
¿Qué es Web Scraping y cómo hacerlo?
Publicado: 2022-06-04Tabla de contenido
- ¿Qué es el web scraping?
- ¿Por qué necesita web scraping?
- ¿Cómo funciona el web scraping?
- ¿Cuáles son algunas de las mejores prácticas de web scraping?
- 5 de las mejores herramientas de web scraping
- Disfruta raspando la web... ¡con precaución!
Si actualmente no está utilizando web scraping como parte de su arsenal, definitivamente está dejando de lado una gran oportunidad para obtener una ventaja sobre su competencia.
Si es como la mayoría de los vendedores, siempre está buscando una ventaja sobre la competencia. Desea encontrar nuevos clientes potenciales, fortalecer las relaciones con los clientes actuales y obtener una mejor comprensión de su industria en su conjunto.
Web scraping puede ayudarlo a hacer todas esas cosas y más. Piense en todas las veces que desearía poder obtener una lista de todas las empresas de su industria que se encuentran en una determinada ciudad. O tal vez quería obtener una lista de todos los contactos de una determinada empresa.
Web scraping puede ayudarlo a obtener esa información de manera rápida y fácil. Pero, ¿qué es y cómo funciona? En esta publicación de blog, responderemos esas preguntas y más. ¡Así que sigue leyendo para aprender todo lo que necesitas saber sobre esta poderosa herramienta!

¿Qué es el web scraping?
Imagina que tuvieras que mirar algo como esto todo el día. Divertido, ¿verdad…?
Ahora imagine si hay una manera de clasificar todos esos datos en cuestión de segundos para obtener un conjunto organizado. Eso es básicamente lo que es el raspado de datos.
En resumen, el web scraping es una forma de extraer datos de sitios web. Por lo general, las computadoras lo hacen automáticamente, pero también se puede hacer manualmente.
Hay algunas formas diferentes de hacerlo, pero la idea básica es cargar una página web y luego analizar el código HTML para encontrar los datos que desea. Una vez que haya encontrado los datos que desea, puede guardarlos en un archivo o base de datos para su uso posterior.
El web scraping puede ser útil para una amplia variedad de tareas, como obtener una lista de todos los nombres y precios de productos de una tienda en línea, o extraer datos de un foro web para ver lo que dice la gente sobre un tema determinado.
¿El web scraping es gratis?
La mayoría de las herramientas de raspado web son de uso gratuito, aunque existen algunas opciones pagas. Las opciones pagas generalmente ofrecen más funciones y son más fáciles de usar, pero las opciones gratuitas generalmente harán el trabajo bien.
Consejo rapido
¿Es legal el web scraping?
Esta es la pregunta más común y la respuesta es... depende. En general, está perfectamente bien extraer datos públicos de sitios web. Sin embargo, si está extrayendo datos que deben ser privados (como la información de contacto de alguien), entonces podría tener problemas legales.
Esta es una pregunta común, y la respuesta es... depende. En general, está perfectamente bien extraer datos públicos de sitios web. Sin embargo, si está extrayendo datos que deben ser privados (como la información de contacto de alguien), entonces podría tener problemas legales.
Siempre es una buena idea verificar los términos de servicio del sitio web que está raspando para asegurarse de que no está violando ninguna regla.
En LaGrowthMachine, hemos desarrollado nuestros propios métodos de extracción utilizando varias fuentes de datos y diferentes tecnologías, lo que nos permite tener una de las mejores funciones de enriquecimiento de datos del mercado.
Recuperamos hasta 28 elementos de datos diferentes sobre nuestros leads (siempre siguiendo un enfoque RGPD-amigable), lo que te permitirá automatizar según variables muy precisas y ser muy natural en tu enfoque.
Si bien la práctica no es reciente, tiende a generalizarse y extenderse.
Se ha convertido en un activo esencial para los especialistas en marketing de crecimiento y las PYME que desean combinar eficiencia y reactividad.
De acuerdo, de eso se trata el alboroto, pero ¿cómo beneficia realmente el web scraping a su negocio?
¿Por qué necesita web scraping?
La ventaja más obvia del web scraping es que puede ahorrarle mucho tiempo.
Imagínese si tuviera que copiar y pegar manualmente datos de sitios web cada vez que quisiera hacer una investigación de mercado. ¡Tomaría una eternidad! Pero con web scraping, puede tener todos los datos que necesita en solo unos minutos.
Otra gran ventaja es que puede ayudarlo a obtener datos que serían difíciles o imposibles de obtener de otra manera. Por ejemplo, si desea investigar un nuevo mercado, el web scraping puede ayudarlo a obtener rápida y fácilmente una lista de todas las empresas en ese mercado.
Además, el raspado web se puede utilizar para una variedad de tareas, algunos de los usos más comunes incluyen:
- Generación de clientes potenciales: extraer datos de sitios web puede ser una excelente manera de encontrar nuevos clientes potenciales. Por ejemplo, puede extraer datos de un directorio de empresas para encontrar todas las empresas de su industria que se encuentran en una determinada ciudad.
- Investigación de mercado: el raspado web se puede utilizar para recopilar datos sobre una determinada industria o mercado. Estos datos se pueden analizar para ayudarlo a comprender mejor el mercado en su conjunto.
- Análisis de la competencia: Vigilar a la competencia es importante en cualquier negocio. Al extraer datos de sus sitios web, puede obtener una mejor comprensión de sus productos, precios y estrategias de marketing.
Yendo aún más lejos, con los datos raspados, puede configurar campañas multicanal en LaGrowthMachine.
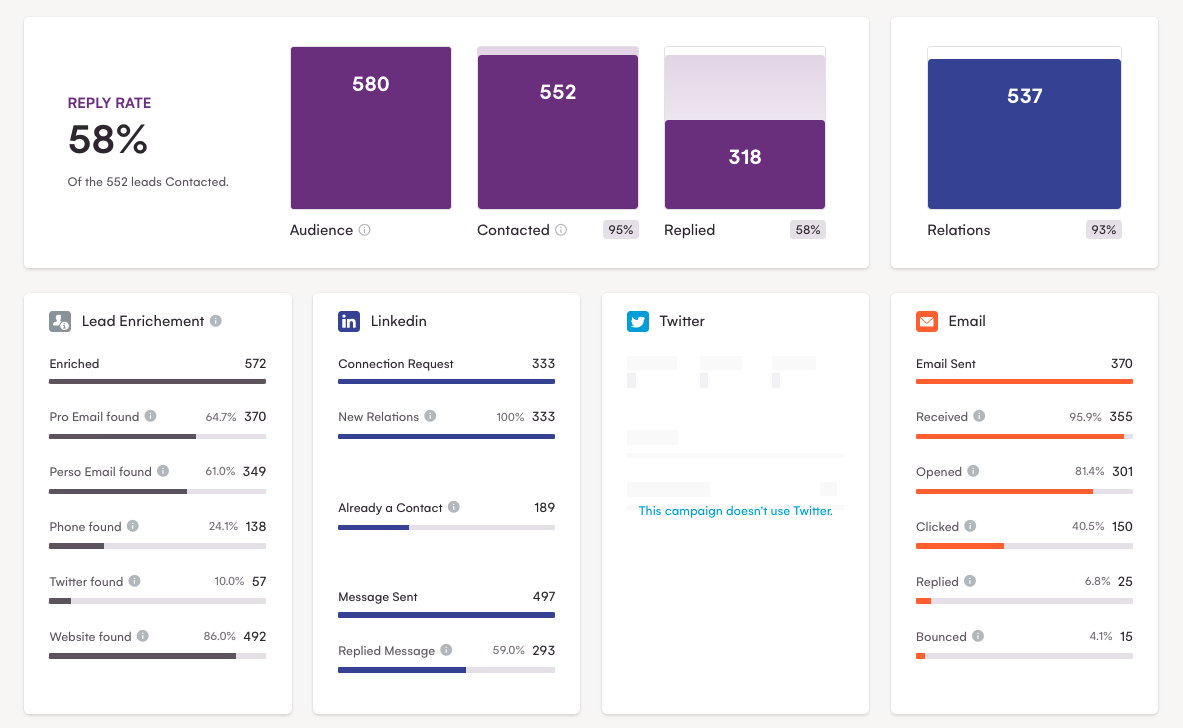
Como puede ver, este método es muy exitoso, ¡con una tasa de respuesta de casi el 60%!
Ahora que le presentamos el web scraping y le mostramos algunos de sus beneficios, echemos un vistazo a los conceptos básicos de cómo funciona.
¿Cómo funciona el web scraping?
El raspado web generalmente lo realizan automáticamente las computadoras, pero también se puede hacer manualmente.
Hay algunas formas diferentes de hacerlo, pero la idea básica es cargar una página web y luego analizar el código HTML para encontrar los datos que desea. Una vez que haya encontrado los datos que desea, puede extraerlos a un archivo o base de datos para su uso posterior.
Por ejemplo, supongamos que desea extraer datos de una tienda en línea para obtener una lista de todos los nombres y precios de los productos.
Primero, necesitaría encontrar y cargar la página web que desea raspar.
Luego, necesitaría escribir un código que analice el código HTML de la página web y extraiga los datos que le interesan.
Por último, deberá guardar los datos en un archivo o base de datos.
El raspado web se puede realizar en una variedad de lenguajes de programación, pero los más populares son Python, Java y PHP.
Si recién está comenzando con el web scraping, le recomendamos que use una herramienta como ParseHub o Scrapy. Estas herramientas facilitan la extracción de datos de sitios web sin tener que escribir ningún código.
¿Cuáles son algunas de las mejores prácticas de web scraping?

Ahora que conoce los conceptos básicos del web scraping, echemos un vistazo a algunas de las mejores prácticas para tener en cuenta.
Consulta las condiciones del servicio
Como mencionamos antes, debe verificar los términos de servicio del sitio web que está raspando. Esto asegurará que no está infringiendo ninguna regla y evitará cualquier problema potencial, legal o de otro tipo, en el futuro. También es una buena idea obtener el permiso del propietario del sitio web antes de raspar su sitio porque algunos webmasters pueden no estar muy contentos con eso.
Usa las herramientas adecuadas
Hay una variedad de diferentes herramientas de raspado web disponibles, por lo que es importante elegir la adecuada para sus necesidades.
Hablando de eso, ¡LaGrowthMachine es uno de ellos!
Repasaremos una lista de las mejores herramientas de web scraping más adelante en esta guía, pero por el bien de este punto, solo mencionaremos algunas de las más populares:
- Scrapy: Scrapy es un marco de web scraping escrito en Python. Es una de las herramientas más populares disponibles y es utilizada por grandes nombres como Google, Yahoo y Facebook.
- ParseHub: ParseHub es un raspador web que admite una amplia variedad de idiomas y plataformas web.
- Octoparse: Octoparse es otro raspador web que admite páginas web tanto estáticas como dinámicas.
No sobrecargues los servidores
Cuando extrae datos de sitios web, es importante no sobrecargar sus servidores con demasiadas solicitudes. Esto puede llevar a que su dirección IP sea prohibida en el sitio web. Para evitar esto, asegúrese de espaciar sus solicitudes y no haga demasiadas a la vez.

Manejar errores con gracia
Es inevitable que te encuentres con errores en algún momento. Ya sea que se trate de un sitio web que no funciona o de datos que no están en el formato que esperaba, es importante tener paciencia y ser cuidadoso al tratar con estos errores. No quieres arriesgarte a romper nada porque tienes demasiada prisa.
Revisa tus datos regularmente
Es importante revisar sus datos periódicamente. A veces, las páginas web cambian y es posible que los datos que extraiga ya no sean precisos. Revisar sus datos regularmente ayudará a garantizar que siempre obtenga información precisa.
Raspe responsablemente
Es importante ser respetuoso con los sitios web que estás raspando. Esto significa no raspar demasiados datos, no raspar con demasiada frecuencia y no raspar datos confidenciales. Además, asegúrese de mantener su raspador actualizado para que no rompa inadvertidamente ningún sitio web que esté raspando.
Sepa cuándo parar
Habrá momentos en los que no podrá obtener los datos que desea de un sitio web. Cuando esto sucede, es importante saber cuándo parar y seguir adelante. No pierda el tiempo tratando de forzar su web scraper para que funcione: hay otros sitios web con los datos que necesita.
Estas son solo algunas de las mejores prácticas a tener en cuenta al realizar la extracción de datos. Seguir estas pautas le ayudará a garantizar que tenga una experiencia positiva y a evitar posibles problemas.
5 de las mejores herramientas de web scraping

Como mencionamos antes, hay una variedad de raspadores web disponibles que van desde marcos complejos hasta herramientas simples. En esta sección, repasaremos algunas de las herramientas de raspado más populares.
Ahora... ya hemos mencionado las herramientas básicas como Scrapy y ParseHub, así que repasaremos rápidamente algunas de las otras.
Pitón
Python es una de las opciones más obvias para sus necesidades de web scraping. Es un lenguaje de secuencias de comandos versátil que se puede utilizar para... raspado de datos, así como para una amplia gama de otras tareas.
La principal ventaja de usar el software de web scraping de Python es que es relativamente fácil de aprender y usar.
Además, Python tiene una amplia gama de bibliotecas y módulos que se pueden usar para la extracción de datos web, lo que la convierte en una herramienta muy poderosa.
Una desventaja es que los raspadores web de Python pueden ser lentos, especialmente si intentan raspar grandes cantidades de datos.
Además, algunos sitios web pueden bloquear su acceso, lo que significa que, a menudo, el web scraping con Python puede llevar más tiempo y ser más difícil que usar otras herramientas de web scraping.
En general, la extracción de datos web con Python tiene ventajas y desventajas, pero sigue siendo una opción popular para muchas personas que buscan extraer datos de la web.
Import.io

Esta es una herramienta de extracción de datos web que le permite extraer datos de sitios web sin tener que escribir ningún código. Es una de las herramientas de web scraping más fáciles de usar disponibles y, además, ¡es genial para principiantes!
Incluye características increíbles como:
- Una interfaz de apuntar y hacer clic fácil de usar
- La capacidad de raspar datos detrás de un inicio de sesión
- Rotación automática de IP para evitar ser baneado
Lo que hace que import.io sea tan bueno es que puede extraer datos de varias páginas de un sitio web. Esto es útil si desea extraer datos de un sitio web grande con muchas páginas. Sin embargo, esto también significa que puede ser lento cuando se extraen datos de sitios web que contienen una tonelada de páginas.
Otra ventaja de import.io es que puede raspar datos de sitios web que son "difíciles" de raspar: lo que significa que puede eludir algunos de los mecanismos de protección que utilizan los sitios web para evitar el raspado. Dicho esto, corres el riesgo de que la herramienta se rompa cuando los sitios web cambian sus mecanismos de protección.
En general, import.io es una gran herramienta para recopilar rápidamente datos de la web, pero es importante tener en cuenta sus limitaciones.
Mozenda

Mozenda es otra herramienta de web scraping que no requiere codificación. Incluye funciones como representación de páginas web, rastreo de páginas web y extracción de datos.
Es una gran solución porque es fácil de usar y se puede configurar para extraer datos de casi cualquier sitio web.
Una de las principales ventajas de usar Mozenda es que es muy rápido y eficiente. Puede manejar grandes cantidades de datos muy rápida y fácilmente.
Además, es muy fácil de usar. La interfaz de usuario es intuitiva y fácil de usar. También hay una amplia gama de recursos en línea disponibles para ayudarlo a comenzar con el web scraping usando esta herramienta.
Sin embargo, uno de los principales inconvenientes es que es bastante caro. Si solo planea raspar web para uso personal, es posible que Mozenda no sea la mejor opción para usted.
Tampoco siempre funciona a la perfección. A veces, los sitios web pueden cambiar su estructura o diseño, lo que puede causar problemas con el web scraping.
apificar

Como plataforma de web scraping, Apify le permite convertir sitios web en datos estructurados. Ofrece una amplia gama de funciones, incluida la capacidad de raspar páginas web dinámicas, crear API y rastrear sitios web completos.
Si bien Apify es una herramienta poderosa, tiene algunas limitaciones:
En primer lugar, no es de uso gratuito, por lo que si tiene poco dinero en efectivo, puede que no sea la mejor opción para usted. También puede ser un desafío configurarlo y usarlo, especialmente para los usuarios que no están familiarizados con el web scraping.
Sea como fuere, este es uno de los web scrapers más escalables que puedes usar. La plataforma puede manejar raspaduras a gran escala, lo que la hace ideal para empresas que necesitan recopilar datos a gran escala.
No obstante, esta escalabilidad tiene un inconveniente; debido a que Apify puede manejar raspados a gran escala, puede ser más propenso a errores y algunos datos pueden perderse durante el proceso de raspado.
En conjunto, Apify sigue siendo una plataforma popular de web scraping debido a su flexibilidad y variedad de funciones. Si está buscando una plataforma de web scraping fácil de usar con una amplia gama de funciones, Apify puede ser una buena opción para usted.
diffbot

Diffbot es un software de web scraping que utiliza inteligencia artificial para extraer datos de páginas web. Ofrece una amplia gama de funciones, incluida la capacidad de raspar web a gran escala, rastrear sitios web y extraer datos de páginas web de JavaScript.
La principal ventaja de usar Diffbot es que es muy preciso. La herramienta puede extraer datos específicos con un alto grado de precisión, lo que significa que es menos probable que encuentre errores al usar la herramienta. También tiene la capacidad de extraer datos de varias páginas y la capacidad de manejar solicitudes AJAX, lo que siempre es una ventaja.
Además, es muy fácil de usar. La interfaz de usuario es intuitiva y fácil de usar, y hay una amplia gama de recursos en línea disponibles para ayudarlo a comenzar con el web scraping usando Diffbot.
Sin embargo, una de las mayores desventajas de Diffbot es que es bastante costoso y no puede extraer datos de sitios que usan JavaScript para cargar contenido.
Además, también necesita tener un sitio web que esté bien estructurado para que funcione al máximo de su potencial. De lo contrario, el proceso de extracción de datos puede ser bastante lento.
Disfruta raspando la web... ¡con precaución!
El raspado web puede ser una excelente manera de recopilar datos de la web. Es rápido, eficiente y relativamente fácil de hacer. Sin embargo, hay algunas cosas que debe tener en cuenta antes de comenzar con el web scraping.
Primero, el web scraping puede ser ilegal en algunos casos. Si planea raspar web con fines comerciales, debe asegurarse de tener el derecho legal para hacerlo.
En segundo lugar, el web scraping puede ser un desafío. Si bien hay muchas herramientas de raspado web disponibles que son bastante fáciles de usar y no requieren codificación, algunos sitios web pueden ser más difíciles de raspar que otros.
Por último, el web scraping puede llevar mucho tiempo. Si planea raspar un sitio web grande, puede llevar algún tiempo obtener todos los datos que necesita.
No obstante, el raspado web puede ser una excelente manera de recopilar datos de manera rápida y eficiente. Solo asegúrese de conocer los riesgos involucrados antes de comenzar con el web scraping.
¡Feliz raspado!