
Quello che non sapevi su AWS Glue
Pubblicato: 2022-10-18Amazon Glue sta guadagnando popolarità perché molte aziende hanno iniziato a utilizzare i servizi di integrazione dei dati gestiti.
ETL è un processo che trasferisce i dati da un database di origine a un data warehouse. ETL è complesso e difficile da implementare per tutti i dati aziendali a causa della sua complessità. Amazon ha introdotto AWS Glue per risolvere questo problema.
Gli sviluppatori ETL e gli ingegneri dei dati utilizzano Glue per creare, monitorare ed eseguire flussi di lavoro ETL.
Cos'è AWS Glue?
AWS Glue, un servizio di integrazione dei dati serverless, semplifica la ricerca, la preparazione, lo spostamento e l'integrazione dei dati da più origini. Ciò è utile per l'apprendimento automatico (ML) e l'analisi.
Riduce drasticamente il tempo necessario per preparare i dati per l'analisi. Trova ed elenca automaticamente i dati, genera codice Scala o Python per trasmettere i dati dalla sorgente e carica e trasforma il lavoro in base agli eventi a tempo.
Ciò consente una pianificazione flessibile e crea un ambiente Apache Spark che può essere ridimensionato per il caricamento dei dati mirato. Inoltre, AWS Glue fornisce il monitoraggio e l'alterazione di flussi di dati complessi. AWS Glue è un servizio serverless che semplifica le complicate operazioni di sviluppo delle applicazioni.
Consente la rapida integrazione di più dati validi. Inoltre, scompone e autorizza rapidamente i dati.
A cosa serve AWS Glue?
È importante conoscere i posti migliori in cui utilizzare Amazon Glue. Questi sono solo alcuni esempi degli usi di AWS Glue che dovresti considerare.
- Amazon Glue è uno strumento che consente di eseguire query serverless sui data lake Amazon S3.
- Amazon Glue è un ottimo strumento per iniziare. Rende tutti i tuoi dati accessibili su un'unica interfaccia, permettendoti di analizzarli senza doverli spostare.
- Amazon Glue può essere utilizzato per comprendere le tue risorse di dati. Amazon Glue ti consente di cercare facilmente diversi set di dati AWS utilizzando il Catalogo dati. Puoi anche salvare i dati su più servizi AWS utilizzando il Catalogo dati pur mantenendo una visualizzazione coerente.
- La colla può essere utile durante la creazione di flussi di lavoro ETL basati su eventi. Puoi eseguire le tue operazioni ETL da Amazon S3 chiamando le tue attività Glue ETL tramite un servizio AWS Lambda.
- AWS Glue può essere utilizzato anche per pulire, verificare, formattare e organizzare i dati per l'archiviazione in un data lake o in un warehouse.
Componenti di AWS Glue
Di seguito sono riportati i componenti principali di AWS Glue:
- Catalogo dati: questo catalogo dati contiene i metadati e la struttura dei dati.
- Database: questa è la chiave per accedere e creare il database per origini e destinazioni.
- Tabella: crea una o più tabelle nel database utilizzabili sia dalla destinazione che dall'origine.
- Crawler e classificatore: il crawler recupera i dati dall'origine utilizzando classificazioni integrate o personalizzate. Crea/utilizza tabelle di metadati predefinite nel catalogo dati.
- Lavoro: questo è il lavoro della logica aziendale per eseguire un'attività ETL. Questa logica di business è scritta internamente da Apache Spark utilizzando i linguaggi python e scala.
- Trigger: un trigger ETL è un dispositivo che avvia l'esecuzione di un lavoro ETL su richiesta o in un momento particolare.
- Endpoint per lo sviluppo: crea un ambiente in cui lo script del lavoro ETL viene testato, sviluppato e sottoposto a debug.
Vantaggi di AWS Glue
Questi sono i vantaggi di usarlo sul posto di lavoro o all'interno di un'organizzazione.
- AWS Glue esegue la scansione di tutti i dati disponibili con un crawler.
- I dati finali elaborati possono essere archiviati in molti luoghi (Amazon RDS e Amazon Redshift, Amazon S3, ecc.
- È un servizio basato su cloud. Non è necessario spendere soldi per le infrastrutture in sede.
- Poiché è un ETL serverless, è una scelta conveniente.
- È veloce. Ti dà immediatamente il codice ETL Python/Scala.
Funzionalità principali di AWS Glue
Amazon Glue ha tutte le funzionalità di cui hai bisogno per integrare i dati in modo da poter ottenere informazioni migliori e utilizzare le tue conoscenze per fare nuovi progressi in pochi minuti anziché mesi. Ecco alcune delle caratteristiche che dovresti conoscere.
- Interfaccia Drag and Drop: un editor di lavori drag-and-drop consente di creare un processo ETL. AWS Glue creerà immediatamente il codice necessario per estrarre, convertire e caricare i dati.
- Rilevamento automatico dello schema: per creare crawler che si connettono a diverse origini dati, puoi utilizzare il servizio Glue. Organizza i dati ed estrae le informazioni rilevanti. Questi dati possono quindi essere utilizzati per monitorare i processi ETL dalle attività ETL.
- Programmazione del lavoro: la colla può essere utilizzata su richiesta o secondo un programma programmato. Lo scheduler può essere utilizzato per creare pipeline ETL complesse, stabilendo dipendenze tra le attività.
- Generazione di codice: Glue Elastic Views ti consente di creare facilmente viste materializzate che combinano e replicano i dati da diverse origini dati senza dover scrivere alcun codice proprietario.
- Machine Learning integrato: Glue viene fornito con una funzionalità di Machine Learning integrata chiamata "FindMatches". Deduplica i record che non sono copie perfette l'uno dell'altro.
- Endpoint per sviluppatori : se desideri sviluppare attivamente il tuo codice ETL, Glue fornisce endpoint per sviluppatori che ti consentono di modificare, eseguire il debug e testare il codice che crea.
- Glue DataBrew: è uno strumento di preparazione dei dati che può essere utilizzato da analisti di dati e scienziati di dati per aiutarli a pulire e normalizzare i dati. Utilizza l'interfaccia attiva e visiva di Glue DataBrew.
Come funzionano i prezzi di AWS Glue?
AWS Glue addebita una tariffa oraria, che viene fatturata al secondo per i crawler (scoperta dei dati) e i lavori ETL (elaborazione e caricamento dei dati). Viene addebitata una semplice tariffa mensile per l'accesso e l'archiviazione dei metadati nel Catalogo dati di AWS Glue.
Amazon Glue parte da $ 0,44. Puoi scegliere tra quattro piani:
- Le attività ETL, gli endpoint di sviluppo e altre attività ETL sono disponibili a $ 0,44
- Le sessioni interattive dei crawler sono disponibili a $ 0,44
- I lavori di DataBrew partono da $ 0,48
- L'archiviazione mensile e le richieste al Catalogo dati costano $ 1,00
AWS non offre un piano Glue gratuito. Ogni ora costerà $ 0,44 per DPU. In media, ti costerebbe $ 21 al giorno. I prezzi possono variare a seconda di dove vivi.
Passaggi per configurare AWS Glue
Il Catalogo dati può essere utilizzato per trovare e cercare rapidamente più set di dati AWS senza dover spostare i dati. Dopo che i dati sono stati catalogati, sono immediatamente disponibili per query e ricerche utilizzando Amazon Athena e Amazon EMR.
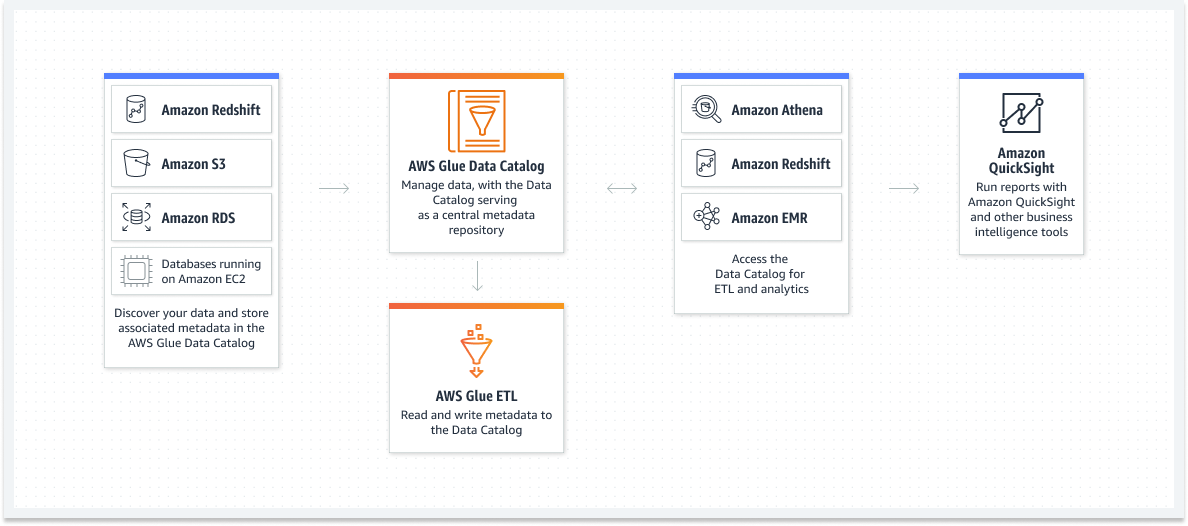
- Amazon Redshift, Amazon S3, Amazon RDS e database su Amazon EC2: scopri i tuoi dati, archivia i metadati e utilizza il catalogo dati di AWS Glue per scoprirli
- Catalogo dati AWS Glue: gestisci i dati con il catalogo dati che funge da repository centrale per i metadati
- AWS Glue ETL: leggi e scrivi metadati nel tuo catalogo dati
- Amazon Athena e Amazon Redshift, Amazon EMR, Amazon ETL: ottieni il catalogo dati per ETL, analisi e altro ancora.
- Amazon QuickSight: esegui report con Amazon QuickSight e altri strumenti di business intelligence
Come configurare AWS Glue?
Innanzitutto, accedi alla Console di gestione AWS e apri la console IAM. Fare clic su Crea ruolo. Quindi, per il tipo di ruolo , trova Colla e seleziona Autorizzazioni .
Scelgo AWSGlueServiceRole per le autorizzazioni generali di AWS Glue Studio e AWS Glue e la policy gestita da AWS AmazonS3FullAccess per l'accesso alle risorse Amazon S3.
Immettere un nome di ruolo.
Fare clic su Crea ruolo.
Crea un bucket Amazon S3.

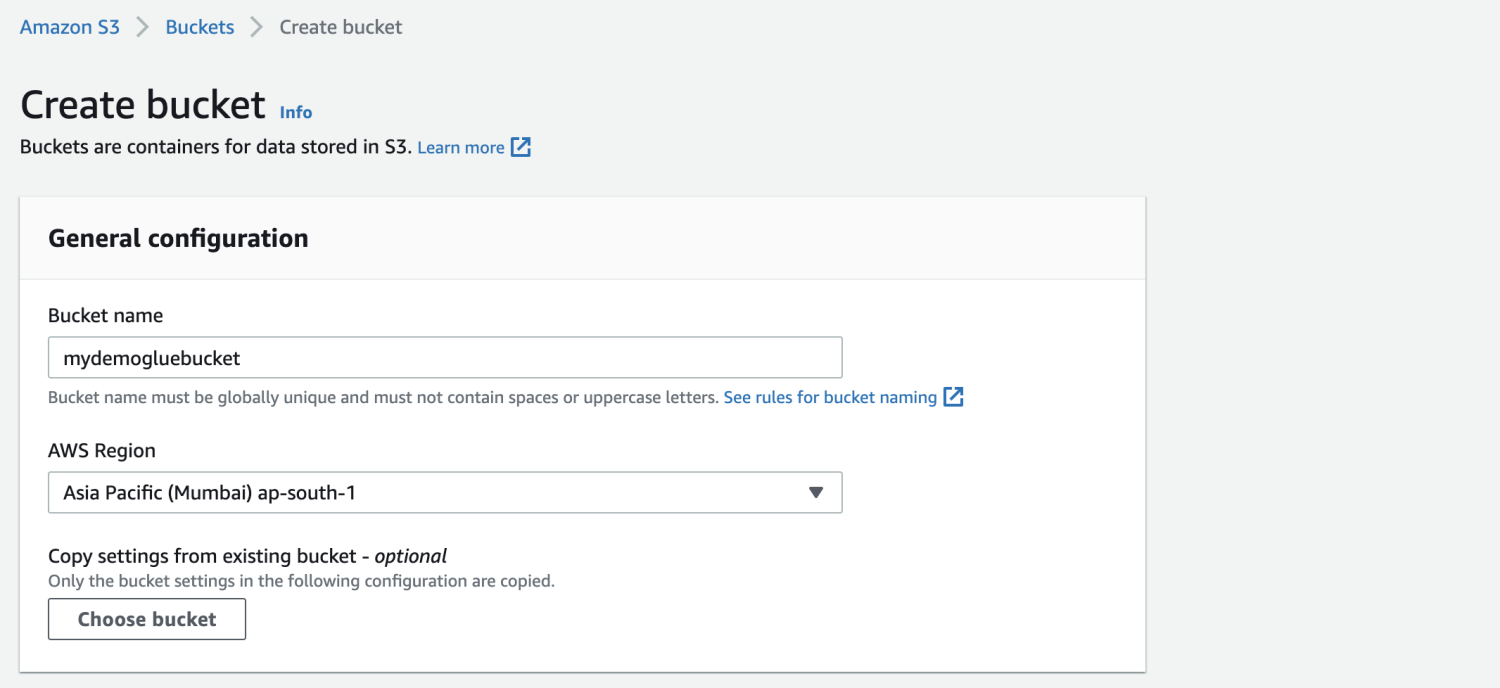
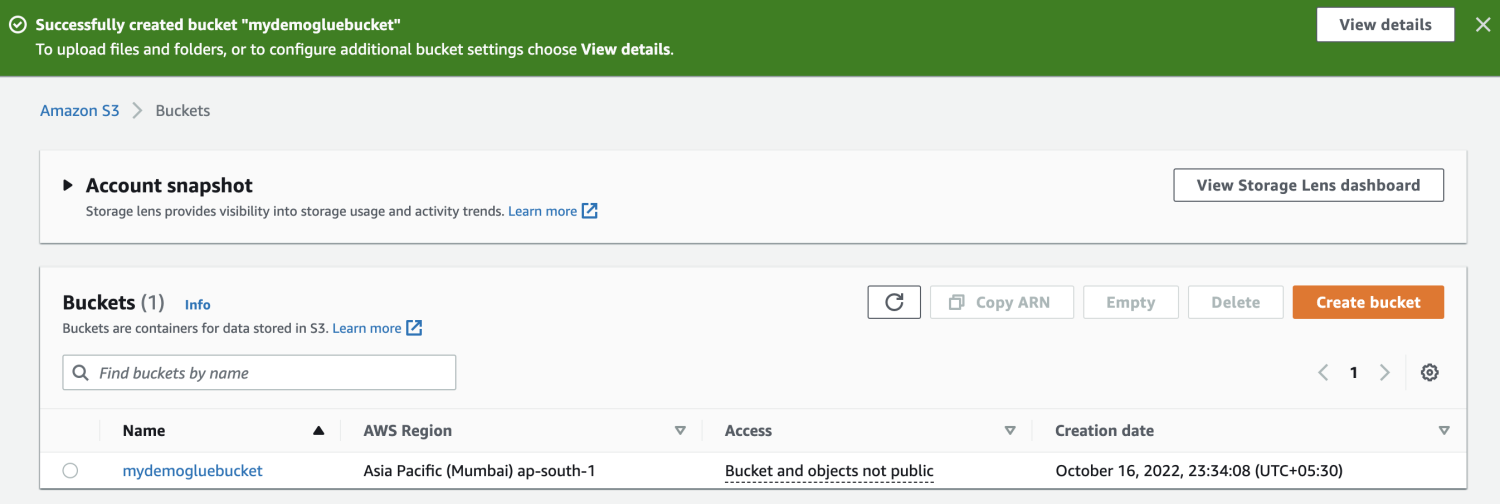
Crea una cartella all'interno del bucket S3.
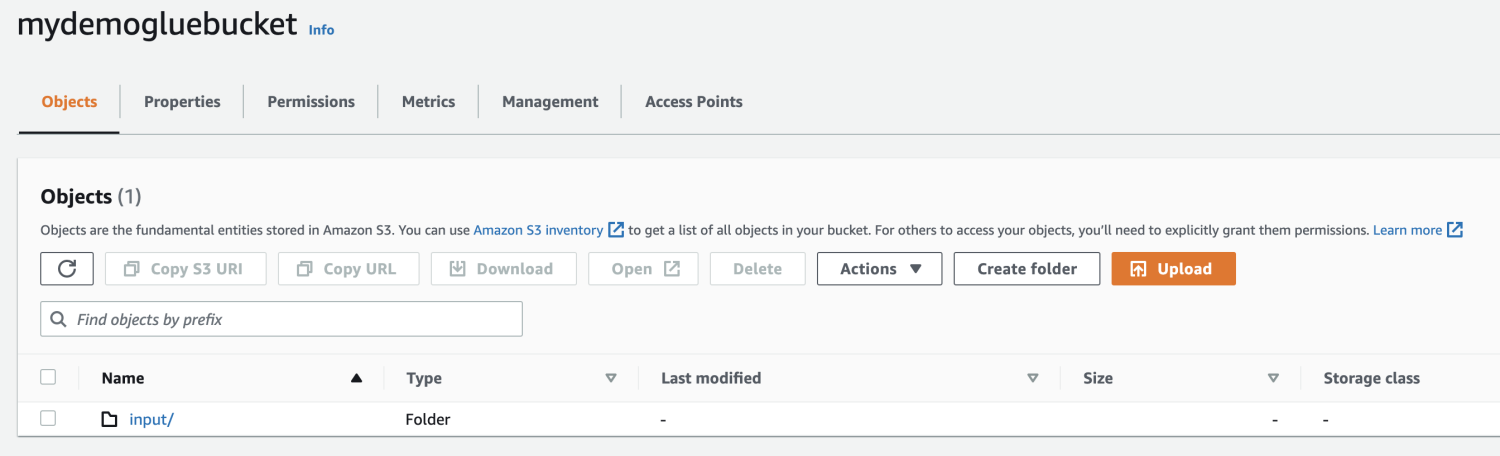
Scegli il file da caricare.
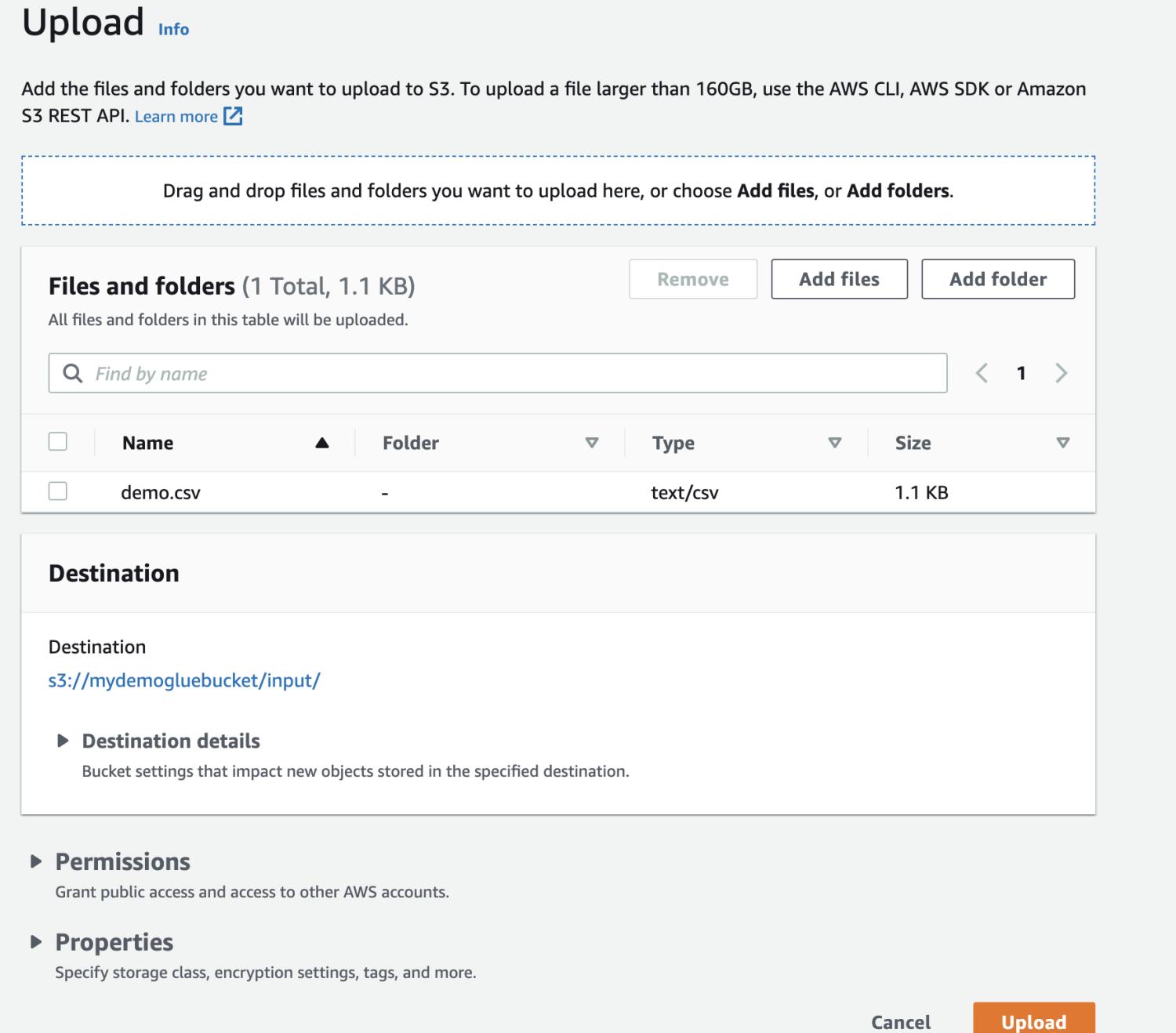
Infine, carica il file nel bucket.
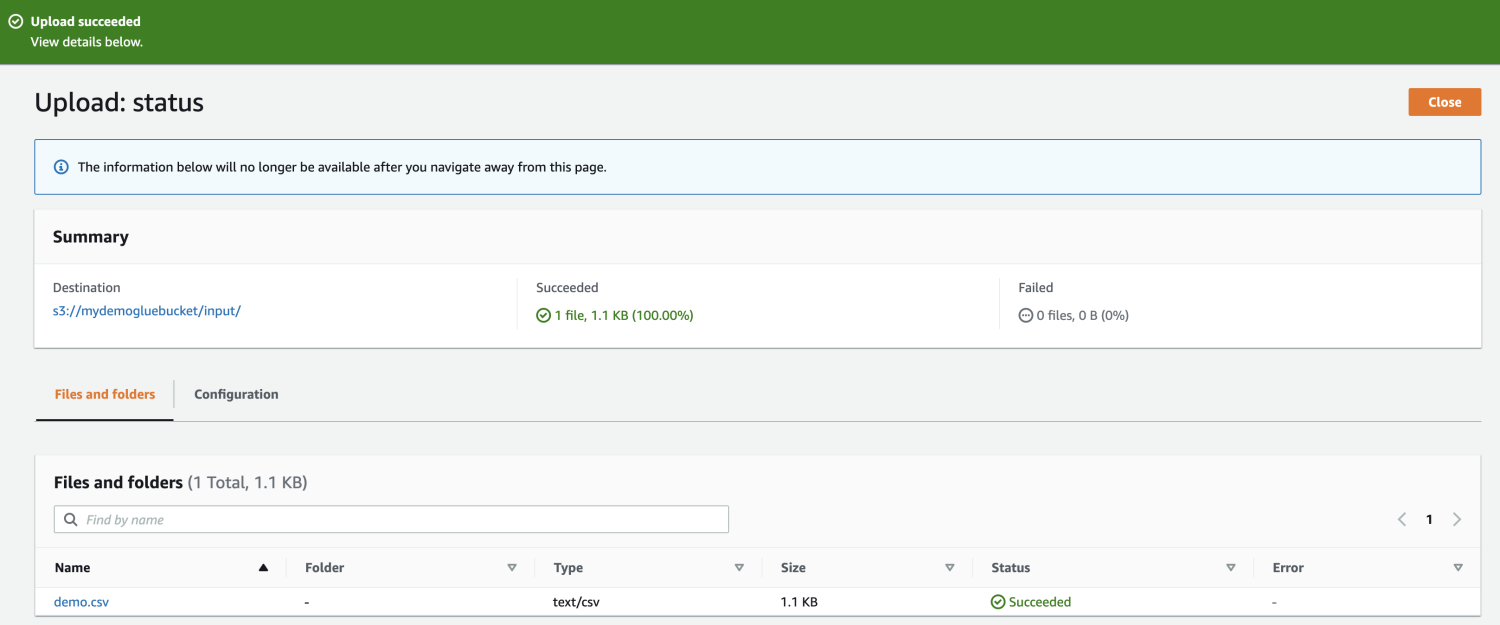
Quindi, apri AWS Glue dalla console di gestione AWS e crea un database.
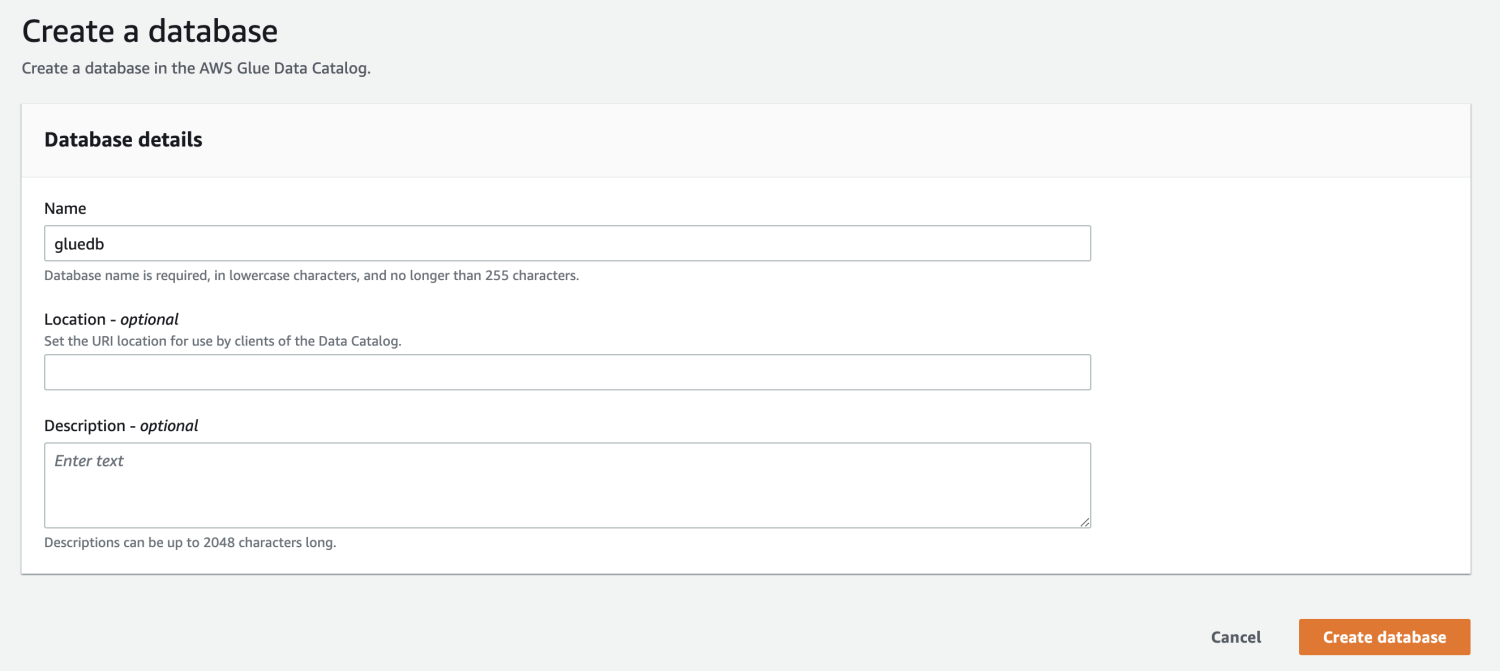
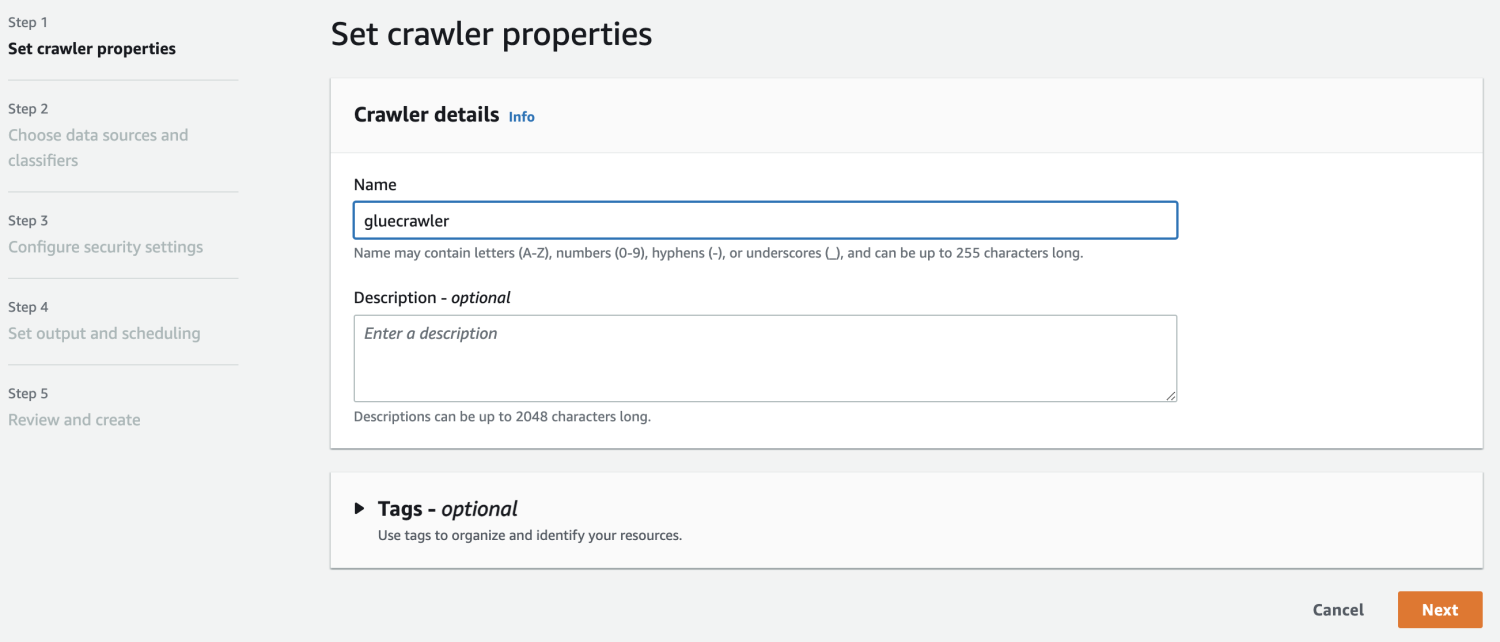
Ora che hai un database in AWS Glue, crea un crawler.
Nell'origine dati, seleziona il bucket S3 che hai creato.
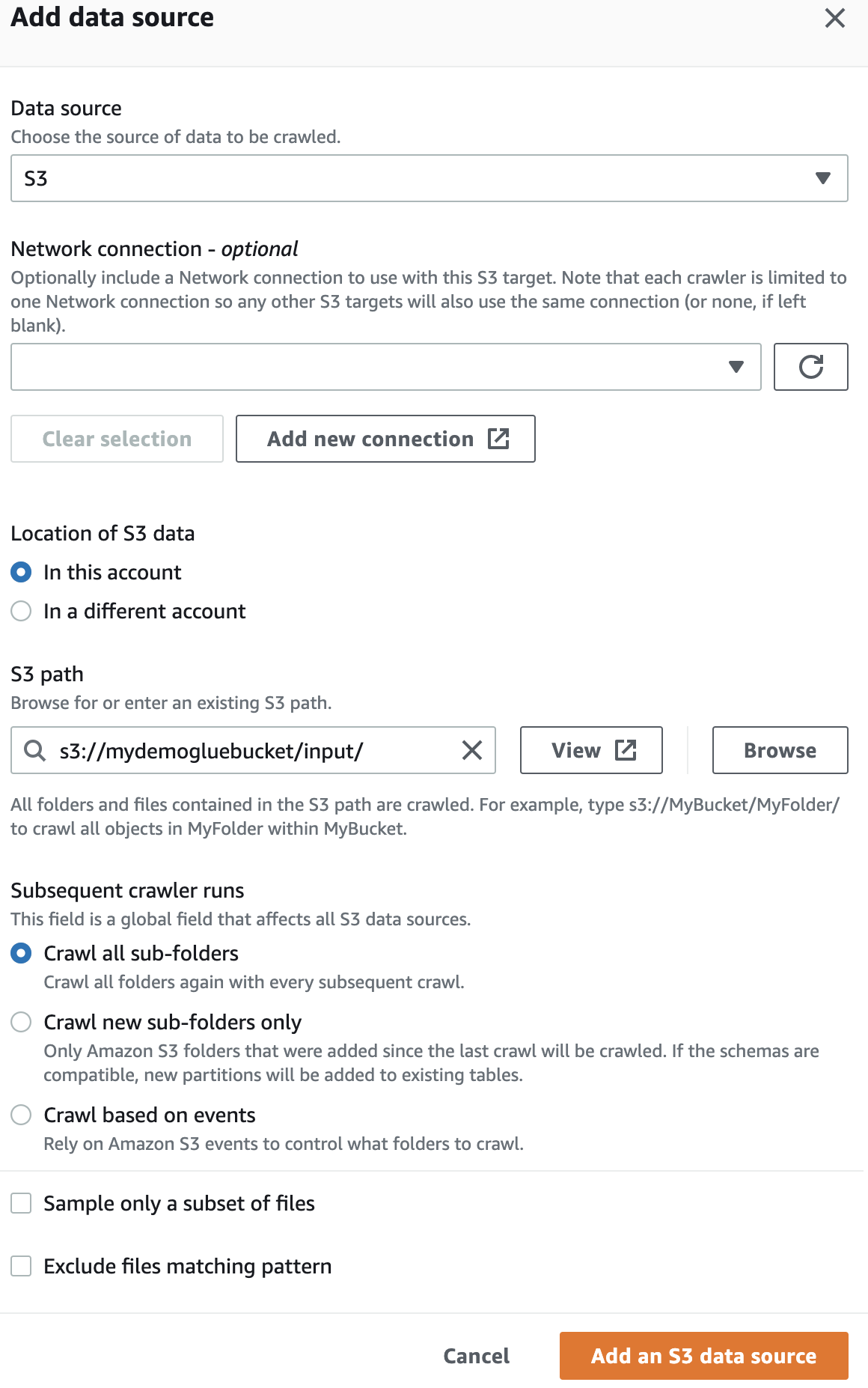
Quindi, seleziona il ruolo IaM per AWS Glue che hai creato all'inizio.
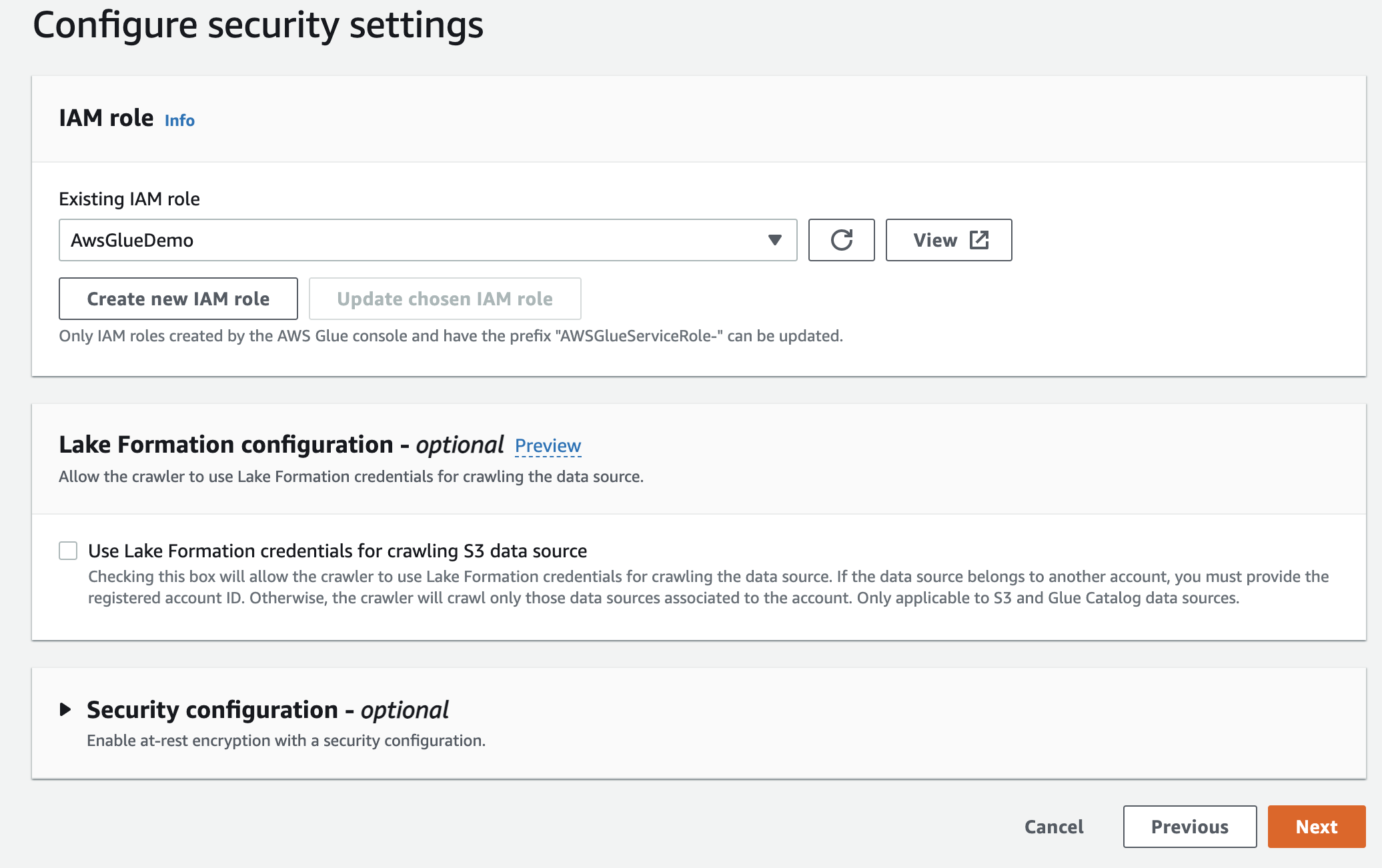
Infine, nell'output, seleziona gluedb che hai creato.
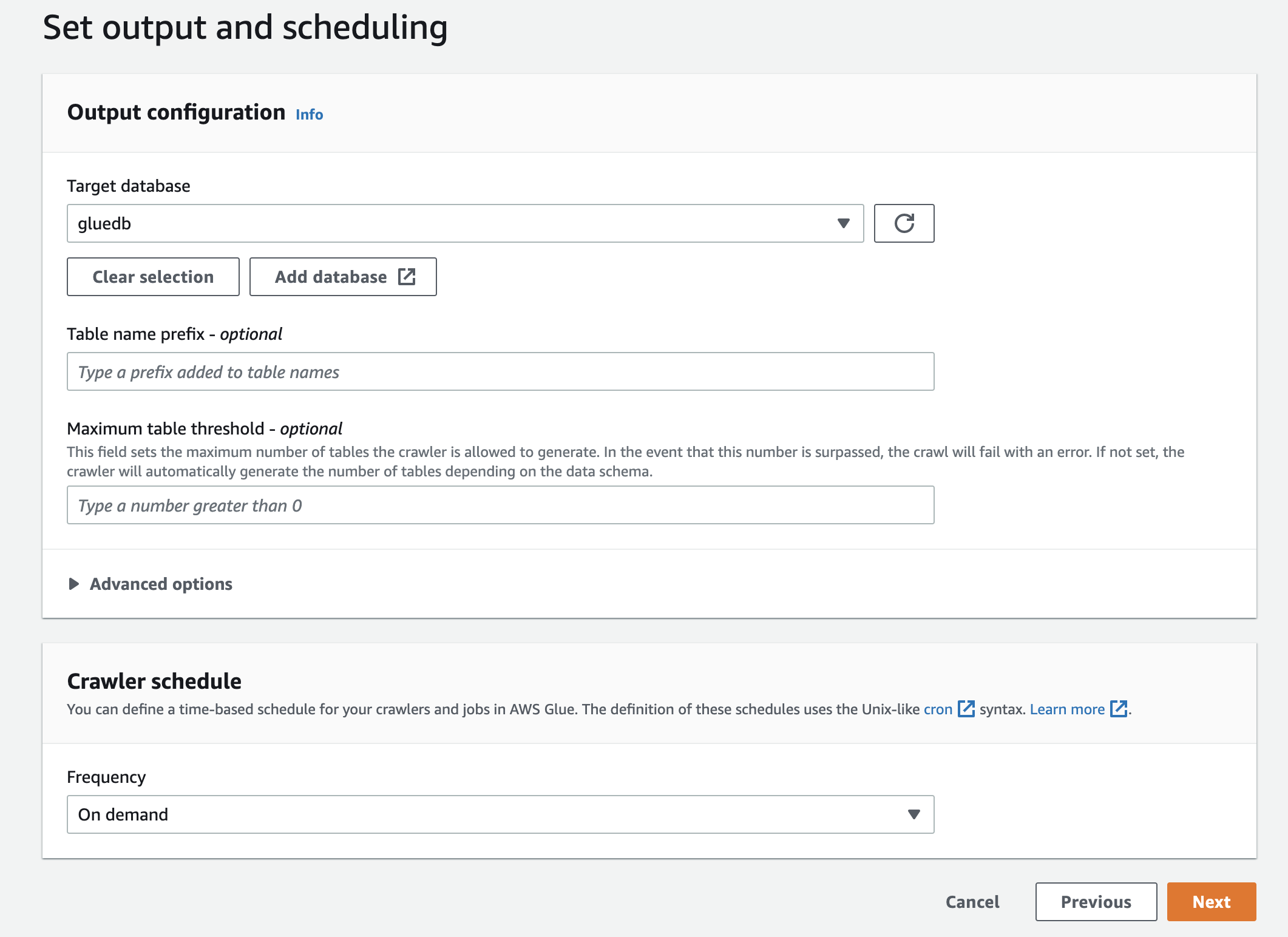
Rivedi tutte le impostazioni e crea il crawler.
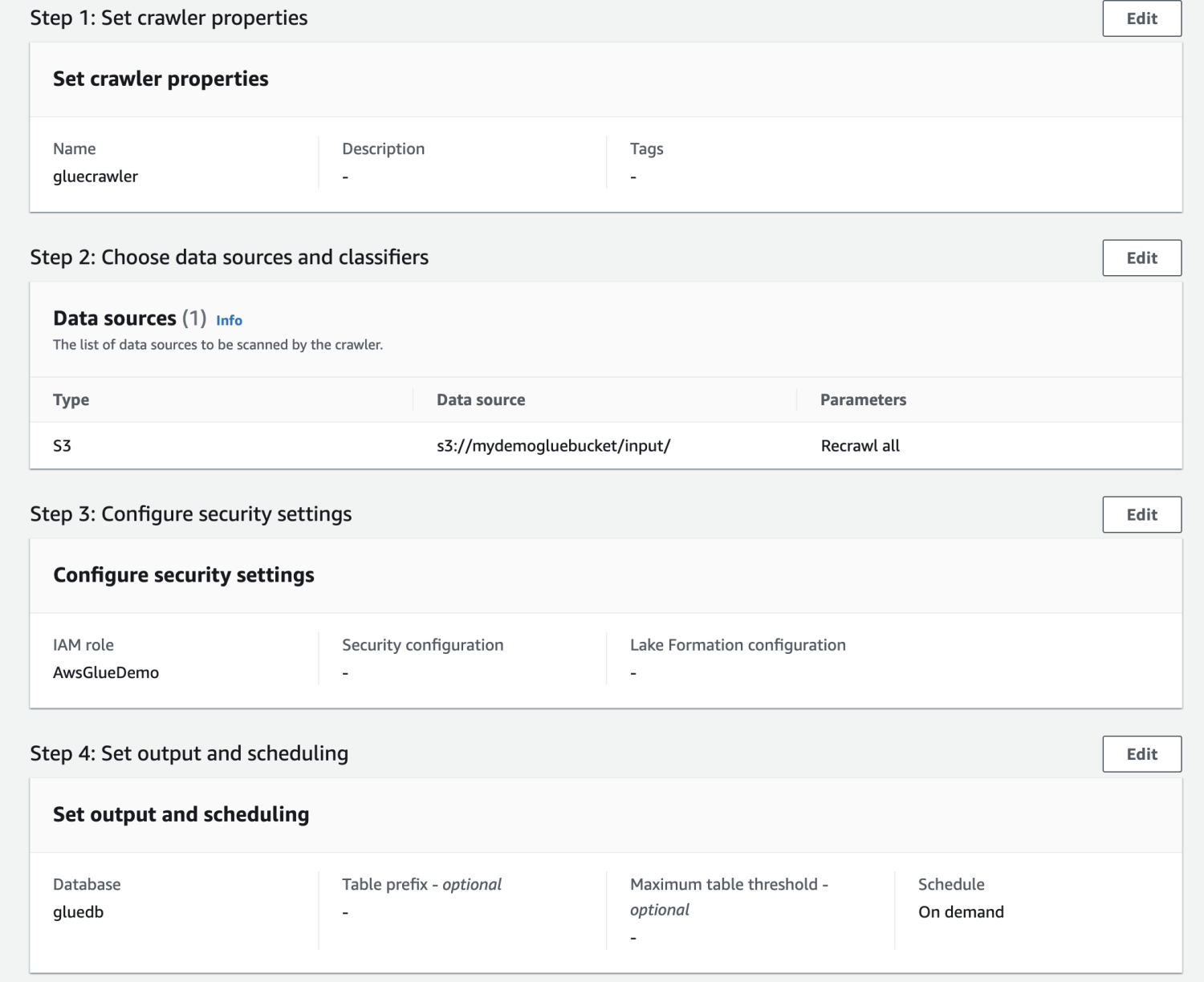
Una volta creato il crawler, selezionalo e fai clic su Esegui. Dopo qualche tempo, otterrai lo stato pronto.
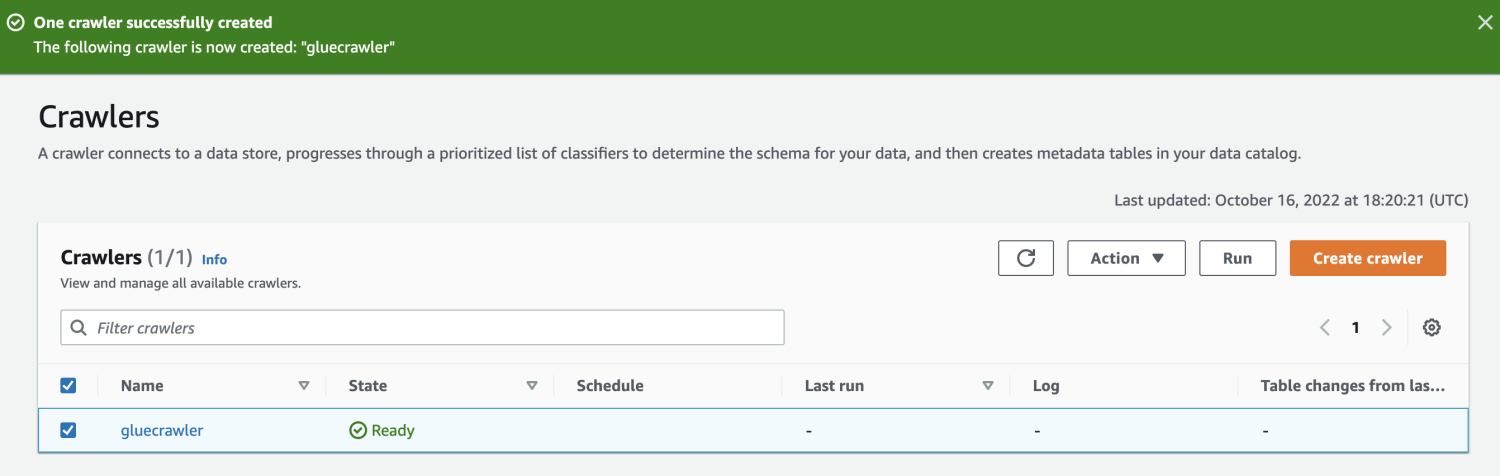
Eseguendo il crawler, il database otterrà una tabella con tutti i dati dal file CSV.
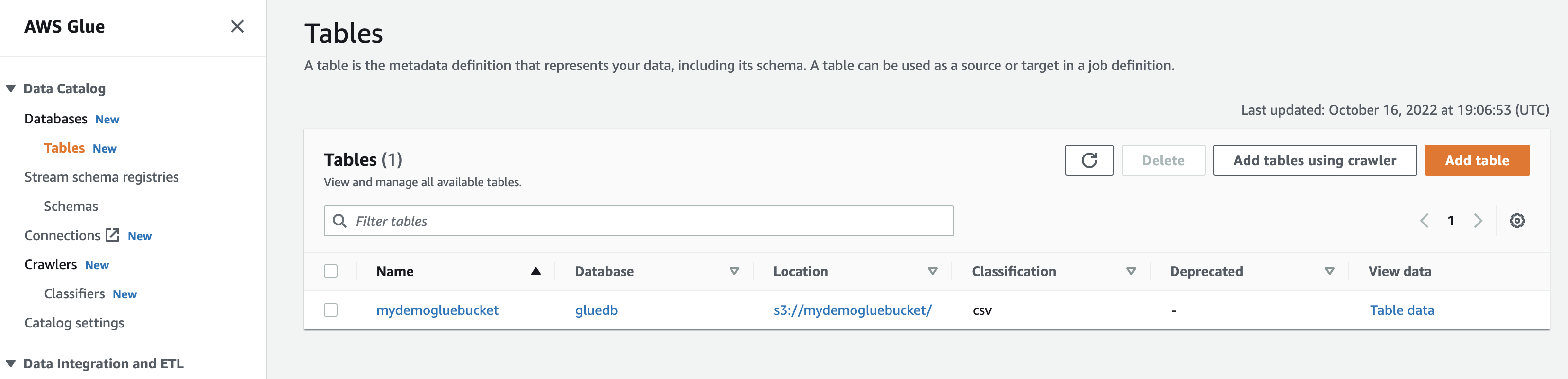
Quando fai clic su Visualizza dati, verrai indirizzato ad Amazon Athena (editor di query). Quando si esegue la query, è possibile visualizzare i dati della tabella.
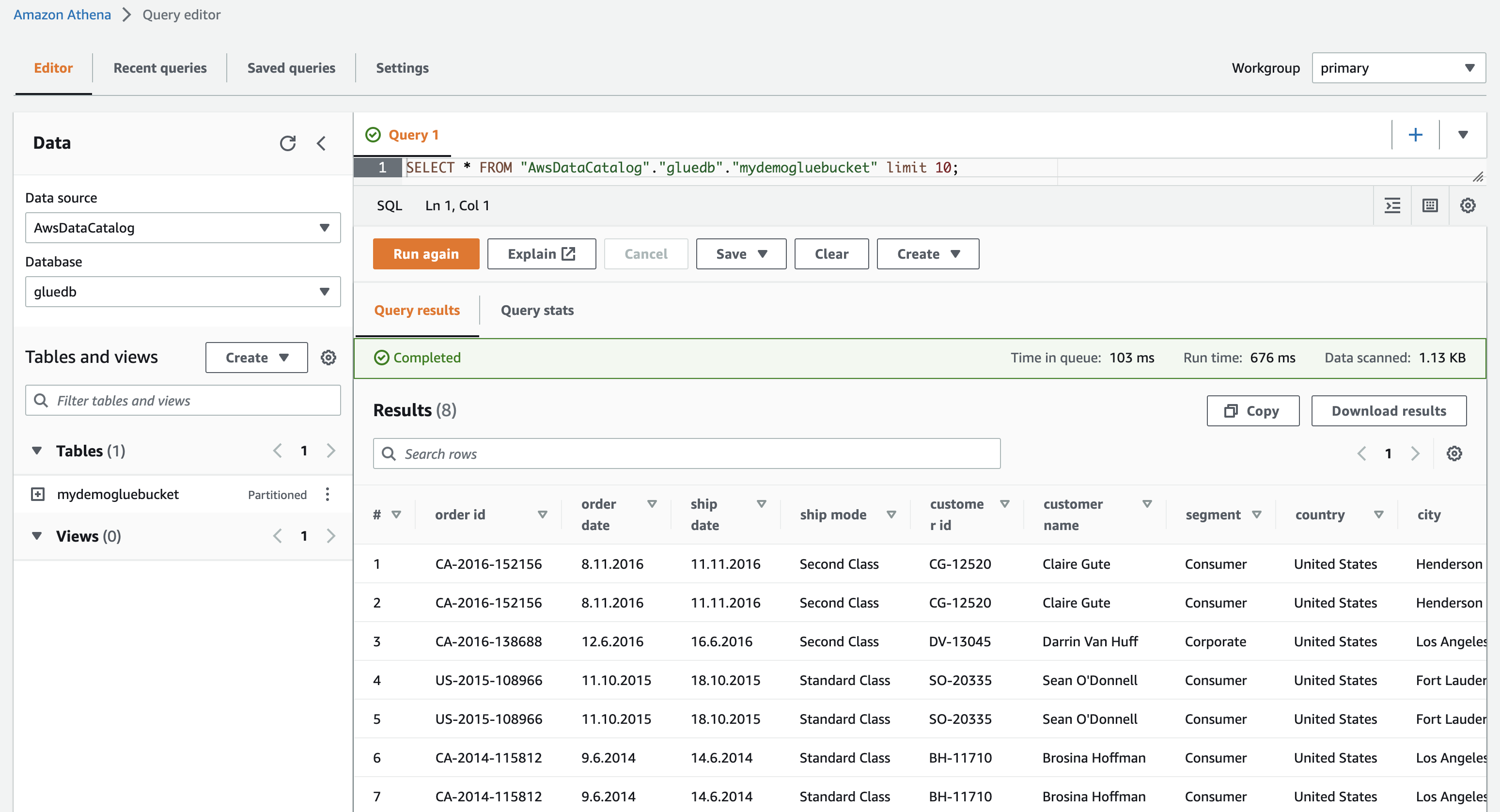
Ora puoi utilizzare con successo questo crawler di AWS Glue in qualsiasi lavoro ETL.
Che cos'è AWS Glue Databrew?
AWS Glue DataBrew consente agli utenti di normalizzare e ripulire i dati senza scrivere codice. DataBrew può ridurre il tempo necessario per preparare i dati per l'apprendimento automatico e l'analisi fino all'80% rispetto alla preparazione dei dati sviluppata su misura.
Esistono oltre 250 trasformazioni di dati predefinite che possono essere utilizzate per automatizzare attività di preparazione dei dati come filtrare le anomalie, correggere valori non validi e convertire i dati in formati standard.
DataBrew semplifica la collaborazione di data scientist, analisti aziendali e ingegneri per estrarre informazioni dai dati grezzi. DataBrew è serverless, quindi non è necessario gestire l'infrastruttura o creare cluster per esplorare e trasformare terabyte di dati grezzi.
Funzionalità di DataBrew per le aziende
Preparazione dei dati visualizzati
DataBrew è un modo diverso per visualizzare i dati che in genere vengono visualizzati nei database a colonne come numeri alfanumerici. DataBrew visualizza tutte le origini dati caricate per aiutarti a comprendere le relazioni e la gerarchia dei dati.
Oltre 250 automazioni per la preparazione dei dati
Ci si aspetta che i data scientist seguano una varietà di flussi di lavoro isolati e ripetibili come parte del loro lavoro. Questi flussi di lavoro e processi sono stati modellati da AWS come moduli di moduli indipendenti dal linguaggio e dai dati. Questa libreria include azioni che possono essere utilizzate dagli utenti finali.
Linea di dati
Analogamente ai log di controllo utilizzati per tenere traccia dell'attività dei clienti nella rete IT di una rete IT, la derivazione dei dati consente di tenere traccia delle attività di trasformazione dei dati all'interno di AWS DataBrew. Queste informazioni includono l'origine dati, le trasformazioni applicate e l'output dei dati, inclusa la posizione di destinazione.
Mappatura dei dati
Databrew ti consente di trovare campi corrispondenti in due origini dati. Una volta identificati i campi corrispondenti, possono essere caricati in uno schema.
AWS Glue DataBrew: vantaggi
Di seguito sono elencate le funzionalità di AWS Glue DataBrew:
- Barriera inferiore all'ingresso per la preparazione dei dati
- Generazione automatizzata di profili dati
- Automatizza oltre 250 processi di preparazione dei dati
- Suggerimenti prescrittivi intelligenti
Alternative ad AWS Glue
Flusso d'aria

Airflow appartiene alla sezione Workflow Manager di uno stack tecnologico. È uno strumento open source che supporta le stelle GitHub, i fork di GitHub e altre funzionalità. Airflow consente di creare flussi di lavoro utilizzando i diagrammi aciclici diretti (DAG). Lo scheduler del flusso d'aria esegue le tue attività utilizzando una serie di lavoratori e seguendo le dipendenze specificate.
Matillion

Matillion ETL, uno strumento ETL/ELT, è stato progettato esplicitamente per piattaforme di database cloud come Amazon Redshift e Google BigQuery. È una moderna interfaccia utente basata su browser con potenti funzionalità ETL/ELT push-down. Puoi essere operativo in pochi minuti con una configurazione rapida.
Cucire
Stitch è un servizio ETL open source che collega più origini dati e replica i dati alle destinazioni preferite. È molto facile da usare, poiché non è necessaria alcuna conoscenza di codifica per spostare i dati tra origini e destinazioni in Stitch. È facile da usare, ha una GUI amichevole ed è veloce.
Stitch non ti consente di scegliere una dashboard predefinita, a differenza di altri strumenti ETL. Invece, devi integrare i tuoi dati negli open data warehouse che selezioni come destinazione. Può essere difficile navigare negli inventari.
Alteryx

Alteryx è una piattaforma di automazione dell'analisi che assiste nella preparazione e nella fusione della raccolta dei dati. Questi dati possono essere utilizzati per accelerare i processi e fornire informazioni dettagliate sul business. Poiché è uno strumento di trascinamento della selezione, non è necessaria alcuna conoscenza di programmazione. Alteryx è un ottimo posto dove cercare consigli e risposte da professionisti del settore.
Conclusione
Quindi, si trattava di AWS Glue, una soluzione basata su cloud che ti consente di lavorare con pipeline ETL. Per riassumere, il processo di interazione dell'utente di AWS Glue comprende tre fasi. Per creare un catalogo di dati, devi prima utilizzare i crawler di dati. Successivamente, crei il codice ETL richiesto dalla pipeline di dati AWS. Infine, viene creata la pianificazione ETL. Spero che questo blog ti abbia dato una buona panoramica di Amazon Glue.
Puoi anche esplorare i migliori suggerimenti per proteggere lo storage AWS S3.