
Apache Hive กับ Apache Impala: ความแตกต่างที่สำคัญ
เผยแพร่แล้ว: 2022-11-23หากคุณยังใหม่กับการวิเคราะห์ข้อมูลขนาดใหญ่ โฮสต์ของเครื่องมือ apache อาจอยู่ในเรดาร์ของคุณ อย่างไรก็ตาม เครื่องมือที่แตกต่างกันมากมายอาจสร้างความสับสนและบางครั้งก็ล้นหลาม
โพสต์นี้จะแก้ไขความสับสนนี้และอธิบายว่า Apache Hive และ Impala คืออะไรและอะไรที่ทำให้พวกมันแตกต่างจากกัน!
อาปาเช่ไฮฟ์
Apache Hive เป็นอินเทอร์เฟซการเข้าถึงข้อมูล SQL สำหรับแพลตฟอร์ม Apache Hadoop Hive ช่วยให้คุณสามารถสืบค้น รวม และวิเคราะห์ข้อมูลโดยใช้ไวยากรณ์ SQL
รูปแบบการเข้าถึงแบบอ่านใช้สำหรับข้อมูลในระบบไฟล์ HDFS ทำให้คุณสามารถปฏิบัติต่อข้อมูลได้เหมือนกับตารางทั่วไปหรือ DBMS เชิงสัมพันธ์ ข้อความค้นหา HiveQL ถูกแปลเป็นโค้ด Java สำหรับงาน MapReduce

ข้อความค้นหาแบบไฮฟ์เขียนด้วยภาษาคิวรี HiveQL ซึ่งใช้ภาษา SQL แต่ไม่รองรับมาตรฐาน SQL-92 อย่างเต็มรูปแบบ
อย่างไรก็ตาม ภาษานี้ช่วยให้โปรแกรมเมอร์ใช้การสืบค้นเมื่อไม่สะดวกหรือไม่มีประสิทธิภาพในการใช้คุณสมบัติ HiveQL HiveQL สามารถขยายได้ด้วยฟังก์ชันสเกลาร์ที่ผู้ใช้กำหนด (UDF) การรวม (รหัส UDAF) และฟังก์ชันตาราง (UDTF)
Apache Hive ทำงานอย่างไร
Apache Hive แปลโปรแกรมที่เขียนด้วยภาษา HiveQL (ใกล้เคียงกับ SQL) เป็นงาน MapReduce, Apache Tez หรือ Apache Spark อย่างน้อยหนึ่งงาน เหล่านี้คือเครื่องมือการดำเนินการสามรายการที่สามารถเปิดใช้บน Hadoop จากนั้น Apache Hive จะจัดระเบียบข้อมูลเป็นอาร์เรย์สำหรับไฟล์ Hadoop Distributed File System (HDFS) เพื่อเรียกใช้งานบนคลัสเตอร์เพื่อสร้างการตอบสนอง
ตาราง Apache Hive คล้ายกับฐานข้อมูลเชิงสัมพันธ์ และหน่วยข้อมูลจะถูกจัดระเบียบจากหน่วยที่สำคัญที่สุดไปยังหน่วยที่ละเอียดที่สุด ฐานข้อมูลเป็นอาร์เรย์ที่ประกอบด้วยพาร์ติชัน ซึ่งสามารถแยกย่อยออกเป็น "บัคเก็ต" ได้อีกครั้ง
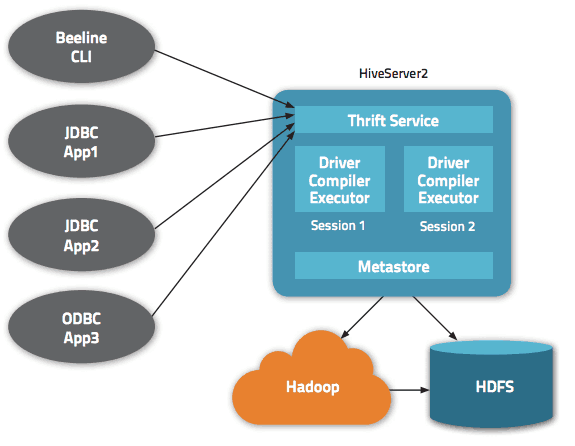
ข้อมูลสามารถเข้าถึงได้ผ่าน HiveQL ภายในแต่ละฐานข้อมูล ข้อมูลจะมีหมายเลข และแต่ละตารางจะสอดคล้องกับไดเร็กทอรี HDFS
อินเทอร์เฟซหลายรายการพร้อมใช้งานภายในสถาปัตยกรรม Apache Hive เช่น เว็บอินเทอร์เฟซ CLI หรือไคลเอนต์ภายนอก
แท้จริงแล้ว เซิร์ฟเวอร์ “Apache Hive Thrift” อนุญาตให้ไคลเอ็นต์ระยะไกลส่งคำสั่งและคำขอไปยัง Apache Hive โดยใช้ภาษาโปรแกรมต่างๆ ไดเรกทอรีกลางของ Apache Hive คือ "metastore" ที่มีข้อมูลทั้งหมด
เครื่องยนต์ที่ทำให้ Hive ทำงานเรียกว่า "ไดรเวอร์" รวมคอมไพเลอร์และเครื่องมือเพิ่มประสิทธิภาพเพื่อกำหนดแผนการดำเนินการที่เหมาะสมที่สุด
สุดท้าย Hadoop จัดเตรียมการรักษาความปลอดภัย ดังนั้นจึงอาศัย Kerberos สำหรับการรับรองความถูกต้องร่วมกันระหว่างไคลเอ็นต์และเซิร์ฟเวอร์ สิทธิ์สำหรับไฟล์ที่สร้างขึ้นใหม่ใน Apache Hive ถูกกำหนดโดย HDFS ซึ่งอนุญาตให้ผู้ใช้ กลุ่ม หรือการอนุญาตอื่นๆ
คุณสมบัติของไฮฟ์
- รองรับกลไกคอมพิวเตอร์ของทั้ง Hadoop และ Spark
- ใช้ HDFS และทำงานเป็นคลังข้อมูล
- ใช้ MapReduce และรองรับ ETL
- เนื่องจาก HDFS จึงมีความทนทานต่อข้อผิดพลาดคล้ายกับ Hadoop
Apache Hive: ประโยชน์
Apache Hive เป็นโซลูชันในอุดมคติสำหรับการสืบค้นข้อมูลและการวิเคราะห์ข้อมูล ช่วยให้ได้รับข้อมูลเชิงลึกเชิงคุณภาพ สร้างความได้เปรียบในการแข่งขันและอำนวยความสะดวกในการตอบสนองต่อความต้องการของตลาด
ในข้อดีหลักๆ ของ Apache Hive เราสามารถพูดถึงความง่ายในการใช้งานที่เชื่อมโยงกับภาษาที่ “เป็นมิตรกับ SQL” นอกจากนี้ยังเพิ่มความเร็วในการแทรกข้อมูลเริ่มต้นเนื่องจากข้อมูลไม่จำเป็นต้องอ่านหรือกำหนดหมายเลขจากดิสก์ในรูปแบบฐานข้อมูลภายใน
เมื่อทราบว่าข้อมูลถูกจัดเก็บไว้ใน HDFS จึงสามารถจัดเก็บชุดข้อมูลขนาดใหญ่ได้ถึงหลายร้อยเพตะไบต์บน Apache Hive โซลูชันนี้สามารถปรับขนาดได้มากกว่าฐานข้อมูลแบบเดิม เมื่อทราบว่าเป็นบริการคลาวด์ Apache Hive ช่วยให้ผู้ใช้สามารถเปิดใช้เซิร์ฟเวอร์เสมือนได้อย่างรวดเร็วตามความผันผวนของปริมาณงาน (เช่น งาน)
การรักษาความปลอดภัยยังเป็นลักษณะที่ Hive ทำงานได้ดีขึ้น ด้วยความสามารถในการทำซ้ำปริมาณงานที่สำคัญต่อการกู้คืนในกรณีที่เกิดปัญหา ประการสุดท้าย ความสามารถในการทำงานไม่มีใครเทียบได้เนื่องจากสามารถดำเนินการได้ถึง 100,000 คำขอต่อชั่วโมง
อาปาเช่ อิมพาลา
Apache Impala เป็นเครื่องมือสืบค้น SQL แบบคู่ขนานขนาดใหญ่สำหรับการดำเนินการโต้ตอบของแบบสอบถาม SQL บนข้อมูลที่จัดเก็บไว้ใน Apache Hadoop ซึ่งเขียนด้วยภาษา C++ และเผยแพร่ภายใต้ลิขสิทธิ์ Apache 2.0
อิมพาลาเรียกอีกอย่างว่าเอ็นจิ้น MPP (การประมวลผลแบบขนานขนาดใหญ่) DBMS แบบกระจาย และแม้แต่ฐานข้อมูลสแต็ก SQL-on-Hadoop

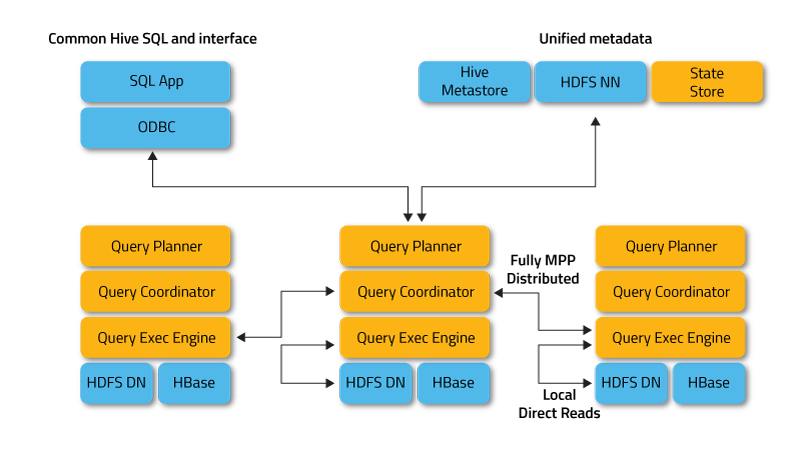
Impala ทำงานในโหมดกระจาย โดยที่อินสแตนซ์ของกระบวนการทำงานบนโหนดคลัสเตอร์ต่างๆ รับ จัดตารางเวลา และประสานงานคำขอของลูกค้า ในกรณีนี้ การดำเนินการแบบขนานของแฟรกเมนต์ของแบบสอบถาม SQL เป็นไปได้
ไคลเอ็นต์คือผู้ใช้และแอปพลิเคชันที่ส่งการสืบค้น SQL กับข้อมูลที่จัดเก็บไว้ใน Apache Hadoop (HBase และ HDFS) หรือ Amazon S3 การโต้ตอบกับ Impala เกิดขึ้นผ่านทางเว็บอินเตอร์เฟส HUE (Hadoop User Experience), ODBC, JDBC และเชลล์บรรทัดคำสั่งของ Impala Shell
Impala ขึ้นอยู่กับโครงสร้างพื้นฐานบนเครื่องมือ SQL-on-Hadoop ที่ได้รับความนิยมอีกตัวหนึ่งคือ Apache Hive โดยใช้ที่เก็บข้อมูลเมตา โดยเฉพาะอย่างยิ่ง Hive Metastore ช่วยให้ Impala ทราบเกี่ยวกับความพร้อมใช้งานและโครงสร้างของฐานข้อมูล
เมื่อสร้าง ปรับเปลี่ยน และลบอ็อบเจ็กต์สคีมาหรือโหลดข้อมูลลงในตารางผ่านคำสั่ง SQL การเปลี่ยนแปลงข้อมูลเมตาที่สอดคล้องกันจะถูกเผยแพร่โดยอัตโนมัติไปยังโหนดอิมพาลาทั้งหมดโดยใช้บริการไดเร็กทอรีพิเศษ
ส่วนประกอบที่สำคัญของ Impala มีดังนี้:
- Impalad หรือ Impala daemon เป็นบริการระบบที่กำหนดเวลาและดำเนินการค้นหาข้อมูล HDFS, HBase และ Amazon S3 กระบวนการ impalad หนึ่งกระบวนการทำงานในแต่ละโหนดคลัสเตอร์
- Statestore เป็นบริการตั้งชื่อที่ติดตามตำแหน่งและสถานะของอิมพาลาดอินสแตนซ์ทั้งหมดในคลัสเตอร์ หนึ่งอินสแตนซ์ของบริการระบบนี้ทำงานในแต่ละโหนดและเซิร์ฟเวอร์หลัก (โหนดชื่อ)
- แคตตาล็อกเป็นบริการประสานงานข้อมูลเมตาที่เผยแพร่การเปลี่ยนแปลงจากคำสั่ง Impala DDL และ DML ไปยังโหนด Impala ที่ได้รับผลกระทบทั้งหมด เพื่อให้ตารางใหม่หรือข้อมูลที่โหลดใหม่สามารถมองเห็นได้ทันทีในโหนดใดๆ ในคลัสเตอร์ ขอแนะนำให้เรียกใช้แค็ตตาล็อกหนึ่งอินสแตนซ์บนโฮสต์คลัสเตอร์เดียวกันกับ Statestored daemon
Apache Impala ทำงานอย่างไร
Impala เช่น Apache Hive ใช้ภาษาเคียวรีแบบประกาศที่คล้ายกัน นั่นคือ Hive Query Language (HiveQL) ซึ่งเป็นชุดย่อยของ SQL92 แทน SQL
การดำเนินการตามจริงของคำขอในอิมพาลามีดังนี้:
แอปพลิเคชันไคลเอนต์ส่งแบบสอบถาม SQL โดยเชื่อมต่อกับอิมพาลาดผ่านอินเทอร์เฟซไดรเวอร์ ODBC หรือ JDBC ที่ได้มาตรฐาน อิมพาลาดที่เชื่อมต่อจะกลายเป็นผู้ประสานงานของคำขอปัจจุบัน

แบบสอบถาม SQL ได้รับการวิเคราะห์เพื่อกำหนดงานสำหรับอินสแตนซ์อิมพาลาดในคลัสเตอร์ จากนั้น จะมีการสร้างแผนการดำเนินการสืบค้นที่เหมาะสมที่สุด
Impalad เข้าถึง HDFS และ HBase โดยตรงโดยใช้อินสแตนซ์ของบริการระบบในเครื่องเพื่อให้ข้อมูล ซึ่งแตกต่างจาก Apache Hive การโต้ตอบโดยตรงดังกล่าวช่วยประหยัดเวลาการดำเนินการค้นหาได้อย่างมาก เนื่องจากผลลัพธ์ระหว่างกลางจะไม่ถูกบันทึก
ในการตอบสนอง daemon แต่ละตัวจะส่งข้อมูลกลับไปยัง impalad ที่ประสานงาน โดยส่งผลลัพธ์กลับไปยังไคลเอ็นต์
คุณสมบัติของอิมพาลา
- รองรับการประมวลผลในหน่วยความจำแบบเรียลไทม์
- SQL ที่เป็นมิตร
- รองรับระบบจัดเก็บข้อมูล เช่น HDFS, Apache HBase และ Amazon S3
- รองรับการทำงานร่วมกับเครื่องมือ BI เช่น Pentaho และ Tableau
- ใช้ไวยากรณ์ HiveQL
Apache Impala: ประโยชน์
Impala หลีกเลี่ยงค่าใช้จ่ายในการเริ่มต้นที่เป็นไปได้เนื่องจากกระบวนการดีมอนของระบบทั้งหมดเริ่มต้นโดยตรงในเวลาบูต ช่วยประหยัดเวลาในการดำเนินการค้นหาได้อย่างมาก ความเร็วที่เพิ่มขึ้นของ Impala เป็นเพราะเครื่องมือ SQL สำหรับ Hadoop ซึ่งแตกต่างจาก Hive คือไม่เก็บผลลัพธ์ระดับกลางและเข้าถึง HDFS หรือ HBase โดยตรง
นอกจากนี้ Impala ยังสร้างโค้ดโปรแกรมที่รันไทม์ ไม่ใช่ที่การคอมไพล์เหมือนที่ Hive ทำ อย่างไรก็ตาม ผลข้างเคียงของประสิทธิภาพความเร็วสูงของ Impala คือความน่าเชื่อถือลดลง
โดยเฉพาะอย่างยิ่ง หากโหนดข้อมูลหยุดทำงานระหว่างการดำเนินการค้นหา SQL อินสแตนซ์ Impala จะเริ่มต้นใหม่ และ Hive จะยังคงเชื่อมต่อกับแหล่งข้อมูลต่อไป
ประโยชน์อื่นๆ ของ Impala ได้แก่ การรองรับในตัวสำหรับโปรโตคอลการตรวจสอบเครือข่ายที่ปลอดภัย Kerberos การจัดลำดับความสำคัญ และความสามารถในการจัดการคิวของคำขอ และการสนับสนุนรูปแบบ Big Data ที่เป็นที่นิยม เช่น LZO, Avro, RCFile, Parquet และ Sequence
Hive Vs Impala: ความคล้ายคลึงกัน
Hive และ Impala เผยแพร่อย่างอิสระภายใต้สิทธิ์การใช้งาน Apache Software Foundation และอ้างถึงเครื่องมือ SQL สำหรับการทำงานกับข้อมูลที่จัดเก็บไว้ในคลัสเตอร์ Hadoop นอกจากนี้ยังใช้ระบบไฟล์แบบกระจาย HDFS
Impala และ Hive ใช้งานที่แตกต่างกันโดยมุ่งเน้นที่การประมวลผล SQL ของข้อมูลขนาดใหญ่ที่จัดเก็บไว้ในคลัสเตอร์ Apache Hadoop Impala มีอินเทอร์เฟซคล้าย SQL ให้คุณอ่านและเขียนตาราง Hive ได้ จึงช่วยให้แลกเปลี่ยนข้อมูลได้ง่าย
ในขณะเดียวกัน Impala ทำให้การดำเนินการ SQL บน Hadoop ค่อนข้างรวดเร็วและมีประสิทธิภาพ ทำให้สามารถใช้ DBMS นี้ในโครงการวิจัยการวิเคราะห์ข้อมูลขนาดใหญ่ได้ เมื่อใดก็ตามที่เป็นไปได้ Impala จะทำงานร่วมกับโครงสร้างพื้นฐาน Apache Hive ที่มีอยู่แล้วซึ่งใช้ในการดำเนินการสืบค้น SQL แบบแบตช์ที่ใช้เวลานาน
นอกจากนี้ Impala ยังจัดเก็บคำจำกัดความของตารางไว้ใน metastore ซึ่งเป็นฐานข้อมูล MySQL หรือ PostgreSQL แบบดั้งเดิม เช่น ในที่เดียวกับที่ Hive เก็บข้อมูลที่คล้ายกัน อนุญาตให้ Impala เข้าถึงตาราง Hive ตราบใดที่คอลัมน์ทั้งหมดใช้ประเภทข้อมูล รูปแบบไฟล์ และตัวแปลงสัญญาณการบีบอัดของ Impala
Hive Vs Impala: ความแตกต่าง

ภาษาโปรแกรม
Hive เขียนด้วย Java ในขณะที่ Impala เขียนด้วย C++ อย่างไรก็ตาม Impala ยังใช้ Hive UDF ที่ใช้ Java บางตัวด้วย
กรณีการใช้งาน
วิศวกรข้อมูลใช้ Hive ในกระบวนการ ETL (แยก แปลง โหลด) ตัวอย่างเช่น สำหรับงานแบตช์ที่ใช้เวลานานในชุดข้อมูลขนาดใหญ่ ตัวอย่างเช่น ในตัวรวบรวมการเดินทางและระบบข้อมูลสนามบิน ในทางกลับกัน Impala มีไว้สำหรับนักวิเคราะห์และนักวิทยาศาสตร์ข้อมูลเป็นหลัก และส่วนใหญ่จะใช้ในงานต่างๆ เช่น ระบบธุรกิจอัจฉริยะ
ประสิทธิภาพ
Impala ดำเนินการสืบค้น SQL แบบเรียลไทม์ ในขณะที่ Hive โดดเด่นด้วยความเร็วในการประมวลผลข้อมูลต่ำ ด้วยการสืบค้น SQL อย่างง่าย Impala สามารถทำงานได้เร็วกว่า Hive 6-69 เท่า อย่างไรก็ตาม Hive จัดการกับข้อความค้นหาที่ซับซ้อนได้ดีกว่า
เวลาแฝง / ปริมาณงาน
ปริมาณงานของ Hive นั้นสูงกว่าของ Impala อย่างมาก คุณลักษณะ LLAP (Live Long and Process) ซึ่งเปิดใช้งานการแคชแบบสอบถามในหน่วยความจำ ทำให้ Hive มีประสิทธิภาพในระดับต่ำที่ดี
LLAP รวมถึงบริการระบบระยะยาว (daemons) ซึ่งช่วยให้คุณสามารถโต้ตอบโดยตรงกับโหนดข้อมูล HDFS และแทนที่โครงสร้างการสืบค้น DAG ที่ผสานรวมอย่างแน่นหนา (กราฟวงกลมกำกับ) ซึ่งเป็นแบบจำลองกราฟที่ใช้ในการประมวลผล Big Data
ความอดทนต่อความผิดพลาด
Hive เป็นระบบที่ทนต่อความผิดพลาดซึ่งรักษาผลลัพธ์ระดับกลางทั้งหมด นอกจากนี้ยังส่งผลในเชิงบวกต่อความสามารถในการปรับขนาด แต่ทำให้ความเร็วในการประมวลผลข้อมูลลดลง ในทางกลับกัน อิมพาลาไม่สามารถเรียกได้ว่าเป็นแพลตฟอร์มที่ทนทานต่อความผิดพลาดได้ เนื่องจากมีการผูกมัดหน่วยความจำมากกว่า
การแปลงรหัส
Hive สร้างนิพจน์คิวรีในขณะคอมไพล์ ในขณะที่ Impala สร้างในขณะรันไทม์ Hive มีลักษณะปัญหา "cold start" ในครั้งแรกที่เปิดใช้งานแอปพลิเคชัน ข้อความค้นหาจะถูกแปลงอย่างช้าๆ เนื่องจากจำเป็นต้องสร้างการเชื่อมต่อกับแหล่งข้อมูล
Impala ไม่มีค่าใช้จ่ายในการเริ่มต้นประเภทนี้ บริการระบบที่จำเป็น (daemons) สำหรับการประมวลผลการสืบค้น SQL จะเริ่มต้นในเวลาบูต ซึ่งเพิ่มความเร็วในการทำงาน
รองรับการจัดเก็บข้อมูล
Impala รองรับรูปแบบ LZO, Avro และ Parquet ในขณะที่ Hive ทำงานร่วมกับ Plain Text และ ORC อย่างไรก็ตาม ทั้งคู่รองรับรูปแบบ RCFIle และ Sequence
| อาปาเช่ไฮฟ์ | อาปาเช่ อิมพาลา | |
| ภาษา | ชวา | ภาษาซี++ |
| ใช้กรณี | วิศวกรรมข้อมูล | การวิเคราะห์และการวิเคราะห์ |
| ประสิทธิภาพ | สูงสำหรับคำถามง่ายๆ | ค่อนข้างต่ำ |
| เวลาแฝง | เวลาแฝงมากขึ้นเนื่องจากการแคช | แฝงน้อยลง |
| ความทนทานต่อความผิดพลาด | ทนทานมากขึ้นเนื่องจาก MapReduce | ความอดทนน้อยลงเนื่องจาก MPP |
| การแปลง | ช้าเนื่องจากเริ่มเย็น | การแปลงเร็วขึ้น |
| การสนับสนุนพื้นที่เก็บข้อมูล | ข้อความล้วนและ ORC | LZO, อัฟโร, ปาร์เก้ |
คำสุดท้าย
ไฮฟ์และอิมพาลาไม่ได้แข่งขันกัน แต่เป็นการเติมเต็มซึ่งกันและกันอย่างมีประสิทธิภาพ แม้ว่าจะมีความแตกต่างกันอย่างมากระหว่างทั้งสอง แต่ก็มีหลายอย่างที่เหมือนกันและการเลือกอย่างใดอย่างหนึ่งขึ้นอยู่กับข้อมูลและข้อกำหนดเฉพาะของโครงการ
คุณยังสามารถสำรวจการเปรียบเทียบแบบตัวต่อตัวระหว่าง Hadoop และ Spark
.