
データ系統とは? データフローを追跡することが重要な理由
公開: 2021-09-28一部の専門家は、データ系統をデータの GPS と見なしています。
これは、データ系統が、ユーザーがデータのパスと変換の視覚的な概要を把握するのに役立つためです。 企業が業務を遂行するために使用する意味のある情報を構成するために、データがどのように処理、変換、送信されるかを文書化します。
データ リネージは、企業がソースから宛先へのデータ フローを詳細に把握するのに役立ちます。 多くの組織が使用 データ仮想化ソフトウェア ユーザーにリアルタイムの情報を提供しながら、データを追跡するのに役立つデータ系列を使用します。
データ系統とは何ですか?
データリネージとは、データの出所を特定し、時間の経過とともにデータがどのように変換および移動するかを記録し、データ ソースからエンド ユーザーまでの流れを視覚化するプロセスです。 これは、データ サイエンティストがデータ ダイナミクスを詳細に可視化し、エラーを根本原因まで追跡できるようにするのに役立ちます。
データ系統は、データ変換とその発生理由についてエンジニアに通知します。 これは、組織がエラーを追跡し、システム移行を実行し、データ検出とメタデータを近づけて、より少ないリスクでプロセス変更を実装するのに役立ちます。
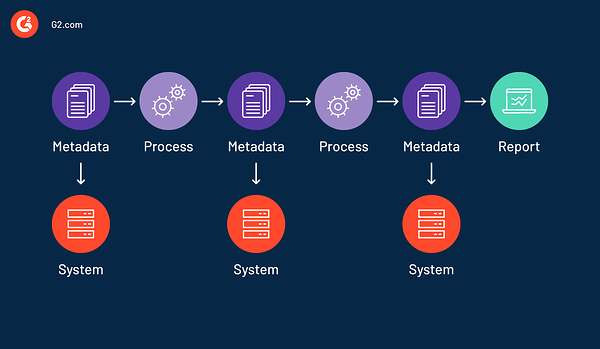
戦略的なビジネス上の意思決定は、データの正確さに依存します。 適切なデータ リネージがなければ、データ プロセスを追跡して検証することが難しくなります。 データ系統により、ユーザーは送信元から送信先までの完全な情報の流れを視覚化できるため、異常の検出と修正が容易になります。 データ リネージを使用すると、ユーザーはデータ フローの特定の部分または入力を再生して、失われた出力をデバッグまたは生成できます。
ユーザーが技術系統の詳細を必要としない状況では、データの来歴を使用してデータ フローの概要を把握します。 たくさんの データベースシステム データの来歴を活用して、デバッグと検証の課題に対処します。
データの来歴とは何ですか?
データの来歴とは、データがどこから来て、どのように生成されたのかを文書化したものです。
データの来歴とデータ系統には類似点がありますが、データの出所に関する概要を必要とするビジネス ユーザーにとっては、データの来歴の方が役立ちます。 反対に、データ系統にはビジネス レベルと技術レベルの両方の系統が含まれ、データ フローの詳細なビューが提供されます。
データ系統とデータ ガバナンス
データ ガバナンスは、組織がデータを維持および制御するために使用する一連の規則と手順です。 データリネージは、ソースから宛先へのデータフローを通知するため、データガバナンスの重要な部分です。
企業は、ニーズに基づいてさまざまな層のデータ系統を使用します。 下位レベルのデータ系列は、データがパイプラインを移動するときに発生する変換に関する具体的な詳細を含めずに、組織内でデータがどのように流れるかを単純に視覚的に表現します。 最上位層は属性レベルのデータ系統であり、データ フローを最適化する方法とデータ プラットフォームを改善する方法についての洞察を提供します。
組織は、ガバナンス構造、実装と監視で発生するコスト、規制上の懸念、およびビジネスへの影響に基づいて、データ系統層を選択します。
データ系統を理解することは、メタデータ管理の重要な側面であり、 データウェアハウス およびデータレイク管理者。 メタデータ管理により、さまざまなシステムを介したデータ フローを表示できるため、特定のレポートまたは抽出、変換、読み込み (ETL) プロセスに関連するすべてのデータを簡単に見つけることができます。
「データ系統を収集する - データの起源、構造、および依存関係を記述する - 提供されるメタデータの品質が自動的に向上し、手作業が削減されます。」
ヨーゼフ・ヴィーハウザー
BMW のプラットフォーム リード
データ系統が重要な理由
データ系統は、問題の修正やシステム移行の実行に役立つだけでなく、変更、その実行方法、作成者を追跡することで、データの機密性と整合性を確保することもできます。
データリネージを使用すると、IT チームはデータのエンドツーエンドのジャーニーを最初から最後まで視覚化できます。 これにより、IT プロフェッショナルの仕事が容易になり、ビジネス ユーザーが自信を持って効果的な意思決定を行うことができます。
データ系統ツールは、次の質問に答えるのに役立ちます。
- データはどのように、どのプロセスによって変更されましたか?
- データ変更の責任者は?
- 変更はいつ行われましたか?
- 変更を行った人物の地理的な場所は?
- 変更が行われた理由とその背後にあるコンテキストは何ですか?
データ系統システムの要件は、主に個人の役割と組織の目的によって決まります。 ただし、データ リネージュは、次のような領域に大きな影響を与える可能性があります。
- 戦略的意思決定:データ リネージにより、ビジネス ユーザーは、処理されたデータがどのように変換されたかを確認することで、よりよく理解できるようになります。 このデータは、事業運営や製品やサービスの改善に不可欠です。
- 新しいデータセットと古いデータセットの最適な使用:データ リネージにより、ビジネスは、進化する収集技術とテクノロジによって変化するさまざまなデータセットを追跡できます。
- データ移行:データ リネージは、IT チームがデータ ソースの場所とライフサイクルを理解することでデータを新しい保存場所に迅速に移動し、移行プロジェクトのリスクを軽減するのに役立ちます。
- データ ガバナンス:データ リネージはデータ ライフサイクル全体をきめ細かく可視化するため、企業がリスクを管理し、業界の規制に準拠し、監査を実行するのに役立ちます。
専門家は、データ リネージュを、リネージ、テスト、およびサンドボックス化がデータ ガバナンス プラクティスの下にある dataGovOps プラクティスと見なしています。
「データリネージは、顧客のデータランドスケープを「知り」、実装されたデータ変換を理解するための最も重要なテクノロジーの 1 つです。」
ヴォルフガング・シュトラッサー
Cubido Business Solutions GMBHのデータコンサルタント
Wolfgang Strasser 氏はさらに次のように付け加えています。情報がどこから発生したか、および目的のシステムへの途中で適用された変換. 一部のプロジェクトでは、顧客でさえ気付いていなかったシステムの依存関係を見つけることができました."
データリネージは、さまざまな職務の個人を支援するさまざまな方法があります。 たとえば、ETL 開発者は ETL ジョブのバグを見つけ、列の削除、追加、名前変更などのデータ フィールドの変更を確認できます。 データ スチュワードはリネージを使用して、ETL ジョブで最も役に立たないデータ資産と最も役に立たないデータ資産を特定できます。 ビジネス ユーザーにとっては、レポートの正確性を確認し、間違ったレポートが生成されたときに関連するプロセスとジョブを特定するのに役立ちます。
データリネージは、次の用途にも使用されます 機械学習。新しいデータまたは変更されたデータに基づいてモデルを再トレーニングするために使用されます。 軽減にも役立ちます モデルドリフト。 モデルのドリフトとは、データの変化と入力変数と出力変数の関係によるモデルのパフォーマンスの低下を指します。
粗粒度と細粒度のデータ系統
学術研究者は、粗粒度と細粒度のデータ系統を異なる方法で使用することがありますが、この概念は基本的に、ユーザーが取得できるデータ系統のレベルをカバーしています。
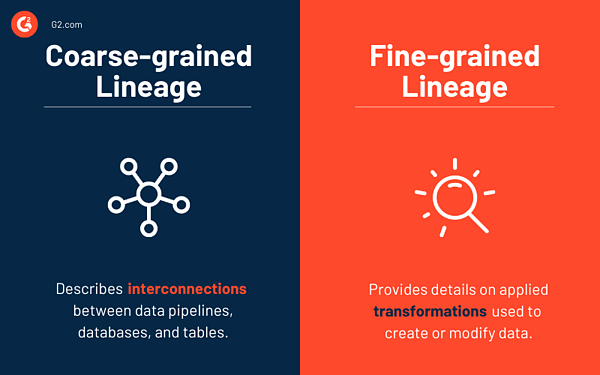
粗粒度のデータ系統では、データ パイプライン、データベース、テーブル、およびそれらがどのように相互接続されているかについて説明します。 通常、系統収集システムは、実行時に大まかな系統を蓄積します。 データ パイプライン、データベース、およびテーブル間の相互接続をキャプチャします。データの変更に使用される変換の詳細は必要ありません。 これにより、キャプチャのオーバーヘッド (データ フローに関する詳細情報) を削減できます。 ユーザーがデバッグ目的でフォレンジック分析を実行したい場合、データ フローを再生して詳細なデータ系列を収集する必要があります。
一方、きめの細かいデータ系列は、データを作成または変更する詳細な適用変換をカバーします。 アクティブ系統収集システムは、実行時に粗粒度または細粒度のデータ系統をキャプチャします。 これにより、優れた再生とデバッグが可能になります。 ただし、粒度の細かい系列データの量が原因で、キャプチャのオーバーヘッドが高くなります。
データリネージのユースケース
データ系統は、組織がライフサイクル全体でデータ フローを追跡し、依存関係を確認し、変換を理解するのに役立ちます。 チームは、データ フローの詳細なビューを活用し、それを多くの目的に使用します。
エラーの根本原因の特定
売上高が財務部門の記録と一致しない状況では混乱が生じ、実際のエラーがどこに存在するかを特定するのは困難です。 データ系列は、そのようなインスタンスについて合理的な説明を提供します。 ビジネス インテリジェンス (BI) マネージャーは、データ系統を使用して完全なデータ フローを追跡し、処理中に行われた変更を確認できます。
エラーが存在するかどうかに関係なく、BI マネージャーは状況について合理的な説明を自信を持って提供できます。 エラーが発生した場合、チームはそれをソースで修正できるため、異なるチーム間でエンド ユーザー データを統一できます。
システムのアップグレード
新しいシステムにアップグレードまたは移行する際には、どのデータセットが関連しており、どのデータセットが古くなったり存在しなくなったりしたかを理解することが不可欠です。 データ リネージは、ビジネス オペレーションを実行するために実際に使用するデータを把握し、無関係なデータの保存と管理への支出を制限するのに役立ちます。

データ リネージを使用すると、システムの移行と更新をシームレスに計画して実行できます。 データ ソース、依存関係、およびプロセスを視覚化するのに役立ち、何を移行する必要があるかを正確に知ることができます。
影響分析
優れたビジネスは、変更を実装する前に、影響を受けるレポート、データ要素、およびエンド ユーザーを特定します。 データ系統ソフトウェアは、チームが下流のデータ オブジェクトを視覚化し、変更の影響を測定するのに役立ちます。
データ リネージを使用すると、ビジネス ユーザーがデータを操作する方法と、変更がビジネス ユーザーに与える影響を確認できます。 これは、企業が特定の変更の影響を理解し、従うべきかどうかを決定するのに役立ちます。
データリネージュ技術
組織は、いくつかの標準的な手法を使用して、戦略的なデータセットでデータ系統を実行できます。 これらの手法により、すべてのデータ変換または処理が追跡され、情報資産がプロセスを通過するすべての段階でデータ要素をマッピングできるようになります。
データ リネージュ技術は、各データ変換後にメタデータを収集して保存し、後でデータ リネージ表現に使用します。
解析による系統
データの処理に使用されるロジックを読み取る最も高度なリネージ フォームの 1 つを解析することによるリネージ。 データ変換ロジックをリバース エンジニアリングすることで、包括的なエンド ツー エンドのトレーサビリティを実現できます。
データの変換と処理に使用されるすべてのツールとプログラミング言語を理解する必要があるため、解析手法によるリネージの展開は比較的複雑です。 これには、ETL ロジック、構造化照会言語 (SQL) ベースのソリューション、JAVA ソリューション、拡張マークアップ言語 (XML) ソリューション、従来のデータ形式などを含めることができます。
多数のプログラミング言語をサポートするデータ リネージ ソリューションを作成するのは難しく、動的処理をサポートするさまざまなツールが複雑さを増しています。 データ リネージ ソリューションを選択する際は、入力パラメーター、実行時情報、およびデフォルト値を考慮し、これらすべての要素を解析して、エンドツーエンドのデータ リネージ配信を自動化するようにしてください。
パターンベースの系統
パターンベースの系統は、コードを読み取る代わりに、パターンを使用して系統表現を提供します。 パターンベースの系列は、テーブル、レポート、および列に関するメタデータを活用し、それらをプロファイリングして、共通の類似性とパターンに基づいて系列を作成します。
この手法では、アルゴリズムではなくデータを監視できるという利点があることは間違いありません。 データ リネージ ソリューションは、データの処理に使用されるプログラミング言語やツールを理解する必要はありません。 Oracle や MySQL などのあらゆるデータベース テクノロジで同じように使用できます。 しかし同時に、この手法では常に正確な結果が得られるとは限りません。 変換ロジックなど、多くの詳細は利用できません。
このアプローチは、コードにアクセスできないか利用できないためにプログラミング ロジックを理解できない場合のデータ系統のユース ケースに適しています。
自己完結型の系統
自己完結型のリネージは、データ処理ロジック、マスター データ管理などを提供する包括的な環境内で、すべてのデータ移動と変換を追跡します。 データフローとそのライフサイクルの追跡が容易になります。
それでも、自己完結型のソリューションは 1 つの特定の環境に排他的なままであり、その外部のすべてに対してブラインドです。 新たなニーズが生まれ、データ処理に新しいツールが使用されるようになると、自己完結型のデータ リネージ ソリューションでは期待どおりの結果が得られない可能性があります。
データのタグ付けによる系統
リネージ バイ データ タグ付けを使用すると、移動または変換される各データは、変換エンジンによってタグ付けされます。 次に、すべてのタグが最初から最後まで読み取られ、系統表現が生成されます。 これは効果的なデータ リネージ手法のように見えますが、データ移動を制御するための一貫した変換エンジンまたはツールが存在する場合にのみ機能します。
この手法は、変換エンジンの外部でのデータの移動を排除するため、クローズド データ システムでデータ リネージを実行するのに適しています。 場合によっては、これが推奨されるデータ リネージ手法ではない可能性があります。 たとえば、開発者は、データ移動のすべてのタッチポイントでソリューション モデルに正式なデータ列を追加することを控えます。
ブロックチェーンは、データのタグ付けによって系統の複雑さに対処するための潜在的なソリューションの 1 つですが、組織のデータ ライフサイクルに大きな影響を与えるほど広く採用されているわけではありません。
手動系統
手動系統には、組織内のデータの流れを理解し、それを文書化するために人々と話すことが含まれます。 アプリケーション所有者、データ統合スペシャリスト、データ スチュワード、およびデータ ライフサイクルに関連するその他の人物にインタビューできます。 次に、単純なマッピング手法を使用してスプレッドシートを使用して系統を定義できます。
場合によっては、矛盾した情報を見つけたり、インタビューを見逃したりして、不適切なデータ系列につながることがあります。 コードを実行しながら、手動でテーブルを確認したり、列を比較したりする必要があるため、時間と手間のかかるプロセスになります。 動的に増加するコード量とその複雑さにより、手作業によるデータ系統の複雑さが増しています。
これらの課題に関係なく、このアプローチは、環境で何が起こっているかを理解するのに有益であることが証明されています。 手動のデータ リネージは、コードが利用できない場合やアクセスできない場合にも効果的です。
データ系統の実装方法
データ系統の実装は、組織のデータ文化に大きく依存します。 確立されたデータ管理フレームワークがあることを確認し、データ管理の専門家やその他の利害関係者と強力なコラボレーションを構築して、データ系統の実装を成功させます。
以下の 7 つの手順に従って、組織にデータリネージを正常に実装してください。
- 主要なビジネス ドライバーを特定する:データ リネージを実装する理由を検討し、それらがビジネス目標を達成するために重要かどうかを確認します。 これらの理由には、ビジネスの変化、データ品質イニシアチブ、監査要件、または法律要件が含まれる場合があります。
- プロジェクトに上級管理職を参加させる:データ リネージの実装には、多くのリソース (人的および財政的) と時間が必要です。 実装プロジェクトを完了に向けて進めるために、上級管理職のサポートがあることを確認してください。 データリネージの利点と、それが業界規制への準拠にどのように役立つかを説明することで、経営陣を納得させることができます。
- イニシアチブのスコープを設定する:上級管理職がプロジェクトを承認したら、特定されたビジネス ドライバーと重要なデータ要素 (CDE) に基づいてそのスコープを決定します。 重要なデータ要素は、組織のパフォーマンスとカスタマー エクスペリエンスに最も大きな影響を与えます。
- スコープを定義する:データ リネージのスコープは、データ ソースから始まり、最終的な使用ポイントで終わります。 大規模な組織は、複雑さを避けるために多くの子会社を持っているため、限られた長さのデータ系統を修正できます。
- ビジネス要件の準備:利害関係者は、データ系統に対して異なる期待を持っている場合があります。 主に、異なる関心を持つビジネス関係者と技術関係者がいます。 ビジネス関係者は、価値、概念データ モデル レベルでのデータ リネージュ、および根本原因分析に関心を持っています。 それどころか、技術関係者は、物理レベルでの影響分析、メタデータ設計系統、およびデータ系統に関心を持っています。
- データ系統を文書化する方法を修正する:説明的または自動化されたデータ系統の文書化を使用できます。 消費する時間とリソースを考慮して、どちらの方法が組織に適しているかを評価します。
- 適切なデータ系統ソフトウェアを選択する:目標と期待に最も適したデータ系統ソフトウェア ソリューションを選択します。 探索できます マスターデータ管理ソフト 自動系統機能を提供します。
データ系統のベスト プラクティス
Lineage は、信頼できる正確なデータを取得して、会社の意思決定プロセスをサポートするのに役立ちます。 計画と実装は、データ ガバナンスの重要な要素です。データがどこから来て、どこへ行くのかを確認する必要があります。
組織でデータリネージを計画および実装する際に考慮できるプラクティスがいくつかあります。
- データ系統抽出の自動化:データとその系統は動的エンティティです。 スプレッドシートでデータ系統を手動でキャプチャするだけでなく、プロセスを自動化して、アジャイルな環境で競争する必要があります。
- メタデータ ソースを含める:データベース管理システム、ビッグ データ ツール、ETL ソフトウェア、およびその他のカスタム アプリケーションは、処理するデータに関する独自のデータを作成します。 データ フローと変更を理解するのに役立つため、このメタデータを系列に含めます。
- メタデータ ソースの検証:アプリケーションとツールの所有者は、メタデータの正確性と関連性を明確に理解しているため、それぞれのメタデータ ソースを検証するよう奨励してください。
- プログレッシブ抽出を計画する:データがシステムを流れるのと同じ順序でメタデータと系統を抽出します。 システム間およびデータ内の接続、関係、および依存関係のマッピングを簡素化します。
- エンド ツー エンドのデータ系統を検証する:システム間の高レベルの接続から始めて段階的に系統を検証し、次に接続されたデータセット、続いてデータ要素を掘り下げてから、変換のドキュメントを検証します。
- データ カタログ ソフトウェアの実装: インテリジェントで自動化されたデータ カタログ ソフトウェア すべてのソースから系統データを収集します。 このソフトウェアを使用すると、メタデータから系統を抽出して推測することもできます。
詳細なレベルでデータ フローを追跡する
データ リネージにより、組織はライフサイクル全体のデータ フローをきめ細かく可視化し、エラーの根本原因の特定、データ ガバナンスの管理、影響分析の実施、およびデータ駆動型のビジネス上の意思決定を行うことができます。
データ系統を文書化するのは難しい場合がありますが、組織がデータを効果的に理解して使用することは有益です。
データ仮想化を使用して戦略的なビジネス上の意思決定を行うためにリアルタイム データを取得する方法の詳細をご覧ください。