
Co to jest rodowód danych? Dlaczego ważne jest śledzenie przepływu danych
Opublikowany: 2021-09-28Niektórzy profesjonaliści postrzegają pochodzenie danych jako GPS danych.
Dzieje się tak, ponieważ pochodzenie danych pomaga użytkownikom uzyskać wizualny przegląd ścieżki danych i przekształceń. Dokumentuje, w jaki sposób dane są przetwarzane, przekształcane i przesyłane w celu uzyskania znaczących informacji używanych przez firmy do prowadzenia działalności.
Pochodzenie danych pomaga firmom uzyskać szczegółowy obraz przepływu danych od źródła do miejsca docelowego. Wiele organizacji używa oprogramowanie do wirtualizacji danych z pochodzeniem danych, aby pomóc im śledzić ich dane, jednocześnie dostarczając użytkownikom informacje w czasie rzeczywistym.
Co to jest rodowód danych?
Pochodzenie danych to proces identyfikowania pochodzenia danych, rejestrowania sposobu ich przekształcania i przemieszczania się w czasie oraz wizualizacji ich przepływu od źródeł danych do użytkowników końcowych. Pomaga analitykom danych uzyskać szczegółowy wgląd w dynamikę danych i umożliwia śledzenie błędów aż do pierwotnej przyczyny.
Pochodzenie danych informuje inżynierów o przekształceniach danych i przyczynach ich występowania. Pomaga organizacjom śledzić błędy, przeprowadzać migracje systemów, przybliżać do siebie wykrywanie danych i metadane oraz wdrażać zmiany procesów przy mniejszym ryzyku.
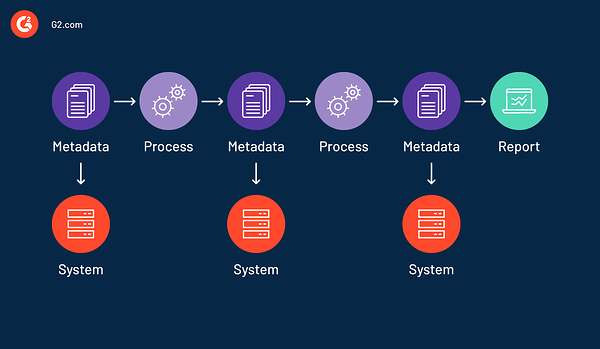
Strategiczne decyzje biznesowe zależą od dokładności danych. Bez dobrej linii danych śledzenie procesów danych i ich weryfikacja staje się trudne. Pochodzenie danych umożliwia użytkownikom wizualizację pełnego przepływu informacji od źródła do miejsca docelowego, ułatwiając wykrywanie i naprawianie anomalii. Dzięki pochodzeniu danych użytkownicy mogą odtwarzać określone fragmenty lub dane wejściowe przepływu danych w celu debugowania lub wygenerowania utraconych danych wyjściowych.
W sytuacjach, w których użytkownicy nie potrzebują szczegółowych informacji na temat pochodzenia technicznego, używają pochodzenia danych, aby uzyskać ogólny przegląd przepływu danych. Wiele systemy bazodanowe wykorzystać pochodzenie danych, aby sprostać wyzwaniom związanym z debugowaniem i walidacją.
Co to jest pochodzenie danych?
Pochodzenie danych to dokumentacja pochodzenia danych i metod ich wytwarzania.
Chociaż pochodzenie danych i pochodzenie danych mają podobieństwa, pochodzenie danych jest bardziej przydatne dla użytkowników biznesowych, którzy potrzebują ogólnego przeglądu tego, skąd pochodzą dane. Wręcz przeciwnie, pochodzenie danych obejmuje pochodzenie zarówno na poziomie biznesowym, jak i technicznym i zapewnia szczegółowy widok przepływu danych.
Pochodzenie danych i zarządzanie danymi
Zarządzanie danymi to zestaw reguł i procedur stosowanych przez organizacje do przechowywania i kontrolowania danych. Pochodzenie danych jest istotną częścią zarządzania danymi, ponieważ informuje o przepływie danych ze źródła do miejsca docelowego.
Firmy korzystają z różnych poziomów linii danych w zależności od swoich potrzeb. Niższe poziomy pochodzenia danych zapewniają prostą wizualną reprezentację przepływu danych w organizacji, bez uwzględniania szczegółowych informacji o przekształceniach zachodzących podczas ich przemieszczania się w potoku. Najwyższa warstwa to pochodzenie danych na poziomie atrybutów, które oferuje wgląd w to, jak można zoptymalizować przepływ danych i sposoby ulepszania platform danych.
Organizacje wybierają poziom pochodzenia danych w oparciu o swoją strukturę zarządzania, koszty poniesione w związku z wdrażaniem i monitorowaniem, kwestie regulacyjne oraz wpływ, jaki miałby on na biznes.
Zrozumienie pochodzenia danych jest kluczowym aspektem zarządzania metadanymi, co czyni go niezbędnym dla hurtownia danych oraz administratorzy jezior danych. Zarządzanie metadanymi umożliwia przeglądanie przepływu danych przez różne systemy, ułatwiając odnalezienie wszystkich danych powiązanych z konkretnym raportem lub wyodrębnianie, przekształcanie, ładowanie (ETL).
„Gromadzenie rodowodu danych – opisujące pochodzenie, strukturę i zależności danych – automatycznie podnosi jakość dostarczanych metadanych i zmniejsza nakład pracy ręcznej”.
Josef Viehhauser
Wiodąca platforma w BMW
Dlaczego pochodzenie danych jest ważne?
Pochodzenie danych nie tylko pomaga rozwiązywać problemy lub przeprowadzać migracje systemu, ale także zapewnia poufność i integralność danych poprzez śledzenie zmian, sposobu ich wykonania i tego, kto je wprowadził.
Dzięki pochodzeniu danych zespoły IT mogą wizualizować kompleksową podróż danych od początku do końca. Ułatwia pracę informatyków i zapewnia użytkownikom biznesowym pewność podejmowania skutecznych decyzji.
Narzędzia linii danych pomagają odpowiedzieć na następujące pytania:
- Jak zmieniono dane i w jakim procesie?
- Kto był odpowiedzialny za modyfikacje danych?
- Kiedy dokonano zmiany?
- Jakie było położenie geograficzne osoby, która dokonała modyfikacji?
- Dlaczego dokonano zmiany i jaki jest jej kontekst?
Wymagania dotyczące systemu pochodzenia danych są określane przede wszystkim przez rolę jednostki i cel organizacji. Jednak pochodzenie danych może mieć znaczący wpływ w obszarach, które obejmują:
- Podejmowanie strategicznych decyzji: Pochodzenie danych umożliwia użytkownikom biznesowym lepsze zrozumienie przetwarzanych danych poprzez przeglądanie ich transformacji. Dane te mają kluczowe znaczenie dla działalności biznesowej oraz ulepszania produktów i usług.
- Optymalne wykorzystanie nowych i starych zestawów danych: Pochodzenie danych umożliwia firmom śledzenie różnych zestawów danych, gdy zmieniają się one z powodu ewoluujących technik i technologii gromadzenia.
- Migracja danych: Pochodzenie danych pomaga zespołom IT szybko przenosić dane do nowej lokalizacji pamięci masowej dzięki zrozumieniu lokalizacji i cyklu życia źródeł danych, dzięki czemu projekty migracji są mniej ryzykowne.
- Zarządzanie danymi: ponieważ pochodzenie danych zapewnia szczegółowy wgląd w cykl życia danych, pomaga firmom zarządzać ryzykiem, przestrzegać przepisów branżowych i przeprowadzać audyty.
Specjaliści postrzegają pochodzenie danych jako praktykę dataGovOps, w której pochodzenie, testowanie i piaskownica podlegają praktykom zarządzania danymi.
„Pochodzenie danych to jedna z najważniejszych technologii umożliwiających „poznanie” krajobrazów danych klientów i zrozumienie wdrożonych transformacji danych”.
Wolfgang Strasser
Konsultant ds. danych w Cubido Business Solutions GMBH
Wolfgang Strasser dodał dalej „Konieczność zrozumienia zależności między wyspami danych i systemami w organizacjach jest niezbędna. Jest to wymagane nie tylko z technicznego punktu widzenia; im lepiej wiesz, jak przepływają dane między systemami, możesz lepiej reagować i widzieć skąd pochodzi część informacji, a także przekształcenia, które zostały zastosowane w drodze do systemu docelowego. W niektórych naszych projektach byliśmy w stanie znaleźć zależności systemowe, o których nawet klient nie wiedział."
Istnieją różne sposoby, w jakie pochodzenie danych może pomóc osobom na różnych stanowiskach. Na przykład programista ETL może znaleźć błędy w zadaniu ETL i sprawdzić wszelkie modyfikacje w polach danych, takie jak usuwanie kolumn, dodawanie lub zmiana nazwy. Steward danych może użyć rodowodu do zidentyfikowania najmniejszego i najbardziej użytecznego zasobu danych w zadaniu ETL. Użytkownikom biznesowym pomaga sprawdzić dokładność raportów oraz zidentyfikować procesy i zadania związane z wygenerowaniem błędnych raportów.
Pochodzenie danych znajduje również zastosowanie w: uczenie maszynowe, w którym służy do ponownego uczenia modeli na podstawie nowych lub zmodyfikowanych danych. Pomaga również zmniejszyć dryf modelu. Dryf modelu odnosi się do degradacji wydajności modelu z powodu zmian danych i relacji między zmiennymi wejściowymi i wyjściowymi.
Pochodzenie danych gruboziarnistych i drobnoziarnistych
Naukowcy akademiccy czasami inaczej używają gruboziarnistego i drobnoziarnistego rodowodu danych, ale koncepcja zasadniczo obejmuje poziom rodowodu danych, jaki może uzyskać użytkownik.
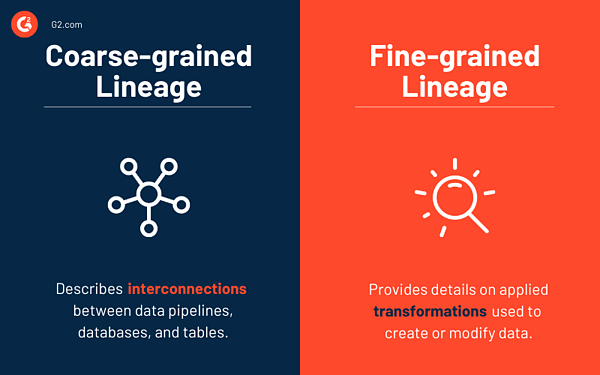
Pochodzenie danych gruboziarnistych opisuje potoki danych, bazy danych, tabele i sposób ich wzajemnego połączenia. Zazwyczaj system zbierania rodowodu gromadzi gruboziarnisty rodowód w czasie wykonywania. Przechwytują wzajemne powiązania między potokami danych, bazami danych i tabelami bez szczegółów dotyczących przekształceń używanych do modyfikowania danych. Pomaga im to obniżyć koszty przechwytywania (szczegółowe informacje o przepływie danych). W sytuacji, gdy użytkownik chce przeprowadzić analizę śledczą w celu debugowania, musiałby odtworzyć przepływ danych w celu zebrania szczegółowego pochodzenia danych.
Z drugiej strony, pochodzenie danych drobnoziarnistych obejmuje szczegółowe zastosowane transformacje, które tworzą lub modyfikują dane. Aktywne systemy gromadzenia danych genealogicznych rejestrują dane o pochodzeniu gruboziarnistym lub drobnoziarnistym w czasie wykonywania. Umożliwia doskonałe odtwarzanie i debugowanie. Jednak koszty wychwytywania są wysokie ze względu na ilość drobnoziarnistych danych o pochodzeniu.
Przypadki użycia linii danych
Pochodzenie danych pomaga organizacjom śledzić przepływ danych w całym cyklu życia, zobaczyć zależności i zrozumieć transformacje. Zespoły wykorzystują szczegółowy widok przepływu danych i wykorzystują go do wielu celów.
Identyfikacja głównej przyczyny błędów
W sytuacjach, w których dane dotyczące sprzedaży nie są zgodne z danymi działu finansowego, pojawia się zamieszanie i trudno jest określić, gdzie faktycznie występuje błąd. Pochodzenie danych zapewnia rozsądne wyjaśnienie takich przypadków. Menedżerowie Business Intelligence (BI) mogą używać linii danych do śledzenia całego przepływu danych i obserwowania wszelkich modyfikacji wprowadzonych podczas przetwarzania.
Niezależnie od tego, czy błąd istnieje, menedżerowie BI mogą mieć pewność, że podają rozsądne wyjaśnienie sytuacji. Jeśli wystąpi błąd, zespoły mogą go naprawić u źródła, umożliwiając jednolitość danych użytkowników końcowych w różnych zespołach.
Aktualizacje systemu
Podczas uaktualniania lub migracji do nowego systemu ważne jest, aby zrozumieć, które zestawy danych są istotne, a które stały się przestarzałe lub nieistniejące. Pochodzenie danych pomaga poznać dane, których faktycznie używasz do wykonywania operacji biznesowych i ogranicza wydatki na przechowywanie nieistotnych danych i zarządzanie nimi.
Dzięki pochodzeniu danych możesz bezproblemowo planować i wykonywać migracje i aktualizacje systemu. Pomaga w wizualizacji źródeł danych, zależności i procesów, dzięki czemu możesz dokładnie wiedzieć, czego potrzebujesz do migracji.

Analiza wpływu
Każda dobra firma identyfikuje raporty, elementy danych i użytkowników końcowych, na które ma wpływ, przed wdrożeniem zmiany. Oprogramowanie do tworzenia linii danych pomaga zespołom wizualizować kolejne obiekty danych i mierzyć wpływ zmiany.
Pochodzenie danych pozwala zobaczyć, w jaki sposób użytkownicy biznesowi wchodzą w interakcję z danymi i jak zmiana wpłynie na nich. Pomaga firmom zrozumieć wpływ konkretnej modyfikacji i pozwala im zdecydować, czy należy ją zastosować.
Techniki pochodzenia danych
Organizacje mogą tworzyć pochodzenie danych na strategicznych zestawach danych przy użyciu kilku standardowych technik. Techniki te zapewniają śledzenie każdej transformacji lub przetwarzania danych, umożliwiając mapowanie elementów danych na każdym etapie, gdy zasoby informacyjne przechodzą przez procesy.
Techniki pochodzenia danych gromadzą i przechowują metadane po każdej transformacji danych, które są później wykorzystywane do reprezentacji pochodzenia danych.
Pochodzenie przez parsowanie
Pochodzenie poprzez analizowanie jednego z najbardziej zaawansowanych formularzy pochodzenia, który odczytuje logikę używaną do przetwarzania danych. Możesz uzyskać kompleksową, kompleksową identyfikowalność dzięki logice transformacji danych inżynierii odwrotnej.
Pochodzenie przez technikę analizowania jest stosunkowo skomplikowane do wdrożenia, ponieważ wymaga zrozumienia wszystkich narzędzi i języków programowania używanych do przekształcania i przetwarzania danych. Może to obejmować logikę ETL, rozwiązania oparte na ustrukturyzowanym języku zapytań (SQL), rozwiązania JAVA, rozwiązania z rozszerzalnym językiem znaczników (XML), starsze formaty danych i wiele innych.
Trudno jest stworzyć rozwiązanie linii danych, które obsługuje kilkanaście języków programowania, a różne narzędzia obsługujące przetwarzanie dynamiczne zwiększają jego złożoność. Wybierając rozwiązanie dotyczące pochodzenia danych, upewnij się, że uwzględnia ono parametry wejściowe, informacje o środowisku wykonawczym i wartości domyślne, a także analizuje wszystkie te elementy, aby zautomatyzować kompleksowe dostarczanie pochodzenia danych.
rodowód oparty na wzorach
Pochodzenie oparte na wzorcach wykorzystuje wzorce do zapewnienia reprezentacji pochodzenia zamiast czytania dowolnego kodu. Pochodzenie oparte na wzorcach wykorzystuje metadane dotyczące tabel, raportów i kolumn oraz profiluje je, aby utworzyć pochodzenie na podstawie wspólnych podobieństw i wzorców.
Bez wątpienia masz przewagę monitorowania danych zamiast algorytmów w tej technice. Twoje rozwiązanie dotyczące pochodzenia danych nie musi rozumieć języków programowania i narzędzi używanych do przetwarzania danych. Może być używany w ten sam sposób w dowolnej technologii baz danych, takiej jak Oracle lub MySQL. Ale jednocześnie ta technika nie zawsze daje dokładne wyniki. Wiele szczegółów, takich jak logika transformacji, jest niedostępnych.
To podejście jest odpowiednie dla przypadków użycia pochodzenia danych, gdy zrozumienie logiki programowania nie jest możliwe z powodu niedostępnego lub niedostępnego kodu.
Samowystarczalny rodowód
Samowystarczalny rodowód śledzi każdy ruch i transformację danych w ramach kompleksowego środowiska, które zapewnia logikę przetwarzania danych, zarządzanie danymi głównymi i nie tylko. Śledzenie przepływu danych i ich cyklu życia staje się łatwe.
Mimo to samodzielne rozwiązanie pozostaje wyłącznie w jednym konkretnym środowisku i jest ślepe na wszystko, co znajduje się poza nim. W miarę pojawiania się nowych potrzeb i wykorzystywania nowych narzędzi do przetwarzania danych, samodzielne rozwiązanie linii danych może nie zapewnić oczekiwanych rezultatów.
Pochodzenie według tagowania danych
Dzięki pochodzeniu przez tagowanie danych każdy fragment danych, który się przenosi lub przekształca, jest oznaczany przez aparat transformacji. Wszystkie znaczniki są następnie odczytywane od początku do końca, aby wytworzyć reprezentację rodowodu. Chociaż wydaje się, że jest to skuteczna technika pochodzenia danych, działa tylko wtedy, gdy istnieje spójny silnik transformacji lub narzędzie do kontrolowania ruchu danych.
Ta technika wyklucza przenoszenie danych poza silnik transformacji, dzięki czemu nadaje się do wykonywania linii danych w zamkniętych systemach danych. W niektórych przypadkach może to nie być preferowana technika pochodzenia danych. Na przykład programiści powstrzymują się od dodawania formalnych kolumn danych do modelu rozwiązania w każdym punkcie styku dla przenoszenia danych.
Blockchain jest jednym z potencjalnych rozwiązań, które pozwala rozwiązać złożoność pochodzenia poprzez tagowanie danych, ale nie ma wystarczająco szerokiego zastosowania, aby wywrzeć znaczący wpływ na cykl życia danych w organizacjach.
Ręczny rodowód
Ręczny rodowód polega na rozmowie z ludźmi, aby zrozumieć przepływ danych w organizacji i go udokumentować. Możesz przeprowadzić wywiady z właścicielami aplikacji, specjalistami ds. integracji danych, administratorami danych i innymi osobami związanymi z cyklem życia danych. Następnie możesz zdefiniować pochodzenie za pomocą arkuszy kalkulacyjnych z prostymi technikami mapowania.
Czasami możesz znaleźć sprzeczne informacje lub przegapić rozmowę z kimś, co prowadzi do niewłaściwego pochodzenia danych. Podczas przechodzenia przez kod będziesz również musiał ręcznie przeglądać tabele, porównywać kolumny itd., co czyni go czasochłonnym i żmudnym procesem. Dynamicznie rosnąca ilość kodu i jego złożoność dodatkowo komplikują ręczne pochodzenie danych.
Niezależnie od tych wyzwań, takie podejście okazuje się korzystne dla zrozumienia, co się dzieje w środowisku. Ręczne pochodzenie danych sprawdza się również, gdy kod jest niedostępny lub niedostępny.
Jak wdrożyć rodowód danych
Wdrażanie pochodzenia danych silnie zależy od kultury danych organizacji. Upewnij się, że masz ugruntowaną strukturę zarządzania danymi i zbuduj ścisłą współpracę ze specjalistami ds. zarządzania danymi i innymi zainteresowanymi stronami, aby pomyślnie wdrożyć linię danych.
Wykonaj te siedem kroków, aby pomyślnie wdrożyć rodowód danych w swojej organizacji.
- Zidentyfikuj kluczowe czynniki biznesowe: Omów powody wdrożenia linii danych i dowiedz się, czy są one kluczowe dla osiągnięcia celów biznesowych. Przyczyny te mogą obejmować zmiany biznesowe, inicjatywy dotyczące jakości danych, wymagania dotyczące audytu lub wymagania prawne.
- Wbudowana kadra kierownicza wyższego szczebla w projekcie: Wdrożenie linii danych wymaga wielu zasobów (zarówno ludzkich, jak i finansowych) oraz czasu. Upewnij się, że masz wsparcie kierownictwa wyższego szczebla, aby doprowadzić projekt wdrożeniowy do końca. Możesz przekonać kierownictwo, wyjaśniając zalety linii danych i sposób, w jaki pomaga w przestrzeganiu przepisów branżowych.
- Zakres inicjatywy: Gdy kierownictwo wyższego szczebla zatwierdzi projekt, zdecyduj o jego zakresie w oparciu o zidentyfikowane czynniki biznesowe i krytyczne elementy danych (CDE). Krytyczne elementy danych mają największy wpływ na wydajność organizacji i doświadczenia klientów.
- Zdefiniuj zakres: zakres pochodzenia danych zaczyna się od źródeł danych i kończy w końcowym punkcie użycia. Duże organizacje mogą ustalić ograniczoną długość linii danych, ponieważ mają wiele oddziałów, aby uniknąć komplikacji.
- Przygotuj wymagania biznesowe: interesariusze mogą mieć różne oczekiwania co do pochodzenia danych. Przede wszystkim istnieją interesariusze biznesowi i interesariusze techniczni, którzy mają różne interesy. Interesariusze biznesowi są bardziej zainteresowani wartością, pochodzeniem danych na poziomach koncepcyjnych modeli danych oraz analizą przyczyn źródłowych. Wręcz przeciwnie, interesariusze techniczni interesują się analizą wpływu, pochodzeniem projektowym metadanych i pochodzeniem danych na poziomie fizycznym.
- Napraw metodę dokumentowania pochodzenia danych: Możesz skorzystać z opisowej lub zautomatyzowanej dokumentacji pochodzenia danych. Oceń, który sposób byłby bardziej odpowiedni dla Twojej organizacji, biorąc pod uwagę czas i zasoby, które będzie ona zużywać.
- Wybierz odpowiednie oprogramowanie do tworzenia linii danych: Wybierz oprogramowanie do tworzenia linii danych, które najlepiej odpowiada Twoim celom i oczekiwaniom. Możesz odkrywać oprogramowanie do zarządzania danymi podstawowymi, który oferuje zautomatyzowane możliwości rodowodu.
Najlepsze praktyki dotyczące linii danych
Lineage pomaga uzyskać wiarygodne i dokładne dane, które wspierają proces podejmowania decyzji w Twojej firmie. Planowanie i wdrażanie to krytyczny element zarządzania danymi — musisz mieć pewność, skąd pochodzą Twoje dane i dokąd Cię prowadzą.
Istnieje kilka praktyk, które możesz wziąć pod uwagę podczas planowania i wdrażania linii danych w swojej organizacji:
- Zautomatyzuj wyodrębnianie pochodzenia danych: Dane i ich pochodzenie to dynamiczna całość. Musisz wyjść poza ręczne rejestrowanie linii danych w arkuszach kalkulacyjnych i zautomatyzować proces, aby konkurować w zwinnym środowisku.
- Uwzględnij źródło metadanych: systemy zarządzania bazami danych, narzędzia Big Data, oprogramowanie ETL i inne niestandardowe aplikacje tworzą własne dane o przetwarzanych danych. Uwzględnij te metadane w swoim rodowodzie, ponieważ pomaga to w zrozumieniu przepływu danych i modyfikacji.
- Weryfikuj źródła metadanych: Zachęć właścicieli aplikacji i narzędzi do weryfikacji odpowiednich źródeł metadanych, ponieważ to oni jasno rozumieją dokładność i trafność metadanych.
- Planuj ekstrakcję progresywną: wyodrębniaj metadane i rodowód w tej samej kolejności, w jakiej dane przepływają przez system. Upraszcza mapowanie połączeń, relacji i zależności między systemami i wewnątrz danych.
- Weryfikuj pochodzenie danych od końca do końca: sprawdzaj pochodzenie stopniowo, zaczynając od połączeń wysokiego poziomu między systemami, a następnie zagłębiaj się w połączone zestawy danych, po których następują elementy danych, przed sprawdzeniem poprawności dokumentacji przekształceń.
- Wdrażanie oprogramowania do katalogowania danych: Zaadoptuj i inteligentne i zautomatyzowane oprogramowanie do katalogowania danych zebrać dane o rodowodach ze wszystkich źródeł. To oprogramowanie umożliwia również wyodrębnienie i wywnioskowanie rodowodu z metadanych.
Śledź przepływ danych na poziomie szczegółowym
Pochodzenie danych umożliwia organizacjom uzyskanie szczegółowego wglądu w przepływ danych przez cały cykl życia i pomaga im zidentyfikować główne przyczyny błędów, zarządzać zarządzaniem danymi, przeprowadzać analizę wpływu i podejmować decyzje biznesowe oparte na danych.
Udokumentowanie pochodzenia danych może być trudne, ale dla organizacji korzystne jest skuteczne zrozumienie i wykorzystanie ich danych.
Dowiedz się więcej o tym, jak uzyskać dane w czasie rzeczywistym, aby podejmować strategiczne decyzje biznesowe dzięki wirtualizacji danych.