
Comprensione delle terminologie di ripristino di emergenza: RTO, RPO, Failover, BCP e altro
Pubblicato: 2022-03-20Un piano di ripristino di emergenza è una misura fondamentale che un'organizzazione deve avere prima che un evento insolito la colpisca.
Nel settore IT, inizia con la creazione di un documento formale contenente piani, azioni e procedure per affrontare il disastro e le sue conseguenze.
Il disastro è un evento che si verifica improvvisamente senza preavviso e può essere di diversi tipi. E quando atterra, individui e organizzazioni devono affrontare difficoltà di vario genere, inclusi problemi finanziari ed esperienza dell'utente.
Se si verifica un attacco, devi essere pronto a minimizzarne gli effetti e ripristinare le tue operazioni più velocemente. È qui che la preparazione di un pratico piano di ripristino di emergenza ti aiuterà a trattenere o prevenire il disastro. Puoi anche ridurne gli effetti collaterali in termini di esperienza utente, costi e tempi di inattività.
Inoltre, devi tenere pronti i tuoi piani, le persone, le strategie, le apparecchiature e i sistemi per rimettere tutto in azione. Ma per questo, è necessario comprendere a fondo il ripristino di emergenza.
In questo articolo, ne parlerò in dettaglio insieme alle terminologie chiave per il ripristino di emergenza in modo che tu possa reagire coraggiosamente e uscirne più forte in condizioni così avverse.
Cominciamo!
Che cos'è un disastro?

Un disastro è un evento imprevisto che può verificarsi ovunque, compreso il settore IT. Si verifica naturalmente o dalle persone e può interferire con le operazioni di un'azienda e disturbare il tessuto dell'infrastruttura.
Di conseguenza, un'organizzazione e i suoi clienti, fornitori, dipendenti e partner sono interessati. Esercita pressione sull'organizzazione in termini di finanze, reputazione del settore, fiducia dei clienti e perimetro di sicurezza.
Quindi, devi essere pronto in anticipo per superare un tale scenario. Per questo, è necessario ripristinare istantaneamente ogni operazione e dati. In parole semplici, devi preparare la tua organizzazione a recuperare tutto nel più breve tempo possibile per i tuoi clienti.
I disastri sono di molti tipi, come attacchi informatici, sabotaggi, attacchi terroristici, ransomware o minacce fisiche, uragani, terremoti, incendi, inondazioni, incidenti industriali, interruzioni di corrente e molto altro ancora.
Cosa intendi per ripristino di emergenza?
Il ripristino di emergenza è il processo di ripristino delle normali operazioni dopo aver subito un disastro. Implica la ripresa dell'accesso a hardware, software, apparecchiature, connettività, rete, alimentazione e dati. È necessario impostare regole e procedure in un processo documentato per preparare la propria organizzazione prima di un disastro.
Tuttavia, se le strutture dell'organizzazione vengono distrutte, è necessario estendere alcune attività lavorando su comunicazioni, trasporti, approvvigionamento, luoghi di lavoro e altro ancora.
Perché è importante il piano di ripristino di emergenza?
La stesura di un piano perfetto per il ripristino da un disastro, naturale o causato dall'uomo, è essenziale per ogni settore IT. Assicurati di avere il dipendente e gli strumenti giusti al posto giusto per portare a termine il piano senza intoppi.
Analizziamo più a fondo il motivo per cui il ripristino di emergenza è fondamentale.
Limitare i danni
Un disastro è imprevedibile. Nessuno sa quando va e viene. Tuttavia, ti prepari in anticipo per controllare i danni causati alla tua infrastruttura.
Ad esempio, nelle aree soggette a inondazioni, è possibile posizionare i documenti e i tipi di attrezzatura essenziali all'ultimo piano per evitare danni.
Allo stesso modo, esegui il backup dei tuoi dati essenziali prima che gli attacchi informatici possano violare i dati o rubarli.
Servizi di ripristino
Se si prepara un solido piano per riprendersi dal disastro, ripristinare tutti i servizi alla loro forma normale è semplice e veloce. Significa che in un breve intervallo di tempo puoi recuperare quasi tutti i principali asset e servizi.
Riduci al minimo l'interruzione
Non puoi sapere cosa accadrà domani o nella fase successiva di un'operazione. Ma, con un piano di recupero perfetto, non devi preoccuparti molto delle conseguenze. La tua infrastruttura può continuare le operazioni con interruzioni minime.
Formazione e preparazione

Un'infrastruttura IT è composta da molti dipendenti che lavorano sotto un tetto. Tutti devono essere a conoscenza del recupero per agire immediatamente come richiesto e previsto in caso di emergenza.
Una preparazione adeguata ridurrà anche i livelli di stress di tutti coloro che sono associati alla tua organizzazione. Inoltre, puoi addestrare i tuoi dipendenti a intraprendere le azioni necessarie se si verifica un evento imprevisto.
Terminologie per il ripristino di emergenza
Iniziamo con le terminologie per comprendere il ripristino di emergenza da una vista più ravvicinata.
RTO
L'obiettivo del tempo di ripristino (RTO) è la quantità di tempo che un'organizzazione imposta in base alla natura dell'azienda per tollerare il disastro senza influire sulla crescita finanziaria.
Durante l'impostazione dell'RTO, un'azienda deve controllare i tempi di inattività che possono influire sulla tua organizzazione in molti modi. Viene utilizzato per studiare strategie praticabili per continuare le operazioni aziendali anche dopo un disastro. Quando i clienti riscontrano problemi nell'applicazione, chiedono quanto tempo impiegherà un'app per tornare all'azione. La risposta è RTO per ogni organizzazione.
Esempio: supponiamo che tu sia una società di transazioni online come PayPal o Pioneer che deve affrontare eventi imprevedibili. In questo caso, il tuo RTO sarà abbastanza veloce da ripristinare l'operazione.
In altre parole, un'azienda imposta il proprio RTO su un'ora o due per evitare conseguenze sotto forma di finanziamenti o dati.
RPO
Recovery Point Objectives (RPO) è la perdita di dati che un'infrastruttura IT può gestire in termini di tempo e quantità di informazioni.
Confuso?
Prendi un esempio di un database che registra le transazioni di una banca, inclusi bonifici, pianificazione, pagamenti e altro. Quando si verifica un disastro, il database viene ripristinato in tempo reale. La differenza tra il database al momento dell'emergenza e il ripristino del database dopo un'emergenza è zero in questo caso.
Per alcune aziende, è accettabile impiegare circa 24 ore per recuperare tutte le informazioni dal backup, ma a volte può essere catastrofico. È essenziale impostare la tua infrastruttura in base ai requisiti RPO. Ciò include il miglioramento della frequenza dei backup, l'aggiunta di un database in standby all'architettura e altro ancora.
Failover
Pensa a una situazione in cui stai percorrendo una lunga distanza. Improvvisamente, hai una gomma a terra per qualche motivo inaspettato. Ringrazia la ruota di scorta disponibile nel tuo veicolo e gli strumenti per cambiare la ruota difettosa.
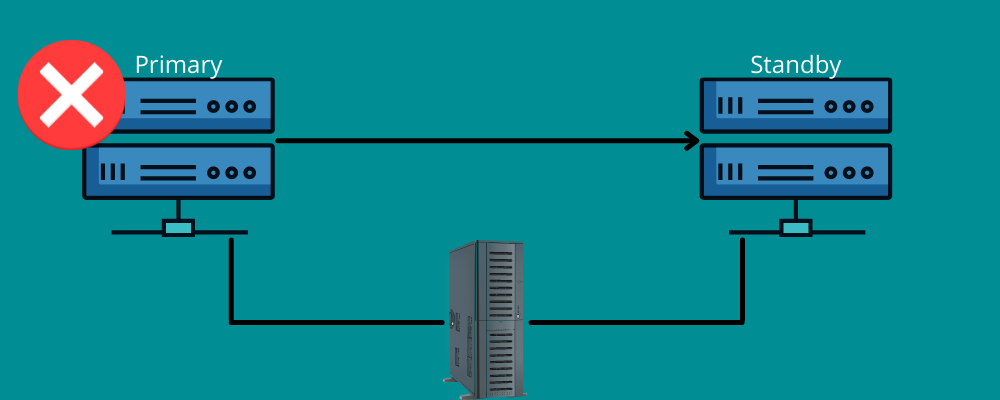
Il failover funziona allo stesso modo.
Significa che hai bisogno di una connessione di backup durante il disastro. In poche parole, failover significa disporre di reti e sistemi che è possibile utilizzare in caso di emergenza per trasferire le informazioni al sistema di ripristino.
Il failover garantisce il corretto funzionamento di tutti i servizi, anche in caso di guasti infrastrutturali o hardware. In questo modo, puoi impedire alla tua organizzazione di perdere dati e ricavi ed evitare interruzioni del servizio per i tuoi utenti finali.
È possibile impostarlo manualmente o consentirne il funzionamento automatico per spostare i dati sul server di standby.
Ritorno
Il failback IT è una semplice operazione in cui la produzione originale torna alla posizione originale (sistema) dopo che un disastro è stato gestito. Durante l'attacco, le aziende seguono un'operazione di failover a causa della quale tutti i carichi di lavoro vengono trasferiti su una replica di VM o su un sistema di backup.
Tuttavia, non puoi semplicemente saltare il passaggio successivo del ritorno. Quando ripristini tutto e torni in azione, devi trasferire tutti i carichi di lavoro alle macchine virtuali o ai sistemi originali. Questo processo complessivo di restituzione dei carichi di lavoro al luogo di lavoro o al sistema originale è noto come failback. Significa che stai tornando "indietro" dopo l'attacco.
Il failback viene utilizzato anche per la manutenzione programmata di un'azienda. È vero che il failback si verifica sempre dopo il failover. In altre parole, il failover è il primo passaggio e il failback è il secondo passaggio per il ripristino dei dati essenziali. Può essere configurato da cloud a cloud, da locale a locale, da locale a cloud o qualsiasi combinazione di questi.
DOTT
Disaster Recovery (DR) è il processo in cui hai piani predefiniti per recuperare le tue risorse entro il periodo di tempo.
Il DR offre a un'organizzazione la possibilità di rispondere rapidamente e ripristinare ogni singolo servizio da un evento imprevisto. Fornisce inoltre una documentazione formale che contiene istruzioni su come intraprendere azioni immediate in caso di incidenti imprevisti.
BCP
Il Business Continuity Plan (BCP) è uno dei piani di ripristino di emergenza più accettabili che consente all'infrastruttura IT di elaborare strategie per gestire le interruzioni IT di server, dispositivi mobili, personal computer e reti.
BCP è leggermente diverso dal ripristino di emergenza in quanto aiuta un'organizzazione a pianificare di ristabilire il software e la produttività aziendali per soddisfare le esigenze aziendali chiave.
Qui, un'azienda crea un sistema di ripristino per superare potenziali minacce, come attacchi informatici o disastri naturali. È progettato per proteggere le risorse e garantire che tutti i servizi tornino operativi rapidamente dopo lo sciopero.

BCM

Business Continuity Management (BCM) è un processo di gestione del rischio appositamente progettato per fungere da scudo contro le minacce ai processi aziendali. BCM è il passaggio successivo di BCP, in cui convalida i piani di ripristino per assicurarsi che tutti nell'azienda rispondano al piano istantaneamente e recuperino tutte le cose essenziali.
BCM funge da framework di gestione per identificare i rischi infrastrutturali quando affronta minacce esterne e/o interne. Garantisce inoltre che il framework funzioni in modo efficiente con l'aiuto di test regolari per migliorare la prevedibilità, ridurre i rischi e allineare il piano per gli attacchi futuri.
BIA
L'analisi dell'impatto aziendale (BIA) è il processo di analisi del tasso di sopravvivenza di un'azienda identificando sistemi, operazioni e processi cruciali. Racconta l'effetto di un disastro sulla tua organizzazione a causa dell'interruzione delle tue operazioni.
BIA prevede le conseguenze prima che si verifichi effettivamente un attacco al fine di raccogliere informazioni chiave che possono aiutare a creare potenti strategie di ripristino. Identifica anche i costi coinvolti a causa dei guasti, come il costo di sostituzione delle apparecchiature, la perdita di flusso di cassa, i profitti, gli stipendi e altro ancora.
Quando si crea un report BIA, è necessario considerare i processi cruciali coinvolti nella propria attività, l'impatto delle interruzioni in aree diverse, la durata accettabile, le aree tollerabili, i costi finanziari e altro ancora.
Albero delle chiamate
Un albero delle chiamate è un processo di cura di un elenco di personale a cui rivolgersi durante un'emergenza. È una procedura che segue una struttura ad albero.
Ad esempio, durante un disastro, una persona contatterà un piccolo gruppo di membri con un messaggio urgente, i membri del personale chiameranno ciascun gruppo separatamente. In questo modo, tutto il personale verrà informato durante la minaccia e inizierà il lavoro assegnato per ripristinare in tempo ogni funzione e processo. Fare un elenco è semplice ma implementarlo in tempo reale crea confusione.
È necessario eseguire attività di chiamata regolari per preparare ogni membro del personale di emergenza a rimanere vigile. Test regolari possono anche aiutare a identificare i numeri modificati o mancanti che possono influire gravemente sulle prestazioni.
Un albero delle chiamate contiene informazioni da utilizzare durante un'emergenza per fornire istruzioni. Può anche essere fatto manualmente, ma le persone usano l'automazione per accelerare il processo e notificare i membri nel mondo digitale di oggi.
Centro di comando/centro di controllo
È una struttura virtuale o fisica appositamente preparata per fornire il comando o il controllo sui piani di ripresa durante una crisi. Comunica con il team per gestire i sistemi e le funzioni durante il disastro.
Tradizionalmente, l'infrastruttura dipende dal centro di comando che affronta le crisi senza alcun approccio adeguato. Al giorno d'oggi, le organizzazioni hanno progettato perfettamente il loro centro di controllo, che trasforma la risposta immediata in competenza di base.
Una volta che avverte un disastro, il centro di comando si avvia rapidamente verso la fase di ripristino. Inoltre, funge da punto di riferimento in caso di servizi, stampa, consegne e altro. Riunisce anche persone di più discipline durante tali scenari.
Risposta all'incidente

La risposta all'incidente è un tipo di risposta data per affrontare un attacco. Viene fatto con l'aiuto delle procedure e del personale giusti per preservare la sicurezza della rete e dei dati in modo efficace al momento giusto.
Se un'organizzazione dispone di un piano per gli incidenti prima dell'evento imprevisto, può proteggere i propri dati dalle minacce in tempo reale. Gli specialisti della risposta agli incidenti stanno sempre attenti ai problemi e agiscono in modo naturale durante un incidente. Adottano determinate misure per evitare violazioni della sicurezza, assicurandosi che non saltino un solo passaggio durante il ripristino di emergenza.
All'inizio, è necessario determinare i dati critici e archiviarli nel cloud o in qualsiasi posizione remota per garantire la sicurezza. Rispondi alle attuali esigenze dell'infrastruttura e alle minacce informatiche in evoluzione aggiornando regolarmente i piani di risposta agli incidenti.
Backup
Le soluzioni di backup aiutano un'infrastruttura IT a conservare le copie dei dati e ad archiviarli in modo sicuro al momento giusto. In caso di danneggiamento del database, cancellazione accidentale di tutti i dati o qualsiasi altro problema, è necessario essere pronti con il backup per ripristinare i dati all'istante e continuare con i servizi.

Implica la replica dei file e l'archiviazione in un luogo sicuro per accedere facilmente a tutti i dati dopo un evento insolito. Ti aiuterà se esegui il backup dei tuoi dati in più posizioni per assicurarti di poterli ripristinare anche in caso di errore di un sito.
Resilienza
La capacità di comunità, stati, organizzazioni e individui di resistere o resistere a un disastro senza compromettere i servizi e i sistemi è nota come resilienza al disastro.
Un'organizzazione deve essere preparata a trattenere una grande quantità di stress a causa dei pericoli. Assicurati di avere le capacità per ridurre al minimo le tue perdite con una migliore pianificazione invece di aspettare che qualcuno venga a salvarti. Ciò ti aiuterà a far fronte ai disastri ea ripristinare in modo efficiente la tua infrastruttura IT.
Qui, l'obiettivo principale è quello di preservare e ripristinare le funzioni e le strutture essenziali al momento giusto, quando necessario. Per diventare un'organizzazione resiliente alle catastrofi, è necessario prepararsi in anticipo e avere la capacità di anticipare i rischi, adattarsi ai cambiamenti, condividere e apprendere, integrare vari settori e gestire i livelli di rischio.
SLA

Il Service Level Agreement (SLA) è un piano di emergenza in cui menzioni agli utenti finali il tempo che potresti impiegare per ripristinare i servizi durante un'emergenza.
SLA garantisce ai clienti che i loro dati sono al sicuro e non compromessi o condivisi con terze parti. È l'unico punto di contatto con i problemi degli utenti finali.
Ogni infrastruttura IT garantisce ai propri clienti lo SLA. Quindi, assicurati di comunicare in anticipo con i tuoi utenti finali.
SPOF
Un Single Point of Failure (SPOF) è un'apparecchiatura, un individuo, una risorsa o un'applicazione a cui sono collegati molti altri sistemi o applicazioni.
Se un tale pezzo di attrezzatura o risorsa si guasta, tutte le parti essenziali collegate al sistema si guastano con esso. Pertanto, l'intero processo e l'operazione aziendale saranno interessati.
Pertanto, è necessario disporre di una strategia per gestire un problema del genere per mantenere in funzione la propria organizzazione. La prima cosa che puoi fare è identificare quel singolo pezzo di attrezzatura o sistema che può avere un impatto maggiore. Successivamente, esegui un'analisi dell'impatto aziendale e ottieni un punteggio di valutazione del rischio per essere a conoscenza delle scene che accadranno. Entra e trovali prima dell'evento.
Una volta elencati tutti gli SPOF, classificali in base al processo di recupero. Metti ciascuno degli SPOF in tre diverse categorie:
- Recupera facilmente e direttamente con meno tempo e budget.
- Il ripristino sarebbe difficile, ma potrebbe essere sviluppato un processo affidabile per il ripristino.
- Nulla può essere fatto per recuperare una volta che va giù.
Puoi agire di conseguenza in base alla categoria.
Ripristino del sistema
Durante un guasto hardware, è necessario eseguire un processo di ripristino per ripristinare il particolare sistema o server nella sua forma originale. E per ripristinare l'intero sistema, devi essere pronto con i requisiti di ripristino, backup, compatibilità firmware e compatibilità hardware.
Il ripristino del sistema è un processo che ripristina la macchina alle impostazioni precedenti o allo stesso stato di quando era nuova. In questo modo eliminerai tutte le infezioni da virus dovute a software o applicazioni installati nel tuo sistema.
Questo processo include la pianificazione del ripristino di un'infrastruttura IT che imposta e segue determinate procedure per garantire la disponibilità dei dati contro le interruzioni causate dall'uomo o naturali.
Ripristino del sistema
Il ripristino del sistema è uno strumento di ripristino che consente di ripristinare determinati file e informazioni allo stato precedente al momento giusto.
Con il ripristino del sistema, puoi ripristinare le chiavi di registro, i programmi installati, i driver, i file di sistema e altro ancora alla versione precedente. Questo funge da salvavita in molti disastri.
Piano di prova
Si riferisce a un documento che memorizza informazioni su una strategia di test, stime, risorse, scadenze, obiettivi e programmi. Funziona come un progetto che esegue test per garantire la sicurezza hardware e software.
Ciò include vari test in base alle procedure e ai passaggi pianificati per gestire i postumi del disastro. Esegui i test regolari per preparare te stesso e la tua organizzazione a non saltare un solo passaggio durante il corso dell'azione. In questo modo, un'infrastruttura IT può comprendere le carenze ed essere pronta per la battaglia.
Conclusione
Nessuno sa quando accadrà un disastro. Pertanto, adeguate misure di sicurezza e protezione sono essenziali per ogni azienda.
Le terminologie di ripristino di emergenza ti aiuteranno a capire come rispondere ad attacchi e disastri. Ti aiuterà anche a prepararti in anticipo in modo da poter salvaguardare la tua infrastruttura durante un evento imprevisto. Sarai in grado di creare un'efficace strategia di ripristino di emergenza in tempo reale per risparmiare milioni di dollari e mantenere la fiducia dei clienti.