
สิ่งที่คุณไม่รู้เกี่ยวกับ AWS Glue
เผยแพร่แล้ว: 2022-10-18Amazon Glue กำลังได้รับความนิยมเนื่องจากหลายบริษัทเริ่มใช้บริการการรวมข้อมูลที่มีการจัดการ
ETL เป็นกระบวนการที่ถ่ายโอนข้อมูลจากฐานข้อมูลต้นทางไปยังคลังข้อมูล ETL นั้นซับซ้อนและใช้งานยากสำหรับข้อมูลองค์กรทั้งหมดเนื่องจากความซับซ้อน Amazon แนะนำ AWS Glue เพื่อแก้ไขปัญหานี้
นักพัฒนา ETL และวิศวกรข้อมูลใช้ Glue เพื่อสร้าง ตรวจสอบ และเรียกใช้เวิร์กโฟลว์ ETL
AWS Glue คืออะไร?
AWS Glue บริการการรวมข้อมูลแบบไร้เซิร์ฟเวอร์ทำให้ง่ายต่อการค้นหา จัดเตรียม ย้าย และผสานข้อมูลจากแหล่งต่างๆ ซึ่งมีประโยชน์สำหรับแมชชีนเลิร์นนิง (ML) และการวิเคราะห์
ช่วยลดเวลาที่ต้องใช้ในการเตรียมข้อมูลสำหรับการวิเคราะห์ได้อย่างมาก ค้นหาและแสดงรายการข้อมูลโดยอัตโนมัติ สร้างรหัส Scala หรือ Python เพื่อส่งข้อมูลจากแหล่งที่มา และโหลดและแปลงงานตามเหตุการณ์ที่กำหนดเวลาไว้
ซึ่งช่วยให้สามารถตั้งเวลาได้อย่างยืดหยุ่นและสร้างสภาพแวดล้อม Apache Spark ที่สามารถปรับขนาดสำหรับการโหลดข้อมูลเป้าหมายได้ นอกจากนี้ AWS Glue ยังมีการตรวจสอบและแก้ไขสตรีมข้อมูลที่ซับซ้อน AWS Glue เป็นบริการแบบไร้เซิร์ฟเวอร์ที่ช่วยให้การดำเนินการที่ซับซ้อนของการพัฒนาแอปพลิเคชันง่ายขึ้น
ช่วยให้สามารถรวมข้อมูลที่ถูกต้องหลายรายการได้อย่างรวดเร็ว นอกจากนี้ยังแยกย่อยและอนุญาตข้อมูลอย่างรวดเร็ว
AWS Glue ใช้ทำอะไร
สิ่งสำคัญคือต้องรู้จักสถานที่ที่ดีที่สุดในการใช้ Amazon Glue นี่เป็นเพียงตัวอย่างเล็กๆ น้อยๆ ของการใช้งาน AWS Glue ที่คุณควรพิจารณา
- Amazon Glue เป็นเครื่องมือที่ช่วยให้คุณเรียกใช้การสืบค้นแบบไร้เซิร์ฟเวอร์บน Data Lake ของ Amazon S3
- Amazon Glue เป็นเครื่องมือที่ยอดเยี่ยมในการเริ่มต้น ทำให้ข้อมูลทั้งหมดของคุณสามารถเข้าถึงได้จากอินเทอร์เฟซเดียว ทำให้คุณสามารถวิเคราะห์ได้โดยไม่ต้องย้าย
- สามารถใช้ Amazon Glue เพื่อทำความเข้าใจเนื้อหาข้อมูลของคุณได้ Amazon Glue ช่วยให้คุณค้นหาชุดข้อมูล AWS ต่างๆ ได้อย่างง่ายดายโดยใช้ Data Catalog คุณยังสามารถบันทึกข้อมูลในบริการต่างๆ ของ AWS ได้โดยใช้ Data Catalog โดยที่ยังคงมีมุมมองที่สอดคล้องกัน
- กาวมีประโยชน์ในการสร้างเวิร์กโฟลว์ ETL ที่ขับเคลื่อนด้วยเหตุการณ์ คุณสามารถดำเนินการ ETL ของคุณจาก Amazon S3 ได้โดยการเรียกงาน ETL ของกาวผ่านบริการ AWS Lambda
- คุณยังสามารถใช้ AWS Glue เพื่อล้าง ตรวจสอบ จัดรูปแบบ และจัดระเบียบข้อมูลสำหรับการจัดเก็บใน Data Lake หรือคลังข้อมูล
ส่วนประกอบของกาว AWS
ด้านล่างนี้เป็นส่วนประกอบหลักของ AWS Glue:
- แคตตาล็อกข้อมูล: แคต ตาล็อกข้อมูลนี้มีข้อมูลเมตาและโครงสร้างข้อมูล
- ฐานข้อมูล: นี่คือกุญแจสำคัญในการเข้าถึงและสร้างฐานข้อมูลสำหรับแหล่งที่มาและเป้าหมาย
- ตาราง: สร้างตารางอย่างน้อยหนึ่งตารางในฐานข้อมูลที่ทั้งเป้าหมายและต้นทางใช้งานได้
- โปรแกรมรวบรวมข้อมูล และตัวแยกประเภท: โปรแกรมรวบรวมข้อมูลดึงข้อมูลจากแหล่งที่มาโดยใช้การจัดประเภทที่มีอยู่แล้วภายในหรือแบบกำหนดเอง มันสร้าง/ใช้ตารางข้อมูลเมตาที่กำหนดไว้ล่วงหน้าในแค็ตตาล็อกข้อมูล
- งาน: นี่คืองานของตรรกะทางธุรกิจในการทำงาน ETL ตรรกะทางธุรกิจนี้เขียนขึ้นภายในโดย Apache Spark โดยใช้ภาษาหลามและภาษาสกาลา
- ทริกเกอร์: ทริกเกอร์ ETL เป็นอุปกรณ์ที่เริ่มต้นการทำงานของงาน ETL แบบออนดีมานด์หรือในเวลาเฉพาะ
- จุด สิ้นสุดสำหรับการพัฒนา: สิ่งนี้สร้างสภาพแวดล้อมที่สคริปต์งาน ETL ได้รับการทดสอบ พัฒนา และดีบั๊ก
ประโยชน์ของกาว AWS
นี่คือประโยชน์ของการใช้งานในที่ทำงานของคุณหรือภายในองค์กร
- AWS Glue จะสแกนข้อมูลทั้งหมดที่มีในโปรแกรมรวบรวมข้อมูล
- ข้อมูลที่ประมวลผลขั้นสุดท้ายสามารถจัดเก็บได้หลายที่ (Amazon RDS และ Amazon Redshift, Amazon S3 เป็นต้น
- เป็นบริการบนคลาวด์ ไม่จำเป็นต้องใช้เงินกับโครงสร้างพื้นฐานภายในองค์กร
- เนื่องจากเป็น ETL แบบไร้เซิร์ฟเวอร์ จึงเป็นตัวเลือกที่คุ้มค่า
- มันเร็ว มันให้รหัส Python/Scala ETL แก่คุณทันที
คุณสมบัติเด่นของ AWS Glue
Amazon Glue มีคุณสมบัติทั้งหมดที่คุณต้องการในการผสานรวมข้อมูล คุณจึงสามารถรับข้อมูลเชิงลึกที่ดีขึ้นและใช้ความรู้ของคุณเพื่อสร้างความก้าวหน้าครั้งใหม่ได้ในเวลาไม่กี่นาทีแทนที่จะเป็นเดือน นี่คือคุณสมบัติบางอย่างที่คุณควรรู้
- อินเทอร์ เฟซแบบลากและวาง: เครื่องมือแก้ไขงานแบบลากแล้วปล่อยช่วยให้คุณสร้างกระบวนการ ETL ได้ AWS Glue จะสร้างโค้ดที่จำเป็นในการดึง แปลง และอัปโหลดข้อมูลทันที
- การค้นหาส คีมาอัตโนมัติ: หากต้องการสร้างโปรแกรมรวบรวมข้อมูลที่เชื่อมต่อกับแหล่งข้อมูลต่างๆ คุณสามารถใช้บริการ Glue จัดระเบียบข้อมูลและดึงข้อมูลที่เกี่ยวข้อง ข้อมูลเหล่านี้สามารถใช้เพื่อตรวจสอบกระบวนการ ETL โดยงาน ETL
- การจัดตารางงาน: กาวสามารถใช้ได้ตามความต้องการหรือตามกำหนดการ ตัวจัดกำหนดการสามารถใช้เพื่อสร้างไปป์ไลน์ ETL ที่ซับซ้อน สร้างการพึ่งพาระหว่างงาน
- การสร้างโค้ด: มุมมองแบบยืดหยุ่นของกาวช่วยให้คุณสร้างมุมมองที่เป็นรูปธรรมที่รวมและทำซ้ำข้อมูลจากแหล่งข้อมูลต่างๆ ได้โดยไม่ต้องเขียนโค้ดที่เป็นกรรมสิทธิ์ใดๆ
- การเรียนรู้ด้วยเครื่องในตัว: กาวมาพร้อมกับคุณลักษณะการเรียนรู้ของเครื่องที่เรียกว่า "FindMatches" โดยจะขจัดข้อมูลซ้ำซ้อนซึ่งไม่ใช่สำเนาที่สมบูรณ์ของกันและกัน
- Developer Endpoints : หากคุณต้องการพัฒนาโค้ด ETL ของคุณอย่างจริงจัง Glue ก็มีจุดสิ้นสุดสำหรับนักพัฒนาที่ให้คุณแก้ไข แก้จุดบกพร่อง และทดสอบโค้ดที่สร้างได้
- Glue DataBrew: เป็นเครื่องมือเตรียมข้อมูลที่นักวิเคราะห์ข้อมูลและนักวิทยาศาสตร์ด้านข้อมูลสามารถใช้เพื่อช่วยทำความสะอาดและทำให้ข้อมูลเป็นมาตรฐาน ใช้อินเทอร์เฟซแบบเห็นภาพและแอ็คทีฟของ Glue DataBrew
การกำหนดราคากาวของ AWS ทำงานอย่างไร
AWS Glue เรียกเก็บค่าธรรมเนียมรายชั่วโมง ซึ่งถูกเรียกเก็บต่อวินาทีสำหรับโปรแกรมรวบรวมข้อมูล (การค้นหาข้อมูล) และงาน ETL (การประมวลผลและการโหลดข้อมูล) มีการเรียกเก็บค่าธรรมเนียมรายเดือนอย่างง่ายสำหรับการเข้าถึงและจัดเก็บข้อมูลเมตาใน AWS Glue Data Catalog
Amazon Glue เริ่มต้นที่ $0.44 คุณสามารถเลือกจากสี่แผน:
- งาน ETL, จุดสิ้นสุดการพัฒนา และงาน ETL อื่นๆ มีให้ในราคา $0.44
- Crawlers Interactive Sessions มีจำหน่ายที่ $0.44
- งาน DataBrew เริ่มต้นที่ $0.48
- การจัดเก็บรายเดือนและคำขอไปยัง Data Catalog มีค่าใช้จ่าย $1.00
AWS ไม่มีแผนบริการกาวฟรี ทุกชั่วโมงจะมีค่าใช้จ่าย 0.44 ดอลลาร์ต่อ DPU โดยเฉลี่ยแล้วจะมีค่าใช้จ่าย $21 ต่อวัน ราคาอาจแตกต่างกันไปขึ้นอยู่กับที่คุณอาศัยอยู่
ขั้นตอนในการตั้งค่า AWS Glue
สามารถใช้ Data Catalog เพื่อค้นหาและค้นหาชุดข้อมูล AWS หลายชุดได้อย่างรวดเร็วโดยไม่ต้องย้ายข้อมูล หลังจากจัดหมวดหมู่ข้อมูลแล้ว จะพร้อมใช้งานสำหรับการค้นหาและค้นหาโดยใช้ Amazon Athena และ Amazon EMR ทันที
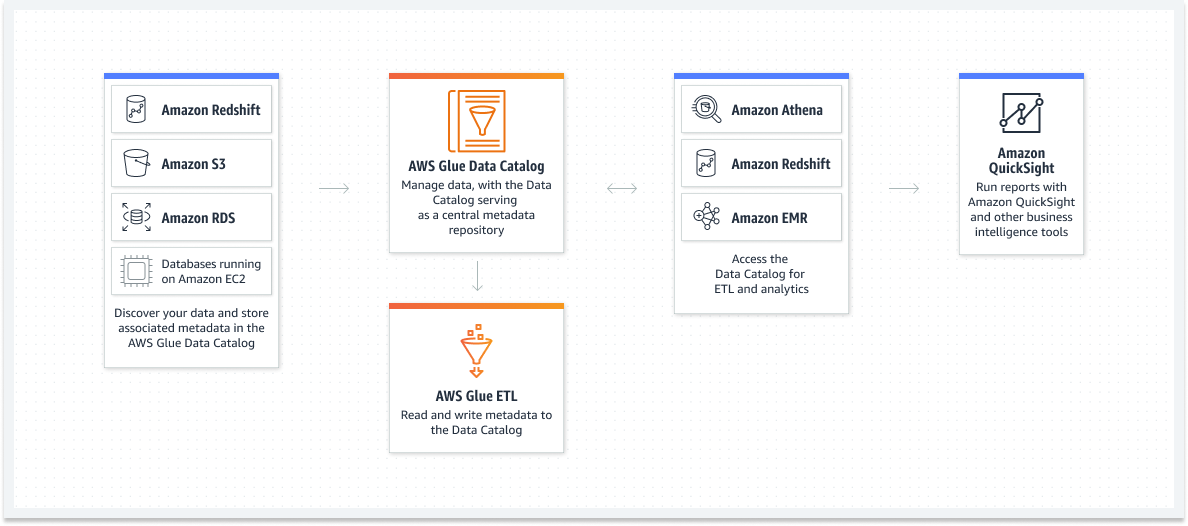
- Amazon Redshift, Amazon S3, Amazon RDS และฐานข้อมูลบน Amazon EC2 – ค้นพบข้อมูลของคุณ จัดเก็บข้อมูลเมตา และใช้ AWS Glue Data Catalog เพื่อค้นหา
- แค็ตตาล็อกข้อมูล AWS Glue – จัดการข้อมูลด้วยแค็ตตาล็อกข้อมูลซึ่งทำหน้าที่เป็นที่เก็บส่วนกลางสำหรับข้อมูลเมตา
- AWS Glue ETL – อ่านและเขียนข้อมูลเมตาลงในแคตตาล็อกข้อมูลของคุณ
- Amazon Athena และ Amazon Redshift, Amazon EMR, Amazon ETL – รับแคตตาล็อกข้อมูลสำหรับ ETL การวิเคราะห์ และอื่นๆ
- Amazon QuickSight – เรียกใช้รายงานด้วย Amazon QuickSight และเครื่องมือข่าวกรองธุรกิจอื่นๆ
วิธีการตั้งค่ากาว AWS
ขั้นแรก ลงชื่อเข้าใช้ AWS Management Console และเปิดคอนโซล IAM คลิกที่สร้างบทบาท จากนั้นสำหรับประเภท บทบาท ให้ค้นหา Glue แล้วเลือก Permissions
ฉันกำลังเลือก AWSGlueServiceRole สำหรับการอนุญาต AWS Glue Studio และ AWS Glue ทั่วไป และนโยบายที่จัดการโดย AWS AmazonS3FullAccess สำหรับการเข้าถึงทรัพยากร Amazon S3
ป้อนชื่อบทบาท
คลิกที่สร้างบทบาท
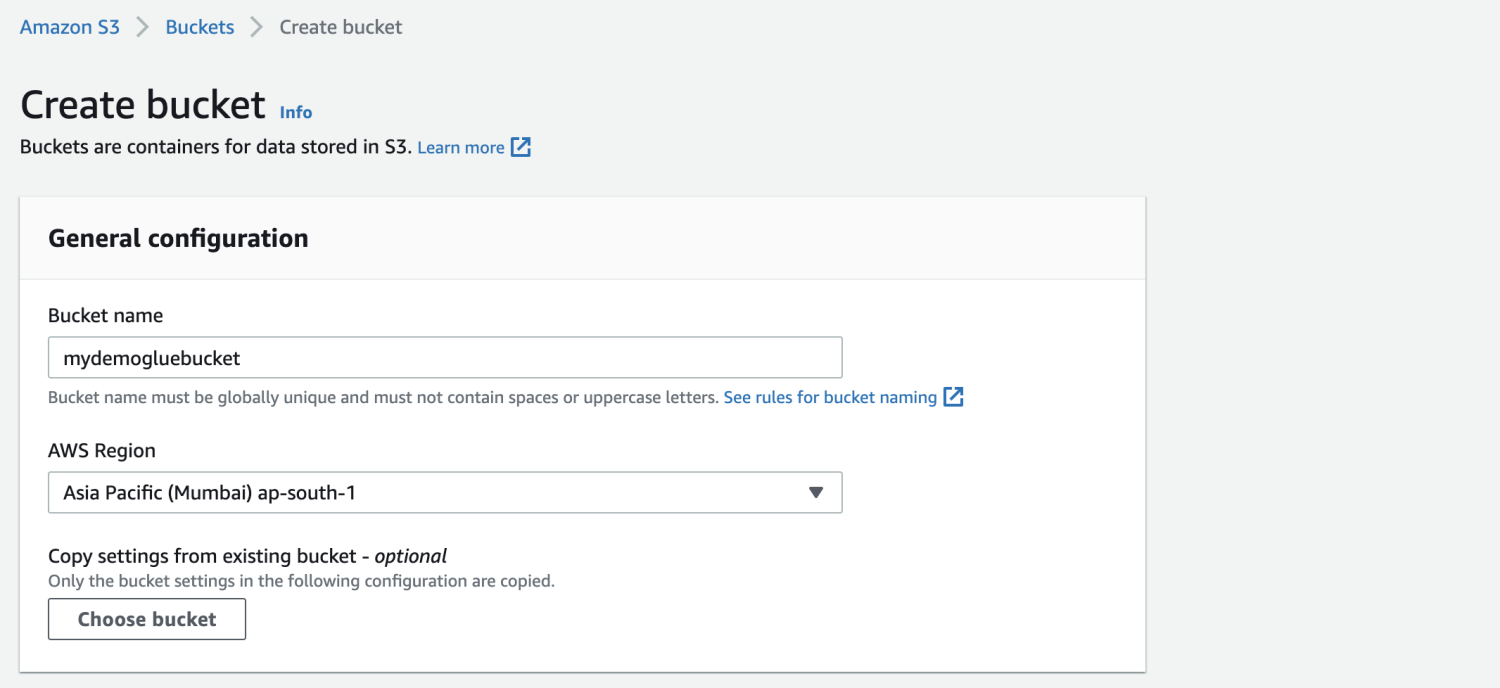
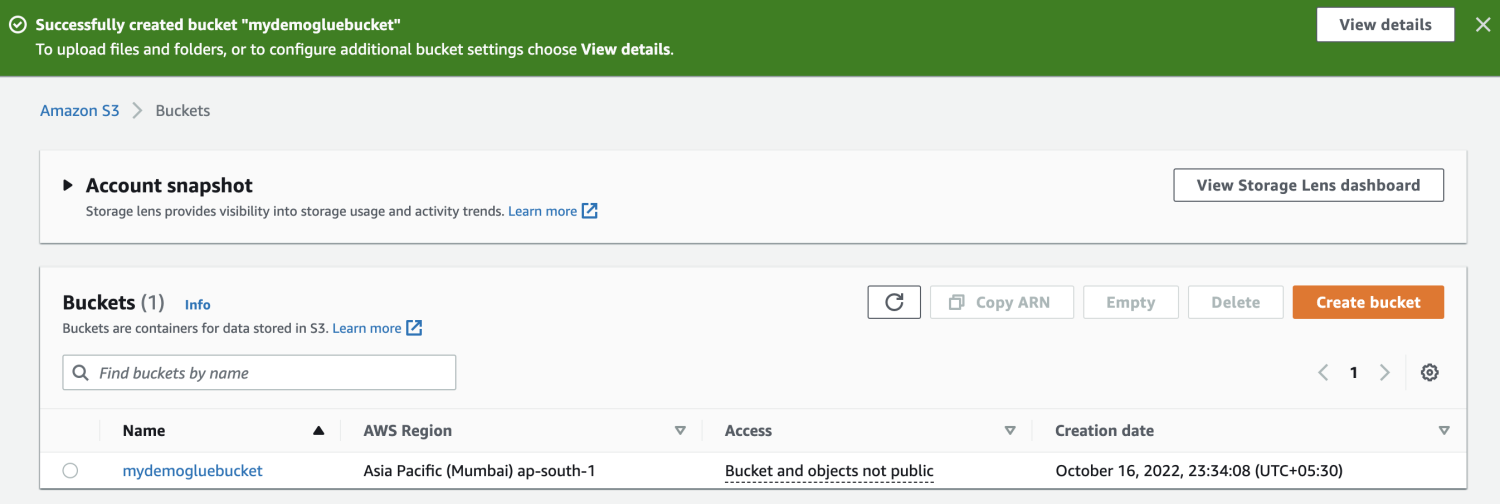
สร้างบัคเก็ต Amazon S3
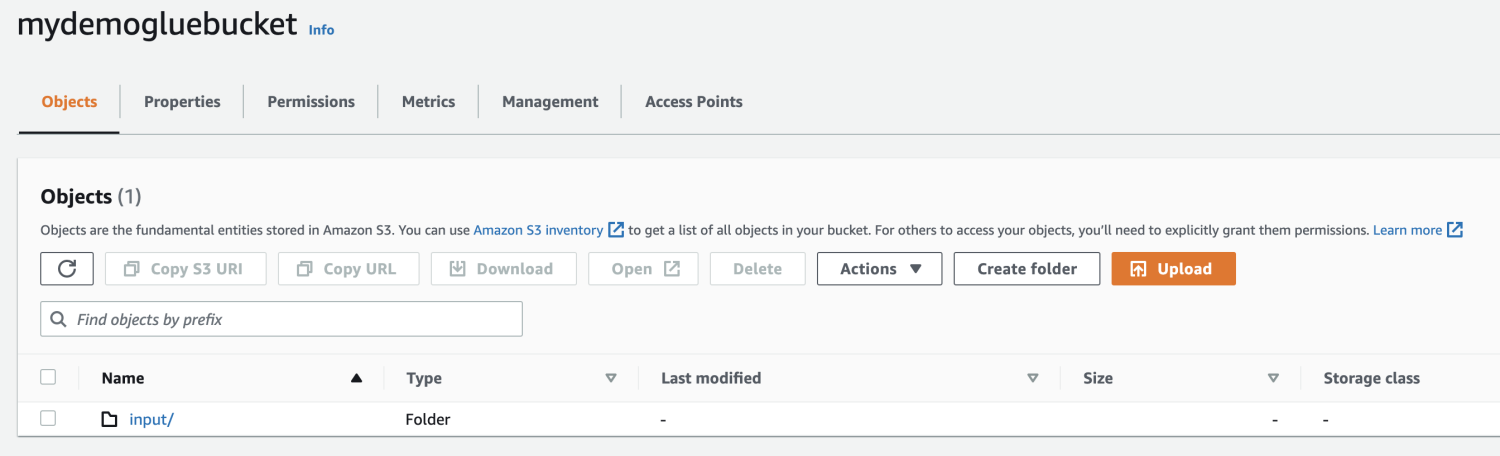
สร้างโฟลเดอร์ภายในบัคเก็ต S3

เลือกไฟล์ที่จะอัปโหลด
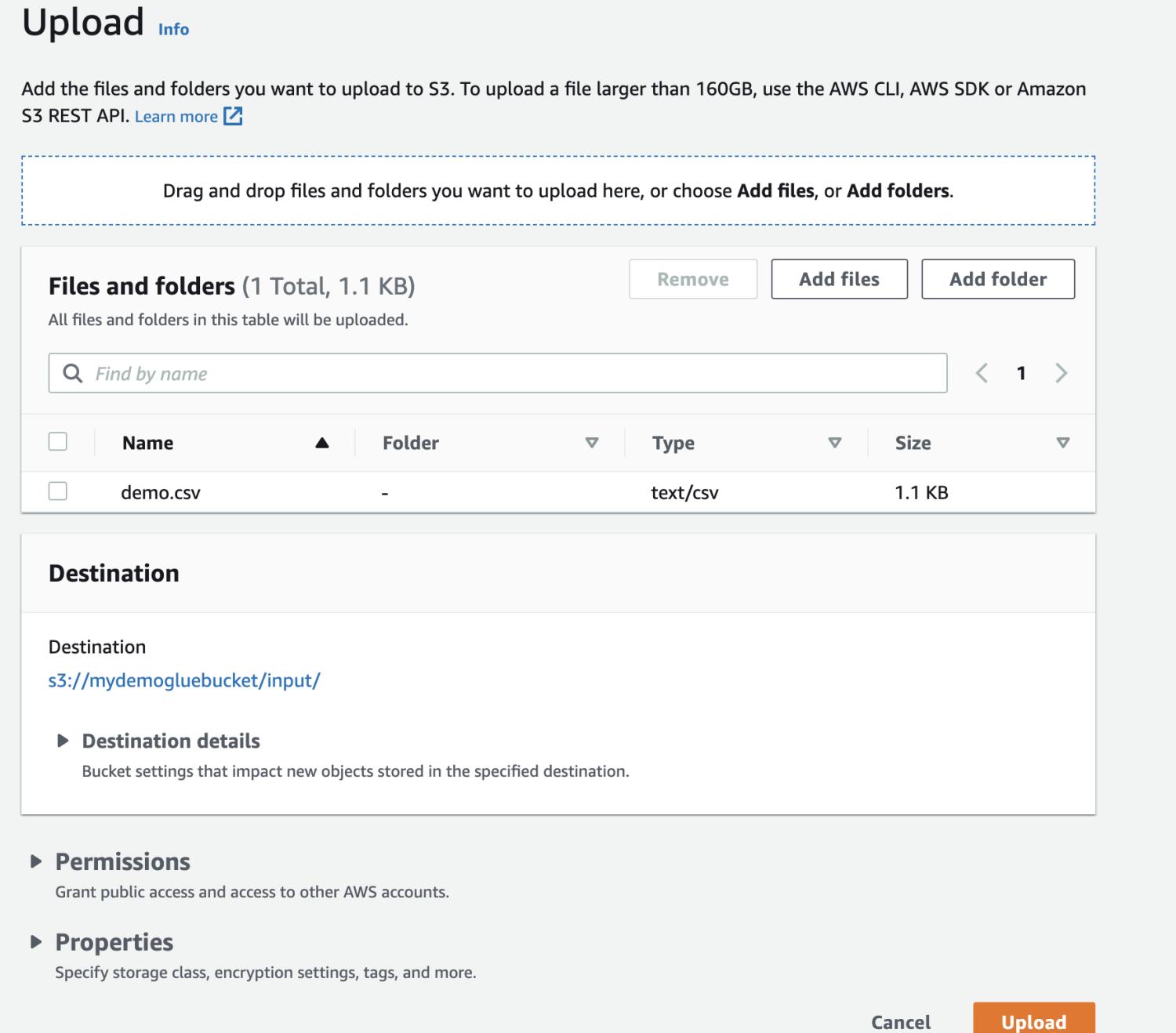
สุดท้าย อัปโหลดไฟล์ในที่เก็บข้อมูล
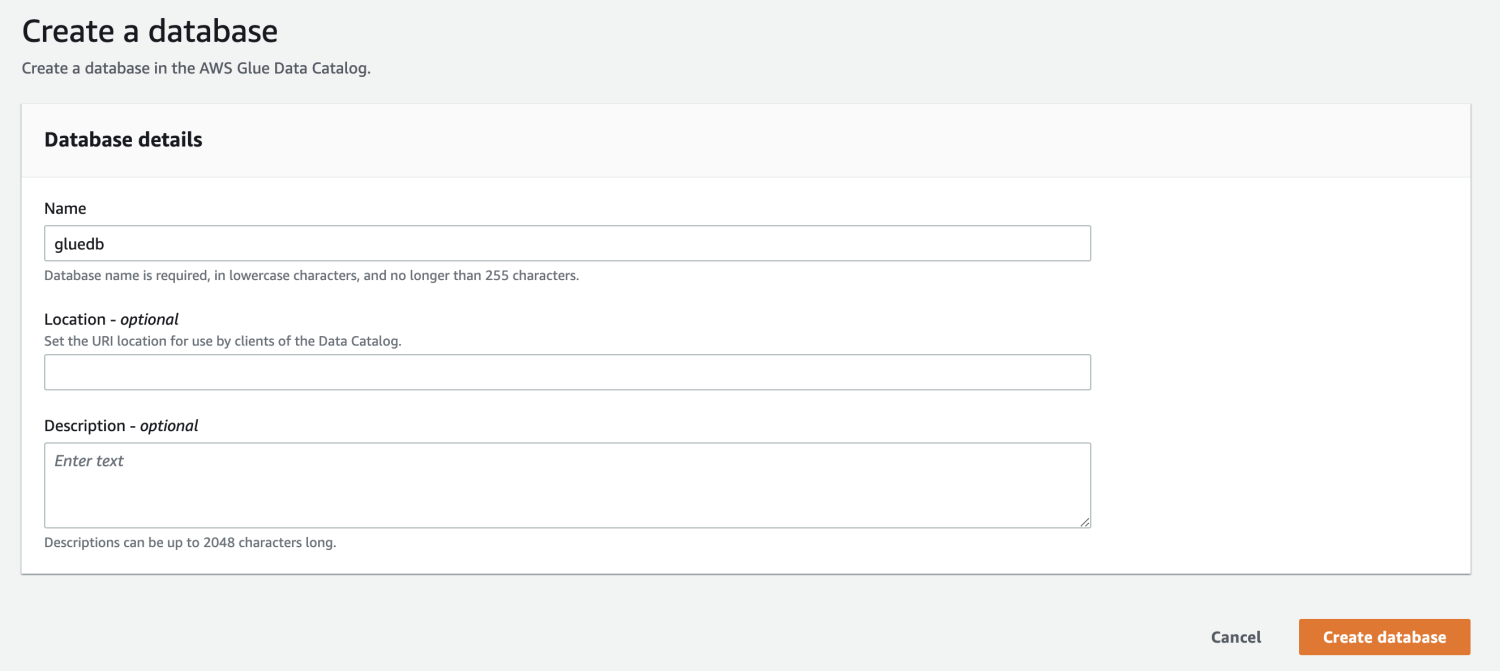
ถัดไป เปิด AWS Glue จากคอนโซลการจัดการ AWS และสร้างฐานข้อมูล
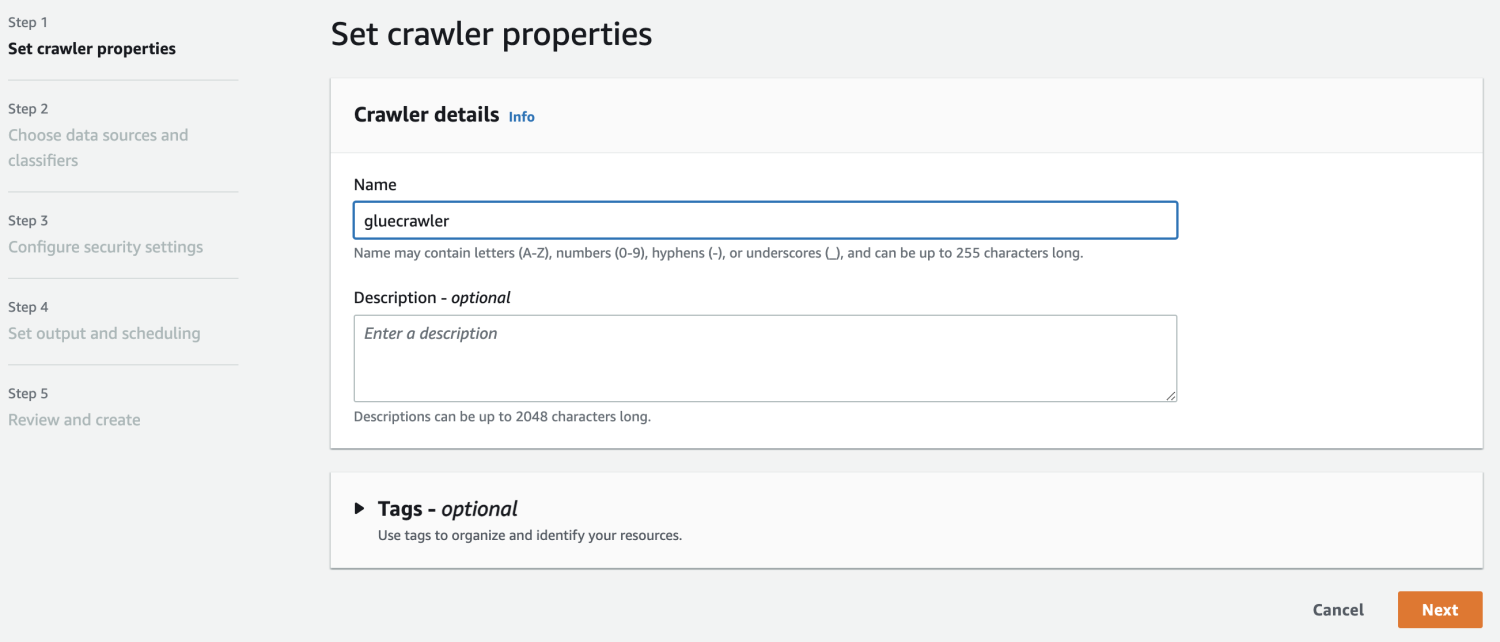
เมื่อคุณมีฐานข้อมูลใน AWS Glue แล้ว ให้สร้างโปรแกรมรวบรวมข้อมูล
ในแหล่งข้อมูล เลือกบัคเก็ต S3 ที่คุณสร้างขึ้น
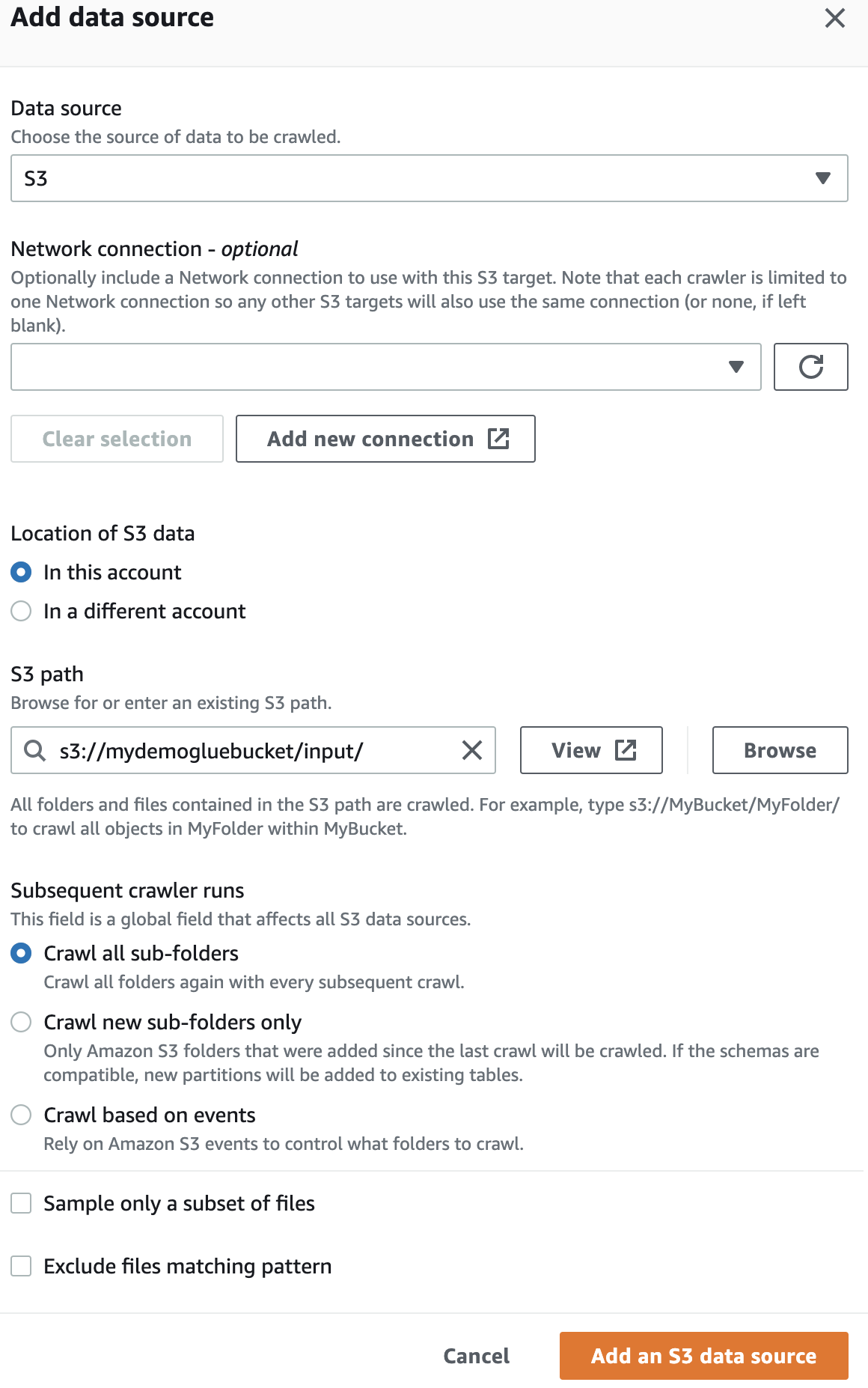
จากนั้นเลือกบทบาท IaM สำหรับ AWS Glue ที่คุณสร้างขึ้นในตอนเริ่มต้น
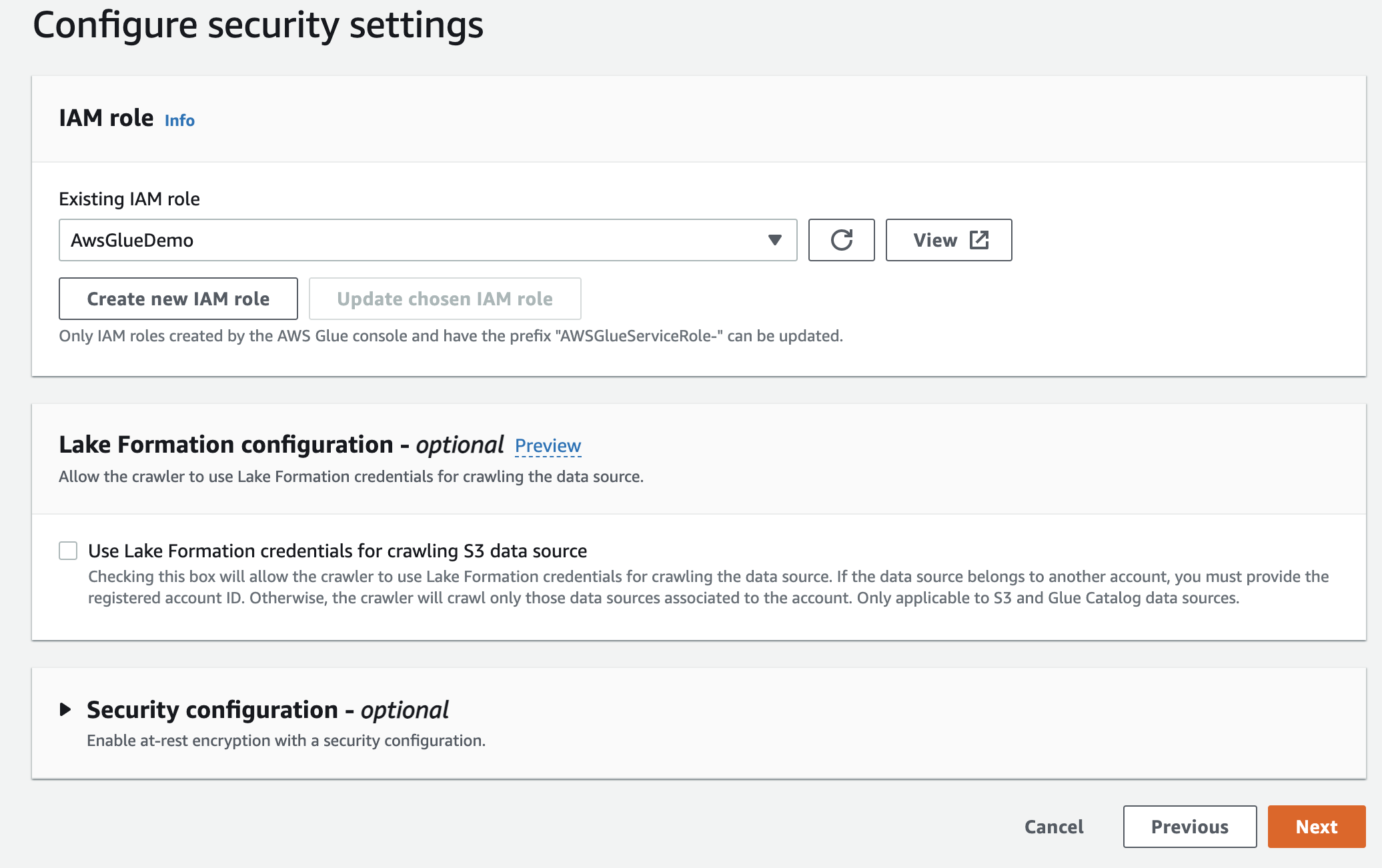
สุดท้ายในผลลัพธ์ ให้เลือก gluedb คุณสร้างขึ้น
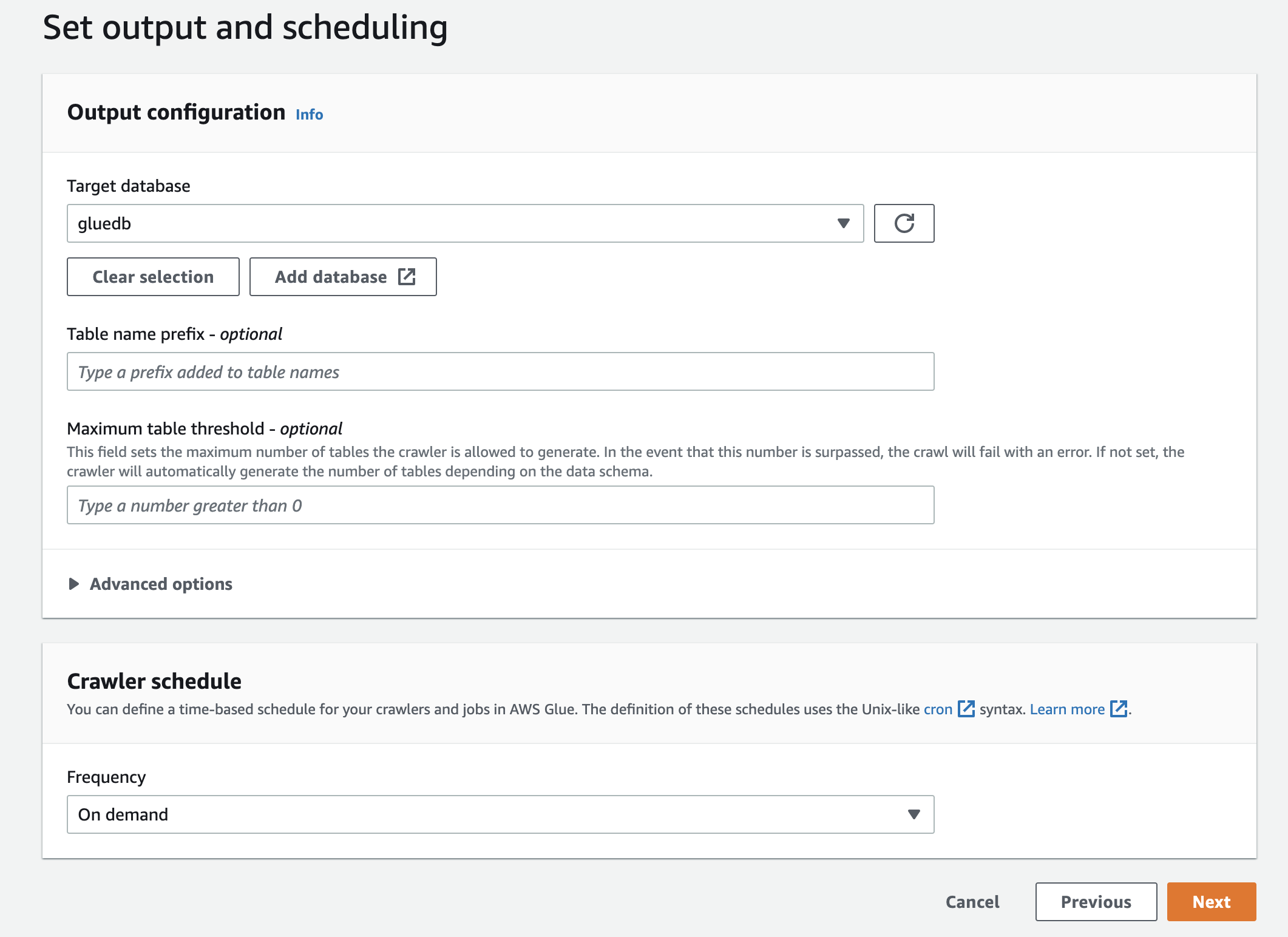
ตรวจสอบการตั้งค่าทั้งหมดและสร้างโปรแกรมรวบรวมข้อมูล
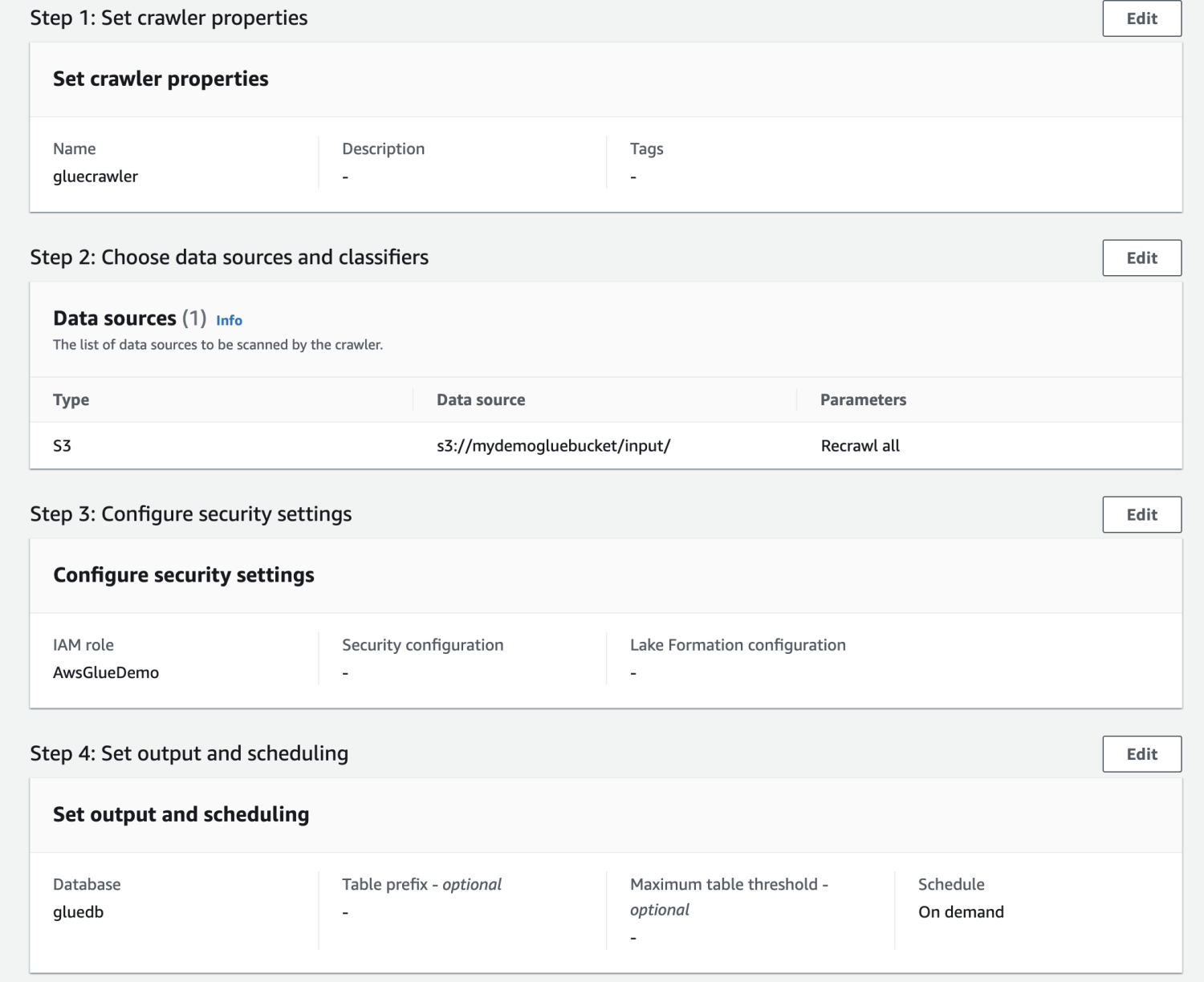
เมื่อสร้างโปรแกรมรวบรวมข้อมูลแล้ว ให้เลือกและคลิกเรียกใช้ หลังจากนั้นสักครู่ คุณจะได้รับสถานะพร้อม
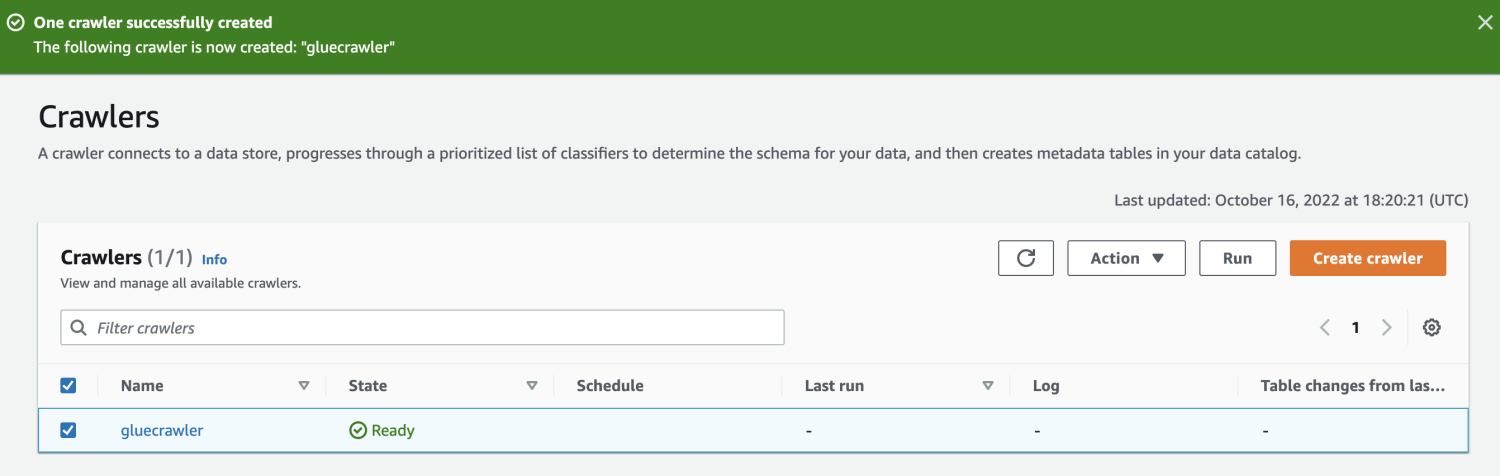
เมื่อเรียกใช้โปรแกรมรวบรวมข้อมูล ฐานข้อมูลจะได้รับตารางที่มีข้อมูลทั้งหมดจากไฟล์ CSV
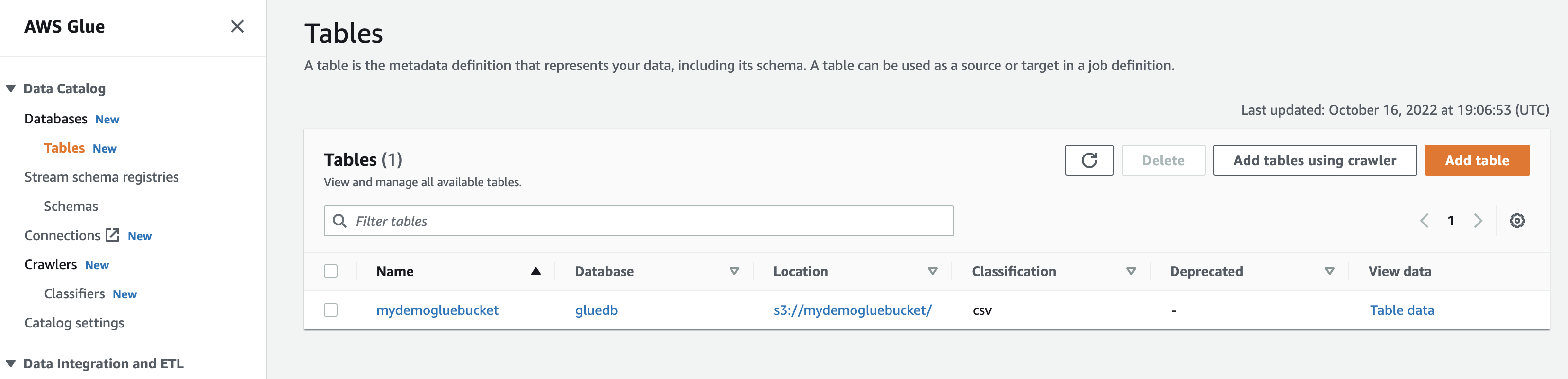
เมื่อคุณคลิกดูข้อมูล คุณจะถูกนำไปที่ Amazon Athena (ตัวแก้ไขแบบสอบถาม) เมื่อคุณเรียกใช้คิวรี คุณสามารถดูข้อมูลตารางได้
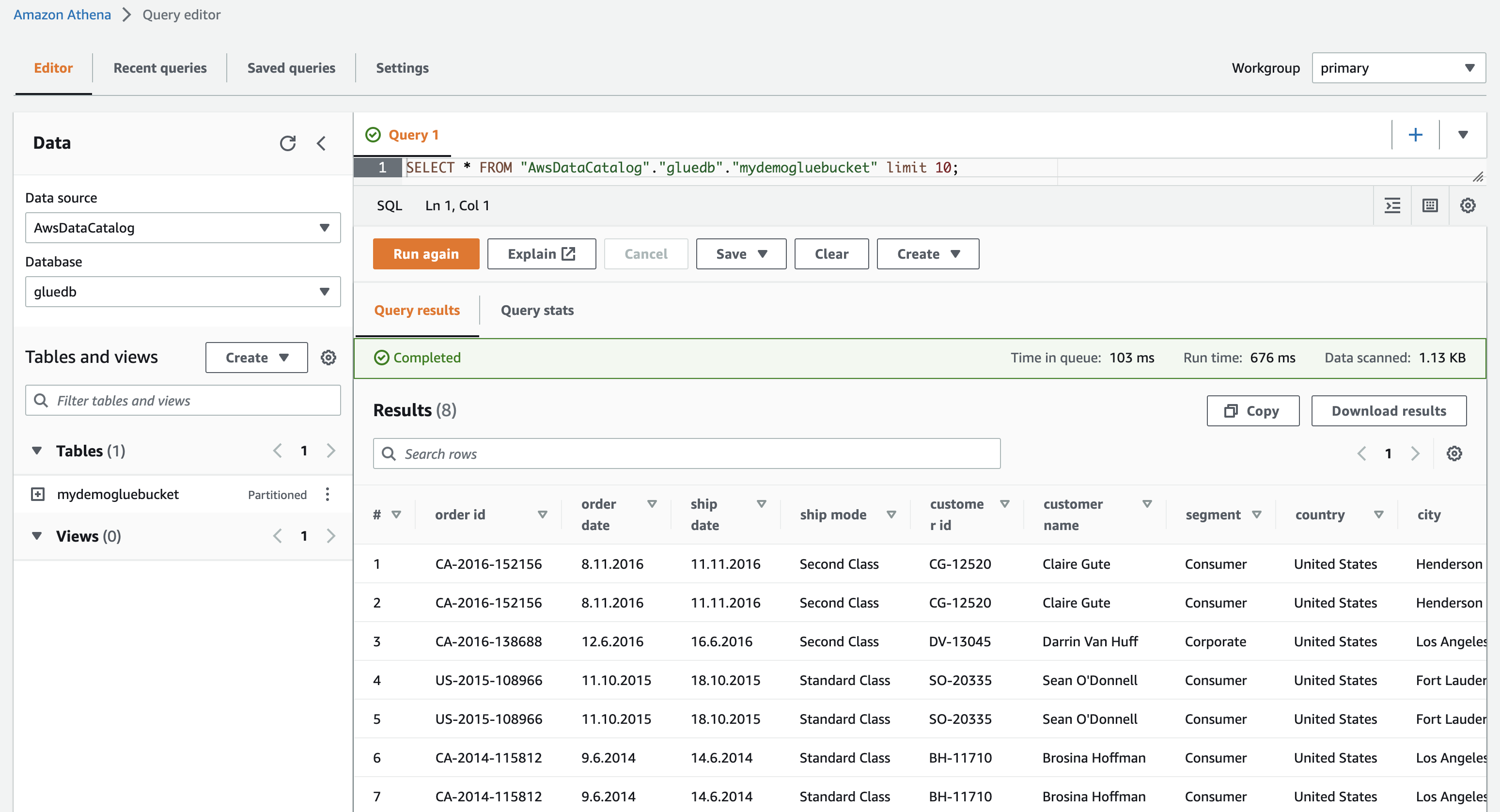
ตอนนี้คุณสามารถใช้โปรแกรมรวบรวมข้อมูล AWS Glue นี้ในงาน ETL ใด ๆ ได้สำเร็จ
AWS Glue Databrew คืออะไร
AWS Glue DataBrew อนุญาตให้ผู้ใช้ทำให้ข้อมูลเป็นมาตรฐานและล้างข้อมูลโดยไม่ต้องเขียนโค้ดใดๆ DataBrew สามารถลดเวลาที่ต้องใช้ในการเตรียมข้อมูลสำหรับการเรียนรู้ของเครื่องและการวิเคราะห์ได้มากถึง 80 เปอร์เซ็นต์ เมื่อเทียบกับการเตรียมข้อมูลที่พัฒนาขึ้นเอง
มีการแปลงข้อมูลที่สร้างไว้ล่วงหน้ามากกว่า 250 แบบที่สามารถใช้เพื่อทำให้งานการเตรียมข้อมูลเป็นแบบอัตโนมัติ เช่น การกรองความผิดปกติ การแก้ไขค่าที่ไม่ถูกต้อง และการแปลงข้อมูลเป็นรูปแบบมาตรฐาน
DataBrew ช่วยให้นักวิทยาศาสตร์ข้อมูล นักวิเคราะห์ธุรกิจ และวิศวกรทำงานร่วมกันในการดึงข้อมูลเชิงลึกจากข้อมูลดิบได้ง่ายขึ้น DataBrew ไม่มีเซิร์ฟเวอร์ ดังนั้นคุณไม่จำเป็นต้องจัดการโครงสร้างพื้นฐานหรือสร้างคลัสเตอร์เพื่อสำรวจและแปลงข้อมูลดิบมูลค่าเทราไบต์
คุณสมบัติ DataBrew สำหรับองค์กร
การเตรียมข้อมูลด้วยภาพ
DataBrew เป็นอีกวิธีหนึ่งในการดูข้อมูลที่โดยทั่วไปจะดูในฐานข้อมูลแบบคอลัมน์เป็นตัวเลขและตัวเลข DataBrew แสดงภาพแหล่งข้อมูลที่โหลดทั้งหมดเพื่อช่วยให้คุณเข้าใจความสัมพันธ์ของข้อมูลและลำดับชั้น
ระบบการเตรียมข้อมูลอัตโนมัติมากกว่า 250+ รายการ
นักวิทยาศาสตร์ด้านข้อมูลได้รับการคาดหวังให้ปฏิบัติตามขั้นตอนการทำงานที่ทำซ้ำและแยกได้หลากหลายซึ่งเป็นส่วนหนึ่งของงาน เวิร์กโฟลว์และกระบวนการเหล่านี้สร้างแบบจำลองโดย AWS เป็นภาษาและโมดูลโมดูลที่ไม่เชื่อเรื่องพระเจ้า ไลบรารีนี้มีการดำเนินการที่ผู้ใช้ปลายทางสามารถใช้ได้
สายข้อมูล
คล้ายกับบันทึกการตรวจสอบที่ใช้ในการติดตามกิจกรรมของลูกค้าในเครือข่าย IT ของเครือข่าย IT สายข้อมูลช่วยให้คุณสามารถติดตามกิจกรรมการแปลงข้อมูลภายใน AWS DataBrew ข้อมูลนี้รวมถึงแหล่งข้อมูล การแปลงที่ใช้ และเอาต์พุตข้อมูล รวมถึงตำแหน่งเป้าหมาย
การทำแผนที่ข้อมูล
Databrew ช่วยให้คุณค้นหาฟิลด์ที่ตรงกันในแหล่งข้อมูลสองแหล่ง เมื่อระบุฟิลด์ที่ตรงกันแล้ว จะสามารถโหลดลงในสคีมาได้
AWS Glue DataBrew: ประโยชน์
ด้านล่างนี้คือคุณสมบัติของ AWS Glue DataBrew:
- ด่านล่างสำหรับการป้อนข้อมูลเพื่อเตรียมข้อมูล
- การสร้างโปรไฟล์ข้อมูลอัตโนมัติ
- ดำเนินการเตรียมข้อมูลโดยอัตโนมัติมากกว่า 250 กระบวนการ
- คำแนะนำตามใบสั่งแพทย์อัจฉริยะ
ทางเลือกแทน AWS Glue
การไหลของอากาศ

Airflow อยู่ในส่วน Workflow Manager ของกองเทคโนโลยี เป็นเครื่องมือโอเพนซอร์ซที่รองรับดาว GitHub, ส้อม GitHub และคุณสมบัติอื่นๆ Airflow ช่วยให้คุณสร้างเวิร์กโฟลว์โดยใช้ไดอะแกรม acyclic แบบกำหนดทิศทาง (DAGs) ตัวกำหนดตารางเวลาการไหลของอากาศทำงานของคุณโดยใช้อาร์เรย์ของผู้ปฏิบัติงานและติดตามการพึ่งพาที่ระบุ
Matillion

Matillion ETL ซึ่งเป็นเครื่องมือ ETL/ELT ได้รับการออกแบบมาโดยเฉพาะสำหรับแพลตฟอร์มฐานข้อมูลบนคลาวด์ เช่น Amazon Redshift และ Google BigQuery เป็น UI ที่ใช้เบราว์เซอร์ที่ทันสมัยพร้อมความสามารถ ETL/ELT แบบกดลงอันทรงพลัง คุณสามารถใช้งานได้ในไม่กี่นาทีด้วยการตั้งค่าอย่างรวดเร็ว
ตะเข็บ
Stitch เป็นบริการ ETL แบบโอเพ่นซอร์สที่เชื่อมต่อแหล่งข้อมูลหลายแหล่งและจำลองข้อมูลไปยังปลายทางที่ต้องการ ใช้งานง่ายมาก เนื่องจากคุณไม่จำเป็นต้องมีความรู้ด้านการเขียนโค้ดใดๆ เพื่อย้ายข้อมูลระหว่างแหล่งที่มาและปลายทางใน Stitch ใช้งานง่าย มี GUI ที่เป็นมิตร และรวดเร็ว
Stitch ไม่อนุญาตให้คุณเลือกแดชบอร์ดที่สร้างไว้ล่วงหน้า ซึ่งแตกต่างจากเครื่องมือ ETL อื่นๆ คุณต้องรวมข้อมูลของคุณเข้ากับคลังข้อมูลแบบเปิดที่คุณเลือกเป็นปลายทางแทน การนำทางสินค้าคงคลังอาจเป็นเรื่องยาก
Alteryx

Alteryx เป็นแพลตฟอร์มการวิเคราะห์อัตโนมัติที่ช่วยในการเตรียมการรวบรวมข้อมูลและการผสมผสาน ข้อมูลนี้สามารถใช้เพื่อเร่งกระบวนการและให้ข้อมูลเชิงลึกทางธุรกิจ เนื่องจากเป็นเครื่องมือแบบลากและวาง คุณไม่จำเป็นต้องมีความรู้ด้านการเขียนโปรแกรมใดๆ Alteryx เป็นสถานที่ที่ดีเยี่ยมในการขอคำแนะนำและคำตอบจากผู้เชี่ยวชาญในอุตสาหกรรม
บทสรุป
นั่นคือทั้งหมดที่เกี่ยวกับ AWS Glue ซึ่งเป็นโซลูชันบนคลาวด์ที่ให้คุณทำงานกับไปป์ไลน์ ETL ได้ โดยสรุป กระบวนการโต้ตอบกับผู้ใช้ AWS Glue ประกอบด้วยสามขั้นตอน ในการสร้างแค็ตตาล็อกข้อมูล คุณต้องใช้โปรแกรมรวบรวมข้อมูลก่อน ถัดไป คุณสร้างรหัส ETL ที่จำเป็นสำหรับไปป์ไลน์ข้อมูล AWS ในที่สุด กำหนดการ ETL จะถูกสร้างขึ้น ฉันหวังว่าบล็อกนี้จะให้ภาพรวมที่ดีของ Amazon Glue แก่คุณ
คุณอาจสำรวจเคล็ดลับที่ดีที่สุดในการรักษาความปลอดภัยพื้นที่จัดเก็บ AWS S3