
Jak wybrać narzędzie do monitorowania witryny, które odpowiada Twoim potrzebom?
Opublikowany: 2020-10-07Budzi Cię sygnał dźwiękowy i nie masz pewności co do godziny, ale na zewnątrz jest ciemno, a gdy zaczynasz odzyskiwać przytomność, widzisz napływające powiadomienia.
Coś spowodowało awarię Twojej aplikacji, a użytkownicy w Europie są dość zaniepokojeni. Minęła godzina bez kopii zapasowej, zachowaj swojego kierownika obsługi klienta, który co 15 minut posłusznie pyta, kiedy spodziewasz się powrotu do normalności. Wasza dwójka patrzy, jak reszta zespołu budzi się, otrzymuje wiadomości i zaczyna wskazywać palcami.
Myślisz, że tej całej sytuacji można uniknąć, gdy narasta czwarta godzina przestoju. Gdyby tylko coś ostrzegało nas przed nadchodzącą zagładą.
Witamy w świecie monitorowania stron internetowych , w którym najważniejsza jest dostępność aplikacji. Może nie tak ugasł pożar o 3 nad ranem, ale jeśli przeżyłeś tak długo w DevOps, miałeś jeden – i założymy się, że nie było to przyjemne.
Jeśli Twoim celem jest zminimalizowanie tej wyjątkowej marki bólu, jesteśmy tutaj, aby pomóc Ci sprawić, że dyżur jest trochę mniej beznadziejny dzięki łatwemu do przeglądania przewodnikowi, który określa, czego potrzebujesz od dostawcy monitorowania sieci .
Kompleksowy przewodnik po wyborze narzędzia do monitorowania witryn
Zacznijmy od podstaw: monitorowanie i raportowanie. Podobnie jak wszystkowidzące teleekrany z 1984 roku, monitorowanie odnosi się tutaj do „zewnętrznego” nadzoru nad twoimi operacjami. Zewnętrzne serwery sondujące są zwykle używane do monitorowania stanu aplikacji.
Odpowiedzialność zaczyna się od nadzoru, a raczej obserwowalności. Czego możesz się nauczyć na podstawie tego, co mówi Ci Twoja infrastruktura?
Raportowanie określa ilościowo twoją odpowiedzialność, ale dobre raportowanie jest subiektywne. Niektórzy mogą lubić surowe dane, które można zapakować w dowolny format. Inni chcą dostarczania automatycznych raportów, niektórzy liczą, inni chcą bardziej wizualnego podejścia. Raportowanie to druga strona monitorowania, a poprawność tych dwóch elementów zapewni, że Twoja aplikacja pozostanie dostępna, a umowy dotyczące poziomu usług będą przestrzegane.
Im lepiej zrozumiesz swoją infrastrukturę, tym większą wartość uzyskasz z monitorowania. Dostawcy często analizują typy czeków, aby utrzymać niskie koszty. Zrozumienie potrzeb monitorowania sieci w Twojej infrastrukturze jest dobrym źródłem oszczędności.
Monitorowanie sieci i raportowanie w celu odpowiedzialności
Monitorowanie nie polega tylko na łapaniu krasnali serwera uśpionych w pracy, powinno powiedzieć ci więcej niż to, czy usługa działa, czy nie. Dzięki metrykom wydajności możesz uzyskać jasny obraz działania Twojej infrastruktury. Zwłaszcza w przypadku bardziej zaawansowanych kontroli, takich jak monitorowanie rzeczywistych użytkowników (RUM) – ale o tym później.
Sprawdź stronę stanu swojego dostawcy i przejrzyj dane dotyczące przestojów z ostatnich sześciu do 12 miesięcy. Czy sprzedawca często przestaje działać? Ich ogólny czas pracy i zarządzanie incydentami powinno dostarczyć wskazówek co do ich niezawodności.
Jakie rodzaje kontroli monitorowania witryny są najbardziej przydatne?
Przed wyborem dostawcy chcesz ocenić swoje potrzeby. Odpowiedz na to, co by cię obudziło w środku nocy? Ta infrastruktura powinna być jednym z pierwszych składników konfigurowanych podczas testowania dostawców.
Opracuj plan ataku do monitorowania i sporządź listę usług, które musisz mieć. Dostawcy usług oferujący ustalone plany mogą tutaj pomóc lub zaszkodzić. Dobre plany uwzględniają wielkość korzystających z nich firm. Nigdy nie zaszkodzi zapytać o opcje uaktualnień i dodatków, aby dostosować swój plan.
Być może powodem, dla którego szukałeś monitora internetowego, był błąd 404 lub SSL, ale zostaw sobie miejsce na eksperymentowanie i rozwój. Podczas testowania bez wątpienia znajdziesz dodatkowe sposoby monitorowania systemu i wykorzystania przydziałów czeków.
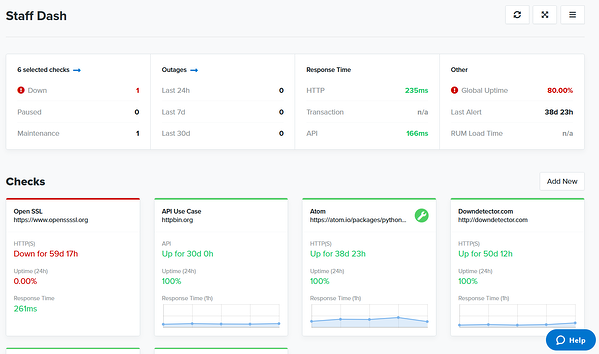
Podstawowe kontrole i ich funkcje monitorowania sieci
Podstawowe kontrole zwykle wykonują tylko jedną rzecz, na przykład monitorowanie pojedynczego adresu URL lub sprawdzanie rekordów DNS. Te typy sprawdzania zwykle skłaniają kogoś do wyszukania monitorowania, zwykle po wystąpieniu awarii. Ważne jest, aby to zrobić dobrze.
HTTP (S), SSL, DNS i wygaśnięcie domeny to kilka dobrych podstawowych kontroli, o których należy pamiętać, ponieważ są to rodzaje awarii, które zwykle odczuwa użytkownik końcowy. Kontrole te stanowią również podstawę monitorowania większości użytkowników korporacyjnych. Plany, które obejmują tylko te typy czeków, są silnymi planami „startowymi” dla start-upów i małych firm.
Kontrole HTTP(S), czasami nazywane „monitorowaniem sieci”, monitorują czas pracy bez przestojów. SSL, DNS i wygaśnięcie domeny zapewniają, że krytyczna infrastruktura nie ulegnie awarii z powodów, których można uniknąć. Jeśli Twój dostawca uwzględnia również wskaźniki wydajności, jest to wyraźny bonus.
Upewnij się, że Twój dostawca obsługuje dostarczanie alertów tam, gdzie jest to potrzebne. Jeśli zbliżało się wygaśnięcie SSL, pomocne byłoby przetasowanie się przez biurokrację i umieszczenie tego powiadomienia bezpośrednio przed osobą, która może zapłacić za odnowienie, z wystarczającym czasem na odnowienie. Byłoby jeszcze lepiej, gdyby sprawa mogła automatycznie eskalować do kogoś innego, gdyby potrzebna była większa wiedza.
Zaawansowane kontrole, które powinien rozważyć każdy zespół DevOps
Zaawansowana kontrola to taka, która albo wykorzystuje rzeczywiste dane użytkownika, albo opiera swoje działania na działaniach użytkownika. Te złożone typy sprawdzania zwykle wymagają pewnego wysiłku podczas konfiguracji. Wypłata może być olbrzymia dla organizacji, które z nich korzystają.
Zaawansowane typy kontroli nadzorują ścieżki celów krytycznych lub nawigacji, takie jak logowanie lub zakup przedmiotu. Ponieważ działają one jak prawdziwi użytkownicy (a czasem czerpią od nich dane), te kontrole dają jasny obraz wydajności witryny w różnych warunkach.
Po co inwestować wysiłek w skonfigurowanie tych typów czeków?
- Testowanie: wgląd w wydajność nowych funkcji i aktualizacji przy jednoczesnym generowaniu dużej ilości danych historycznych
- Pierwsza odpowiedź: awaria strony kasy może oznaczać, że więcej niż pojedyncze sprawdzenie HTTP(S) kończy się niepowodzeniem. Co zawiodło i kiedy jest dobrym wskaźnikiem tego, od czego zacząć diagnozę.
Spotkajmy się z Jamesem i zobaczmy, jak przydatne są różne typy czeków:
James wprowadza na rynek nowy produkt dla swojej firmy, Edgeco. Ta nowa usługa będzie wymagała własnego certyfikatu bezpieczeństwa oraz nowej infrastruktury. James wdroży tę usługę z monitorowaniem rzeczywistych użytkowników, aby dowiedzieć się więcej o wczesnych doświadczeniach użytkowników. Monitorowanie SSL zapewni, że gdy James przejdzie do innych projektów, jego certyfikat będzie miał zabezpieczenia, które zapewnią, że odnowienie nie zostanie zapomniane.
Dzięki kontroli HTTP(S) monitorującej ten adres URL, James i jego zespół mają możliwość pierwszej odpowiedzi w przypadku wykrycia przestoju. Korzystając ze sprawdzania transakcji, James może testować krytyczne przepływy użytkowników, takie jak logowanie się do nowej usługi i używanie jej podstawowych komponentów.
Ponieważ James wdrożył funkcję Real User Monitoring, jego usługa gromadziła statystyki użytkowania podczas każdej zmiany wprowadzonej przez niego i jego zespół w okresie istnienia usługi. W ciągu sześciu miesięcy James będzie miał wystarczającą ilość danych, aby zidentyfikować problemy z wydajnością zlokalizowane w określonych regionach i pokierować swoim zespołem, aby odpowiednio się ulepszył. Warstwy kontroli pomagają zabezpieczyć i uprościć zarządzanie złożoną infrastrukturą.
Oprogramowanie do monitorowania sieci, które warto mieć
Po ustaleniu typów czeków, których potrzebujesz, nadszedł czas, aby zacząć porównywać przydatne funkcje, aby ułatwić Ci życie. Istnieje tu duża różnica, ponieważ niektórzy dostawcy udostępniają stronę stanu lub integracje jako oferty „premium”.
Sprawozdawczość publiczna i prywatna
Widoczność ma znaczenie. Kto to może zobaczyć? Czy menedżerowie to zrozumieją? Czy opinia publiczna ma dostęp? Podczas awarii DevOps prawdopodobnie wywiera presję wewnętrznie i za pośrednictwem użytkowników, więc widoczne jest raportowanie.
Wsparcie nie działa za darmo. Każde zgłoszenie do pomocy technicznej, nawet z makro/szybką odpowiedzią, wymaga czasu. Ktoś musi wypełnić zgłoszenie, przestać pracować nad innym zadaniem i na nie odpowiedzieć. Zwiększ swoją bazę użytkowników o setki tysięcy lub miliony użytkowników, a pomoc techniczna może stracić całe dni produktywności, wysyłając te same standardowe odpowiedzi na pytania o to, czy jest w górę, czy w dół. Widoczne raportowanie tworzy platformę do odpowiadania na pytania i zmniejszania obciążenia związanego z odpowiedzią wsparcia.
Drugorzędną korzyścią jest przesyłanie wiadomości, ponieważ zła wiadomość może zniszczyć twoją reputację. Kiedy stoisz w obliczu katastrofy, skupiając się na przejrzystości, stajesz się źródłem wiadomości. To jest nieskończenie lepsze niż bycie zdanym na łaskę branży napędzanej przez klikanie kontrowersji.
Łatwość użytkowania i wartość
Wszystko od monitoringu i raportowania wygląda świetnie. A co z kosztami instalacji ? Podobnie jak zespół wsparcia, inżynierowie również nie pracują za darmo. Nawet przetestowanie dostawcy wiąże się z kosztami konfiguracji, więc poświęć trochę czasu na ocenę wszystkich swoich wymagań.
Łatwość użycia odnosi się do wszystkiego, od konfiguracji konta po wprowadzanie nowych użytkowników. Podczas okresu próbnego możesz skoncentrować się na podstawach i jak najszybciej zacząć działać; projektować długoterminowo i zastanowić się, w jaki sposób użytkownicy będą wchodzić w interakcję z systemem.

Jeśli zmieniasz dostawcę, przydatna jest również funkcja importu/eksportu, dzięki której możesz łatwo przesyłać setki czeków.
Dobrym przykładem jest oprogramowanie do jednokrotnego logowania (SSO), które zapewnia firmie pewien stopień bezpieczeństwa i ułatwia użytkownikom wdrożenie. Dokumentacja pomocy technicznej i ogólne użytkowanie mogą pomóc w uzyskaniu informacji o dostępności oprogramowania. Możesz rozważyć zaproszenie innego użytkownika, aby spróbował skonfigurować pewne kontrole lub pobrać raporty, aby przetestować działanie systemu z każdej perspektywy.
Dostosowanie i obserwowalność
Rozważmy przeciętny przypadek użycia w przedsiębiorstwie, w którym ponad 100 monitorów nie jest wykluczone. Jak wygląda raportowanie w tego rodzaju konfiguracji? Masywny, to jedno słowo. Powikłany, może inny. Ponad sto elementów będzie trudne do śledzenia, więc budowanie obserwowalności z monitorowania sieci powinno również uwzględniać to, co musisz zobaczyć, aby wykonać swoją pracę. Sposób, w jaki Twój dostawca radzi sobie z widocznością, wiele mówi o jego podstawowej działalności.
Niektóre przydatne funkcje, na które należy zwrócić uwagę, obejmują tagi, w których można kodować kolorami lub używać zespołowej lub wewnętrznej konwencji nazewnictwa do organizowania kontroli. Możesz również preferować pracę w wierszu poleceń, w którym to przypadku API jest ważną funkcją, której należy szukać. Pamiętaj tylko, aby zapytać o potencjalne ograniczenia, o których musisz wiedzieć, rozważając swoje opcje.
Deski rozdzielcze zapewniają widoczność wewnątrz
Jednym ze sposobów podejścia do problemu wolumenu jest zapewnienie scentralizowanej przestrzeni do zarządzania czekami. Jeśli jesteś typem, który lubi przegląd i natychmiastowy dostęp do kluczowych wskaźników, pulpity nawigacyjne zapewniają widoczność, której pragniesz. Bonusy tutaj obejmują możliwość dzielenia się. Czy Ty lub Twój zespół możesz projektować pulpity nawigacyjne, do których możesz się przełączać w locie? Czy możesz kontrolować dostęp lub przypisać konkretnym użytkownikom określone pulpity nawigacyjne?
Markowe strony statusu zapewniają zaufanie
Większość firm ceni przejrzystość, więc strony statusu to kolejna fajna rzecz. Zaufanie się nie objawia. Połączenie strony monitorowania i stanu zapewnia prostotę. Jeśli korzystasz z usług dostawcy dla każdej z tych usług, musisz mieć między nimi pewną warstwę, która pomaga wspierać komunikację między nimi. Zwykle oznacza to, że ktoś musi skrupulatnie stworzyć komponenty lub napisać skrypt. Nawet wtedy prawdopodobnie pobierasz dane do samoobsługowej usługi, która może powodować takie samo ryzyko przestoju jak Twoja witryna.
Bezproblemowe połączenie między stroną statusu a witryną wygląda profesjonalnie. Musisz jednak włączyć zarządzanie incydentami do procedury reagowania, w tym regularne aktualizacje strony stanu w okresie przestoju lub konserwacji.
Istnieją również wewnętrzne strony statusu zaprojektowane tak, aby przechowywać informacje na zasadzie niezbędnej wiedzy. Osoby spoza zespołu IT mogą mieć wgląd w krytyczne przestoje. Gdy nastąpi awaria, wewnętrzne strony stanu stają się centrum aktualizującym całą firmę.
Alerty i obserwowalność
Umowy dotyczące poziomu usług mają zwykle wbudowane progi, które sygnalizują, że nadszedł czas, aby zareagować na problem. Te „budżety błędów” pozwalają Twojemu zespołowi spać w nocy. Alerty i to, co one zawierają, decydują o czasie reakcji od pięciu do 60 minut.
Dobre ostrzeganie jest pouczające. Alerty mogą zawierać kody stanu, sugerowane poprawki lub kierować do przydatnych zasobów, takich jak analiza alertów. Najlepsze alerty oznaczają wystąpienie prawdziwego problemu i informują, jaki może być ten problem. „Uszkodzony” lub „Zgłasza błąd 500” wskazują na bardzo różne problemy.
Alerty i szczegóły
Zbyt niejasne i devops prawdopodobnie stracą włosy w poszukiwaniu problemu, ale rzadko występuje problem z byciem zbyt konkretnym. Dokładnie przetestuj systemy alarmowe. Jeśli planujesz zmienić dostawcę, uruchom ćwiczenie w dniu gry, korzystając z systemu alertów. Jakie informacje są przekazywane Twojemu zespołowi? Czy ostrzeżenie pomogło w Twojej diagnozie?
Jeśli planujesz wielokrotne przestoje, zarówno w formie ćwiczeń w trakcie gry, jak i rozszerzonych testów, możesz się wiele dowiedzieć o tym, jak działa Twój system monitorowania. Czy alerty są eskalowane? A co z okresami konserwacji zamiast przestojów? Czy Twój system może się odróżnić?
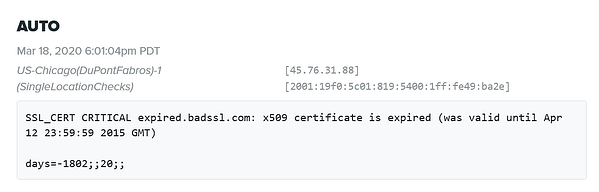
Dostawa alertu
Wróćmy do naszego przypadku użycia Edgecom. James monitoruje swoją usługę, gdy otrzymuje ping na swoim kanale Slack. Awaria HTTP(S) oznacza, że jego blog nie działa. James jest w stanie oznaczyć osobę odpowiedzialną za bloga, która szybko bada incydent. Okazuje się, że przyczyną jest nietypowa liczba wczytań stron.
Zespół zastanawia się, czy ostatni post stał się wirusowy. James wyczuwa zbliżający się atak i skaluje serwery w celu zwiększenia pojemności. Rzeczywiście, jego działania są częścią łańcucha wydarzeń, które pomagają odeprzeć atak DDoS mający na celu zniszczenie jego głównej witryny.
Morał jest taki, że alerty dostarczane Twojemu zespołowi mogą prowadzić do diagnozy i nieoczekiwanego zbiegu okoliczności. Brak alertów oznacza ból. Okropny ból.
Monitorowanie sieci to tak naprawdę analiza
Nie przeocz wartości historii alarmów. Doświadczeni użytkownicy devops prawdopodobnie mają nadprzyrodzone wyczucie katastrofy. Jak doskonalą ten zmysł? Obserwując przyczyny katastrofy i dokładnie je dokumentując.
Eskalacje i elastyczność
Powiedzmy, że James nie jest już DevOps Spider-Manem, a jego nadprzyrodzone zmysły nie są w stanie zgasić. Atak DDoS powoduje wyłączenie niektórych usług. W czym może pomóc dostawca usług monitorowania?
Eskalacje i konserwacja to dobry początek. Jeśli Twój dostawca na to pozwala, okna konserwacji mogą zapewnić elastyczność w reagowaniu na awarie, jednocześnie ostrzegając użytkowników. Niezależnie od tego, czy konserwacja ma wpływ na umowę SLA, czy nie, jest to przydatne, gdy można zaplanować okresy rutynowej konserwacji i przesyłać aktualizacje do zaawansowanych użytkowników.
Tracisz również mniej czasu na tasowanie odpowiedzialności i eskalację wewnętrznie, jeśli wcześniej określisz swoje granice. Jak długo trwa przestój? Eskalacja po pięciu lub dziesięciu minutach to dobry początek, ponieważ dłuższe przerwy oznaczają, że coś jest naprawdę nie tak. Systemy alertów, które automatyzują eskalacje, usuwają to zgadywanie, umożliwiając zespołowi pracę bez martwienia się o to, kiedy powiadomić wyższe poziomy.
Syntetyczne i rzeczywiste monitorowanie sieci przez użytkowników, aby uchwycić wrażenia użytkownika
Przestań polegać na raportach użytkowników płacących beta testerów (Twoich klientów) i uchwyć wrażenia użytkownika z pierwszej ręki. Monitorowanie rzeczywistych użytkowników zazwyczaj wymaga pewnego kodu, takiego jak piksel śledzący, ale korzyścią są rzeczywiste dane użytkownika z rzeczywistych sesji. Jeśli kiedykolwiek zastanawiałeś się, co widzi Twój użytkownik, monitorowanie RUM jest przydatnym dodatkiem do Twojego zestawu narzędzi.
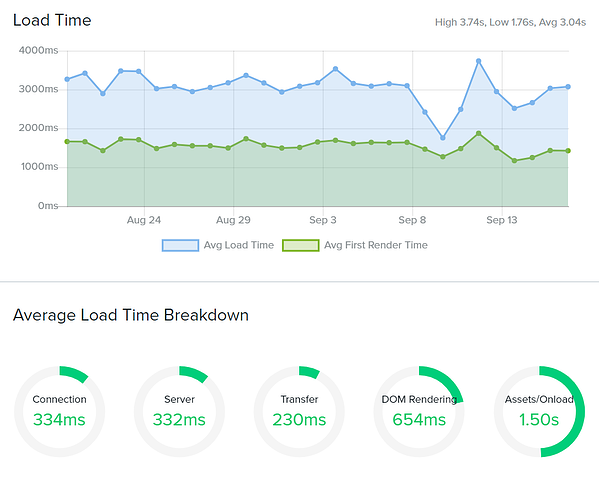
Monitorowanie syntetyczne
Monitoring syntetyczny występuje w dwóch wersjach, zazwyczaj: API i Transaction. Kontrole transakcji są dokładnie takie, jak brzmią. Testują ścieżki celów i zapewniają możliwość pierwszej odpowiedzi na krytyczne transakcje. Bądź pierwszym, który dowie się o problemach z koszykiem, formularzami rejestracji, loginami i nie tylko.
Kontrole API są przydatne do badania punktów końcowych, które sterują stroną automatyzacji Twojej usługi. Możesz GET, PUSH, PULL, PATCH lub DELETE z większością dostawców, co daje szereg możliwości monitorowania punktów końcowych. Dodatkowe punkty, jeśli możesz ustawić i pobrać zmienne.
Wsparcie jest niewidocznym czynnikiem w monitorowaniu sieci
Jest druga w nocy, a monitorowanie sieci wysyła alerty z lewej i prawej strony. Potrzebujesz pomocy! Potrzebujesz analizy i wyjaśnień. Responsywne wsparcie ze strony twojego dostawcy udowadnia swoją wartość, gdy napotkasz błąd, którego albo nie widzisz, albo nie możesz zreplikować.
Kiedy potrzebujesz pomocy, ważny jest zespół chętny do współpracy. Wczesne interakcje wsparcia są dobrym wskaźnikiem jakości usług. Ile czasu zajmuje agentom odpowiedź na zgłoszenie? Jaka jest jakość ich odpowiedzi i jaką dokumentację mogą dostarczyć? Jakie rodzaje pomocy są dostępne, takie jak pomoc telefoniczna lub na czacie? Gdy dostawca ukrywa przycisk kontaktu, może to być czerwona flaga.
Dokumentacja
Dokumentacja powinna być dokładna, zawierać przykłady i zawierać instrukcje krok po kroku. Jeśli twój dostawca używa kodu w swojej dokumentacji, to dobry znak, że wie, o czym mówi i traktuje to poważnie. Dodatkowe punkty dla dostawców, którzy opracowują zewnętrzne zestawy narzędzi, rozszerzenia przeglądarki i nie tylko, aby pomóc w tworzeniu systemu monitorowania.
Zobowiązanie do dostawcy monitorowania sieci
Monitorowanie i raportowanie to najważniejsze elementy decydujące o wyborze dostawcy, ale lista przydatnych funkcji może uprościć pracę i usprawnić nadzór. Pamiętaj, że celem alertu jest pierwsza odpowiedź. Jeśli twój alarm ginie w eterze i nikt nie może go twierdzić, czy ogień naprawdę się wydarzył?
Oprogramowanie do monitorowania sieci jest częścią ważnego zobowiązania, jakie podejmujesz wobec swojej bazy klientów. Mówi, że zależy Ci na świadczeniu usługi i że Twoi użytkownicy mogą ufać, że będziesz tam dla nich. Poważne potraktowanie tego zobowiązania oznacza zastanowienie się, które z tych wymagań jest najbardziej istotne dla Twojej organizacji.