
ディザスタリカバリの用語を理解する– RTO、RPO、フェイルオーバー、BCPなど
公開: 2022-03-20災害復旧計画は、異常なイベントが発生する前に組織が持っていなければならない最も重要な手段です。
IT業界では、災害とその後遺症に対処するための計画、アクション、および手順を含む正式なドキュメントを作成することから始めます。
災害は、事前の通知なしに突然発生するイベントであり、さまざまなタイプの可能性があります。 そして、それが着陸すると、個人や組織は、経済的な問題やユーザーエクスペリエンスなど、さまざまな困難に直面します。
攻撃が発生した場合は、その影響を最小限に抑え、操作をより迅速に復元する準備ができている必要があります。 これは、実用的な災害復旧計画を作成することが、災害を差し控えたり防止したりするのに役立つ場所です。 また、ユーザーエクスペリエンス、コスト、およびダウンタイムの観点から、後遺症を減らすことができます。
さらに、すべてを実行に戻すために、計画、人員、戦略、機器、およびシステムを準備しておく必要があります。 ただし、このためには、ディザスタリカバリを深く理解する必要があります。
この記事では、このような悪条件で勇敢に反撃し、より強くなることができるように、主要な災害復旧の用語とともにこれについて詳しく説明します。
さぁ、始めよう!
災害とは何ですか?

災害は、IT業界を含め、どこでも発生する可能性のある予期しないイベントです。 これは自然に発生するか、人によって発生し、企業の運営を妨害し、インフラストラクチャの構造を乱す可能性があります。
その結果、組織とその顧客、ベンダー、従業員、およびパートナーが影響を受けます。 それは、財務、業界の評判、顧客の信頼、およびセキュリティ境界の観点から組織に圧力をかけます。
したがって、そのようなシナリオを克服するために事前に準備する必要があります。 このためには、すべての操作とデータを即座に回復する必要があります。 簡単に言うと、顧客が可能な限り短い間隔ですべてを回復できるように組織を準備する必要があります。
災害には、サイバー攻撃、妨害行為、テロ攻撃、ランサムウェアや物理的な脅威、ハリケーン、地震、火災、洪水、産業事故、停電など、さまざまな種類があります。
ディザスタリカバリとはどういう意味ですか?
災害復旧は、災害に見舞われた後、通常の運用を回復するプロセスです。 これには、ハードウェア、ソフトウェア、機器、接続、ネットワーキング、電源、およびデータへのアクセスの再開が含まれます。 災害前に組織を準備するには、文書化されたプロセスでルールと手順を設定する必要があります。
ただし、組織の施設が破壊された場合は、通信、輸送、調達、作業場所などに取り組むことによって、一部の活動を拡張する必要があります。
災害復旧計画が重要なのはなぜですか?
自然災害または人為的災害のいずれかから回復するための完璧な計画を作成することは、すべてのIT業界にとって不可欠です。 計画を円滑に実行するために、適切な場所に適切な従業員とツールがあることを確認してください。
災害復旧が重要である理由をさらに深く掘り下げましょう。
損害賠償を制限する
災害は予測できません。 それがいつ来て行くのか誰も知りません。 ただし、インフラストラクチャに発生する損傷を制御するために事前に準備します。
たとえば、洪水が発生しやすい地域では、損傷を避けるために、重要な書類や機器の種類を最上階に置くことができます。
同様に、サイバー攻撃がデータを侵害したり盗んだりする前に、重要なデータをバックアップしてください。
サービスの復元
災害からの復旧のためのしっかりした計画を立てれば、すべてのサービスを通常の形にすばやく簡単に復元できます。 これは、短い時間間隔で、ほとんどすべての主要な資産とサービスを回復できることを意味します。
中断を最小限に抑える
明日や手術の次のステップで何が起こるかを知ることはできません。 しかし、完璧な復旧計画があれば、結果についてあまり心配する必要はありません。 インフラストラクチャは、最小限の中断で運用を継続できます。
トレーニングと準備

ITインフラストラクチャは、屋根の下で働く多くの従業員で構成されています。 緊急時に必要かつ予想されるとおりに即座に行動するためには、すべての人が回復について知っている必要があります。
適切な準備はまたあなたの組織に関係するすべての人のストレスレベルを下げるでしょう。 さらに、予期しないイベントが発生した場合に必要なアクションを実行するように従業員をトレーニングできます。
災害復旧の用語
ディザスタリカバリをより詳細に理解するための用語から始めましょう。
RTO
目標復旧時間(RTO)は、組織がビジネスの性質に応じて、財務の成長に影響を与えることなく災害に耐えるために設定する時間です。
RTOを設定する際、企業は組織にさまざまな影響を与える可能性のあるダウンタイムを確認する必要があります。 災害後も事業を継続するための実行可能な戦略を研究するために使用されます。 お客様がアプリケーションで障害に直面した場合、アプリがアクションに戻るまでにどのくらいの時間がかかるかを尋ねます。 答えは、すべての組織のRTOです。
例:あなたがPayPalやPioneerのような予測できない出来事に直面しているオンライン取引会社であると仮定します。 この場合、RTOは操作を回復するのに十分な速さです。
言い換えれば、企業は、財務またはデータの形での結果を回避するために、RTOを1時間または2時間に設定します。
RPO
目標復旧時点(RPO)は、ITインフラストラクチャが時間と情報量の観点から処理できるデータ損失です。
紛らわしい?
送金、スケジュール設定、支払いなど、銀行の取引を記録するデータベースの例を見てみましょう。 災害が発生すると、データベースはリアルタイムで復旧されます。 この場合、災害時のデータベースと災害後のデータベース回復の差はゼロです。
一部の企業では、バックアップからすべての情報を回復するのに約24時間かかることが許容されますが、場合によっては壊滅的となる可能性があります。 RPO要件に従ってインフラストラクチャを設定することが不可欠です。 これには、バックアップの頻度の向上、アーキテクチャへのスタンバイデータベースの追加などが含まれます。
フェイルオーバー
あなたが長距離を旅行している状況を考えてみてください。 突然、思いがけない理由でパンクした。 あなたはあなたの車で利用可能なスペアタイヤと欠陥のあるタイヤを交換するための道具に感謝します。
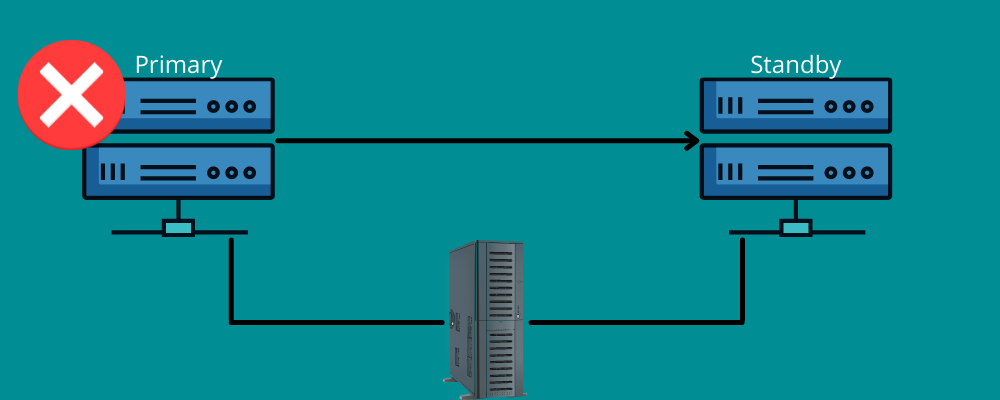
フェイルオーバーも同じように機能します。
これは、災害時にバックアップ接続が必要であることを意味します。 簡単に言うと、フェイルオーバーとは、災害時に情報を復旧システムに切り替えるために使用できるネットワークとシステムを用意することを意味します。
フェイルオーバーにより、インフラストラクチャやハードウェアに障害が発生した場合でも、すべてのサービスがスムーズに実行されます。 このようにして、組織がデータと収益を失うのを防ぎ、エンドユーザーのサービスの中断を回避できます。
手動で設定するか、自動的に機能させてデータをスタンバイサーバーに移動することができます。
フェイルバック
ITフェイルバックは、災害が処理された後、元の本番環境が元の場所(システム)に戻るという単純な操作です。 攻撃中、企業はフェイルオーバー操作に従います。これにより、すべてのワークロードがVMレプリカまたはバックアップシステムに転送されます。
ただし、戻るという次のステップをスキップすることはできません。 すべてを回復してアクションに戻るときは、すべてのワークロードを元のVMまたはシステムに転送する必要があります。 ワークロードを元のワークプレースまたはシステムに戻すこの全体的なプロセスは、フェイルバックと呼ばれます。 これは、攻撃後に「戻ってくる」ことを意味します。
フェイルバックは、企業のスケジュールされたメンテナンスにも使用されます。 フェイルバックは常にフェイルオーバー後に発生することは事実です。 つまり、フェイルオーバーは最初のステップであり、フェイルバックは重要なデータを回復するための2番目のステップです。 クラウドからクラウド、オンプレミスからオンプレミス、オンプレミスからクラウド、またはこれらの任意の組み合わせの間に設定できます。
DR
ディザスタリカバリ(DR)は、時間枠内に資産をリカバリするための計画を事前に作成したプロセスです。
DRは、組織が迅速に対応し、予期しないイベントからすべてのサービスを回復する機能を提供します。 また、予期しないインシデントが発生した場合に即座に対応するための指示を含む正式なドキュメントも提供します。
BCP
事業継続計画(BCP)は、ITインフラストラクチャがサーバー、モバイルデバイス、パーソナルコンピューター、およびネットワークへのITの中断に対処するための戦略を立てることを可能にする、最も受け入れられるディザスタリカバリ計画の1つです。

BCPは、組織が主要なビジネスニーズを満たすためにエンタープライズソフトウェアと生産性を再確立する計画を立てるのに役立つため、ディザスタリカバリとは少し異なります。
ここでは、企業はサイバー攻撃や自然災害などの潜在的な脅威を克服するための復旧システムを作成します。 資産を確保し、ストライキ後すぐにすべてのサービスが再開されるように設計されています。
BCM

ビジネス継続性管理(BCM)は、ビジネスプロセスへの脅威に対するシールドとして機能するように特別に設計されたリスク管理プロセスです。 BCMはBCPの次のステップであり、復旧計画を検証して、ビジネスの全員が計画に即座に対応し、すべての重要なものを復旧することを確認します。
BCMは、外部および/または内部の脅威に直面したときにインフラストラクチャのリスクを特定するための管理フレームワークとして機能します。 また、フレームワークが定期的なテストの助けを借りて効率的に機能し、予測可能性を高め、リスクを軽減し、将来の攻撃の計画を調整することを保証します。
BIA
ビジネスインパクト分析(BIA)は、重要なシステム、運用、およびプロセスを特定することにより、ビジネスの生存率を分析するプロセスです。 業務の中断による組織への災害の影響について説明します。
BIAは、強力な回復戦略の作成に役立つ重要な情報を収集するために、攻撃が実際に発生する前に結果を予測します。 また、機器の交換コスト、キャッシュフローの損失、利益、給与など、障害に関連するコストも特定します。
BIAレポートを作成するときは、ビジネスに関連する重要なプロセス、さまざまな領域への混乱の影響、許容可能な期間、許容可能な領域、財務コストなどを考慮する必要があります。
ツリーを呼び出す
コールツリーは、緊急時に呼び出すスタッフのリストをキュレートするプロセスです。 これは、ツリーのような構造に従う手順です。
たとえば、災害時には、1人の人が緊急のメッセージで小さなグループのメンバーに連絡し、それらのスタッフは各グループに個別に電話をかけます。 このようにして、すべてのスタッフは脅威の間に通知を受け、割り当てられた仕事を開始して、すべての機能とプロセスを時間内に回復します。 リストの作成は簡単ですが、リアルタイムで実装すると混乱が生じます。
すべての緊急スタッフが警戒を怠らないように準備するために、定期的な電話活動を実行する必要があります。 定期的なテストは、パフォーマンスに深刻な影響を与える可能性のある変更された番号や欠落している番号を特定するのにも役立ちます。
コールツリーには、緊急時に指示を出すために使用される情報が含まれています。 手動で行うこともできますが、人々は自動化を使用してプロセスを加速し、今日のデジタル世界のメンバーに通知します。
コマンドセンター/コントロールセンター
これは、危機の際の復旧計画を指揮または制御するために特別に準備された仮想または物理的な施設です。 チームと通信して、災害時のシステムと機能を管理します。
従来、インフラストラクチャは、適切なアプローチなしで危機に対処するコマンドセンターに依存しています。 今日、組織はコントロールセンターを完璧に設計しており、コアコンピテンシーへの即時対応を可能にしています。
災害を検知すると、コマンドセンターは急速に復旧フェーズに向かいます。 さらに、サービス、プレス、配送などの場合のレポートポイントとしても機能します。 また、そのようなシナリオでは、複数の分野の人々が集まります。
インシデント対応

インシデントレスポンスは、攻撃に対処するために与えられる一種のレスポンスです。 これは、適切な手順と担当者の助けを借りて行われ、ネットワークとデータのセキュリティを適切なタイミングで効果的に維持します。
組織が予期しないイベントの前にインシデント計画を立てている場合、組織はリアルタイムで脅威からデータを保護できます。 インシデント対応スペシャリストは、常に問題に注意を払い、インシデント中に自然に行動します。 彼らはセキュリティ違反を回避するために特定の対策を講じており、災害復旧中に1つのステップをスキップしないようにしています。
最初に、重要なデータを特定し、安全を確保するためにクラウドまたはリモートの場所に保存する必要があります。 インシデント対応計画を定期的に更新することにより、現在のインフラストラクチャのニーズと進化するサイバー脅威に対処します。
バックアップ
バックアップソリューションは、ITインフラストラクチャがデータのコピーを維持し、適切なタイミングで安全に保存するのに役立ちます。 データベースの破損、すべてのデータの誤った削除、またはその他の問題に直面した場合は、データを即座に復元してサービスを継続するために、バックアップの準備ができている必要があります。

これには、ファイルを複製して安全な場所に保存し、異常なイベントの後にすべてのデータに簡単にアクセスできるようにすることが含まれます。 複数の場所にデータをバックアップして、サイトに障害が発生した場合でもデータを確実に復元できるようにする場合に役立ちます。
レジリエンス
コミュニティ、州、組織、および個人が、サービスやシステムを損なうことなく災害に抵抗または耐える能力は、災害回復力として知られています。
組織は、危険による大量のストレスに耐えられるように準備する必要があります。 誰かが来てあなたを救助するのを待つのではなく、より良い計画で損失を最小限に抑える能力があることを確認してください。 これにより、災害に対応し、ITインフラストラクチャを効率的に復旧できます。
ここでの主な目標は、必要なときに必要なときに重要な機能と構造を保存および復元することです。 災害に強い組織になるには、事前に準備し、リスクを予測し、変化に適応し、共有して学習し、さまざまなセクターを統合し、リスクレベルを管理する能力を備えている必要があります。
SLA

サービスレベルアグリーメント(SLA)は、緊急時にサービスを復元するためにかかる可能性のある時間をエンドユーザーに通知する災害計画です。
SLAは、データが安全であり、侵害されたり、サードパーティと共有されたりしないことを顧客に保証します。 これは、エンドユーザーの問題との単一の窓口です。
すべてのITインフラストラクチャは、SLAに関する保証を顧客に提供します。 したがって、事前にエンドユーザーと通信するようにしてください。
SPOF
単一障害点(SPOF)は、他の多くのシステムまたはアプリケーションが接続されている機器、個人、リソース、またはアプリケーションの一部です。
そのような機器やリソースがダウンすると、システムに接続されているすべての重要な部品がダウンします。 したがって、プロセス全体と事業運営が影響を受けます。
したがって、組織を運営し続けるには、このような問題を処理するための戦略が必要です。 最初にできることは、より大きな影響を与える可能性のある単一の機器またはシステムを特定することです。 次に、ビジネスへの影響分析を実行し、リスク評価スコアを取得して、発生するシーンを認識します。 イベントの前に掘り下げて見つけてください。
すべてのSPOFをリストしたら、回復プロセスに従ってそれらを分類します。 SPOFのそれぞれを3つの異なるカテゴリに分類します。
- より少ない時間と予算で簡単かつ直接的に回復します。
- 回復は困難ですが、復元するための信頼できるプロセスを開発することができます。
- 一度ダウンすると、回復するために何もできません。
カテゴリに基づいてそれに応じて行動することができます。
システムの回復
ハードウェア障害時には、リカバリプロセスを実行して、特定のシステムまたはサーバーを元の形式に戻す必要があります。 また、システム全体をリカバリするには、リカバリ要件、バックアップ、ファームウェアの互換性、およびハードウェアの互換性に備える必要があります。
システムリカバリは、マシンを以前の設定または新しいときと同じ状態にリセットするプロセスです。 これを行うと、システムにインストールされているソフトウェアまたはアプリケーションに起因するすべてのウイルス感染が一掃されます。
このプロセスには、人為的または自然な混乱に対してデータの可用性を確保するための特定の手順を設定および実行するITインフラストラクチャの復旧計画が含まれます。
システムの復元
システムの復元は、特定のファイルと情報を適切なタイミングで以前の状態に復元できるようにする回復ツールです。
システムの復元を使用すると、レジストリキー、インストールされているプログラム、ドライバ、システムファイルなどを以前のバージョンに復元できます。 これは、多くの災害で命の恩人として機能します。
テスト計画
これは、テスト戦略、見積もり、リソース、期限、目的、およびスケジュールに関する情報を格納するドキュメントを指します。 これは、ハードウェアとソフトウェアの安全性を確認するためのテストを実行する青写真として機能します。
これには、災害後遺症を管理するために計画された手順と手順に従ったさまざまなテストが含まれます。 アクションの過程で1つのステップをスキップしないように、自分自身と組織を準備するために、定期的なテストを実行します。 このようにして、ITインフラストラクチャは欠点を理解し、戦いに備えることができます。
結論
いつ災害が起こるかは誰にも分かりません。 したがって、適切な安全とセキュリティ対策はすべてのビジネスに不可欠です。
災害復旧の用語は、攻撃や災害に対応する方法を理解するのに役立ちます。 また、予期しないイベントが発生した場合にインフラストラクチャを保護できるように、事前に準備するのにも役立ちます。 効果的なリアルタイムのディザスタリカバリ戦略を作成して、数百万ドルを節約し、顧客の信頼を差し控えることができます。