
サーバーレス データベースについて知っておくべきこと
公開: 2022-12-23次世代のデータベース、つまりサーバーレス データベースについて詳しく知る準備をしましょう。
サーバーレス コンピューティングのコア原則に準拠しているデータベースはすべて、サーバーレス データベースです。 サーバーレス データベースは、予測不可能で急速に変化するワークロード向けに作成されました。
サーバーレスとは、サーバーが必要ないという意味ではありません。 これは、基盤となるサーバーを管理、プロビジョニング、または支払う必要がないことを意味します。
CPU と RAM の容量、およびリソースのアクティブ度に基づいて、使用したリソースに対して料金を支払います。
サーバーレス データベースの仕組み
サーバーレス データベース モデルは、処理とストレージの分離に依存しています。 エンドポイントを作成し、最小容量と最大容量を設定する必要があります。
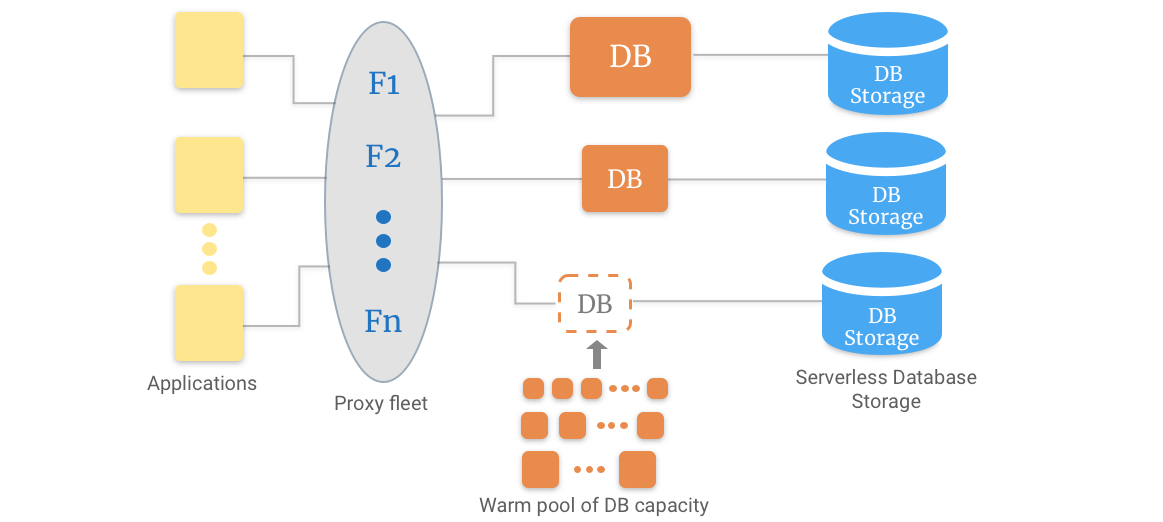
その後、エンドポイントにクエリを発行できます。 このプロキシは、多数のデータベース リソースへのリンクとして機能します。 これにより、スケーリング操作が舞台裏で行われても、接続はそのまま維持されます。
ストレージを処理から分離することには、別の利点があります。 処理をゼロにスケールダウンすることが可能で、ストレージの料金のみを支払う必要があります。 アプリケーションにもよりますが、スケーリングはわずか5秒で完了します。 また、ニーズに合わせて役立つ「ウォーム」リソースのプールにもアクセスできます。
サーバーレス データベース: 利点

コスト効率
固定数のサーバーは、サーバーレス データベースよりもコストがかかり、購入に時間がかかります。 自動スケーリング グループを設定するよりもコストがかからず、マシン リソースのビン パッキングによって効率が向上するため、費用対効果も高くなります。
これには、ライセンス、インストール、メンテナンス、サポート、およびパッチ適用が含まれます。 コードの実行に使用した時間とメモリに対してのみ課金されます。
自動スケーラビリティ
開発者は、ワークロードに基づくサーバーレス スケーリングを実現するために、自動スケーリング ポリシーやシステムを構成またはセットアップする必要はありません。 これはすべて、適切なパフォーマンス力で実際の要求を満たす必要があるクラウド プロバイダーの肩にかかっています。
迅速な展開と更新
サーバーレス インフラストラクチャにより、コードをサーバーにアップロードし、バックエンド設定を構成して動作するアプリケーションを作成する必要がなくなります。 開発者が小さなコードをアップロードして、新しい製品をリリースするのは簡単です。 開発者は、両方のコードを一度にアップロードし、一度に 1 つの関数をアップロードできます。
これにより、アプリの更新、パッチ適用、修正、新機能の追加が簡単になります。 開発者は、アプリケーション全体を更新するのではなく、アプリケーションに小さな変更を加えることができます。
生産性の向上
サーバーレス システムに費やす時間を減らし、対話が必要な領域での労力を減らし、より良い結果を得るために最適な規模の専門家チームを雇えば、サーバーレス システムを最大限に活用できます。
サーバーレス データベース: 短所
コールドスタートの問題
コールド スタートの処理は、この分野で最も重要かつ困難な側面の 1 つです。 使用されていないサーバーレス データベースは、リソースを節約し、不要なパフォーマンスを防ぐためにアイドル状態になります。
システムが「起動」し、すべてのプロセスを再起動する時間が必要です。 コールド スタートのシステムに最初に触れると、遅延や応答時間が遅くなることがあります。
アプリケーションのテストとデバッグが困難
サーバーレス モデルには別の課題があります。 サーバーレス環境をレプリケートして、稼働前にコードのパフォーマンスをテストおよび監視することは困難です。 これは、開発者がクラウド プロバイダーのバックエンド サービスにアクセスできないことが原因の 1 つです。
複雑なシステムを詳細かつ効率的にデバッグするために、プロファイラーやデバッガーを使用することはできません。 市場でますます入手可能になっているサードパーティのツールを試すオプションがあります。
より多くの監視
サーバーレス ソリューションでは、パフォーマンスの問題やリソースの過剰使用を監視して指摘することに重点を置く必要があります。 これは主に、クラウド ソリューションがほとんどオープンソースではないという事実によるものです。
ベンダーロックイン
別のプロバイダーに移行する場合、サーバーレス モデルを選択すると問題が発生する可能性があります。 これは、プロバイダーごとにワークフローと機能が異なるためです。
サーバーレス データベースの機能
サーバーレス データベースは、次のような最もエキサイティングな機能を提供します。
#1。 マルチテナント アーキテクチャ
サーバーレス データベースには、組織内の複数のプロジェクトに使用できる単一のプール リソースを使用できるという利点があります。 これは、アプリケーション固有のサイロ化されたデータ ソースを作成する必要がないため、開発者にとって大きなメリットです。
マルチテナント アーキテクチャがこれを可能にします。 開発者は、単一のデータベース クラスタ内で複数のアプリケーションをセットアップ、構成、および展開できます。
#2。 地域分布
ほとんどのビジネスはグローバル ベースで運営されているため、世界中でデータを利用できることが不可欠です。 リアルタイム エクスペリエンスは、データ センターに近いことで強化できます。 障害点も排除されるため、停止の可能性はほとんどありません。

サーバーレス データベースを使用すると、追加のツールやカスタム開発を行うことなく、世界中に複数のデータ セットをレプリケートできます。
#3。 手動によるサーバー管理はほとんどまたはまったくありません
サーバーレスは誤称です。 これは、抽象化され、管理しやすくするために自動化されたサーバーのコレクションです。 プロビジョニング、キャパシティ プランニング、スケーリング、メンテナンス、更新などのすべての手動タスクは、引き続きバックグラウンドで実行されます。 これらは非常に使いやすく、手動による介入はほとんどまたはまったく必要ありません。
#4。 従量課金制
サーバーレス データベースは、料金が使用量に基づいているため、最も費用対効果が高くなります。 ストレージは必要ありません。 使用した分だけお支払いいただきます。 予算超過を回避したい場合は、支出制限を設定できます。
リレーショナル サーバーレス データベースと非リレーショナル サーバーレス データベース

デジタル年齢データは、運用データと分析データに分類できます。 開発者が到達するいくつかの異なるデータベース オプションを見て、それらがどのように比較されるかを見てみましょう。
ほとんどの企業では、データを格納するために OLTP (運用) および OLAP (分析) システムが必要です。 ビジネス ニーズをサポートするために、リレーショナル データベースまたは非リレーショナル データベースのいずれかを使用できます。
リレーショナル サーバーレス データベース
リレーショナル データベースは、主要なデータ ポイント間の定義済みの関係に従ってデータを編成および収集するデータベース タイプです。 複数のユーザーが論理データの分類を変更せずにデータを検索およびソートできるように、データを編成します。
ストレージプロセスでのデータの重複を排除します。 構造化照会言語は、リレーショナル データバンク用のアプリケーション プログラム インターフェイス (API) です。
このシステムは、データを表形式で表示します。 このテーブルは、製品やモバイル アプリなどのエンティティを表します。 各行は実際の値であり、各行には、このタイプのエンティティのインスタンスである一意の識別子があります。 そのため、レコードが呼び出されます。
一方、列はデータの属性を保持します。 それらはエンティティの実際の値です。 データベーステーブルを再編成することなく、データにアクセスできます。
NoSQL (非リレーショナル) サーバーレス データベース
非リレーショナル データベース (NoSQL) は、SQL データベースよりも分散される可能性が高くなります。 多数のデータベースで使用できます。 企業は、NoSQL データベースなどの最新の機能を使用して、クラウドネイティブ アプリケーションを構築する必要があります。
NoSQL サーバーレス データベースは、リアルタイム Web アプリで使用されます。 設計がシンプルで、水平方向のスケーリングで大量のデータをすばやく処理できます。 これは、スキーマが不明確で、高い取り込み率が必要になる可能性がある状況に最適です。
NoSQL サーバーレス データベースは、グラフ、ドキュメント、キーと値のペア、列指向のデータ構造など、さまざまな形式で大量のデータを格納するため、非常に人気があります。 これにより、開発者はデータ構造を簡単に変更できます。
サーバーレス データベースを使用する必要があるのはなぜですか?
サーバーレス データベースは、従来のデータベースを管理およびスケーリングするのに十分なスタッフがいない小規模なチームに最適なオプションです。 サーバーレス データベースでは、インフラストラクチャとメンテナンスはほとんど必要ありません。 これは、チームがシステムの保守に費やす時間を短縮できることを意味します。 また、サーバーレス データベースを使用して、新しいテーブルを作成し、新しい機能をテストすることも簡単です。
最後にコストです。 サーバーレス データベースでは、従来のデータベースのようにコストを構成して微調整する必要がなく、使用した分だけ支払うことができます。 サーバーレス データベースは、新しい機能を迅速にプッシュする必要がある開発者やチームに最適です。
サーバーレス データベースのユース ケース

#1。 新しいアプリケーション
1 週間または 1 日の間に数分間の使用。 トラフィックの少ないブログを所有していて、ユーザーがサイトにアクセスした時間に対してのみ料金を支払いたい場合、これはオプションです。 使用したデータベース リソースに対して 1 秒ごとに料金が発生します。
#2。 ライブ ビデオ ブロードキャストの柔軟なサイズ変更
サーバーレスアーキテクチャにより、ライブビデオブロードキャストが可能になります。 ライブ ビデオ ブロードキャストのシナリオでは、複数の視聴者メンバーが対話できます。 ホストは複数のマイクに同時に接続できます。 主催者は、複数の視聴者や友人を画面に接続し、ライブ ストリームの視聴者に提示される 1 つのシナリオに画像を合成できます。
#3。 使用頻度の低いアプリケーション
あなたが誇りに思っているアプリを持っていて、それがどのように受け入れられるかわからない場合、そしてアプリが失敗したくないので、この方法はあなたのためです. エンドポイントを作成するだけで、サーバーレス データベースがアプリケーションのニーズに合わせて自動的にスケーリングされます。
#4。 モノのインターネット (IoT)
IoT は、インターネットに接続してさまざまな機能を実行できる、今日の家庭にあるデバイスを表す用語として説明できます。 FaaS は、これらのデバイスでタスクを実行するためにますます使用されています。 イベントがトリガーされたときにのみデータを送受信します。
企業は、使用していないコンピューティング パワーに追加料金を支払う必要がないため、コストを節約できます。 FaaS を使用すると、迅速かつ自動的にスケーリングできるため、開発者は予測できない使用パターンについて心配する必要がありません。
結論
これらのシナリオは、サーバーレス アーキテクチャが開発者と企業に多くのメリットをもたらすことを示しています。 サーバーレス データベースは、スケーリングとリソースの時間とコストを削減しながら、コンピューティング速度と回復力を向上させることができます。 サーバーレス データベースには、リレーショナルと非リレーショナルの両方の多くの種類があります。 ただし、それらはすべて同じ目標を持っています。つまり、管理の負担を増やさずにオンデマンドでスケーリングし、コストを削減することです。