
Was ist Datenherkunft? Warum es wichtig ist, den Datenfluss zu verfolgen
Veröffentlicht: 2021-09-28Einige Fachleute betrachten die Datenherkunft als das GPS der Daten.
Dies liegt daran, dass die Datenherkunft Benutzern hilft, einen visuellen Überblick über den Pfad und die Transformationen der Daten zu erhalten. Es dokumentiert, wie Daten verarbeitet, transformiert und übertragen werden, um aussagekräftige Informationen darzustellen, die Unternehmen für ihre Geschäftstätigkeit verwenden.
Die Datenherkunft hilft Unternehmen, einen detaillierten Überblick darüber zu erhalten, wie Daten von der Quelle zum Ziel fließen. Viele Organisationen verwenden Datenvirtualisierungssoftware mit Datenherkunft, um ihnen zu helfen, ihre Daten zu verfolgen und gleichzeitig den Benutzern Echtzeitinformationen bereitzustellen.
Was ist Datenherkunft?
Die Datenherkunft ist der Prozess der Identifizierung des Ursprungs von Daten, der Aufzeichnung, wie sie sich im Laufe der Zeit verändern und bewegen, und der Visualisierung ihres Flusses von Datenquellen zu Endbenutzern. Es hilft Datenwissenschaftlern, einen detaillierten Einblick in die Datendynamik zu erhalten, und ermöglicht es ihnen, Fehler bis zur Grundursache zurückzuverfolgen.
Die Datenherkunft informiert Ingenieure über Datentransformationen und warum sie auftreten. Es hilft Unternehmen, Fehler zu verfolgen, Systemmigrationen durchzuführen, Datenerkennung und Metadaten näher zusammenzubringen und Prozessänderungen mit weniger Risiko zu implementieren.
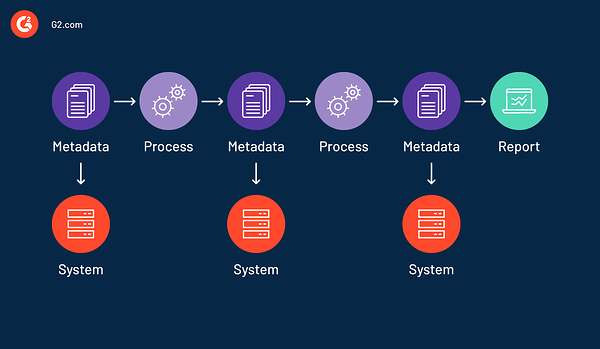
Strategische Geschäftsentscheidungen hängen von der Genauigkeit der Daten ab. Ohne eine gute Datenherkunft wird es schwierig, Datenprozesse zu verfolgen und zu verifizieren. Die Datenherkunft ermöglicht es Benutzern, den gesamten Informationsfluss von der Quelle bis zum Ziel zu visualisieren, wodurch es einfacher wird, Anomalien zu erkennen und zu beheben. Mit der Datenherkunft können Benutzer bestimmte Teile oder Eingaben des Datenflusses wiedergeben, um Fehler zu beheben oder verlorene Ausgaben zu generieren.
In Situationen, in denen Benutzer keine Details zur technischen Herkunft benötigen, verwenden sie die Datenherkunft, um sich einen allgemeinen Überblick über den Datenfluss zu verschaffen. Viele Datenbanksysteme Nutzen Sie die Datenherkunft, um Debugging- und Validierungsherausforderungen zu bewältigen.
Was ist Datenherkunft?
Die Datenherkunft ist die Dokumentation darüber, woher Daten stammen und mit welchen Methoden sie erstellt wurden.
Obwohl Datenherkunft und Datenherkunft Ähnlichkeiten aufweisen, ist die Datenherkunft nützlicher für Geschäftsanwender, die einen allgemeinen Überblick darüber benötigen, woher die Daten stammen. Im Gegensatz dazu umfasst die Datenherkunft sowohl die geschäftliche als auch die technische Herkunft und bietet eine detaillierte Ansicht des Datenflusses.
Datenherkunft und Datenverwaltung
Data Governance ist die Sammlung von Regeln und Verfahren, die Organisationen verwenden, um Daten zu verwalten und zu kontrollieren. Die Datenherkunft ist ein wesentlicher Bestandteil der Data Governance, da sie darüber informiert, wie Daten von der Quelle zum Ziel fließen.
Unternehmen verwenden je nach Bedarf unterschiedliche Ebenen von Datenherkünften. Niedrigere Ebenen der Datenherkunft bieten eine einfache visuelle Darstellung des Datenflusses innerhalb einer Organisation, ohne dass spezifische Details zu den Transformationen enthalten sind, die während der Bewegung durch die Pipeline stattfinden. Die höchste Ebene ist die Datenherkunft auf Attributebene, die Einblicke in die Optimierung des Datenflusses und Möglichkeiten zur Verbesserung von Datenplattformen bietet.
Unternehmen wählen die Datenherkunftsebene basierend auf ihrer Governance-Struktur, den Kosten für die Implementierung und Überwachung, regulatorischen Bedenken und den Auswirkungen auf das Geschäft aus.
Das Verständnis der Datenherkunft ist ein kritischer Aspekt des Metadatenmanagements und daher unerlässlich für Datenlager und Data Lake-Administratoren. Die Metadatenverwaltung ermöglicht es Ihnen, den Datenfluss durch verschiedene Systeme anzuzeigen, wodurch es einfacher wird, alle Daten zu finden, die mit einem bestimmten Bericht oder einem bestimmten ETL-Prozess (Extract, Transform, Load) verbunden sind.
„Das Sammeln von Data Lineage – das Beschreiben von Herkunft, Struktur und Abhängigkeiten von Daten – erhöht automatisch die Qualität der bereitgestellten Metadaten und reduziert den manuellen Aufwand.“
Josef Viehhäuser
Plattformführer bei BMW
Warum ist die Datenherkunft wichtig?
Die Datenherkunft hilft Ihnen nicht nur bei der Behebung von Problemen oder der Durchführung von Systemmigrationen, sondern ermöglicht Ihnen auch, die Vertraulichkeit und Integrität von Daten zu gewährleisten, indem Sie Änderungen nachverfolgen, wie sie durchgeführt wurden und wer sie vorgenommen hat.
Mit Data Lineage können IT-Teams die End-to-End-Reise von Daten von Anfang bis Ende visualisieren. Es erleichtert die Arbeit eines IT-Experten und gibt Geschäftsanwendern das Vertrauen, effektive Entscheidungen zu treffen.
Datenherkunftstools helfen Ihnen bei der Beantwortung der folgenden Fragen:
- Wie wurden Daten verändert und durch welchen Prozess?
- Wer war für Datenänderungen verantwortlich?
- Wann wurde die Änderung vorgenommen?
- Was war der geografische Standort der Person, die Änderungen vorgenommen hat?
- Warum wurde eine Änderung vorgenommen und was ist der Kontext dahinter?
Die Anforderungen an ein Datenherkunftssystem werden in erster Linie durch die Rolle einer Person und das Ziel der Organisation bestimmt. Die Datenherkunft kann jedoch erhebliche Auswirkungen auf folgende Bereiche haben:
- Strategische Entscheidungsfindung: Die Datenherkunft ermöglicht es Geschäftsanwendern, verarbeitete Daten besser zu verstehen, indem sie sehen, wie sie Transformationen durchlaufen haben. Diese Daten sind entscheidend für den Geschäftsbetrieb und die Verbesserung von Produkten und Dienstleistungen.
- Optimale Nutzung neuer und alter Datensätze: Die Datenherkunft ermöglicht es Unternehmen, verschiedene Datensätze zu verfolgen, wenn sie sich aufgrund sich entwickelnder Erfassungstechniken und -technologien ändern.
- Datenmigration: Die Datenherkunft hilft IT-Teams, Daten schnell an einen neuen Speicherort zu verschieben, indem sie den Standort und den Lebenszyklus von Datenquellen versteht, wodurch Migrationsprojekte weniger riskant werden.
- Daten-Governance: Da Data Lineage eine granulare Transparenz über den Datenlebenszyklus bietet, hilft es Unternehmen, Risiken zu managen, Branchenvorschriften einzuhalten und Audits durchzuführen.
Fachleute sehen die Datenherkunft als eine dataGovOps-Praxis, bei der Herkunft, Tests und Sandboxing zu Data-Governance-Praktiken gehören.
„Data Lineage ist eine der wichtigsten Technologien, um die Datenlandschaften der Kunden „kennenzulernen“ und die implementierten Datentransformationen zu verstehen.“
Wolfgang Straßer
Datenberater bei Cubido Business Solutions GMBH
Wolfgang Strasser fügte hinzu: „Die Notwendigkeit, die Abhängigkeiten zwischen den Dateninseln und Systemen in Organisationen zu verstehen, ist von entscheidender Bedeutung. Dies ist nicht nur aus technischer Sicht erforderlich; je besser Sie wissen, wie Ihre Daten zwischen den Systemen fließen, desto besser können Sie reagieren und sehen woher eine Information stammt und welche Transformationen auf dem Weg zum Zielsystem vorgenommen wurden. In einigen unserer Projekte konnten wir Systemabhängigkeiten feststellen, die selbst dem Kunden nicht bewusst waren.“
Es gibt verschiedene Möglichkeiten, wie die Datenherkunft Einzelpersonen in verschiedenen beruflichen Rollen helfen kann. Beispielsweise kann ein ETL-Entwickler Fehler in einem ETL-Job finden und auf Änderungen in Datenfeldern wie Spaltenlöschungen, -hinzufügungen oder -umbenennungen prüfen. Ein Datenverwalter kann Herkunft verwenden, um das am wenigsten und nützlichste Datenobjekt in einem ETL-Job zu identifizieren. Für Geschäftsanwender hilft es, die Genauigkeit von Berichten zu überprüfen und die beteiligten Prozesse und Jobs zu identifizieren, wenn falsche Berichte generiert werden.
Data Lineage findet auch seine Anwendung in maschinelles Lernen, wo es verwendet wird, um Modelle basierend auf neuen oder geänderten Daten neu zu trainieren. Es hilft auch zu reduzieren Modelldrift. Modelldrift bezieht sich auf die Verschlechterung der Modellleistung aufgrund von Änderungen in Daten und Beziehungen zwischen Eingabe- und Ausgabevariablen.
Grobkörnige vs. feinkörnige Datenherkunft
Akademiker verwenden grobkörnige und feinkörnige Datenherkunft manchmal unterschiedlich, aber das Konzept deckt im Wesentlichen die Ebene der Datenherkunft ab, die ein Benutzer erhalten kann.
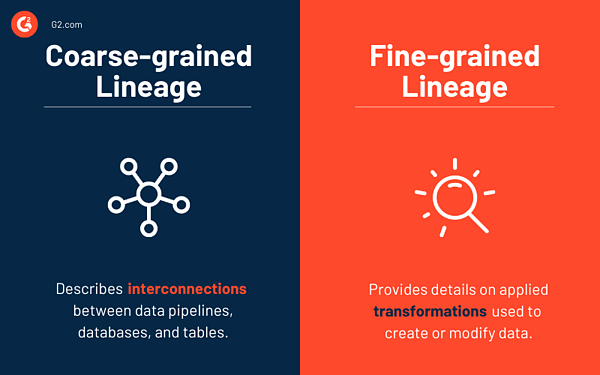
Die grobkörnige Datenherkunft beschreibt Datenpipelines, Datenbanken, Tabellen und wie sie miteinander verbunden sind. Typischerweise akkumuliert ein Herkunftserfassungssystem zur Laufzeit eine grobkörnige Herkunft. Sie erfassen die Vernetzung zwischen Datenpipelines, Datenbanken und Tabellen ohne Details zu Transformationen, die zum Ändern von Daten verwendet werden. Dies hilft ihnen, ihren Erfassungsaufwand zu senken (detaillierte Informationen zum Datenfluss). In einer Situation, in der ein Benutzer eine forensische Analyse zu Debugging-Zwecken durchführen möchte, müsste er den Datenfluss wiederholen, um eine detaillierte Datenherkunft zu sammeln.
Auf der anderen Seite umfasst die feinkörnige Datenherkunft detaillierte angewandte Transformationen, die Daten erstellen oder ändern. Aktive Herkunftserfassungssysteme erfassen zur Laufzeit grob- oder feinkörnige Datenherkunft. Es ermöglicht eine hervorragende Wiedergabe und Fehlersuche. Aufgrund der Menge feinkörniger Abstammungsdaten ist der Erfassungsaufwand jedoch hoch.
Anwendungsfälle der Datenherkunft
Die Datenherkunft hilft Unternehmen, den Datenfluss während des gesamten Lebenszyklus zu verfolgen, Abhängigkeiten zu erkennen und Transformationen zu verstehen. Teams nutzen die granulare Ansicht des Datenflusses und nutzen sie für viele Zwecke.
Identifizieren der Grundursache von Fehlern
Es gibt Verwirrung in Situationen, in denen die Verkaufszahlen nicht mit den Aufzeichnungen der Finanzabteilung übereinstimmen, und es ist schwierig, den tatsächlichen Fehler zu lokalisieren. Die Datenherkunft bietet eine vernünftige Erklärung für solche Fälle. Business-Intelligence-Manager (BI) können die Datenherkunft verwenden, um den gesamten Datenfluss zu verfolgen und alle Änderungen anzuzeigen, die während der Verarbeitung vorgenommen wurden.
Unabhängig davon, ob ein Fehler vorliegt, können BI-Manager zuversichtlich sein, eine vernünftige Erklärung für die Situation bereitzustellen. Wenn ein Fehler auftritt, können Teams ihn an seiner Quelle beheben, wodurch die Einheitlichkeit der Endbenutzerdaten über verschiedene Teams hinweg ermöglicht wird.
System-Upgrades
Beim Upgrade oder der Migration auf ein neues System ist es wichtig zu verstehen, welche Datensätze relevant sind und welche veraltet oder nicht mehr vorhanden sind. Die Datenherkunft hilft Ihnen, die Daten zu kennen, die Sie tatsächlich zur Durchführung von Geschäftsvorgängen verwenden, und begrenzt die Ausgaben für die Speicherung und Verwaltung irrelevanter Daten.
Mit Data Lineage können Sie Systemmigrationen und -aktualisierungen nahtlos planen und ausführen. Es hilft Ihnen, die Datenquellen, Abhängigkeiten und Prozesse zu visualisieren, sodass Sie genau wissen, was Sie migrieren müssen.

Einflussanalyse
Jedes gute Unternehmen identifiziert Berichte, Datenelemente und betroffene Endbenutzer, bevor eine Änderung implementiert wird. Datenherkunftssoftware hilft Teams, nachgelagerte Datenobjekte zu visualisieren und die Auswirkungen der Änderung zu messen.
Mit der Datenherkunft können Sie sehen, wie Geschäftsbenutzer mit Daten interagieren und wie sich eine Änderung auf sie auswirken würde. Es hilft Unternehmen, die Auswirkungen einer bestimmten Änderung zu verstehen, und ermöglicht es ihnen, zu entscheiden, ob sie sie durchziehen sollten.
Data-Lineage-Techniken
Unternehmen können mithilfe einiger Standardtechniken eine Datenherkunft für strategische Datensätze durchführen. Diese Techniken stellen sicher, dass jede Datentransformation oder -verarbeitung nachverfolgt wird, sodass Sie Datenelemente in jeder Phase abbilden können, in der Informationsassets Prozesse durchlaufen.
Datenherkunftstechniken sammeln und speichern nach jeder Datentransformation Metadaten, die später zur Darstellung der Datenherkunft verwendet werden.
Abstammung durch Parsing
Herkunft durch Analysieren einer der fortschrittlichsten Herkunftsformen, die die Logik liest, die zum Verarbeiten von Daten verwendet wird. Sie können eine umfassende End-to-End-Rückverfolgbarkeit durch Reverse Engineering der Datentransformationslogik erhalten.
Die Lineage-by-Parsing-Technik ist relativ kompliziert einzusetzen, da sie das Verständnis aller Tools und Programmiersprachen erfordert, die zum Transformieren und Verarbeiten von Daten verwendet werden. Dies kann ETL-Logik, SQL-basierte Lösungen (Structured Query Language), JAVA-Lösungen, XML-Lösungen (Extensible Markup Language), Legacy-Datenformate und mehr umfassen.
Es ist schwierig, eine Datenherkunftslösung zu erstellen, die ein Dutzend Programmiersprachen unterstützt, und verschiedene Tools, die eine dynamische Verarbeitung unterstützen, tragen zu ihrer Komplexität bei. Stellen Sie bei der Auswahl einer Datenherkunftslösung sicher, dass sie Eingabeparameter, Laufzeitinformationen und Standardwerte berücksichtigt und alle diese Elemente analysiert, um die End-to-End-Datenherkunftsbereitstellung zu automatisieren.
Musterbasierte Abstammung
Die musterbasierte Herkunft verwendet Muster, um die Herkunftsdarstellung bereitzustellen, anstatt Code zu lesen. Die musterbasierte Herkunft nutzt Metadaten zu Tabellen, Berichten und Spalten und profiliert sie, um eine Herkunft basierend auf gemeinsamen Ähnlichkeiten und Mustern zu erstellen.
Sie haben bei dieser Technik zweifelsohne den Vorteil, Daten anstelle von Algorithmen zu überwachen. Ihre Data-Lineage-Lösung muss keine Programmiersprachen und Tools verstehen, die zur Verarbeitung von Daten verwendet werden. Es kann auf die gleiche Weise für jede Datenbanktechnologie wie Oracle oder MySQL verwendet werden. Aber gleichzeitig zeigt diese Technik nicht immer genaue Ergebnisse. Viele Details, wie z. B. Transformationslogik, sind nicht verfügbar.
Dieser Ansatz eignet sich für Anwendungsfälle der Datenherkunft, wenn das Verständnis der Programmierlogik aufgrund von unzugänglichem oder nicht verfügbarem Code nicht möglich ist.
Eigenständige Abstammung
Die eigenständige Herkunft verfolgt jede Datenbewegung und -transformation innerhalb einer allumfassenden Umgebung, die Datenverarbeitungslogik, Stammdatenverwaltung und mehr bereitstellt. Es wird einfach, den Datenfluss und seinen Lebenszyklus zu verfolgen.
Dennoch bleibt die in sich geschlossene Lösung exklusiv für eine bestimmte Umgebung und ist blind für alles außerhalb. Wenn neue Anforderungen auftreten und neue Tools zur Datenverarbeitung verwendet werden, kann die in sich geschlossene Data-Lineage-Lösung die erwarteten Ergebnisse nicht liefern.
Abstammung durch Daten-Tagging
Bei Herkunft durch Daten-Tagging wird jedes Datenelement, das verschoben oder transformiert wird, von einer Transformations-Engine getaggt. Alle Tags werden dann von Anfang bis Ende gelesen, um eine Herkunftsdarstellung zu erzeugen. Obwohl es sich um eine effektive Data-Lineage-Technik handelt, funktioniert es nur, wenn es eine konsistente Transformations-Engine oder ein Tool zur Steuerung der Datenbewegung gibt.
Diese Technik schließt Datenbewegungen außerhalb der Transformations-Engine aus und eignet sich daher für die Durchführung von Data Lineage auf geschlossenen Datensystemen. In einigen Fällen ist dies möglicherweise keine bevorzugte Datenherkunftstechnik. Beispielsweise sehen Entwickler davon ab, an jedem Berührungspunkt für Datenbewegungen formale Datenspalten zum Lösungsmodell hinzuzufügen.
Blockchain ist eine potenzielle Lösung, um die Komplexität der Abstammung durch Datenkennzeichnung anzugehen, aber sie ist nicht weit genug verbreitet, um einen signifikanten Einfluss auf den Datenlebenszyklus in Unternehmen zu haben.
Manuelle Abstammung
Bei der manuellen Abstammung geht es darum, mit Menschen zu sprechen, um den Datenfluss in einer Organisation zu verstehen und ihn zu dokumentieren. Sie können Anwendungseigentümer, Datenintegrationsspezialisten, Datenverwalter und andere Personen befragen, die mit dem Datenlebenszyklus zu tun haben. Als Nächstes können Sie die Abstammung mithilfe von Tabellenkalkulationen mit einfachen Mapping-Techniken definieren.
Manchmal finden Sie möglicherweise widersprüchliche Informationen oder verpassen es, jemanden zu interviewen, was zu einer falschen Datenherkunft führt. Während Sie den Code durchgehen, müssen Sie auch manuell Tabellen überprüfen, Spalten vergleichen usw., was es zu einem zeitaufwändigen und langwierigen Prozess macht. Das dynamisch wachsende Codevolumen und seine Komplexität tragen zu Komplikationen bei der manuellen Datenherkunft bei.
Unabhängig von diesen Herausforderungen erweist sich dieser Ansatz als vorteilhaft, um zu verstehen, was in einer Umgebung vor sich geht. Die manuelle Datenherkunft erweist sich auch als effektiv, wenn Code nicht verfügbar oder nicht zugänglich ist.
So implementieren Sie Data Lineage
Die Implementierung der Datenherkunft hängt stark von der Datenkultur Ihres Unternehmens ab. Stellen Sie sicher, dass Sie über ein etabliertes Datenmanagement-Framework verfügen, und bauen Sie eine enge Zusammenarbeit mit Datenmanagement-Experten und anderen Interessenvertretern für eine erfolgreiche Data-Lineage-Implementierung auf.
Befolgen Sie diese sieben Schritte, um Data Lineage in Ihrem Unternehmen erfolgreich zu implementieren.
- Identifizieren Sie wichtige Geschäftstreiber: Diskutieren Sie Gründe für die Implementierung von Data Lineage und finden Sie heraus, ob sie für das Erreichen von Geschäftszielen entscheidend sind. Diese Gründe können geschäftliche Änderungen, Datenqualitätsinitiativen, auditive Anforderungen oder gesetzliche Anforderungen umfassen.
- Integrieren Sie die Geschäftsleitung in das Projekt: Die Implementierung der Datenherkunft erfordert viele Ressourcen (sowohl personell als auch finanziell) und Zeit. Stellen Sie sicher, dass Sie die Unterstützung der Geschäftsleitung haben, um das Implementierungsprojekt zum Abschluss zu bringen. Sie können das Management überzeugen, indem Sie die Vorteile der Datenherkunft erklären und erklären, wie sie bei der Einhaltung von Branchenvorschriften hilft.
- Umfang der Initiative: Sobald die Geschäftsleitung das Projekt genehmigt hat, legen Sie den Umfang basierend auf den identifizierten Geschäftstreibern und kritischen Datenelementen (CDE) fest. Kritische Datenelemente haben den größten Einfluss auf die Leistung und das Kundenerlebnis des Unternehmens.
- Definieren Sie den Umfang: Der Umfang der Datenherkunft beginnt mit den Datenquellen und endet am endgültigen Verwendungspunkt. Große Organisationen können eine begrenzte Länge der Datenherkunft festlegen, da sie viele Niederlassungen haben, um Komplikationen zu vermeiden.
- Bereiten Sie Geschäftsanforderungen vor: Stakeholder können unterschiedliche Erwartungen an die Datenherkunft haben. In erster Linie gibt es geschäftliche Interessenvertreter und technische Interessenvertreter, die unterschiedliche Interessen haben. Geschäftsbeteiligte sind mehr an Wert, Datenherkunft auf konzeptionellen Datenmodellebenen und Ursachenanalyse interessiert. Im Gegensatz dazu haben technische Interessenvertreter Interesse an Auswirkungsanalysen, Metadaten-Design-Herkunft und Datenherkunft auf physischer Ebene.
- Legen Sie eine Methode zum Dokumentieren der Datenherkunft fest: Sie können entweder die beschreibende oder die automatisierte Datenherkunftsdokumentation verwenden. Bewerten Sie, welcher Weg für Ihr Unternehmen am besten geeignet ist, und berücksichtigen Sie dabei den Zeit- und Ressourcenaufwand.
- Wählen Sie eine geeignete Data-Lineage-Software: Wählen Sie eine Data-Lineage-Softwarelösung, die Ihren Zielen und Erwartungen am besten entspricht. Sie können erkunden Stammdatenverwaltungssoftware die automatisierte Herkunftsfunktionen bietet.
Best Practices für die Datenherkunft
Lineage hilft Ihnen, vertrauenswürdige und genaue Daten zu erhalten, um den Entscheidungsprozess Ihres Unternehmens zu unterstützen. Planung und Implementierung sind ein kritisches Element der Data Governance – Sie müssen sicher sein, woher Ihre Daten kommen und wohin sie Sie führen.
Es gibt einige Vorgehensweisen, die Sie bei der Planung und Implementierung der Datenherkunft in Ihrer Organisation berücksichtigen können:
- Automatisierte Extraktion der Datenherkunft: Daten und ihre Herkunft sind eine dynamische Einheit. Sie müssen über die manuelle Erfassung der Datenherkunft in Tabellenkalkulationen hinausgehen und den Prozess automatisieren, um in einer agilen Umgebung wettbewerbsfähig zu sein.
- Metadatenquelle einbeziehen: Datenbankverwaltungssysteme, Big-Data-Tools, ETL-Software und andere benutzerdefinierte Anwendungen erstellen ihre eigenen Daten über die von ihnen verarbeiteten Daten. Nehmen Sie diese Metadaten in Ihre Herkunft auf, da sie beim Verständnis des Datenflusses und der Änderungen helfen.
- Verifizieren Sie Metadatenquellen: Ermutigen Sie Besitzer von Anwendungen und Tools, die jeweiligen Metadatenquellen zu verifizieren, da sie diejenigen sind, die die Genauigkeit und Relevanz von Metadaten genau verstehen.
- Planen Sie die progressive Extraktion: Extrahieren Sie Metadaten und Abstammung in derselben Reihenfolge, in der Daten durch Ihr System fließen. Es vereinfacht die Abbildung von Verbindungen, Beziehungen und Abhängigkeiten zwischen Systemen und innerhalb von Daten.
- Validieren Sie die End-to-End-Datenherkunft: Validieren Sie die Herkunft schrittweise, indem Sie mit High-Level-Verbindungen zwischen Systemen beginnen und sich dann in verbundene Datasets vertiefen, gefolgt von Datenelementen, bevor Sie die Transformationsdokumentation validieren.
- Implementieren Sie eine Datenkatalogsoftware: Nehmen Sie an intelligente und automatisierte Datenkatalogsoftware Abstammungsdaten aus allen Quellen zu sammeln. Mit dieser Software können Sie auch die Abstammung aus Metadaten extrahieren und ableiten.
Verfolgen Sie den Datenfluss auf granularer Ebene
Die Datenherkunft ermöglicht Unternehmen eine granulare Sichtbarkeit des Datenflusses während des gesamten Lebenszyklus und hilft ihnen, die Grundursache von Fehlern zu identifizieren, die Datenverwaltung zu verwalten, Auswirkungsanalysen durchzuführen und datengesteuerte Geschäftsentscheidungen zu treffen.
Die Dokumentation der Datenherkunft kann schwierig sein, aber es ist für Unternehmen von Vorteil, ihre Daten effektiv zu verstehen und zu nutzen.
Erfahren Sie mehr darüber, wie Sie mit Datenvirtualisierung Echtzeitdaten erhalten, um strategische Geschäftsentscheidungen zu treffen.