
了解災難恢復術語 – RTO、RPO、故障轉移、BCP 等
已發表: 2022-03-20災難恢復計劃是組織在發生異常事件之前必須採取的首要措施。
在 IT 行業,它首先創建一份正式文件,其中包含處理災難及其後果的計劃、行動和程序。
災難是在沒有事先通知的情況下突然發生的事件,可以有不同的類型。 當它落地時,個人和組織將面臨多種困難,包括財務問題和用戶體驗。
如果發生攻擊,您必須準備好將其影響降至最低並更快地恢復您的運營。 這是準備實用的災難恢復計劃將幫助您阻止或防止災難的地方。 您還可以減少其在用戶體驗、成本和停機時間方面的後遺症。
此外,您必須準備好您的計劃、人員、策略、設備和系統,以使一切恢復正常。 但為此,您必須深入了解災難恢復。
在本文中,我將詳細討論這一點以及關鍵的災難恢復術語,以便您可以勇敢地反擊並在這種不利條件下變得更強大。
讓我們開始!
什麼是災難?

災難是可以在任何地方發生的不可預見的事件,包括 IT 行業。 它既可以自然發生,也可以人為發生,可能會干擾公司的運營並擾亂基礎設施的結構。
因此,組織及其客戶、供應商、員工和合作夥伴都會受到影響。 它在財務、行業聲譽、客戶信任和安全範圍方面給組織帶來了壓力。
因此,您必須提前做好準備以克服這種情況。 為此,您需要立即恢復每個操作和數據。 簡而言之,您必須讓您的組織做好準備,以便在盡可能短的時間間隔內為您的客戶恢復一切。
災難有多種類型,例如網絡攻擊、破壞、恐怖襲擊、勒索軟件或物理威脅、颶風、地震、火災、洪水、工業事故、停電等等。
災難恢復是什麼意思?
災難恢復是在遭受災難後恢復正常運行的過程。 它涉及恢復對硬件、軟件、設備、連接性、網絡、電源和數據的訪問。 您必須在記錄的過程中設置規則和程序,以便您的組織在災難發生前做好準備。
但是,如果您組織的設施遭到破壞,您必須通過通信、運輸、採購、工作地點等方面的工作來擴展一些活動。
為什麼災難恢復計劃很重要?
為從自然或人為災難中恢復制定一個完美的計劃對於每個 IT 行業都是必不可少的。 確保您在正確的地方擁有正確的員工和工具,以便順利執行計劃。
讓我們更深入地了解為什麼災難恢復至關重要。
限制損害賠償
災難是不可預知的。 沒有人知道它什麼時候來,什麼時候去。 但是,您提前準備好控制對基礎架構造成的損害。
例如,在洪水多發地區,您可以將重要文件和設備類型放在頂層以避免損壞。
同樣,在網絡攻擊破壞數據或竊取數據之前備份您的基本數據。
恢復服務
如果您為從災難中恢復制定了可靠的計劃,那麼將所有服務恢復到正常狀態是快速而容易的。 這意味著在很短的時間內,您可以恢復幾乎所有的主要資產和服務。
盡量減少中斷
您無法知道明天或手術的下一步會發生什麼。 但是,有了完美的恢復計劃,您就不必擔心後果。 您的基礎架構可以以最小的中斷繼續運行。
培訓和準備

IT 基礎架構由許多在屋簷下工作的員工組成。 所有人都必須了解恢復情況,以便在緊急情況下按要求和預期立即採取行動。
適當的準備還將降低與您的組織相關的每個人的壓力水平。 此外,您可以培訓您的員工在發生意外事件時採取必要的行動。
災難恢復術語
讓我們從術語開始,以更深入地了解災難恢復。
RTO
恢復時間目標 (RTO) 是組織根據業務性質設定的在不影響財務增長的情況下容忍災難的時間量。
在設置 RTO 時,公司必須檢查可能以多種方式影響您的組織的停機時間。 它用於研究可行的策略,即使在災難之後也能繼續您的業務運營。 當客戶在應用程序中遇到任何干擾時,他們會詢問應用程序需要多長時間才能恢復操作。 答案是每個組織的 RTO。
示例:假設您是 PayPal 或 Pioneer 等在線交易公司,面臨不可預測的事件。 在這種情況下,您的 RTO 將足夠快地恢復操作。
換句話說,一家公司將其 RTO 設置為一兩個小時,以避免財務或數據形式的後果。
RPO
恢復點目標 (RPO) 是 IT 基礎架構在時間和信息量方面可以處理的數據丟失。
令人困惑?
以記錄銀行交易的數據庫為例,包括轉賬、調度、支付等。 當災難發生時,數據庫會實時恢復。 在這種情況下,災難時的數據庫與災難後的數據庫恢復之間的差異為零。
對於一些公司來說,從備份中恢復所有信息需要大約 24 小時是可以接受的,但有時這可能是災難性的。 根據 RPO 要求設置基礎架構至關重要。 這包括提高備份頻率、在架構中添加備用數據庫等等。
故障轉移
想一想您長途旅行的情況。 突然,由於一些意想不到的原因,你爆胎了。 您感謝您車輛中的備用輪胎和更換有缺陷輪胎的工具。
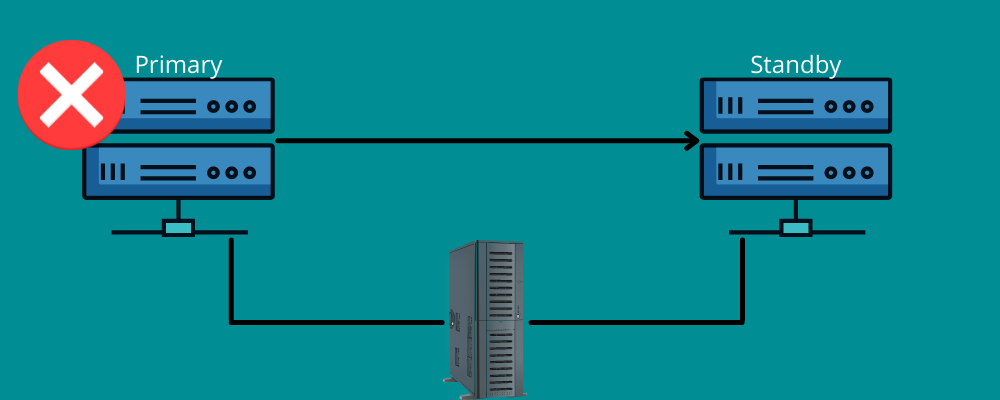
故障轉移以相同的方式工作。
這意味著您在災難期間需要備份連接。 簡而言之,故障轉移意味著擁有可在災難發生時將信息切換到恢復系統的網絡和系統。
故障轉移可確保您的所有服務順利運行,即使存在基礎設施或硬件故障。 這樣,您可以防止您的組織丟失數據和收入,並避免最終用戶的服務中斷。
您可以手動設置它,也可以讓它自動運行以將數據移動到備用服務器。
故障回复
IT 故障恢復是一種簡單的操作,在處理災難後,原始生產回到其原始位置(系統)。 在攻擊期間,公司會執行故障轉移操作,因此所有工作負載都會轉移到 VM 副本或備份系統。
但是,您不能只是跳過返回的下一步。 當您恢復一切並重新投入使用時,您需要將所有工作負載轉移到其原始虛擬機或系統上。 將工作負載返回到原始工作場所或系統的整個過程稱為故障恢復。 這意味著您在攻擊後“回來”。
故障回復也用於企業的定期維護。 確實,故障恢復總是在故障轉移之後發生。 換句話說,故障轉移是第一步,故障恢復是恢復基本數據的第二步。 它可以在雲到雲、本地到本地、本地到雲或這些之間的任何組合之間設置。
博士
災難恢復 (DR) 是您預先制定計劃以在時間範圍內恢復資產的過程。
災難恢復使組織能夠快速響應並從意外事件中恢復每一項服務。 它還提供正式文件,其中包含在發生意外事件時立即採取行動的說明。
BCP
業務連續性計劃 (BCP) 是最可接受的災難恢復計劃之一,它允許 IT 基礎架構制定策略以處理服務器、移動設備、個人計算機和網絡的 IT 中斷。

BCP 與災難恢復略有不同,因為它幫助組織製定計劃以重建企業軟件和生產力以滿足關鍵業務需求。
在這裡,一家公司創建了一個恢復系統來克服潛在的威脅,例如網絡攻擊或自然災害。 它旨在保護資產並確保所有服務在罷工後迅速恢復運作。
BCM

業務連續性管理 (BCM) 是一種風險管理流程,專門設計用於抵禦對業務流程的威脅。 BCM 是 BCP 的下一步,它驗證恢復計劃以確保企業中的每個人都能立即響應計劃並恢復所有重要的東西。
BCM 充當管理框架,用於在面臨外部和/或內部威脅時識別基礎設施風險。 它還確保框架在定期測試的幫助下高效運行,以增強可預測性、降低風險並調整未來攻擊的計劃。
BIA
業務影響分析 (BIA) 是通過識別關鍵系統、運營和流程來分析業務生存率的過程。 它講述了由於您的運營中斷而導致的災難對您的組織的影響。
BIA 在攻擊實際發生之前預測後果,以收集有助於創建強大恢復策略的關鍵信息。 它還確定了由於故障而涉及的成本,例如設備的更換成本、現金流損失、利潤、工資等。
創建 BIA 報告時,您必須考慮業務中涉及的關鍵流程、中斷對不同區域的影響、可接受的持續時間、可容忍的區域、財務成本等。
調用樹
呼叫樹是一個管理人員列表的過程,以便在緊急情況下呼叫。 這是一個遵循樹狀結構的過程。
例如,在災難期間,一個人會聯繫一小組成員並發送緊急信息,這些工作人員會分別呼叫每個小組。 這樣,所有員工都會在威脅期間得到通知,並開始他們分配的工作,以及時恢復每個功能和流程。 製作清單很簡單,但實時實施會造成混亂。
您必須執行定期呼叫活動,以使每個緊急工作人員做好保持警覺的準備。 定期測試還可以幫助識別可能嚴重影響性能的更改或丟失的數字。
呼叫樹包含在緊急情況下用於傳遞指令的信息。 它也可以手動完成,但人們使用自動化來加速流程並通知當今數字世界的成員。
指揮中心/控制中心
它是一個虛擬或物理設施,專門準備在危機期間提供對恢復計劃的指揮或控制。 它與團隊溝通以在災難期間管理系統和功能。
傳統上,基礎設施依賴於指揮中心處理危機而沒有任何適當的方法。 如今,組織已經完美地設計了他們的控制中心,這將即時響應轉變為核心競爭力。
一旦感知到災難,指揮中心就會迅速進入恢復階段。 此外,它還充當服務、新聞、交付等方面的報告點。 在這種情況下,它還將來自多個學科的人聚集在一起。
事件響應

事件響應是為應對攻擊而給出的一種響應。 它是在正確的程序和人員的幫助下完成的,以在正確的時間有效地保護網絡和數據安全。
如果組織在意外事件發生之前製定了事件計劃,則可以實時保護其數據免受威脅。 事件響應專家始終對問題保持警惕,並在事件發生時自然採取行動。 他們採取某些措施來避免安全漏洞,確保在災難恢復期間不跳過任何一步。
一開始,您必須確定關鍵數據並將其存儲在雲端或任何遠程位置以確保安全。 通過定期更新事件響應計劃來解決當前的基礎設施需求和不斷演變的網絡威脅。
備份
備份解決方案可幫助 IT 基礎架構維護數據副本並在正確的時間安全地存儲數據。 如果您面臨數據庫損壞、所有數據的意外刪除或任何其他問題,您必須準備好備份以立即恢復數據並繼續使用服務。

它涉及復製文件並將它們存儲在安全位置,以便在發生異常事件後輕鬆訪問所有數據。 如果您在多個位置備份數據以確保即使站點出現故障也可以恢復它,這將有所幫助。
彈力
社區、州、組織和個人在不影響服務和系統的情況下抵抗或抵禦災難的能力被稱為災難恢復力。
組織必須準備好承受因危險而產生的大量壓力。 確保您有能力通過更好的計劃來最大程度地減少損失,而不是等待有人來拯救您。 這將幫助您應對災難並有效地恢復您的 IT 基礎架構。
在這裡,主要目標是在必要時在正確的時間保存和恢復基本功能和結構。 要成為具有抗災能力的組織,您必須提前做好準備,並具備預測風險、適應變化、分享學習、整合各部門、管理風險等級的能力。
服務水平協議

服務水平協議 (SLA) 是一項災難計劃,您可以在其中向最終用戶提及在緊急情況下恢復服務所需的時間。
SLA 確保客戶的數據安全且不會洩露或與第三方共享。 它是與最終用戶問題的單點聯繫。
每個 IT 基礎架構都向其客戶提供有關 SLA 的保證。 因此,請確保事先與最終用戶進行溝通。
單點光纖
單點故障 (SPOF) 是連接到許多其他系統或應用程序的設備、個人、資源或應用程序。
如果這樣的設備或資源出現故障,連接到系統的所有重要部件都會隨之出現故障。 因此,整個流程和業務運營都會受到影響。
因此,您必須制定策略來處理此類問題,以保持您的組織正常運行。 您可以做的第一件事是確定可以產生更大影響的單個設備或系統。 接下來,運行業務影響分析並獲得風險評估分數,以了解即將發生的場景。 在事件發生前挖掘並找到它們。
列出所有 SPOF 後,根據恢復過程對它們進行分類。 將每個 SPOF 分為三個不同的類別:
- 以更少的時間和預算輕鬆直接地恢復。
- 恢復將是困難的,但可以開發一個可靠的過程來恢復。
- 一旦它下降,就無法採取任何措施來恢復。
您可以根據類別採取相應的行動。
系統恢復
在硬件故障期間,您必須運行恢復過程以將特定係統或服務器恢復為其原始形式。 要恢復整個系統,您需要準備好恢復要求、備份、固件兼容性和硬件兼容性。
系統恢復是將機器重置為其以前的設置或與新機器相同的狀態的過程。 這樣做將消除由於系統中安裝的軟件或應用程序而導致的所有病毒感染。
此過程包括 IT 基礎架構的恢復計劃,該基礎架構設置並遵循某些程序,以確保數據可用性免受人為或自然中斷的影響。
系統還原
系統還原是一種恢復工具,可讓您在正確的時間將某些文件和信息恢復到以前的狀態。
通過系統還原,您可以將註冊表項、已安裝的程序、驅動程序、系統文件等恢復到之前的版本。 這在許多災難中起到了救命稻草的作用。
測試計劃
它是指存儲有關測試策略、估計、資源、截止日期、目標和時間表的信息的文檔。 它作為運行測試以確保硬件和軟件安全的藍圖。
這包括根據計劃管理災難後果的程序和步驟進行的各種測試。 執行定期測試,以使您和您的組織做好準備,在行動過程中不要跳過一個步驟。 這樣,IT 基礎架構就可以了解缺點並為戰鬥做好準備。
結論
沒有人知道災難何時會發生。 因此,適當的安全和安保措施對每個企業都至關重要。
災難恢復術語將幫助您了解如何應對攻擊和災難。 它還將幫助您提前做好準備,以便在發生意外事件時保護您的基礎設施。 您將能夠創建有效的實時災難恢復策略來節省數百萬美元並保留客戶的信任。