
Что вы не знали об AWS Glue
Опубликовано: 2022-10-18Amazon Glue набирает популярность, поскольку многие компании начали использовать сервисы интеграции управляемых данных.
ETL — это процесс, который передает данные из исходной базы данных в хранилище данных. ETL сложна и трудна для реализации для всех корпоративных данных из-за ее сложности. Amazon представила AWS Glue для решения этой проблемы.
Разработчики ETL и инженеры данных используют Glue для создания, мониторинга и запуска рабочих процессов ETL.
Что такое клей AWS?
AWS Glue, бессерверный сервис интеграции данных, упрощает поиск, подготовку, перемещение и интеграцию данных из нескольких источников. Это полезно для машинного обучения (ML) и аналитики.
Это значительно сокращает время, необходимое для подготовки данных к анализу. Он автоматически находит и составляет список данных, генерирует код Scala или Python для передачи данных из источника, а также загружает и преобразует задание в соответствии с синхронизированными событиями.
Это обеспечивает гибкое планирование и создает среду Apache Spark, которую можно масштабировать для целевой загрузки данных. Кроме того, AWS Glue обеспечивает комплексный мониторинг и изменение потока данных. AWS Glue — это бессерверный сервис, упрощающий сложные операции разработки приложений.
Это позволяет быстро интегрировать несколько достоверных данных. Он также быстро разбирает и авторизует данные.
Для чего используется AWS Glue?
Важно знать лучшие места для использования Amazon Glue. Это всего лишь несколько примеров использования AWS Glue, которые следует учитывать.
- Amazon Glue — это инструмент, позволяющий выполнять бессерверные запросы к озерам данных Amazon S3.
- Amazon Glue — отличный инструмент для начала работы. Это делает все ваши данные доступными в одном интерфейсе, позволяя вам анализировать их, не перемещая их.
- Amazon Glue можно использовать для понимания ваших активов данных. Amazon Glue упрощает поиск различных наборов данных AWS с помощью каталога данных. Вы также можете сохранять данные в нескольких сервисах AWS с помощью каталога данных, сохраняя при этом согласованное представление.
- Glue может быть полезен при создании рабочих процессов ETL, управляемых событиями. Вы можете выполнять операции ETL из Amazon S3, вызывая задачи Glue ETL через сервис AWS Lambda.
- AWS Glue также можно использовать для очистки, проверки, форматирования и организации данных для хранения в озере данных или хранилище.
Компоненты AWS Glue
Ниже приведены основные компоненты AWS Glue:
- Каталог данных: этот каталог данных содержит метаданные и структуру данных.
- База данных: это ключ к доступу и созданию базы данных для источников и целей.
- Таблица: создайте одну или несколько таблиц в базе данных, которые могут использоваться как целью, так и источником.
- Искатель и классификатор . Искатель извлекает данные из источника с помощью встроенных или настраиваемых классификаций. Он создает/использует предопределенные таблицы метаданных в каталоге данных.
- Работа: это работа бизнес-логики для выполнения задачи ETL. Эта бизнес-логика написана внутри Apache Spark с использованием языков python и scala.
- Триггер: триггер ETL — это устройство, которое инициирует выполнение задания ETL по требованию или в определенное время.
- Конечная точка для разработки: создает среду, в которой сценарий задания ETL тестируется, разрабатывается и отлаживается.
Преимущества клея AWS
Это преимущества использования его на вашем рабочем месте или в организации.
- AWS Glue сканирует все доступные данные с помощью сканера.
- Окончательно обработанные данные могут храниться во многих местах (Amazon RDS и Amazon Redshift, Amazon S3 и т. д.).
- Это облачный сервис. Нет необходимости тратить деньги на локальную инфраструктуру.
- Поскольку это бессерверный ETL, это экономичный выбор.
- Это быстро. Он немедленно дает вам ETL-код Python/Scala.
Основные возможности AWS Glue
В Amazon Glue есть все функции, необходимые для интеграции данных, чтобы вы могли получать более точные аналитические данные и использовать свои знания для достижения новых результатов за считанные минуты, а не месяцы. Вот некоторые из особенностей, которые вы должны знать.
- Интерфейс перетаскивания. Редактор заданий с перетаскиванием позволяет создать процесс ETL. AWS Glue немедленно создаст код, необходимый для извлечения, преобразования и загрузки данных.
- Автоматическое обнаружение схемы: для создания поисковых роботов, которые подключаются к различным источникам данных, вы можете использовать службу Glue. Он организует данные и извлекает соответствующую информацию. Затем эти данные можно использовать для мониторинга процессов ETL с помощью задач ETL.
- Планирование работы: клей можно использовать по запросу или по расписанию. Планировщик можно использовать для построения сложных конвейеров ETL, устанавливая зависимости между задачами.
- Генерация кода: Glue Elastic Views позволяет легко создавать материализованные представления, которые комбинируют и реплицируют данные из разных источников данных без необходимости написания какого-либо проприетарного кода.
- Встроенное машинное обучение: Glue поставляется со встроенной функцией машинного обучения под названием «Найти совпадения». Он дедуплицирует записи, которые не являются идеальными копиями друг друга.
- Конечные точки разработчика . Если вы хотите активно разрабатывать свой ETL-код, Glue предоставляет конечные точки разработчика, которые позволяют изменять, отлаживать и тестировать создаваемый им код.
- Glue DataBrew: это инструмент подготовки данных, который могут использовать аналитики данных и специалисты по данным, чтобы помочь им очистить и нормализовать данные. Он использует активный и визуальный интерфейс Glue DataBrew.
Как работает ценообразование на AWS Glue?
AWS Glue взимает почасовую плату, которая взимается за каждую секунду для сканеров (обнаружение данных) и заданий ETL (обработка и загрузка данных). За доступ и хранение метаданных в каталоге данных AWS Glue взимается простая ежемесячная плата.
Amazon Glue стоит от 0,44 доллара. Вы можете выбрать один из четырех планов:
- Задачи ETL, конечные точки разработки и другие задачи ETL доступны по цене 0,44 доллара США.
- Интерактивные сеансы Crawlers доступны по цене 0,44 доллара США.
- Вакансии DataBrew начинаются с 0,48 доллара США.
- Ежемесячное хранение и запросы к каталогу данных стоят 1 доллар США.
AWS не предлагает бесплатный план Glue. Каждый час будет стоить 0,44 доллара США за DPU. В среднем это будет стоить вам 21 доллар в день. Цены могут варьироваться в зависимости от того, где вы живете.
Шаги по настройке AWS Glue
Каталог данных можно использовать для быстрого поиска и поиска нескольких наборов данных AWS без необходимости перемещения данных. После того как данные каталогизированы, они сразу становятся доступными для запроса и поиска с помощью Amazon Athena и Amazon EMR.
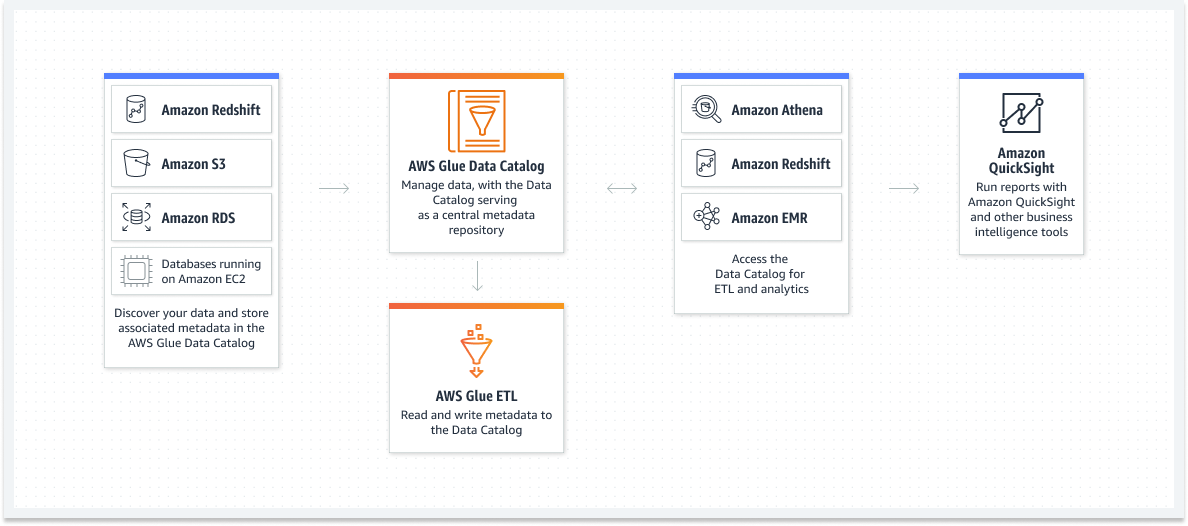
- Amazon Redshift, Amazon S3, Amazon RDS и базы данных на Amazon EC2 — находите свои данные, храните метаданные и используйте каталог данных AWS Glue для их обнаружения.
- Каталог данных AWS Glue — управляйте данными с помощью каталога данных, выступающего в качестве центрального репозитория метаданных.
- AWS Glue ETL — чтение и запись метаданных в каталог данных
- Amazon Athena и Amazon Redshift, Amazon EMR, Amazon ETL — получите каталог данных для ETL, аналитики и многого другого.
- Amazon QuickSight — создавайте отчеты с помощью Amazon QuickSight и других инструментов бизнес-аналитики.
Как настроить AWS Glue?
Во-первых, войдите в консоль управления AWS и откройте консоль IAM. Нажмите «Создать роль». Затем для типа роли найдите Glue и выберите Permissions .
Я выбираю AWSGloeServiceRole для общих разрешений AWS Glue Studio и AWS Glue, а также управляемую AWS политику AmazonS3FullAccess для доступа к ресурсам Amazon S3.
Введите имя роли.
Нажмите «Создать роль».
Создайте корзину Amazon S3.

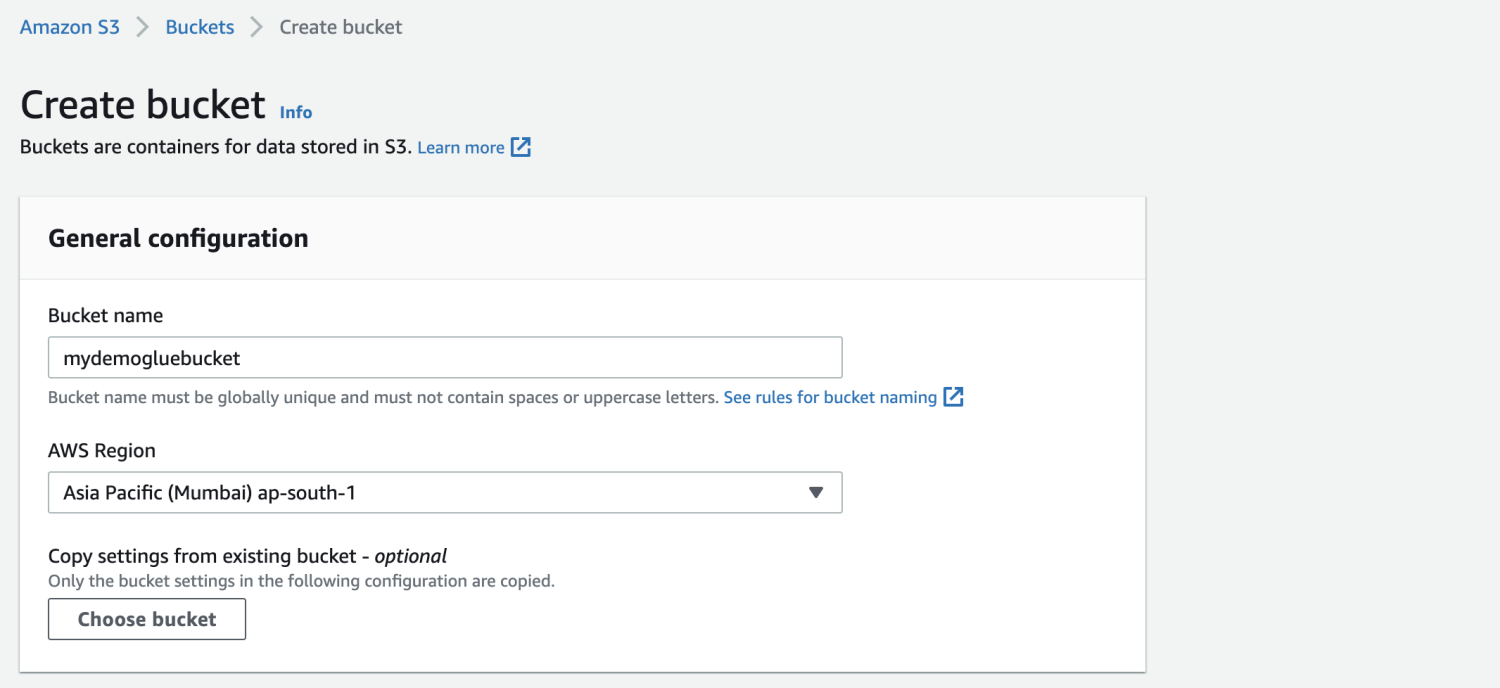
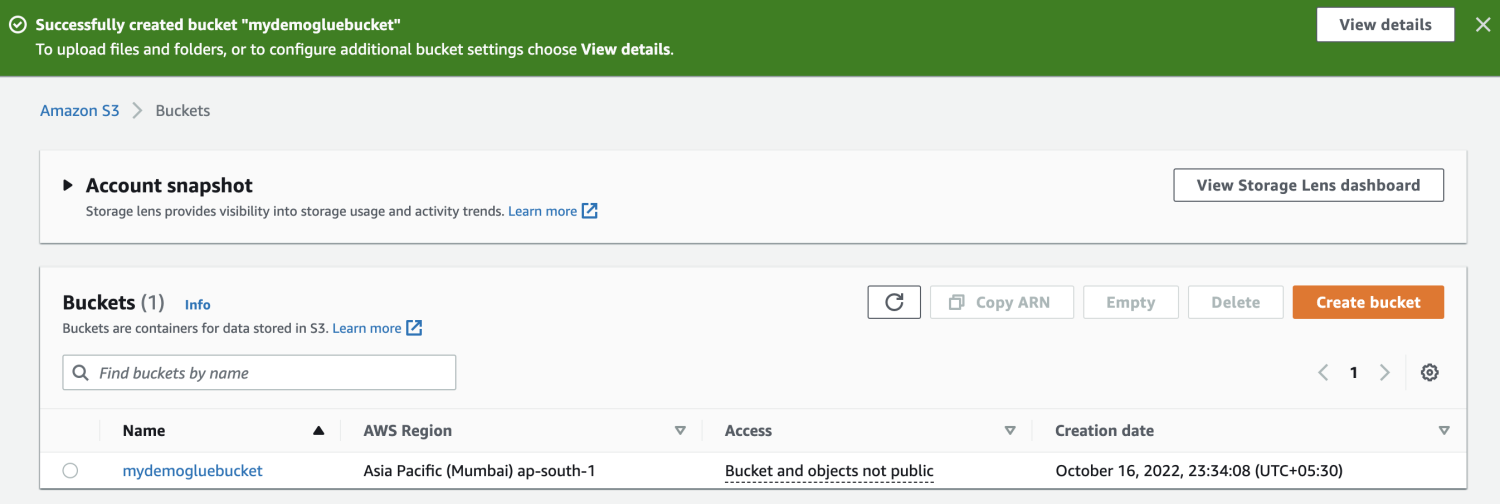
Создайте папку внутри корзины S3.
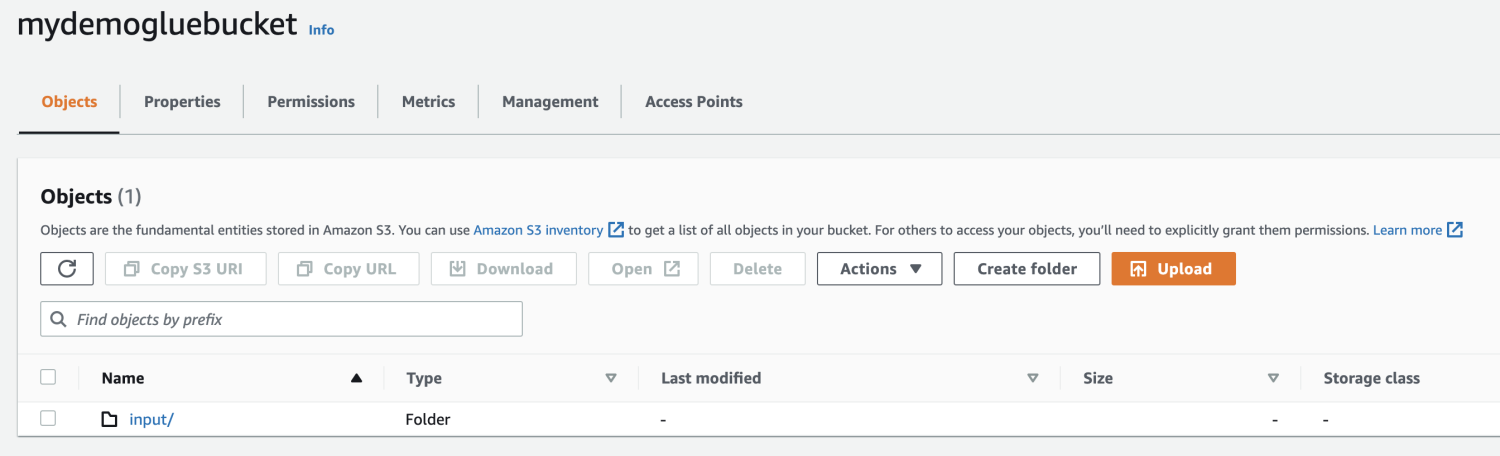
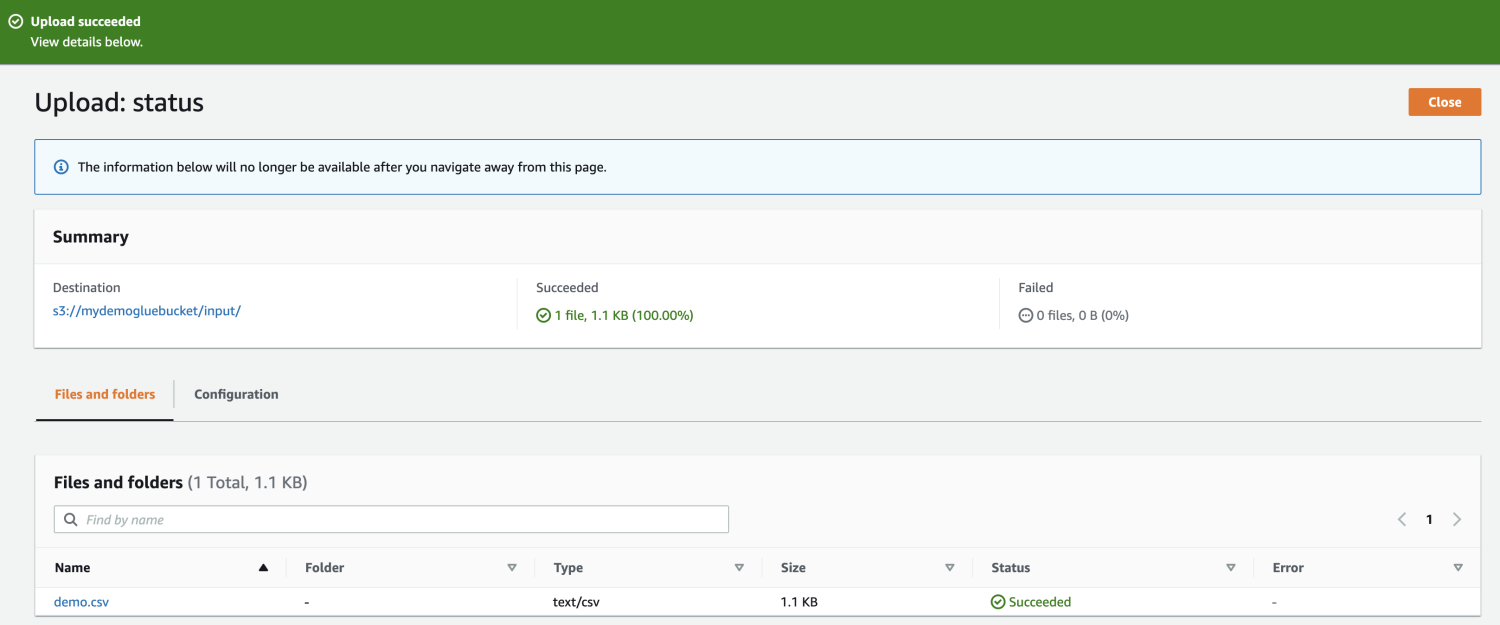
Выберите файл для загрузки.
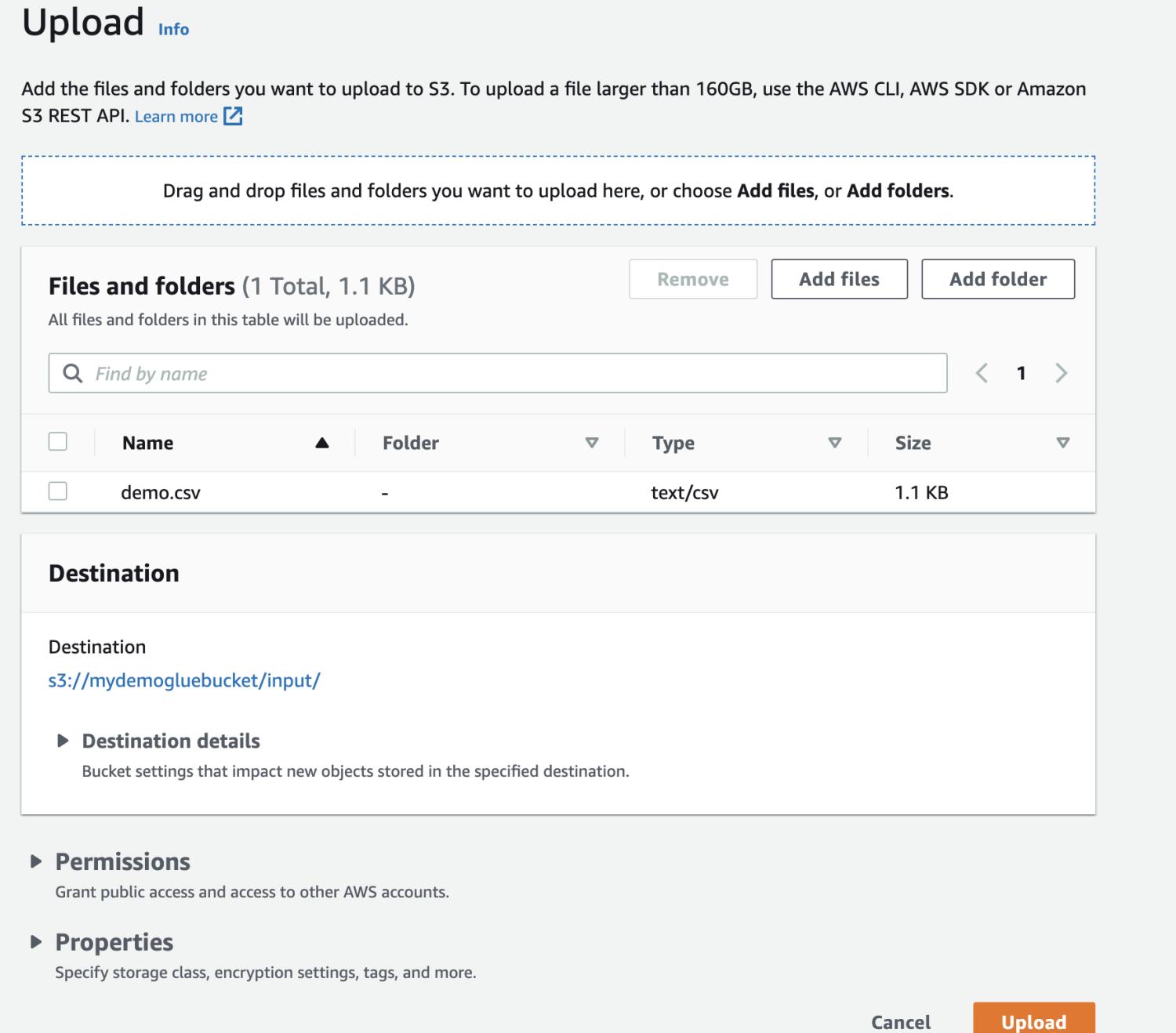
Наконец, загрузите файл в корзину.
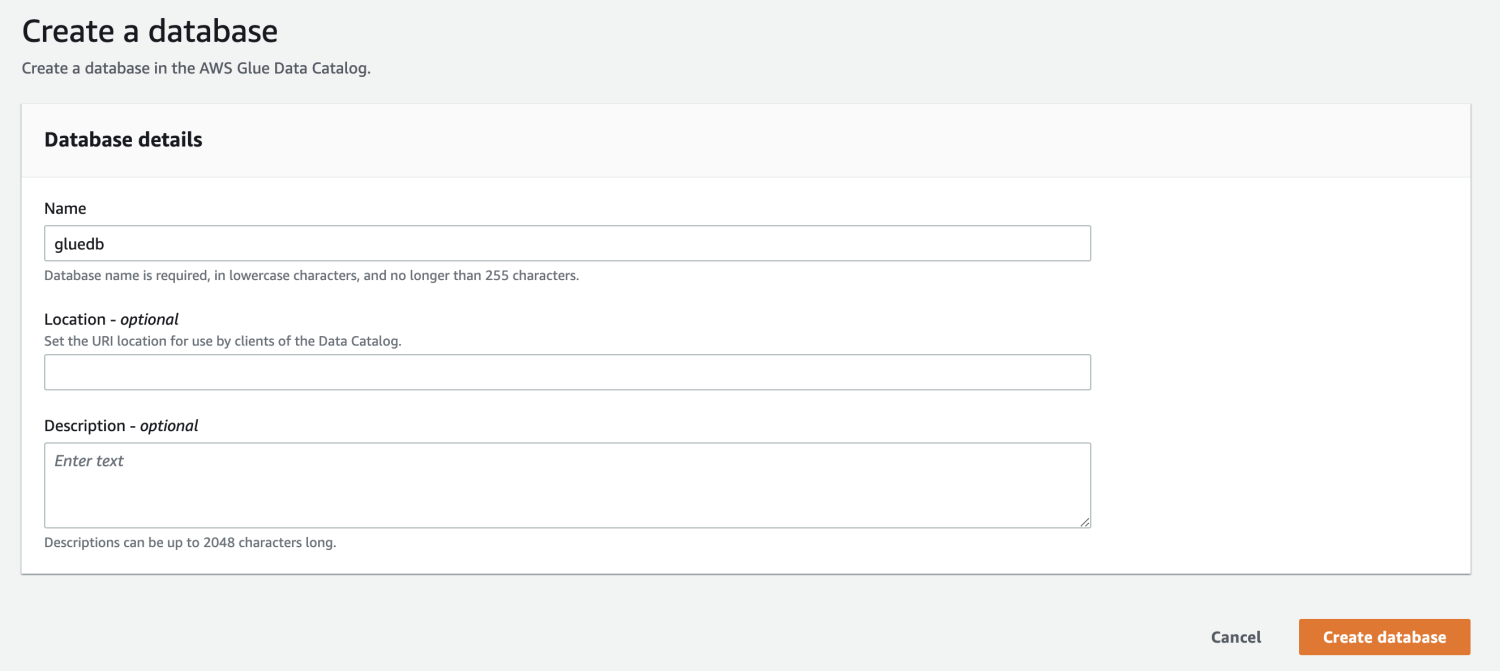
Затем откройте AWS Glue из консоли управления AWS и создайте базу данных.
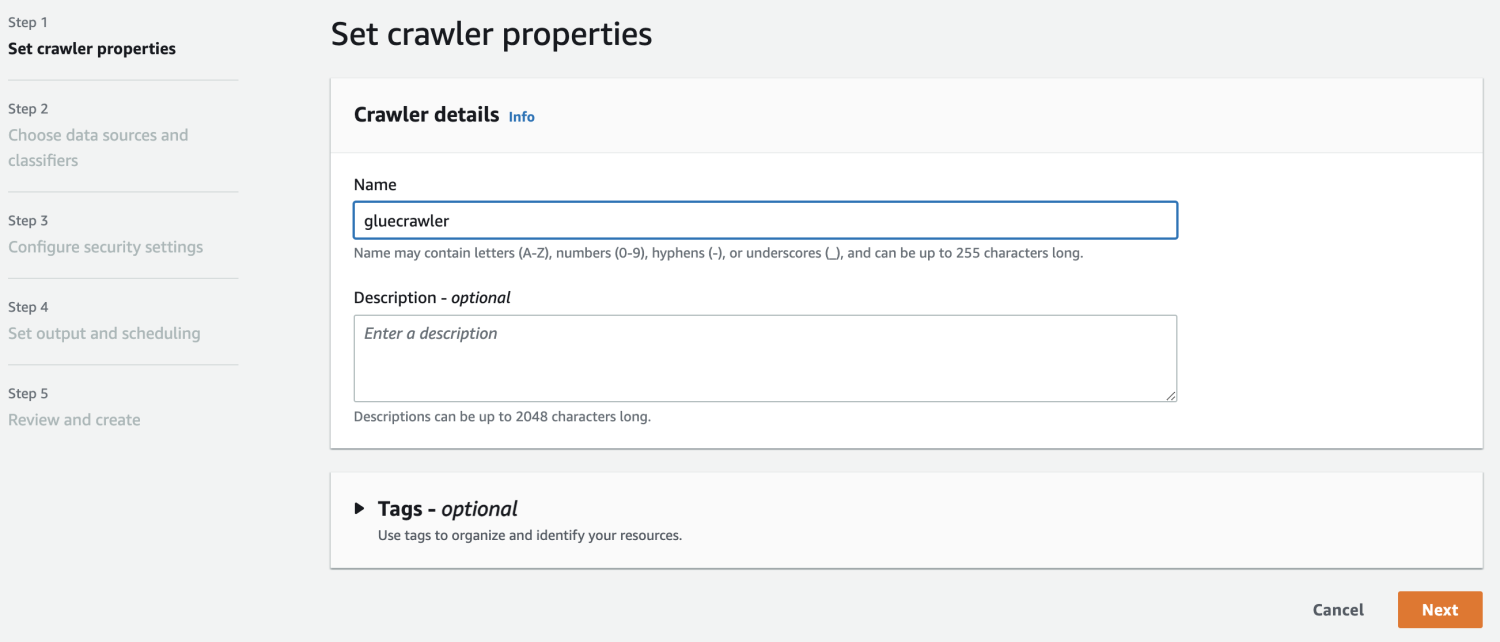
Теперь, когда у вас есть база данных в AWS Glue, создайте сканер.
В источнике данных выберите созданную вами корзину S3.
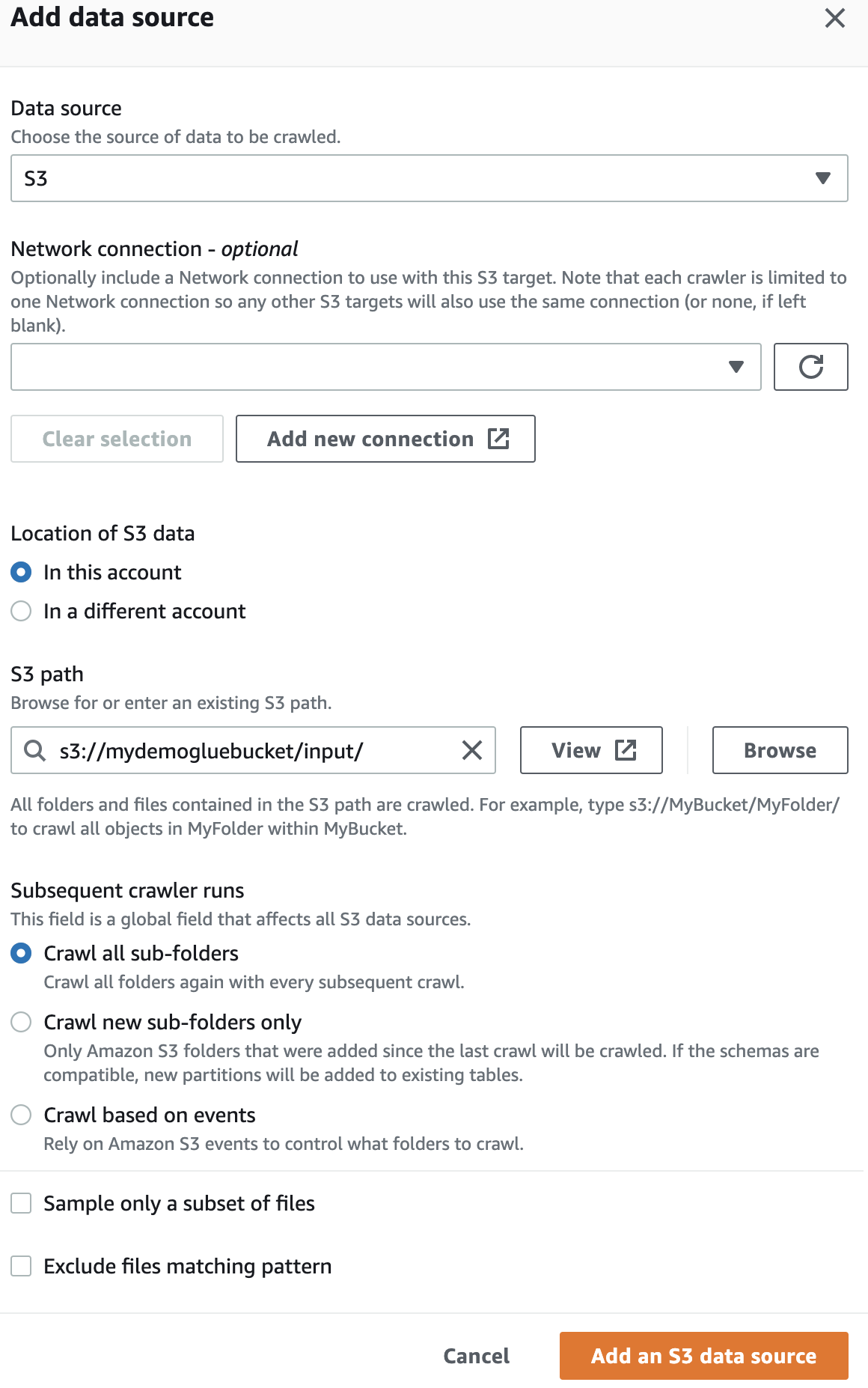
Затем выберите роль IaM для AWS Glue, которую вы создали вначале.
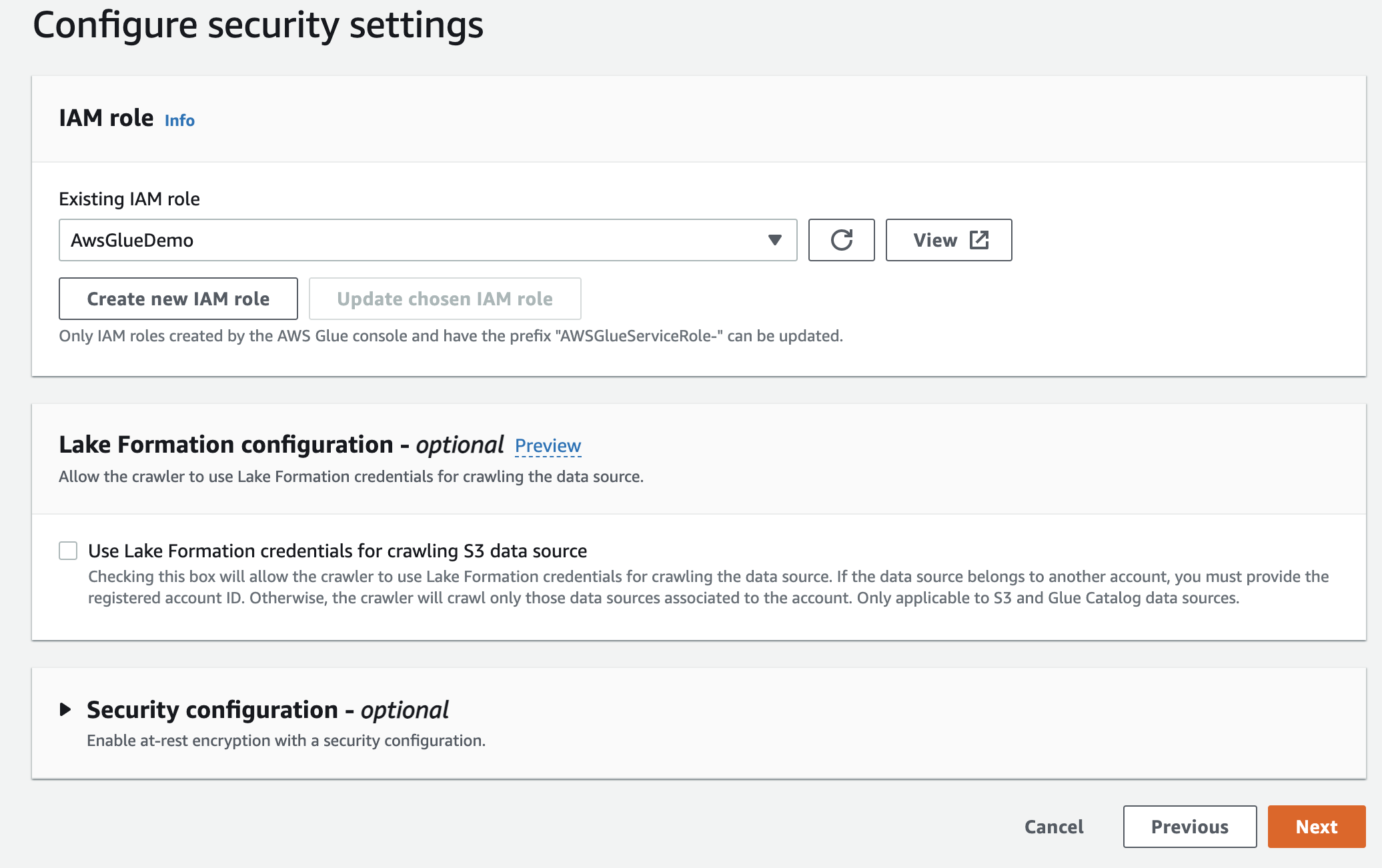
Наконец, в выводе выберите созданный вами gluedb .
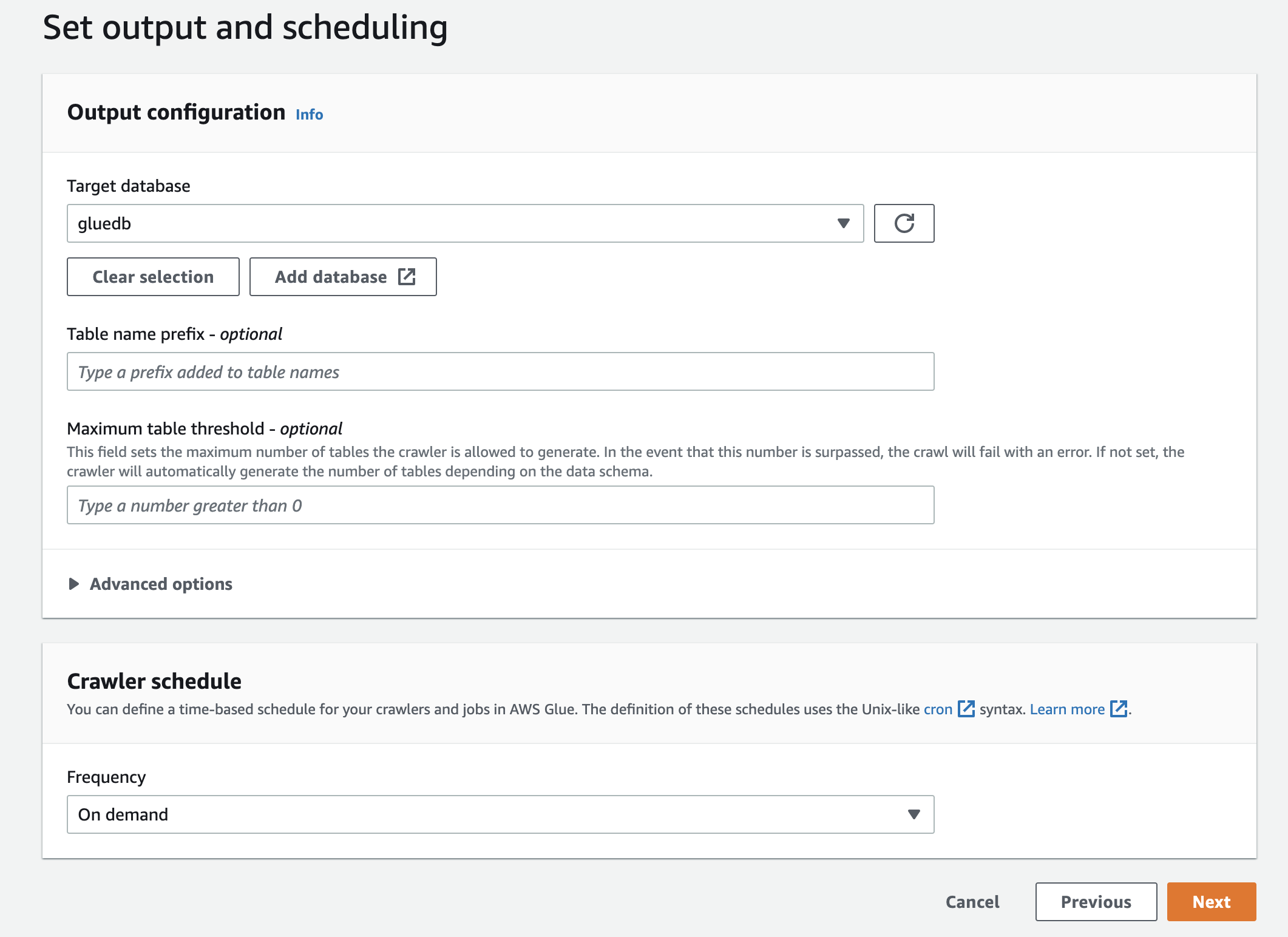
Просмотрите все настройки и создайте сканер.
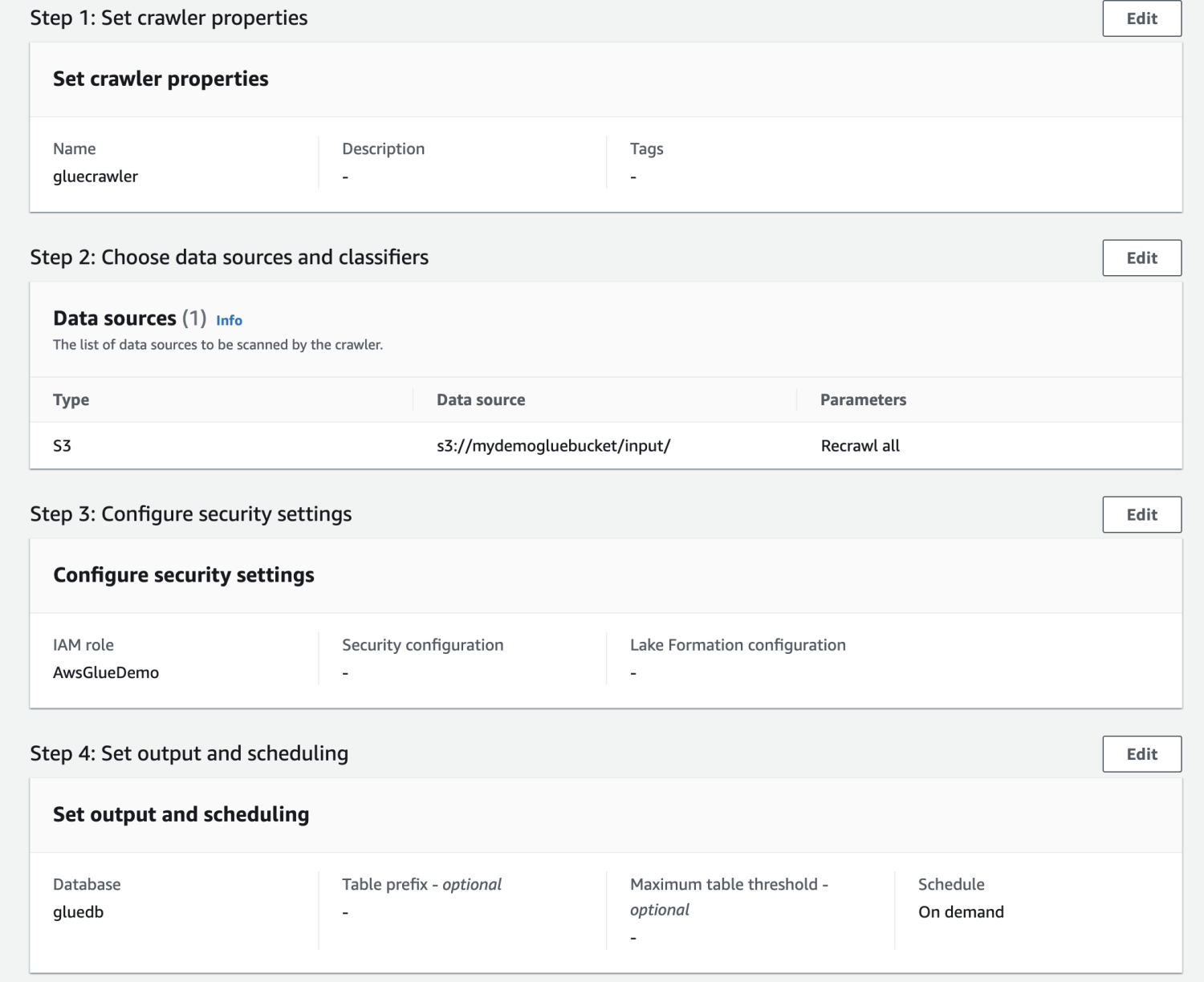
После создания сканера выберите его и нажмите «Выполнить». Через некоторое время вы получите готовый статус.
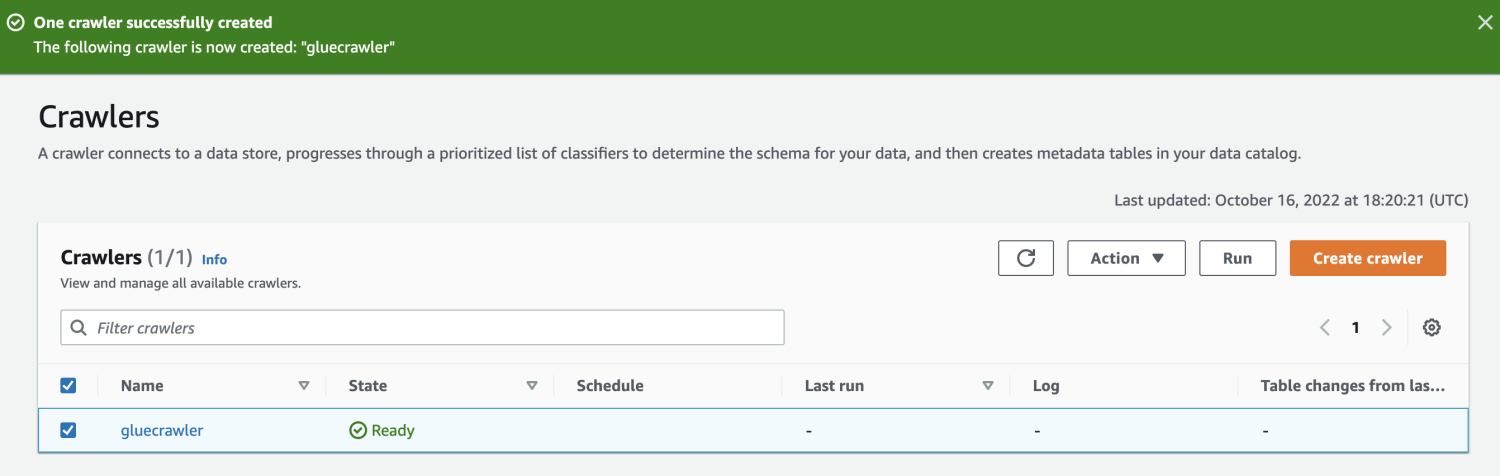
Запустив краулер, база данных получит таблицу со всеми данными из CSV-файла.
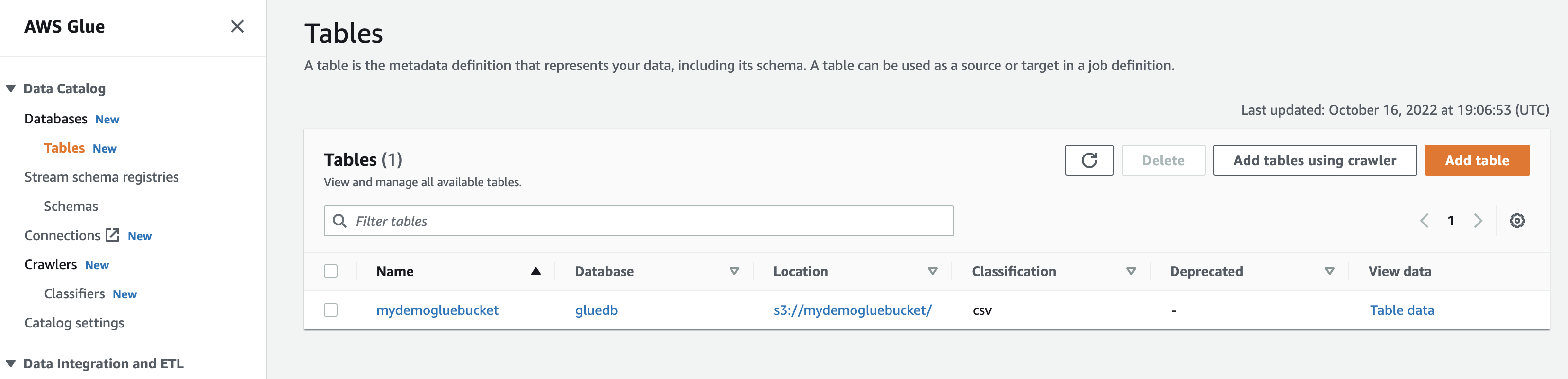
Когда вы нажмете на просмотр данных, вы попадете в Amazon Athena (редактор запросов). Когда вы запускаете запрос, вы можете увидеть данные таблицы.
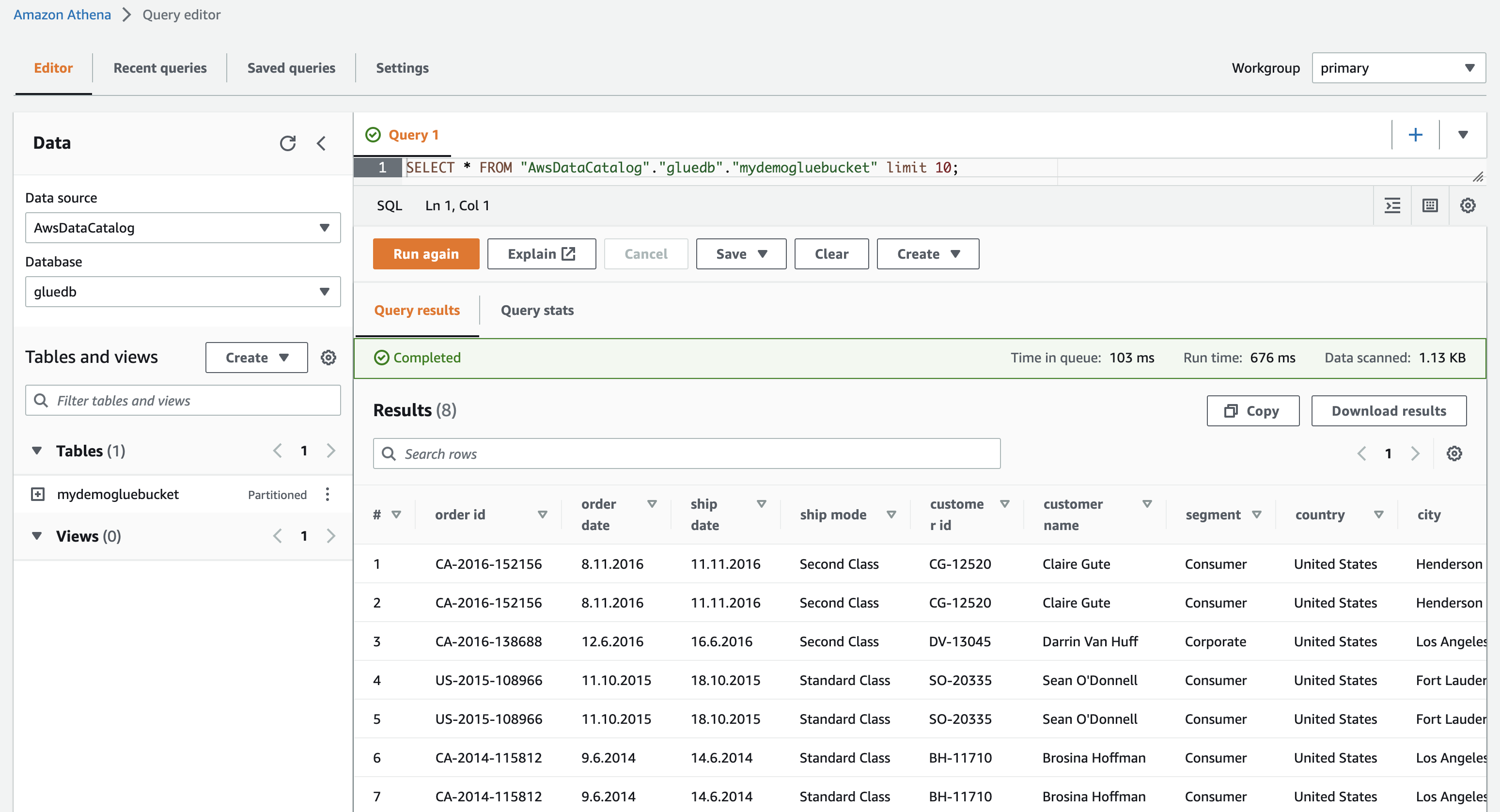
Теперь вы можете успешно использовать этот сканер AWS Glue в любом задании ETL.
Что такое AWS Glue Databrew?
AWS Glue DataBrew позволяет пользователям нормализовать и очищать данные без написания кода. DataBrew может сократить время, необходимое для подготовки данных для машинного обучения и аналитики, на целых 80 процентов по сравнению с подготовкой данных, разработанной по индивидуальному заказу.
Существует более 250 готовых преобразований данных, которые можно использовать для автоматизации задач подготовки данных, таких как фильтрация аномалий, исправление недопустимых значений и преобразование данных в стандартные форматы.
DataBrew упрощает совместную работу специалистов по обработке и анализу данных, бизнес-аналитиков и инженеров для извлечения полезных сведений из необработанных данных. DataBrew является бессерверным, поэтому вам не нужно управлять инфраструктурой или создавать кластеры для изучения и преобразования необработанных данных объемом в терабайты.
Возможности DataBrew для предприятий
Подготовка визуализированных данных
DataBrew — это другой способ просмотра данных, которые обычно просматриваются в столбчатых базах данных как буквенно-цифровые числа. DataBrew визуализирует все загруженные источники данных, чтобы помочь вам понять отношения и иерархию данных.
250+ Автоматизация подготовки данных
Ожидается, что специалисты по данным будут следовать множеству повторяющихся изолированных рабочих процессов в рамках своей работы. Эти рабочие процессы и процессы были смоделированы AWS в виде модульных модулей, не зависящих от языка и данных. Эта библиотека включает действия, которые могут использовать конечные пользователи.
Происхождение данных
Подобно журналам аудита, которые используются для отслеживания действий клиентов в ИТ-сети ИТ-сети, передача данных позволяет отслеживать действия по преобразованию данных в AWS DataBrew. Эта информация включает в себя источник данных, примененные преобразования и выходные данные, включая целевое местоположение.
Отображение данных
Databrew позволяет найти совпадающие поля в двух источниках данных. После определения совпадающих полей их можно загрузить в схему.
AWS Glue DataBrew: преимущества
Ниже перечислены функции AWS Glue DataBrew:
- Низкий порог входа для подготовки данных
- Автоматическая генерация профиля данных
- Автоматизируйте более 250 процессов подготовки данных
- Интеллектуальные предписывающие предложения
Альтернативы AWS Glue
Воздушный поток

Airflow относится к разделу Workflow Manager технологического стека. Это инструмент с открытым исходным кодом, который поддерживает звезды GitHub, форки GitHub и другие функции. Airflow позволяет создавать рабочие процессы с использованием направленных ациклических диаграмм (DAG). Планировщик воздушного потока выполняет ваши задачи, используя массив рабочих процессов и следуя указанным зависимостям.
Матиллион

Matillion ETL, инструмент ETL/ELT, был разработан специально для облачных платформ баз данных, таких как Amazon Redshift и Google BigQuery. Это современный пользовательский интерфейс на основе браузера с мощными возможностями ETL/ELT. Вы можете приступить к работе за считанные минуты с помощью быстрой настройки.
Стежок
Stitch — это служба ETL с открытым исходным кодом, которая соединяет несколько источников данных и реплицирует данные в предпочтительные места назначения. Его очень легко использовать, так как вам не нужны знания программирования для перемещения данных между источниками и пунктами назначения в Stitch. Он прост в использовании, имеет дружественный графический интерфейс и работает быстро.
Stitch не позволяет вам выбрать готовую панель мониторинга, в отличие от других инструментов ETL. Вместо этого вы должны интегрировать свои данные в открытые хранилища данных, которые вы выбираете в качестве места назначения. Ориентироваться в запасах может быть сложно.
Альтерикс

Alteryx — это платформа автоматизации аналитики, которая помогает в подготовке и объединении данных. Эти данные можно использовать для ускорения процессов и предоставления бизнес-аналитики. Поскольку это инструмент перетаскивания, вам не нужны какие-либо знания в области программирования. Alteryx — отличное место, где можно получить советы и ответы от профессионалов отрасли.
Вывод
Итак, это было все об AWS Glue, облачном решении, позволяющем работать с конвейерами ETL. Подводя итог, можно сказать, что процесс взаимодействия с пользователем AWS Glue состоит из трех этапов. Чтобы создать каталог данных, вы сначала используете поисковые роботы. Затем вы создаете код ETL, необходимый для конвейера данных AWS. Наконец, создается расписание ETL. Я надеюсь, что этот блог дал вам хороший обзор Amazon Glue.
Вы также можете ознакомиться с лучшими советами по защите хранилища AWS S3.