
Что такое обучающие данные? Как это используется в машинном обучении
Опубликовано: 2021-07-30Модели машинного обучения так же хороши, как и данные, на которых они обучаются.
Без качественных обучающих данных даже самые эффективные машинное обучение алгоритмы не будут работать.
Потребность в качественных, точных, полных и релевантных данных возникает уже в процессе обучения. Только если алгоритм снабжен хорошими данными для обучения, он может легко подобрать функции и найти отношения, которые ему необходимы для прогнозирования в будущем.
Точнее говоря, качественные обучающие данные являются наиболее важным аспектом машинного обучения (и искусственного интеллекта), чем любой другой. Если вы применяете алгоритмы машинного обучения (ML) к нужным данным, вы настраиваете их на точность и успех.
Что такое обучающие данные?
Обучающие данные — это исходный набор данных, используемый для обучения алгоритмов машинного обучения. Модели создают и уточняют свои правила, используя эти данные. Это набор образцов данных, используемых для подбора параметров модели машинного обучения для ее обучения на примере.
Данные для обучения также известны как набор данных для обучения, набор для обучения и набор для обучения. Это важный компонент каждой модели машинного обучения, который помогает им делать точные прогнозы или выполнять желаемую задачу.
Проще говоря, обучающие данные создают модель машинного обучения. Он учит, как выглядит ожидаемый результат. Модель многократно анализирует набор данных, чтобы глубоко понять его характеристики и настроить себя для повышения производительности.
В более широком смысле обучающие данные можно разделить на две категории: размеченные данные и неразмеченные данные .

Что такое размеченные данные?
Размеченные данные — это группа образцов данных, помеченных одной или несколькими значащими метками. Их также называют аннотированными данными, и их метки идентифицируют определенные характеристики, свойства, классификации или содержащиеся объекты.
Например, изображения фруктов можно пометить как яблоки, бананы или виноград .
Помеченные обучающие данные используются в контролируемое обучение. Это позволяет моделям машинного обучения изучать характеристики, связанные с конкретными метками, которые можно использовать для классификации новых точек данных. В приведенном выше примере это означает, что модель может использовать помеченные данные изображения, чтобы понять особенности конкретных фруктов и использовать эту информацию для группировки новых изображений.
Маркировка данных или аннотация — это трудоемкий процесс, поскольку людям необходимо пометить или пометить точки данных. Сбор помеченных данных является сложной и дорогостоящей задачей. Хранить помеченные данные непросто по сравнению с неразмеченными данными.
Что такое немаркированные данные?
Как и ожидалось, немаркированные данные противоположны помеченным данным. Это необработанные данные или данные, которые не помечены какими-либо метками для идентификации классификаций, характеристик или свойств. Он используется в неконтролируемое машинное обучение, а модели машинного обучения должны находить закономерности или сходства в данных, чтобы делать выводы.
Возвращаясь к предыдущему примеру с яблоками , бананами и виноградом , в немаркированных обучающих данных изображения этих фруктов не будут помечены. Модель должна будет оценить каждое изображение, взглянув на его характеристики, такие как цвет и форма.
Проанализировав значительное количество изображений, модель сможет дифференцировать новые изображения (новые данные) на типы фруктов: яблоки , бананы или виноград . Конечно, модель не знала, что этот фрукт называется яблоком. Вместо этого он знает характеристики, необходимые для его идентификации.
Существуют гибридные модели, в которых используется комбинация контролируемого и неконтролируемого машинного обучения.
Как обучающие данные используются в машинном обучении
В отличие от алгоритмов машинного обучения, традиционные алгоритмы программирования следуют набору инструкций для приема входных данных и предоставления выходных данных. Они не полагаются на исторические данные, и каждое их действие основано на правилах. Это также означает, что они не улучшаются со временем, чего нельзя сказать о машинном обучении.
Для моделей машинного обучения исторические данные — это корм. Точно так же, как люди полагаются на прошлый опыт, чтобы принимать лучшие решения, модели машинного обучения смотрят на свой набор обучающих данных с прошлыми наблюдениями, чтобы делать прогнозы.
Прогнозы могут включать классификацию изображений, как в случае распознавание изображений или понимание контекста предложения, как при обработке естественного языка (NLP).
Думайте об ученом данных как об учителе, об алгоритме машинного обучения — как об ученике, а об обучающем наборе данных — как о коллекции всех учебников.
Стремление учителя состоит в том, чтобы ученик хорошо справлялся с экзаменами, а также в реальном мире. В случае алгоритмов ML тестирование похоже на экзамены. Учебники (обучающий набор данных) содержат несколько примеров вопросов, которые будут заданы на экзамене.
Совет: ознакомьтесь с аналитикой больших данных узнать, как собираются, структурируются, очищаются и анализируются большие данные.
Конечно, он не будет содержать все примеры вопросов, которые будут заданы на экзамене, и не все примеры, включенные в учебник, будут заданы на экзамене. Учебники могут помочь подготовить учащихся, научив их, чего ожидать и как реагировать.
Ни один учебник никогда не может быть полностью законченным. С течением времени виды задаваемых вопросов будут меняться, поэтому информация, включенная в учебники, должна быть изменена. В случае алгоритмов ML обучающая выборка должна периодически обновляться для включения новой информации.
Короче говоря, обучающие данные — это учебник, который помогает ученым, работающим с данными, дать алгоритмам машинного обучения представление о том, чего ожидать. Хотя обучающий набор данных не содержит всех возможных примеров, он сделает алгоритмы способными делать прогнозы.
Данные обучения, тестовые данные и проверочные данные
Обучающие данные используются при обучении модели, или, другими словами, это данные, используемые для подгонки модели. Напротив, тестовые данные используются для оценки производительности или точности модели. Это образец данных, используемый для беспристрастной оценки окончательной модели, подходящей для обучающих данных.
Набор обучающих данных — это начальный набор данных, который учит модели машинного обучения идентифицировать желаемые закономерности или выполнять определенную задачу. Набор тестовых данных используется для оценки эффективности обучения или точности модели.
После того, как алгоритм машинного обучения обучен на определенном наборе данных, и если вы протестируете его на том же наборе данных, он, скорее всего, будет иметь высокую точность, поскольку модель знает, чего ожидать. Если обучающий набор данных содержит все возможные значения, с которыми модель может столкнуться в будущем, все в порядке.
Но это никогда не так. Набор обучающих данных никогда не может быть исчерпывающим и не может научить всему, с чем модель может столкнуться в реальном мире. Поэтому тестовый набор данных, содержащий невидимые точки данных, используется для оценки точности модели.
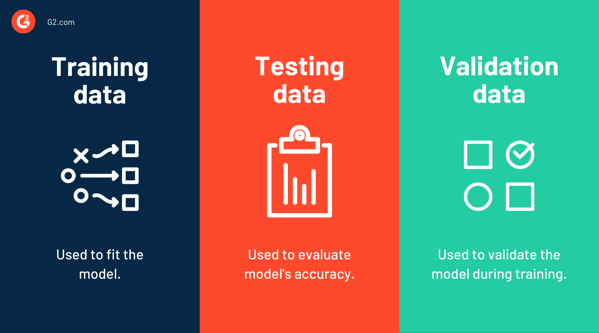
Затем идут проверочные данные . Этот набор данных используется для частой оценки на этапе обучения. Хотя модель время от времени видит этот набор данных, она не учится на нем. Набор для проверки также называется набором для разработки или набором для разработки. Это помогает защитить модели от переобучения и недообучения.
Хотя проверочные данные отделены от обучающих данных, специалисты по данным могут зарезервировать часть обучающих данных для проверки. Но, конечно, это автоматически означает, что во время обучения проверочные данные скрывались.
Совет. Если у вас ограниченный объем данных, для оценки производительности модели можно использовать метод, называемый перекрестной проверкой. Этот метод включает в себя случайное разбиение обучающих данных на несколько подмножеств и резервирование одного для оценки.
Многие используют термины «тестовые данные» и «проверочные данные» как синонимы. Основное различие между ними заключается в том, что данные проверки используются для проверки модели во время обучения, а набор тестов используется для проверки модели после завершения обучения.
Набор данных проверки дает модели первый вкус невидимых данных. Однако не все специалисты по данным выполняют начальную проверку с использованием проверочных данных. Они могут пропустить эту часть и сразу перейти к тестированию данных.

Что такое человек в петле?
Человек в цикле относится к людям, участвующим в сборе и подготовке данных для обучения.
Необработанные данные собираются из нескольких источников, включая устройства IoT, платформы социальных сетей, веб-сайты и отзывы клиентов. После сбора лица, участвующие в процессе, определят важные атрибуты данных, которые являются хорошими индикаторами результата, который вы хотите предсказать с помощью модели.
Данные подготавливаются путем их очистки, учета пропущенных значений, удаления выбросов, маркировки точек данных и загрузки их в подходящие места для обучения алгоритмов машинного обучения. Также будет несколько раундов проверки качества; как известно, неправильные метки могут существенно повлиять на точность модели.
Что делает обучающие данные хорошими?
Высококачественные данные преобразуются в точные модели машинного обучения.
Данные низкого качества могут существенно повлиять на точность моделей, что может привести к серьезным финансовым потерям. Это почти как дать ученику учебник, содержащий неверную информацию, и ожидать, что он отлично сдаст экзамен.
Ниже приведены четыре основных признака качественных обучающих данных.
Актуальны
Данные должны соответствовать поставленной задаче. Например, если вы хотите обучить компьютерное зрение алгоритм для автономных транспортных средств, вам, вероятно, не потребуются изображения фруктов и овощей. Вместо этого вам понадобится обучающий набор данных, содержащий фотографии дорог, тротуаров, пешеходов и транспортных средств.
Представитель
Данные обучения ИИ должны иметь точки данных или функции, которые приложение предназначено для прогнозирования или классификации. Конечно, набор данных никогда не может быть абсолютным, но он должен иметь хотя бы атрибуты, которые приложение ИИ должно распознавать.
Например, если модель предназначена для распознавания лиц на изображениях, она должна быть снабжена разнообразными данными, содержащими лица людей разных национальностей. Это уменьшит проблему предвзятости ИИ, и модель не будет предвзято относиться к определенной расе, полу или возрастной группе.
Униформа
Все данные должны иметь один и тот же атрибут и должны поступать из одного и того же источника.
Предположим, ваш проект машинного обучения направлен на прогнозирование скорости оттока клиентов на основе информации о клиентах. Для этого у вас будет база данных с информацией о клиентах, которая включает имя клиента, адрес, количество заказов, частоту заказов и другую соответствующую информацию. Это исторические данные, и их можно использовать в качестве обучающих данных.
Одна часть данных не может содержать дополнительную информацию, например возраст или пол. Это сделает обучающие данные неполными, а модель — неточной. Короче говоря, единообразие является критическим аспектом качественных обучающих данных.
Всесторонний
Опять же, обучающие данные никогда не могут быть абсолютными. Но это должен быть большой набор данных, представляющий большинство вариантов использования модели. В обучающих данных должно быть достаточно примеров, которые позволят модели правильно обучаться. Он должен содержать образцы данных из реального мира, поскольку это поможет научить модель понимать, чего ожидать.
Если вы думаете об обучающих данных как о значениях, размещенных в большом количестве строк и столбцов, извините, вы ошибаетесь. Это может быть любой тип данных, например текст, изображения, аудио или видео.
Что влияет на качество обучающих данных?
Люди — очень социальные существа, но есть некоторые предубеждения, которые мы могли усвоить в детстве и для избавления от которых требуются постоянные сознательные усилия. Хотя такие предубеждения неблагоприятны, они могут повлиять на наши творения, и приложения машинного обучения ничем не отличаются.
Для моделей машинного обучения обучающие данные — единственная книга, которую они читают. Их эффективность или точность будут зависеть от того, насколько всеобъемлющей, актуальной и репрезентативной является сама книга.
При этом на качество обучающих данных влияют три фактора:
Люди. Люди, которые обучают модель, оказывают значительное влияние на ее точность или производительность. Если они предвзяты, это, естественно, повлияет на то, как они помечают данные и, в конечном счете, на то, как работает модель машинного обучения.
Процессы: процесс маркировки данных должен иметь жесткий контроль качества. Это значительно повысит качество обучающих данных.
Инструменты. Несовместимые или устаревшие инструменты могут ухудшить качество данных. Использование надежного программного обеспечения для маркировки данных может сократить затраты и время, связанные с процессом.
Где взять данные для тренировок
Есть несколько способов получить обучающие данные. Ваш выбор источников может варьироваться в зависимости от масштаба вашего проекта машинного обучения, бюджета и доступного времени. Ниже приведены три основных источника для сбора данных.
Данные для обучения с открытым исходным кодом
Большинство разработчиков машинного обучения-любителей и представителей малого бизнеса, которые не могут позволить себе сбор или маркировку данных, полагаются на обучающие данные из открытых источников. Это простой выбор, так как он уже собран и бесплатен. Однако вам, скорее всего, придется настроить или повторно аннотировать такие наборы данных, чтобы они соответствовали вашим потребностям в обучении. ImageNet, Kaggle и Google Dataset Search — вот некоторые примеры наборов данных с открытым исходным кодом.
Интернет и Интернет вещей
Большинство компаний среднего размера собирают данные с помощью Интернета и устройств IoT. Камеры, датчики и другие интеллектуальные устройства помогают собирать необработанные данные, которые позже будут очищены и аннотированы. Этот метод сбора данных будет специально адаптирован к требованиям вашего проекта машинного обучения, в отличие от наборов данных с открытым исходным кодом. Однако очистка, стандартизация и маркировка данных — это трудоемкий и ресурсоемкий процесс.
Данные искусственного обучения
Как следует из названия, данные искусственного обучения — это искусственно созданные данные с использованием моделей машинного обучения. Их также называют синтетическими данными, и это отличный выбор, если вам нужны обучающие данные хорошего качества с определенными функциями для обучения алгоритма. Конечно, этот метод потребует больших вычислительных ресурсов и достаточного времени.
Сколько обучающих данных достаточно?
Нет конкретного ответа на вопрос, сколько обучающих данных достаточно для обучения. Это зависит от обучаемого алгоритма — его ожидаемого результата, применения, сложности и многих других факторов.
Предположим, вы хотите обучить текстовый классификатор, который классифицирует предложения на основе встречаемости терминов «кошка» и «собака» и их синонимов, таких как «котенок», «котенок», «кошечка», «щенок» или «собачка». . Для этого может не потребоваться большой набор данных, поскольку для сопоставления и сортировки требуется всего несколько терминов.
Но если бы это был классификатор изображений, который классифицировал изображения как «кошки» и «собаки», количество точек данных, необходимых в обучающем наборе данных, значительно увеличилось бы. Короче говоря, многие факторы вступают в игру, чтобы решить, какие обучающие данные являются достаточными обучающими данными.
Объем требуемых данных будет меняться в зависимости от используемого алгоритма.
Для контекста, глубокое обучение, подмножество машинного обучения, требует миллионов точек данных для обучения искусственных нейронных сетей (ИНС). Напротив, алгоритмы машинного обучения требуют только тысячи точек данных. Но, конечно, это надуманное обобщение, поскольку объем необходимых данных зависит от приложения.
Чем больше вы обучаете модель, тем точнее она становится. Поэтому всегда лучше иметь большой объем данных для обучения.
Мусор на входе, мусор на выходе
Фраза «мусор на входе, мусор на выходе» — одна из старейших и наиболее часто используемых фраз в науке о данных. Даже при экспоненциальном росте скорости генерации данных это остается верным.
Ключевым моментом является предоставление высококачественных репрезентативных данных для алгоритмов машинного обучения. Это может значительно повысить точность моделей. Данные обучения хорошего качества также имеют решающее значение для создания объективных приложений машинного обучения.
Вы когда-нибудь задумывались, на что способны компьютеры с человеческим интеллектом? Компьютерный эквивалент человеческого интеллекта известен как общий искусственный интеллект, и нам еще предстоит сделать вывод, будет ли он величайшим или самым опасным изобретением всех времен.