
Apache Hive против Apache Impala: основные различия
Опубликовано: 2022-11-23Если вы новичок в анализе больших данных, вам может быть интересен целый ряд инструментов Apache; однако само количество различных инструментов может сбивать с толку, а иногда и подавлять.
Этот пост разрешит эту путаницу и объяснит, что такое Apache Hive и Impala и чем они отличаются друг от друга!
Апачский улей
Apache Hive — это интерфейс доступа к данным SQL для платформы Apache Hadoop. Hive позволяет запрашивать, агрегировать и анализировать данные с использованием синтаксиса SQL.
Для данных в файловой системе HDFS используется схема доступа на чтение, позволяющая обращаться с данными как с обычной табличной или реляционной СУБД. Запросы HiveQL переводятся в код Java для заданий MapReduce.

Запросы Hive пишутся на языке запросов HiveQL, который основан на языке SQL, но не имеет полной поддержки стандарта SQL-92.
Однако этот язык позволяет программистам использовать свои запросы, когда неудобно или неэффективно использовать функции HiveQL. HiveQL можно расширить за счет пользовательских скалярных функций (UDF), агрегатов (коды UDAF) и табличных функций (UDTF).
Как работает Apache Hive
Apache Hive переводит программы, написанные на языке HiveQL (близком к SQL), в одну или несколько задач MapReduce, Apache Tez или Apache Spark. Это три механизма выполнения, которые можно запустить в Hadoop. Затем Apache Hive организует данные в массив для файла распределенной файловой системы Hadoop (HDFS), чтобы запускать задания в кластере для получения ответа.
Таблицы Apache Hive аналогичны реляционным базам данных, а единицы данных организованы от наиболее значимой единицы до наиболее детализированной. Базы данных — это массивы, состоящие из разделов, которые снова можно разбить на «сегменты».
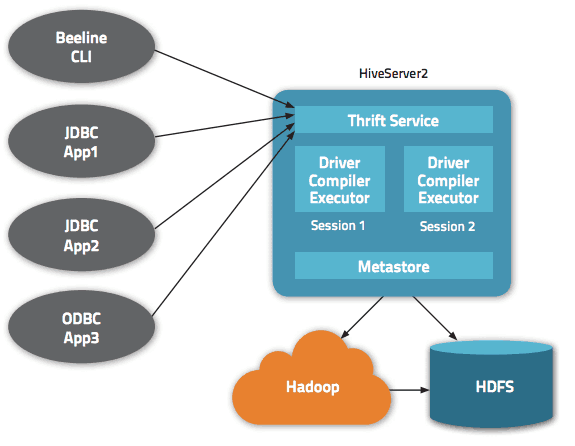
Данные доступны через HiveQL. В каждой базе данных данные пронумерованы, и каждая таблица соответствует каталогу HDFS.
В архитектуре Apache Hive доступно несколько интерфейсов, таких как веб-интерфейс, интерфейс командной строки или внешние клиенты.
Действительно, сервер «Apache Hive Thrift» позволяет удаленным клиентам отправлять команды и запросы в Apache Hive, используя различные языки программирования. Центральный каталог Apache Hive — это «хранилище метаданных», содержащее всю информацию.
Движок, благодаря которому Hive работает, называется «драйвер». Он объединяет компилятор и оптимизатор для определения оптимального плана выполнения.
Наконец, безопасность обеспечивается Hadoop. Поэтому он полагается на Kerberos для взаимной аутентификации между клиентом и сервером. Разрешение для вновь созданных файлов в Apache Hive диктуется HDFS, разрешая авторизацию пользователя, группы или иным образом.
Особенности улья
- Поддерживает вычислительный движок Hadoop и Spark.
- Использует HDFS и работает как хранилище данных.
- Использует MapReduce и поддерживает ETL
- Благодаря HDFS имеет отказоустойчивость, аналогичную Hadoop.
Apache Hive: преимущества
Apache Hive — идеальное решение для запросов и анализа данных. Это позволяет получить качественную информацию, обеспечивая конкурентное преимущество и облегчая реагирование на рыночный спрос.
Среди основных преимуществ Apache Hive можно отметить простоту использования, связанную с его «дружественным к SQL» языком. Кроме того, это ускоряет первоначальную вставку данных, поскольку данные не нужно считывать или нумеровать с диска в формате внутренней базы данных.
Зная, что данные хранятся в HDFS, можно хранить большие наборы данных объемом до сотен петабайт данных в Apache Hive. Это решение гораздо более масштабируемо, чем традиционная база данных. Зная, что это облачная служба, Apache Hive позволяет пользователям быстро запускать виртуальные серверы в зависимости от колебаний рабочих нагрузок (то есть задач).
Безопасность также является аспектом, в котором Hive работает лучше благодаря его способности воспроизводить критически важные для восстановления рабочие нагрузки в случае возникновения проблемы. Наконец, производительность беспрецедентна, поскольку он может выполнять до 100 000 запросов в час.
Апач Импала
Apache Impala — это массивно-параллельный механизм SQL-запросов для интерактивного выполнения SQL-запросов к данным, хранящимся в Apache Hadoop, написанный на C++ и распространяемый по лицензии Apache 2.0.
Impala также называют механизмом MPP (Massively Parallel Processing), распределенной СУБД и даже базой данных стека SQL-on-Hadoop.

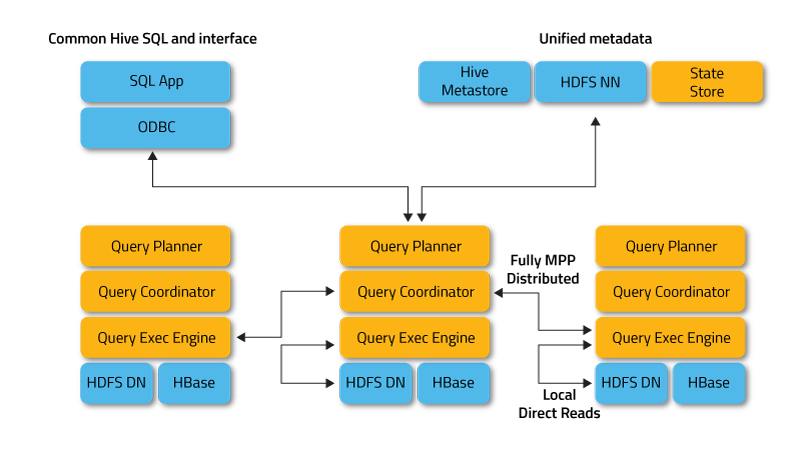
Impala работает в распределенном режиме, когда экземпляры процессов запускаются на разных узлах кластера, получая, планируя и координируя клиентские запросы. В этом случае возможно параллельное выполнение фрагментов SQL-запроса.
Клиенты — это пользователи и приложения, которые отправляют SQL-запросы к данным, хранящимся в Apache Hadoop (HBase и HDFS) или Amazon S3. Взаимодействие с Impala происходит через веб-интерфейс HUE (Hadoop User Experience), ODBC, JDBC и оболочку командной строки Impala Shell.
Инфраструктура Impala зависит от другого популярного инструмента SQL-on-Hadoop, Apache Hive, использующего его хранилище метаданных. В частности, хранилище метаданных Hive сообщает Impala о доступности и структуре баз данных.
При создании, изменении и удалении объектов схемы или загрузке данных в таблицы с помощью операторов SQL соответствующие изменения метаданных автоматически распространяются на все узлы Impala с помощью специализированной службы каталогов.
Ключевыми компонентами Impala являются следующие исполняемые файлы:
- Демон Impalad или Impala — это системная служба, которая планирует и выполняет запросы к данным HDFS, HBase и Amazon S3. Один процесс impalad выполняется на каждом узле кластера.
- Statestore — это служба имен, которая отслеживает местоположение и состояние всех экземпляров impalad в кластере. Один экземпляр этой системной службы работает на каждом узле и на главном сервере (Name Node).
- Каталог — это служба координации метаданных, которая распространяет изменения из операторов DDL и DML Impala на все затронутые узлы Impala, чтобы новые таблицы или недавно загруженные данные были немедленно видны любому узлу в кластере. Рекомендуется, чтобы один экземпляр Catalog работал на том же узле кластера, что и демон Statetored.
Как работает Apache Impala
Impala, как и Apache Hive, использует аналогичный язык декларативных запросов, Hive Query Language (HiveQL), который является подмножеством SQL92, вместо SQL.
Фактическое выполнение запроса в Impala выглядит следующим образом:
Клиентское приложение отправляет SQL-запрос, подключаясь к любому импаладу через стандартизированные интерфейсы драйверов ODBC или JDBC. Подключенный импалад становится координатором текущего запроса.

SQL-запрос анализируется для определения задач для экземпляров impalad в кластере; затем строится оптимальный план выполнения запроса.
Impalad напрямую обращается к HDFS и HBase, используя локальные экземпляры системных служб для предоставления данных. В отличие от Apache Hive такое прямое взаимодействие существенно экономит время выполнения запросов, так как промежуточные результаты не сохраняются.
В ответ каждый демон возвращает данные координирующему импаладу, отправляя результаты обратно клиенту.
Особенности Импалы
- Поддержка обработки в памяти в реальном времени
- SQL дружественный
- Поддерживает такие системы хранения, как HDFS, Apache HBase и Amazon S3.
- Поддерживает интеграцию с инструментами бизнес-аналитики, такими как Pentaho и Tableau.
- Использует синтаксис HiveQL
Apache Impala: преимущества
Impala позволяет избежать возможных накладных расходов при запуске, поскольку все процессы системного демона запускаются непосредственно во время загрузки. Это значительно экономит время выполнения запроса. Дополнительное увеличение скорости Impala связано с тем, что этот инструмент SQL для Hadoop, в отличие от Hive, не хранит промежуточные результаты и напрямую обращается к HDFS или HBase.
Кроме того, Impala генерирует программный код во время выполнения, а не при компиляции, как это делает Hive. Однако побочным эффектом высокой скорости Impala является снижение надежности.
В частности, если узел данных выйдет из строя во время выполнения SQL-запроса, экземпляр Impala перезапустится, а Hive продолжит поддерживать соединение с источником данных, обеспечивая отказоустойчивость.
Другие преимущества Impala включают встроенную поддержку безопасного протокола сетевой аутентификации Kerberos, приоритезацию и возможность управления очередью запросов, а также поддержку популярных форматов больших данных, таких как LZO, Avro, RCFile, Parquet и Sequence.
Улей против Импалы: сходства
Hive и Impala свободно распространяются по лицензии Apache Software Foundation и относятся к инструментам SQL для работы с данными, хранящимися в кластере Hadoop. Кроме того, они также используют распределенную файловую систему HDFS.
Impala и Hive реализуют разные задачи с общим акцентом на SQL-обработку больших данных, хранящихся в кластере Apache Hadoop. Impala предоставляет SQL-подобный интерфейс, позволяющий читать и записывать таблицы Hive, что упрощает обмен данными.
В то же время Impala делает SQL-операции на Hadoop достаточно быстрыми и эффективными, что позволяет использовать эту СУБД в исследовательских проектах по аналитике больших данных. Когда это возможно, Impala работает с существующей инфраструктурой Apache Hive, которая уже используется для выполнения длительных пакетных запросов SQL.
Кроме того, Impala хранит свои определения таблиц в хранилище метаданных, традиционной базе данных MySQL или PostgreSQL, то есть там же, где Hive хранит аналогичные данные. Это позволяет Impala получать доступ к таблицам Hive, если все столбцы используют поддерживаемые Impala типы данных, форматы файлов и кодеки сжатия.
Улей против Импалы: различия

Язык программирования
Hive написан на Java, а Impala — на C++. Однако Impala также использует некоторые пользовательские функции Hive на основе Java.
Сценарии использования
Инженеры данных используют Hive в процессах ETL (извлечение, преобразование, загрузка), например, для длительных пакетных заданий на больших наборах данных, например, в агрегаторах путешествий и информационных системах аэропортов. В свою очередь, Impala предназначена в основном для аналитиков и специалистов по данным и в основном используется в таких задачах, как бизнес-аналитика.
Производительность
Impala выполняет SQL-запросы в режиме реального времени, а Hive отличается низкой скоростью обработки данных. С помощью простых SQL-запросов Impala может работать в 6–69 раз быстрее, чем Hive. Однако Hive лучше обрабатывает сложные запросы.
Задержка/пропускная способность
Пропускная способность Hive значительно выше, чем у Impala. Функция LLAP (Live Long and Process), обеспечивающая кэширование запросов в памяти, дает Hive хорошую производительность на низком уровне.
LLAP включает в себя долговременные системные службы (демоны), которые позволяют напрямую взаимодействовать с узлами данных HDFS и заменяют тесно интегрированную структуру запросов DAG (направленный ациклический граф) — графовую модель, активно используемую в вычислениях с большими данными.
Отказоустойчивость
Hive — отказоустойчивая система, сохраняющая все промежуточные результаты. Это также положительно влияет на масштабируемость, но приводит к снижению скорости обработки данных. В свою очередь, Impala нельзя назвать отказоустойчивой платформой, потому что она больше привязана к памяти.
Преобразование кода
Hive генерирует выражения запросов во время компиляции, а Impala — во время выполнения. Для Hive характерна проблема «холодного запуска» при первом запуске приложения; запросы конвертируются медленно из-за необходимости установления соединения с источником данных.
У Impala нет таких накладных расходов при запуске. Необходимые системные службы (демоны) для обработки SQL-запросов запускаются во время загрузки, что ускоряет работу.
Поддержка хранения
Impala поддерживает форматы LZO, Avro и Parquet, а Hive работает с обычным текстом и ORC. Однако оба поддерживают форматы RCFIle и Sequence.
| Апачский улей | Апач Импала | |
| Язык | Ява | С++ |
| Сценарии использования | Инжиниринг данных | Анализ и аналитика |
| Производительность | Высокий для простых запросов | Сравнительно низкий |
| Задержка | Больше задержки из-за кэширования | Менее латентный |
| Отказоустойчивость | Более толерантный благодаря MapReduce | Менее терпимый из-за MPP |
| Преобразование | Медленно из-за холодного запуска | Более быстрая конвертация |
| Поддержка хранения | Простой текст и ORC | ЛЗО, Авро, Паркет |
Заключительные слова
Hive и Impala не конкурируют, а эффективно дополняют друг друга. Несмотря на то, что между ними есть существенные различия, также есть много общего, и выбор одного из них зависит от данных и конкретных требований проекта.
Вы также можете изучить прямые сравнения между Hadoop и Spark.
.