
Apache Hive ve Apache Impala: Büyük Farklılıklar
Yayınlanan: 2022-11-23Büyük veri analizinde yeniyseniz, birçok apache aracı radarınızda olabilir; ancak, farklı araçların saflığı kafa karıştırıcı ve bazen bunaltıcı hale gelebilir.
Bu gönderi, bu karışıklığı çözecek ve Apache Hive ile Impala'nın ne olduğunu ve onları birbirinden farklı kılan şeyleri açıklayacak!
Apache Kovanı
Apache Hive, Apache Hadoop platformu için bir SQL veri erişim arayüzüdür. Hive, SQL sözdizimini kullanarak verileri sorgulamanıza, toplamanıza ve analiz etmenize olanak tanır.
HDFS dosya sistemindeki veriler için, verileri sıradan bir tablo veya ilişkisel DBMS gibi ele almanıza izin veren bir okuma erişim şeması kullanılır. HiveQL sorguları, MapReduce işleri için Java koduna çevrilir.

Hive sorguları, SQL dilini temel alan ancak SQL-92 standardını tam olarak desteklemeyen HiveQL sorgu dilinde yazılır.
Ancak bu dil, HiveQL özelliklerini kullanmanın uygun olmadığı veya verimsiz olduğu durumlarda programcıların sorgularını kullanmalarına izin verir. HiveQL, kullanıcı tanımlı skaler işlevler (UDF'ler), toplamalar (UDAF kodları) ve tablo işlevleri (UDTF'ler) ile genişletilebilir.
Apache Hive nasıl çalışır?
Apache Hive, HiveQL dilinde (SQL'e yakın) yazılmış programları bir veya daha fazla MapReduce, Apache Tez veya Apache Spark görevine çevirir. Bunlar, Hadoop'ta başlatılabilen üç yürütme motorudur. Ardından, Apache Hive, bir yanıt oluşturmak üzere işleri bir kümede çalıştırmak üzere Hadoop Dağıtılmış Dosya Sistemi (HDFS) dosyası için verileri bir dizi halinde düzenler.
Apache Hive tabloları ilişkisel veritabanlarına benzer ve veri birimleri en önemli birimden en ayrıntılıya doğru düzenlenir. Veritabanları, yine "demetlere" bölünebilen bölümlerden oluşan dizilerdir.
Verilere HiveQL aracılığıyla erişilebilir. Her veritabanında veriler numaralandırılmıştır ve her tablo bir HDFS dizinine karşılık gelir.
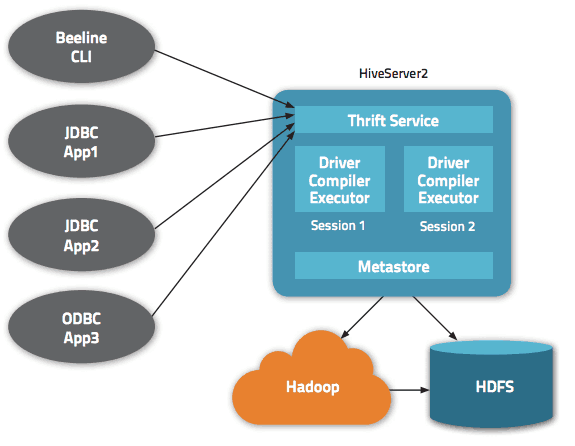
Apache Hive mimarisinde web arabirimi, CLI veya harici istemciler gibi birden çok arabirim mevcuttur.
Gerçekten de, "Apache Hive Thrift" sunucusu, uzak istemcilerin çeşitli programlama dillerini kullanarak Apache Hive'a komutlar ve istekler göndermesine olanak tanır. Apache Hive'ın merkezi dizini, tüm bilgileri içeren bir “metastore”dur.
Hive'ı çalıştıran motora "sürücü" denir. Optimum yürütme planını belirlemek için bir derleyici ve optimize edici içerir.
Son olarak, güvenlik Hadoop tarafından sağlanmaktadır. Bu nedenle, istemci ve sunucu arasında karşılıklı kimlik doğrulama için Kerberos'a güvenir. Apache Hive'da yeni oluşturulan dosyalar için izin, kullanıcı, grup veya başka türlü yetkilendirmeye izin verecek şekilde HDFS tarafından belirlenir.
Hive'ın Özellikleri
- Hem Hadoop hem de Spark'ın bilgi işlem motorunu destekler
- HDFS kullanır ve veri ambarı olarak çalışır.
- MapReduce kullanır ve ETL'yi destekler
- HDFS sayesinde Hadoop'a benzer hata toleransına sahiptir
Apache Kovanı: Yararları
Apache Hive, sorgular ve veri analizi için ideal bir çözümdür. Rekabet avantajı sağlayarak ve pazar talebine cevap vermeyi kolaylaştırarak nitel içgörüler elde etmeyi mümkün kılar.
Apache Hive'ın başlıca avantajları arasında, "SQL dostu" diliyle bağlantılı kullanım kolaylığından bahsedebiliriz. Ek olarak, verilerin dahili veritabanı biçiminde bir diskten okunması veya numaralandırılması gerekmediğinden, verilerin ilk eklenmesini hızlandırır.
Verilerin HDFS'de depolandığını bilerek, yüzlerce petabayta kadar büyük veri kümelerini Apache Hive üzerinde depolamak mümkündür. Bu çözüm, geleneksel bir veritabanından çok daha fazla ölçeklenebilir. Bir bulut hizmeti olduğunu bilen Apache Hive, kullanıcıların iş yüklerindeki (ör. görevler) dalgalanmalara dayalı olarak sanal sunucuları hızla başlatmasına olanak tanır.
Güvenlik ayrıca, bir sorun durumunda kurtarma açısından kritik iş yüklerini çoğaltma becerisiyle Hive'ın daha iyi performans gösterdiği bir özelliktir. Son olarak, saatte 100.000 adede kadar istek gerçekleştirebildiği için çalışma kapasitesi benzersizdir.
Apaçi Impala
Apache Impala, C++ ile yazılmış ve Apache 2.0 lisansı altında dağıtılan, Apache Hadoop'ta depolanan veriler üzerinde SQL sorgularının etkileşimli yürütülmesi için büyük ölçüde paralel bir SQL sorgu motorudur.
Impala ayrıca bir MPP (Massively Parallel Processing) motoru, dağıtılmış bir DBMS ve hatta bir SQL-on-Hadoop yığın veritabanı olarak da adlandırılır.

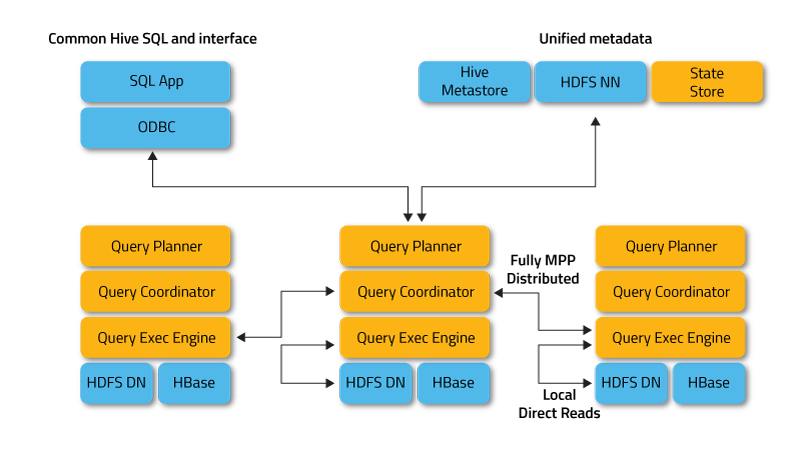
Impala, işlem örneklerinin farklı küme düğümlerinde çalıştığı, müşteri isteklerini aldığı, planladığı ve koordine ettiği dağıtılmış modda çalışır. Bu durumda, SQL sorgusunun parçalarının paralel yürütülmesi mümkündür.
İstemciler, Apache Hadoop (HBase ve HDFS) veya Amazon S3'te depolanan verilere karşı SQL sorguları gönderen kullanıcılar ve uygulamalardır. Impala ile etkileşim, HUE (Hadoop Kullanıcı Deneyimi) web arayüzü, ODBC, JDBC ve Impala Shell komut satırı kabuğu aracılığıyla gerçekleşir.
Impala, meta veri deposunu kullanan bir başka popüler SQL-on-Hadoop aracı olan Apache Hive'a altyapısal olarak bağlıdır. Özellikle Hive Metastore, Impala'nın veritabanlarının kullanılabilirliği ve yapısı hakkında bilgi sahibi olmasını sağlar.
Şema nesneleri oluştururken, değiştirirken ve silerken veya SQL deyimleri yoluyla tablolara veri yüklerken, karşılık gelen meta veri değişiklikleri, özel bir dizin hizmeti kullanılarak tüm Impala düğümlerine otomatik olarak yayılır.
Impala'nın temel bileşenleri aşağıdaki yürütülebilir dosyalardır:
- Impalad veya Impala arka plan programı, HDFS, HBase ve Amazon S3 verileri üzerinde sorguları planlayan ve yürüten bir sistem hizmetidir. Her küme düğümünde bir impalad işlemi çalışır.
- Statestore, kümedeki tüm impalad örneklerinin konumunu ve durumunu takip eden bir adlandırma hizmetidir. Bu sistem hizmetinin bir örneği, her düğümde ve ana sunucuda (Ad Düğümü) çalışır.
- Katalog, Impala DDL ve DML ifadelerindeki değişiklikleri etkilenen tüm Impala düğümlerine yayan, böylece yeni tabloların veya yeni yüklenen verilerin kümedeki herhangi bir düğüm tarafından hemen görülebilmesini sağlayan bir meta veri koordinasyon hizmetidir. Bir Katalog örneğinin, Statestored arka plan programıyla aynı küme ana bilgisayarında çalışıyor olması önerilir.
Apache Impala Nasıl Çalışır?
Impala, Apache Hive gibi, SQL yerine SQL92'nin bir alt kümesi olan benzer bir bildirime dayalı sorgu dili olan Hive Query Language (HiveQL) kullanır.
Impala'daki talebin gerçek yürütmesi aşağıdaki gibidir:
İstemci uygulaması, standartlaştırılmış ODBC veya JDBC sürücü arabirimleri aracılığıyla herhangi bir impalad'a bağlanarak bir SQL sorgusu gönderir. Bağlı impalad, mevcut talebin koordinatörü olur.

Kümedeki impalad örnekleri için görevleri belirlemek üzere SQL sorgusu analiz edilir; ardından en uygun sorgu yürütme planı oluşturulur.
Impalad, veri sağlamak için sistem hizmetlerinin yerel örneklerini kullanarak doğrudan HDFS ve HBase'e erişir. Apache Hive'dan farklı olarak, bu tür doğrudan etkileşim, ara sonuçlar kaydedilmediğinden sorgu yürütme süresinden önemli ölçüde tasarruf sağlar.
Yanıt olarak her arka plan programı, verileri istemciye geri göndererek koordinatör impalad'a döndürür.
Impala'nın Özellikleri
- Gerçek zamanlı bellek içi işleme desteği
- SQL dostu
- HDFS, Apache HBase ve Amazon S3 gibi depolama sistemlerini destekler
- Pentaho ve Tableau gibi BI araçlarıyla entegrasyonu destekler
- HiveQL söz dizimini kullanır
Apache Impala: Yararları
Impala, tüm sistem arka plan programı işlemleri doğrudan önyükleme sırasında başlatıldığı için olası başlatma ek yükünü önler. Sorgu yürütme süresinden önemli ölçüde tasarruf sağlar. Impala'nın hızında ek bir artış, Hadoop için bu SQL aracının, Hive'ın aksine, ara sonuçları depolamaması ve doğrudan HDFS veya HBase'e erişmesidir.
Ek olarak, Impala program kodunu Hive'ın yaptığı gibi derleme sırasında değil çalışma zamanında üretir. Bununla birlikte, Impala'nın yüksek hızlı performansının bir yan etkisi, güvenilirliğin azalmasıdır.
Özellikle, bir SQL sorgusunun yürütülmesi sırasında veri düğümü kapanırsa, Impala örneği yeniden başlatılır ve Hive, hata toleransı sağlayarak veri kaynağıyla bağlantıyı sürdürmeye devam eder.
Impala'nın diğer avantajları arasında güvenli bir ağ kimlik doğrulama protokolü Kerberos için yerleşik destek, önceliklendirme ve istek sırasını yönetme yeteneği ve LZO, Avro, RCFile, Parquet ve Sequence gibi popüler Büyük Veri biçimleri için destek yer alır.
Hive Vs Impala: Benzerlikler
Hive ve Impala, Apache Software Foundation lisansı altında ücretsiz olarak dağıtılır ve bir Hadoop kümesinde depolanan verilerle çalışmak için SQL araçlarına başvurur. Ayrıca, HDFS dağıtılmış dosya sistemini de kullanırlar.
Impala ve Hive, bir Apache Hadoop kümesinde depolanan büyük verilerin SQL işlenmesine ortak odaklanarak farklı görevler uygular. Impala, Hive tablolarını okumanıza ve yazmanıza izin veren SQL benzeri bir arayüz sağlar, böylece kolay veri alışverişi sağlar.
Aynı zamanda Impala, Hadoop üzerindeki SQL operasyonlarını oldukça hızlı ve verimli hale getirerek, bu DBMS'nin Büyük Veri analitiği araştırma projelerinde kullanılmasına olanak tanır. Impala, mümkün olduğunda, uzun süredir devam eden SQL toplu sorgularını yürütmek için halihazırda kullanılan mevcut bir Apache Hive altyapısıyla çalışır.
Ayrıca Impala, tablo tanımlarını bir metastore'da, geleneksel bir MySQL veya PostgreSQL veritabanında, yani Hive'ın benzer verileri depoladığı yerde saklar. Tüm sütunlar Impala'nın desteklediği veri türlerini, dosya formatlarını ve sıkıştırma kodeklerini kullandığı sürece Impala'nın Hive tablolarına erişmesine izin verir.
Hive Vs Impala: Farklılıklar

Programlama dili
Hive Java ile yazılırken, Impala C++ ile yazılır. Ancak Impala, bazı Java tabanlı Hive UDF'leri de kullanır.
Kullanım örnekleri
Veri Mühendisleri, Hive'ı ETL süreçlerinde (Ayıkla, Dönüştür, Yükle), örneğin seyahat toplayıcıları ve havaalanı bilgi sistemleri gibi büyük veri kümelerindeki uzun süreli toplu işler için kullanır. Buna karşılık Impala, esas olarak analistler ve veri bilimcileri için tasarlanmıştır ve esas olarak iş zekası gibi görevlerde kullanılır.
Verim
Impala, SQL sorgularını gerçek zamanlı olarak yürütürken, Hive düşük veri işleme hızıyla karakterize edilir. Basit SQL sorguları ile Impala, Hive'dan 6-69 kat daha hızlı çalışabilir. Ancak, Hive karmaşık sorguları daha iyi işler.
Gecikme/verimlilik
Hive'ın iş hacmi, Impala'nınkinden önemli ölçüde daha yüksektir. Sorgunun bellekte önbelleğe alınmasını sağlayan LLAP (Live Long and Process) özelliği, Hive'a düşük düzeyde iyi performans verir.
LLAP, HDFS veri düğümleriyle doğrudan etkileşim kurmanıza ve Büyük Veri bilgi işleminde aktif olarak kullanılan bir grafik modeli olan sıkıca tümleşik DAG sorgu yapısını (Yönlendirilmiş asiklik grafik) değiştirmenize olanak tanıyan uzun vadeli sistem hizmetlerini (arka plan programları) içerir.
Hata toleransı
Hive, tüm ara sonuçları koruyan, hataya dayanıklı bir sistemdir. Ayrıca ölçeklenebilirliği olumlu etkiler ancak veri işleme hızında düşüşe neden olur. Buna karşılık, Impala daha fazla belleğe bağlı olduğu için hataya dayanıklı bir platform olarak adlandırılamaz.
Kod dönüştürme
Hive, derleme zamanında sorgu ifadeleri oluştururken, Impala bunları çalışma zamanında oluşturur. Hive, uygulama ilk kez başlatıldığında "soğuk başlatma" sorunu ile karakterize edilir; veri kaynağına bağlantı kurma ihtiyacı nedeniyle sorgular yavaş dönüştürülür.
Impala'nın bu tür bir başlangıç ek yükü yoktur. SQL sorgularını işlemek için gerekli sistem servisleri (daemon'lar) açılışta başlatılır ve bu da işi hızlandırır.
Depolama desteği
Impala, LZO, Avro ve Parquet biçimlerini desteklerken Hive, Düz Metin ve ORC ile çalışır. Ancak her ikisi de RCFIle ve Sequence biçimlerini destekler.
| Apache Kovanı | Apaçi Impala | |
| Dil | java | C++ |
| Kullanım Örnekleri | Veri Mühendisliği | Analiz ve analitik |
| Verim | Basit sorgular için yüksek | Nispeten düşük |
| gecikme | Önbelleğe alma nedeniyle daha fazla gecikme | Daha az gizli |
| Hata Toleransı | MapReduce sayesinde daha toleranslı | MPP nedeniyle daha az toleranslı |
| Dönüştürmek | Soğuk başlatma nedeniyle yavaş | Daha hızlı dönüşüm |
| Depolama Desteği | Düz Metin ve ORC | LZO, Avro, Parke |
Son sözler
Hive ve Impala rekabet etmez, aksine etkili bir şekilde birbirini tamamlar. İkisi arasında önemli farklılıklar olsa da, oldukça fazla ortak nokta vardır ve birinin diğerine tercih edilmesi, verilere ve projenin özel gereksinimlerine bağlıdır.
Hadoop ve Spark arasındaki bire bir karşılaştırmaları da keşfedebilirsiniz.
.