
ทำความเข้าใจคำศัพท์การกู้คืนจากภัยพิบัติ – RTO, RPO, Failover, BCP และอื่นๆ
เผยแพร่แล้ว: 2022-03-20แผนการกู้คืนข้อมูลหลังภัยพิบัติเป็นมาตรการสำคัญที่องค์กรต้องมีก่อนเกิดเหตุการณ์ผิดปกติ
ในอุตสาหกรรมไอที เริ่มต้นด้วยการสร้างเอกสารอย่างเป็นทางการซึ่งประกอบด้วยแผน การดำเนินการ และขั้นตอนในการจัดการกับภัยพิบัติและผลกระทบที่ตามมา
ภัยพิบัติเป็นเหตุการณ์ที่เกิดขึ้นอย่างกะทันหันโดยไม่ต้องแจ้งให้ทราบล่วงหน้าและอาจเกิดได้หลายประเภท และเมื่อมันมาถึง บุคคลและองค์กรต้องเผชิญกับปัญหาหลายประเภท รวมถึงปัญหาทางการเงินและประสบการณ์ของผู้ใช้
หากมีการโจมตี คุณต้องพร้อมที่จะลดผลกระทบของมันและฟื้นฟูการทำงานของคุณให้เร็วขึ้น นี่คือที่ที่การเตรียมแผนการกู้คืนความเสียหายในทางปฏิบัติจะช่วยคุณระงับหรือป้องกันภัยพิบัติ คุณยังสามารถลดผลกระทบที่ตามมาในแง่ของประสบการณ์ผู้ใช้ ต้นทุน และเวลาหยุดทำงาน
นอกจากนี้ คุณต้องเตรียมแผน บุคลากร กลยุทธ์ อุปกรณ์ และระบบของคุณให้พร้อมเพื่อให้ทุกอย่างกลับมาดำเนินการได้ แต่สำหรับสิ่งนี้ คุณต้องเข้าใจการกู้คืนระบบในเชิงลึก
ในบทความนี้ ฉันจะพูดถึงรายละเอียดเกี่ยวกับเรื่องนี้พร้อมกับคำศัพท์การกู้คืนระบบหลัก เพื่อให้คุณสามารถต่อสู้อย่างกล้าหาญและแข็งแกร่งขึ้นในสภาวะที่ไม่เอื้ออำนวยดังกล่าว
เอาล่ะ!
ภัยพิบัติคืออะไร?

ภัยพิบัติเป็นเหตุการณ์ที่ไม่คาดฝันที่สามารถเกิดขึ้นได้ทุกที่ รวมทั้งอุตสาหกรรมไอที มันเกิดขึ้นโดยธรรมชาติหรือโดยคน และสามารถแทรกแซงการดำเนินงานของบริษัทและรบกวนโครงสร้างของโครงสร้างพื้นฐาน
ส่งผลให้องค์กรและลูกค้า ผู้ขาย พนักงาน และคู่ค้าได้รับผลกระทบ มันสร้างแรงกดดันต่อองค์กรในแง่ของการเงิน ชื่อเสียงของอุตสาหกรรม ความไว้วางใจของลูกค้า และขอบเขตความปลอดภัย
ดังนั้น คุณต้องพร้อมล่วงหน้าเพื่อเอาชนะสถานการณ์ดังกล่าว สำหรับสิ่งนี้ คุณต้องกู้คืนทุกการดำเนินการและข้อมูลทันที พูดง่ายๆ คือ คุณต้องเตรียมองค์กรของคุณเพื่อกู้คืนทุกอย่างในช่วงเวลาที่สั้นที่สุดสำหรับลูกค้าของคุณ
ภัยพิบัติมีหลายประเภท เช่น การโจมตีทางไซเบอร์ การก่อวินาศกรรม การโจมตีของผู้ก่อการร้าย แรนซัมแวร์หรือภัยคุกคามทางกายภาพ พายุเฮอริเคน แผ่นดินไหว ไฟไหม้ น้ำท่วม อุบัติเหตุทางอุตสาหกรรม ไฟฟ้าดับ และอื่นๆ อีกมากมาย
คุณหมายถึงอะไรโดยการกู้คืนจากภัยพิบัติ?
การกู้คืนจากภัยพิบัติเป็นกระบวนการของการกู้คืนการดำเนินงานตามปกติหลังจากประสบภัยพิบัติ มันเกี่ยวข้องกับการเข้าถึงฮาร์ดแวร์ ซอฟต์แวร์ อุปกรณ์ การเชื่อมต่อ เครือข่าย พลังงาน และข้อมูลอีกครั้ง คุณต้องตั้งกฎและขั้นตอนในกระบวนการจัดทำเอกสารเพื่อเตรียมองค์กรของคุณก่อนเกิดภัยพิบัติ
อย่างไรก็ตาม หากสิ่งอำนวยความสะดวกในองค์กรของคุณถูกทำลาย คุณต้องขยายกิจกรรมบางอย่างโดยการทำงานด้านการสื่อสาร การขนส่ง การจัดหา สถานที่ทำงาน และอื่นๆ
เหตุใดแผนกู้คืนจากภัยพิบัติจึงมีความสำคัญ
การร่างแผนที่สมบูรณ์แบบสำหรับการกู้คืนจากภัยพิบัติ ทั้งจากธรรมชาติหรือที่มนุษย์สร้างขึ้น เป็นสิ่งจำเป็นสำหรับอุตสาหกรรมไอทีทุกแห่ง ตรวจสอบให้แน่ใจว่าคุณมีพนักงานและเครื่องมือที่เหมาะสมในสถานที่ที่เหมาะสมเพื่อดำเนินการตามแผนได้อย่างราบรื่น
มาเจาะลึกกันว่าเหตุใดการกู้คืนจากภัยพิบัติจึงมีความสำคัญ
จำกัดความเสียหาย
ภัยพิบัติเป็นสิ่งที่คาดเดาไม่ได้ ไม่มีใครรู้ว่ามันมาและไปเมื่อไหร่ แต่คุณต้องเตรียมตัวล่วงหน้าเพื่อควบคุมความเสียหายที่เกิดกับโครงสร้างพื้นฐานของคุณ
ตัวอย่างเช่น ในพื้นที่เสี่ยงน้ำท่วม คุณสามารถวางเอกสารสำคัญและประเภทอุปกรณ์ที่ชั้นบนสุดเพื่อหลีกเลี่ยงความเสียหาย
ในทำนองเดียวกัน สำรองข้อมูลสำคัญของคุณก่อนที่การโจมตีทางไซเบอร์จะละเมิดข้อมูลหรือขโมยข้อมูลได้
บริการฟื้นฟู
หากคุณเตรียมแผนที่มั่นคงสำหรับการกู้คืนจากภัยพิบัติ การคืนค่าบริการทั้งหมดให้อยู่ในรูปแบบปกตินั้นทำได้ง่ายและรวดเร็ว หมายความว่าในช่วงเวลาสั้นๆ คุณสามารถกู้คืนสินทรัพย์และบริการหลักเกือบทั้งหมดได้
ลดการหยุดชะงัก
คุณไม่รู้หรอกว่าจะเกิดอะไรขึ้นในวันพรุ่งนี้หรือในขั้นตอนต่อไปของการดำเนินการ แต่ด้วยแผนการกู้คืนที่สมบูรณ์แบบ คุณไม่ต้องกังวลกับผลที่จะตามมามากนัก โครงสร้างพื้นฐานของคุณสามารถดำเนินการต่อไปได้โดยมีการหยุดชะงักน้อยที่สุด
การฝึกอบรมและการเตรียมการ

โครงสร้างพื้นฐานด้านไอทีประกอบด้วยพนักงานจำนวนมากที่ทำงานภายใต้หลังคา ทั้งหมดต้องทราบเกี่ยวกับการกู้คืนเพื่อดำเนินการทันทีตามความจำเป็นและคาดหวังในกรณีฉุกเฉิน
การเตรียมตัวอย่างเหมาะสมจะช่วยลดระดับความเครียดของทุกคนที่เกี่ยวข้องกับองค์กรของคุณ นอกจากนี้ คุณสามารถฝึกอบรมพนักงานของคุณให้ดำเนินการที่จำเป็นหากเกิดเหตุการณ์ที่ไม่คาดคิด
คำศัพท์การกู้คืนจากภัยพิบัติ
เริ่มต้นด้วยคำศัพท์เพื่อทำความเข้าใจการกู้คืนจากความเสียหายจากมุมมองที่ใกล้ชิดยิ่งขึ้น
RTO
Recovery Time Objective (RTO) คือระยะเวลาที่องค์กรกำหนดตามลักษณะของธุรกิจเพื่อทนต่อภัยพิบัติโดยไม่กระทบต่อการเติบโตทางการเงิน
ขณะตั้งค่า RTO บริษัทต้องตรวจสอบเวลาหยุดทำงานที่อาจส่งผลต่อองค์กรของคุณในหลายๆ ด้าน ใช้เพื่อศึกษากลยุทธ์ที่สามารถดำเนินการได้เพื่อดำเนินธุรกิจต่อไปแม้หลังจากเกิดภัยพิบัติ เมื่อลูกค้าเผชิญกับสิ่งรบกวนในแอปพลิเคชัน พวกเขาถามว่าจะใช้เวลานานแค่ไหนที่แอปจะกลับไปดำเนินการ คำตอบคือ RTO สำหรับทุกองค์กร
ตัวอย่าง: สมมติว่าคุณเป็นบริษัทที่ทำธุรกรรมออนไลน์ เช่น PayPal หรือ Pioneer ที่เผชิญกับเหตุการณ์ที่คาดเดาไม่ได้ ในกรณีนี้ RTO ของคุณจะเร็วพอที่จะกู้คืนการดำเนินการได้
กล่าวอีกนัยหนึ่ง บริษัทกำหนด RTO เป็นหนึ่งหรือสองชั่วโมงเพื่อหลีกเลี่ยงผลกระทบในรูปแบบของการเงินหรือข้อมูล
RPO
Recovery Point Objectives (RPO) คือการสูญเสียข้อมูลที่โครงสร้างพื้นฐานด้านไอทีสามารถจัดการได้ในแง่ของเวลาและปริมาณของข้อมูล
สับสน?
ยกตัวอย่างฐานข้อมูลที่บันทึกธุรกรรมของธนาคาร รวมถึงการโอนเงิน กำหนดเวลา การชำระเงิน และอื่นๆ เมื่อเกิดภัยพิบัติขึ้น ฐานข้อมูลจะถูกกู้คืนตามเวลาจริง ความแตกต่างระหว่างฐานข้อมูล ณ เวลาที่เกิดภัยพิบัติและการกู้คืนฐานข้อมูลหลังเกิดภัยพิบัติเป็นศูนย์ในกรณีนี้
สำหรับบางบริษัท อาจใช้เวลาประมาณ 24 ชั่วโมงในการกู้คืนข้อมูลทั้งหมดจากข้อมูลสำรอง แต่อาจเป็นหายนะในบางครั้ง จำเป็นต้องตั้งค่าโครงสร้างพื้นฐานของคุณตามข้อกำหนด RPO ซึ่งรวมถึงการเพิ่มความถี่ของการสำรองข้อมูล การเพิ่มฐานข้อมูลสแตนด์บายลงในสถาปัตยกรรมของคุณ และอื่นๆ
เฟลโอเวอร์
ลองนึกถึงสถานการณ์ที่คุณเดินทางไกล จู่ๆ คุณก็ยางแบนเพราะเหตุที่ไม่คาดคิด ขอขอบคุณยางอะไหล่ที่มีอยู่ในรถของคุณและเครื่องมือในการเปลี่ยนยางที่ชำรุด
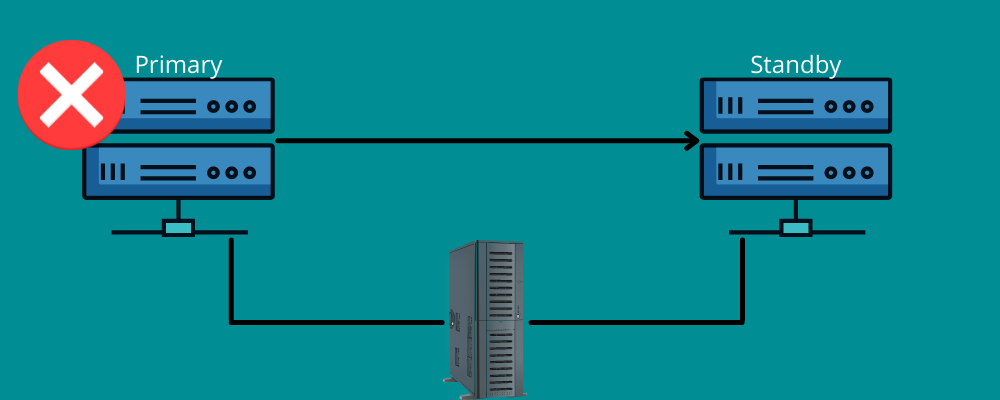
เฟลโอเวอร์ทำงานในลักษณะเดียวกัน
หมายความว่าคุณต้องมีการเชื่อมต่อสำรองระหว่างเกิดภัยพิบัติ โดยสรุป เฟลโอเวอร์หมายถึงการมีเครือข่ายและระบบที่คุณสามารถใช้ได้ในขณะที่เกิดภัยพิบัติเพื่อเปลี่ยนข้อมูลของคุณเป็นระบบการกู้คืน
เฟลโอเวอร์ช่วยให้แน่ใจว่าบริการทั้งหมดของคุณทำงานได้อย่างราบรื่น แม้ว่าจะมีความล้มเหลวในโครงสร้างพื้นฐานหรือฮาร์ดแวร์ก็ตาม ด้วยวิธีนี้ คุณสามารถป้องกันไม่ให้องค์กรของคุณสูญเสียข้อมูลและรายได้ และหลีกเลี่ยงการหยุดชะงักของบริการสำหรับผู้ใช้ปลายทางของคุณ
คุณสามารถตั้งค่าด้วยตนเองหรืออนุญาตให้ทำงานโดยอัตโนมัติเพื่อย้ายข้อมูลไปยังเซิร์ฟเวอร์สแตนด์บาย
Failback
IT failback เป็นการดำเนินการง่ายๆ โดยที่การผลิตดั้งเดิมจะกลับไปยังตำแหน่งเดิม (ระบบ) หลังจากจัดการกับภัยพิบัติ ในระหว่างการโจมตี บริษัทต่างๆ ปฏิบัติตามการดำเนินการเฟลโอเวอร์ เนื่องจากปริมาณงานทั้งหมดถ่ายโอนไปยังแบบจำลอง VM หรือระบบสำรองข้อมูล
อย่างไรก็ตาม คุณไม่สามารถข้ามขั้นตอนถัดไปของการกลับมาได้ เมื่อคุณกู้คืนทุกอย่างและกลับมาดำเนินการได้ คุณจะต้องโอนปริมาณงานทั้งหมดไปยัง VM หรือระบบเดิม กระบวนการโดยรวมในการส่งคืนปริมาณงานไปยังสถานที่ทำงานหรือระบบเดิมเรียกว่าการย้อนกลับ หมายความว่าคุณกำลัง "กลับมา" หลังจากการโจมตี
Failback ยังใช้สำหรับการบำรุงรักษาตามกำหนดเวลาขององค์กร เป็นความจริงที่ความล้มเหลวมักเกิดขึ้นหลังจากเกิดข้อผิดพลาด กล่าวอีกนัยหนึ่งเฟลโอเวอร์เป็นขั้นตอนแรก และความล้มเหลวเป็นขั้นตอนที่สองในการกู้คืนข้อมูลที่จำเป็น สามารถตั้งค่าได้ระหว่างระบบคลาวด์กับระบบคลาวด์ จากภายในองค์กรถึงภายในองค์กร จากภายในองค์กรไปยังระบบคลาวด์ หรือชุดค่าผสมใดๆ จากสิ่งเหล่านี้
DR
Disaster Recovery (DR) เป็นกระบวนการที่คุณมีแผนสร้างไว้ล่วงหน้าเพื่อกู้คืนทรัพย์สินของคุณภายในกรอบเวลา
DR ช่วยให้องค์กรสามารถตอบสนองได้อย่างรวดเร็วและกู้คืนทุกบริการจากเหตุการณ์ที่ไม่คาดคิด นอกจากนี้ยังให้เอกสารที่เป็นทางการซึ่งมีคำแนะนำในการดำเนินการทันทีในกรณีที่เกิดเหตุการณ์ไม่คาดฝัน
BCP
แผนความต่อเนื่องทางธุรกิจ (BCP) เป็นหนึ่งในแผนการกู้คืนความเสียหายที่ยอมรับได้มากที่สุด ซึ่งช่วยให้โครงสร้างพื้นฐานด้านไอทีสร้างกลยุทธ์เพื่อจัดการกับการหยุดชะงักของไอทีในเซิร์ฟเวอร์ อุปกรณ์เคลื่อนที่ คอมพิวเตอร์ส่วนบุคคล และเครือข่าย
BCP แตกต่างจากการกู้คืนจากความเสียหายเล็กน้อย เนื่องจากช่วยให้องค์กรวางแผนสร้างซอฟต์แวร์ระดับองค์กรและผลิตภาพใหม่เพื่อตอบสนองความต้องการทางธุรกิจที่สำคัญ
ที่นี่ บริษัทสร้างระบบการกู้คืนเพื่อเอาชนะภัยคุกคามที่อาจเกิดขึ้น เช่น การโจมตีทางไซเบอร์หรือภัยธรรมชาติ ออกแบบมาเพื่อรักษาความปลอดภัยทรัพย์สินและให้บริการทั้งหมดกลับมาใช้งานได้อย่างรวดเร็วหลังจากการประท้วง

BCM

การจัดการความต่อเนื่องทางธุรกิจ (BCM) เป็นกระบวนการจัดการความเสี่ยงที่ออกแบบมาเป็นพิเศษเพื่อทำหน้าที่เป็นเกราะป้องกันกระบวนการทางธุรกิจ BCM เป็นขั้นตอนต่อไปของ BCP ซึ่งจะตรวจสอบแผนการกู้คืนเพื่อให้แน่ใจว่าทุกคนในธุรกิจตอบสนองต่อแผนทันทีและกู้คืนสิ่งสำคัญทั้งหมด
BCM ทำหน้าที่เป็นกรอบการจัดการเพื่อระบุความเสี่ยงด้านโครงสร้างพื้นฐานเมื่อเผชิญกับภัยคุกคามภายนอกและ/หรือภายใน นอกจากนี้ยังช่วยให้มั่นใจได้ว่ากรอบงานทำงานอย่างมีประสิทธิภาพด้วยความช่วยเหลือของการทดสอบเป็นประจำเพื่อเพิ่มความสามารถในการคาดการณ์ ลดความเสี่ยง และปรับแผนสำหรับการโจมตีในอนาคต
BIA
การวิเคราะห์ผลกระทบทางธุรกิจ (BIA) เป็นกระบวนการของการวิเคราะห์อัตราการอยู่รอดของธุรกิจโดยการระบุระบบ การดำเนินงาน และกระบวนการที่สำคัญ มันบอกเกี่ยวกับผลกระทบของภัยพิบัติในองค์กรของคุณเนื่องจากการหยุดชะงักในการดำเนินงานของคุณ
BIA คาดการณ์ผลที่ตามมาก่อนที่การโจมตีจะเกิดขึ้นจริง เพื่อรวบรวมข้อมูลสำคัญที่สามารถช่วยสร้างกลยุทธ์การกู้คืนที่มีประสิทธิภาพ นอกจากนี้ยังระบุต้นทุนที่เกี่ยวข้องเนื่องจากความล้มเหลว เช่น ต้นทุนการเปลี่ยนอุปกรณ์ การสูญเสียกระแสเงินสด กำไร เงินเดือน และอื่นๆ
เมื่อสร้างรายงาน BIA คุณต้องพิจารณากระบวนการที่สำคัญที่เกี่ยวข้องกับธุรกิจของคุณ ผลกระทบของการหยุดชะงักในพื้นที่ต่างๆ ระยะเวลาที่ยอมรับได้ พื้นที่ที่ยอมรับได้ ต้นทุนทางการเงิน และอื่นๆ
โทรต้นไม้
โครงสร้างการโทรเป็นกระบวนการในการรวบรวมรายชื่อพนักงานที่จะโทรออกในกรณีฉุกเฉิน เป็นขั้นตอนที่ทำตามโครงสร้างเหมือนต้นไม้
ตัวอย่างเช่น ระหว่างเกิดภัยพิบัติ บุคคลหนึ่งจะติดต่อกับสมาชิกกลุ่มเล็กๆ ด้วยข้อความด่วน เจ้าหน้าที่เหล่านั้นจะเรียกแต่ละกลุ่มแยกกัน ด้วยวิธีนี้ พนักงานทุกคนจะได้รับแจ้งในระหว่างการคุกคามและเริ่มงานที่ได้รับมอบหมายเพื่อกู้คืนทุกหน้าที่และกระบวนการในเวลา การทำรายการเป็นเรื่องง่าย แต่การใช้งานตามเวลาจริงจะสร้างความสับสน
คุณต้องทำกิจกรรมการโทรเป็นประจำเพื่อเตรียมเจ้าหน้าที่ฉุกเฉินทุกคนให้ตื่นตัว การทดสอบเป็นประจำยังช่วยระบุตัวเลขที่เปลี่ยนแปลงหรือขาดหายไปซึ่งอาจส่งผลกระทบอย่างรุนแรงต่อประสิทธิภาพการทำงาน
โครงสร้างการโทรประกอบด้วยข้อมูลที่จะใช้ในกรณีฉุกเฉินเพื่อให้คำแนะนำ สามารถทำได้ด้วยตนเอง แต่ผู้คนใช้ระบบอัตโนมัติเพื่อเร่งกระบวนการและแจ้งสมาชิกในโลกดิจิทัลในปัจจุบัน
ศูนย์บัญชาการ/ศูนย์ควบคุม
เป็นสถานที่เสมือนหรือทางกายภาพที่เตรียมไว้เป็นพิเศษเพื่อให้คำสั่งหรือการควบคุมแผนการกู้คืนในช่วงวิกฤต สื่อสารกับทีมเพื่อจัดการระบบและการทำงานระหว่างเกิดภัยพิบัติ
ตามเนื้อผ้า โครงสร้างพื้นฐานขึ้นอยู่กับศูนย์บัญชาการที่จัดการกับวิกฤตโดยไม่มีวิธีการที่เหมาะสม ในปัจจุบัน องค์กรต่างๆ ได้ออกแบบศูนย์ควบคุมของตนได้อย่างสมบูรณ์แบบ ซึ่งจะเปลี่ยนการตอบสนองในทันทีสู่ความสามารถหลัก
เมื่อรับรู้ถึงภัยพิบัติ ศูนย์บัญชาการจะเร่งไปสู่ขั้นตอนการกู้คืนอย่างรวดเร็ว นอกจากนี้ยังทำหน้าที่เป็นจุดรายงานในกรณีของการบริการ สื่อ การส่งมอบ และอื่นๆ นอกจากนี้ยังนำผู้คนจากหลากหลายสาขาวิชามารวมกันในสถานการณ์ดังกล่าว
การตอบสนองต่อเหตุการณ์

การตอบสนองต่อเหตุการณ์เป็นการตอบสนองประเภทหนึ่งเพื่อจัดการกับการโจมตี โดยใช้ขั้นตอนและบุคลากรที่เหมาะสมในการรักษาความปลอดภัยของเครือข่ายและข้อมูลอย่างมีประสิทธิภาพในเวลาที่เหมาะสม
หากองค์กรมีแผนเหตุการณ์ก่อนเกิดเหตุการณ์ที่ไม่คาดคิด ก็สามารถรักษาความปลอดภัยข้อมูลจากภัยคุกคามในแบบเรียลไทม์ ผู้เชี่ยวชาญด้านการตอบสนองเหตุการณ์มักจะตื่นตัวต่อปัญหาและดำเนินการอย่างเป็นธรรมชาติในระหว่างเหตุการณ์ พวกเขาใช้มาตรการบางอย่างเพื่อหลีกเลี่ยงการละเมิดความปลอดภัย เพื่อให้แน่ใจว่าจะไม่ข้ามขั้นตอนเดียวระหว่างการกู้คืนจากภัยพิบัติ
ในการเริ่มต้น คุณต้องกำหนดข้อมูลสำคัญและจัดเก็บไว้ในระบบคลาวด์หรือตำแหน่งระยะไกลใดๆ เพื่อความปลอดภัย จัดการกับความต้องการด้านโครงสร้างพื้นฐานในปัจจุบันและการพัฒนาภัยคุกคามทางไซเบอร์โดยอัพเดทแผนการตอบสนองต่อเหตุการณ์อย่างสม่ำเสมอ
สำรอง
โซลูชันการสำรองข้อมูลช่วยโครงสร้างพื้นฐานด้านไอทีในการเก็บรักษาสำเนาข้อมูลและจัดเก็บอย่างปลอดภัยในเวลาที่เหมาะสม หากคุณเผชิญกับความเสียหายของฐานข้อมูล การลบข้อมูลทั้งหมดโดยไม่ได้ตั้งใจ หรือปัญหาอื่นๆ คุณต้องเตรียมพร้อมกับการสำรองข้อมูลเพื่อกู้คืนข้อมูลในทันทีและดำเนินการกับบริการต่อไป

มันเกี่ยวข้องกับการจำลองไฟล์และเก็บไว้ในตำแหน่งที่ปลอดภัยเพื่อเข้าถึงข้อมูลทั้งหมดได้อย่างง่ายดายหลังจากเหตุการณ์ผิดปกติ จะช่วยได้หากคุณสำรองข้อมูลในหลายตำแหน่งเพื่อให้แน่ใจว่าคุณสามารถกู้คืนได้แม้ว่าไซต์จะล้มเหลว
ความยืดหยุ่น
ความสามารถของชุมชน รัฐ องค์กร และบุคคลในการต่อต้านหรือทนต่อภัยพิบัติโดยไม่กระทบต่อบริการและระบบนั้นเรียกว่าความยืดหยุ่นจากภัยพิบัติ
องค์กรต้องเตรียมพร้อมที่จะระงับความเครียดจำนวนมากอันเนื่องมาจากอันตราย ตรวจสอบให้แน่ใจว่าคุณมีความสามารถในการลดการสูญเสียของคุณด้วยการวางแผนที่ดีขึ้นแทนที่จะรอให้ใครมาช่วยเหลือคุณ ซึ่งจะช่วยให้คุณรับมือกับภัยพิบัติและกู้คืนโครงสร้างพื้นฐานด้านไอทีของคุณได้อย่างมีประสิทธิภาพ
ที่นี่ เป้าหมายหลักคือการรักษาและฟื้นฟูหน้าที่และโครงสร้างที่จำเป็นในเวลาที่เหมาะสมเมื่อจำเป็น ในการเป็นองค์กรที่รับมือกับภัยพิบัติได้ คุณต้องเตรียมการล่วงหน้าและมีความสามารถในการคาดการณ์ความเสี่ยง ปรับให้เข้ากับการเปลี่ยนแปลง แบ่งปันและเรียนรู้ บูรณาการภาคส่วนต่างๆ และจัดการระดับความเสี่ยง
SLA

ข้อตกลงระดับบริการ (SLA) คือแผนภัยพิบัติที่คุณพูดถึงผู้ใช้ปลายทางเกี่ยวกับเวลาที่คุณอาจใช้เพื่อกู้คืนบริการในกรณีฉุกเฉิน
SLA ช่วยให้ลูกค้ามั่นใจได้ว่าข้อมูลของพวกเขาจะปลอดภัยและไม่ถูกบุกรุกหรือแบ่งปันกับบุคคลที่สาม เป็นจุดเดียวในการติดต่อกับปัญหาของผู้ใช้ปลายทาง
โครงสร้างพื้นฐานด้านไอทีทุกชิ้นให้การรับรองเกี่ยวกับ SLA แก่ลูกค้า ดังนั้น ตรวจสอบให้แน่ใจว่าคุณได้สื่อสารกับผู้ใช้ปลายทางของคุณล่วงหน้า
SPOF
จุดเดียวของความล้มเหลว (SPOF) คือชิ้นส่วนของอุปกรณ์ บุคคล ทรัพยากร หรือแอปพลิเคชันที่เชื่อมต่อกับระบบหรือแอปพลิเคชันอื่นๆ มากมาย
หากอุปกรณ์หรือทรัพยากรดังกล่าวหยุดทำงาน ส่วนประกอบสำคัญทั้งหมดที่เชื่อมต่อกับระบบก็จะลดลงไปด้วย ดังนั้นกระบวนการทั้งหมดและการดำเนินธุรกิจจะได้รับผลกระทบ
ดังนั้น คุณต้องมีกลยุทธ์ในการจัดการกับปัญหาดังกล่าวเพื่อให้องค์กรของคุณทำงานต่อไป สิ่งแรกที่คุณทำได้คือระบุอุปกรณ์หรือระบบชิ้นเดียวที่อาจส่งผลกระทบได้มากกว่า ถัดไป เรียกใช้การวิเคราะห์ผลกระทบทางธุรกิจและรับคะแนนการประเมินความเสี่ยงเพื่อรับทราบเหตุการณ์ที่จะเกิดขึ้น ขุดค้นเจอก่อนถึงงาน
เมื่อคุณระบุ SPOF ทั้งหมดแล้ว ให้จัดประเภทตามกระบวนการกู้คืน จัด SPOF แต่ละรายการในสามประเภทที่แตกต่างกัน:
- กู้คืนได้ง่ายและตรงเวลาโดยใช้เวลาและงบประมาณน้อยลง
- การกู้คืนจะเป็นเรื่องยาก แต่กระบวนการที่เชื่อถือได้สามารถพัฒนาเพื่อกู้คืนได้
- ไม่มีอะไรสามารถทำได้เพื่อกู้คืนเมื่อมันลงไป
คุณสามารถดำเนินการตามหมวดหมู่ได้
การกู้คืนระบบ
ระหว่างความล้มเหลวของฮาร์ดแวร์ คุณต้องเรียกใช้กระบวนการกู้คืนเพื่อเรียกข้อมูลระบบหรือเซิร์ฟเวอร์นั้น ๆ กลับคืนสู่รูปแบบเดิม และในการกู้คืนระบบทั้งหมด คุณจะต้องพร้อมสำหรับข้อกำหนดในการกู้คืน การสำรองข้อมูล ความเข้ากันได้ของเฟิร์มแวร์ และความเข้ากันได้ของฮาร์ดแวร์
การกู้คืนระบบเป็นกระบวนการที่รีเซ็ตเครื่องเป็นการตั้งค่าก่อนหน้าหรือสถานะเดียวกับเมื่อเป็นเครื่องใหม่ การทำเช่นนี้จะล้างการติดไวรัสทั้งหมดเนื่องจากซอฟต์แวร์หรือแอปพลิเคชันที่ติดตั้งในระบบของคุณ
กระบวนการนี้รวมถึงการวางแผนการกู้คืนโครงสร้างพื้นฐานด้านไอทีซึ่งกำหนดและปฏิบัติตามขั้นตอนบางอย่างเพื่อให้แน่ใจว่ามีข้อมูลพร้อมใช้งานจากการหยุดชะงักที่มนุษย์สร้างขึ้นหรือการหยุดชะงักตามธรรมชาติ
ระบบการเรียกคืน
การคืนค่าระบบเป็นเครื่องมือการกู้คืนที่ให้คุณกู้คืนไฟล์และข้อมูลบางอย่างกลับเป็นสถานะก่อนหน้าในเวลาที่เหมาะสม
ด้วยการคืนค่าระบบ คุณสามารถกู้คืนรีจิสตรีคีย์ โปรแกรมที่ติดตั้ง ไดรเวอร์ ไฟล์ระบบ และอื่นๆ กลับเป็นเวอร์ชันก่อนหน้าได้ ซึ่งทำหน้าที่เป็นเครื่องช่วยชีวิตในภัยพิบัติต่างๆ
แผนการทดสอบ
หมายถึงเอกสารที่เก็บข้อมูลเกี่ยวกับกลยุทธ์การทดสอบ การประมาณค่า ทรัพยากร วันครบกำหนด วัตถุประสงค์ และกำหนดการ ทำงานเป็นพิมพ์เขียวที่ทำการทดสอบเพื่อความปลอดภัยของฮาร์ดแวร์และซอฟต์แวร์
ซึ่งรวมถึงการทดสอบต่างๆ ตามขั้นตอนและขั้นตอนที่วางแผนไว้เพื่อจัดการผลกระทบหลังภัยพิบัติ ทำแบบทดสอบปกติเพื่อเตรียมตัวคุณเองและองค์กรของคุณไม่ให้ข้ามขั้นตอนเดียวระหว่างการดำเนินการ ด้วยวิธีนี้ โครงสร้างพื้นฐานด้านไอทีสามารถเข้าใจข้อบกพร่องและพร้อมสำหรับการต่อสู้
บทสรุป
ไม่มีใครรู้ว่าภัยพิบัติจะเกิดขึ้นเมื่อใด ดังนั้นมาตรการด้านความปลอดภัยและความมั่นคงจึงเป็นสิ่งจำเป็นสำหรับทุกธุรกิจ
คำศัพท์การกู้คืนข้อมูลหลังภัยพิบัติจะช่วยให้คุณเข้าใจวิธีตอบสนองต่อการโจมตีและภัยพิบัติ นอกจากนี้ยังช่วยให้คุณเตรียมการล่วงหน้าเพื่อให้คุณสามารถปกป้องโครงสร้างพื้นฐานของคุณในระหว่างเหตุการณ์ที่ไม่คาดคิด คุณจะสามารถสร้างกลยุทธ์การกู้คืนความเสียหายแบบเรียลไทม์ที่มีประสิทธิภาพเพื่อประหยัดเงินได้หลายล้านดอลลาร์และระงับความไว้วางใจจากลูกค้า