dengan cara ini, menjadi lebih mudah untuk mengeluarkan proses paling besar dalam hitungan detik.
Dengan demikian, ML adalah alat yang ampuh yang digunakan oleh banyak industri saat ini, dan permintaannya terus meningkat. Dan tidak lama lagi kita bisa mendapatkan jawaban yang lebih tepat untuk masalah kita yang rumit.