
GoogleのBigQueryデータ構造:クラウドストレージの使用を開始する方法
公開: 2022-04-12Google BigQueryは、すべてのデータを1つのシステムに収集し、SQLクエリを使用して簡単に分析できるクラウドストレージサービスです。 データを操作しやすくするには、データを正しく構造化する必要があります。 この記事では、GoogleBigQueryにアップロードするためのテーブルとデータセットを作成する方法について説明します。
目次
- データセット:データセットとは何か、データセットの作成方法
- データをGoogleBigQueryに読み込むためのテーブルを追加する方法
- テーブルスキーマを変更する方法
- GoogleBigQueryとの間でデータをエクスポートおよびインポートする
- OWOXBIのアドオンを使用してデータをエクスポートおよびインポートします
- なぜGoogleBigQueryでデータを収集するのですか?

最高のOWOXBIマーケティングケース
ダウンロードデータセット:データセットとは何か、データセットの作成方法
Google BigQueryを使用するには、Google Cloud Platform(GCP)でプロジェクトを作成する必要があります。 登録すると、無料試用期間中にすべてのクラウドプラットフォーム製品にアクセスでき、今後12か月以内にこれらの製品に300ドルを費やすことができます。
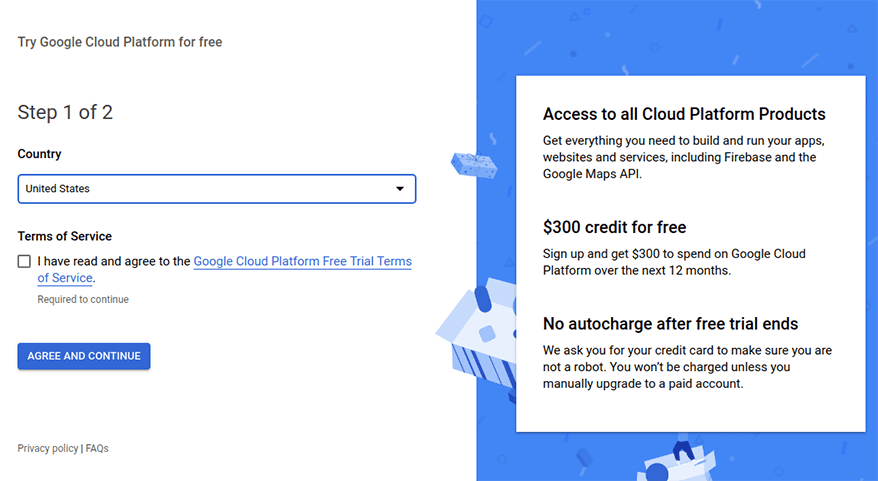
Google Cloud Platformでプロジェクトを作成したら、少なくとも1つのデータセットをGoogleBigQueryに追加する必要があります。
データセットは、データへのアクセスを整理および制御するために使用される最上位のコンテナです。 簡単に言えば、それはあなたの情報がテーブルとビューの形で保存される一種のフォルダです。
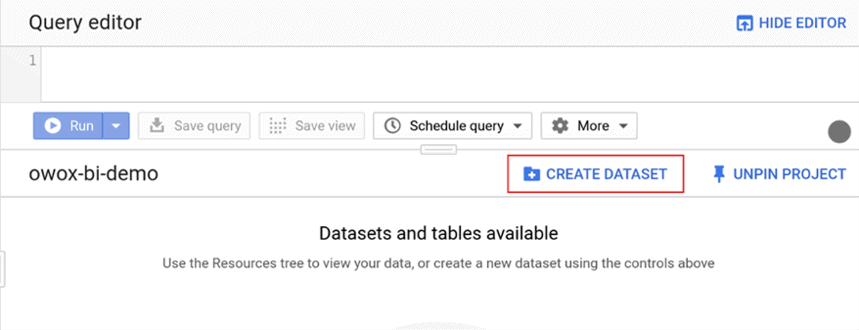
GCPでプロジェクトを開き、[ BigQuery ]タブに移動して、[データセットの作成]をクリックします。
開いたウィンドウで、データセットの名前とテーブルの有効期間を指定します。 データを含むテーブルを自動的に削除する場合は、正確なタイミングを指定してください。 または、デフォルトのPerpetualオプションをそのままにして、テーブルを手動でのみ削除できるようにします。
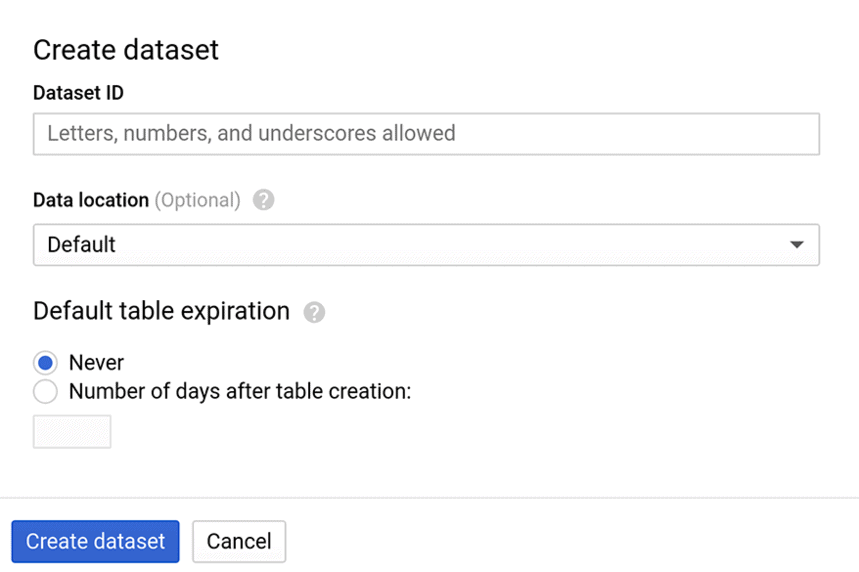
処理サイトフィールドはオプションです。 デフォルトでは、USマルチリージョンに設定されています。 データを保存するためのリージョンの詳細については、ヘルプセクションを参照してください。
データをGoogleBigQueryに読み込むためのテーブルを追加する方法
データセットを作成した後、データが収集されるテーブルを追加する必要があります。 テーブルは行のセットです。 各行は、フィールドとも呼ばれる列で構成されます。 データソースに応じて、BigQueryでテーブルを作成する方法はいくつかあります。
- 空のテーブルを手動で作成し、そのデータスキーマを設定します
- 以前に計算されたSQLクエリの結果を使用してテーブルを作成します
- コンピューターからファイルをアップロードします(CSV、AVRO、JSON、Parquet、ORC、またはGoogle Sheets形式)
- データをダウンロードまたはストリーミングする代わりに、外部ソース(Cloud Bigtable、Cloud Storage、またはGoogleドライブ)を参照するテーブルを作成できます。
この記事では、最初の方法である手動でテーブルを作成する方法について詳しく見ていきます。
ステップ1 。 テーブルを追加するデータセットを選択し、[テーブルの作成]をクリックします。
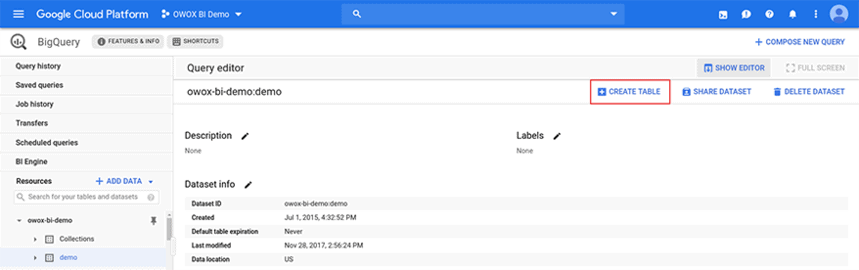
ステップ2. 「ソース」フィールドで「空のテーブル」を選択し、「テーブル・タイプ」フィールドで、ターゲット・オブジェクトのネイティブ形式の「テーブル」を選択します。 テーブルの名前を思い付く。
重要:データセット、テーブル、およびフィールドの名前はラテン文字である必要があり、文字、数字、およびアンダースコアのみが含まれている必要があります。
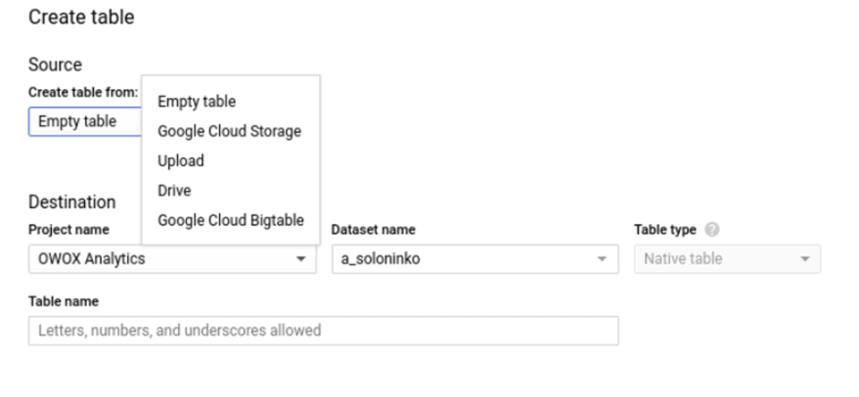
ステップ3 。 テーブルスキーマを指定します。 スキーマは4つのコンポーネントで構成されています。2つは必須(列名とデータ型)、2つはオプション(列モードと説明)です。 適切に選択されたタイプとフィールドモードは、データの操作を容易にします。
BigQueryのスキーマの例:
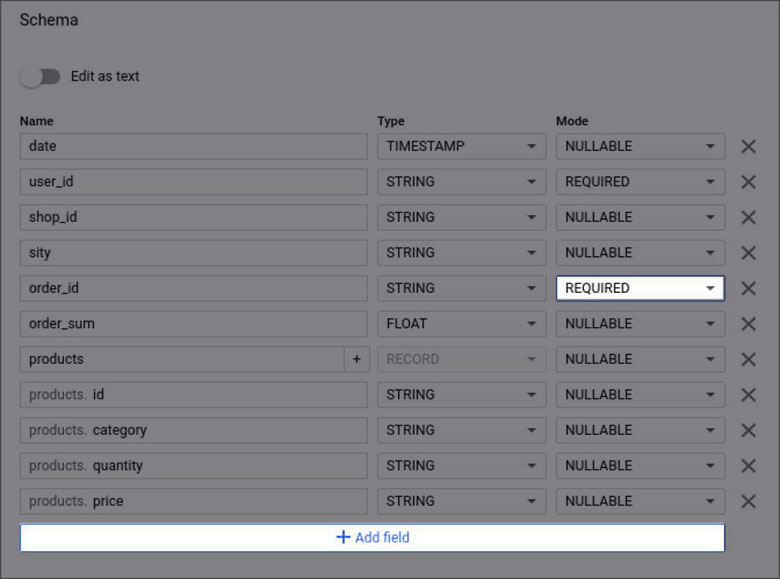
列名
列名には、各列が担当するパラメーター(date、user_id、productsなど)を指定する必要があります。タイトルには、ラテン文字、数字、およびアンダースコア(最大128文字)のみを含めることができます。 大文字と小文字が異なっていても、同じフィールド名は使用できません。
1
データ型
BigQueryでテーブルを作成する場合、次のフィールドタイプを使用できます。
モード
BigQueryは、テーブル列に対して次のモードをサポートしています。
注:[モード]フィールドに入力する必要はありません。 モードが指定されていない場合、デフォルトの列はNULL可能です。
列の説明
必要に応じて、特定のパラメーターの意味を説明するために、テーブルの各列に簡単な説明(1024文字以下)を追加できます。
BigQueryで空のテーブルを作成する場合は、スキーマを手動で設定する必要があります。 これは、次の2つの方法で実行できます。
1. [フィールドの追加]ボタンをクリックして、各列の名前、タイプ、およびモードを入力します。
2. [テキストとして編集]スイッチを使用して、テーブルスキーマをJSON配列として入力します。
さらに、Google BigQueryは、CSVファイルとJSONファイルからデータを読み込むときに自動スキーマ検出を使用できます。
このオプションは、次の原則に基づいて機能します。BigQueryは、指定したソースからランダムファイルを選択し、その中の最大100行のデータをスキャンし、その結果を代表的なサンプルとして使用します。 次に、アップロードされたファイルの各フィールドをチェックし、サンプルの値に基づいてデータ型を割り当てようとします。
Googleファイルを読み込むときに、BigQueryは列の名前を変更して、独自のSQL構文と互換性を持たせることができます。 したがって、英語のフィールド名を持つテーブルをアップロードすることをお勧めします。 たとえば、名前がロシア語の場合、システムは自動的に名前を変更します。 例えば:
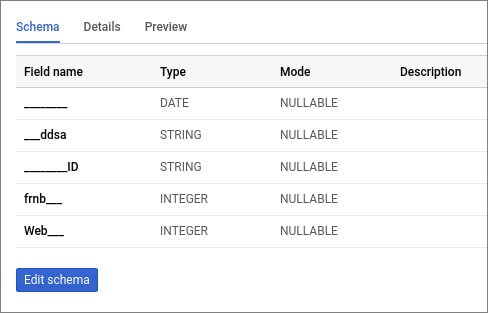
データのロード時に列の名前が正しく入力されていない場合、または既存のテーブルの列の名前とタイプを変更する場合は、手動でこれを行うことができます。 その方法をお教えします。
テーブルスキーマを変更する方法
Google BigQueryにデータを読み込んだ後、テーブルのレイアウトが元のレイアウトと少し異なる場合があります。 たとえば、BigQueryでサポートされていない文字が原因でフィールド名が変更された場合や、フィールドタイプがSTRINGではなくINTEGERである場合があります。 この場合、スキーマを手動で調整できます。
列名を変更する方法
SQLクエリを使用して、テーブル内のすべての列を選択し、名前を変更する列の新しい名前を指定します。 この場合、既存のテーブルを上書きするか、新しいテーブルを作成できます。 リクエストの例:
#legacySQL Select date, order_id, order___________ as order_type, -- new field name product_id from [project_name:dataset_name.owoxbi_sessions_20190314]
#legacySQL Select date, order_id, order___________ as order_type, -- new field name product_id from [project_name:dataset_name.owoxbi_sessions_20190314]
#standardSQL Select * EXCEPT (orotp, ddat), orotp as order_id, ddat as date from `project_name.dataset_name.owoxbi_sessions_20190314`
#standardSQL Select * EXCEPT (orotp, ddat), orotp as order_id, ddat as date from `project_name.dataset_name.owoxbi_sessions_20190314`スキーマのデータ型を変更する方法
SQLクエリを使用して、テーブルからすべてのデータを選択し、対応する列を別のデータ型に変換します。 クエリ結果を使用して、既存のテーブルを上書きしたり、新しいテーブルを作成したりできます。 リクエストの例:

#standardSQL Select CAST (order_id as STRING) as order_id, CAST (date as TIMESTAMP) as date from `project_name.dataset_name.owoxbi_sessions_20190314`
#standardSQL Select CAST (order_id as STRING) as order_id, CAST (date as TIMESTAMP) as date from `project_name.dataset_name.owoxbi_sessions_20190314`カラムモードを変更する方法
ヘルプドキュメントの説明に従って、列モードをREQUIREDからNULLABLEに変更できます。 2番目のオプションは、データをCloud Storageにエクスポートし、そこからすべての列に対して正しいモードでBigQueryに返すことです。
データスキーマから列を削除する方法
SELECT * EXCEPTクエリを使用して1つまたは複数の列を除外してから、クエリ結果を古いテーブルに書き込むか、新しいテーブルを作成します。 リクエストの例:
#standardSQL Select * EXCEPT (order_id) from `project_name.dataset_name.owoxbi_sessions_20190314`
#standardSQL Select * EXCEPT (order_id) from `project_name.dataset_name.owoxbi_sessions_20190314` さらに、上記のすべてのタスクに適したスキーマを変更する2つ目の方法があります。それは、データをエクスポートして新しいテーブルにロードすることです。 列の名前を変更するには、BigQueryからCloud Storageにデータをアップロードしてから、新しいテーブルのCloud StorageからBigQueryにエクスポートするか、詳細パラメータを使用して古いテーブルのデータを上書きします。
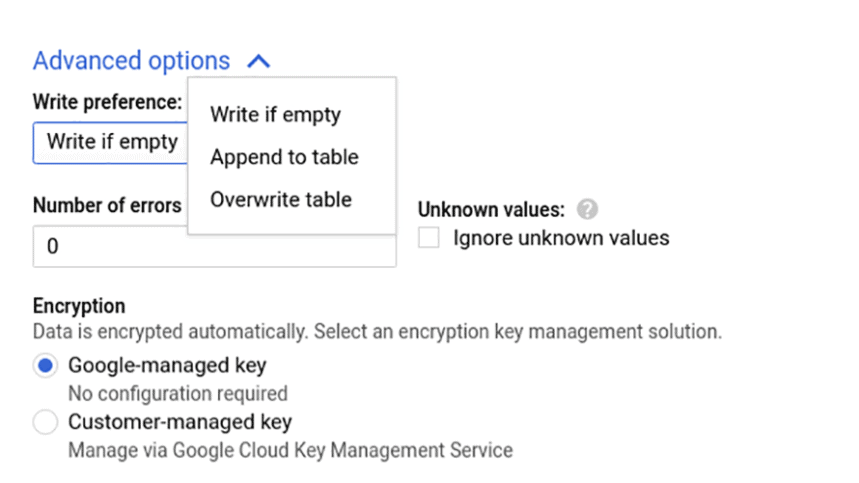
テーブル構造を変更する他の方法については、GoogleCloudPlatformのヘルプドキュメントをご覧ください。
GoogleBigQueryとの間でデータをエクスポートおよびインポートする
インターフェイスやOWOXBIの特別なアドオンを介して、開発者の助けを借りずにBigQueryからデータをダウンロードしたり、BigQueryにデータをアップロードしたりできます。 それぞれの方法を詳しく考えてみましょう。
GoogleBigQueryインターフェースを介してデータをインポートする
必要な情報(ユーザーやオフライン注文に関するデータなど)をストレージにアップロードするには、データセットを開き、[テーブルの作成]をクリックして、データソース(Cloud Storage、コンピューター、Googleドライブ、Cloud Bigtable)を選択します。 ファイルへのパス、その形式、およびデータがロードされるテーブルの名前を指定します。
[テーブルの作成]をクリックすると、データセットにテーブルが表示されます。
GoogleBigQueryインターフェースを介してデータをエクスポートする
BigQueryから処理済みデータをアップロードすることもできます。たとえば、システムインターフェースを介してレポートを作成できます。 これを行うには、データを含む目的のテーブルを開き、[エクスポート]ボタンをクリックします。
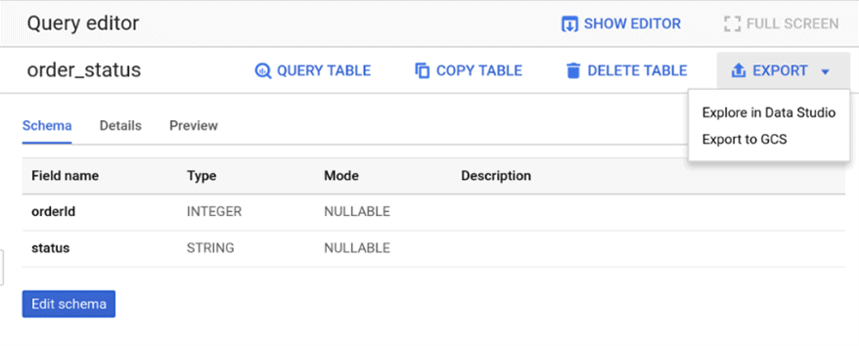
システムには2つのオプションがあります。GoogleDataStudioでデータを表示するか、GoogleCloudStorageにアップロードします。 最初のオプションを選択すると、すぐにデータスタジオに移動し、レポートを保存できます。
Google Cloud Storageにエクスポートすることを選択すると、新しいウィンドウが開きます。 その中で、データを保存する場所と形式を指定する必要があります。
OWOXBIのアドオンを使用してデータをエクスポートおよびインポートします
無料のOWOXBIBigQuery Reportsアドオンを使用すると、GoogleBigQueryからGoogleSheetsに、またはその逆にデータをすばやく簡単に転送できます。 したがって、CSVファイルを準備したり、有料のサードパーティサービスを使用したりする必要はありません。
たとえば、オフライン注文データをBigQueryにアップロードして、ROPOレポートを作成するとします。 このためには、次のことを行う必要があります。
- ブラウザにBigQueryReportsアドオンをインストールします。
- Googleスプレッドシートでデータファイルを開き、[アドオン]タブで、[ OWOXBIBigQueryレポート]→[BigQueryにデータをアップロード]を選択します。
- 開いたウィンドウで、BigQueryでプロジェクトとデータセットを選択し、テーブルに必要な名前を入力します。 また、値をロードするフィールドを選択します。 デフォルトでは、すべてのフィールドのタイプはSTRINGですが、コンテキストに応じてデータタイプを選択することをお勧めします(たとえば、数値識別子を持つフィールドの場合はINTEGERを選択し、価格の場合はFLOATを選択します)。
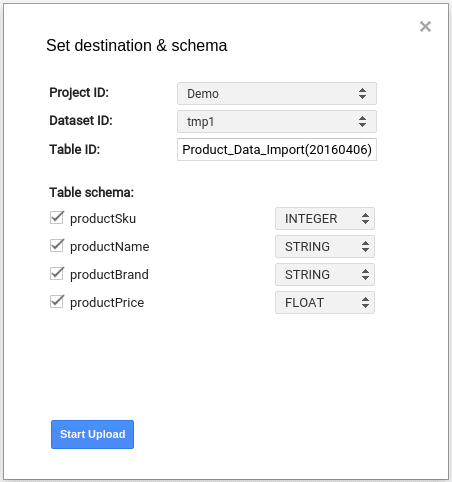
- [アップロードを開始]ボタンをクリックすると、データがGoogleBigQueryに読み込まれます
このアドオンを使用して、BigQueryからGoogleスプレッドシートにデータをエクスポートすることもできます。たとえば、データを視覚化したり、BigQueryにアクセスできない同僚と共有したりできます。 このため:
- Googleスプレッドシートを開きます。 [アドオン]タブで、[ OWOXBIBigQueryレポート]→[新しいレポートの追加]を選択します。
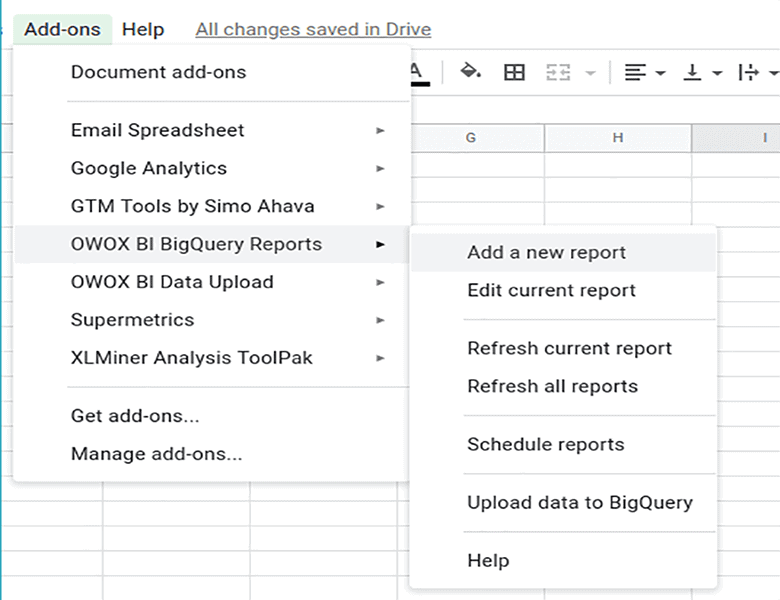
- 次に、プロジェクトをGoogle BigQueryに入力し、[新しいクエリを追加]を選択します。
- 新しいウィンドウで、SQLクエリを挿入します。 これは、テーブルからBigQueryにデータをアップロードするクエリ、または必要なデータを取得して計算するクエリの場合があります。
- [保存して実行]ボタンをクリックしてクエリを簡単に見つけて起動できるように、クエリの名前を変更します。
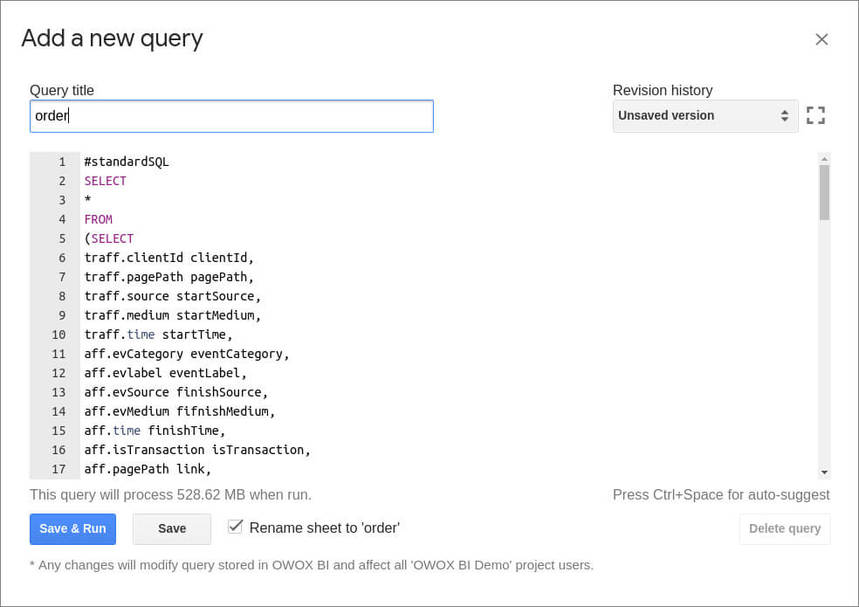
BigQueryからGoogleスプレッドシートに定期的にデータをアップロードするには、スケジュールされたデータ更新を有効にします。
- [アドオン]タブで、[ OWOX BIBigQueryレポート]→[レポートのスケジュール]を選択します。
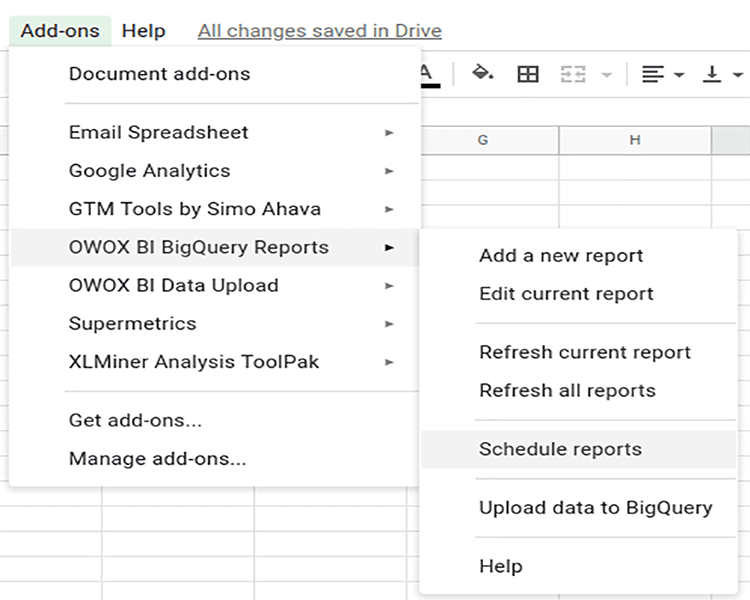
- 開いたウィンドウで、レポートの更新の時間と頻度を設定し、[保存]をクリックします:
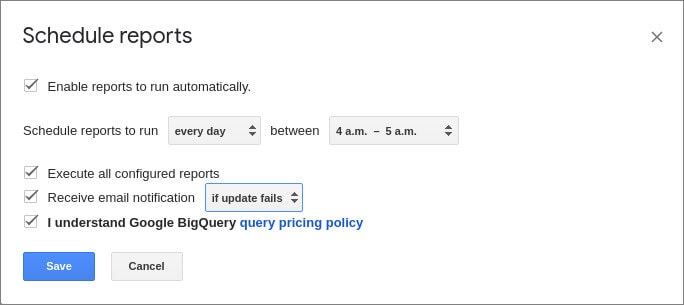
なぜGoogleBigQueryでデータを収集するのですか?
Google BigQueryクラウドストレージのメリットをまだ理解していない場合は、試してみることをお勧めします。 OWOX BIを使用すると、次の目的で、ウェブサイト、広告ソース、内部CRMシステムのデータをBigQueryに組み合わせることができます。
- エンドツーエンドの分析を設定し、オフライン注文、返品、および購入に至るまでのすべてのユーザーステップを考慮して、マーケティングの実際の収益を調べます。
- パラメータとインジケータを使用して、完全な非サンプリングデータに関するレポートを作成します。
- コホート分析を使用して顧客獲得チャネルを評価します。
- オンライン広告がオフライン販売にどのように影響するかをご覧ください。
- 広告費の割合を減らし、顧客のライフサイクルを延長し、顧客ベース全体のLTVを増やします。
- 活動に応じて顧客をセグメント化し、顧客とのコミュニケーションをパーソナライズします。
OWOX BIには、サービスのすべての機能を試すことができる無料の試用期間があります。