
Google広告からGoogleBigQueryに生データをアップロードする方法
公開: 2022-04-12GoogleアナリティクスでGoogle広告キャンペーンの効果を分析することにより、サンプリング、データ集約、またはその他のシステムインターフェースの制限が発生する可能性があります。 幸い、この問題は、広告サービスからGoogleBigQueryに生データをアップロードすることで簡単に解決できます。
この記事では、Google広告アカウントからBigQueryに生データをアップロードし、自動ラベル付けされたキャンペーンのすべてのUTMタグを特定する方法を学習します。
キャンペーン情報をサイトのユーザーアクティビティにリンクするには、OWOXBIが必要です。 デモにサインアップすると、OWOXBIで解決できるすべての課題について詳しく説明します。
目次
- Google広告の生データが必要な理由
- Google広告からBigQueryに生データをアップロードする2つの方法
- データ転送を使用してアップロードを構成する方法
- 広告スクリプトを使用してアップロードを設定する方法
- Google広告からダウンロードしたデータをOWOXBIに接続する方法
- 役立つヒント
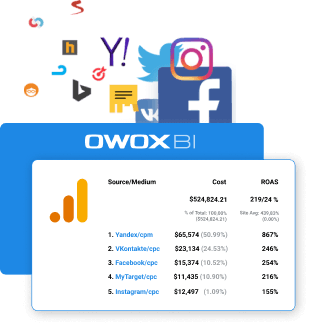
キャンペーンの真の価値を知る
すべての広告サービスからGoogleアナリティクスに費用データを自動的にインポートします。 キャンペーンの費用、CPC、ROASを1つのレポートで比較します。
Google広告の生データが必要な理由
Google広告の生データを使用すると、各キーワードまで正確に広告キャンペーンを分析できます。 BigQueryにデータをアップロードすると、次のことができます。
- GAの制限に制限されることなく、必要に応じて詳細なレポートを作成できます。
- セッションレベルとユーザーレベルで広告キャンペーンの効果を判断します。
- 地域、ユーザータイプ(新規または返品)、デバイス、その他のパラメーターごとにROI、ROAS、CRRを計算します。
- 料金を効果的に管理し、リマーケティングリストを作成します。
- Google広告、Googleアナリティクス、CRMのデータを組み合わせて、アイテムのマージンと償還可能性に基づいてキャンペーンの効果を評価します。
- より正確な計画のためにMLモデルをトレーニングします。
どのキャンペーン、広告、キーワードがユーザーをサイトに呼び込むかを理解するには、Google広告とアナリティクスのデータをBigQueryに組み合わせる必要があります。 これは、OWOXBIストリーミングを使用して行うことができます。
この情報をストリーミングすると、サイトのサンプリングされていないユーザー行動データがGBQに送信されます。 ヒットはリアルタイムで送信され、セッションはこれらのヒットに基づいて形成されます。
OWOX BIトラフィックソース情報は、マークアップをアドバタイズするUTMタグから取得されます。 タグは手動と自動です。
広告を手動でマークし、次のURLを取得したとします。
https://example.com/?utm_source=facebook&utm_medium=cpc&utm_campaign=utm_tags
この場合、OWOX BIに接続すると、ソース、チャネル、およびキャンペーンのデータがGBQテーブルで利用できるようになります。
- TrafficSource.source — google
- TrafficSource.medium — cpc
- TrafficSource.campaign — utm_tags
UTMタグを正しく作成する方法の詳細をご覧ください。
広告サービスで自動マークアップを有効にしている場合は、特別なgclidパラメータが各広告に割り当てられます。 ユーザーがアナウンスをクリックすると、ランディングページのURLに追加されます。
そのようなリンクの例:
http://www.example.com/?gclid=TeSter-123
自動マークアップを使用する場合、生データがないとgclidからソース、メディア、キャンペーンを取得できません。これらのフィールドは、OWOXBIが収集するBigQueryテーブルでは空になります。
そのような場合に何ができるでしょうか。また、gclidだけを使用して、キャンペーンの名前やその他のパラメーターを取得するにはどうすればよいでしょうか。 Google広告からGBQへの自動アップロードを設定します。
注:アナウンスがまったくマークされていない場合、OWOXBIは次のようにリンクを割り当てます。
- 紹介トラフィックとしてのGoogle以外のソースの場合(例:Facebook /紹介)
- 直接トラフィックとしてのGoogleソースの場合(直接/なし)
レポートに直接/なしのトラフィックが多い場合は、ボットフィルタリングが有効になっていないか、タグなしの広告が多数ある可能性があります。
Google広告からBigQueryに生データをアップロードする2つの方法
Google広告から生データをアップロードするには、データ転送コネクタと広告スクリプトの2つの方法を使用することをお勧めします。
どちらを選択するかは、目標と予算によって異なります。
データ転送機能
- GBQとのネイティブ統合。
- 制限なしで任意の期間の履歴データをダウンロードします。
- 無料です。
Google広告スクリプトの機能
- 無料。
- 履歴データはアップロードできません。 前日の情報のみがダウンロードされます。
- 多数のアカウントからのアップロードを設定する場合は、さらに必要です。 アカウントごとに手動でスクリプトを変更する必要があります。 同時に、間違いを犯すリスクが高くなります。
設定に必要なもの
アクティブなプロジェクトとアカウント:
- Google Cloud Platform(GCP)
- Google BigQuery(GBQ)
- OWOX BI
- Google広告
アクセス:
- GCPの所有者
- GBQの管理者
- OWOXBIでの編集。 重要:Googleアナリティクス→GoogleBigQueryストリーミングパイプラインを作成したユーザーのみがGoogle広告からのダウンロードをオンにできます。
- Google広告で読む
GBQでアクセス権を付与する方法
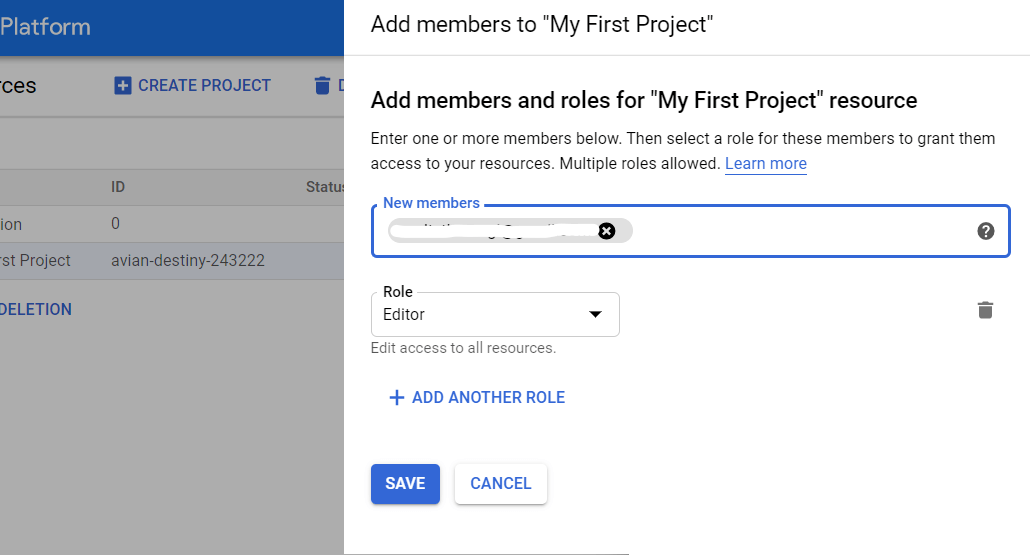
GCPコンソールを開き、サイドメニューから[IAMと管理] —[リソースの管理]を選択します。 次に、プロジェクトを選択し、[メンバーの追加]をクリックします。 ユーザーのメールアドレスを入力し、BigQuery管理者の役割を選択して、変更を保存します。
データ転送を使用してアップロードを構成する方法
手順1.GoogleCloudPlatformでプロジェクトを作成します
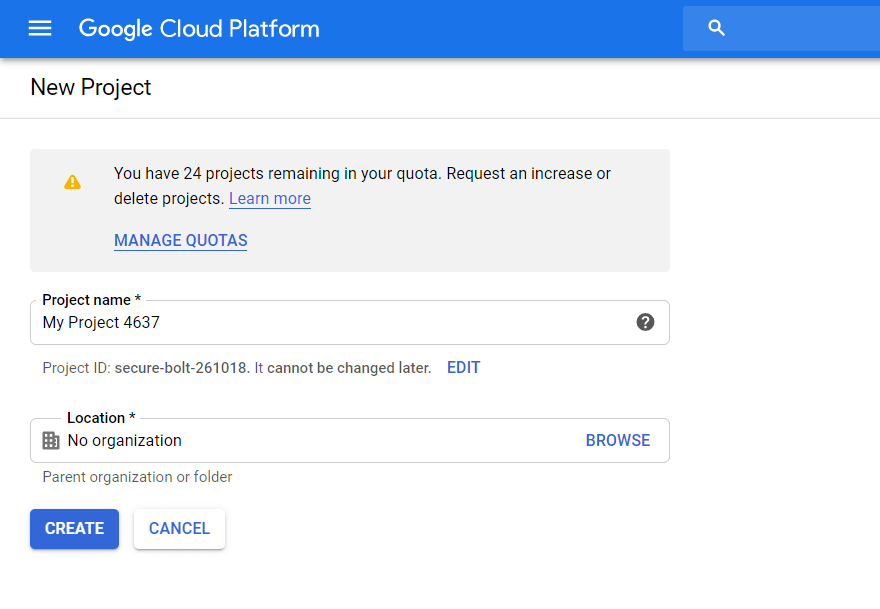
GCPにすでにプロジェクトがある場合は、この手順をスキップしてください。 そうでない場合は、GCPコンソールを開き、サイドメニューから[IAMと管理] —[リソースの管理]を選択します。 [プロジェクトの作成]ボタンをクリックします。 次に、プロジェクト名を入力し、組織を指定して、[作成]をクリックします。
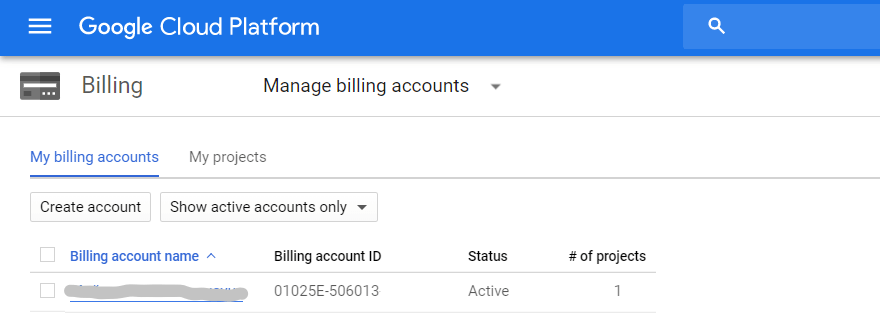
必ず請求を有効にしてください。 これを行うには、サイドメニューの[請求—アカウント管理]タブを開き、プロジェクトを選択して、[請求アカウント]にリンクします。
次に、連絡先と支払いカードの詳細を入力して、すべてのフィールドに入力します。 これがGCPでの最初のプロジェクトである場合、12か月間使用できる300ドルを受け取ります。 1〜2個のGoogle広告アカウントがあり、1か月あたり最大100,000人のユニークユーザーがいるプロジェクトでは、1年間で十分です。 この制限を使い果たした場合、お金を返す必要はありません。 さらに使用するには、プロジェクトにリンクしたカードの残高を補充するだけです。
手順2.APIBigQueryをオンにする
プロジェクトを作成したら、BigQueryAPIをアクティブ化する必要があります。 これを行うには、GCPサイドメニューから[APIとサービス—ダッシュボード]に移動し、プロジェクトを選択して、[APIとサービスを有効にする]をクリックします。
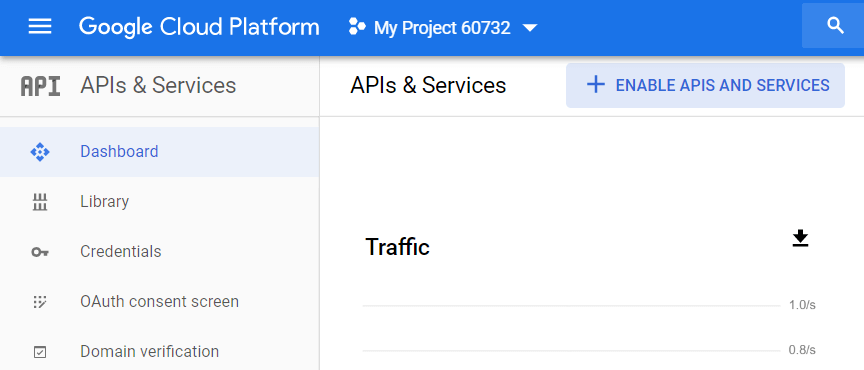
APIライブラリで、「BigQuery API」を検索し、[有効にする]をクリックします。
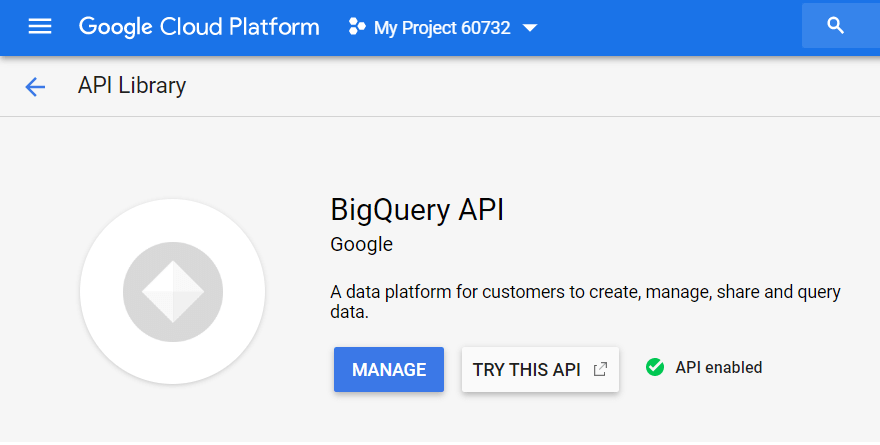
APIを使用するには、[資格情報の作成]をクリックします。
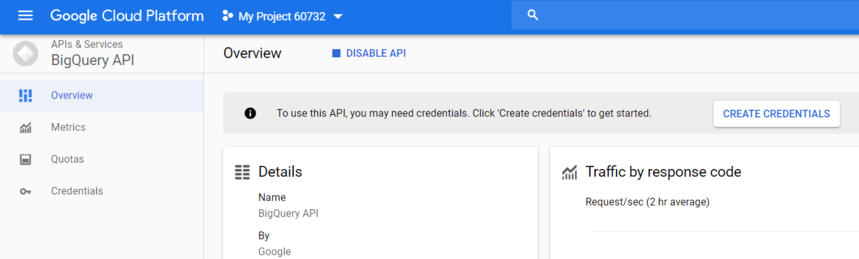
ドロップダウンリストからBigQueryAPIを選択し、[どのクレデンシャルが必要ですか?]をクリックします。
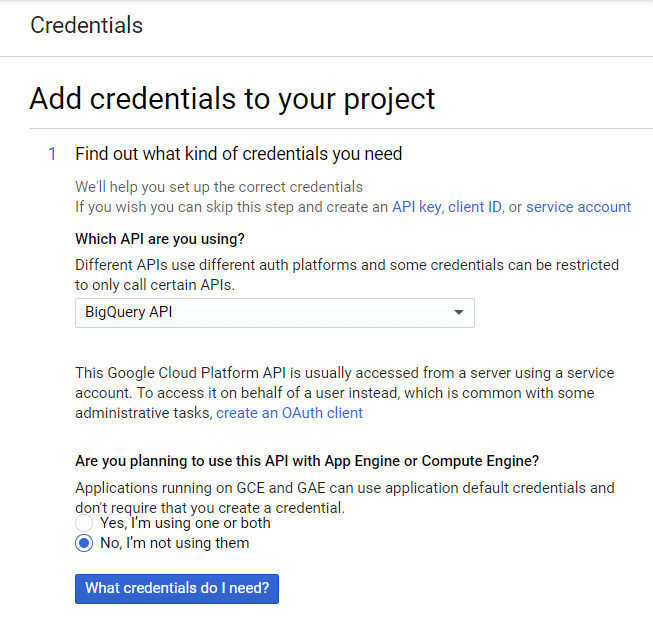
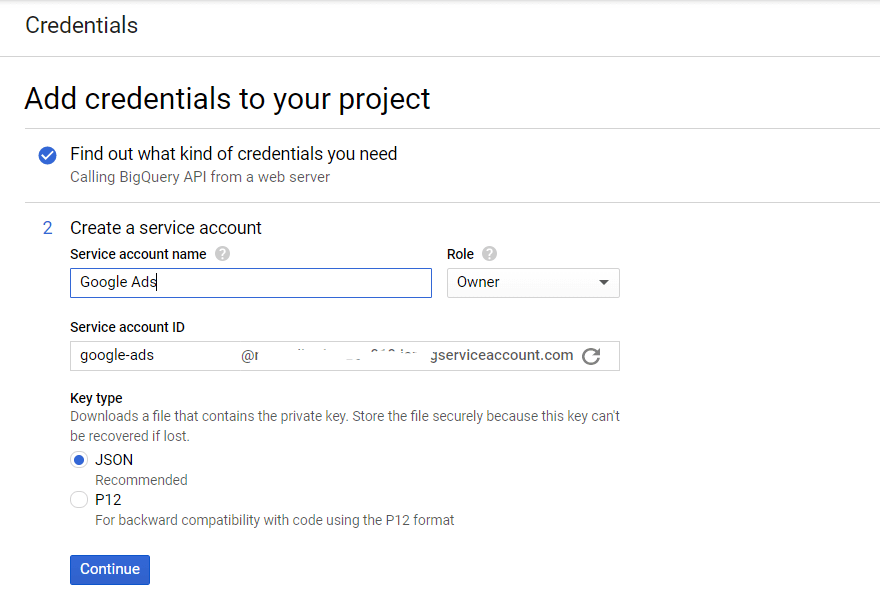
サービスアカウントの名前を作成し、BigQueryロールのアクセスレベルを指定します。 JSONキーのタイプを選択し、[続行]をクリックします。
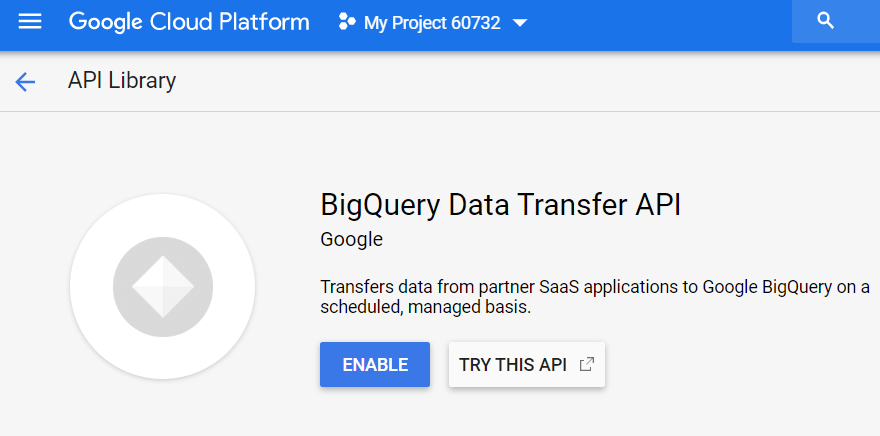
ステップ3.データ転送APIをアクティブ化する
次に、BigQueryでデータサービスを有効にする必要があります。 これを行うには、GBQを開き、左側のサイドメニューから[転送]を選択します。 次に、BigQuery DataTransferAPIを有効にします。
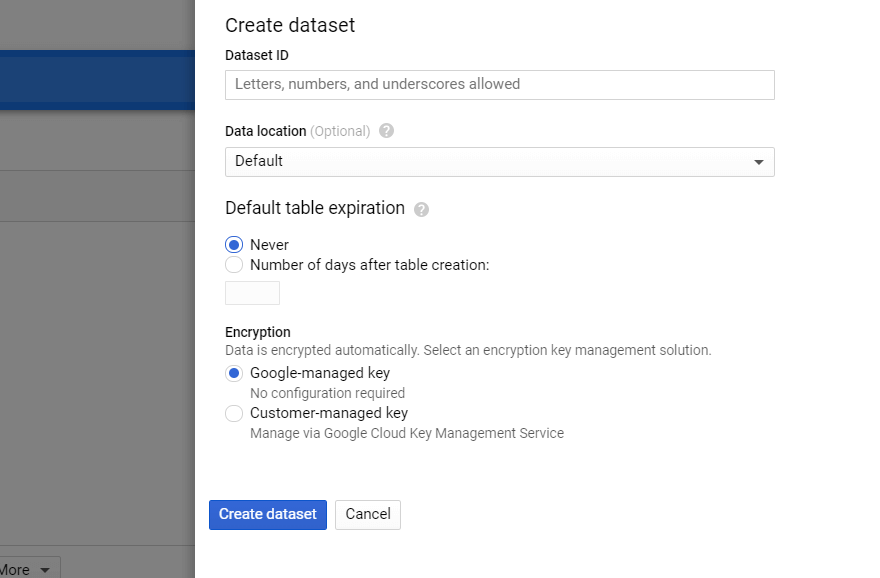
ステップ4.GBQでデータセットを準備します
BigQueryでプロジェクトを選択し、右側の[データセットの作成]ボタンをクリックします。 新しいデータセットに必要なすべてのフィールド(名前、場所、保持)に入力します。
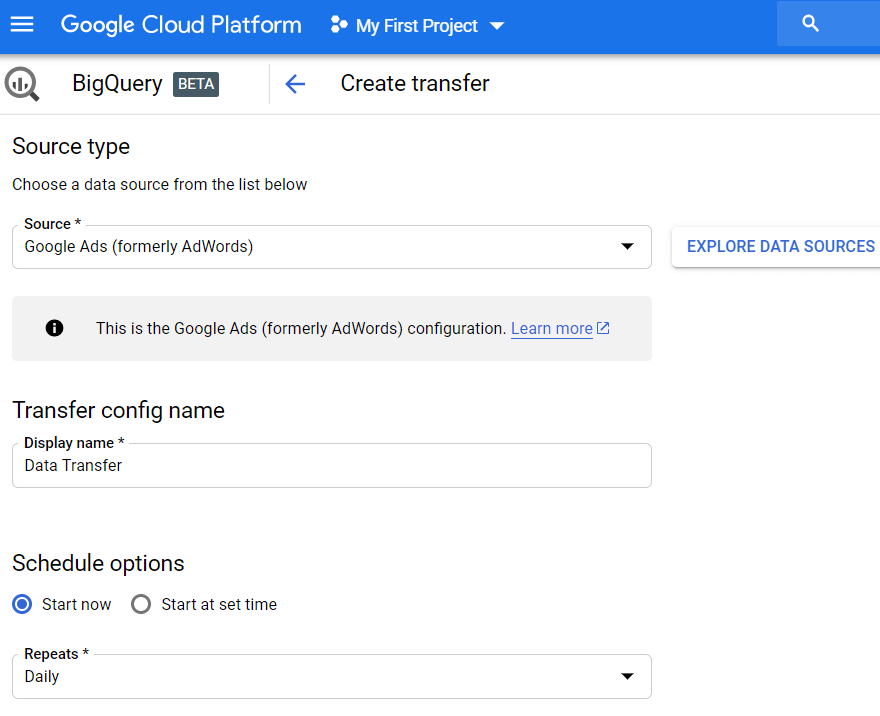
ステップ5.Google広告からのデータ転送を設定する
サイドメニューの[転送]タブをクリックし、[転送の作成]をクリックします。 次に、ソースとしてGoogle広告(以前のAdWords)を選択し、アップロードの名前(データ転送など)を入力します。
[スケジュールオプション]で、デフォルトを[今すぐ開始]に設定したままにするか、ダウンロードを開始する日時を設定できます。 [繰り返し]フィールドで、アップロードする頻度を選択します:毎日、毎週、毎月のオンデマンドなど。
次に、Google広告からレポートを読み込むGBQデータセットを指定する必要があります。 顧客ID(これはGoogle広告アカウントまたはMCC IDのID)を入力し、[追加]をクリックします。 顧客IDは、右上隅のメールの横にあるGoogle広告アカウントで確認できます。
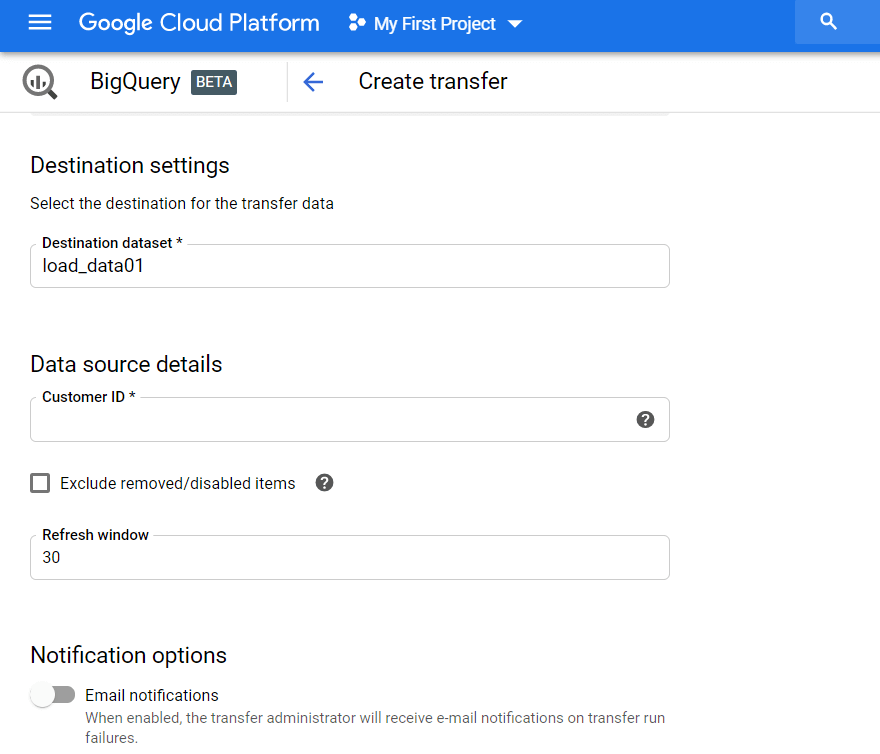
次に、使用しているGmailアカウントを承認する必要があります。 翌日、転送の設定時に指定したデータセットに情報が表示されます。
その結果、キャンペーン別のテーブル、オーディエンス、一般的な(カスタム)テーブル、キーワード、コンバージョンなど、GBQで大量の生データを受け取ることができます。 たとえば、カスタムダッシュボードを作成する場合は、これらのテーブルから非集計データを取得できます。
広告スクリプトを使用してアップロードを設定する方法
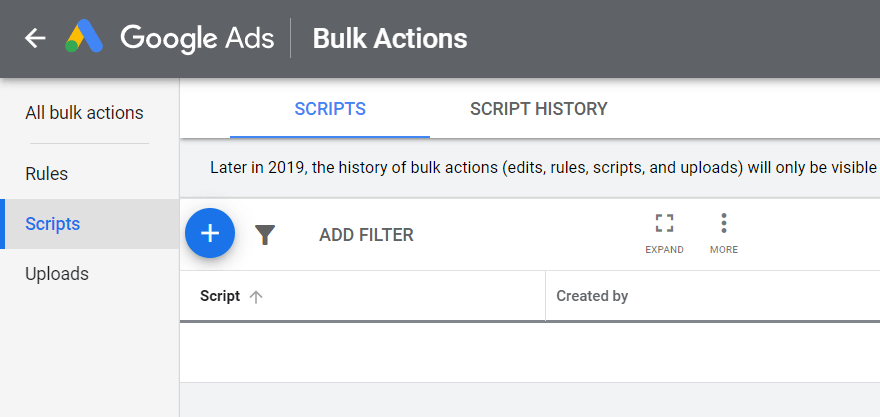
Google広告アカウントを開き、右上隅にある[ツールと設定]をクリックし、[一括操作-スクリプト]を選択して、プラス記号をクリックします。
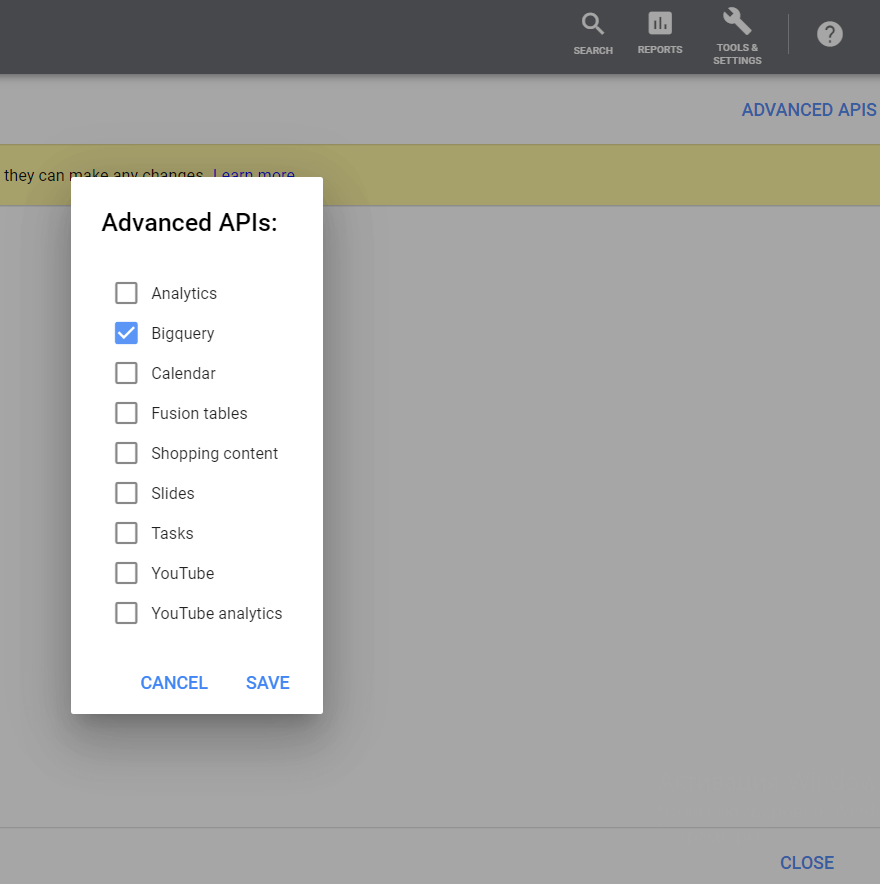
次に、右上隅にある[高度なAPI]ボタンをクリックし、[BigQuery]を選択して、変更を保存します。
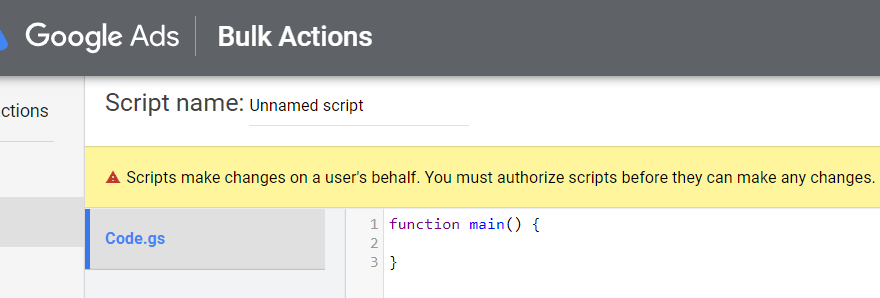
次の方法でGoogle広告にログインしたアカウントで登録してください。
以下のスクリプトをコピーします。 BIGQUERY_PROJECT_ID、BIGQUERY_DATASET_ID、およびYour email行で、値を独自の情報(プロジェクト名、GBQデータセット、および電子メール)に置き換えます。 スクリプトテキストをテキストエディタに貼り付けます。
/** * @name Export Data to BigQuery * * @overview The Export Data to BigQuery script sets up a BigQuery * dataset and tables, downloads a report from AdWords and then * loads the report to BigQuery. * * @author AdWords Scripts Team [[email protected]] * * @version 1.3 */ var CONFIG = { BIGQUERY_PROJECT_ID: 'BQ project name', BIGQUERY_DATASET_ID: AdWordsApp.currentAccount().getCustomerId().replace(/-/g, '_'), // Truncate existing data, otherwise will append. TRUNCATE_EXISTING_DATASET: false, TRUNCATE_EXISTING_TABLES: true, // Lists of reports and fields to retrieve from AdWords. REPORTS: [], RECIPIENT_EMAILS: [ 'Your email' ] }; var report = { NAME: 'CLICK_PERFORMANCE_REPORT', //https://developers.google.com/adwords/api/docs/appendix/reports/click-performance-report CONDITIONS: '', FIELDS: {'AccountDescriptiveName': 'STRING', 'AdFormat': 'STRING', 'AdGroupId': 'STRING', 'AdGroupName': 'STRING', 'AoiCountryCriteriaId': 'STRING', 'CampaignId': 'STRING', 'CampaignLocationTargetId': 'STRING', 'CampaignName': 'STRING', 'CampaignStatus': 'STRING', 'Clicks': 'INTEGER', 'ClickType': 'STRING', 'CreativeId': 'STRING', 'CriteriaId': 'STRING', 'CriteriaParameters': 'STRING', 'Date': 'DATE', 'Device': 'STRING', 'ExternalCustomerId': 'STRING', 'GclId': 'STRING', 'KeywordMatchType': 'STRING', 'LopCountryCriteriaId': 'STRING', 'Page': 'INTEGER' }, DATE_RANGE: new Date(new Date().setDate(new Date().getDate()-1)).toISOString().slice(0, 10).replace(/-/g, "")+','+new Date(new Date().setDate(new Date().getDate()-1)).toISOString().slice(0, 10).replace(/-/g, ""), DATE: new Date(new Date().setDate(new Date().getDate()-1)).toISOString().slice(0, 10).replace(/-/g, "") }; //Regular export CONFIG.REPORTS.push(JSON.parse(JSON.stringify(report))); //One-time historical export //for(var i=2;i<91;i++){ // report.DATE_RANGE = new Date(new Date().setDate(new Date().getDate()-i)).toISOString().slice(0, 10).replace(/-/g, "")+','+new Date(new Date().setDate(new Date().getDate()-i)).toISOString().slice(0, 10).replace(/-/g, ""); // report.DATE = new Date(new Date().setDate(new Date().getDate()-i)).toISOString().slice(0, 10).replace(/-/g, ""); // CONFIG.REPORTS.push(JSON.parse(JSON.stringify(report))); //} /** * Main method */ function main() { createDataset(); for (var i = 0; i < CONFIG.REPORTS.length; i++) { var reportConfig = CONFIG.REPORTS[i]; createTable(reportConfig); } var jobIds = processReports(); waitTillJobsComplete(jobIds); sendEmail(jobIds); } /** * Creates a new dataset. * * If a dataset with the same id already exists and the truncate flag * is set, will truncate the old dataset. If the truncate flag is not * set, then will not create a new dataset. */ function createDataset() { if (datasetExists()) { if (CONFIG.TRUNCATE_EXISTING_DATASET) { BigQuery.Datasets.remove(CONFIG.BIGQUERY_PROJECT_ID, CONFIG.BIGQUERY_DATASET_ID, {'deleteContents' : true}); Logger.log('Truncated dataset.'); } else { Logger.log('Dataset %s already exists. Will not recreate.', CONFIG.BIGQUERY_DATASET_ID); return; } } // Create new dataset. var dataSet = BigQuery.newDataset(); dataSet.friendlyName = CONFIG.BIGQUERY_DATASET_ID; dataSet.datasetReference = BigQuery.newDatasetReference(); dataSet.datasetReference.projectId = CONFIG.BIGQUERY_PROJECT_ID; dataSet.datasetReference.datasetId = CONFIG.BIGQUERY_DATASET_ID; dataSet = BigQuery.Datasets.insert(dataSet, CONFIG.BIGQUERY_PROJECT_ID); Logger.log('Created dataset with id %s.', dataSet.id); } /** * Checks if dataset already exists in project. * * @return {boolean} Returns true if dataset already exists. */ function datasetExists() { // Get a list of all datasets in project. var datasets = BigQuery.Datasets.list(CONFIG.BIGQUERY_PROJECT_ID); var datasetExists = false; // Iterate through each dataset and check for an id match. if (datasets.datasets != null) { for (var i = 0; i < datasets.datasets.length; i++) { var dataset = datasets.datasets[i]; if (dataset.datasetReference.datasetId == CONFIG.BIGQUERY_DATASET_ID) { datasetExists = true; break; } } } return datasetExists; } /** * Creates a new table. * * If a table with the same id already exists and the truncate flag * is set, will truncate the old table. If the truncate flag is not * set, then will not create a new table. * * @param {Object} reportConfig Report configuration including report name, * conditions, and fields. */ function createTable(reportConfig) { var tableName = reportConfig.NAME+reportConfig.DATE; if (tableExists(tableName)) { if (CONFIG.TRUNCATE_EXISTING_TABLES) { BigQuery.Tables.remove(CONFIG.BIGQUERY_PROJECT_ID, CONFIG.BIGQUERY_DATASET_ID, tableName); Logger.log('Truncated table %s.', tableName); } else { Logger.log('Table %s already exists. Will not recreate.', tableName); return; } } // Create new table. var table = BigQuery.newTable(); var schema = BigQuery.newTableSchema(); var bigQueryFields = []; // Add each field to table schema. var fieldNames = Object.keys(reportConfig.FIELDS); for (var i = 0; i < fieldNames.length; i++) { var fieldName = fieldNames[i]; var bigQueryFieldSchema = BigQuery.newTableFieldSchema(); bigQueryFieldSchema.description = fieldName; bigQueryFieldSchema.name = fieldName; bigQueryFieldSchema.type = reportConfig.FIELDS[fieldName]; bigQueryFields.push(bigQueryFieldSchema); } schema.fields = bigQueryFields; table.schema = schema; table.friendlyName = tableName; table.tableReference = BigQuery.newTableReference(); table.tableReference.datasetId = CONFIG.BIGQUERY_DATASET_ID; table.tableReference.projectId = CONFIG.BIGQUERY_PROJECT_ID; table.tableReference.tableId = tableName; table = BigQuery.Tables.insert(table, CONFIG.BIGQUERY_PROJECT_ID, CONFIG.BIGQUERY_DATASET_ID); Logger.log('Created table with id %s.', table.id); } /** * Checks if table already exists in dataset. * * @param {string} tableId The table id to check existence. * * @return {boolean} Returns true if table already exists. */ function tableExists(tableId) { // Get a list of all tables in the dataset. var tables = BigQuery.Tables.list(CONFIG.BIGQUERY_PROJECT_ID, CONFIG.BIGQUERY_DATASET_ID); var tableExists = false; // Iterate through each table and check for an id match. if (tables.tables != null) { for (var i = 0; i < tables.tables.length; i++) { var table = tables.tables[i]; if (table.tableReference.tableId == tableId) { tableExists = true; break; } } } return tableExists; } /** * Process all configured reports * * Iterates through each report to: retrieve AdWords data, * backup data to Drive (if configured), load data to BigQuery. * * @return {Array.<string>} jobIds The list of all job ids. */ function processReports() { var jobIds = []; // Iterate over each report type. for (var i = 0; i < CONFIG.REPORTS.length; i++) { var reportConfig = CONFIG.REPORTS[i]; Logger.log('Running report %s', reportConfig.NAME); // Get data as csv var csvData = retrieveAdwordsReport(reportConfig); //Logger.log(csvData); // Convert to Blob format. var blobData = Utilities.newBlob(csvData, 'application/octet-stream'); // Load data var jobId = loadDataToBigquery(reportConfig, blobData); jobIds.push(jobId); } return jobIds; } /** * Retrieves AdWords data as csv and formats any fields * to BigQuery expected format. * * @param {Object} reportConfig Report configuration including report name, * conditions, and fields. * * @return {string} csvData Report in csv format. */ function retrieveAdwordsReport(reportConfig) { var fieldNames = Object.keys(reportConfig.FIELDS); var query = 'SELECT ' + fieldNames.join(', ') + ' FROM ' + reportConfig.NAME + '' + reportConfig.CONDITIONS + ' DURING ' + reportConfig.DATE_RANGE; Logger.log(query); var report = AdWordsApp.report(query); var rows = report.rows(); var csvRows = []; // Header row csvRows.push(fieldNames.join(',')); // Iterate over each row. while (rows.hasNext()) { var row = rows.next(); var csvRow = []; for (var i = 0; i < fieldNames.length; i++) { var fieldName = fieldNames[i]; var fieldValue = row[fieldName].toString(); var fieldType = reportConfig.FIELDS[fieldName]; // Strip off % and perform any other formatting here. if (fieldType == 'FLOAT' || fieldType == 'INTEGER') { if (fieldValue.charAt(fieldValue.length - 1) == '%') { fieldValue = fieldValue.substring(0, fieldValue.length - 1); } fieldValue = fieldValue.replace(/,/g,''); if (fieldValue == '--' || fieldValue == 'Unspecified') { fieldValue = '' } } // Add double quotes to any string values. if (fieldType == 'STRING') { if (fieldValue == '--') { fieldValue = '' } fieldValue = fieldValue.replace(/"/g, '""'); fieldValue = '"' + fieldValue + '"' } csvRow.push(fieldValue); } csvRows.push(csvRow.join(',')); } Logger.log('Downloaded ' + reportConfig.NAME + ' with ' + csvRows.length + ' rows.'); return csvRows.join('\n'); } /** * Creates a BigQuery insertJob to load csv data. * * @param {Object} reportConfig Report configuration including report name, * conditions, and fields. * @param {Blob} data Csv report data as an 'application/octet-stream' blob. * * @return {string} jobId The job id for upload. */ function loadDataToBigquery(reportConfig, data) { // Create the data upload job. var job = { configuration: { load: { destinationTable: { projectId: CONFIG.BIGQUERY_PROJECT_ID, datasetId: CONFIG.BIGQUERY_DATASET_ID, tableId: reportConfig.NAME + reportConfig.DATE }, skipLeadingRows: 1 } } }; var insertJob = BigQuery.Jobs.insert(job, CONFIG.BIGQUERY_PROJECT_ID, data); Logger.log('Load job started for %s. Check on the status of it here: ' + 'https://bigquery.cloud.google.com/jobs/%s', reportConfig.NAME, CONFIG.BIGQUERY_PROJECT_ID); return insertJob.jobReference.jobId; } /** * Polls until all jobs are 'DONE'. * * @param {Array.<string>} jobIds The list of all job ids. */ function waitTillJobsComplete(jobIds) { var complete = false; var remainingJobs = jobIds; while (!complete) { if (AdWordsApp.getExecutionInfo().getRemainingTime() < 5){ Logger.log('Script is about to timeout, jobs ' + remainingJobs.join(',') + ' are still incomplete.'); } remainingJobs = getIncompleteJobs(remainingJobs); if (remainingJobs.length == 0) { complete = true; } if (!complete) { Logger.log(remainingJobs.length + ' jobs still being processed.'); // Wait 5 seconds before checking status again. Utilities.sleep(5000); } } Logger.log('All jobs processed.'); } /** * Iterates through jobs and returns the ids for those jobs * that are not 'DONE'. * * @param {Array.<string>} jobIds The list of job ids. * * @return {Array.<string>} remainingJobIds The list of remaining job ids. */ function getIncompleteJobs(jobIds) { var remainingJobIds = []; for (var i = 0; i < jobIds.length; i++) { var jobId = jobIds[i]; var getJob = BigQuery.Jobs.get(CONFIG.BIGQUERY_PROJECT_ID, jobId); if (getJob.status.state != 'DONE') { remainingJobIds.push(jobId); } } return remainingJobIds; } /** * Sends a notification email that jobs have completed loading. * * @param {Array.<string>} jobIds The list of all job ids. */ function sendEmail(jobIds) { var html = []; html.push( '<html>', '<body>', '<table width=800 cellpadding=0 border=0 cellspacing=0>', '<tr>', '<td colspan=2 align=right>', "<div style='font: italic normal 10pt Times New Roman, serif; " + "margin: 0; color: #666; padding-right: 5px;'>" + 'Powered by AdWords Scripts</div>', '</td>', '</tr>', "<tr bgcolor='#3c78d8'>", '<td width=500>', "<div style='font: normal 18pt verdana, sans-serif; " + "padding: 3px 10px; color: white'>Adwords data load to " + "Bigquery report</div>", '</td>', '<td align=right>', "<div style='font: normal 18pt verdana, sans-serif; " + "padding: 3px 10px; color: white'>", AdWordsApp.currentAccount().getCustomerId(), '</tr>', '</table>', '<table width=800 cellpadding=0 border=1 cellspacing=0>', "<tr bgcolor='#ddd'>", "<td style='font: 12pt verdana, sans-serif; " + 'padding: 5px 0px 5px 5px; background-color: #ddd; ' + "text-align: left'>Report</td>", "<td style='font: 12pt verdana, sans-serif; " + 'padding: 5px 0px 5px 5px; background-color: #ddd; ' + "text-align: left'>JobId</td>", "<td style='font: 12pt verdana, sans-serif; " + 'padding: 5px 0px 5x 5px; background-color: #ddd; ' + "text-align: left'>Rows</td>", "<td style='font: 12pt verdana, sans-serif; " + 'padding: 5px 0px 5x 5px; background-color: #ddd; ' + "text-align: left'>State</td>", "<td style='font: 12pt verdana, sans-serif; " + 'padding: 5px 0px 5x 5px; background-color: #ddd; ' + "text-align: left'>ErrorResult</td>", '</tr>', createTableRows(jobIds), '</table>', '</body>', '</html>'); MailApp.sendEmail(CONFIG.RECIPIENT_EMAILS.join(','), 'Adwords data load to Bigquery Complete', '', {htmlBody: html.join('\n')}); } /** * Creates table rows for email report. * * @param {Array.<string>} jobIds The list of all job ids. */ function createTableRows(jobIds) { var html = []; for (var i = 0; i < jobIds.length; i++) { var jobId = jobIds[i]; var job = BigQuery.Jobs.get(CONFIG.BIGQUERY_PROJECT_ID, jobId); var errorResult = '' if (job.status.errorResult) { errorResult = job.status.errorResult; } html.push('<tr>', "<td style='padding: 0px 10px'>" + job.configuration.load.destinationTable.tableId + '</td>', "<td style='padding: 0px 10px'>" + jobId + '</td>', "<td style='padding: 0px 10px'>" + job.statistics.load?job.statistics.load.outputRows:0 + '</td>', "<td style='padding: 0px 10px'>" + job.status.state + '</td>', "<td style='padding: 0px 10px'>" + errorResult + '</td>', '</tr>'); } return html.join('\n'); }
/** * @name Export Data to BigQuery * * @overview The Export Data to BigQuery script sets up a BigQuery * dataset and tables, downloads a report from AdWords and then * loads the report to BigQuery. * * @author AdWords Scripts Team [[email protected]] * * @version 1.3 */ var CONFIG = { BIGQUERY_PROJECT_ID: 'BQ project name', BIGQUERY_DATASET_ID: AdWordsApp.currentAccount().getCustomerId().replace(/-/g, '_'), // Truncate existing data, otherwise will append. TRUNCATE_EXISTING_DATASET: false, TRUNCATE_EXISTING_TABLES: true, // Lists of reports and fields to retrieve from AdWords. REPORTS: [], RECIPIENT_EMAILS: [ 'Your email' ] }; var report = { NAME: 'CLICK_PERFORMANCE_REPORT', //https://developers.google.com/adwords/api/docs/appendix/reports/click-performance-report CONDITIONS: '', FIELDS: {'AccountDescriptiveName': 'STRING', 'AdFormat': 'STRING', 'AdGroupId': 'STRING', 'AdGroupName': 'STRING', 'AoiCountryCriteriaId': 'STRING', 'CampaignId': 'STRING', 'CampaignLocationTargetId': 'STRING', 'CampaignName': 'STRING', 'CampaignStatus': 'STRING', 'Clicks': 'INTEGER', 'ClickType': 'STRING', 'CreativeId': 'STRING', 'CriteriaId': 'STRING', 'CriteriaParameters': 'STRING', 'Date': 'DATE', 'Device': 'STRING', 'ExternalCustomerId': 'STRING', 'GclId': 'STRING', 'KeywordMatchType': 'STRING', 'LopCountryCriteriaId': 'STRING', 'Page': 'INTEGER' }, DATE_RANGE: new Date(new Date().setDate(new Date().getDate()-1)).toISOString().slice(0, 10).replace(/-/g, "")+','+new Date(new Date().setDate(new Date().getDate()-1)).toISOString().slice(0, 10).replace(/-/g, ""), DATE: new Date(new Date().setDate(new Date().getDate()-1)).toISOString().slice(0, 10).replace(/-/g, "") }; //Regular export CONFIG.REPORTS.push(JSON.parse(JSON.stringify(report))); //One-time historical export //for(var i=2;i<91;i++){ // report.DATE_RANGE = new Date(new Date().setDate(new Date().getDate()-i)).toISOString().slice(0, 10).replace(/-/g, "")+','+new Date(new Date().setDate(new Date().getDate()-i)).toISOString().slice(0, 10).replace(/-/g, ""); // report.DATE = new Date(new Date().setDate(new Date().getDate()-i)).toISOString().slice(0, 10).replace(/-/g, ""); // CONFIG.REPORTS.push(JSON.parse(JSON.stringify(report))); //} /** * Main method */ function main() { createDataset(); for (var i = 0; i < CONFIG.REPORTS.length; i++) { var reportConfig = CONFIG.REPORTS[i]; createTable(reportConfig); } var jobIds = processReports(); waitTillJobsComplete(jobIds); sendEmail(jobIds); } /** * Creates a new dataset. * * If a dataset with the same id already exists and the truncate flag * is set, will truncate the old dataset. If the truncate flag is not * set, then will not create a new dataset. */ function createDataset() { if (datasetExists()) { if (CONFIG.TRUNCATE_EXISTING_DATASET) { BigQuery.Datasets.remove(CONFIG.BIGQUERY_PROJECT_ID, CONFIG.BIGQUERY_DATASET_ID, {'deleteContents' : true}); Logger.log('Truncated dataset.'); } else { Logger.log('Dataset %s already exists. Will not recreate.', CONFIG.BIGQUERY_DATASET_ID); return; } } // Create new dataset. var dataSet = BigQuery.newDataset(); dataSet.friendlyName = CONFIG.BIGQUERY_DATASET_ID; dataSet.datasetReference = BigQuery.newDatasetReference(); dataSet.datasetReference.projectId = CONFIG.BIGQUERY_PROJECT_ID; dataSet.datasetReference.datasetId = CONFIG.BIGQUERY_DATASET_ID; dataSet = BigQuery.Datasets.insert(dataSet, CONFIG.BIGQUERY_PROJECT_ID); Logger.log('Created dataset with id %s.', dataSet.id); } /** * Checks if dataset already exists in project. * * @return {boolean} Returns true if dataset already exists. */ function datasetExists() { // Get a list of all datasets in project. var datasets = BigQuery.Datasets.list(CONFIG.BIGQUERY_PROJECT_ID); var datasetExists = false; // Iterate through each dataset and check for an id match. if (datasets.datasets != null) { for (var i = 0; i < datasets.datasets.length; i++) { var dataset = datasets.datasets[i]; if (dataset.datasetReference.datasetId == CONFIG.BIGQUERY_DATASET_ID) { datasetExists = true; break; } } } return datasetExists; } /** * Creates a new table. * * If a table with the same id already exists and the truncate flag * is set, will truncate the old table. If the truncate flag is not * set, then will not create a new table. * * @param {Object} reportConfig Report configuration including report name, * conditions, and fields. */ function createTable(reportConfig) { var tableName = reportConfig.NAME+reportConfig.DATE; if (tableExists(tableName)) { if (CONFIG.TRUNCATE_EXISTING_TABLES) { BigQuery.Tables.remove(CONFIG.BIGQUERY_PROJECT_ID, CONFIG.BIGQUERY_DATASET_ID, tableName); Logger.log('Truncated table %s.', tableName); } else { Logger.log('Table %s already exists. Will not recreate.', tableName); return; } } // Create new table. var table = BigQuery.newTable(); var schema = BigQuery.newTableSchema(); var bigQueryFields = []; // Add each field to table schema. var fieldNames = Object.keys(reportConfig.FIELDS); for (var i = 0; i < fieldNames.length; i++) { var fieldName = fieldNames[i]; var bigQueryFieldSchema = BigQuery.newTableFieldSchema(); bigQueryFieldSchema.description = fieldName; bigQueryFieldSchema.name = fieldName; bigQueryFieldSchema.type = reportConfig.FIELDS[fieldName]; bigQueryFields.push(bigQueryFieldSchema); } schema.fields = bigQueryFields; table.schema = schema; table.friendlyName = tableName; table.tableReference = BigQuery.newTableReference(); table.tableReference.datasetId = CONFIG.BIGQUERY_DATASET_ID; table.tableReference.projectId = CONFIG.BIGQUERY_PROJECT_ID; table.tableReference.tableId = tableName; table = BigQuery.Tables.insert(table, CONFIG.BIGQUERY_PROJECT_ID, CONFIG.BIGQUERY_DATASET_ID); Logger.log('Created table with id %s.', table.id); } /** * Checks if table already exists in dataset. * * @param {string} tableId The table id to check existence. * * @return {boolean} Returns true if table already exists. */ function tableExists(tableId) { // Get a list of all tables in the dataset. var tables = BigQuery.Tables.list(CONFIG.BIGQUERY_PROJECT_ID, CONFIG.BIGQUERY_DATASET_ID); var tableExists = false; // Iterate through each table and check for an id match. if (tables.tables != null) { for (var i = 0; i < tables.tables.length; i++) { var table = tables.tables[i]; if (table.tableReference.tableId == tableId) { tableExists = true; break; } } } return tableExists; } /** * Process all configured reports * * Iterates through each report to: retrieve AdWords data, * backup data to Drive (if configured), load data to BigQuery. * * @return {Array.<string>} jobIds The list of all job ids. */ function processReports() { var jobIds = []; // Iterate over each report type. for (var i = 0; i < CONFIG.REPORTS.length; i++) { var reportConfig = CONFIG.REPORTS[i]; Logger.log('Running report %s', reportConfig.NAME); // Get data as csv var csvData = retrieveAdwordsReport(reportConfig); //Logger.log(csvData); // Convert to Blob format. var blobData = Utilities.newBlob(csvData, 'application/octet-stream'); // Load data var jobId = loadDataToBigquery(reportConfig, blobData); jobIds.push(jobId); } return jobIds; } /** * Retrieves AdWords data as csv and formats any fields * to BigQuery expected format. * * @param {Object} reportConfig Report configuration including report name, * conditions, and fields. * * @return {string} csvData Report in csv format. */ function retrieveAdwordsReport(reportConfig) { var fieldNames = Object.keys(reportConfig.FIELDS); var query = 'SELECT ' + fieldNames.join(', ') + ' FROM ' + reportConfig.NAME + '' + reportConfig.CONDITIONS + ' DURING ' + reportConfig.DATE_RANGE; Logger.log(query); var report = AdWordsApp.report(query); var rows = report.rows(); var csvRows = []; // Header row csvRows.push(fieldNames.join(',')); // Iterate over each row. while (rows.hasNext()) { var row = rows.next(); var csvRow = []; for (var i = 0; i < fieldNames.length; i++) { var fieldName = fieldNames[i]; var fieldValue = row[fieldName].toString(); var fieldType = reportConfig.FIELDS[fieldName]; // Strip off % and perform any other formatting here. if (fieldType == 'FLOAT' || fieldType == 'INTEGER') { if (fieldValue.charAt(fieldValue.length - 1) == '%') { fieldValue = fieldValue.substring(0, fieldValue.length - 1); } fieldValue = fieldValue.replace(/,/g,''); if (fieldValue == '--' || fieldValue == 'Unspecified') { fieldValue = '' } } // Add double quotes to any string values. if (fieldType == 'STRING') { if (fieldValue == '--') { fieldValue = '' } fieldValue = fieldValue.replace(/"/g, '""'); fieldValue = '"' + fieldValue + '"' } csvRow.push(fieldValue); } csvRows.push(csvRow.join(',')); } Logger.log('Downloaded ' + reportConfig.NAME + ' with ' + csvRows.length + ' rows.'); return csvRows.join('\n'); } /** * Creates a BigQuery insertJob to load csv data. * * @param {Object} reportConfig Report configuration including report name, * conditions, and fields. * @param {Blob} data Csv report data as an 'application/octet-stream' blob. * * @return {string} jobId The job id for upload. */ function loadDataToBigquery(reportConfig, data) { // Create the data upload job. var job = { configuration: { load: { destinationTable: { projectId: CONFIG.BIGQUERY_PROJECT_ID, datasetId: CONFIG.BIGQUERY_DATASET_ID, tableId: reportConfig.NAME + reportConfig.DATE }, skipLeadingRows: 1 } } }; var insertJob = BigQuery.Jobs.insert(job, CONFIG.BIGQUERY_PROJECT_ID, data); Logger.log('Load job started for %s. Check on the status of it here: ' + 'https://bigquery.cloud.google.com/jobs/%s', reportConfig.NAME, CONFIG.BIGQUERY_PROJECT_ID); return insertJob.jobReference.jobId; } /** * Polls until all jobs are 'DONE'. * * @param {Array.<string>} jobIds The list of all job ids. */ function waitTillJobsComplete(jobIds) { var complete = false; var remainingJobs = jobIds; while (!complete) { if (AdWordsApp.getExecutionInfo().getRemainingTime() < 5){ Logger.log('Script is about to timeout, jobs ' + remainingJobs.join(',') + ' are still incomplete.'); } remainingJobs = getIncompleteJobs(remainingJobs); if (remainingJobs.length == 0) { complete = true; } if (!complete) { Logger.log(remainingJobs.length + ' jobs still being processed.'); // Wait 5 seconds before checking status again. Utilities.sleep(5000); } } Logger.log('All jobs processed.'); } /** * Iterates through jobs and returns the ids for those jobs * that are not 'DONE'. * * @param {Array.<string>} jobIds The list of job ids. * * @return {Array.<string>} remainingJobIds The list of remaining job ids. */ function getIncompleteJobs(jobIds) { var remainingJobIds = []; for (var i = 0; i < jobIds.length; i++) { var jobId = jobIds[i]; var getJob = BigQuery.Jobs.get(CONFIG.BIGQUERY_PROJECT_ID, jobId); if (getJob.status.state != 'DONE') { remainingJobIds.push(jobId); } } return remainingJobIds; } /** * Sends a notification email that jobs have completed loading. * * @param {Array.<string>} jobIds The list of all job ids. */ function sendEmail(jobIds) { var html = []; html.push( '<html>', '<body>', '<table width=800 cellpadding=0 border=0 cellspacing=0>', '<tr>', '<td colspan=2 align=right>', "<div style='font: italic normal 10pt Times New Roman, serif; " + "margin: 0; color: #666; padding-right: 5px;'>" + 'Powered by AdWords Scripts</div>', '</td>', '</tr>', "<tr bgcolor='#3c78d8'>", '<td width=500>', "<div style='font: normal 18pt verdana, sans-serif; " + "padding: 3px 10px; color: white'>Adwords data load to " + "Bigquery report</div>", '</td>', '<td align=right>', "<div style='font: normal 18pt verdana, sans-serif; " + "padding: 3px 10px; color: white'>", AdWordsApp.currentAccount().getCustomerId(), '</tr>', '</table>', '<table width=800 cellpadding=0 border=1 cellspacing=0>', "<tr bgcolor='#ddd'>", "<td style='font: 12pt verdana, sans-serif; " + 'padding: 5px 0px 5px 5px; background-color: #ddd; ' + "text-align: left'>Report</td>", "<td style='font: 12pt verdana, sans-serif; " + 'padding: 5px 0px 5px 5px; background-color: #ddd; ' + "text-align: left'>JobId</td>", "<td style='font: 12pt verdana, sans-serif; " + 'padding: 5px 0px 5x 5px; background-color: #ddd; ' + "text-align: left'>Rows</td>", "<td style='font: 12pt verdana, sans-serif; " + 'padding: 5px 0px 5x 5px; background-color: #ddd; ' + "text-align: left'>State</td>", "<td style='font: 12pt verdana, sans-serif; " + 'padding: 5px 0px 5x 5px; background-color: #ddd; ' + "text-align: left'>ErrorResult</td>", '</tr>', createTableRows(jobIds), '</table>', '</body>', '</html>'); MailApp.sendEmail(CONFIG.RECIPIENT_EMAILS.join(','), 'Adwords data load to Bigquery Complete', '', {htmlBody: html.join('\n')}); } /** * Creates table rows for email report. * * @param {Array.<string>} jobIds The list of all job ids. */ function createTableRows(jobIds) { var html = []; for (var i = 0; i < jobIds.length; i++) { var jobId = jobIds[i]; var job = BigQuery.Jobs.get(CONFIG.BIGQUERY_PROJECT_ID, jobId); var errorResult = '' if (job.status.errorResult) { errorResult = job.status.errorResult; } html.push('<tr>', "<td style='padding: 0px 10px'>" + job.configuration.load.destinationTable.tableId + '</td>', "<td style='padding: 0px 10px'>" + jobId + '</td>', "<td style='padding: 0px 10px'>" + job.statistics.load?job.statistics.load.outputRows:0 + '</td>', "<td style='padding: 0px 10px'>" + job.status.state + '</td>', "<td style='padding: 0px 10px'>" + errorResult + '</td>', '</tr>'); } return html.join('\n'); } スクリプトを実行する前に、必ず右下隅の[プレビュー]ボタンをクリックして結果を確認してください。 エラーがある場合は、次のスクリーンショットのように、システムが警告を発し、どの行でエラーが発生したかを示します。

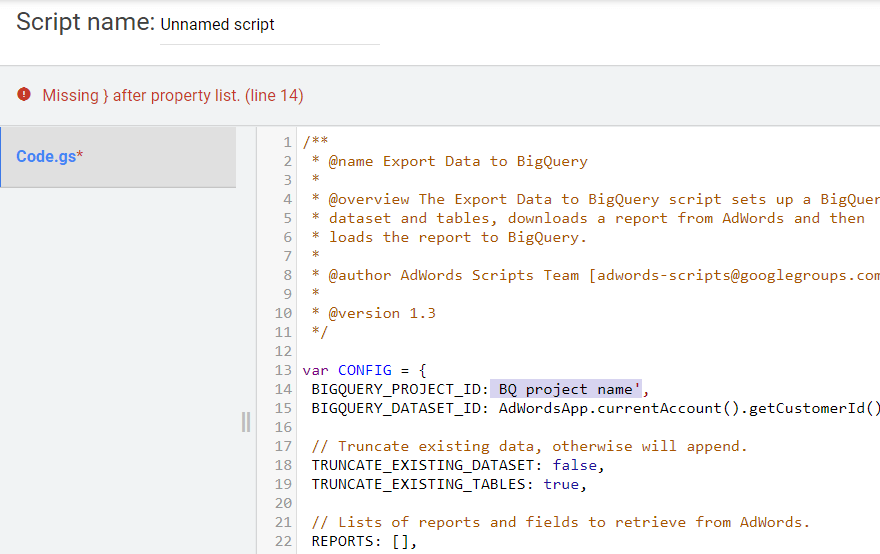
エラーがない場合は、[実行]ボタンをクリックします。
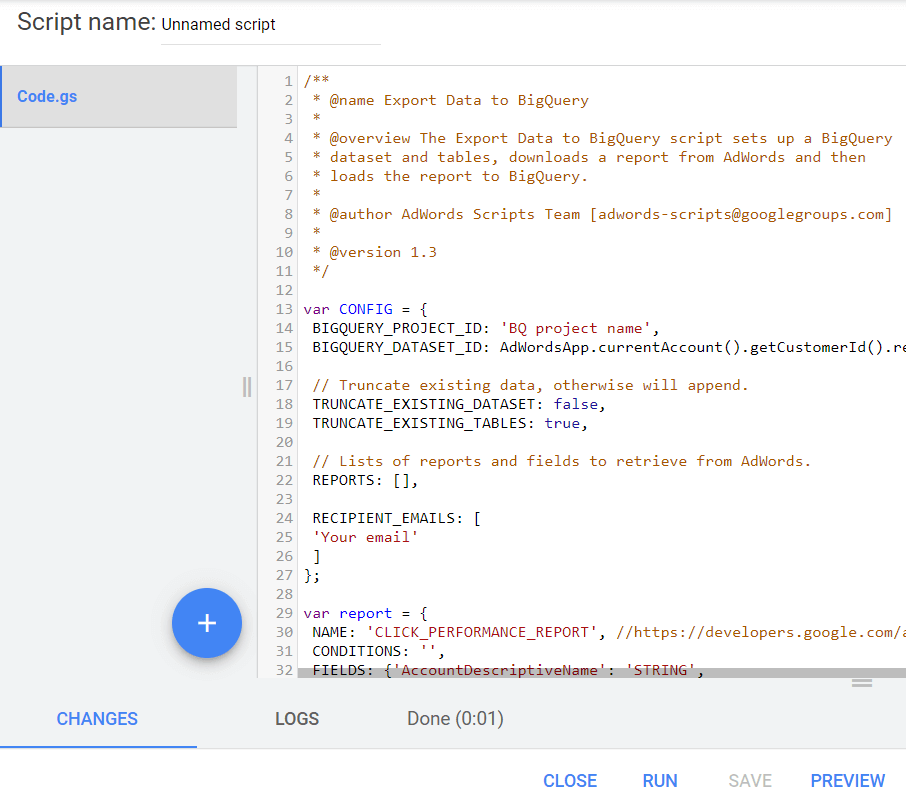
その結果、GBQに新しいCLICK_PERFORMANCE_REPORTレポートが届き、翌日利用できるようになります。
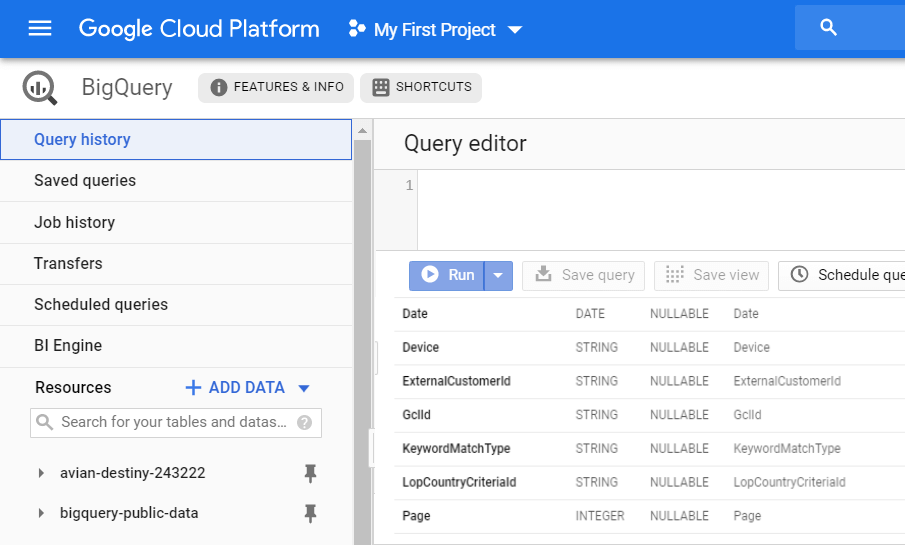
データ転送を使用すると、大量の未集計の非集計データが取得されることを思い出してください。 広告スクリプトを使用すると、特定のフィールドに関する情報のみが表示されます。
このアップロードの次のフィールドは、セッション関連のOWOXBIテーブルに含まれています。
- GclId
- CampaignId
- キャンペーン名
- AdGroupId
- AdGroupName
- CriteriaId
- CriteriaParameters
- キーワードマッチタイプ
Google広告からダウンロードしたデータをOWOXBIに接続する方法
次に、Google広告の情報とサイトデータを組み合わせて、ユーザーがどのキャンペーンを通じてサイトにアクセスしたかを理解する必要があります。 データ転送などのBigQueryで取得するテーブルには、クライアントIDパラメータがありません。 gclidデータをOWOXBIフローデータにリンクすることによってのみ、どの顧客が広告をクリックしたかを判断できます。
OWOXBIにGoogleAnalytics→GoogleBigQueryストリーミングパイプラインがまだない場合は、作成方法の説明をお読みください。
次に、OWOX BIプロジェクトに移動し、このパイプラインを開きます。 [設定]タブをクリックし、[セッションデータ収集]で[設定の編集]をクリックします。
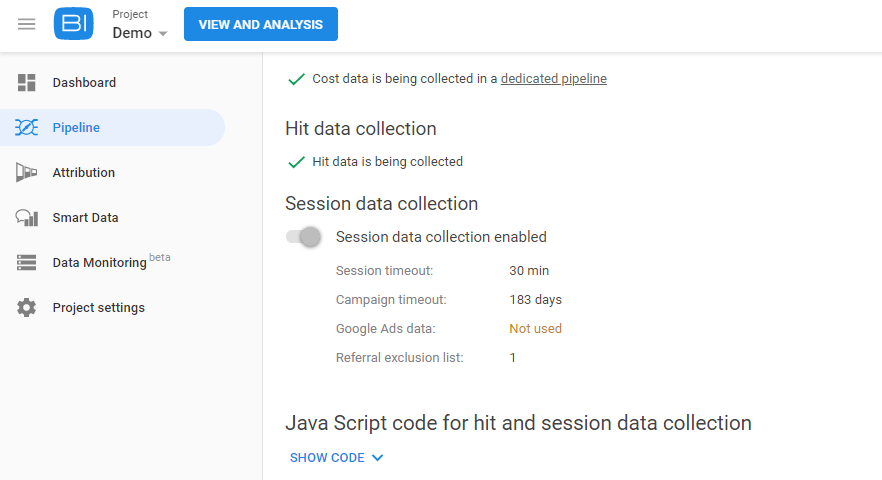
スライダーを使用して、Google広告の自動ラベル付きキャンペーンのデータ収集を有効にし、[設定の変更]をクリックします。
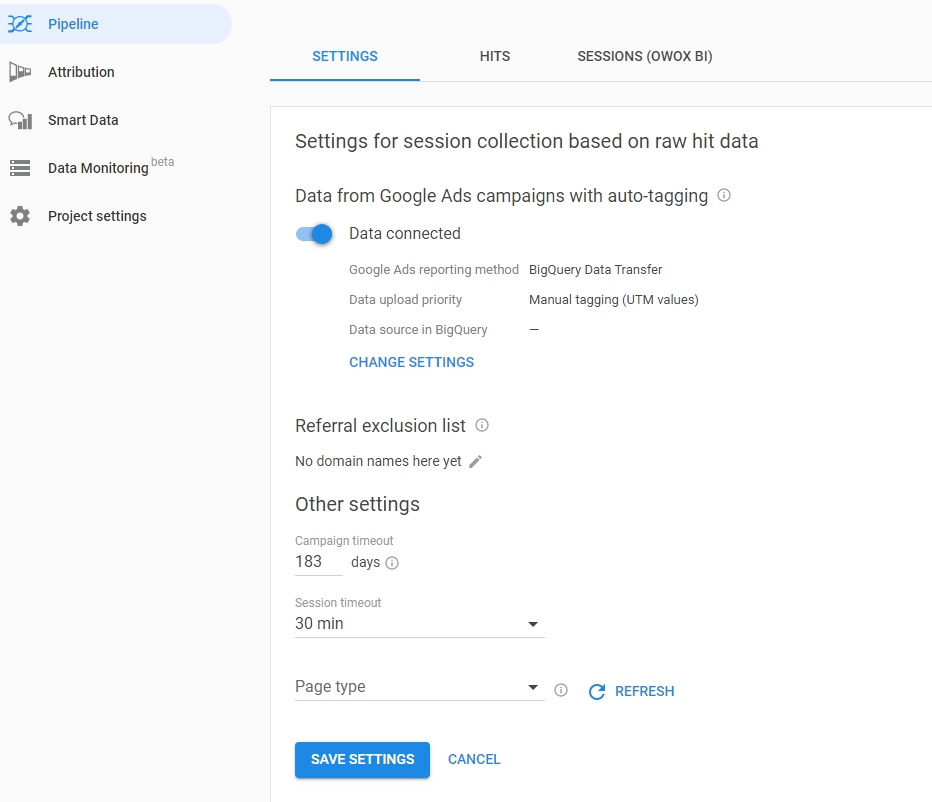
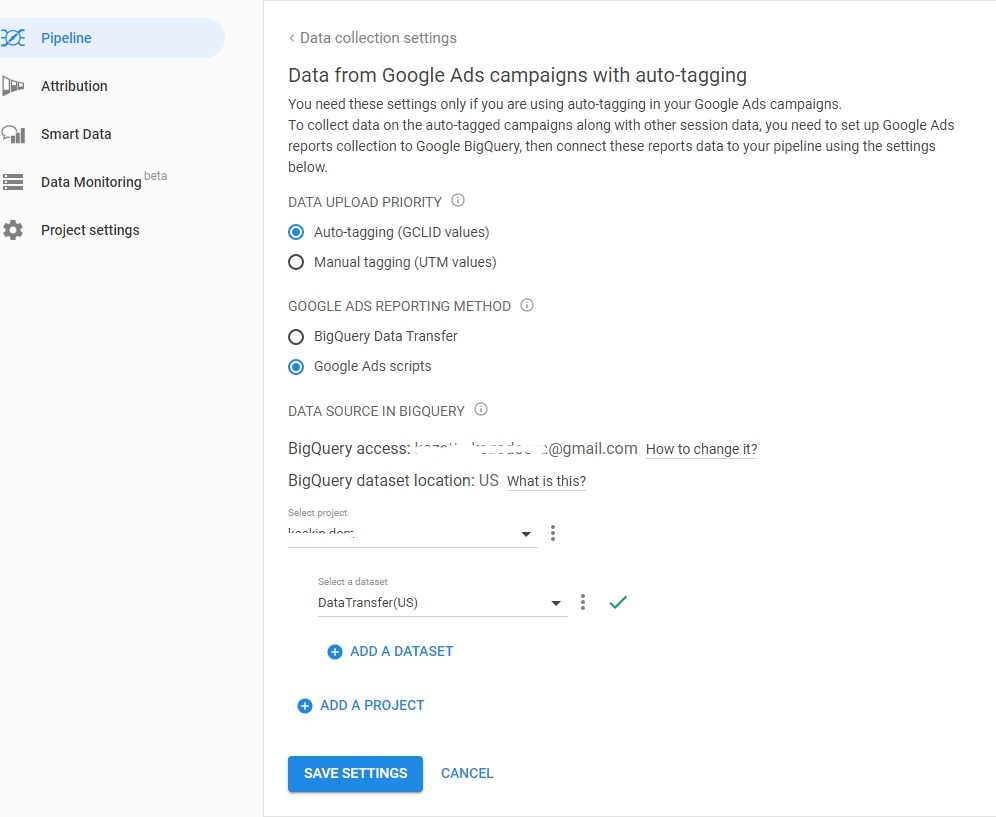
AutoLabelマークアップタイプを選択し、データ転送または広告スクリプトをBigQueryに読み込む方法を指定します。 Google広告データのダウンロード元のプロジェクトとデータセットを指定し、設定を保存します。
役立つヒント
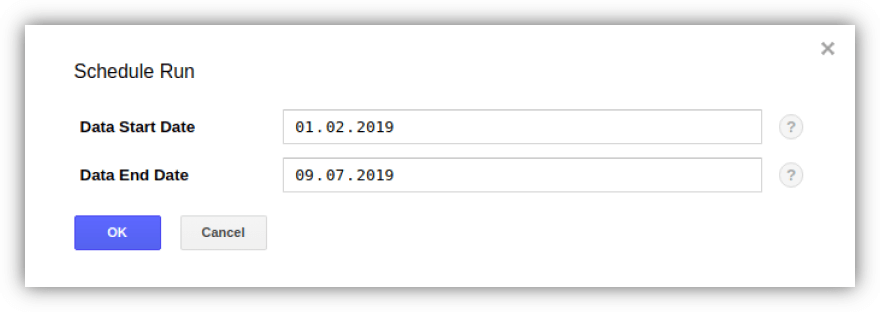
ヒント1.データ転送を使用すると、Google広告からGBQに履歴データをアップロードできます。 同時に、ロードの合計期間(1年間または3年間)に制限はありませんが、一度に180日間のデータしかありません。
アップロードをアクティブにし、必要な転送を選択して、[転送]タブの[埋め戻しのスケジュール]ボタンを使用して期間を指定できます。
ヒント2.GCPが請求するGoogle広告アカウントの数を確認する場合は、クエリを使用してCustomerテーブルのExternalCustomerIDの数を決定する必要があります。
SELECT ExternalCustomerId FROM `project_name.dataset_name.Customer_*` WHERE _PARTITIONTIME >= "2020-01-01 00:00:00" AND _PARTITIONTIME < "2020-07-10 00:00:00" group by 1
SELECT ExternalCustomerId FROM `project_name.dataset_name.Customer_*` WHERE _PARTITIONTIME >= "2020-01-01 00:00:00" AND _PARTITIONTIME < "2020-07-10 00:00:00" group by 1クエリで日付を編集できます。
ヒント3.SQLクエリを使用して、アップロードされたデータに自分でアクセスできます。 たとえば、ここでは、データ転送から派生した「Campaign」テーブルと「CampaignBasicStats」テーブルからキャンペーンの有効性を判断するためのクエリを示します。
SELECT {source language="sql"} c.ExternalCustomerId, c.CampaignName, c.CampaignStatus, SUM(cs.Impressions) AS Impressions, SUM(cs.Interactions) AS Interactions, {/source} (SUM(cs.Cost) / 1000000) AS Cost FROM `[DATASET].Campaign_[CUSTOMER_ID]` c LEFT JOIN {source language="sql"} {source language="sql"} `[DATASET].CampaignBasicStats_[CUSTOMER_ID]` cs ON (c.CampaignId = cs.CampaignId AND cs._DATA_DATE BETWEEN DATE_ADD(CURRENT_DATE(), INTERVAL -31 DAY) AND DATE_ADD(CURRENT_DATE(), INTERVAL -1 DAY)) WHERE c._DATA_DATE = c._LATEST_DATE GROUP BY 1, 2, 3 ORDER BY Impressions DESC
SELECT {source language="sql"} c.ExternalCustomerId, c.CampaignName, c.CampaignStatus, SUM(cs.Impressions) AS Impressions, SUM(cs.Interactions) AS Interactions, {/source} (SUM(cs.Cost) / 1000000) AS Cost FROM `[DATASET].Campaign_[CUSTOMER_ID]` c LEFT JOIN {source language="sql"} {source language="sql"} `[DATASET].CampaignBasicStats_[CUSTOMER_ID]` cs ON (c.CampaignId = cs.CampaignId AND cs._DATA_DATE BETWEEN DATE_ADD(CURRENT_DATE(), INTERVAL -31 DAY) AND DATE_ADD(CURRENT_DATE(), INTERVAL -1 DAY)) WHERE c._DATA_DATE = c._LATEST_DATE GROUP BY 1, 2, 3 ORDER BY Impressions DESC PS Google BigQueryへのデータのアップロードとマージについてサポートが必要な場合は、いつでもサポートいたします。 デモにサインアップします—詳細について説明します。