
AWS Glue について知らなかったこと
公開: 2022-10-18多くの企業がマネージド データ統合サービスを使用し始めたため、Amazon Glue の人気が高まっています。
ETL は、ソース データベースからデータ ウェアハウスにデータを転送するプロセスです。 ETL は複雑であり、その複雑さのためにすべての企業データに実装するのは困難です。 Amazon は、この問題に対処するために AWS Glue を導入しました。
ETL 開発者とデータ エンジニアは、Glue を使用して ETL ワークフローを構築、監視、実行します。
AWS Glue とは何ですか?
サーバーレスのデータ統合サービスである AWS Glue を使用すると、複数のソースからのデータを簡単に検索、準備、移動、統合できます。 これは、機械学習 (ML) と分析に役立ちます。
分析用のデータを準備するために必要な時間を大幅に短縮します。 データを自動的に検索して一覧表示し、Scala または Python コードを生成してソースからデータを送信し、時間指定されたイベントに従ってジョブをロードして変換します。
これにより、柔軟なスケジューリングが可能になり、対象となるデータの読み込みに合わせてスケーリングできる Apache Spark 環境が作成されます。 さらに、AWS Glue は複雑なデータ ストリームの監視と変更を提供します。 AWS Glue は、アプリケーション開発の複雑な操作を簡素化するサーバーレス サービスです。
複数の有効なデータをすばやく統合できます。 また、データをすばやく分解して承認します。
AWS Glue は何に使用されますか?
Amazon Glue を使用するのに最適な場所を知ることが重要です。 これらは、考慮すべき AWS Glue の使用例のほんの一部です。
- Amazon Glue は、Amazon S3 データレイクでサーバーレスクエリを実行できるツールです。
- Amazon Glue は、始めるのに最適なツールです。 すべてのデータに 1 つのインターフェイスからアクセスできるため、データを移動することなく分析できます。
- Amazon Glue を使用して、データ資産を理解できます。 Amazon Glue を使用すると、Data Catalog を使用してさまざまな AWS データセットを簡単に検索できます。 一貫したビューを維持しながら、Data Catalog を使用して複数の AWS サービスにわたってデータを保存することもできます。
- Glue は、イベント駆動型の ETL ワークフローを構築するときに役立ちます。 AWS Lambda サービスを介して Glue ETL タスクを呼び出すことにより、Amazon S3 から ETL オペレーションを実行できます。
- AWS Glue は、データレイクまたはウェアハウスに保存するためにデータをクリーニング、検証、フォーマット、整理するためにも使用できます。
AWS Glue のコンポーネント
以下は、AWS Glue の主なコンポーネントです。
- データ カタログ:このデータ カタログには、メタデータとデータ構造が含まれています。
- データベース:これは、ソースとターゲットのデータベースにアクセスして作成するための鍵です。
- テーブル:ターゲットとソースの両方で使用できる 1 つまたは複数のテーブルをデータベースに作成します。
- クローラーと分類子:クローラーは、組み込みまたはカスタムの分類を使用して、ソースからデータを取得します。 データ カタログに事前定義されたメタデータ テーブルを作成/使用します。
- ジョブ:これは、ETL タスクを実行するビジネス ロジックのジョブです。 このビジネス ロジックは、python および scala 言語を使用して Apache Spark によって内部的に記述されます。
- トリガー: ETL トリガーは、オンデマンドまたは特定の時間に ETL ジョブの実行を開始するデバイスです。
- 開発用のエンドポイント: ETL ジョブ スクリプトをテスト、開発、およびデバッグする環境を作成します。
AWS Glue の利点
これらは、職場や組織内で使用する利点です。
- AWS Glue は、クローラーで利用可能なすべてのデータをスキャンします。
- 最終的に処理されたデータは、多くの場所 (Amazon RDS と Amazon Redshift、Amazon S3 など) に保存できます。
- クラウドベースのサービスです。 オンプレミスのインフラストラクチャにお金を費やす必要はありません。
- サーバーレス ETL であるため、費用対効果の高い選択肢です。
- これは速い。 すぐに Python/Scala ETL コードが提供されます。
AWS Glue の主な機能
Amazon Glue には、データを統合するために必要なすべての機能が備わっているため、より良い洞察を得て、知識を使用して、数か月ではなく数分で新しい進歩を遂げることができます。 ここでは、知っておくべき機能をいくつか紹介します。
- ドラッグ アンド ドロップ インターフェイス:ドラッグ アンド ドロップのジョブ エディターにより、ETL プロセスを作成できます。 AWS Glue は、データの抽出、変換、アップロードに必要なコードをすぐに構築します。
- 自動スキーマ検出:さまざまなデータ ソースに接続するクローラーを作成するには、Glue サービスを使用できます。 データを整理し、関連情報を抽出します。 これらのデータは、ETL タスクによる ETL プロセスの監視に使用できます。
- ジョブのスケジューリング: Glue は、オンデマンドまたはスケジュールされたスケジュールに従って使用できます。 スケジューラを使用して複雑な ETL パイプラインを構築し、タスク間の依存関係を確立できます。
- コード生成: Glue Elastic Views を使用すると、独自のコードを記述することなく、さまざまなデータ ソースからのデータを組み合わせて複製するマテリアライズド ビューを簡単に作成できます。
- 組み込みの機械学習: Glue には、「FindMatches」と呼ばれる組み込みの機械学習機能が付属しています。 互いの完全なコピーではないレコードを重複排除します。
- 開発者エンドポイント: ETL コードを積極的に開発したい場合、Glue は、作成したコードを変更、デバッグ、およびテストできる開発者エンドポイントを提供します。
- Glue DataBrew:データ アナリストやデータ サイエンティストがデータのクリーニングと正規化を支援するために使用できるデータ準備ツールです。 Glue DataBrew のアクティブでビジュアルなインターフェイスを使用します。
AWS Glue の料金体系はどのようになっていますか?
AWS Glue は、クローラー (データの検出) と ETL ジョブ (データの処理とロード) に対して 1 秒ごとに請求される時間単位の料金を請求します。 AWS Glue データカタログにアクセスしてメタデータを保存するには、単純な月額料金が請求されます。
Amazon Glue は 0.44 ドルから。 以下の4つのプランからお選びいただけます。
- ETL タスク、開発エンドポイント、およびその他の ETL タスクは $0.44 で利用できます
- Crawlers インタラクティブ セッションは 0.44 ドルで利用可能
- DataBrew ジョブは $0.48 から
- 毎月のストレージと Data Catalog へのリクエストの料金は $1.00 です
AWS は無料の Glue プランを提供していません。 1 時間ごとに、DPU あたり $0.44 の費用がかかります。 平均すると、1 日あたり 21 ドルかかります。 料金はお住まいの地域によって異なる場合があります。
AWS Glue をセットアップする手順
Data Catalog を使用すると、データを移動することなく、複数の AWS データセットをすばやく見つけて検索できます。 データがカタログ化されると、すぐに Amazon Athena と Amazon EMR を使用してクエリと検索を行うことができます。
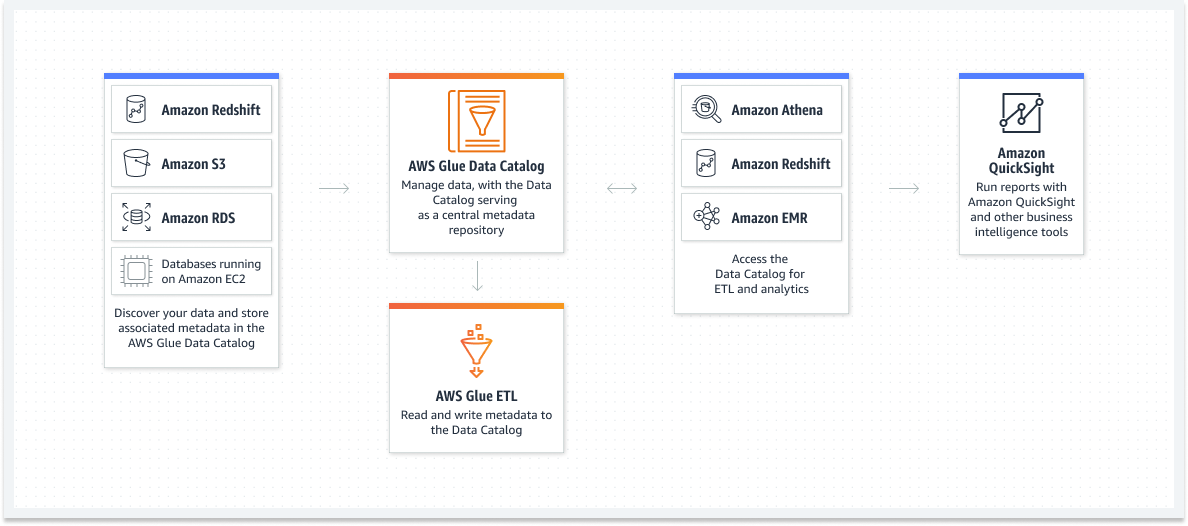
- Amazon Redshift、Amazon S3、Amazon RDS、および Amazon EC2 上のデータベース – データを検出し、メタデータを保存し、AWS Glue データカタログを使用してそれらを検出します
- AWS Glue データカタログ – メタデータの中央リポジトリとして機能するデータカタログでデータを管理します
- AWS Glue ETL – データカタログへのメタデータの読み取りと書き込み
- Amazon Athena と Amazon Redshift、Amazon EMR、Amazon ETL – ETL、分析などのデータカタログを入手してください。
- Amazon QuickSight – Amazon QuickSight やその他のビジネス インテリジェンス ツールを使用してレポートを実行する
AWS Glue のセットアップ方法?
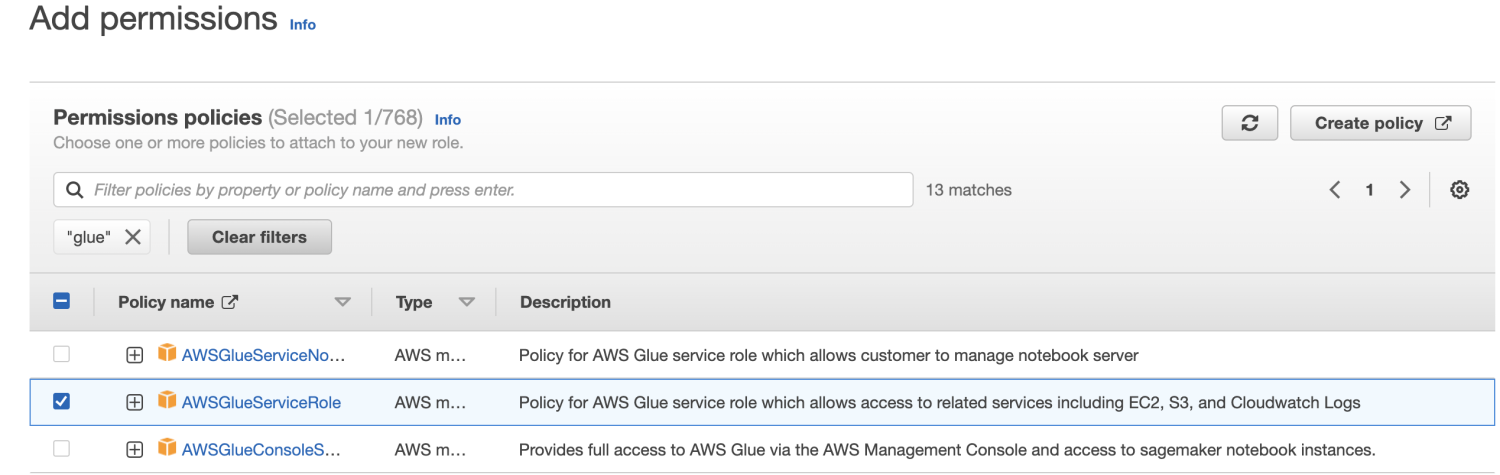
まず、AWS マネジメント コンソールにサインインし、IAM コンソールを開きます。 [ロールの作成] をクリックします。 次に、役割の種類として [Glue] を見つけ、 [アクセス許可]を選択します。
一般的な AWS Glue Studio と AWS Glue のアクセス許可にはAWSGlueServiceRoleを選択し、Amazon S3 リソースへのアクセスには AWS が管理するポリシー AmazonS3FullAccess を選択しています。
ロール名を入力します。
[ロールの作成] をクリックします。
Amazon S3 バケットを作成します。
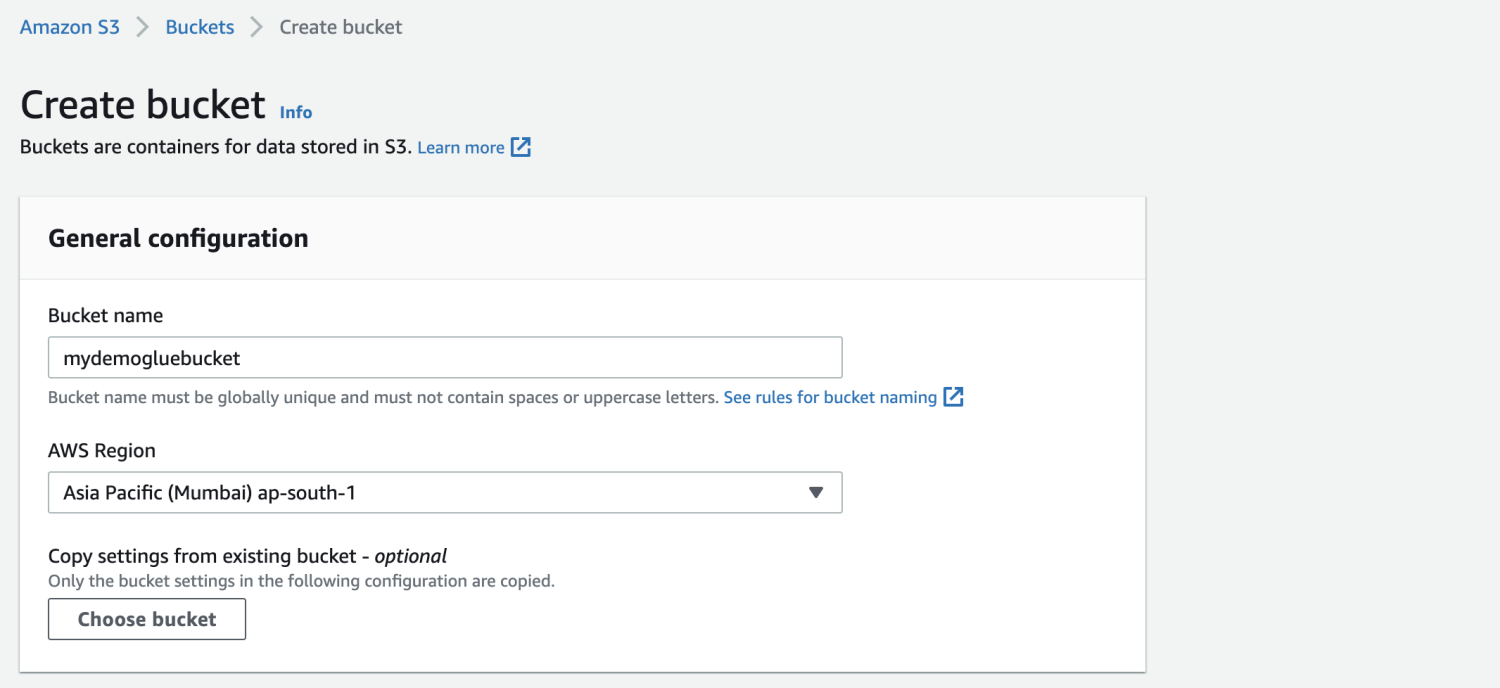
S3 バケット内にフォルダーを作成します。

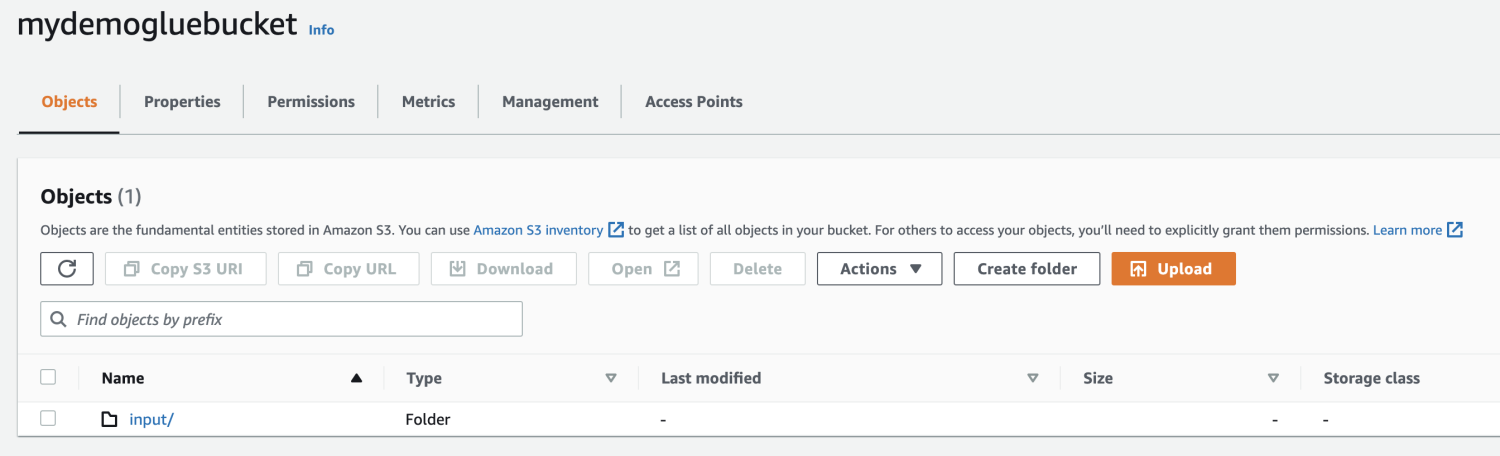
アップロードするファイルを選択します。
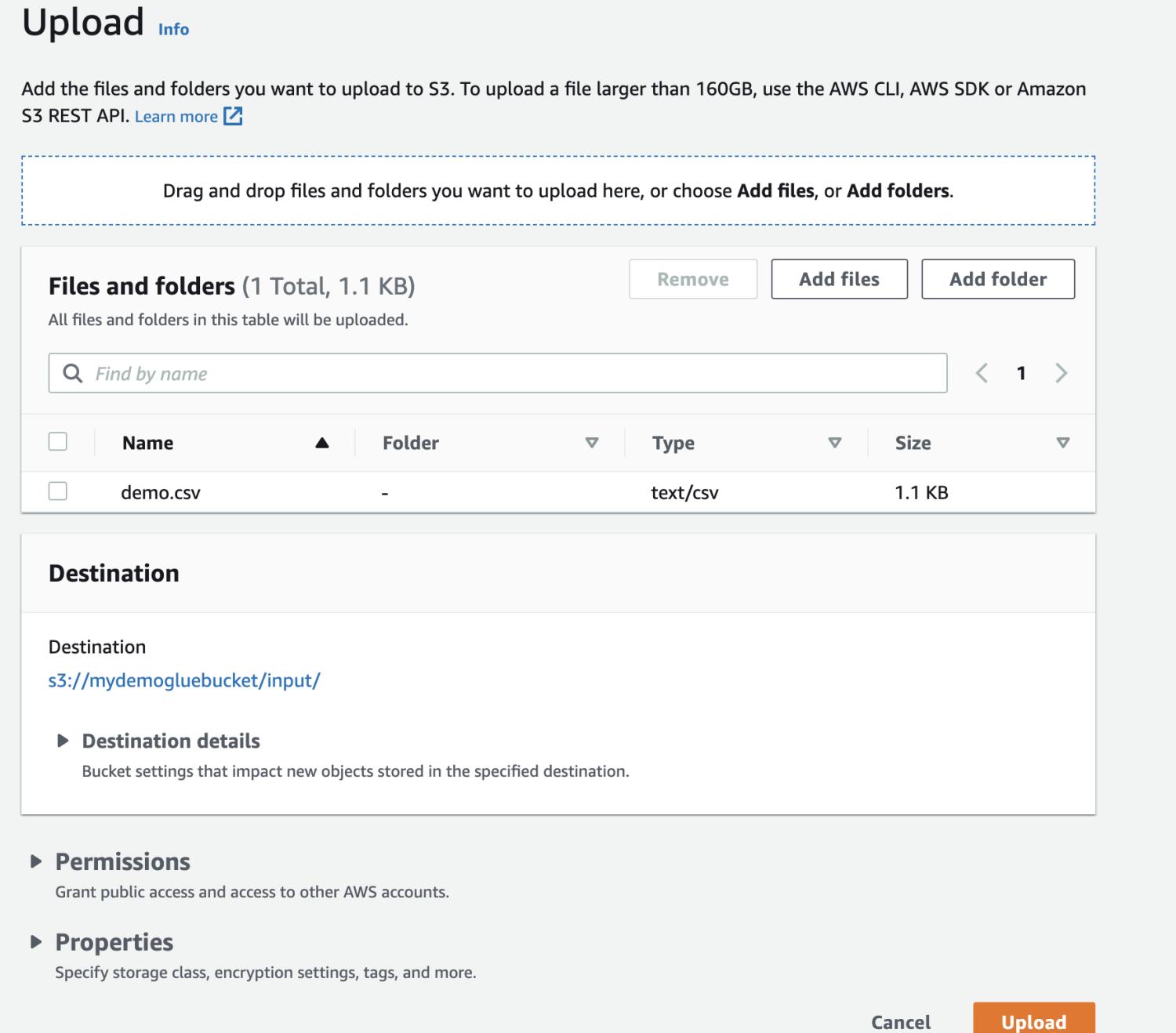
最後に、バケットにファイルをアップロードします。
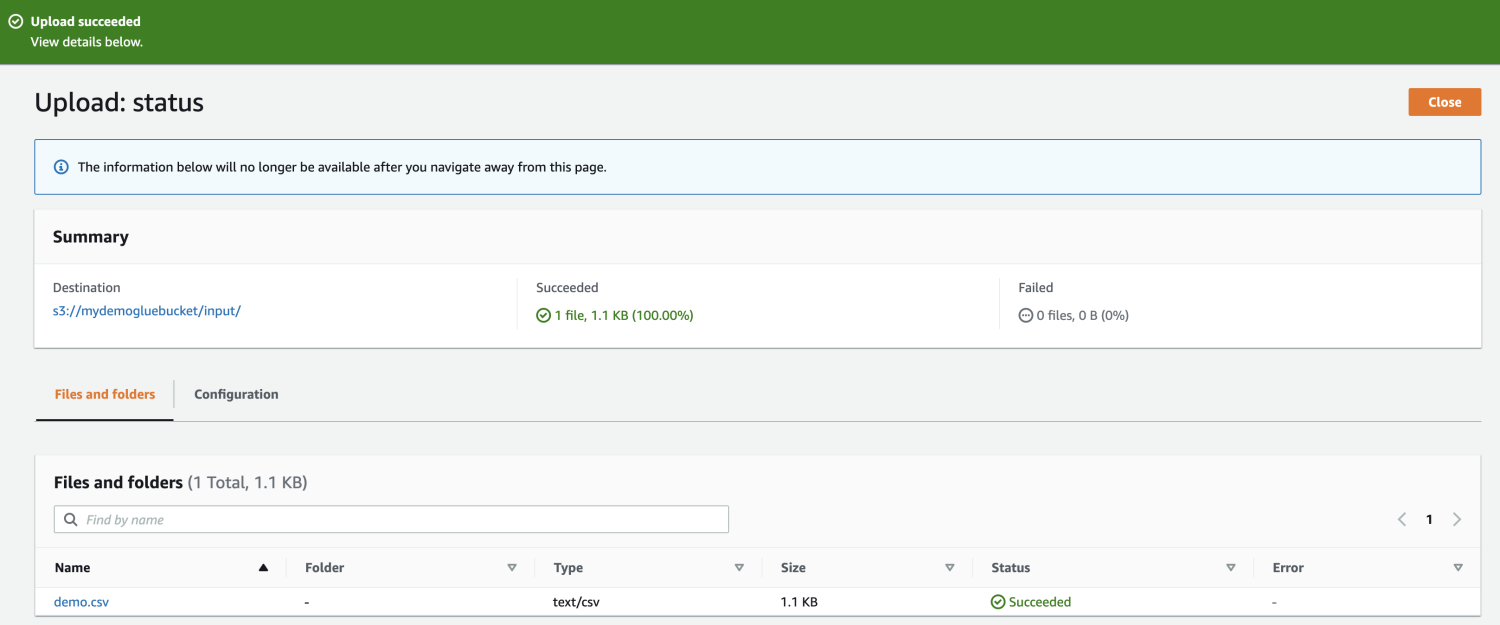
次に、AWS マネジメント コンソールから AWS Glue を開き、データベースを作成します。
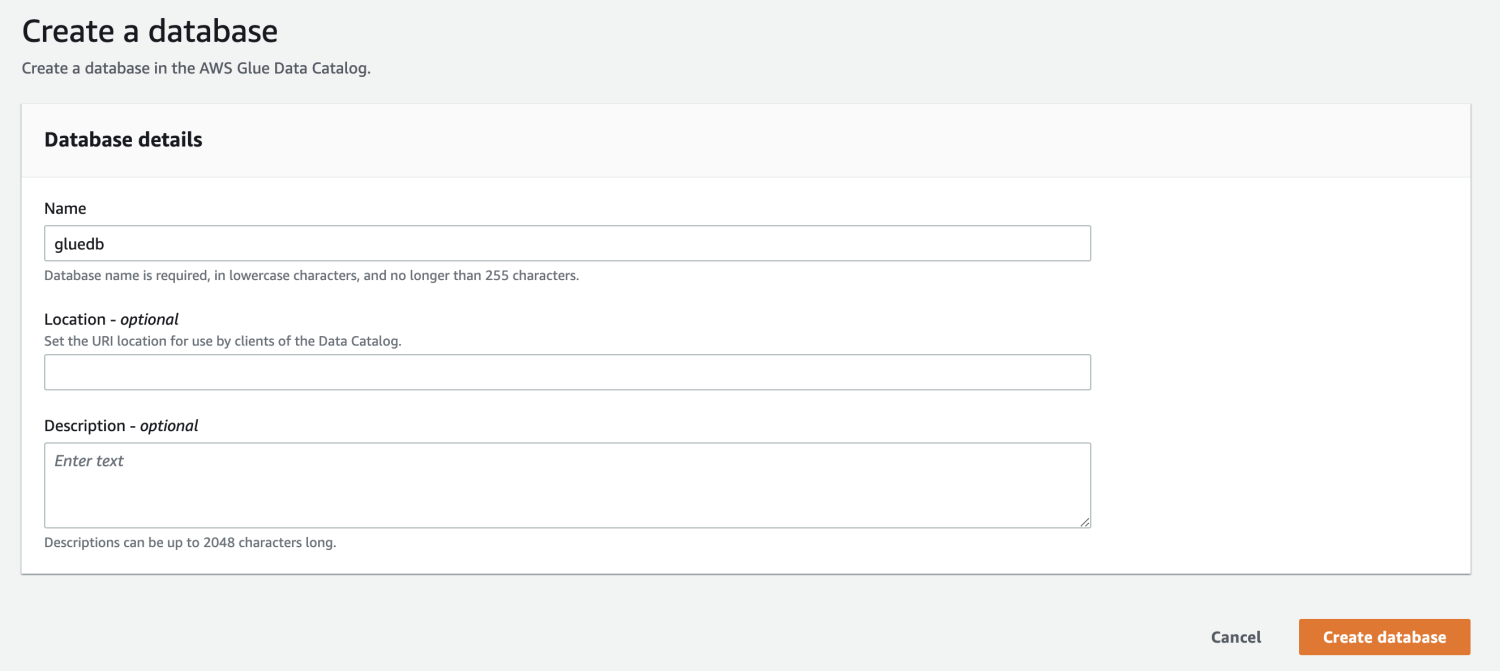
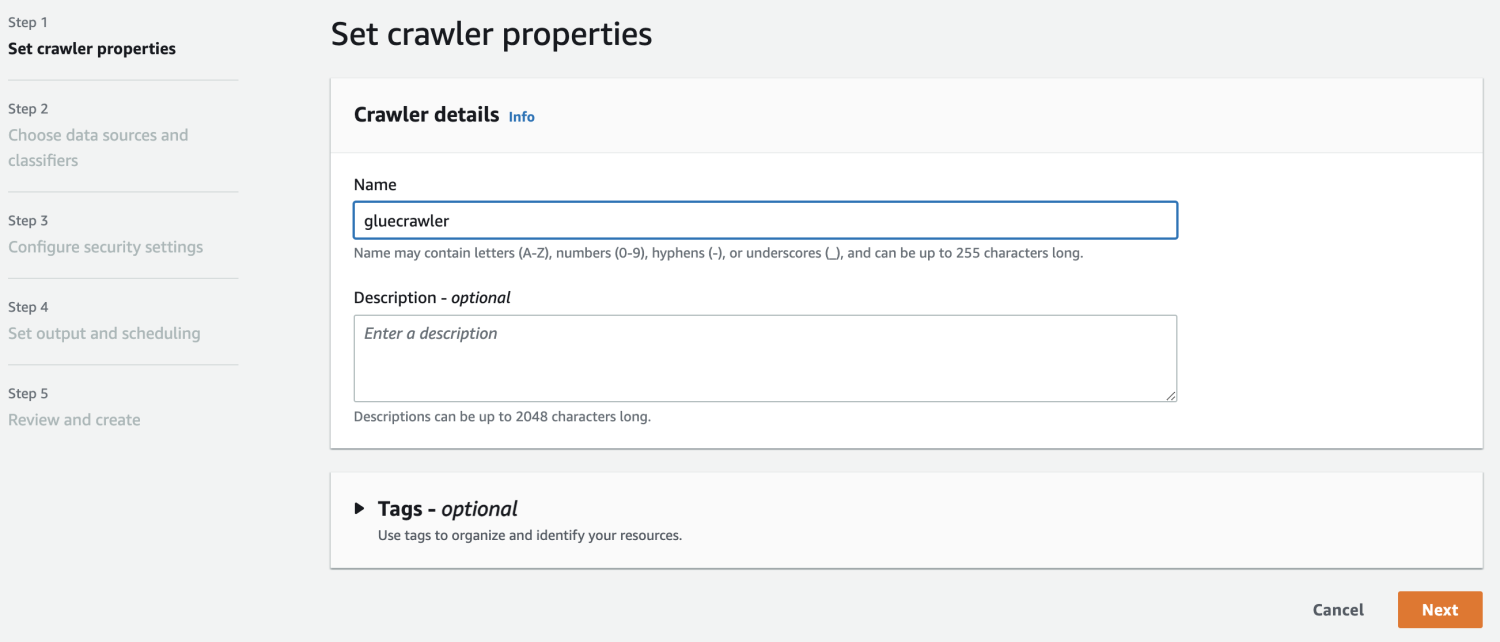
AWS Glue にデータベースができたので、クローラーを作成します。
データ ソースで、作成した S3 バケットを選択します。
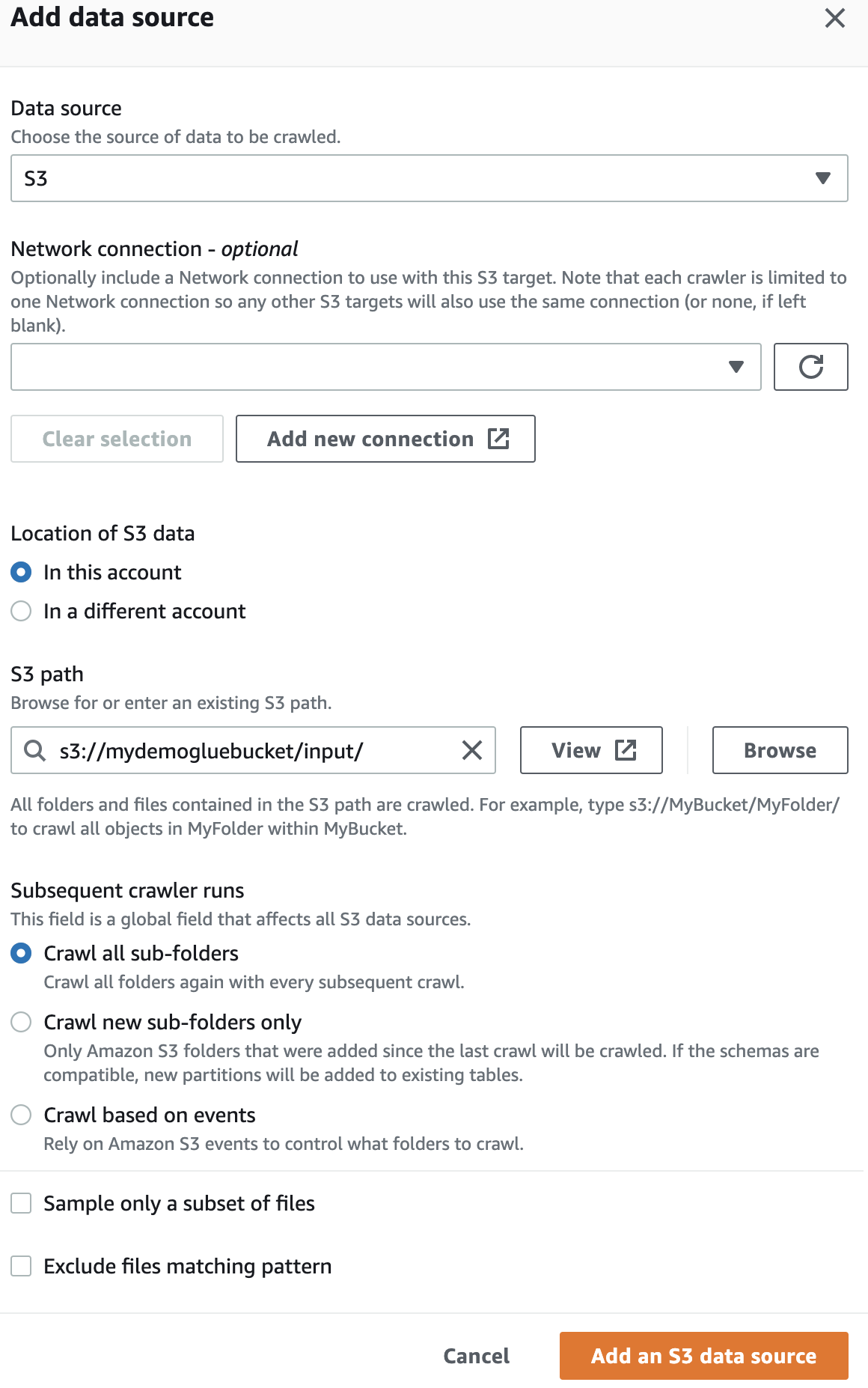
次に、最初に作成した AWS Glue の IaM ロールを選択します。
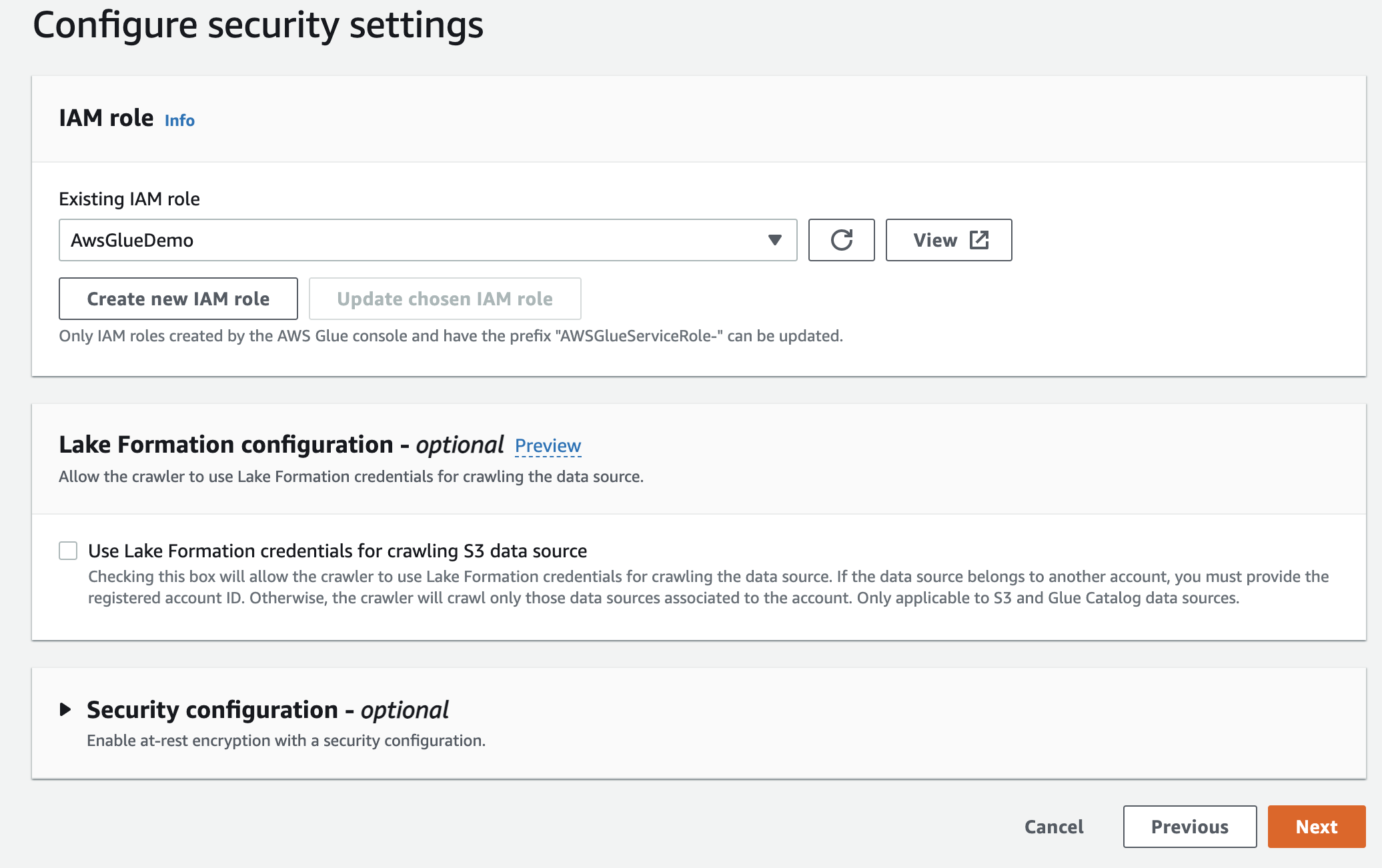
最後に、出力で、作成したgluedbを選択します。
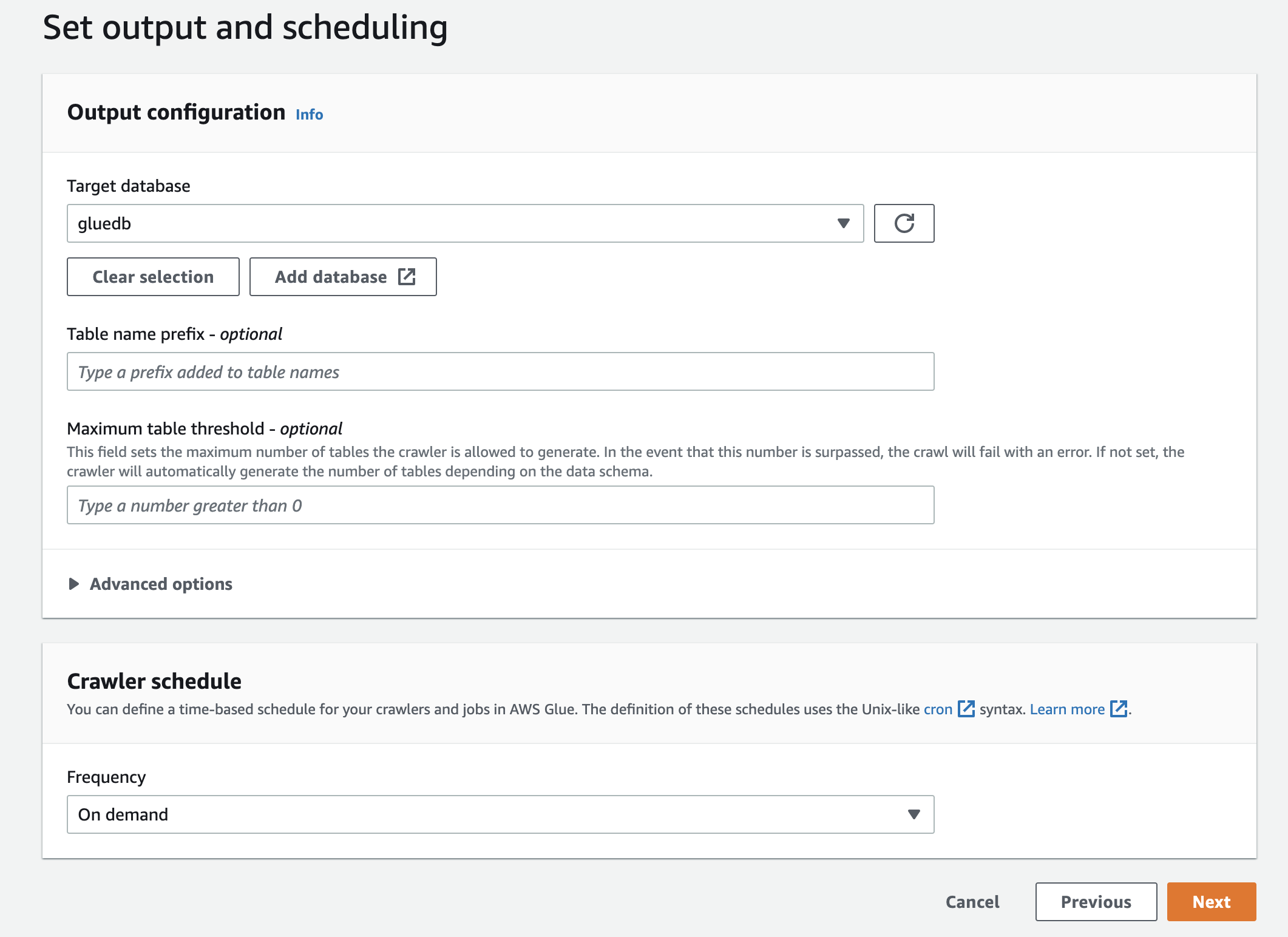
すべての設定を確認し、クローラーを作成します。
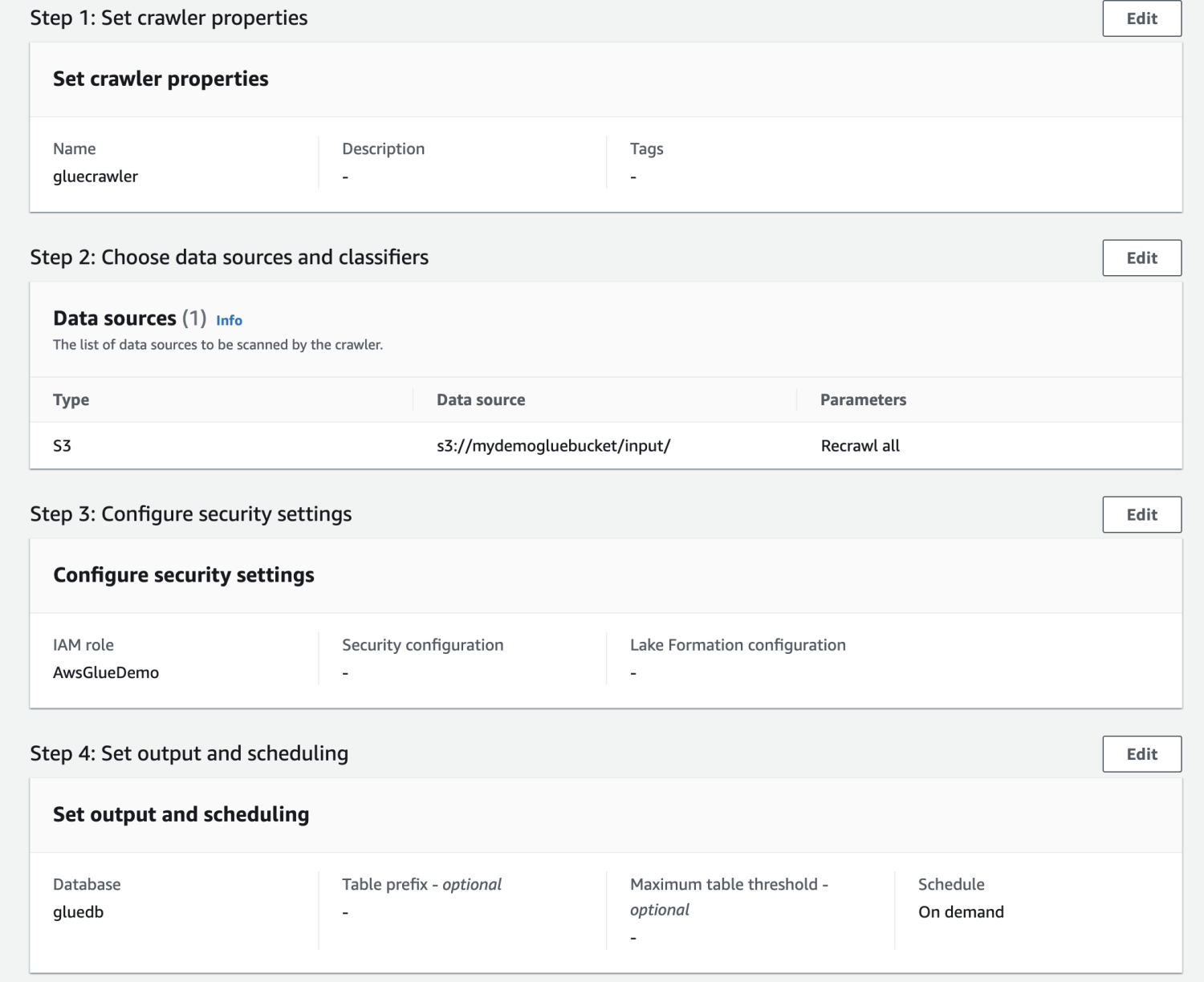
クローラーが作成されたら、それを選択して「実行」をクリックします。 しばらくすると、ステータスが準備完了になります。
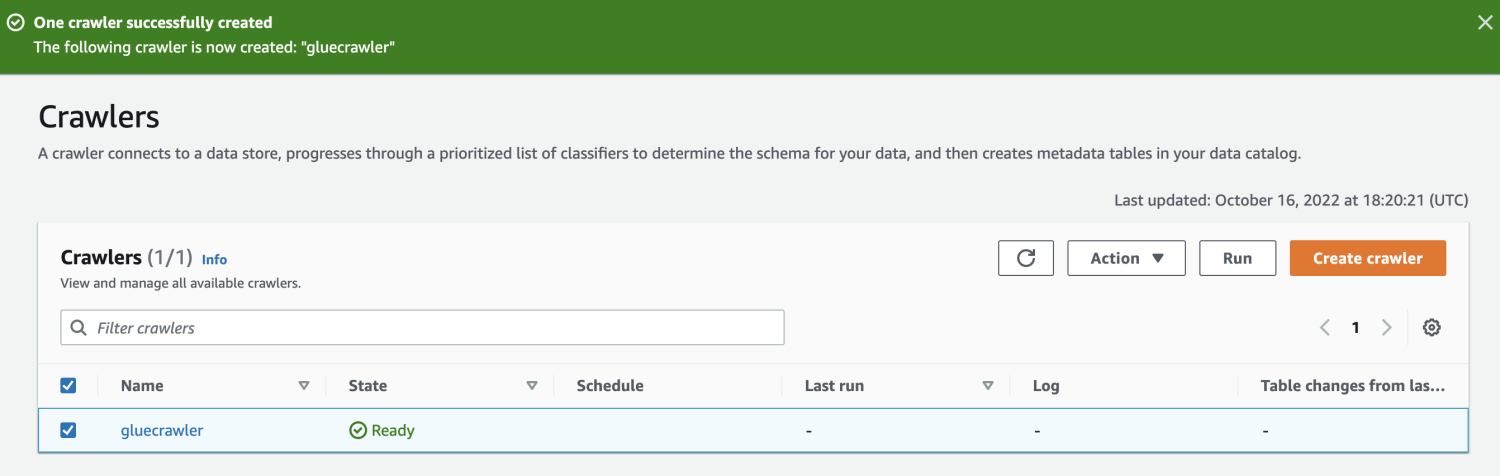
クローラーを実行すると、データベースは CSV ファイルからすべてのデータを含むテーブルを取得します。
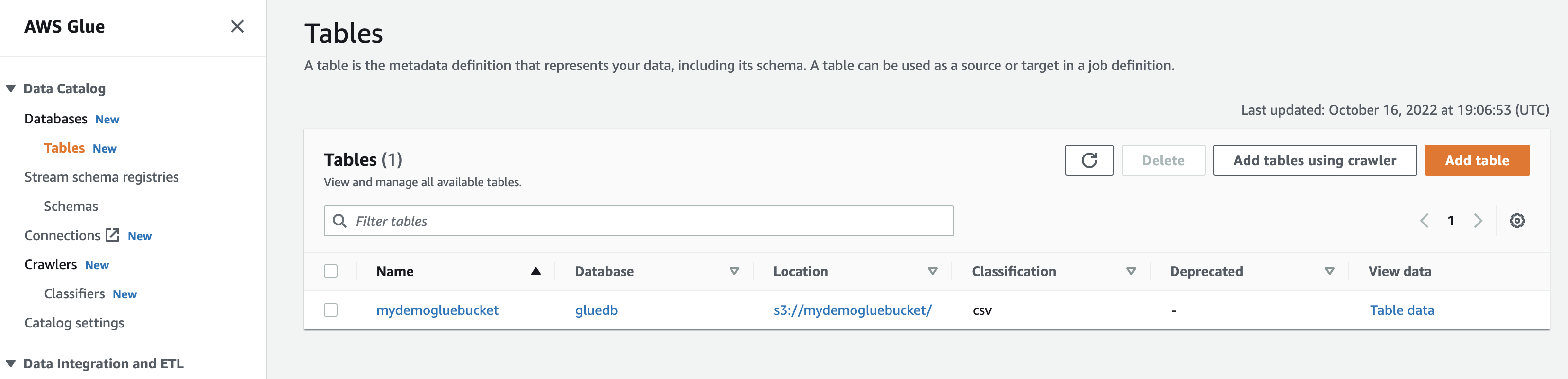
[データの表示] をクリックすると、Amazon Athena (クエリ エディター) に移動します。 クエリを実行すると、テーブル データが表示されます。
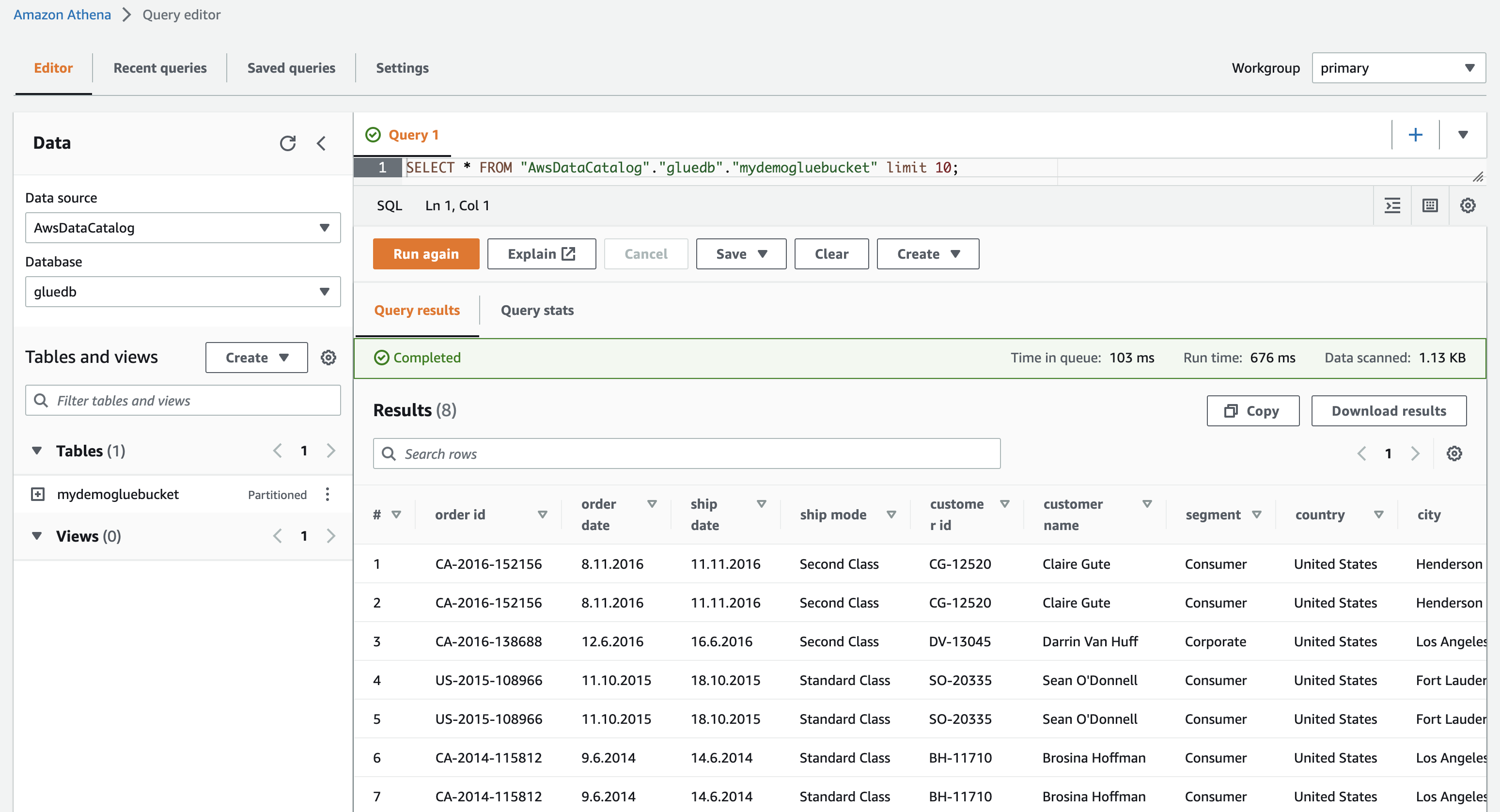
これで、この AWS Glue クローラーを任意の ETL ジョブで正常に使用できるようになりました。
AWS Glue Databrew とは?
AWS Glue DataBrew を使用すると、ユーザーはコードを記述せずにデータを正規化およびクリーンアップできます。 DataBrew は、カスタム開発されたデータ準備と比較して、機械学習と分析用のデータ準備に必要な時間を 80% も短縮できます。
異常のフィルタリング、無効な値の修正、データの標準形式への変換などのデータ準備タスクを自動化するために使用できる、250 を超える事前に作成されたデータ変換があります。
DataBrew を使用すると、データ サイエンティスト、ビジネス アナリスト、およびエンジニアが生データから洞察を抽出するために協力しやすくなります。 DataBrew はサーバーレスであるため、インフラストラクチャを管理したり、クラスターを作成して、テラバイト相当の生データを探索および変換したりする必要はありません。
エンタープライズ向けの DataBrew 機能
視覚化されたデータの準備
DataBrew は、通常は列型データベースで英数字として表示されるデータを表示する別の方法です。 DataBrew は、読み込まれたすべてのデータ ソースを視覚化して、データの関係と階層を理解するのに役立ちます。
250 以上のデータ準備の自動化
データ サイエンティストは、仕事の一環として、反復可能なさまざまな分離されたワークフローに従うことが期待されています。 これらのワークフローとプロセスは、AWS によって言語およびデータに依存しないモジュール モジュールとしてモデル化されています。 このライブラリには、エンド ユーザーが使用できるアクションが含まれています。
データ系統
IT ネットワークの IT ネットワークで顧客のアクティビティを追跡するために使用される監査ログと同様に、データリネージを使用すると、AWS DataBrew 内のデータ変換アクティビティを追跡できます。 この情報には、データ ソース、適用された変換、およびターゲットの場所を含むデータ出力が含まれます。
データ マッピング
Databrew を使用すると、2 つのデータ ソースで一致するフィールドを見つけることができます。 一致するフィールドが特定されると、それらをスキーマにロードできます。
AWS Glue DataBrew: 利点
以下は、AWS Glue DataBrew の機能です。
- データ準備の参入障壁を下げる
- 自動データプロファイル生成
- 250 以上のデータ準備プロセスを自動化
- インテリジェントな規範的提案
AWS Glue の代替
気流

Airflow は、技術スタックのワークフロー マネージャー セクションに属します。 これは、GitHub スター、GitHub フォーク、およびその他の機能をサポートするオープンソース ツールです。 Airflow を使用すると、有向非巡回図 (DAG) を使用してワークフローを作成できます。 Airflow スケジューラは、ワーカーの配列を使用し、指定された依存関係に従ってタスクを実行します。
マティリオン

ETL/ELT ツールである Matillion ETL は、Amazon Redshift や Google BigQuery などのクラウド データベース プラットフォーム用に明示的に設計されました。 これは、強力なプッシュダウン ETL/ELT 機能を備えた最新のブラウザーベースの UI です。 クイックセットアップで数分で起動して実行できます。
ステッチ
スティッチは、複数のデータ ソースを接続し、データを優先する宛先にレプリケートするオープン ソースの ETL サービスです。 コーディングの知識がなくても、Stitch でソースと宛先の間でデータを移動できるため、非常に簡単に使用できます。 使いやすく、使いやすい GUI を備え、高速です。
他の ETL ツールとは異なり、Stitch では既製のダッシュボードを選択することはできません。 代わりに、宛先として選択したオープン データ ウェアハウスにデータを統合する必要があります。 インベントリをナビゲートするのは難しい場合があります。
オルテックス

Alteryx は、データ収集の準備とブレンディングを支援する分析自動化プラットフォームです。 このデータを使用して、プロセスをスピードアップし、ビジネスの洞察を得ることができます。 ドラッグ アンド ドロップ ツールなので、プログラミングの知識は必要ありません。 Alteryx は、業界の専門家からアドバイスや回答を得るのに最適な場所です。
結論
以上が、ETL パイプラインを操作できるクラウドベースのソリューションである AWS Glue についてでした。 要約すると、AWS Glue のユーザー インタラクション プロセスは 3 つのフェーズで構成されています。 データ カタログを作成するには、まずデータ クローラーを使用します。 次に、AWS データ パイプラインに必要な ETL コードを作成します。 最後に、ETL スケジュールが作成されます。 このブログで Amazon Glue の概要を理解していただければ幸いです。
また、AWS S3 ストレージを保護するための最良のヒントを調べることもできます。