
了解主要模式:星与雪花
已发表: 2022-08-26多维模式旨在构建数据仓库系统模型。
这些模式的主要目的是满足为分析目的而构建的大型数据库 (OLAP) 的需求。
此方法用于对数据库中的数据进行排序,使数据库中的内容排列良好。 该模式允许客户提出与业务或市场趋势相关的问题。
此外,多维模式以数据立方体的形式表示数据,可以从不同的角度和维度查看和建模数据。
它分为三种类型,但很多人混淆了星星和雪花。 因此,他们很难选择更好的模型。
如果您是其中之一,让我们讨论星型和雪花模式之间的区别,从定义开始,了解它们的好处、挑战、图表和特征。
什么是多维模式?
Schema 是指完整的数据库和数据集市的逻辑描述。 它包括记录的名称及其描述,包括聚合和相关的数据项。
数据库一般使用关系模型来描述,而数据仓库系统使用Schema模型。
可以使用数据挖掘查询语言 (DMQL) 定义多维模式。
为了定义数据集市和数据仓库,它使用两个原语——维度定义和多维数据集定义。
多维模式使用不同类型的模式模型。 他们是:
- 星型图
- 雪花模式
- 银河架构
让我们讨论一下什么是星型和雪花模式。
星与雪花:它们是什么?
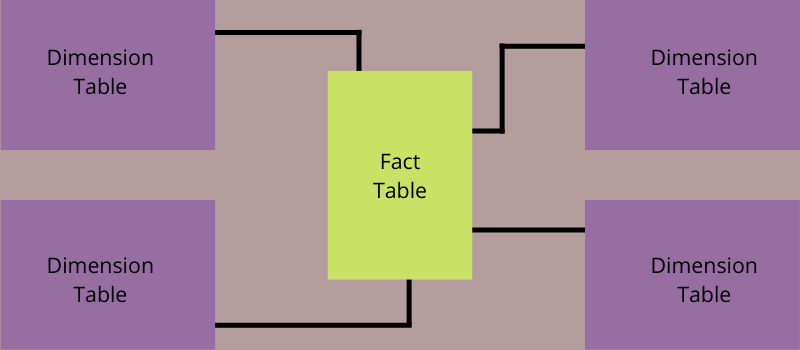
什么是星图?
星型模式是一种架构数据仓库和商业智能模型,需要单个事实表来存储测量数据和事务数据。 它还使用不同的较小维度表来保存有关业务数据的属性。
它是根据其结构命名的。 事实表就像一颗星,位于图表的中心,而小维度表就像中心表的分支一样,形成一个星形结构。
每个星型模式都由一个事实表和多个小维度表组成。 事实表包括需要分析的特定的、可测量的数据,例如记录的绩效、财务数据或销售记录。 它可能是一次或事务性的历史数据快照。
此外,星型模式是数据仓库和数据集市模式中最简单、最基本的模式。 它在处理基本查询方面很有效。 星型模式通常支持商业智能、即席查询、分析应用程序和在线分析处理多维数据集。
星型模式还支持许多记录的计数、平均、总和和其他聚合。 用户可以轻松地按维度过滤和分组聚合。 例如,用户会生成诸如“查找 6 月份的所有销售记录”或“分析 2022 年 XYZ 办公室的总收入”之类的查询。
什么是雪花模式?
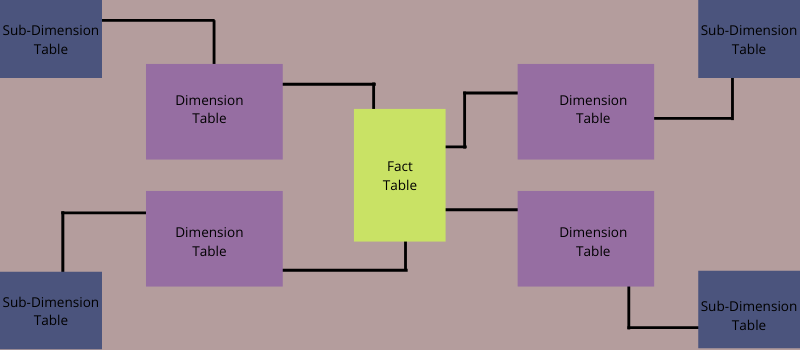
雪花模式是一种多维数据模型,也可以称为星型模式的扩展。 这是因为雪花模式中的维度表分解为子维度。
如果一个或多个维度表不直接链接到事实表而是通过其他维度表连接,那么架构就是一片雪花。
雪花化是一种对星型模式中的维度表进行规范化的现象。 当您对所有维度表进行规范化时,生成的结构类似于在结构中间包含事实表的雪花。
简单来说,雪花模式由模型中间的一个事实表组成,它连接到维度表,维度表又链接到其他维度表。 此模式用于增强查询的性能。
该模型是为跨复杂关系和维度进行快速、灵活的查询而创建的。 它有助于各个维度级别之间的一对多和多对多关系。
由于更严格地遵守更多规范化标准,您将获得更高的存储效率。 但是,与星型模式等非规范化数据模型相比,数据冗余可以忽略不计,并且性能较低。
星与雪花:它们是如何工作的?
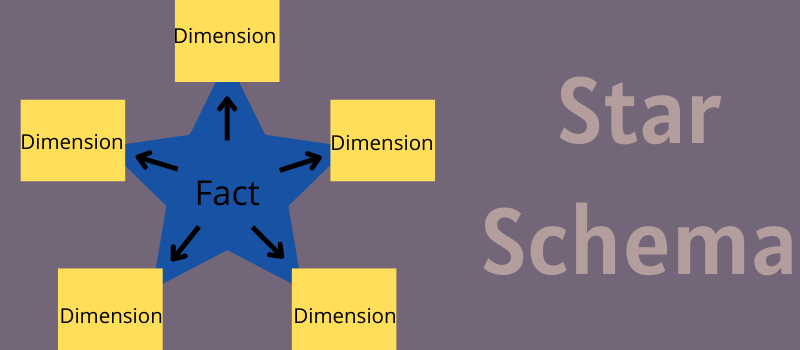
星型模式如何工作?
星型模型中间的事实表存储两种类型的信息——数值和维度属性值。 让我们通过一个销售数据库的例子来理解它们。
- 数值对于每一行和数据点都是唯一的。 这与存储在另一行中的数据无关或不相关。 这些是关于给定交易的事实,例如总金额、订单数量、确切时间、净利润、订单 ID 等。
- 维度属性值不直接存储任何数据,而是存储维度表中行的外键值。 中心表的不同行会引用这些信息,例如数据值、销售人员 ID、分公司 ID、产品 ID 等。
维度表总是存储来自事实表的支持信息。 每个维度表都与事实表的列以及维度值相关,并存储有关该值的附加数据。
示例:员工维度表以员工 ID 作为键值,还包含姓名、性别、地址、电话号码等信息。 同样,产品维度表存储信息,包括产品名称、颜色、首次上市日期、制造成本等。
雪花模式如何工作?
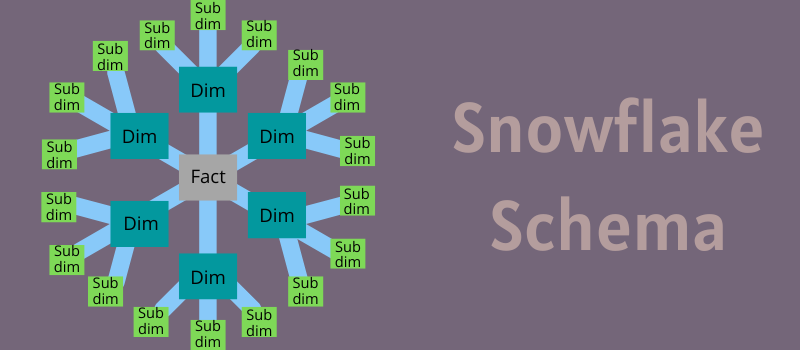
想想一个带有中心盒子的雪花设计,并通过该盒子与不同的点进行不同的连接。 为了维护数据集市和数据仓库,雪花模式设计应运而生。
它类似于星型模式,但有细微的变化。 与星型模式不同,雪花模式扩展了它的子维度表,这些子维度表链接到维度表。
该模型的主要目的是对星形模型的非规范化信息进行归一化。 这样,它可以解决与星型模式相关的常见问题。
在模式的核心,您会发现一个与维度表中包含的信息链接的事实表。 这些表再次向外辐射到具有描述维度表信息的详细信息的子维度表。
示例:雪花模式包含一个销售事实表和商店位置、行、系列、产品和时间维度表。 市场维度由两个维度表组成,商店作为主维度表,商店的位置作为子维度表。 产品维度具有三个子维度表,分别是产品、线和系列子维度表。
星与雪花:特征
星型模式的特征
- 星型模式可以从规范化数据中过滤数据,以满足数据仓库的需求。 唯一键是根据每个事实表的关联信息生成的,以标识每一行。
- 它提供快速计算和汇总,例如获得的收入和每月月底售出的总物品。 这些细节可以根据需要通过构建合适的查询来过滤。
- 它是事件的度量,包括由外键组成的有限数值。 这些键与维度表相关。 有多种类型的事实表以原子级别的值作为框架。
- 事务事实表包含有关特定事件的数据,例如销售和假期。
- 记录事实包括给定的时期,例如年底或每个季度的帐户信息。
- 维度表给出了在中心表中找到的属性或记录的详细数据。
- 用户可根据需要自行设计表格。
- 您可以使用星型模式来累积快照表。
雪花模式的特征
- 雪花模式需要较小的磁盘空间。
- 由于其独立的主要维度表,该模型易于实现。
- 维度表包含至少两个属性来定义多个粒度的信息。
- 由于有多个表,与星型模式相比,性能较低。
- 由于规范化,雪花模式具有最高的数据完整性级别和低冗余。
Star vs. Snowflake:优势

星型模式的优势
- 星型模式是数据集市模式中最简单的方式。
- 它有一个简单的报告逻辑。 这个逻辑是动态隐含的。
- 它的设计使用通过在线交易流程应用的喂食立方体,以使立方体高效地工作。
- 星型模式由简单的逻辑和查询组成,这些查询很容易从事务过程中提取出来。
- 它为报告应用程序提供了增强的性能。
- 它被部署来控制数据的快速恢复。
- 过滤和选择的信息可以很容易地应用于不同的情况。
雪花模式的优点
- 由于磁盘存储需求较少,星型模式用于提高查询性能。
- 它在组件和维度级别之间的关系中提供了更大的可伸缩性。
- 它更容易维护。
- 星型模式提供快速的数据检索。
- 它是用于数据仓库的常见且简单的数据模式。
- 它有助于提高数据质量。
- 结构化数据减少了数据完整性问题。
星与雪花:限制
星型模式的局限性
它具有高度的非规范化和完整性状态。 如果用户更新数据失败,整个过程就会崩溃。 安全和保护也是有限的。 此外,星型模式不如分析模型灵活。 它没有为各种关系提供有效的支持。

雪花模式的局限性
您会发现 Snowflake 的主要限制是由于小维度表数量的增加而导致的额外维护工作。 许多复杂的查询使查找所需数据变得具有挑战性。 此外,由于表格较高,问题的实施时间也很长。 这种模式也是刚性的,需要更高的维护成本。
星与雪花:差异
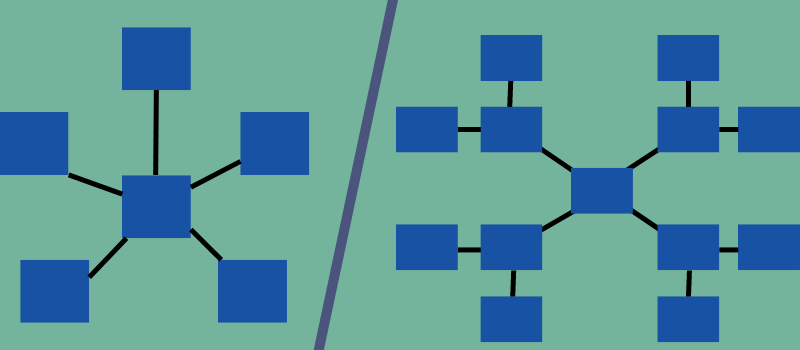
Star 和 Snowflake 是多维模式的类型,但具有不同的结构和属性。 前者像星星,后者像雪花,定义了他们的名字。
在星型模式中,只有一个连接在中心事实表和侧维度表之间建立关系。 另一方面,在雪花模式中,需要多个连接来链接到维度表。
当维度表中的行数较少时,通常使用星型模式,而当维度表相对较大时,使用雪花模式。
下图区分了这两种模型以及维度表和事实表如何在不同的模式中链接。
| 参数 | 星型图 | 雪花模式 |
| 磁盘空间 | 星型模式使用更多磁盘空间。 | 雪花模式使用更少的磁盘空间。 |
| 数据冗余 | 它具有高数据冗余。 | 它具有低数据冗余。 |
| 正常化 | 维度表是非规范化的,这意味着在表中重复相同的值。 | 维度表已完全规范化。 |
| 查询性能 | 执行查询需要最少的时间,从而获得更好的性能。 | 查询执行比星型模式花费更多时间,使其性能不如星型模式。 |
| 查询复杂度 | 查询复杂度低。 | 查询复杂度高于星型模式。 |
| 维护 | 由于数据冗余度高,维护星型模式有点困难。 | 由于数据冗余低,易于维护和更改雪花模式。 |
| 数据的完整性 | 数据完整性很高,因为数据冗余存储在维度表中存在多个副本的位置。 | 数据完整性很低,因为它完全规范了维度表。 |
| 层次结构 | 星型模式中维度表的层次结构存储在维度表中。 | 层次结构分为单独的维度表。 |
| 数据库设计 | 它有一个简单的数据库设计。 | 它有一个非常复杂的数据库设计。 |
| 事实表 | 多个维度表围绕着一个事实表。 | 事实表被维度表包围,维度表也被子维度表包围。 |
| 设置 | 星型模式易于设计和设置,因为直接关系代表它们。 | 另一方面,雪花模式的设置有点复杂。 |
| 立方体处理 | 立方体处理速度更快。 | 由于复杂的连接,多维数据集处理有点慢。 |
| 外键 | 它有最少数量的外键。 | 它具有最大数量的外键。 |
结论
Star 和 Snowflake 模式在不同领域都很有用。 因此,决定哪个更好是基于他们的要求。
雪花模式是星型模式的扩展,它对星型模式中的维度表进行规范化。
星型模式设计简单,运行查询更快,设置也很简单。 另一方面,雪花模式更容易维护,占用更少的磁盘空间,并且更不容易出现数据完整性问题。
因此,如果您需要简单的设计、更少的外键和更快的多维数据集处理,星型模式可能是更好的选择。 但是,如果您需要更少的磁盘空间、低数据完整性和低维护,雪花模式可能更合适。
您还可以探索一些最佳的图形数据库解决方案。