
Google Ads에서 Google BigQuery로 원시 데이터를 업로드하는 방법
게시 됨: 2022-04-12Google 애널리틱스에서 Google Ads 광고 캠페인의 효과를 분석하면 샘플링, 데이터 집계 또는 기타 시스템 인터페이스 제한이 발생할 수 있습니다. 다행히도 이 문제는 광고 서비스의 원시 데이터를 Google BigQuery에 업로드하면 쉽게 해결됩니다.
이 문서에서는 Google Ads 계정에서 BigQuery로 원시 데이터를 업로드하고 자동 레이블이 지정된 캠페인의 모든 UTM 태그를 식별하는 방법을 알아봅니다.
캠페인 정보를 사이트의 사용자 활동에 연결하려면 OWOX BI가 필요합니다. 데모에 등록하면 OWOX BI로 해결할 수 있는 모든 문제에 대해 자세히 설명하겠습니다.
목차
- Google Ads의 원시 데이터가 필요한 이유
- Google Ads에서 BigQuery로 원시 데이터를 업로드하는 두 가지 방법
- 데이터 전송을 사용하여 업로드를 구성하는 방법
- 광고 스크립트를 사용하여 업로드를 설정하는 방법
- Google Ads에서 OWOX BI로 데이터 다운로드를 연결하는 방법
- 유용한 팁
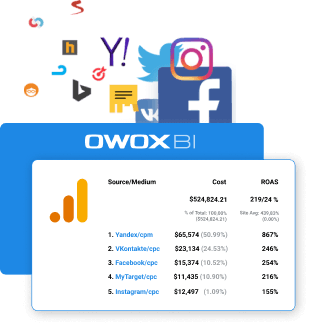
캠페인의 진정한 가치 알아보기
모든 광고 서비스에서 Google Analytics로 비용 데이터를 자동으로 가져옵니다. 단일 보고서에서 캠페인 비용, CPC 및 ROAS를 비교합니다.
Google Ads의 원시 데이터가 필요한 이유
Google Ads의 원시 데이터를 사용하면 각 키워드까지 정확하게 광고 캠페인을 분석할 수 있습니다. BigQuery에 데이터를 업로드하여 다음을 수행할 수 있습니다.
- GA 제한 사항의 제한 없이 원하는 만큼 상세한 보고서를 작성하십시오.
- 세션 및 사용자 수준에서 광고 캠페인의 효과를 결정합니다.
- 지역, 사용자 유형(신규 또는 반환), 장치 및 기타 매개변수별로 ROI, ROAS, CRR을 계산합니다.
- 요금을 효과적으로 관리하고 리마케팅 목록을 만드십시오.
- Google Ads, Google Analytics 및 CRM의 데이터를 결합하여 항목의 마진과 상환 가능성을 기반으로 캠페인의 효율성을 평가합니다.
- 보다 정확한 계획을 위해 ML 모델을 학습시키십시오.
어떤 캠페인, 광고, 키워드가 사용자를 사이트로 유도하는지 이해하려면 Google Ads와 Analytics의 데이터를 BigQuery로 결합해야 합니다. OWOX BI 스트리밍을 사용하여 이 작업을 수행할 수 있습니다.
이 정보를 스트리밍하면 사이트의 샘플링되지 않은 사용자 행동 데이터가 GBQ로 전송됩니다. 조회수는 실시간으로 전송되며 이러한 조회수를 기반으로 세션이 형성됩니다.
OWOX BI 트래픽 소스 정보는 UTM 태그 광고 마크업에서 가져옵니다. 태그는 수동 및 자동입니다.
광고를 수동으로 표시했고 다음 URL을 얻었다고 가정해 보겠습니다.
https://example.com/?utm_source=facebook&utm_medium=cpc&utm_campaign=utm_tags
이 경우 OWOX BI를 연결한 후 GBQ 테이블에서 소스, 채널 및 캠페인 데이터를 사용할 수 있습니다.
- trafficSource.source — 구글
- trafficSource.medium — CPC
- trafficSource.campaign — utm_tags
UTM 태그를 올바르게 만드는 방법에 대해 자세히 알아보세요.
광고 서비스에서 자동 마크업을 활성화한 경우 각 광고에 특수 gclid 매개변수가 할당됩니다. 사용자가 공지사항을 클릭하면 방문 페이지 URL에 추가됩니다.
그러한 링크의 예:
http://www.example.com/?gclid=TeSter-123
자동 마크업을 사용하는 경우 원시 데이터 없이 gclid에서 소스, 매체 또는 캠페인을 가져올 수 없습니다. 이러한 필드는 OWOX BI가 수집하는 BigQuery 테이블에서 비어 있습니다.
이러한 경우에 무엇을 할 수 있으며 gclid만 있는 캠페인 및 기타 매개변수의 이름을 어떻게 얻을 수 있습니까? Google Ads에서 GBQ로 자동 업로드를 구성합니다.
참고: 공지 사항이 전혀 표시되지 않은 경우 OWOX BI는 다음과 같이 링크를 할당합니다.
- 추천 트래픽(예: facebook/referral)으로 Google 이외의 소스에 대해
- Google 소스의 경우 직접 트래픽(직접/없음)
보고서에 직접/없음 트래픽이 많은 경우 봇 필터링이 활성화되지 않았거나 태그가 지정되지 않은 광고가 많을 수 있습니다.
Google Ads에서 BigQuery로 원시 데이터를 업로드하는 두 가지 방법
Google Ads에서 원시 데이터를 업로드하는 데 데이터 전송 커넥터와 광고 스크립트의 두 가지 방법을 사용하고 권장합니다.
선택하는 방법은 목표와 예산에 따라 다릅니다.
데이터 전송 기능
- GBQ와의 기본 통합.
- 제한 없이 모든 기간에 대한 기록 데이터를 다운로드합니다.
- 무료로.
Google Ads 스크립트 기능
- 무료.
- 과거 데이터를 업로드할 수 없습니다. 전날의 정보만 다운로드 됩니다.
- 많은 수의 계정에서 업로드를 설정하려면 더 많이 필요합니다. 각 계정에 대해 스크립트를 수동으로 변경해야 합니다. 동시에 실수할 위험도 높습니다.
설정에 필요한 것
활성 프로젝트 및 계정:
- 구글 클라우드 플랫폼(GCP)
- 구글 빅쿼리(GBQ)
- 오복스 BI
- 구글 광고
접속하다:
- GCP의 소유자
- GBQ의 관리자
- OWOX BI에서 편집. 중요: Google Analytics → Google BigQuery 스트리밍 파이프라인을 만든 사용자만 Google Ads에서 다운로드를 켤 수 있습니다.
- Google Ads에서 읽기
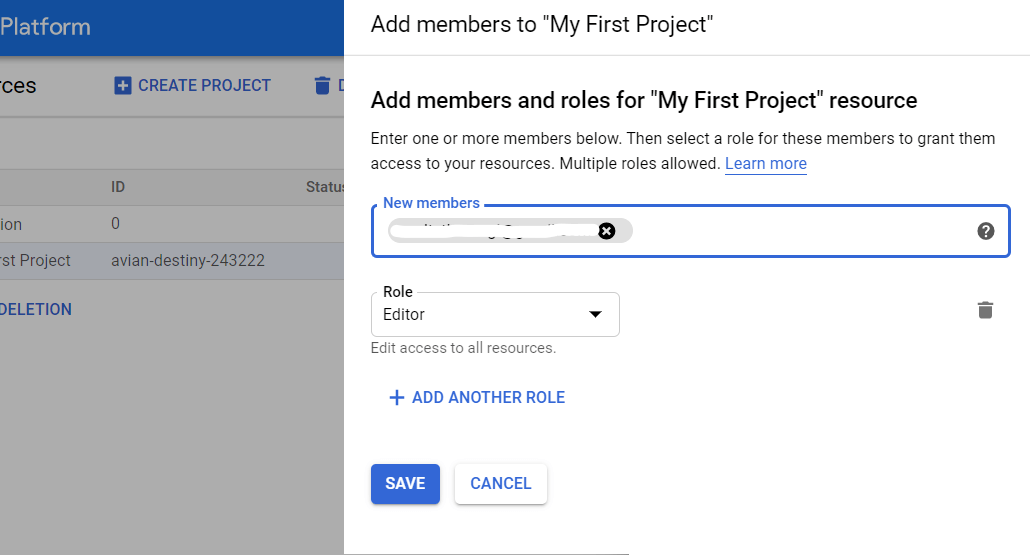
GBQ에서 접근 권한을 부여하는 방법
GCP 콘솔을 열고 사이드 메뉴에서 IAM 및 관리자 — 리소스 관리를 선택합니다. 그런 다음 프로젝트를 선택하고 구성원 추가를 클릭합니다. 사용자의 이메일을 입력하고 BigQuery 관리자 역할을 선택한 다음 변경사항을 저장합니다.
데이터 전송을 사용하여 업로드를 구성하는 방법
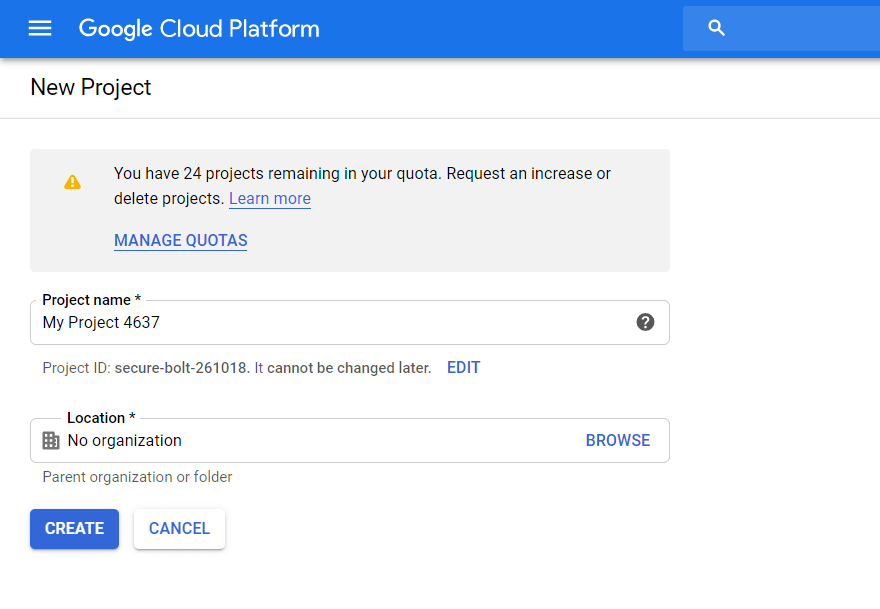
1단계. Google Cloud Platform에서 프로젝트 만들기
GCP에 이미 프로젝트가 있는 경우 이 단계를 건너뜁니다. 그렇지 않은 경우 GCP 콘솔을 열고 사이드 메뉴에서 IAM 및 관리자 — 리소스 관리를 선택합니다. 프로젝트 생성 버튼을 클릭합니다. 그런 다음 프로젝트 이름을 입력하고 조직을 지정한 다음 만들기를 클릭합니다.
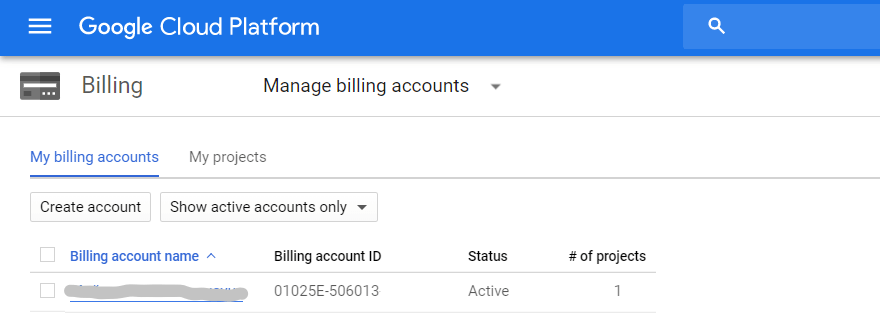
결제를 활성화해야 합니다. 이렇게 하려면 사이드 메뉴에서 결제 — 계정 관리 탭을 열고 프로젝트를 선택한 다음 결제 계정을 연결합니다.
그런 다음 연락처와 지불 카드 세부 정보를 입력하여 모든 필드를 완성합니다. 이것이 GCP의 첫 번째 프로젝트인 경우 12개월 동안 사용할 수 있는 $300를 받게 됩니다. Google Ads 계정이 1-2개이고 매월 최대 100,000명의 고유 사용자가 있는 프로젝트는 1년 동안 충분합니다. 이 한도가 소진되면 돈을 반환할 필요가 없습니다. 추가 사용을 위해 프로젝트에 연결한 카드의 잔액을 다시 채우면 됩니다.
2단계. API BigQuery 사용 설정
프로젝트를 만든 후에는 BigQuery API를 활성화해야 합니다. 이렇게 하려면 GCP 사이드 메뉴에서 API 및 서비스 — 대시보드로 이동하여 프로젝트를 선택하고 API 및 서비스 활성화를 클릭합니다.
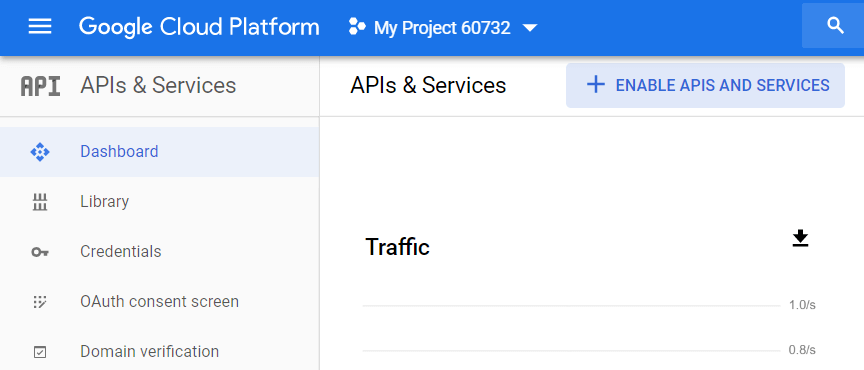
API 라이브러리에서 "BigQuery API"를 검색하고 사용을 클릭합니다.
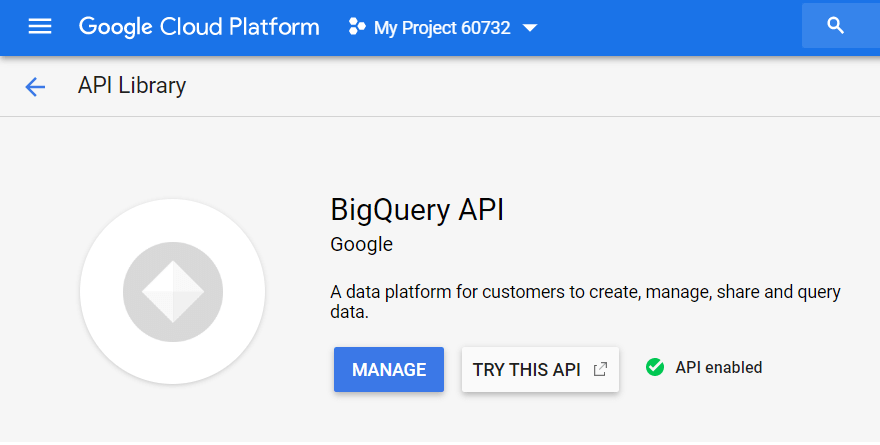
API를 사용하려면 자격 증명 생성을 클릭합니다.
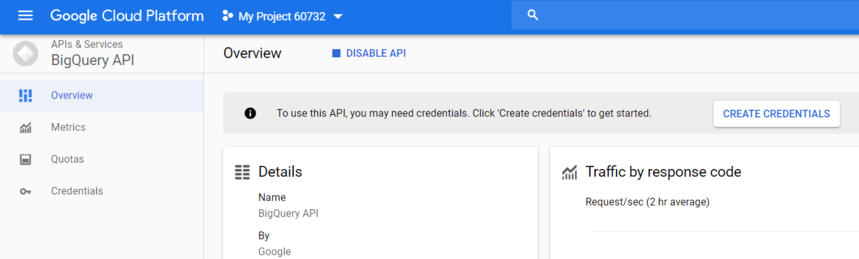
드롭다운 목록에서 BigQuery API를 선택하고 어떤 자격 증명이 필요합니까?를 클릭합니다.
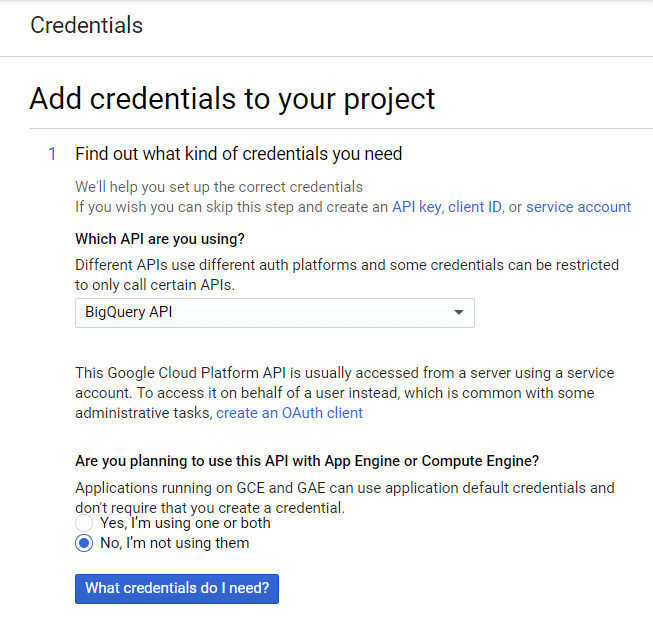
서비스 계정의 이름을 만들고 BigQuery 역할 액세스 수준을 지정합니다. JSON 키 유형을 선택하고 계속을 클릭합니다.
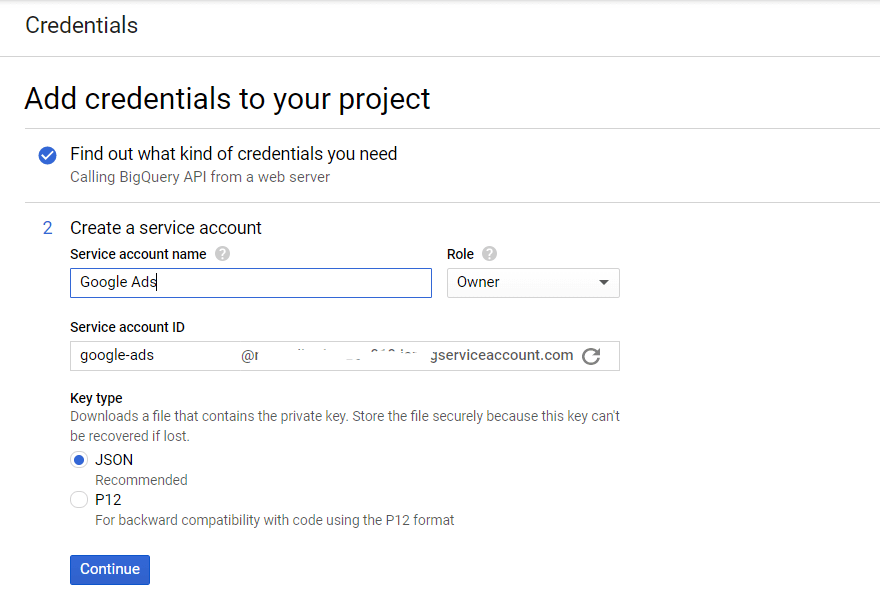
3단계. 데이터 전송 API 활성화
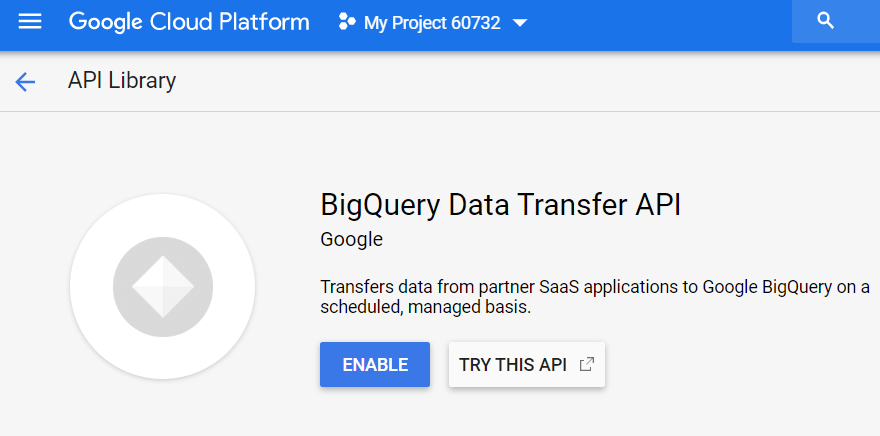
다음으로 BigQuery에서 데이터 서비스를 활성화해야 합니다. 이렇게 하려면 GBQ를 열고 왼쪽 사이드 메뉴에서 전송을 선택합니다. 그런 다음 BigQuery Data Transfer API를 사용 설정합니다.
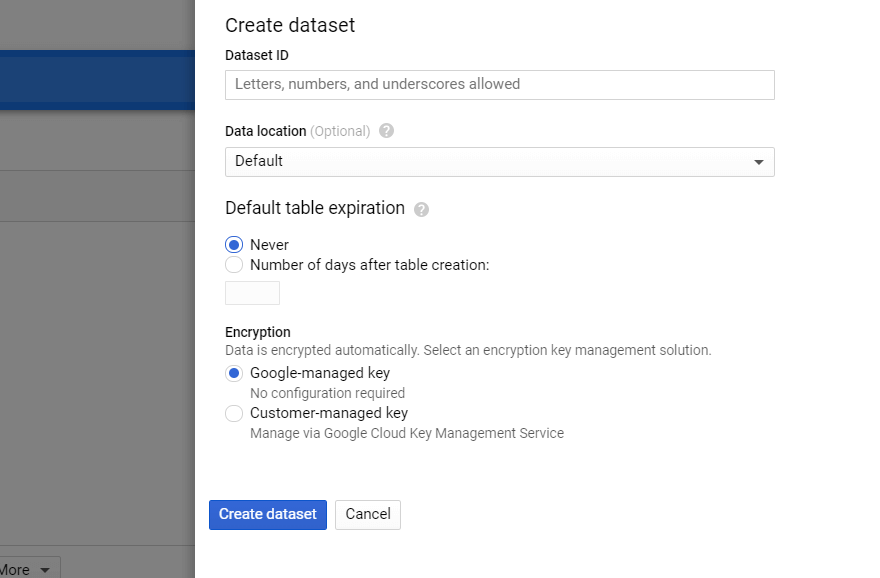
4단계. GBQ에서 데이터 세트 준비
BigQuery에서 프로젝트를 선택하고 오른쪽에 있는 Create Dataset 버튼을 클릭합니다. 새 데이터 세트의 모든 필수 필드(이름, 위치, 보존)를 완료합니다.
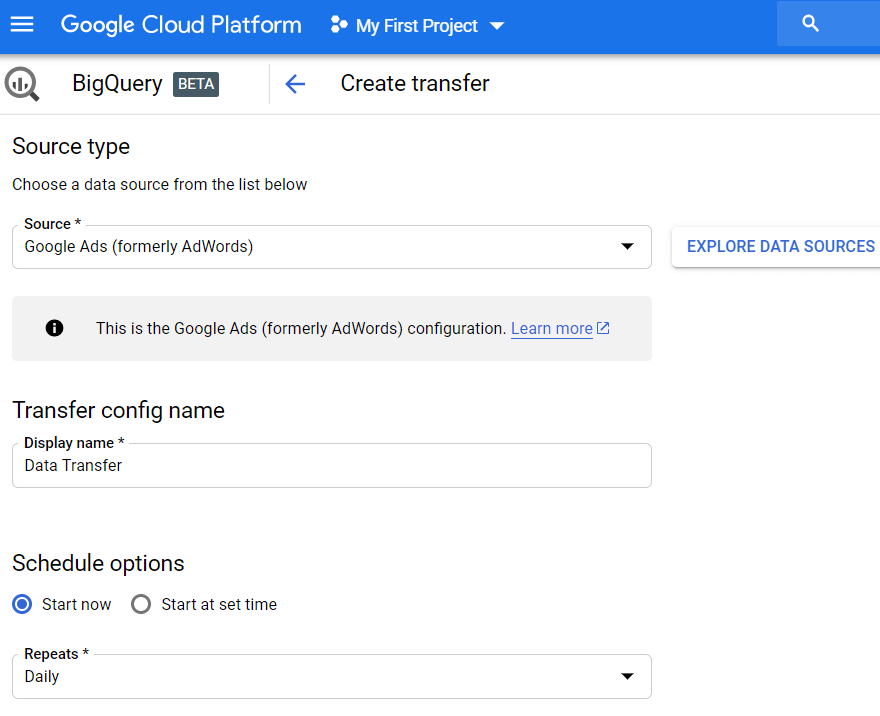
5단계. Google Ads에서 데이터 전송 설정
사이드 메뉴에서 전송 탭을 클릭한 다음 전송 생성을 클릭합니다. 그런 다음 소스로 Google Ads(이전 애드워즈)를 선택하고 업로드 이름(예: 데이터 전송)을 입력합니다.
일정 옵션에서 기본 설정을 지금 시작으로 그대로 두거나 다운로드를 시작할 날짜와 시간을 설정할 수 있습니다. 반복 필드에서 업로드 빈도(매일, 매주, 매월 주문형 등)를 선택합니다.
그런 다음 Google Ads에서 보고서를 로드할 GBQ 데이터세트를 지정해야 합니다. 고객 ID(Google Ads 계정의 ID 또는 MCC ID)를 입력하고 추가를 클릭합니다. 이메일 옆의 오른쪽 상단에 있는 Google Ads 계정에서 고객 ID를 볼 수 있습니다.
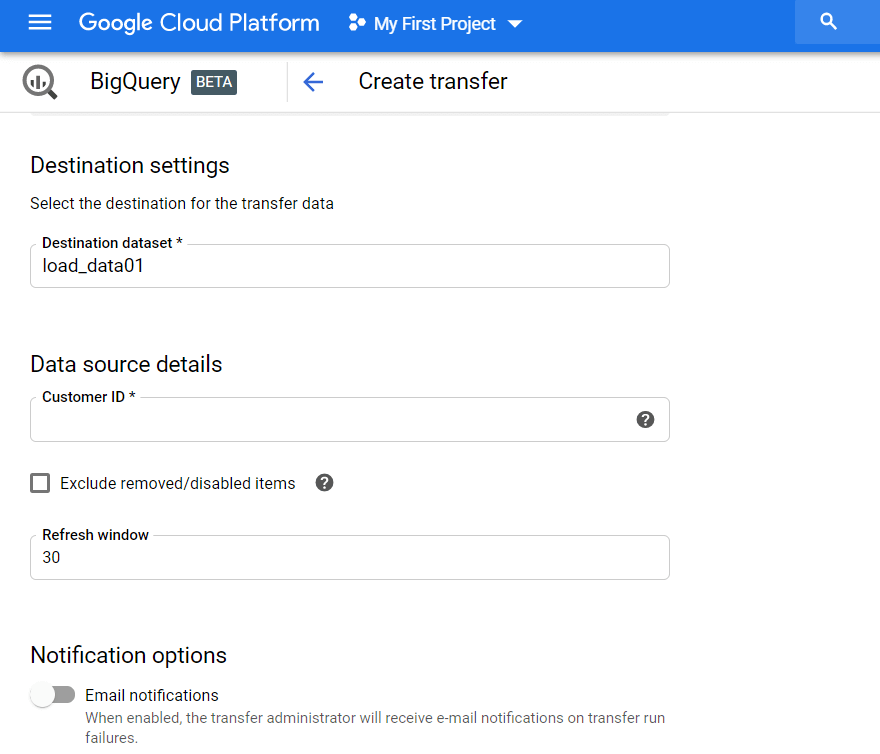
그런 다음 사용 중인 Gmail 계정을 인증해야 합니다. 다음 날 전송을 설정할 때 지정한 데이터세트에 정보가 표시됩니다.
결과적으로 캠페인, 대상, 공통(사용자 정의) 테이블, 키워드 및 전환별 테이블과 같이 작업할 수 있는 많은 양의 원시 데이터를 GBQ로 받게 됩니다. 예를 들어 사용자 지정 대시보드를 구축하려는 경우 이러한 테이블에서 집계되지 않은 데이터를 가져올 수 있습니다.
광고 스크립트를 사용하여 업로드를 설정하는 방법
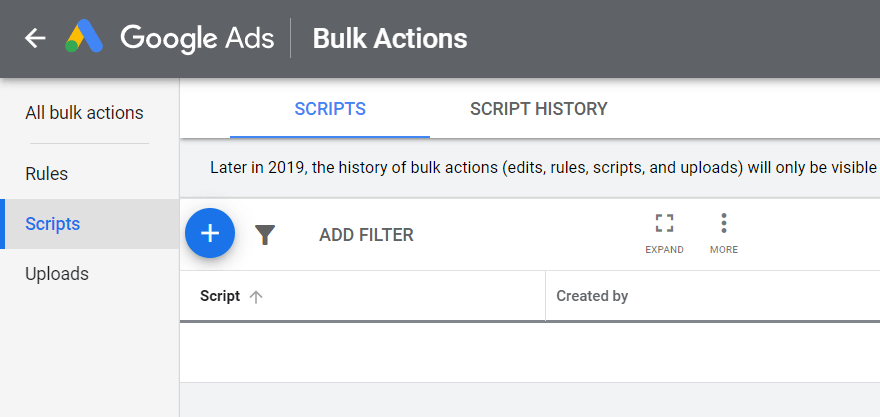
Google Ads 계정을 열고 오른쪽 상단에서 도구 및 설정을 클릭하고 일괄 작업 - 스크립트를 선택하고 더하기 기호를 클릭합니다.
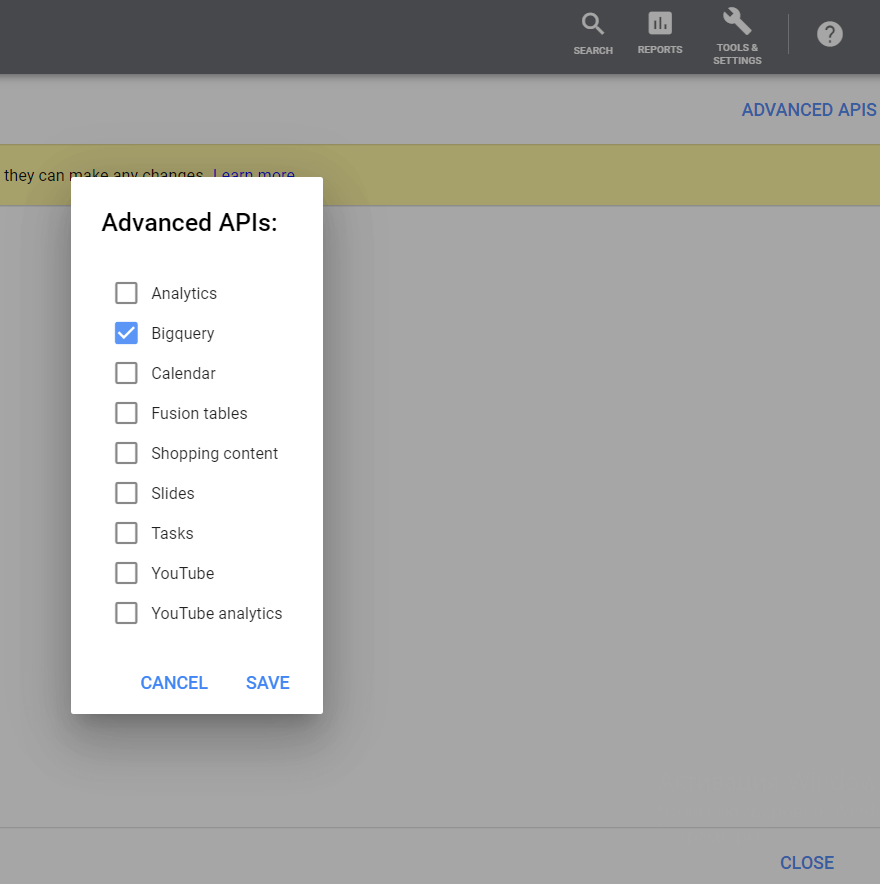
그런 다음 오른쪽 상단에서 고급 API 버튼을 클릭하고 BigQuery를 선택한 다음 변경 사항을 저장합니다.
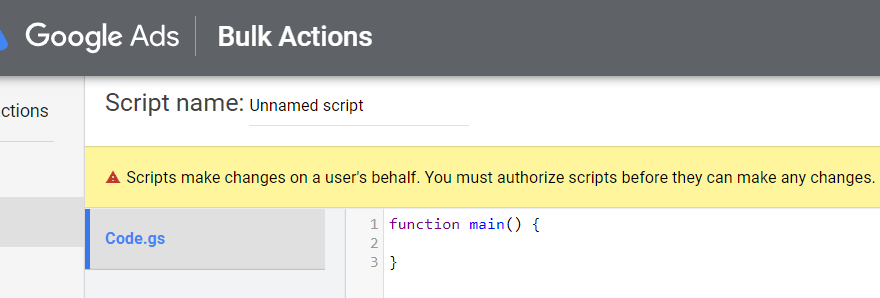
다음을 사용하여 Google Ads에 로그인한 계정으로 가입해야 합니다.
아래 스크립트를 복사합니다. BIGQUERY_PROJECT_ID, BIGQUERY_DATASET_ID 및 사용자 이메일 행에서 값을 프로젝트 이름, GBQ 데이터세트 및 이메일과 같은 고유 정보로 바꿉니다. 스크립트 텍스트를 텍스트 편집기에 붙여넣습니다.
/** * @name Export Data to BigQuery * * @overview The Export Data to BigQuery script sets up a BigQuery * dataset and tables, downloads a report from AdWords and then * loads the report to BigQuery. * * @author AdWords Scripts Team [[email protected]] * * @version 1.3 */ var CONFIG = { BIGQUERY_PROJECT_ID: 'BQ project name', BIGQUERY_DATASET_ID: AdWordsApp.currentAccount().getCustomerId().replace(/-/g, '_'), // Truncate existing data, otherwise will append. TRUNCATE_EXISTING_DATASET: false, TRUNCATE_EXISTING_TABLES: true, // Lists of reports and fields to retrieve from AdWords. REPORTS: [], RECIPIENT_EMAILS: [ 'Your email' ] }; var report = { NAME: 'CLICK_PERFORMANCE_REPORT', //https://developers.google.com/adwords/api/docs/appendix/reports/click-performance-report CONDITIONS: '', FIELDS: {'AccountDescriptiveName': 'STRING', 'AdFormat': 'STRING', 'AdGroupId': 'STRING', 'AdGroupName': 'STRING', 'AoiCountryCriteriaId': 'STRING', 'CampaignId': 'STRING', 'CampaignLocationTargetId': 'STRING', 'CampaignName': 'STRING', 'CampaignStatus': 'STRING', 'Clicks': 'INTEGER', 'ClickType': 'STRING', 'CreativeId': 'STRING', 'CriteriaId': 'STRING', 'CriteriaParameters': 'STRING', 'Date': 'DATE', 'Device': 'STRING', 'ExternalCustomerId': 'STRING', 'GclId': 'STRING', 'KeywordMatchType': 'STRING', 'LopCountryCriteriaId': 'STRING', 'Page': 'INTEGER' }, DATE_RANGE: new Date(new Date().setDate(new Date().getDate()-1)).toISOString().slice(0, 10).replace(/-/g, "")+','+new Date(new Date().setDate(new Date().getDate()-1)).toISOString().slice(0, 10).replace(/-/g, ""), DATE: new Date(new Date().setDate(new Date().getDate()-1)).toISOString().slice(0, 10).replace(/-/g, "") }; //Regular export CONFIG.REPORTS.push(JSON.parse(JSON.stringify(report))); //One-time historical export //for(var i=2;i<91;i++){ // report.DATE_RANGE = new Date(new Date().setDate(new Date().getDate()-i)).toISOString().slice(0, 10).replace(/-/g, "")+','+new Date(new Date().setDate(new Date().getDate()-i)).toISOString().slice(0, 10).replace(/-/g, ""); // report.DATE = new Date(new Date().setDate(new Date().getDate()-i)).toISOString().slice(0, 10).replace(/-/g, ""); // CONFIG.REPORTS.push(JSON.parse(JSON.stringify(report))); //} /** * Main method */ function main() { createDataset(); for (var i = 0; i < CONFIG.REPORTS.length; i++) { var reportConfig = CONFIG.REPORTS[i]; createTable(reportConfig); } var jobIds = processReports(); waitTillJobsComplete(jobIds); sendEmail(jobIds); } /** * Creates a new dataset. * * If a dataset with the same id already exists and the truncate flag * is set, will truncate the old dataset. If the truncate flag is not * set, then will not create a new dataset. */ function createDataset() { if (datasetExists()) { if (CONFIG.TRUNCATE_EXISTING_DATASET) { BigQuery.Datasets.remove(CONFIG.BIGQUERY_PROJECT_ID, CONFIG.BIGQUERY_DATASET_ID, {'deleteContents' : true}); Logger.log('Truncated dataset.'); } else { Logger.log('Dataset %s already exists. Will not recreate.', CONFIG.BIGQUERY_DATASET_ID); return; } } // Create new dataset. var dataSet = BigQuery.newDataset(); dataSet.friendlyName = CONFIG.BIGQUERY_DATASET_ID; dataSet.datasetReference = BigQuery.newDatasetReference(); dataSet.datasetReference.projectId = CONFIG.BIGQUERY_PROJECT_ID; dataSet.datasetReference.datasetId = CONFIG.BIGQUERY_DATASET_ID; dataSet = BigQuery.Datasets.insert(dataSet, CONFIG.BIGQUERY_PROJECT_ID); Logger.log('Created dataset with id %s.', dataSet.id); } /** * Checks if dataset already exists in project. * * @return {boolean} Returns true if dataset already exists. */ function datasetExists() { // Get a list of all datasets in project. var datasets = BigQuery.Datasets.list(CONFIG.BIGQUERY_PROJECT_ID); var datasetExists = false; // Iterate through each dataset and check for an id match. if (datasets.datasets != null) { for (var i = 0; i < datasets.datasets.length; i++) { var dataset = datasets.datasets[i]; if (dataset.datasetReference.datasetId == CONFIG.BIGQUERY_DATASET_ID) { datasetExists = true; break; } } } return datasetExists; } /** * Creates a new table. * * If a table with the same id already exists and the truncate flag * is set, will truncate the old table. If the truncate flag is not * set, then will not create a new table. * * @param {Object} reportConfig Report configuration including report name, * conditions, and fields. */ function createTable(reportConfig) { var tableName = reportConfig.NAME+reportConfig.DATE; if (tableExists(tableName)) { if (CONFIG.TRUNCATE_EXISTING_TABLES) { BigQuery.Tables.remove(CONFIG.BIGQUERY_PROJECT_ID, CONFIG.BIGQUERY_DATASET_ID, tableName); Logger.log('Truncated table %s.', tableName); } else { Logger.log('Table %s already exists. Will not recreate.', tableName); return; } } // Create new table. var table = BigQuery.newTable(); var schema = BigQuery.newTableSchema(); var bigQueryFields = []; // Add each field to table schema. var fieldNames = Object.keys(reportConfig.FIELDS); for (var i = 0; i < fieldNames.length; i++) { var fieldName = fieldNames[i]; var bigQueryFieldSchema = BigQuery.newTableFieldSchema(); bigQueryFieldSchema.description = fieldName; bigQueryFieldSchema.name = fieldName; bigQueryFieldSchema.type = reportConfig.FIELDS[fieldName]; bigQueryFields.push(bigQueryFieldSchema); } schema.fields = bigQueryFields; table.schema = schema; table.friendlyName = tableName; table.tableReference = BigQuery.newTableReference(); table.tableReference.datasetId = CONFIG.BIGQUERY_DATASET_ID; table.tableReference.projectId = CONFIG.BIGQUERY_PROJECT_ID; table.tableReference.tableId = tableName; table = BigQuery.Tables.insert(table, CONFIG.BIGQUERY_PROJECT_ID, CONFIG.BIGQUERY_DATASET_ID); Logger.log('Created table with id %s.', table.id); } /** * Checks if table already exists in dataset. * * @param {string} tableId The table id to check existence. * * @return {boolean} Returns true if table already exists. */ function tableExists(tableId) { // Get a list of all tables in the dataset. var tables = BigQuery.Tables.list(CONFIG.BIGQUERY_PROJECT_ID, CONFIG.BIGQUERY_DATASET_ID); var tableExists = false; // Iterate through each table and check for an id match. if (tables.tables != null) { for (var i = 0; i < tables.tables.length; i++) { var table = tables.tables[i]; if (table.tableReference.tableId == tableId) { tableExists = true; break; } } } return tableExists; } /** * Process all configured reports * * Iterates through each report to: retrieve AdWords data, * backup data to Drive (if configured), load data to BigQuery. * * @return {Array.<string>} jobIds The list of all job ids. */ function processReports() { var jobIds = []; // Iterate over each report type. for (var i = 0; i < CONFIG.REPORTS.length; i++) { var reportConfig = CONFIG.REPORTS[i]; Logger.log('Running report %s', reportConfig.NAME); // Get data as csv var csvData = retrieveAdwordsReport(reportConfig); //Logger.log(csvData); // Convert to Blob format. var blobData = Utilities.newBlob(csvData, 'application/octet-stream'); // Load data var jobId = loadDataToBigquery(reportConfig, blobData); jobIds.push(jobId); } return jobIds; } /** * Retrieves AdWords data as csv and formats any fields * to BigQuery expected format. * * @param {Object} reportConfig Report configuration including report name, * conditions, and fields. * * @return {string} csvData Report in csv format. */ function retrieveAdwordsReport(reportConfig) { var fieldNames = Object.keys(reportConfig.FIELDS); var query = 'SELECT ' + fieldNames.join(', ') + ' FROM ' + reportConfig.NAME + '' + reportConfig.CONDITIONS + ' DURING ' + reportConfig.DATE_RANGE; Logger.log(query); var report = AdWordsApp.report(query); var rows = report.rows(); var csvRows = []; // Header row csvRows.push(fieldNames.join(',')); // Iterate over each row. while (rows.hasNext()) { var row = rows.next(); var csvRow = []; for (var i = 0; i < fieldNames.length; i++) { var fieldName = fieldNames[i]; var fieldValue = row[fieldName].toString(); var fieldType = reportConfig.FIELDS[fieldName]; // Strip off % and perform any other formatting here. if (fieldType == 'FLOAT' || fieldType == 'INTEGER') { if (fieldValue.charAt(fieldValue.length - 1) == '%') { fieldValue = fieldValue.substring(0, fieldValue.length - 1); } fieldValue = fieldValue.replace(/,/g,''); if (fieldValue == '--' || fieldValue == 'Unspecified') { fieldValue = '' } } // Add double quotes to any string values. if (fieldType == 'STRING') { if (fieldValue == '--') { fieldValue = '' } fieldValue = fieldValue.replace(/"/g, '""'); fieldValue = '"' + fieldValue + '"' } csvRow.push(fieldValue); } csvRows.push(csvRow.join(',')); } Logger.log('Downloaded ' + reportConfig.NAME + ' with ' + csvRows.length + ' rows.'); return csvRows.join('\n'); } /** * Creates a BigQuery insertJob to load csv data. * * @param {Object} reportConfig Report configuration including report name, * conditions, and fields. * @param {Blob} data Csv report data as an 'application/octet-stream' blob. * * @return {string} jobId The job id for upload. */ function loadDataToBigquery(reportConfig, data) { // Create the data upload job. var job = { configuration: { load: { destinationTable: { projectId: CONFIG.BIGQUERY_PROJECT_ID, datasetId: CONFIG.BIGQUERY_DATASET_ID, tableId: reportConfig.NAME + reportConfig.DATE }, skipLeadingRows: 1 } } }; var insertJob = BigQuery.Jobs.insert(job, CONFIG.BIGQUERY_PROJECT_ID, data); Logger.log('Load job started for %s. Check on the status of it here: ' + 'https://bigquery.cloud.google.com/jobs/%s', reportConfig.NAME, CONFIG.BIGQUERY_PROJECT_ID); return insertJob.jobReference.jobId; } /** * Polls until all jobs are 'DONE'. * * @param {Array.<string>} jobIds The list of all job ids. */ function waitTillJobsComplete(jobIds) { var complete = false; var remainingJobs = jobIds; while (!complete) { if (AdWordsApp.getExecutionInfo().getRemainingTime() < 5){ Logger.log('Script is about to timeout, jobs ' + remainingJobs.join(',') + ' are still incomplete.'); } remainingJobs = getIncompleteJobs(remainingJobs); if (remainingJobs.length == 0) { complete = true; } if (!complete) { Logger.log(remainingJobs.length + ' jobs still being processed.'); // Wait 5 seconds before checking status again. Utilities.sleep(5000); } } Logger.log('All jobs processed.'); } /** * Iterates through jobs and returns the ids for those jobs * that are not 'DONE'. * * @param {Array.<string>} jobIds The list of job ids. * * @return {Array.<string>} remainingJobIds The list of remaining job ids. */ function getIncompleteJobs(jobIds) { var remainingJobIds = []; for (var i = 0; i < jobIds.length; i++) { var jobId = jobIds[i]; var getJob = BigQuery.Jobs.get(CONFIG.BIGQUERY_PROJECT_ID, jobId); if (getJob.status.state != 'DONE') { remainingJobIds.push(jobId); } } return remainingJobIds; } /** * Sends a notification email that jobs have completed loading. * * @param {Array.<string>} jobIds The list of all job ids. */ function sendEmail(jobIds) { var html = []; html.push( '<html>', '<body>', '<table width=800 cellpadding=0 border=0 cellspacing=0>', '<tr>', '<td colspan=2 align=right>', "<div style='font: italic normal 10pt Times New Roman, serif; " + "margin: 0; color: #666; padding-right: 5px;'>" + 'Powered by AdWords Scripts</div>', '</td>', '</tr>', "<tr bgcolor='#3c78d8'>", '<td width=500>', "<div style='font: normal 18pt verdana, sans-serif; " + "padding: 3px 10px; color: white'>Adwords data load to " + "Bigquery report</div>", '</td>', '<td align=right>', "<div style='font: normal 18pt verdana, sans-serif; " + "padding: 3px 10px; color: white'>", AdWordsApp.currentAccount().getCustomerId(), '</tr>', '</table>', '<table width=800 cellpadding=0 border=1 cellspacing=0>', "<tr bgcolor='#ddd'>", "<td style='font: 12pt verdana, sans-serif; " + 'padding: 5px 0px 5px 5px; background-color: #ddd; ' + "text-align: left'>Report</td>", "<td style='font: 12pt verdana, sans-serif; " + 'padding: 5px 0px 5px 5px; background-color: #ddd; ' + "text-align: left'>JobId</td>", "<td style='font: 12pt verdana, sans-serif; " + 'padding: 5px 0px 5x 5px; background-color: #ddd; ' + "text-align: left'>Rows</td>", "<td style='font: 12pt verdana, sans-serif; " + 'padding: 5px 0px 5x 5px; background-color: #ddd; ' + "text-align: left'>State</td>", "<td style='font: 12pt verdana, sans-serif; " + 'padding: 5px 0px 5x 5px; background-color: #ddd; ' + "text-align: left'>ErrorResult</td>", '</tr>', createTableRows(jobIds), '</table>', '</body>', '</html>'); MailApp.sendEmail(CONFIG.RECIPIENT_EMAILS.join(','), 'Adwords data load to Bigquery Complete', '', {htmlBody: html.join('\n')}); } /** * Creates table rows for email report. * * @param {Array.<string>} jobIds The list of all job ids. */ function createTableRows(jobIds) { var html = []; for (var i = 0; i < jobIds.length; i++) { var jobId = jobIds[i]; var job = BigQuery.Jobs.get(CONFIG.BIGQUERY_PROJECT_ID, jobId); var errorResult = '' if (job.status.errorResult) { errorResult = job.status.errorResult; } html.push('<tr>', "<td style='padding: 0px 10px'>" + job.configuration.load.destinationTable.tableId + '</td>', "<td style='padding: 0px 10px'>" + jobId + '</td>', "<td style='padding: 0px 10px'>" + job.statistics.load?job.statistics.load.outputRows:0 + '</td>', "<td style='padding: 0px 10px'>" + job.status.state + '</td>', "<td style='padding: 0px 10px'>" + errorResult + '</td>', '</tr>'); } return html.join('\n'); }
/** * @name Export Data to BigQuery * * @overview The Export Data to BigQuery script sets up a BigQuery * dataset and tables, downloads a report from AdWords and then * loads the report to BigQuery. * * @author AdWords Scripts Team [[email protected]] * * @version 1.3 */ var CONFIG = { BIGQUERY_PROJECT_ID: 'BQ project name', BIGQUERY_DATASET_ID: AdWordsApp.currentAccount().getCustomerId().replace(/-/g, '_'), // Truncate existing data, otherwise will append. TRUNCATE_EXISTING_DATASET: false, TRUNCATE_EXISTING_TABLES: true, // Lists of reports and fields to retrieve from AdWords. REPORTS: [], RECIPIENT_EMAILS: [ 'Your email' ] }; var report = { NAME: 'CLICK_PERFORMANCE_REPORT', //https://developers.google.com/adwords/api/docs/appendix/reports/click-performance-report CONDITIONS: '', FIELDS: {'AccountDescriptiveName': 'STRING', 'AdFormat': 'STRING', 'AdGroupId': 'STRING', 'AdGroupName': 'STRING', 'AoiCountryCriteriaId': 'STRING', 'CampaignId': 'STRING', 'CampaignLocationTargetId': 'STRING', 'CampaignName': 'STRING', 'CampaignStatus': 'STRING', 'Clicks': 'INTEGER', 'ClickType': 'STRING', 'CreativeId': 'STRING', 'CriteriaId': 'STRING', 'CriteriaParameters': 'STRING', 'Date': 'DATE', 'Device': 'STRING', 'ExternalCustomerId': 'STRING', 'GclId': 'STRING', 'KeywordMatchType': 'STRING', 'LopCountryCriteriaId': 'STRING', 'Page': 'INTEGER' }, DATE_RANGE: new Date(new Date().setDate(new Date().getDate()-1)).toISOString().slice(0, 10).replace(/-/g, "")+','+new Date(new Date().setDate(new Date().getDate()-1)).toISOString().slice(0, 10).replace(/-/g, ""), DATE: new Date(new Date().setDate(new Date().getDate()-1)).toISOString().slice(0, 10).replace(/-/g, "") }; //Regular export CONFIG.REPORTS.push(JSON.parse(JSON.stringify(report))); //One-time historical export //for(var i=2;i<91;i++){ // report.DATE_RANGE = new Date(new Date().setDate(new Date().getDate()-i)).toISOString().slice(0, 10).replace(/-/g, "")+','+new Date(new Date().setDate(new Date().getDate()-i)).toISOString().slice(0, 10).replace(/-/g, ""); // report.DATE = new Date(new Date().setDate(new Date().getDate()-i)).toISOString().slice(0, 10).replace(/-/g, ""); // CONFIG.REPORTS.push(JSON.parse(JSON.stringify(report))); //} /** * Main method */ function main() { createDataset(); for (var i = 0; i < CONFIG.REPORTS.length; i++) { var reportConfig = CONFIG.REPORTS[i]; createTable(reportConfig); } var jobIds = processReports(); waitTillJobsComplete(jobIds); sendEmail(jobIds); } /** * Creates a new dataset. * * If a dataset with the same id already exists and the truncate flag * is set, will truncate the old dataset. If the truncate flag is not * set, then will not create a new dataset. */ function createDataset() { if (datasetExists()) { if (CONFIG.TRUNCATE_EXISTING_DATASET) { BigQuery.Datasets.remove(CONFIG.BIGQUERY_PROJECT_ID, CONFIG.BIGQUERY_DATASET_ID, {'deleteContents' : true}); Logger.log('Truncated dataset.'); } else { Logger.log('Dataset %s already exists. Will not recreate.', CONFIG.BIGQUERY_DATASET_ID); return; } } // Create new dataset. var dataSet = BigQuery.newDataset(); dataSet.friendlyName = CONFIG.BIGQUERY_DATASET_ID; dataSet.datasetReference = BigQuery.newDatasetReference(); dataSet.datasetReference.projectId = CONFIG.BIGQUERY_PROJECT_ID; dataSet.datasetReference.datasetId = CONFIG.BIGQUERY_DATASET_ID; dataSet = BigQuery.Datasets.insert(dataSet, CONFIG.BIGQUERY_PROJECT_ID); Logger.log('Created dataset with id %s.', dataSet.id); } /** * Checks if dataset already exists in project. * * @return {boolean} Returns true if dataset already exists. */ function datasetExists() { // Get a list of all datasets in project. var datasets = BigQuery.Datasets.list(CONFIG.BIGQUERY_PROJECT_ID); var datasetExists = false; // Iterate through each dataset and check for an id match. if (datasets.datasets != null) { for (var i = 0; i < datasets.datasets.length; i++) { var dataset = datasets.datasets[i]; if (dataset.datasetReference.datasetId == CONFIG.BIGQUERY_DATASET_ID) { datasetExists = true; break; } } } return datasetExists; } /** * Creates a new table. * * If a table with the same id already exists and the truncate flag * is set, will truncate the old table. If the truncate flag is not * set, then will not create a new table. * * @param {Object} reportConfig Report configuration including report name, * conditions, and fields. */ function createTable(reportConfig) { var tableName = reportConfig.NAME+reportConfig.DATE; if (tableExists(tableName)) { if (CONFIG.TRUNCATE_EXISTING_TABLES) { BigQuery.Tables.remove(CONFIG.BIGQUERY_PROJECT_ID, CONFIG.BIGQUERY_DATASET_ID, tableName); Logger.log('Truncated table %s.', tableName); } else { Logger.log('Table %s already exists. Will not recreate.', tableName); return; } } // Create new table. var table = BigQuery.newTable(); var schema = BigQuery.newTableSchema(); var bigQueryFields = []; // Add each field to table schema. var fieldNames = Object.keys(reportConfig.FIELDS); for (var i = 0; i < fieldNames.length; i++) { var fieldName = fieldNames[i]; var bigQueryFieldSchema = BigQuery.newTableFieldSchema(); bigQueryFieldSchema.description = fieldName; bigQueryFieldSchema.name = fieldName; bigQueryFieldSchema.type = reportConfig.FIELDS[fieldName]; bigQueryFields.push(bigQueryFieldSchema); } schema.fields = bigQueryFields; table.schema = schema; table.friendlyName = tableName; table.tableReference = BigQuery.newTableReference(); table.tableReference.datasetId = CONFIG.BIGQUERY_DATASET_ID; table.tableReference.projectId = CONFIG.BIGQUERY_PROJECT_ID; table.tableReference.tableId = tableName; table = BigQuery.Tables.insert(table, CONFIG.BIGQUERY_PROJECT_ID, CONFIG.BIGQUERY_DATASET_ID); Logger.log('Created table with id %s.', table.id); } /** * Checks if table already exists in dataset. * * @param {string} tableId The table id to check existence. * * @return {boolean} Returns true if table already exists. */ function tableExists(tableId) { // Get a list of all tables in the dataset. var tables = BigQuery.Tables.list(CONFIG.BIGQUERY_PROJECT_ID, CONFIG.BIGQUERY_DATASET_ID); var tableExists = false; // Iterate through each table and check for an id match. if (tables.tables != null) { for (var i = 0; i < tables.tables.length; i++) { var table = tables.tables[i]; if (table.tableReference.tableId == tableId) { tableExists = true; break; } } } return tableExists; } /** * Process all configured reports * * Iterates through each report to: retrieve AdWords data, * backup data to Drive (if configured), load data to BigQuery. * * @return {Array.<string>} jobIds The list of all job ids. */ function processReports() { var jobIds = []; // Iterate over each report type. for (var i = 0; i < CONFIG.REPORTS.length; i++) { var reportConfig = CONFIG.REPORTS[i]; Logger.log('Running report %s', reportConfig.NAME); // Get data as csv var csvData = retrieveAdwordsReport(reportConfig); //Logger.log(csvData); // Convert to Blob format. var blobData = Utilities.newBlob(csvData, 'application/octet-stream'); // Load data var jobId = loadDataToBigquery(reportConfig, blobData); jobIds.push(jobId); } return jobIds; } /** * Retrieves AdWords data as csv and formats any fields * to BigQuery expected format. * * @param {Object} reportConfig Report configuration including report name, * conditions, and fields. * * @return {string} csvData Report in csv format. */ function retrieveAdwordsReport(reportConfig) { var fieldNames = Object.keys(reportConfig.FIELDS); var query = 'SELECT ' + fieldNames.join(', ') + ' FROM ' + reportConfig.NAME + '' + reportConfig.CONDITIONS + ' DURING ' + reportConfig.DATE_RANGE; Logger.log(query); var report = AdWordsApp.report(query); var rows = report.rows(); var csvRows = []; // Header row csvRows.push(fieldNames.join(',')); // Iterate over each row. while (rows.hasNext()) { var row = rows.next(); var csvRow = []; for (var i = 0; i < fieldNames.length; i++) { var fieldName = fieldNames[i]; var fieldValue = row[fieldName].toString(); var fieldType = reportConfig.FIELDS[fieldName]; // Strip off % and perform any other formatting here. if (fieldType == 'FLOAT' || fieldType == 'INTEGER') { if (fieldValue.charAt(fieldValue.length - 1) == '%') { fieldValue = fieldValue.substring(0, fieldValue.length - 1); } fieldValue = fieldValue.replace(/,/g,''); if (fieldValue == '--' || fieldValue == 'Unspecified') { fieldValue = '' } } // Add double quotes to any string values. if (fieldType == 'STRING') { if (fieldValue == '--') { fieldValue = '' } fieldValue = fieldValue.replace(/"/g, '""'); fieldValue = '"' + fieldValue + '"' } csvRow.push(fieldValue); } csvRows.push(csvRow.join(',')); } Logger.log('Downloaded ' + reportConfig.NAME + ' with ' + csvRows.length + ' rows.'); return csvRows.join('\n'); } /** * Creates a BigQuery insertJob to load csv data. * * @param {Object} reportConfig Report configuration including report name, * conditions, and fields. * @param {Blob} data Csv report data as an 'application/octet-stream' blob. * * @return {string} jobId The job id for upload. */ function loadDataToBigquery(reportConfig, data) { // Create the data upload job. var job = { configuration: { load: { destinationTable: { projectId: CONFIG.BIGQUERY_PROJECT_ID, datasetId: CONFIG.BIGQUERY_DATASET_ID, tableId: reportConfig.NAME + reportConfig.DATE }, skipLeadingRows: 1 } } }; var insertJob = BigQuery.Jobs.insert(job, CONFIG.BIGQUERY_PROJECT_ID, data); Logger.log('Load job started for %s. Check on the status of it here: ' + 'https://bigquery.cloud.google.com/jobs/%s', reportConfig.NAME, CONFIG.BIGQUERY_PROJECT_ID); return insertJob.jobReference.jobId; } /** * Polls until all jobs are 'DONE'. * * @param {Array.<string>} jobIds The list of all job ids. */ function waitTillJobsComplete(jobIds) { var complete = false; var remainingJobs = jobIds; while (!complete) { if (AdWordsApp.getExecutionInfo().getRemainingTime() < 5){ Logger.log('Script is about to timeout, jobs ' + remainingJobs.join(',') + ' are still incomplete.'); } remainingJobs = getIncompleteJobs(remainingJobs); if (remainingJobs.length == 0) { complete = true; } if (!complete) { Logger.log(remainingJobs.length + ' jobs still being processed.'); // Wait 5 seconds before checking status again. Utilities.sleep(5000); } } Logger.log('All jobs processed.'); } /** * Iterates through jobs and returns the ids for those jobs * that are not 'DONE'. * * @param {Array.<string>} jobIds The list of job ids. * * @return {Array.<string>} remainingJobIds The list of remaining job ids. */ function getIncompleteJobs(jobIds) { var remainingJobIds = []; for (var i = 0; i < jobIds.length; i++) { var jobId = jobIds[i]; var getJob = BigQuery.Jobs.get(CONFIG.BIGQUERY_PROJECT_ID, jobId); if (getJob.status.state != 'DONE') { remainingJobIds.push(jobId); } } return remainingJobIds; } /** * Sends a notification email that jobs have completed loading. * * @param {Array.<string>} jobIds The list of all job ids. */ function sendEmail(jobIds) { var html = []; html.push( '<html>', '<body>', '<table width=800 cellpadding=0 border=0 cellspacing=0>', '<tr>', '<td colspan=2 align=right>', "<div style='font: italic normal 10pt Times New Roman, serif; " + "margin: 0; color: #666; padding-right: 5px;'>" + 'Powered by AdWords Scripts</div>', '</td>', '</tr>', "<tr bgcolor='#3c78d8'>", '<td width=500>', "<div style='font: normal 18pt verdana, sans-serif; " + "padding: 3px 10px; color: white'>Adwords data load to " + "Bigquery report</div>", '</td>', '<td align=right>', "<div style='font: normal 18pt verdana, sans-serif; " + "padding: 3px 10px; color: white'>", AdWordsApp.currentAccount().getCustomerId(), '</tr>', '</table>', '<table width=800 cellpadding=0 border=1 cellspacing=0>', "<tr bgcolor='#ddd'>", "<td style='font: 12pt verdana, sans-serif; " + 'padding: 5px 0px 5px 5px; background-color: #ddd; ' + "text-align: left'>Report</td>", "<td style='font: 12pt verdana, sans-serif; " + 'padding: 5px 0px 5px 5px; background-color: #ddd; ' + "text-align: left'>JobId</td>", "<td style='font: 12pt verdana, sans-serif; " + 'padding: 5px 0px 5x 5px; background-color: #ddd; ' + "text-align: left'>Rows</td>", "<td style='font: 12pt verdana, sans-serif; " + 'padding: 5px 0px 5x 5px; background-color: #ddd; ' + "text-align: left'>State</td>", "<td style='font: 12pt verdana, sans-serif; " + 'padding: 5px 0px 5x 5px; background-color: #ddd; ' + "text-align: left'>ErrorResult</td>", '</tr>', createTableRows(jobIds), '</table>', '</body>', '</html>'); MailApp.sendEmail(CONFIG.RECIPIENT_EMAILS.join(','), 'Adwords data load to Bigquery Complete', '', {htmlBody: html.join('\n')}); } /** * Creates table rows for email report. * * @param {Array.<string>} jobIds The list of all job ids. */ function createTableRows(jobIds) { var html = []; for (var i = 0; i < jobIds.length; i++) { var jobId = jobIds[i]; var job = BigQuery.Jobs.get(CONFIG.BIGQUERY_PROJECT_ID, jobId); var errorResult = '' if (job.status.errorResult) { errorResult = job.status.errorResult; } html.push('<tr>', "<td style='padding: 0px 10px'>" + job.configuration.load.destinationTable.tableId + '</td>', "<td style='padding: 0px 10px'>" + jobId + '</td>', "<td style='padding: 0px 10px'>" + job.statistics.load?job.statistics.load.outputRows:0 + '</td>', "<td style='padding: 0px 10px'>" + job.status.state + '</td>', "<td style='padding: 0px 10px'>" + errorResult + '</td>', '</tr>'); } return html.join('\n'); } 스크립트를 실행하기 전에 반드시 우측 하단의 미리보기 버튼을 클릭하여 결과를 확인하시기 바랍니다. 오류가 있는 경우 다음 스크린샷과 같이 시스템에서 사용자에게 경고하고 오류가 발생한 줄을 표시합니다.

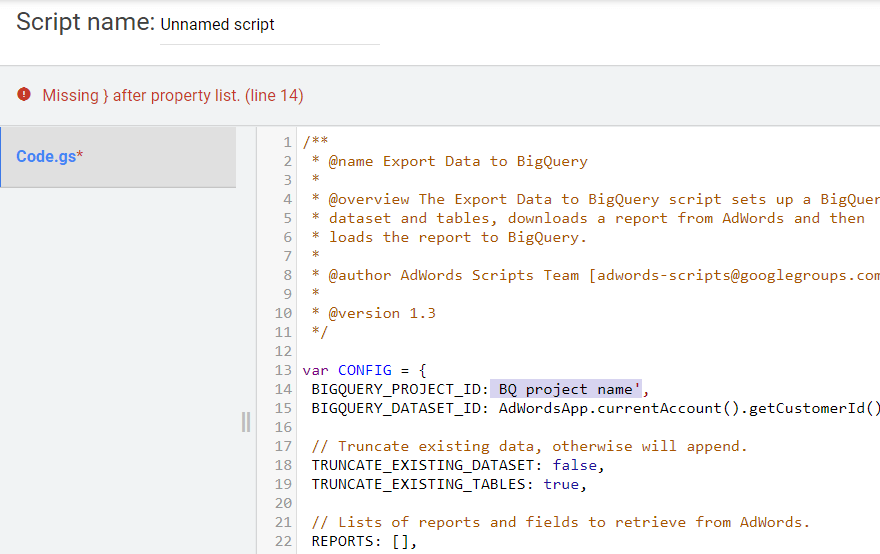
오류가 없으면 실행 버튼을 클릭합니다.
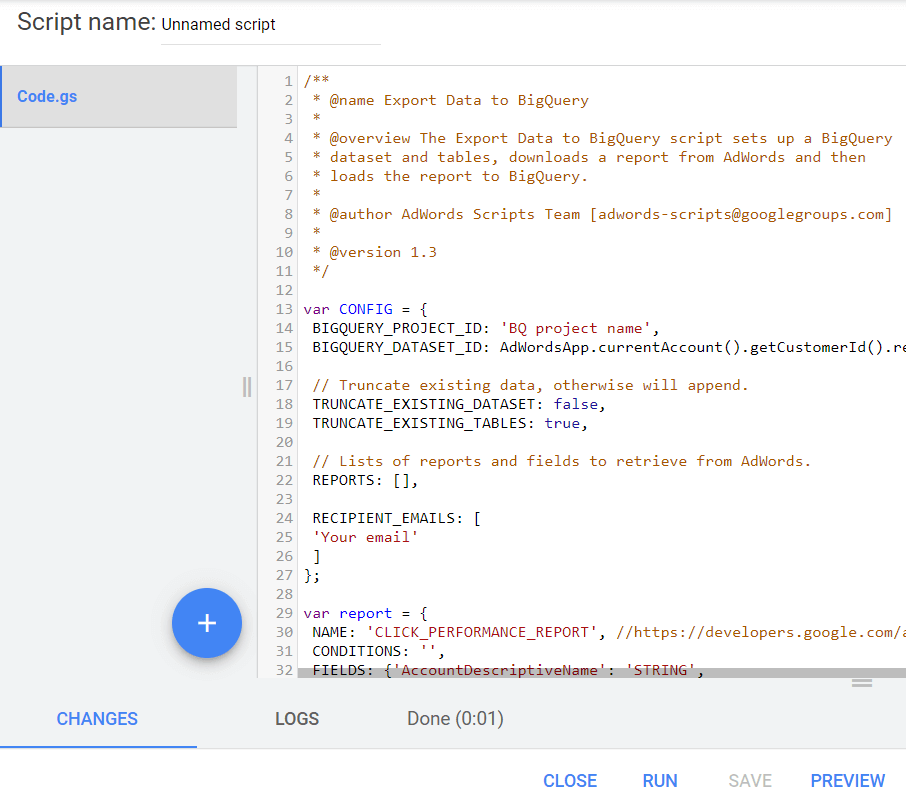
결과적으로 다음 날 사용할 수 있는 새로운 CLICK_PERFORMANCE_REPORT 보고서를 GBQ로 받게 됩니다.
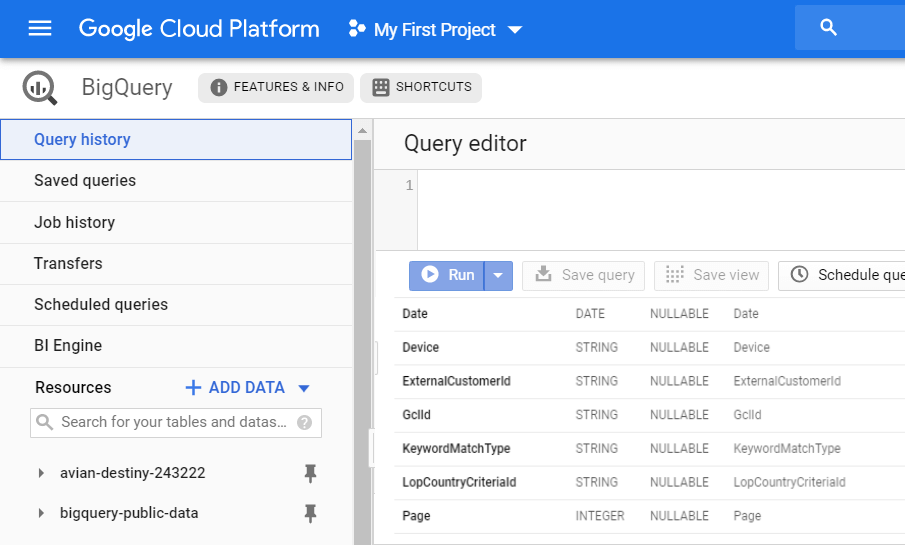
데이터 전송을 사용할 때 집계되지 않은 원시 데이터를 대량으로 얻는다는 점을 기억하십시오. 광고 스크립트를 사용하면 특정 필드에 대한 정보만 갖게 됩니다.
이 업로드의 다음 필드는 세션 관련 OWOX BI 테이블에 포함됩니다.
- GCLID
- 캠페인 ID
- 캠페인 이름
- 광고그룹 ID
- 광고그룹명
- 기준 ID
- 기준 매개변수
- 키워드 일치 유형
Google Ads에서 OWOX BI로 데이터 다운로드를 연결하는 방법
이제 Google Ads의 정보를 사이트 데이터와 결합하여 사용자가 귀하의 사이트에 도달한 캠페인을 이해해야 합니다. 데이터 전송과 같이 BigQuery에서 가져온 테이블에는 클라이언트 ID 매개변수가 없습니다. gclid 데이터를 OWOX BI 흐름 데이터에 연결해야만 어떤 고객이 광고를 클릭했는지 확인할 수 있습니다.
아직 OWOX BI에 Google Analytics → Google BigQuery 스트리밍 파이프라인이 없다면 만드는 방법에 대한 지침을 읽으십시오.
그런 다음 OWOX BI 프로젝트로 이동하여 이 파이프라인을 엽니다. 설정 탭을 클릭하고 세션 데이터 수집에서 설정 편집을 클릭합니다.
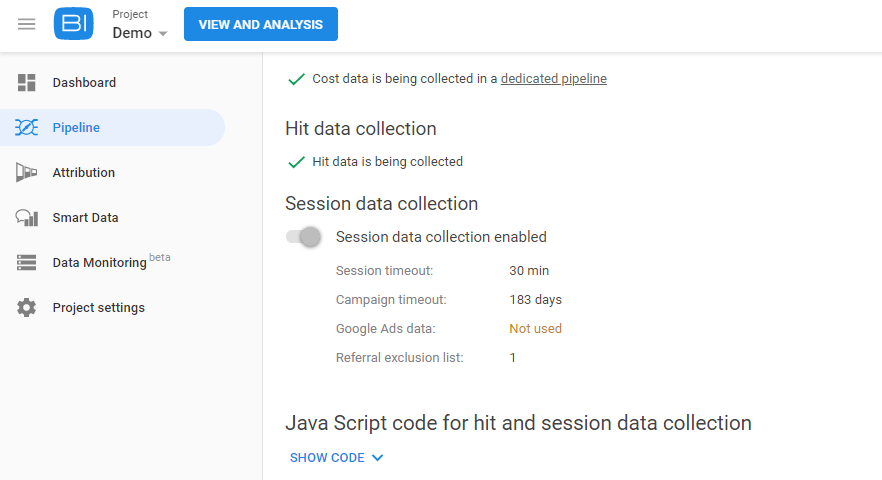
슬라이더를 사용하여 Google Ads 자동 라벨이 지정된 캠페인에 대한 데이터 수집을 활성화하고 설정 변경을 클릭합니다.
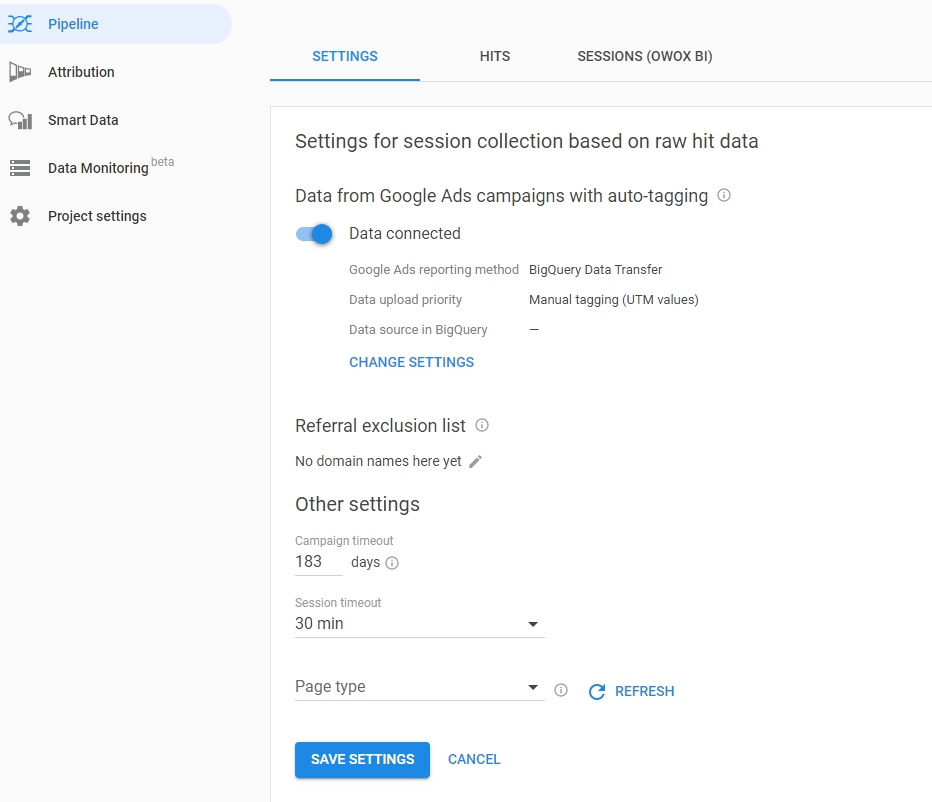
AutoLabel 마크업 유형을 선택하고 BigQuery에 데이터 전송 또는 광고 스크립트를 로드하는 방법을 지정합니다. Google Ads 데이터를 다운로드할 프로젝트 및 데이터세트를 지정하고 설정을 저장합니다.
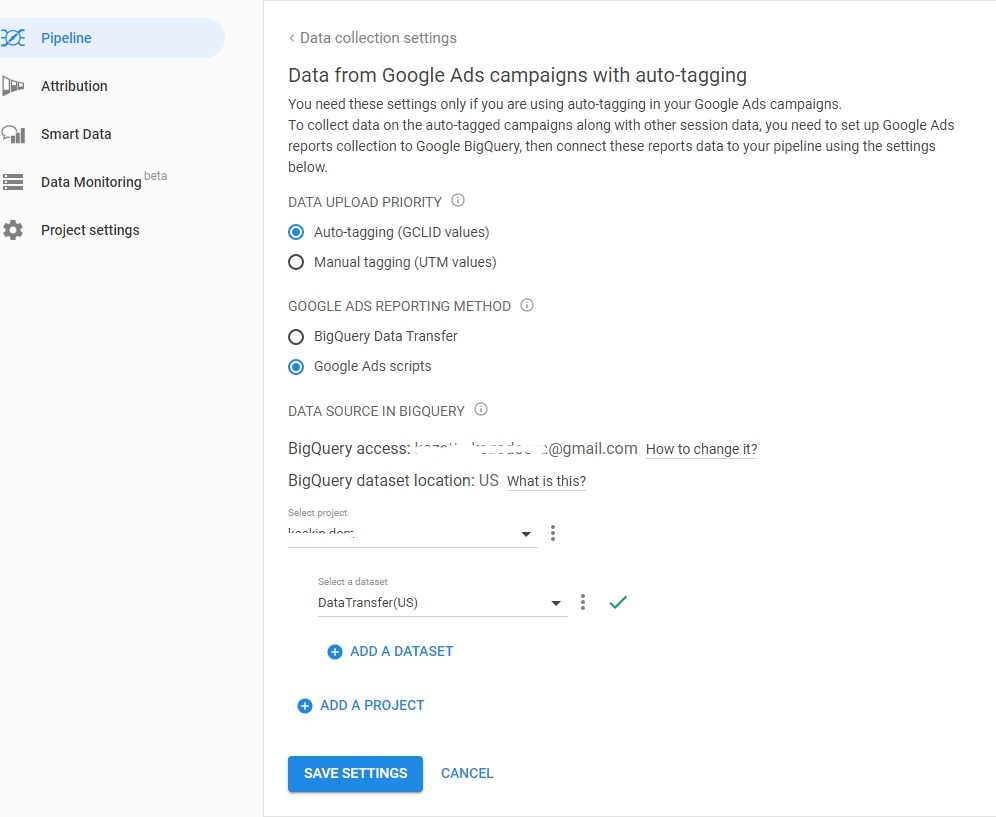
유용한 팁
팁 1. 데이터 전송을 사용하면 Google Ads에서 GBQ로 이전 데이터를 업로드할 수 있습니다. 동시에 총 로딩 기간(1년 또는 3년)에 대한 제한은 없지만 한 번에 180일 동안의 데이터만 있습니다.
업로드를 활성화하고 원하는 전송을 선택하여 전송 탭의 백필 예약 버튼을 사용하여 기간을 지정할 수 있습니다.
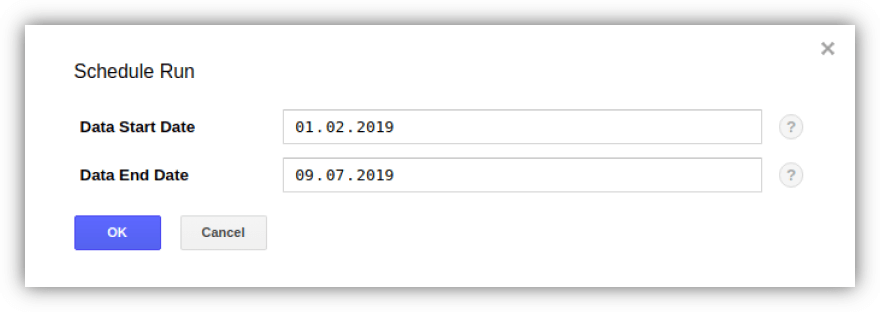
팁 2. GCP에서 청구할 Google Ads 계정의 수를 확인하려면 다음 쿼리를 사용하여 Customer 테이블에서 ExternalCustomerID의 수를 확인해야 합니다.
SELECT ExternalCustomerId FROM `project_name.dataset_name.Customer_*` WHERE _PARTITIONTIME >= "2020-01-01 00:00:00" AND _PARTITIONTIME < "2020-07-10 00:00:00" group by 1
SELECT ExternalCustomerId FROM `project_name.dataset_name.Customer_*` WHERE _PARTITIONTIME >= "2020-01-01 00:00:00" AND _PARTITIONTIME < "2020-07-10 00:00:00" group by 1쿼리에서 날짜를 편집할 수 있습니다.
팁 3. 업로드된 데이터는 SQL 쿼리를 사용하여 직접 액세스할 수 있습니다. 예를 들어 다음은 데이터 전송에서 파생된 "Campaign" 및 "CampaignBasicStats" 테이블에서 캠페인의 효율성을 확인하는 쿼리입니다.
SELECT {source language="sql"} c.ExternalCustomerId, c.CampaignName, c.CampaignStatus, SUM(cs.Impressions) AS Impressions, SUM(cs.Interactions) AS Interactions, {/source} (SUM(cs.Cost) / 1000000) AS Cost FROM `[DATASET].Campaign_[CUSTOMER_ID]` c LEFT JOIN {source language="sql"} {source language="sql"} `[DATASET].CampaignBasicStats_[CUSTOMER_ID]` cs ON (c.CampaignId = cs.CampaignId AND cs._DATA_DATE BETWEEN DATE_ADD(CURRENT_DATE(), INTERVAL -31 DAY) AND DATE_ADD(CURRENT_DATE(), INTERVAL -1 DAY)) WHERE c._DATA_DATE = c._LATEST_DATE GROUP BY 1, 2, 3 ORDER BY Impressions DESC
SELECT {source language="sql"} c.ExternalCustomerId, c.CampaignName, c.CampaignStatus, SUM(cs.Impressions) AS Impressions, SUM(cs.Interactions) AS Interactions, {/source} (SUM(cs.Cost) / 1000000) AS Cost FROM `[DATASET].Campaign_[CUSTOMER_ID]` c LEFT JOIN {source language="sql"} {source language="sql"} `[DATASET].CampaignBasicStats_[CUSTOMER_ID]` cs ON (c.CampaignId = cs.CampaignId AND cs._DATA_DATE BETWEEN DATE_ADD(CURRENT_DATE(), INTERVAL -31 DAY) AND DATE_ADD(CURRENT_DATE(), INTERVAL -1 DAY)) WHERE c._DATA_DATE = c._LATEST_DATE GROUP BY 1, 2, 3 ORDER BY Impressions DESC 추신: Google BigQuery에 데이터를 업로드하고 병합하는 데 도움이 필요하면 언제든지 도와드리겠습니다. 데모에 등록하면 세부 사항에 대해 논의할 것입니다.