
Google의 BigQuery 데이터 구조: 클라우드 스토리지를 시작하는 방법
게시 됨: 2022-04-12Google BigQuery는 하나의 시스템에서 모든 데이터를 수집하고 SQL 쿼리를 사용하여 쉽게 분석할 수 있는 클라우드 스토리지 서비스입니다. 데이터 작업이 편리하려면 올바르게 구성되어야 합니다. 이 기사에서는 Google BigQuery에 업로드할 테이블과 데이터세트를 만드는 방법을 설명합니다.
목차
- 데이터 세트: 정의 및 생성 방법
- Google BigQuery에 데이터를 로드하기 위해 테이블을 추가하는 방법
- 테이블 스키마를 변경하는 방법
- Google BigQuery에서 데이터 내보내기 및 가져오기
- OWOX BI의 애드온을 사용하여 데이터 내보내기 및 가져오기
- Google BigQuery에서 데이터를 수집하는 이유는 무엇인가요?

최고의 OWOX BI 마케팅 사례
다운로드데이터 세트: 정의 및 생성 방법
Google BigQuery를 사용하려면 Google Cloud Platform(GCP)에서 프로젝트를 생성해야 합니다. 등록하면 무료 평가판 기간 동안 모든 Cloud Platform 제품에 액세스할 수 있으며 향후 12개월 이내에 이러한 제품에 사용할 수 있는 $300가 제공됩니다.
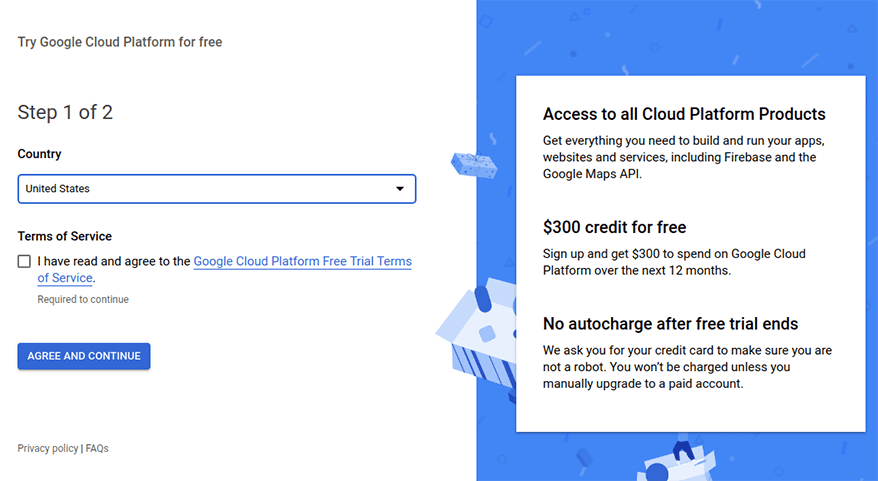
Google Cloud Platform에서 프로젝트를 만든 후 Google BigQuery에 데이터세트를 하나 이상 추가해야 합니다.
데이터세트는 데이터에 대한 액세스를 구성하고 제어하는 데 사용되는 최상위 컨테이너입니다. 간단히 말해서 정보가 테이블과 뷰의 형태로 저장되는 일종의 폴더입니다.
GCP에서 프로젝트를 열고 BigQuery 탭으로 이동한 다음 데이터세트 만들기 를 클릭합니다.
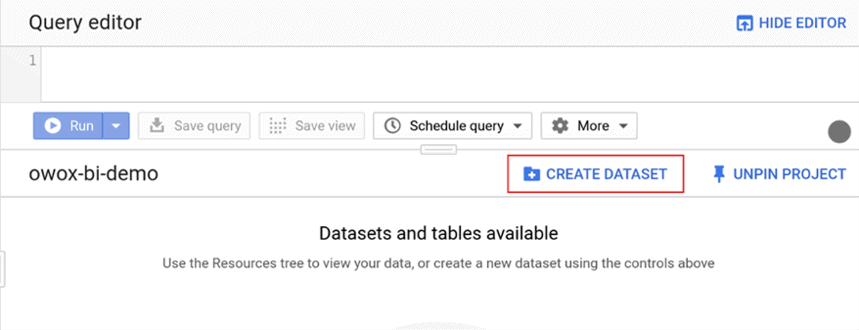
열리는 창에서 데이터 세트의 이름과 테이블의 저장 수명을 지정합니다. 데이터가 있는 테이블이 자동으로 삭제되도록 하려면 정확히 언제를 지정합니다. 또는 테이블을 수동으로만 삭제할 수 있도록 기본 영구 옵션 을 그대로 둡니다.
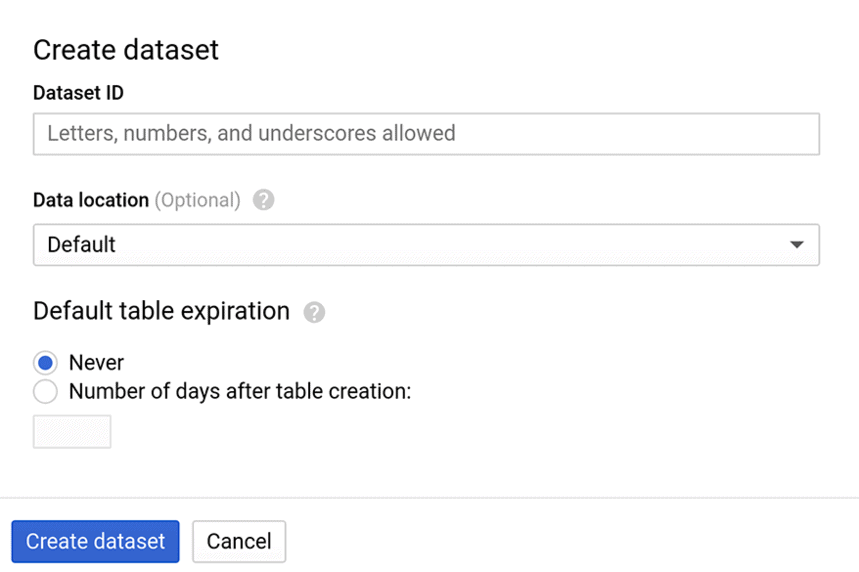
처리 사이트 필드는 선택 사항입니다. 기본적으로 미국 다중 지역으로 설정되어 있습니다. 도움말 섹션에서 데이터 저장 영역에 대한 자세한 정보를 찾을 수 있습니다.
Google BigQuery에 데이터를 로드하기 위해 테이블을 추가하는 방법
데이터 세트를 생성한 후 데이터를 수집할 테이블을 추가해야 합니다. 테이블은 행의 집합입니다. 각 행은 필드라고도 하는 열로 구성됩니다. 데이터 소스에 따라 BigQuery에서 테이블을 만드는 방법에는 여러 가지가 있습니다.
- 수동으로 빈 테이블을 만들고 이에 대한 데이터 스키마 설정
- 이전에 계산된 SQL 쿼리의 결과를 사용하여 테이블 생성
- 컴퓨터에서 파일 업로드(CSV, AVRO, JSON, Parquet, ORC 또는 Google 스프레드시트 형식)
- 데이터를 다운로드하거나 스트리밍하는 대신 Cloud Bigtable, Cloud Storage 또는 Google 드라이브와 같은 외부 소스를 참조하는 테이블을 만들 수 있습니다.
이 기사에서는 첫 번째 방법인 수동으로 테이블을 만드는 방법을 자세히 살펴보겠습니다.
1단계 . 테이블을 추가할 데이터세트를 선택한 다음 테이블 생성 을 클릭합니다.
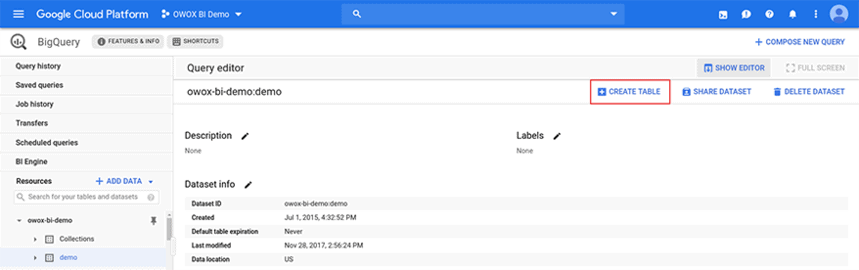
단계 2. 소스 필드에서 빈 테이블 을 선택하고 테이블 유형 필드 에서 대상 개체의 기본 형식으로 테이블을 선택합니다. 테이블의 이름을 생각해 보세요.
중요 : 데이터 세트, 테이블 및 필드의 이름은 라틴 문자여야 하며 문자, 숫자 및 밑줄만 포함해야 합니다.
3단계 . 테이블 스키마를 지정합니다. 스키마는 4개의 구성요소로 구성됩니다. 두 개의 필수 구성요소(열 이름 및 데이터 유형)와 두 개의 선택적 구성요소(열 모드 및 설명). 적절하게 선택된 유형과 필드 모드는 데이터 작업을 용이하게 합니다.
BigQuery의 예시 스키마:
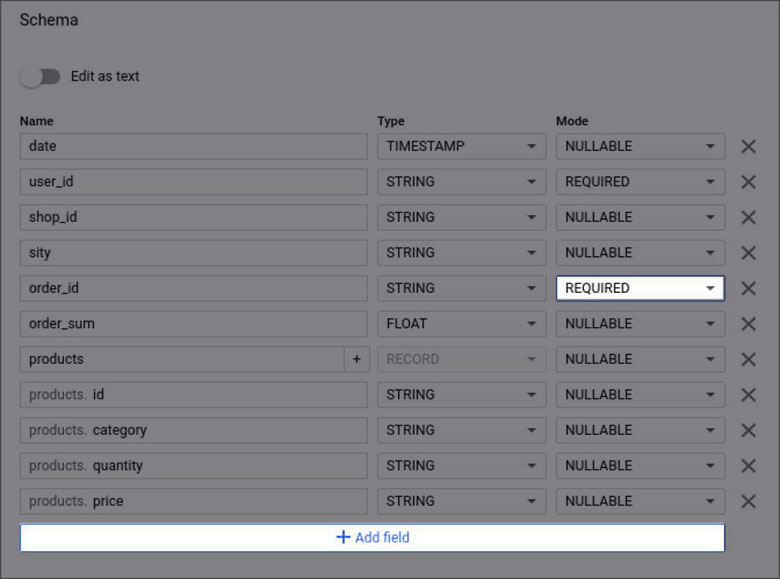
열 이름
열 이름에서 각 열이 담당하는 매개변수(날짜, user_id, 제품 등)를 지정해야 합니다. 제목에는 라틴 문자, 숫자 및 밑줄만 포함될 수 있습니다(최대 128자). 대소문자가 다르더라도 동일한 필드 이름은 허용되지 않습니다.
데이터 유형
BigQuery에서 테이블을 만들 때 다음 필드 유형을 사용할 수 있습니다.
모드
BigQuery는 테이블 열에 대해 다음 모드를 지원합니다.
참고 : 모드 필드를 채울 필요는 없습니다. 모드가 지정되지 않은 경우 기본 열은 NULLABLE입니다.
열 설명
원하는 경우 특정 매개변수의 의미를 설명하기 위해 테이블의 각 열에 대한 간단한 설명(1024자 이하)을 추가할 수 있습니다.
BigQuery에서 빈 테이블을 생성할 때 스키마를 수동으로 설정해야 합니다. 이는 두 가지 방법으로 수행할 수 있습니다.
1. 필드 추가 버튼을 클릭하고 각 열의 이름, 유형 및 모드를 입력합니다.
2. 텍스트로 편집 스위치를 사용하여 테이블 스키마를 JSON 배열로 입력합니다.
또한 Google BigQuery는 CSV 및 JSON 파일에서 데이터를 로드할 때 자동 스키마 감지를 사용할 수 있습니다.
이 옵션은 다음 원칙에 따라 작동합니다. BigQuery는 지정한 소스에서 임의의 파일을 선택하고 그 안에 있는 데이터의 최대 100행을 스캔하고 그 결과를 대표 샘플로 사용합니다. 그런 다음 업로드된 파일의 각 필드를 확인하고 샘플의 값을 기반으로 데이터 유형을 할당하려고 시도합니다.
Google 파일을 로드할 때 BigQuery는 열 이름을 변경하여 자체 SQL 구문과 호환되도록 할 수 있습니다. 따라서 영어 필드 이름이 있는 테이블을 업로드하는 것이 좋습니다. 예를 들어 이름이 러시아어인 경우 시스템에서 자동으로 이름을 변경합니다. 예를 들어:
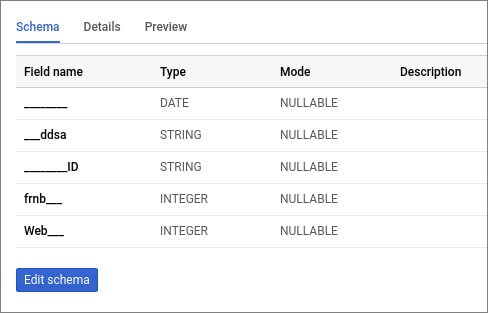
데이터를 로드할 때 열 이름을 잘못 입력했거나 기존 테이블의 열 이름과 유형을 변경하려는 경우 수동으로 수행할 수 있습니다. 방법을 알려드리겠습니다.
테이블 스키마를 변경하는 방법
Google BigQuery에 데이터를 로드한 후 테이블 레이아웃이 원본과 약간 다를 수 있습니다. 예를 들어 BigQuery에서 지원되지 않는 문자로 인해 필드 이름이 변경되었거나 필드 유형이 STRING 대신 INTEGER일 수 있습니다. 이 경우 스키마를 수동으로 조정할 수 있습니다.
열 이름을 변경하는 방법
SQL 쿼리를 사용하여 테이블의 모든 열을 선택하고 이름을 바꾸려는 열의 새 이름을 지정합니다. 이 경우 기존 테이블을 덮어쓰거나 새 테이블을 생성할 수 있습니다. 요청 예시:
#legacySQL Select date, order_id, order___________ as order_type, -- new field name product_id from [project_name:dataset_name.owoxbi_sessions_20190314]
#legacySQL Select date, order_id, order___________ as order_type, -- new field name product_id from [project_name:dataset_name.owoxbi_sessions_20190314]
#standardSQL Select * EXCEPT (orotp, ddat), orotp as order_id, ddat as date from `project_name.dataset_name.owoxbi_sessions_20190314`
#standardSQL Select * EXCEPT (orotp, ddat), orotp as order_id, ddat as date from `project_name.dataset_name.owoxbi_sessions_20190314`스키마에서 데이터 유형을 변경하는 방법
SQL 쿼리를 사용하여 테이블에서 모든 데이터를 선택하고 해당 열을 다른 데이터 유형으로 변환합니다. 쿼리 결과를 사용하여 기존 테이블을 덮어쓰거나 새 테이블을 생성할 수 있습니다. 요청 예:

#standardSQL Select CAST (order_id as STRING) as order_id, CAST (date as TIMESTAMP) as date from `project_name.dataset_name.owoxbi_sessions_20190314`
#standardSQL Select CAST (order_id as STRING) as order_id, CAST (date as TIMESTAMP) as date from `project_name.dataset_name.owoxbi_sessions_20190314`열 모드를 변경하는 방법
도움말 문서에 설명된 대로 열 모드를 REQUIRED에서 NULLABLE로 변경할 수 있습니다. 두 번째 옵션은 데이터를 Cloud Storage로 내보낸 다음 모든 열에 대해 올바른 모드로 BigQuery로 데이터를 반환하는 것입니다.
데이터 스키마에서 열을 제거하는 방법
SELECT * EXCEPT 쿼리를 사용하여 열을 제외하고 쿼리 결과를 이전 테이블에 쓰거나 새 테이블을 만듭니다. 요청 예:
#standardSQL Select * EXCEPT (order_id) from `project_name.dataset_name.owoxbi_sessions_20190314`
#standardSQL Select * EXCEPT (order_id) from `project_name.dataset_name.owoxbi_sessions_20190314` 또한 위에서 설명한 모든 작업에 적합한 스키마를 변경하는 두 번째 방법이 있습니다. 데이터를 내보내고 새 테이블에 로드하는 것입니다. 열 이름을 바꾸려면 BigQuery에서 Cloud Storage로 데이터를 업로드한 다음 새 테이블의 Cloud Storage에서 BigQuery로 내보내거나 고급 매개변수를 사용하여 이전 테이블의 데이터를 덮어쓸 수 있습니다.
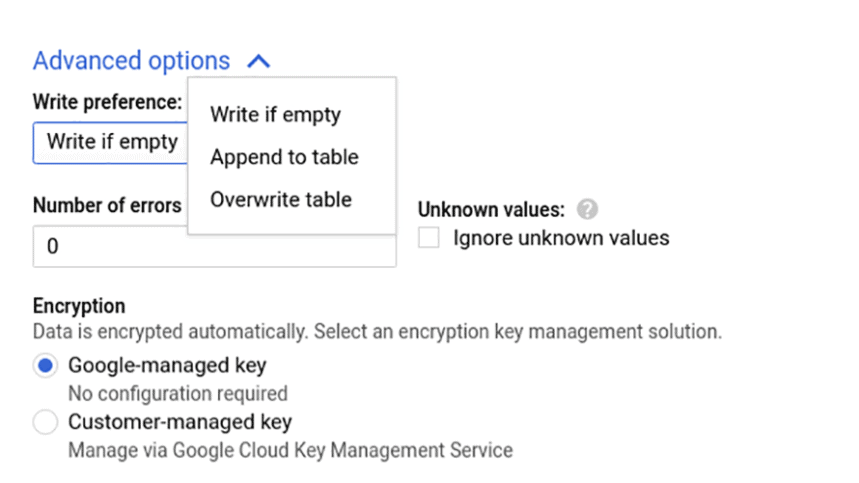
Google Cloud Platform 도움말 문서에서 테이블 구조를 변경하는 다른 방법을 읽을 수 있습니다.
Google BigQuery에서 데이터 내보내기 및 가져오기
인터페이스나 OWOX BI의 특수 애드온을 통해 개발자의 도움 없이 BigQuery에서 데이터를 다운로드하거나 BigQuery에 업로드할 수 있습니다. 각 방법을 자세히 살펴 보겠습니다.
Google BigQuery 인터페이스를 통해 데이터 가져오기
필요한 정보(예: 사용자 및 오프라인 주문에 대한 데이터)를 저장소에 업로드하려면 데이터세트를 열고 테이블 만들기를 클릭한 다음 데이터 소스(Cloud Storage, 컴퓨터, Google 드라이브 또는 Cloud Bigtable)를 선택합니다. 파일 경로, 형식 및 데이터가 로드될 테이블 이름을 지정합니다.
테이블 생성을 클릭하면 데이터세트에 테이블이 나타납니다.
Google BigQuery 인터페이스를 통해 데이터 내보내기
BigQuery에서 처리된 데이터를 업로드하는 것도 가능합니다. 예를 들어 시스템 인터페이스를 통해 보고서를 생성할 수 있습니다. 이렇게 하려면 데이터가 있는 원하는 테이블을 열고 내보내기 버튼을 클릭합니다.
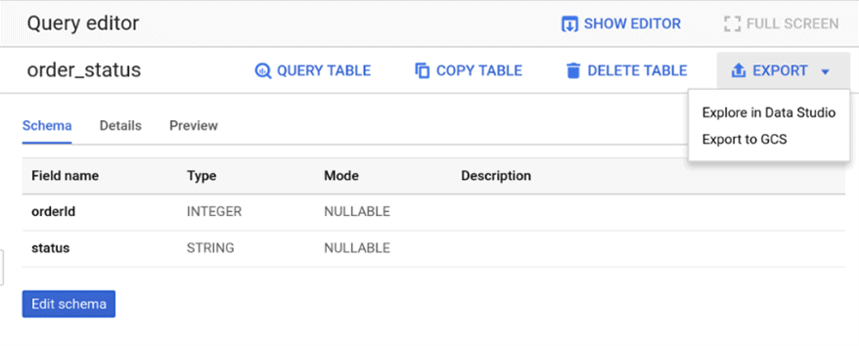
시스템은 Google 데이터 스튜디오에서 데이터를 보거나 Google Cloud Storage에 업로드하는 두 가지 옵션을 제공합니다. 첫 번째 옵션을 선택하면 보고서를 저장할 수 있는 데이터 스튜디오로 즉시 이동합니다.
Google Cloud Storage로 내보내기를 선택하면 새 창이 열립니다. 그 안에 데이터를 저장할 위치와 형식을 지정해야 합니다.
OWOX BI의 애드온을 사용하여 데이터 내보내기 및 가져오기
무료 OWOX BI BigQuery 보고서 추가 기능을 사용하면 Google BigQuery에서 Google 스프레드시트로 또는 그 반대로 직접 데이터를 빠르고 편리하게 전송할 수 있습니다. 따라서 CSV 파일을 준비하거나 유료 타사 서비스를 사용할 필요가 없습니다.
예를 들어 오프라인 주문 데이터를 BigQuery에 업로드하여 ROPO 보고서를 작성한다고 가정해 보겠습니다. 이를 위해 다음을 수행해야 합니다.
- 브라우저에 BigQuery 보고서 부가기능을 설치합니다.
- Google 스프레드시트에서 데이터 파일을 열고 추가 기능 탭에서 OWOX BI BigQuery 보고서 → BigQuery에 데이터 업로드를 선택합니다.
- 열리는 창에서 BigQuery의 프로젝트와 데이터세트를 선택하고 원하는 테이블 이름을 입력합니다. 또한 값을 로드할 필드를 선택하십시오. 기본적으로 모든 필드의 유형은 STRING이지만 컨텍스트에 따라 데이터 유형을 선택하는 것이 좋습니다(예: 숫자 식별자가 있는 필드의 경우 INTEGER를 선택하고 가격의 경우 FLOAT를 선택).
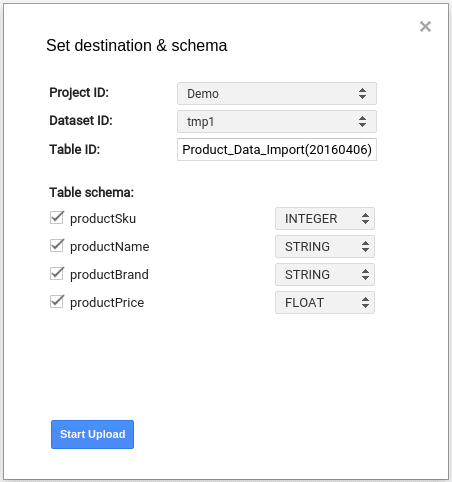
- 업로드 시작 버튼을 클릭하면 데이터가 Google BigQuery에 로드됩니다.
이 부가기능을 사용하여 BigQuery에서 Google 스프레드시트로 데이터를 내보낼 수도 있습니다. 예를 들어 데이터를 시각화하거나 BigQuery에 액세스할 수 없는 동료와 공유할 수 있습니다. 이를 위해:
- Google 스프레드시트를 엽니다. 추가 기능 탭에서 OWOX BI BigQuery 보고서 → 새 보고서 추가를 선택합니다.
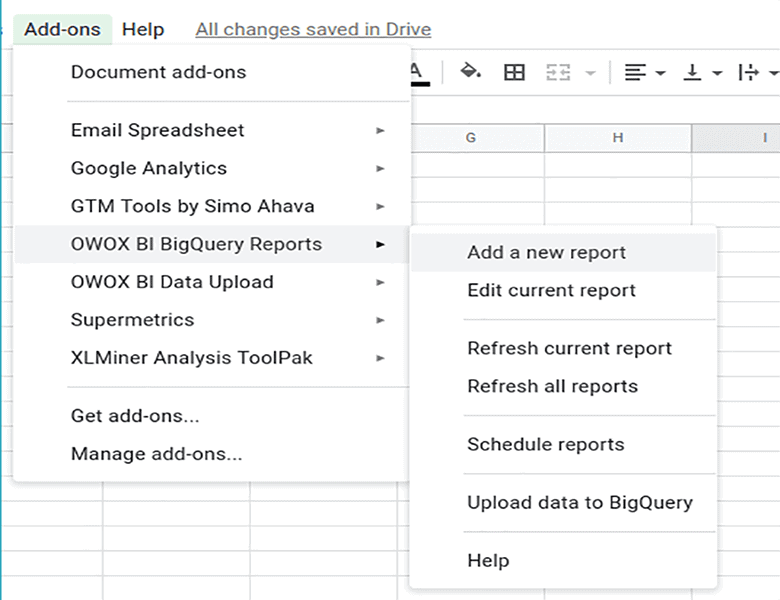
- 그런 다음 Google BigQuery에 프로젝트를 입력하고 새 쿼리 추가를 선택합니다.
- 새 창에서 SQL 쿼리를 삽입합니다. 이는 테이블에서 BigQuery로 데이터를 업로드하는 쿼리이거나 필요한 데이터를 가져와 계산하는 쿼리일 수 있습니다.
- 저장 및 실행 버튼을 클릭하여 쿼리를 쉽게 찾고 실행할 수 있도록 쿼리 이름을 바꿉니다.
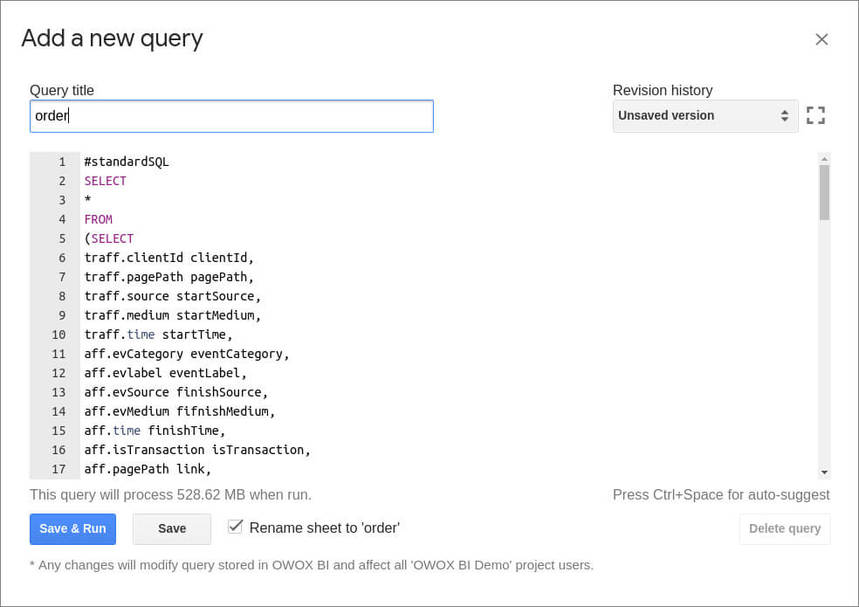
정기적으로 BigQuery에서 Google 스프레드시트로 데이터를 업로드하려면 예약된 데이터 업데이트를 사용 설정하면 됩니다.
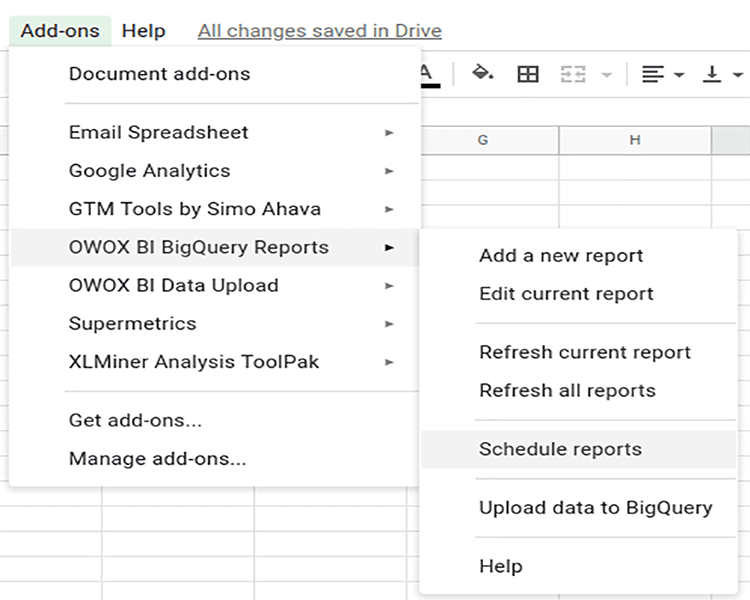
- 추가 기능 탭에서 OWOX BI BigQuery 보고서 → 보고서 예약 을 선택합니다.
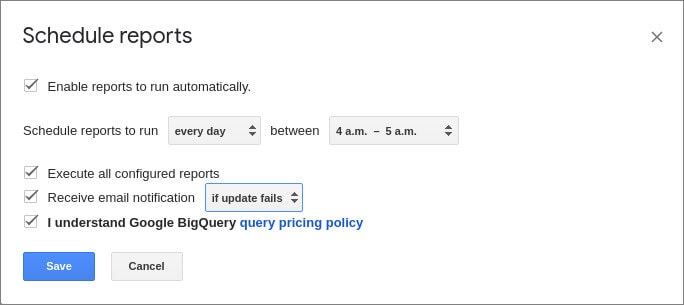
- 열리는 창에서 보고서 업데이트 시간과 빈도를 설정하고 저장 을 클릭합니다.
Google BigQuery에서 데이터를 수집하는 이유는 무엇인가요?
Google BigQuery 클라우드 스토리지의 이점을 아직 이해하지 못했다면 사용해 보는 것이 좋습니다. OWOX BI의 도움으로 웹사이트, 광고 소스, 내부 CRM 시스템의 데이터를 BigQuery로 결합하여 다음을 수행할 수 있습니다.
- 엔드 투 엔드 분석을 설정하고 오프라인 주문, 반품 및 구매에 이르는 모든 사용자 단계를 고려하여 마케팅의 실제 수익을 찾으십시오.
- 모든 매개변수 및 지표를 사용하여 샘플링되지 않은 완전한 데이터에 대한 보고서를 생성합니다.
- 코호트 분석을 사용하여 고객 획득 채널을 평가합니다.
- 온라인 광고가 오프라인 판매에 어떤 영향을 미치는지 알아보십시오.
- 광고 비용의 몫을 줄이고 고객의 수명 주기를 연장하며 전체 고객 기반의 LTV를 높입니다.
- 활동에 따라 고객을 분류하고 고객과의 커뮤니케이션을 개인화합니다.
OWOX BI는 서비스의 모든 기능을 사용할 수 있는 무료 평가판 기간이 있습니다.