
¿Qué son los datos de entrenamiento? Cómo se usa en el aprendizaje automático
Publicado: 2021-07-30Los modelos de aprendizaje automático son tan buenos como los datos con los que se entrenan.
Sin datos de entrenamiento de alta calidad, incluso los más eficientes aprendizaje automático los algoritmos no funcionarán.
La necesidad de datos de calidad, precisos, completos y relevantes comienza desde el principio del proceso de capacitación. Solo si el algoritmo se alimenta con buenos datos de entrenamiento, puede captar fácilmente las características y encontrar las relaciones que necesita para predecir en el futuro.
Más precisamente, los datos de entrenamiento de calidad son el aspecto más importante del aprendizaje automático (y la inteligencia artificial) que cualquier otro. Si introduce los algoritmos de aprendizaje automático (ML) en los datos correctos, los está configurando para la precisión y el éxito.
¿Qué son los datos de entrenamiento?
Los datos de entrenamiento son el conjunto de datos inicial que se utiliza para entrenar algoritmos de aprendizaje automático. Los modelos crean y refinan sus reglas utilizando estos datos. Es un conjunto de muestras de datos que se utilizan para ajustar los parámetros de un modelo de aprendizaje automático para entrenarlo con el ejemplo.
Los datos de entrenamiento también se conocen como conjunto de datos de entrenamiento, conjunto de aprendizaje y conjunto de entrenamiento. Es un componente esencial de cada modelo de aprendizaje automático y les ayuda a hacer predicciones precisas o realizar una tarea deseada.
En pocas palabras, los datos de entrenamiento construyen el modelo de aprendizaje automático. Enseña cómo se ve el resultado esperado. El modelo analiza el conjunto de datos repetidamente para comprender en profundidad sus características y ajustarse para un mejor rendimiento.
En un sentido más amplio, los datos de entrenamiento se pueden clasificar en dos categorías: datos etiquetados y datos no etiquetados .

¿Qué son los datos etiquetados?
Los datos etiquetados son un grupo de muestras de datos etiquetados con una o más etiquetas significativas. También se denominan datos anotados y sus etiquetas identifican características, propiedades, clasificaciones u objetos contenidos específicos.
Por ejemplo, las imágenes de frutas se pueden etiquetar como manzanas, plátanos o uvas .
Los datos de entrenamiento etiquetados se utilizan en aprendizaje supervisado. Permite que los modelos de ML aprendan las características asociadas con etiquetas específicas, que se pueden usar para clasificar puntos de datos más nuevos. En el ejemplo anterior, esto significa que un modelo puede usar datos de imágenes etiquetadas para comprender las características de frutas específicas y usar esta información para agrupar nuevas imágenes.
El etiquetado o la anotación de datos es un proceso que lleva mucho tiempo, ya que los humanos necesitan etiquetar o etiquetar los puntos de datos. La recopilación de datos etiquetados es desafiante y costosa. No es fácil almacenar datos etiquetados en comparación con datos no etiquetados.
¿Qué son los datos sin etiquetar?
Como era de esperar, los datos sin etiquetar son lo opuesto a los datos etiquetados. Son datos sin procesar o datos que no están etiquetados con ninguna etiqueta para identificar clasificaciones, características o propiedades. se usa en aprendizaje automático no supervisado, y los modelos ML tienen que encontrar patrones o similitudes en los datos para llegar a conclusiones.
Volviendo al ejemplo anterior de manzanas , plátanos y uvas , en datos de entrenamiento sin etiquetar, las imágenes de esas frutas no estarán etiquetadas. El modelo tendrá que evaluar cada imagen observando sus características, como el color y la forma.
Después de analizar una cantidad considerable de imágenes, el modelo podrá diferenciar nuevas imágenes (nuevos datos) en los tipos de frutas de manzanas , plátanos o uvas . Por supuesto, el modelo no sabría que la fruta en particular se llama manzana. En cambio, conoce las características necesarias para identificarlo.
Hay modelos híbridos que utilizan una combinación de aprendizaje automático supervisado y no supervisado.
Cómo se utilizan los datos de entrenamiento en el aprendizaje automático
A diferencia de los algoritmos de aprendizaje automático, los algoritmos de programación tradicionales siguen un conjunto de instrucciones para aceptar datos de entrada y proporcionar resultados. No se basan en datos históricos y cada acción que realizan se basa en reglas. Esto también significa que no mejoran con el tiempo, lo que no ocurre con el aprendizaje automático.
Para los modelos de aprendizaje automático, los datos históricos son forraje. Así como los humanos confían en experiencias pasadas para tomar mejores decisiones, los modelos ML analizan su conjunto de datos de entrenamiento con observaciones pasadas para hacer predicciones.
Las predicciones podrían incluir la clasificación de imágenes como en el caso de reconocimiento de imágenes, o comprensión del contexto de una oración como en el procesamiento del lenguaje natural (PNL).
Piense en un científico de datos como un maestro, el algoritmo de aprendizaje automático como el estudiante y el conjunto de datos de capacitación como la colección de todos los libros de texto.
La aspiración del docente es que el alumno se desempeñe bien en los exámenes y también en el mundo real. En el caso de los algoritmos de ML, las pruebas son como los exámenes. Los libros de texto (conjunto de datos de entrenamiento) contienen varios ejemplos del tipo de preguntas que se harán en el examen.
Sugerencia: consulte el análisis de big data saber cómo se recopilan, estructuran, limpian y analizan los grandes datos.
Por supuesto, no contendrá todos los ejemplos de preguntas que se harán en el examen, ni todos los ejemplos incluidos en el libro de texto se harán en el examen. Los libros de texto pueden ayudar a preparar al estudiante enseñándole qué esperar y cómo responder.
Ningún libro de texto puede estar completamente completo. A medida que pasa el tiempo, el tipo de preguntas que se hacen cambiará y, por lo tanto, es necesario cambiar la información incluida en los libros de texto. En el caso de los algoritmos de ML, el conjunto de entrenamiento debe actualizarse periódicamente para incluir nueva información.
En resumen, los datos de entrenamiento son un libro de texto que ayuda a los científicos de datos a dar a los algoritmos de ML una idea de qué esperar. Aunque el conjunto de datos de entrenamiento no contiene todos los ejemplos posibles, creará algoritmos capaces de hacer predicciones.
Datos de entrenamiento frente a datos de prueba frente a datos de validación
Los datos de entrenamiento se usan en el entrenamiento del modelo, o en otras palabras, son los datos que se usan para ajustar el modelo. Por el contrario, los datos de prueba se utilizan para evaluar el rendimiento o la precisión del modelo. Es una muestra de datos utilizada para hacer una evaluación imparcial del modelo final que se ajusta a los datos de entrenamiento.
Un conjunto de datos de entrenamiento es un conjunto de datos inicial que enseña a los modelos de ML a identificar patrones deseados o realizar una tarea en particular. Se utiliza un conjunto de datos de prueba para evaluar qué tan efectivo fue el entrenamiento o qué tan preciso es el modelo.
Una vez que se entrena un algoritmo de ML en un conjunto de datos en particular y si lo prueba en el mismo conjunto de datos, es más probable que tenga una alta precisión porque el modelo sabe qué esperar. Si el conjunto de datos de entrenamiento contiene todos los valores posibles que el modelo podría encontrar en el futuro, todo muy bien.
Pero ese nunca es el caso. Un conjunto de datos de entrenamiento nunca puede ser completo y no puede enseñar todo lo que un modelo podría encontrar en el mundo real. Por lo tanto, se utiliza un conjunto de datos de prueba, que contiene puntos de datos no vistos , para evaluar la precisión del modelo.
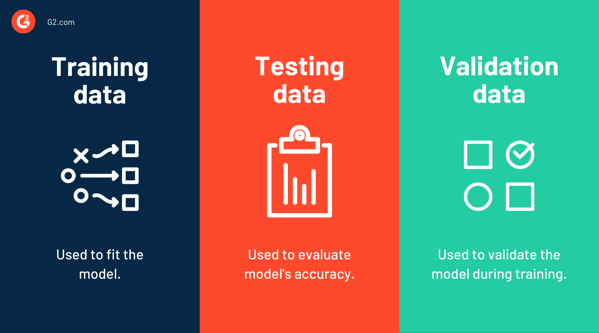
Luego están los datos de validación . Este es un conjunto de datos utilizado para la evaluación frecuente durante la fase de entrenamiento. Aunque el modelo ve este conjunto de datos ocasionalmente, no aprende de él. El conjunto de validación también se conoce como conjunto de desarrollo o conjunto de desarrollo. Ayuda a proteger los modelos de sobreajustes y desajustes.
Aunque los datos de validación están separados de los datos de entrenamiento, los científicos de datos pueden reservar una parte de los datos de entrenamiento para la validación. Pero, por supuesto, esto significa automáticamente que los datos de validación se mantuvieron alejados durante el entrenamiento.
Sugerencia: si tiene una cantidad limitada de datos, se puede usar una técnica llamada validación cruzada para estimar el rendimiento del modelo. Este método implica dividir aleatoriamente los datos de entrenamiento en varios subconjuntos y reservar uno para su evaluación.
Muchos usan los términos "datos de prueba" y "datos de validación" indistintamente. La principal diferencia entre los dos es que los datos de validación se usan para validar el modelo durante el entrenamiento, mientras que el conjunto de prueba se usa para probar el modelo una vez que se completa el entrenamiento.

El conjunto de datos de validación le da al modelo la primera muestra de datos no vistos. Sin embargo, no todos los científicos de datos realizan una verificación inicial utilizando datos de validación. Podrían saltarse esta parte e ir directamente a la prueba de datos.
¿Qué es humano en el bucle?
Human in the loop se refiere a las personas involucradas en la recopilación y preparación de datos de entrenamiento.
Los datos sin procesar se recopilan de múltiples fuentes, incluidos dispositivos IoT, plataformas de redes sociales, sitios web y comentarios de los clientes. Una vez recopilados, las personas involucradas en el proceso determinarían los atributos cruciales de los datos que son buenos indicadores del resultado que desea que prediga el modelo.
Los datos se preparan limpiándolos, teniendo en cuenta los valores faltantes, eliminando valores atípicos, etiquetando puntos de datos y cargándolos en lugares adecuados para entrenar algoritmos de ML. También habrá varias rondas de controles de calidad; como sabe, las etiquetas incorrectas pueden afectar significativamente la precisión del modelo.
¿Qué hace que los datos de entrenamiento sean buenos?
Los datos de alta calidad se traducen en modelos precisos de aprendizaje automático.
Los datos de baja calidad pueden afectar significativamente la precisión de los modelos, lo que puede provocar graves pérdidas financieras. Es casi como darle a un estudiante un libro de texto que contiene información incorrecta y esperar que sobresalga en el examen.
Los siguientes son los cuatro rasgos principales de los datos de entrenamiento de calidad.
Importante
Los datos deben ser relevantes para la tarea en cuestión. Por ejemplo, si desea entrenar a un visión por computador algoritmo para vehículos autónomos, probablemente no necesitará imágenes de frutas y verduras. En su lugar, necesitaría un conjunto de datos de entrenamiento que contenga fotos de carreteras, aceras, peatones y vehículos.
Representante
Los datos de entrenamiento de IA deben tener los puntos de datos o características que la aplicación pretende predecir o clasificar. Por supuesto, el conjunto de datos nunca puede ser absoluto, pero debe tener al menos los atributos que la aplicación de IA debe reconocer.
Por ejemplo, si el modelo está destinado a reconocer rostros dentro de imágenes, debe alimentarse con diversos datos que contengan rostros de personas de diversas etnias. Esto reducirá el problema del sesgo de la IA y el modelo no tendrá prejuicios contra una raza, género o grupo de edad en particular.
Uniforme
Todos los datos deben tener el mismo atributo y deben provenir de la misma fuente.
Suponga que su proyecto de aprendizaje automático tiene como objetivo predecir la tasa de abandono al observar la información del cliente. Para eso, tendrá una base de datos de información del cliente que incluye el nombre del cliente, la dirección, la cantidad de pedidos, la frecuencia de los pedidos y otra información relevante. Estos son datos históricos y se pueden usar como datos de entrenamiento.
Una parte de los datos no puede tener información adicional, como la edad o el sexo. Esto hará que los datos de entrenamiento sean incompletos y el modelo impreciso. En resumen, la uniformidad es un aspecto crítico de los datos de entrenamiento de calidad.
Integral
Nuevamente, los datos de entrenamiento nunca pueden ser absolutos. Pero debe ser un gran conjunto de datos que represente la mayoría de los casos de uso del modelo. Los datos de entrenamiento deben tener suficientes ejemplos que permitan que el modelo aprenda adecuadamente. Debe contener muestras de datos del mundo real, ya que ayudará a entrenar el modelo para comprender qué esperar.
Si está pensando en entrenar datos como valores colocados en un gran número de filas y columnas, lo siento, está equivocado. Puede ser cualquier tipo de datos como texto, imágenes, audio o videos.
¿Qué afecta la calidad de los datos de entrenamiento?
Los seres humanos son criaturas muy sociales, pero existen algunos prejuicios que podríamos haber elegido de niños y que requieren un esfuerzo consciente constante para deshacerse de ellos. Aunque desfavorables, estos sesgos pueden afectar nuestras creaciones y las aplicaciones de aprendizaje automático no son diferentes.
Para los modelos ML, los datos de entrenamiento son el único libro que leen. Su desempeño o precisión dependerá de qué tan completo, relevante y representativo sea el libro.
Dicho esto, tres factores afectan la calidad de los datos de entrenamiento:
Personas: las personas que entrenan el modelo tienen un impacto significativo en su precisión o rendimiento. Si están sesgados, naturalmente afectará la forma en que etiquetan los datos y, en última instancia, cómo funciona el modelo ML.
Procesos: El proceso de etiquetado de datos debe contar con estrictos controles de calidad. Esto aumentará significativamente la calidad de los datos de entrenamiento.
Herramientas: Las herramientas incompatibles u obsoletas pueden hacer que la calidad de los datos se vea afectada. El uso de un software robusto de etiquetado de datos puede reducir el costo y el tiempo asociados con el proceso.
Dónde obtener datos de entrenamiento
Hay varias formas de obtener datos de entrenamiento. Su elección de fuentes puede variar según la escala de su proyecto de aprendizaje automático, el presupuesto y el tiempo disponible. Las siguientes son las tres fuentes principales para recopilar datos.
Datos de entrenamiento de código abierto
La mayoría de los desarrolladores de aprendizaje automático aficionados y las pequeñas empresas que no pueden permitirse el lujo de recopilar o etiquetar datos confían en los datos de capacitación de código abierto. Es una elección fácil ya que ya está recopilada y es gratuita. Sin embargo, lo más probable es que tenga que modificar o volver a anotar dichos conjuntos de datos para que se ajusten a sus necesidades de capacitación. ImageNet, Kaggle y Google Dataset Search son algunos ejemplos de conjuntos de datos de código abierto.
Internet y IoT
La mayoría de las medianas empresas recopilan datos mediante Internet y dispositivos IoT. Las cámaras, los sensores y otros dispositivos inteligentes ayudan a recopilar datos sin procesar, que se limpiarán y anotarán más adelante. Este método de recopilación de datos se adaptará específicamente a los requisitos de su proyecto de aprendizaje automático, a diferencia de los conjuntos de datos de código abierto. Sin embargo, limpiar, estandarizar y etiquetar los datos es un proceso que requiere mucho tiempo y recursos.
Datos de entrenamiento artificial
Como sugiere el nombre, los datos de entrenamiento artificial son datos creados artificialmente utilizando modelos de aprendizaje automático. También se denominan datos sintéticos y son una excelente opción si necesita datos de entrenamiento de buena calidad con funciones específicas para entrenar un algoritmo. Por supuesto, este método requerirá grandes cantidades de recursos computacionales y mucho tiempo.
¿Cuántos datos de entrenamiento son suficientes?
No hay una respuesta específica sobre cuántos datos de entrenamiento son suficientes. Depende del algoritmo que esté entrenando: su resultado esperado, aplicación, complejidad y muchos otros factores.
Supongamos que desea entrenar un clasificador de texto que categorice oraciones en función de la aparición de los términos "gato" y "perro" y sus sinónimos, como "gatito", "gatito", "gatito", "cachorro" o "perrito". . Es posible que esto no requiera un gran conjunto de datos, ya que solo hay unos pocos términos para hacer coincidir y ordenar.
Pero, si se tratara de un clasificador de imágenes que clasificara las imágenes como "gatos" y "perros", la cantidad de puntos de datos necesarios en el conjunto de datos de entrenamiento se dispararía significativamente. En resumen, muchos factores entran en juego para decidir qué datos de entrenamiento son suficientes.
La cantidad de datos requeridos cambiará según el algoritmo utilizado.
Por contexto, el aprendizaje profundo, un subconjunto del aprendizaje automático, requiere millones de puntos de datos para entrenar las redes neuronales artificiales (ANN). Por el contrario, los algoritmos de aprendizaje automático requieren solo miles de puntos de datos. Pero, por supuesto, esta es una generalización exagerada ya que la cantidad de datos necesarios varía según la aplicación.
Cuanto más entrenas al modelo, más preciso se vuelve. Por lo tanto, siempre es mejor tener una gran cantidad de datos como datos de entrenamiento.
Basura dentro basura fuera
La frase "basura entra, basura sale" es una de las frases más antiguas y utilizadas en la ciencia de datos. Incluso con la tasa de generación de datos creciendo exponencialmente, sigue siendo cierto.
La clave es proporcionar datos representativos y de alta calidad a los algoritmos de aprendizaje automático. Si lo hace, puede mejorar significativamente la precisión de los modelos. Los datos de entrenamiento de buena calidad también son cruciales para crear aplicaciones de aprendizaje automático imparciales.
¿Alguna vez se preguntó de qué serían capaces las computadoras con inteligencia similar a la humana? El equivalente informático de la inteligencia humana se conoce como inteligencia artificial general, y aún tenemos que concluir si será el invento más grande o el más peligroso de la historia.