
什么是网页抓取以及如何操作?
已发表: 2022-06-04目录
- 什么是网页抓取?
- 为什么需要网页抓取?
- 网络抓取如何工作?
- 有哪些网络抓取最佳实践?
- 5个最好的网页抓取工具
- 享受抓取网页......小心!
如果您目前没有将网络抓取作为武器库的一部分,那么您肯定会错过一个在竞争中获得优势的巨大机会。
如果你和大多数销售人员一样,你总是在寻找竞争优势。 您想寻找新的潜在客户,加强与现有客户的关系,并更好地了解您的整个行业。
网络抓取可以帮助您完成所有这些事情,甚至更多。 想一想您希望获得位于某个城市的行业中所有公司的列表的所有时间。 或者,也许您想获取某个公司的所有联系人的列表。
网络抓取可以帮助您快速轻松地获取该信息。 但它是什么,它是如何工作的? 在这篇博文中,我们将回答这些问题以及更多问题。 因此,请继续阅读以了解有关此强大工具的所有信息!

什么是网页抓取?
想象一下,你必须整天看着这样的东西。 有趣,对吧……?
现在想象一下,如果有一种方法可以在几秒钟内对所有这些数据进行分类,从而得出一个有组织的集合。 这基本上就是抓取数据的内容。
简而言之,网络抓取是一种从网站中提取数据的方法。 它通常由计算机自动完成,但也可以手动完成。
有几种不同的方法可以做到这一点,但基本思想是加载一个网页,然后解析 HTML 代码以找到您想要的数据。 找到所需数据后,您可以将其保存到文件或数据库中以备后用。
网络抓取可用于多种任务,例如从在线商店获取所有产品名称和价格的列表,或从网络论坛中提取数据以查看人们对某个主题的看法。
网页抓取是免费的吗?
尽管有一些付费选项,但大多数网络抓取工具都是免费使用的。 付费选项通常提供更多功能并且更易于使用,但免费选项通常可以很好地完成工作。
小建议
网络抓取合法吗?
这是最常见的问题,答案是……视情况而定。 一般来说,从网站上抓取公共数据是完全可以的。 但是,如果您要抓取隐私数据(例如某人的联系信息),那么您可能会遇到一些法律问题。
这是一个常见的问题,答案是……这取决于。 一般来说,从网站上抓取公共数据是完全可以的。 但是,如果您要抓取隐私数据(例如某人的联系信息),那么您可能会遇到一些法律问题。
检查您正在抓取的网站的服务条款始终是一个好主意,以确保您没有违反任何规则。
在 LaGrowthMachine,我们使用多种数据源和不同技术开发了自己的抓取方法,这使我们能够拥有市场上最好的数据丰富功能之一。
我们在线索上恢复多达 28 个不同的数据项(始终遵循对 RGPD 友好的方法),这将允许您根据非常精确的变量进行自动化,并且在您的方法中非常自然。
虽然这种做法不是最近才出现的,但它往往变得更加普遍和广泛。
它已成为希望将效率和反应性结合起来的成长型营销人员和中小企业的重要资产。
好的,这就是大惊小怪的原因,但是网络抓取实际上如何使您的业务受益?
为什么需要网页抓取?
最明显的网络抓取优势是它可以为您节省大量时间。
想象一下,如果您每次想要进行市场调查时都必须从网站手动复制和粘贴数据。 这将需要永远! 但是通过网络抓取,您可以在几分钟内获得所需的所有数据。
另一个很大的优势是它可以帮助您获得难以或不可能以任何其他方式获得的数据。 例如,如果您想研究一个新市场,网络抓取可以帮助您快速轻松地获取该市场中所有公司的列表。
此外,网页抓取可用于各种任务,一些最常见的用途包括:
- 潜在客户生成:从网站上抓取数据可能是寻找新潜在客户的好方法。 例如,您可以从企业目录中抓取数据,以查找您所在行业中位于某个城市的所有公司。
- 市场研究:网络抓取可用于收集有关某个行业或市场的数据。 然后可以分析这些数据,以帮助您更好地了解整个市场。
- 竞争对手分析:密切关注您的竞争对手在任何业务中都很重要。 通过从他们的网站上抓取数据,您可以更好地了解他们的产品、定价和营销策略。
更进一步,利用抓取的数据,您可以在 LaGrowthMachine 中设置多渠道活动。
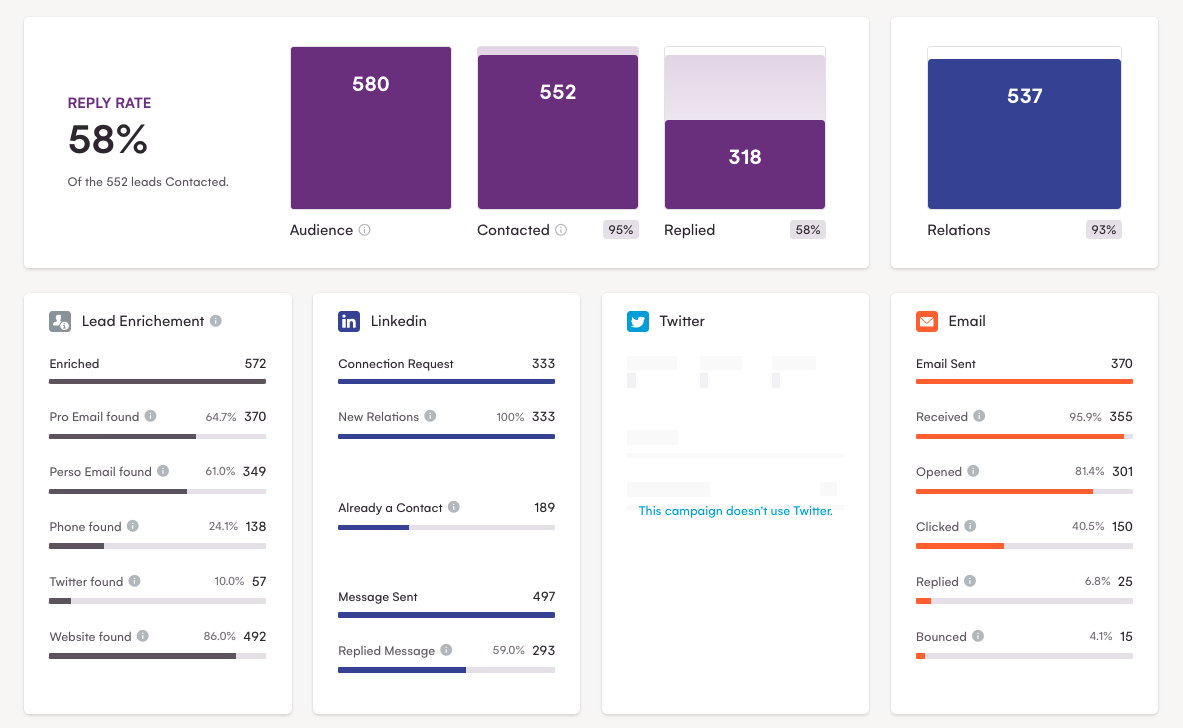
如您所见,这种方法非常成功,回复率几乎达到了 60%!
既然我们已经向您介绍了网络抓取并展示了它的一些好处,那么让我们来看看它是如何工作的基础知识。
网络抓取如何工作?
网页抓取通常由计算机自动完成,但也可以手动完成。
有几种不同的方法可以做到这一点,但基本思想是加载一个网页,然后解析 HTML 代码以找到您想要的数据。 找到所需数据后,您可以将其提取到文件或数据库中以备后用。
例如,假设您想从在线商店抓取数据以获取所有产品名称和价格的列表。
首先,您需要找到并加载要抓取的网页。
然后,您需要编写一些代码来解析网页的 HTML 代码并提取您感兴趣的数据。
最后,您需要将数据保存到文件或数据库中。
Web 抓取可以用多种编程语言完成,但最流行的是 Python、Java 和 PHP。
如果您刚刚开始使用网络抓取,我们建议您使用 ParseHub 或 Scrapy 之类的工具。 这些工具可以轻松地从网站上抓取数据,而无需编写任何代码。
有哪些网络抓取最佳实践?

既然您已经了解了网络抓取的基础知识,那么让我们来看看一些需要牢记的最佳实践。
检查服务条款
正如我们之前提到的,您需要检查您正在抓取的网站的服务条款。 这将确保您不会违反任何规则,并避免任何潜在的麻烦 - 法律或其他方面 - 在路上。 在抓取他们的网站之前获得网站所有者的许可也是一个好主意,因为一些网站管理员可能对此不太满意。
使用正确的工具
有多种不同的网络抓取工具可供使用,因此选择适合您需求的工具非常重要。
说到这里,LaGrowthMachine 就是其中之一!
我们将在本指南的后面部分介绍最佳网络抓取工具列表,但为了这一点,我们将仅提及一些最受欢迎的工具:
- Scrapy: Scrapy 是一个用 Python 编写的网页抓取框架。 它是最流行的工具之一,被谷歌、雅虎和 Facebook 等大牌使用。
- ParseHub: ParseHub 是一个支持多种语言和网络平台的网络爬虫。
- Octoparse: Octoparse 是另一个同时支持静态和动态网页的网络爬虫。
不要超载服务器
当您从网站上抓取数据时,重要的是不要让他们的服务器因过多的请求而过载。 这可能会导致您的 IP 地址被网站禁止访问。 为避免这种情况,请确保将您的请求分开,并且不要一次发出太多请求。

优雅地处理错误
您不可避免地会在某些时候遇到错误。 无论是关闭的网站还是不符合您预期格式的数据,在处理这些错误时保持耐心和温和的接触非常重要。 你不想冒险破坏任何东西,因为你太着急了。
定期查看您的数据
定期检查您的数据很重要。 有时,网页会发生变化,您提取的数据可能不再准确。 定期查看您的数据将有助于确保您始终获得准确的信息。
负责任地刮擦
尊重您正在抓取的网站非常重要。 这意味着不要抓取太多数据,不要过于频繁地抓取,也不要抓取敏感数据。 此外,请确保让您的抓取工具保持最新状态,以免无意中破坏您正在抓取的任何网站。
知道何时停止
有时您将无法从网站获取所需的数据。 发生这种情况时,重要的是要知道何时停止并继续前进。 不要浪费你的时间来强迫你的网络爬虫工作——还有其他网站有你需要的数据。
这些只是执行数据提取时要牢记的一些最佳实践。 遵循这些准则将有助于确保您获得积极的体验并避免任何潜在的问题。
5个最好的网页抓取工具

正如我们之前提到的,有各种各样的网络爬虫可用,从复杂的框架到简单的工具。 在本节中,我们将介绍一些最流行的抓取工具。
现在……我们已经提到了 Scrapy 和 ParseHub 等基本工具,所以我们将快速介绍其他一些工具。
Python
Python 是满足您的网络抓取需求的最明显的选择之一。 它是一种通用的脚本语言,可以很好地用于……数据抓取,以及广泛的其他任务。
使用 Python 的网页抓取软件的主要优点是它相对容易学习和使用。
此外,Python 具有广泛的库和模块,可用于 Web 数据提取,使其成为一个非常强大的工具。
一个缺点是 Python 网络爬虫可能会很慢,尤其是当它们试图爬取大量数据时。
此外,一些网站可能会阻止其访问,这意味着使用 Python 进行网页抓取通常比使用其他网页抓取工具更耗时且困难。
总体而言,使用 Python 进行网络数据提取既有优点也有缺点,但对于许多希望从网络上抓取数据的人来说,它仍然是一种流行的选择。
进口.io

这是一个网络数据提取工具,可让您从网站上抓取数据,而无需编写任何代码。 它是可用的最用户友好的网络抓取工具之一,而且还有一个好处:它非常适合初学者!
它包括很棒的功能,例如:
- 用户友好的点击式界面
- 从登录后抓取数据的能力
- 自动IP轮换以避免被禁止
import.io 之所以如此出色,是因为它可以从网站的多个页面中抓取数据。 如果您想从具有许多页面的大型网站中抓取数据,这将非常有用。 但是,这也意味着从包含大量页面的网站中抓取数据时可能会很慢。
import.io 的另一个优点是它可以从“难以”抓取的网站上抓取数据:这意味着它可以绕过网站用来防止抓取的一些保护机制。 也就是说,当网站更改其保护机制时,您将面临工具损坏的风险。
总的来说,import.io 是一个从网络快速收集数据的好工具,但重要的是要意识到它的局限性。
莫曾达

Mozenda 是另一个不需要任何编码的网络抓取工具。 它包括网页渲染、网页抓取和数据提取等功能。
这是一个很好的解决方案,因为它易于使用并且可以配置为从几乎任何网站上抓取数据。
使用 Mozenda 的主要优点之一是它非常快速和高效。 它可以非常快速轻松地处理大量数据。
此外,它非常人性化。 用户界面直观且易于使用。 还有大量在线资源可帮助您开始使用此工具进行网络抓取。
但是,主要缺点之一是它非常昂贵。 如果您只计划个人使用网络抓取,那么 Mozenda 可能不是您的最佳选择。
它也不总是完美的。 有时网站可能会更改其结构或设计,这可能会导致您的网页抓取出现问题。
Apify

作为一个网页抓取平台,Apify 使您能够将网站变成结构化数据。 它提供了广泛的功能,包括抓取动态网页、创建 API 和抓取整个网站的能力。
虽然 Apify 是一个强大的工具,但它有一些限制:
首先,它不是免费使用的,所以如果你现金短缺,它可能不是你的最佳选择。 设置和使用也可能具有挑战性,特别是对于不熟悉网络抓取的用户。
尽管如此,这是您可以使用的最具扩展性的网络爬虫之一。 该平台可以处理大规模的抓取,非常适合需要大规模收集数据的企业。
尽管如此,这种可扩展性也有一个缺点。 因为 Apify 可以处理如此大规模的抓取,所以它更容易出错,并且在抓取过程中可能会丢失一些数据。
总而言之,由于其灵活性和功能范围,Apify 仍然是一个流行的网络抓取平台。 如果您正在寻找一个易于使用且具有多种功能的网页抓取平台,Apify 可能是您的不错选择。
差异机器人

Diffbot 是一个网页抓取软件,它使用人工智能从网页中提取数据。 它提供了广泛的功能,包括大规模网络抓取、抓取网站以及从 JavaScript 网页中提取数据的能力。
使用 Diffbot 的主要优点是它非常精确。 该工具能够以高精度提取特定数据,这意味着您在使用该工具时不太可能遇到错误。 它还具有从多个页面抓取数据的能力以及处理 AJAX 请求的能力,这始终是一个优势。
此外,它非常人性化。 用户界面直观且易于使用,并且有大量在线资源可帮助您开始使用 Diffbot 进行网络抓取。
然而,Diffbot 的最大缺点之一是它非常昂贵,而且它无法从使用 JavaScript 加载内容的站点中抓取数据。
更重要的是,它还需要一个结构良好的网站,才能充分发挥其潜力。 如果没有,数据抓取过程可能会非常缓慢。
享受抓取网页......小心!
网络抓取是从网络收集数据的好方法。 它快速、高效且相对容易实现。 但是,在开始网络抓取之前,您需要注意一些事项。
首先,在某些情况下,网络抓取可能是非法的。 如果您计划出于商业目的进行网络抓取,则需要确保您拥有这样做的合法权利。
其次,网络抓取可能具有挑战性。 虽然有许多非常用户友好且不需要任何编码的网络抓取工具可用,但有些网站可能比其他网站更难抓取。
最后,网页抓取可能很耗时。 如果您计划对大型网站进行网络抓取,则可能需要一些时间才能获取所需的所有数据。
尽管如此,网络抓取可以成为快速有效地收集数据的好方法。 在开始网络抓取之前,请确保您了解所涉及的风险。
快乐刮!