
Apache Hive vs Apache Impala: الاختلافات الرئيسية
نشرت: 2022-11-23إذا كنت حديث العهد بتحليل البيانات الضخمة ، فقد تجد مجموعة أدوات اباتشي على رادارك ؛ ومع ذلك ، قد تصبح مجرد الأدوات المختلفة مربكة ، وفي بعض الأحيان ، ساحقة.
هذا المنشور سيحل هذا الالتباس ويشرح ما هي Apache Hive و Impala وما الذي يجعلهما مختلفين عن بعضهما البعض!
اباتشي خلية
Apache Hive هي واجهة وصول إلى بيانات SQL لمنصة Apache Hadoop. يسمح لك Hive بالاستعلام عن البيانات وتجميعها وتحليلها باستخدام بناء جملة SQL.
يتم استخدام نظام الوصول للقراءة للبيانات في نظام ملفات HDFS ، مما يسمح لك بمعالجة البيانات كما هو الحال مع جدول عادي أو DBMS علائقي. تتم ترجمة استعلامات HiveQL إلى كود Java لوظائف MapReduce.

تتم كتابة استعلامات Hive بلغة استعلام HiveQL ، والتي تستند إلى لغة SQL ولكنها لا تحتوي على دعم كامل لمعيار SQL-92.
ومع ذلك ، تسمح هذه اللغة للمبرمجين باستخدام استفساراتهم عندما يكون استخدام ميزات HiveQL غير ملائم أو غير فعال. يمكن توسيع HiveQL بوظائف عددية محددة من قبل المستخدم (UDFs) ، وتجميعات (رموز UDAF) ، ووظائف الجدول (UDTFs).
كيف يعمل Apache Hive
يترجم Apache Hive البرامج المكتوبة بلغة HiveQL (القريبة من SQL) إلى مهمة أو أكثر من مهام MapReduce أو Apache Tez أو Apache Spark. هذه ثلاثة محركات تنفيذ يمكن إطلاقها على Hadoop. بعد ذلك ، ينظم Apache Hive البيانات في مصفوفة لملف Hadoop Distributed File System (HDFS) لتشغيل المهام على مجموعة لإنتاج استجابة.
تشبه جداول Apache Hive قواعد البيانات العلائقية ، ويتم تنظيم وحدات البيانات من الوحدة الأكثر أهمية إلى الأكثر دقة. قواعد البيانات عبارة عن مصفوفات مكونة من أقسام ، والتي يمكن تقسيمها مرة أخرى إلى "مجموعات".
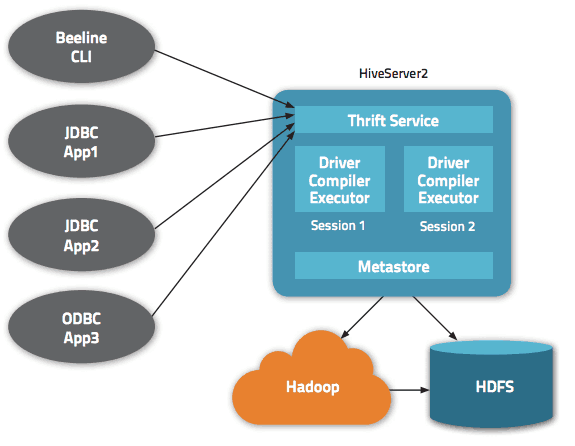
يمكن الوصول إلى البيانات عبر HiveQL. داخل كل قاعدة بيانات ، يتم ترقيم البيانات ، ويتوافق كل جدول مع دليل HDFS.
تتوفر واجهات متعددة داخل بنية Apache Hive ، مثل واجهة الويب أو CLI أو العملاء الخارجيين.
في الواقع ، يسمح خادم "Apache Hive Thrift" للعملاء البعيدين بإرسال الأوامر والطلبات إلى Apache Hive باستخدام لغات برمجة مختلفة. دليل Apache Hive المركزي هو "metastore" يحتوي على جميع المعلومات.
يُطلق على المحرك الذي يجعل Hive يعمل "السائق". يجمع بين مترجم ومحسن لتحديد خطة التنفيذ المثلى.
أخيرًا ، يتم توفير الأمان بواسطة Hadoop. لذلك ، يعتمد على Kerberos للمصادقة المتبادلة بين العميل والخادم. يتم إملاء الإذن الخاص بالملفات التي تم إنشاؤها حديثًا في Apache Hive بواسطة HDFS ، مما يسمح للمستخدم أو المجموعة أو التفويض بأي شكل آخر.
ميزات الخلية
- يدعم محرك الحوسبة لكل من Hadoop و Spark
- يستخدم HDFS ويعمل كمستودع بيانات.
- يستخدم MapReduce ويدعم ETL
- نظرًا لـ HDFS ، فإن لديها تسامحًا مع الخطأ مشابهًا لـ Hadoop
خلية اباتشي: الفوائد
يعد Apache Hive حلاً مثاليًا للاستعلامات وتحليل البيانات. يجعل من الممكن الحصول على رؤى نوعية ، وتوفير ميزة تنافسية وتسهيل الاستجابة لطلب السوق.
من بين المزايا الرئيسية لـ Apache Hive ، يمكننا أن نذكر سهولة الاستخدام المرتبطة بلغتها "الصديقة لـ SQL". بالإضافة إلى ذلك ، يعمل على تسريع الإدخال الأولي للبيانات نظرًا لأن البيانات لا تحتاج إلى قراءة أو ترقيم من قرص بتنسيق قاعدة البيانات الداخلية.
مع العلم أن البيانات مخزنة في HDFS ، فمن الممكن تخزين مجموعات كبيرة من البيانات تصل إلى مئات بيتابايت من البيانات على Apache Hive. هذا الحل أكثر قابلية للتوسع من قاعدة البيانات التقليدية. مع العلم أنها خدمة سحابية ، تسمح Apache Hive للمستخدمين بتشغيل الخوادم الافتراضية بسرعة بناءً على التقلبات في أعباء العمل (أي المهام).
يعد الأمان أيضًا أحد الجوانب التي تؤدي فيها Hive أداءً أفضل ، مع قدرتها على تكرار أعباء العمل الحرجة في حالة حدوث مشكلة. أخيرًا ، قدرة العمل لا مثيل لها حيث يمكنها أداء ما يصل إلى 100،000 طلب في الساعة.
اباتشي امبالا
Apache Impala هو محرك استعلام SQL متوازي بشكل كبير للتنفيذ التفاعلي لاستعلامات SQL على البيانات المخزنة في Apache Hadoop ، والمكتوبة بلغة C ++ وتوزيعها بموجب ترخيص Apache 2.0.
يُطلق على إمبالا أيضًا اسم محرك MPP (المعالجة المتوازية الضخمة) ، ونظام إدارة قواعد البيانات الموزع ، وحتى قاعدة بيانات مكدس SQL-on-Hadoop.

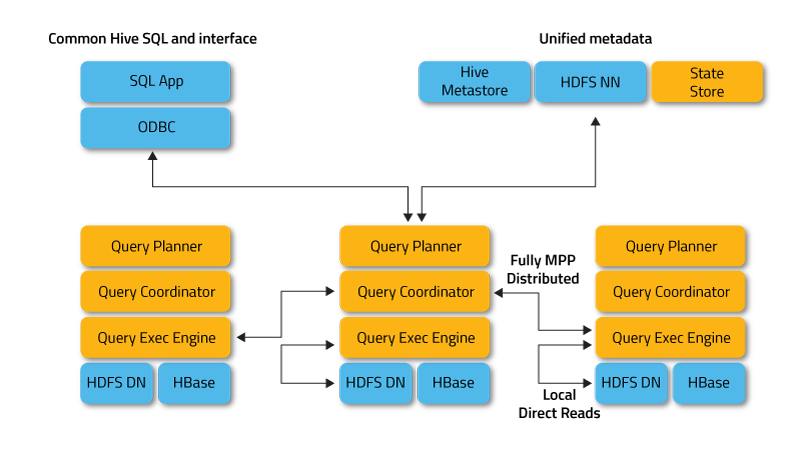
تعمل Impala في الوضع الموزع ، حيث تعمل مثيلات العملية على عقد مجموعة مختلفة ، وتستقبل طلبات العملاء وتجدولتها وتنسيقها. في هذه الحالة ، يكون التنفيذ المتوازي لأجزاء من استعلام SQL ممكنًا.
العملاء هم المستخدمون والتطبيقات التي ترسل استعلامات SQL مقابل البيانات المخزنة في Apache Hadoop (HBase و HDFS) أو Amazon S3. يحدث التفاعل مع Impala من خلال واجهة الويب HUE (تجربة مستخدم Hadoop) و ODBC و JDBC و Impala Shell سطر أوامر shell.
تعتمد إمبالا بشكل أساسي على أداة أخرى شائعة في SQL-on-Hadoop ، Apache Hive ، باستخدام مخزن البيانات الوصفية الخاص بها. على وجه الخصوص ، يتيح Hive Metastore لإمبالا معرفة مدى توفر قواعد البيانات وهيكلها.
عند إنشاء كائنات المخطط وتعديلها وحذفها أو تحميل البيانات في جداول عبر عبارات SQL ، يتم نشر تغييرات البيانات الوصفية المقابلة تلقائيًا لجميع عقد إمبالا باستخدام خدمة دليل متخصصة.
المكونات الرئيسية لإمبالا هي الملفات القابلة للتنفيذ التالية:
- Impalad أو Impala daemon هي خدمة نظام تقوم بجدولة وتنفيذ الاستعلامات على بيانات HDFS و HBase و Amazon S3. يتم تشغيل عملية إمبالاد واحدة على كل عقدة كتلة.
- Statestore هي خدمة تسمية تتعقب موقع وحالة جميع مثيلات Impalad في المجموعة. يتم تشغيل مثيل واحد من خدمة النظام هذه على كل عقدة والخادم الرئيسي (عقدة الاسم).
- الكتالوج هو خدمة تنسيق البيانات الوصفية التي تنشر التغييرات من عبارات Impala DDL و DML إلى جميع عقد Impala المتأثرة بحيث تظهر الجداول الجديدة أو البيانات التي تم تحميلها حديثًا على الفور لأي عقدة في الكتلة. من المستحسن أن يتم تشغيل مثيل واحد من الكتالوج على نفس مضيف الكتلة مثل البرنامج الخفي المُحدد الحالة.
كيف يعمل اباتشي امبالا
تستخدم Impala ، مثل Apache Hive ، لغة استعلام تعريفية مماثلة ، Hive Query Language (HiveQL) ، وهي مجموعة فرعية من SQL92 ، بدلاً من SQL.
التنفيذ الفعلي للطلب في إمبالا كالتالي:
يرسل تطبيق العميل استعلام SQL عن طريق الاتصال بأي إمبالاد من خلال واجهات تشغيل ODBC أو JDBC القياسية. تصبح إمبالاد المتصلة منسق الطلب الحالي.

يتم تحليل استعلام SQL لتحديد مهام مثيلات Impalad في الكتلة ؛ ثم يتم بناء خطة تنفيذ الاستعلام الأمثل.
يصل Impalad مباشرة إلى HDFS و HBase باستخدام المثيلات المحلية لخدمات النظام لتوفير البيانات. على عكس Apache Hive ، فإن مثل هذا التفاعل المباشر يوفر وقت تنفيذ الاستعلام بشكل كبير ، حيث لا يتم حفظ النتائج الوسيطة.
استجابةً لذلك ، يقوم كل عفريت بإرجاع البيانات إلى Impalad المنسق ، وإرسال النتائج مرة أخرى إلى العميل.
ميزات إمبالا
- دعم المعالجة في الذاكرة في الوقت الحقيقي
- لغة SQL ودية
- يدعم أنظمة التخزين مثل HDFS و Apache HBase و Amazon S3
- يدعم التكامل مع أدوات ذكاء الأعمال مثل Pentaho و Tableau
- يستخدم بناء جملة HiveQL
اباتشي امبالا: الفوائد
تتجنب Impala الحمل الزائد المحتمل لبدء التشغيل لأن جميع عمليات البرنامج الخفي للنظام تبدأ مباشرةً في وقت التمهيد. يوفر وقت تنفيذ الاستعلام بشكل كبير. هناك زيادة إضافية في سرعة Impala لأن أداة SQL هذه لـ Hadoop ، على عكس Hive ، لا تخزن النتائج الوسيطة وتصل إلى HDFS أو HBase مباشرة.
بالإضافة إلى ذلك ، تقوم Impala بإنشاء رمز البرنامج في وقت التشغيل وليس عند التجميع ، كما تفعل Hive. ومع ذلك ، فإن أحد الآثار الجانبية لأداء إمبالا عالي السرعة هو تقليل الموثوقية.
على وجه الخصوص ، إذا تعطلت عقدة البيانات أثناء تنفيذ استعلام SQL ، فسيتم إعادة تشغيل مثيل Impala ، وستستمر Hive في الاحتفاظ بالاتصال بمصدر البيانات ، مما يوفر التسامح مع الخطأ.
تشمل المزايا الأخرى لـ Impala الدعم المدمج لبروتوكول مصادقة الشبكة الآمنة Kerberos ، وتحديد الأولويات ، والقدرة على إدارة قائمة انتظار الطلبات ودعم تنسيقات البيانات الكبيرة الشائعة مثل LZO و Avro و RCFile و Parquet و Sequence.
خلية مقابل إمبالا: أوجه التشابه
يتم توزيع Hive و Impala مجانًا بموجب ترخيص Apache Software Foundation ويشيران إلى أدوات SQL للعمل مع البيانات المخزنة في مجموعة Hadoop. بالإضافة إلى ذلك ، يستخدمون أيضًا نظام الملفات الموزعة HDFS.
تنفذ Impala و Hive مهام مختلفة مع التركيز المشترك على معالجة SQL للبيانات الضخمة المخزنة في مجموعة Apache Hadoop. يوفر Impala واجهة تشبه SQL ، مما يسمح لك بقراءة جداول Hive وكتابتها ، مما يتيح سهولة تبادل البيانات.
في الوقت نفسه ، تجعل Impala عمليات SQL على Hadoop سريعة وفعالة للغاية ، مما يسمح باستخدام DBMS في مشاريع بحث تحليلات البيانات الكبيرة. كلما كان ذلك ممكنًا ، تعمل إمبالا مع بنية Apache Hive الأساسية الحالية المستخدمة بالفعل لتنفيذ استعلامات SQL المجمعة طويلة الأمد.
أيضًا ، تخزن Impala تعريفات الجدول الخاصة بها في metastore ، أو قاعدة بيانات MySQL أو PostgreSQL تقليدية ، أي في نفس المكان حيث تخزن Hive بيانات مماثلة. يسمح لـ Impala بالوصول إلى جداول Hive طالما أن جميع الأعمدة تستخدم أنواع البيانات المدعومة من Impala وتنسيقات الملفات وبرامج ترميز الضغط.
خلية مقابل إمبالا: الاختلافات

لغة برمجة
تمت كتابة Hive بلغة Java ، بينما تمت كتابة Impala بلغة C ++. ومع ذلك ، تستخدم إمبالا أيضًا بعض UDFs Hive المستندة إلى Java.
استخدم حالات
يستخدم مهندسو البيانات Hive في عمليات ETL (الاستخراج والتحويل والتحميل) ، على سبيل المثال ، للوظائف المجمعة طويلة المدى في مجموعات البيانات الكبيرة ، على سبيل المثال ، في مجمعات السفر وأنظمة معلومات المطارات. في المقابل ، تم تصميم إمبالا بشكل أساسي للمحللين وعلماء البيانات وتستخدم بشكل أساسي في مهام مثل ذكاء الأعمال.
أداء
تنفذ Impala استعلامات SQL في الوقت الفعلي ، بينما تتميز Hive بسرعة معالجة البيانات المنخفضة. باستخدام استعلامات SQL البسيطة ، يمكن لـ Impala تشغيل 6-69 مرة أسرع من Hive. ومع ذلك ، يتعامل Hive مع الاستعلامات المعقدة بشكل أفضل.
الكمون / الإنتاجية
إنتاجية الخلية أعلى بكثير من إنتاجية إمبالا. توفر ميزة LLAP (Live Long and Process) ، التي تتيح تخزين الاستعلام مؤقتًا في الذاكرة ، أداءً جيدًا بمستوى منخفض لـ Hive.
يتضمن LLAP خدمات النظام طويلة المدى (daemons) ، والتي تسمح لك بالتفاعل المباشر مع عقد بيانات HDFS واستبدال بنية استعلام DAG المتكاملة بإحكام (الرسم البياني غير الدوري المباشر) - نموذج الرسم البياني المستخدم بنشاط في حوسبة البيانات الضخمة.
التسامح مع الخطأ
Hive هو نظام متسامح مع الأخطاء يحافظ على جميع النتائج الوسيطة. كما أنه يؤثر بشكل إيجابي على قابلية التوسع ولكنه يؤدي إلى انخفاض في سرعة معالجة البيانات. في المقابل ، لا يمكن تسمية إمبالا بمنصة متسامحة مع الأخطاء لأنها مرتبطة بقدر أكبر بالذاكرة.
تحويل الكود
تنشئ الخلية تعبيرات استعلام في وقت الترجمة ، بينما تنشئها إمبالا في وقت التشغيل. يتميز Hive بمشكلة "البداية الباردة" في المرة الأولى التي يتم فيها تشغيل التطبيق ؛ يتم تحويل الاستعلامات ببطء بسبب الحاجة إلى إنشاء اتصال بمصدر البيانات.
لا تملك إمبالا هذا النوع من النفقات العامة لبدء التشغيل. تبدأ خدمات النظام الضرورية (daemons) لمعالجة استعلامات SQL في وقت التمهيد ، مما يؤدي إلى تسريع العمل.
دعم التخزين
تدعم إمبالا تنسيقات LZO و Avro و Parquet ، بينما تعمل Hive مع Plain Text و ORC. ومع ذلك ، يدعم كلاهما تنسيقات RCFIle و Sequence.
| اباتشي خلية | اباتشي امبالا | |
| لغة | جافا | C ++ |
| استخدم حالات | هندسة البيانات | التحليل والتحليل |
| أداء | عالية لطلبات البحث البسيطة | منخفضة نسبيا |
| وقت الإستجابة | المزيد من وقت الاستجابة بسبب التخزين المؤقت | أقل كامنة |
| التسامح مع الخطأ | أكثر تسامحا بسبب MapReduce | أقل تسامحا بسبب MPP |
| تحويلات | بطيء بسبب البداية الباردة | تحويل أسرع |
| دعم التخزين | نص عادي و ORC | LZO ، أفرو ، باركيه |
الكلمات الأخيرة
لا يتنافس Hive و Impala بل يكملان بعضهما البعض بشكل فعال. على الرغم من وجود اختلافات كبيرة بين الاثنين ، إلا أن هناك أيضًا الكثير من القواسم المشتركة ، ويعتمد اختيار أحدهما على الآخر على البيانات والمتطلبات الخاصة للمشروع.
يمكنك أيضًا استكشاف المقارنات المباشرة بين Hadoop و Spark.
.