
Tutto ciò che devi sapere sul database serverless
Pubblicato: 2022-12-23Preparati a conoscere tutto sul futuro dei database di prossima generazione, ovvero i database Serverless!
Qualsiasi database che aderisce ai principi fondamentali dell'elaborazione senza server è un database senza server. Serverless Database è stato creato per carichi di lavoro imprevedibili e che possono cambiare rapidamente.
Serverless non significa che non sono necessari server. Significa che i server sottostanti non devono essere gestiti, forniti o pagati da te.
Paghi per le risorse che utilizzi in base alle loro capacità di CPU e RAM e alla loro attività.
Come funziona il database senza server
Il modello Serverless Database si basa sulla separazione tra elaborazione e archiviazione. È necessario creare un endpoint e impostare le capacità minima e massima.
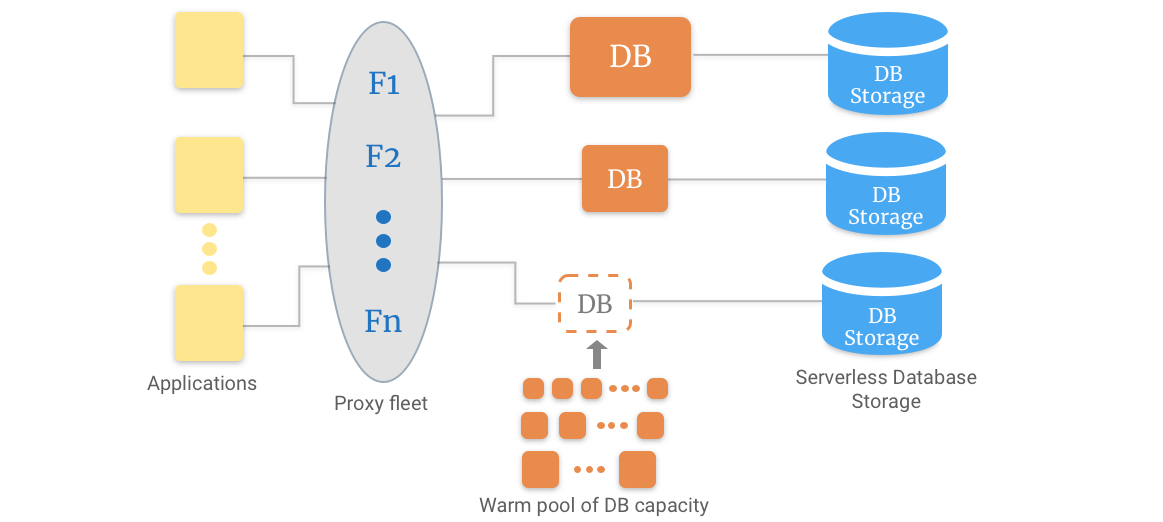
Quindi, puoi inviare query all'endpoint. Questo proxy funge da collegamento a un gran numero di risorse del database. Ciò consente alle tue connessioni di rimanere intatte anche se le operazioni di ridimensionamento avvengono dietro le quinte.
Separare l'archiviazione dall'elaborazione ha un altro vantaggio. È possibile ridurre l'elaborazione a zero e devi solo pagare per l'archiviazione. Il ridimensionamento può essere eseguito in soli 5 secondi, a seconda dell'applicazione. Hai anche accesso a un pool di risorse "calde" pronte ad aiutarti con le tue esigenze.
Database senza server: vantaggi

Efficienza dei costi
Un numero fisso di server è più costoso di un database senza server e richiede più tempo per l'acquisto. Può essere più economico rispetto alla creazione di un gruppo di scalabilità automatica ed è anche più conveniente perché il bin-packing delle risorse della macchina lo rende più efficiente.
Ciò include la licenza, l'installazione, la manutenzione, il supporto e l'applicazione di patch. Ti viene addebitato solo il tempo e la memoria utilizzati per eseguire il codice.
Scalabilità automatizzata
Gli sviluppatori non devono configurare o impostare criteri o sistemi di scalabilità automatica per ottenere una scalabilità serverless basata sul carico di lavoro. Tutto questo ricade sulle spalle del provider cloud, che deve soddisfare le richieste effettive con i poteri prestazionali adeguati.
Distribuzioni e aggiornamenti rapidi
L'infrastruttura serverless elimina la necessità di caricare il codice sui server e configurare le impostazioni di back-end per creare un'applicazione funzionante. È facile per gli sviluppatori caricare piccoli pezzi di codice e quindi rilasciare un nuovo prodotto. Gli sviluppatori possono caricare entrambi i codici contemporaneamente e una funzione alla volta.
Ciò semplifica l'aggiornamento, la correzione, la correzione o l'aggiunta rapida di nuove funzionalità a un'app. Gli sviluppatori possono apportare piccole modifiche a un'applicazione anziché aggiornare l'intera applicazione.
Maggiore produttività
Otterrai di più dal tuo sistema serverless se ci dedichi meno tempo, fai meno sforzi nelle aree in cui è richiesta l'interazione e assumi un team di professionisti dimensionato in modo ottimale per ottenere risultati migliori.
Database senza server: svantaggi
Problemi di avviamento a freddo
La gestione delle partenze a freddo è uno degli aspetti più importanti e impegnativi in questo campo. Un database serverless che non viene utilizzato rimarrà semplicemente inattivo per conservare le risorse e impedire prestazioni non necessarie.
Il sistema si “sveglia” e ha bisogno di tempo per riavviare tutti i suoi processi. Potresti riscontrare ritardi e tempi di risposta lenti se sei la prima persona a toccare il sistema all'avvio a freddo.
Difficoltà di test e debug delle applicazioni
Il modello serverless presenta un'altra sfida. È difficile replicare un ambiente serverless per testare e monitorare le prestazioni del codice prima che diventi attivo. Ciò è dovuto in parte al fatto che gli sviluppatori non hanno accesso ai servizi di back-end del provider di servizi cloud.
Per eseguire il debug di sistemi complessi in modo approfondito ed efficiente, non è possibile utilizzare un profiler o un debugger. Hai la possibilità di provare strumenti di terze parti sempre più disponibili sul mercato.
Più monitoraggio
Le soluzioni serverless richiedono di porre maggiore enfasi sul monitoraggio e sulla segnalazione dei problemi di prestazioni o dell'uso eccessivo delle risorse. Ciò è dovuto in gran parte al fatto che le soluzioni cloud sono raramente open-source.
Blocco del venditore
Durante la migrazione a un altro provider, la scelta di un modello senza server può presentare problemi. Ciò è dovuto al fatto che ogni provider ha flussi di lavoro e funzionalità diversi.
Funzionalità del database senza server
I database serverless offrono alcune delle funzionalità più interessanti, come:
#1. Architettura multi-tenant
I database senza server offrono il vantaggio di poter utilizzare una singola risorsa del pool che può essere utilizzata per più progetti nell'organizzazione. Questo è un grande vantaggio per gli sviluppatori in quanto non devono creare origini di dati in silos specifiche per l'applicazione.
L'architettura multi-tenant lo rende possibile. Gli sviluppatori possono impostare, configurare e distribuire più applicazioni all'interno di un singolo cluster di database.
#2. Distribuzione geografica
Poiché la maggior parte delle aziende opera su base globale, è essenziale che i dati siano disponibili in tutto il mondo. L'esperienza in tempo reale può essere migliorata dalla vicinanza ai data center. Viene inoltre eliminato un punto di errore, quindi la possibilità di un'interruzione è molto improbabile.

I database serverless consentono di replicare più set di dati in tutto il mondo senza strumenti aggiuntivi o sviluppo personalizzato.
#3. Poca o nessuna amministrazione manuale del server
Serverless è un termine improprio. È una raccolta di server che sono stati astratti e automatizzati per semplificarne la gestione. Tutte le attività manuali, come il provisioning, la pianificazione della capacità, la scalabilità, la manutenzione, gli aggiornamenti e così via, vengono ancora eseguite dietro le quinte. Sono molto facili da usare e richiedono poco o nessun intervento manuale.
#4. Fatturazione a consumo
Il database serverless, poiché i costi sono basati sull'utilizzo, è il più conveniente. L'archiviazione non è richiesta. Paghi solo per quello che usi. Se vuoi evitare il superamento del budget, puoi impostare un limite di spesa.
Database serverless relazionali e non relazionali

I dati dell'era digitale possono essere classificati in dati operativi e dati analitici. Diamo un'occhiata ad alcune diverse opzioni di database che gli sviluppatori raggiungono e vediamo come si confrontano.
La maggior parte delle aziende richiede sistemi OLTP (operativi) e OLAP (analitici) per archiviare i propri dati. Possono utilizzare un database relazionale o non relazionale per supportare le proprie esigenze aziendali.
Database relazionale senza server
Un database relazionale è un tipo di database che organizza e raccoglie dati in base a relazioni predefinite tra punti dati chiave. Organizza i dati in modo che più utenti possano trovare e ordinare i dati senza modificare la categorizzazione logica dei dati.
Elimina la duplicazione dei dati nei processi di archiviazione. Structured Query Language è l'interfaccia del programma applicativo (API) per una banca dati relazionale.
Questo sistema presenta i dati in formato tabellare. Questa tabella rappresenta un'entità, ad esempio un prodotto o un'app per dispositivi mobili. Ogni riga è il valore effettivo e ogni riga ha un identificatore univoco che è un'istanza di questo tipo di entità. Ecco perché vengono chiamati i record.
Le colonne, invece, contengono gli attributi dei dati. Sono il valore effettivo dell'entità. L'accesso ai dati è possibile senza dover riorganizzare la tabella del database.
Database senza server NoSQL (non relazionale).
I database non relazionali (NoSQL) hanno maggiori probabilità di essere distribuiti rispetto ai database SQL. Può essere utilizzato con un gran numero di database. Le aziende devono utilizzare funzionalità moderne come i database NoSQL per creare applicazioni cloud-native.
I database serverless NoSQL vengono utilizzati nelle app Web in tempo reale. Sono semplici nel design e possono gestire rapidamente grandi quantità di dati con ridimensionamento orizzontale. Questo è l'ideale per le situazioni in cui lo schema non è chiaro e potrebbero essere richieste velocità di importazione elevate.
I database serverless NoSQL sono molto popolari in quanto memorizzano grandi quantità di dati in molte forme, inclusi grafici, documenti, coppie chiave/valore e strutture di dati orientate alle colonne. Questo rende facile per gli sviluppatori modificare la struttura dei dati.
Perché si dovrebbero usare database serverless?
I database serverless sono un'ottima opzione per i piccoli team che non dispongono di personale sufficiente per gestire e ridimensionare i database tradizionali. I database serverless richiedono poca infrastruttura e manutenzione. Ciò significa che il tuo team dovrà dedicare meno tempo alla manutenzione del sistema. È anche facile creare nuove tabelle e testare nuove funzionalità utilizzando un database senza server.
Infine i costi. I database serverless ti consentono di pagare solo per ciò che usi senza dover configurare e ottimizzare i costi come i database tradizionali. I database serverless sono ottimi per sviluppatori e team che devono implementare rapidamente nuove funzionalità.
Casi d'uso di database senza server

#1. Nuove applicazioni
Pochi minuti di utilizzo nel corso di una settimana o di un giorno. Se possiedi un blog con poco traffico e vuoi pagare solo per il tempo in cui qualsiasi utente accede al tuo sito, questa è un'opzione. Paghi al secondo per le risorse del database che utilizzi.
#2. Ridimensionamento elastico per la trasmissione di video in diretta
La trasmissione video in diretta è resa possibile dall'architettura senza server. Più membri del pubblico possono interagire in scenari di trasmissione video in diretta. L'host può essere connesso a più microfoni contemporaneamente. Un host può connettere diversi membri del pubblico o amici allo schermo e quindi sintetizzare l'immagine in uno scenario che viene presentato agli spettatori in live streaming.
#3. Applicazioni usate raramente
Se hai un'app di cui sei orgoglioso e non sai come verrà accolta e perché non vuoi che l'app fallisca, questo metodo fa per te. Crea semplicemente un endpoint e il database serverless si ridimensionerà automaticamente per soddisfare le esigenze della tua applicazione.
#4. Internet delle cose (IoT)
L'IoT può essere descritto come un termine che descrive i dispositivi presenti oggi nelle case che possono connettersi a Internet per svolgere varie funzioni. FaaS viene sempre più utilizzato da questi dispositivi per svolgere le proprie attività. Inviano e ricevono dati solo quando un evento li attiva.
Le aziende risparmiano denaro non dovendo pagare extra per la potenza di calcolo che non utilizzano. FaaS rende possibile la scalabilità rapida e automatica, quindi gli sviluppatori non devono preoccuparsi di modelli di utilizzo imprevedibili.
Conclusione
Questi scenari mostrano che l'architettura serverless ha molti vantaggi per sviluppatori e aziende. I database serverless possono migliorare la velocità di elaborazione e la resilienza riducendo i tempi e i costi di scalabilità e risorse. Esistono molti tipi di database serverless, sia relazionali che non relazionali. Tuttavia, hanno tutti lo stesso obiettivo: scalare su richiesta senza aggiungere oneri di gestione e ridurre solo i costi