
Ketahui Tentang Skema Utama: Bintang vs. Kepingan Salju
Diterbitkan: 2022-08-26Skema multidimensi dirancang untuk membangun model sistem data warehouse.
Tujuan utama dari skema ini adalah untuk memenuhi kebutuhan database yang lebih besar yang dibangun untuk tujuan analitis (OLAP).
Metode ini digunakan untuk mengurutkan data dalam database dengan susunan yang baik dari isi dalam database. Skema ini memungkinkan pelanggan untuk mengajukan pertanyaan terkait dengan tren bisnis atau pasar.
Selanjutnya, skema multidimensi mewakili data dalam bentuk kubus data yang memungkinkan melihat dan memodelkan data dari perspektif dan dimensi yang berbeda.
Ini dari tiga jenis, tetapi banyak yang bingung antara bintang dan Kepingan Salju. Oleh karena itu, menjadi sulit bagi mereka untuk memilih model yang lebih disukai.
Jika Anda salah satunya, mari kita bahas perbedaan skema bintang dan kepingan salju, mulai dari definisi dan pemahaman manfaat, tantangan, diagram, dan karakteristiknya.
Apa itu Skema Multidimensi?
Skema mengacu pada deskripsi logis dari database lengkap dan data mart. Ini mencakup nama catatan dan deskripsinya, termasuk agregat dan item data terkait.
Sebuah database umumnya menggunakan model relasional untuk menggambarkan, sedangkan sistem data warehouse menggunakan model Skema.
Skema multidimensi dapat didefinisikan dengan Data Mining Query Language (DMQL).
Untuk mendefinisikan data mart dan gudang data, ia menggunakan dua primitif – definisi dimensi dan definisi kubus.
Skema multidimensi menggunakan berbagai jenis model skema. Mereka:
- Skema bintang
- Skema kepingan salju
- Skema galaksi
Mari kita bahas apa itu skema bintang dan Snowflake.
Bintang vs. Kepingan Salju: Apa Itu?
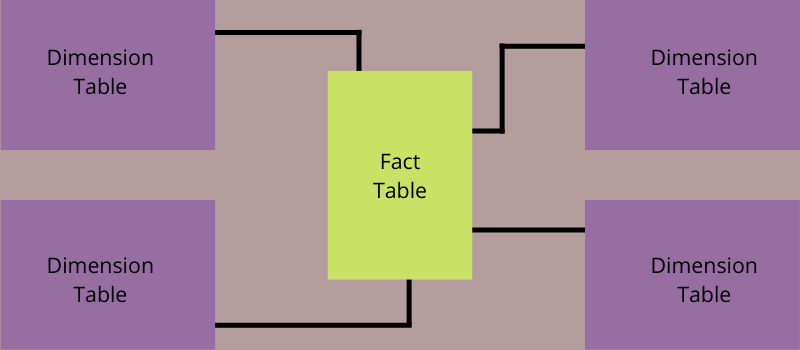
Apa itu Skema Bintang?
Skema bintang adalah pergudangan data arsitektur dan model intelijen bisnis yang membutuhkan tabel fakta tunggal untuk menyimpan data terukur dan transaksional. Itu juga menggunakan tabel dimensi yang lebih kecil yang berbeda untuk menyimpan atribut tentang data bisnis.
Itu dinamai sesuai dengan strukturnya. Seperti sebuah bintang, tabel fakta mengambil tempat di tengah diagram, dan tabel dimensi kecil duduk seperti cabang ke meja tengah untuk membentuk struktur seperti bintang.
Setiap skema bintang terdiri dari satu tabel fakta tetapi beberapa tabel dimensi kecil. Tabel fakta mencakup data spesifik dan terukur yang perlu dianalisis, seperti kinerja yang dicatat, data keuangan, atau catatan penjualan. Ini mungkin snap data historis pada suatu waktu atau transaksional.
Selain itu, skema Star adalah yang paling sederhana dan paling mendasar di antara data warehouse dan skema data mart. Ini efisien dalam menangani kueri dasar. Skema bintang umumnya mendukung intelijen bisnis, kueri ad hoc, aplikasi analitik, dan kubus pemrosesan analitik online.
Skema bintang juga mendukung jumlah, rata-rata, jumlah, dan agregasi lain dari banyak catatan. Pengguna dapat dengan mudah memfilter dan mengelompokkan agregasi berdasarkan dimensi. Misalnya, pengguna membuat kueri seperti "temukan semua catatan penjualan pada bulan Juni" atau "analisis total pendapatan dari kantor XYZ pada tahun 2022".
Apa itu Skema Kepingan Salju?
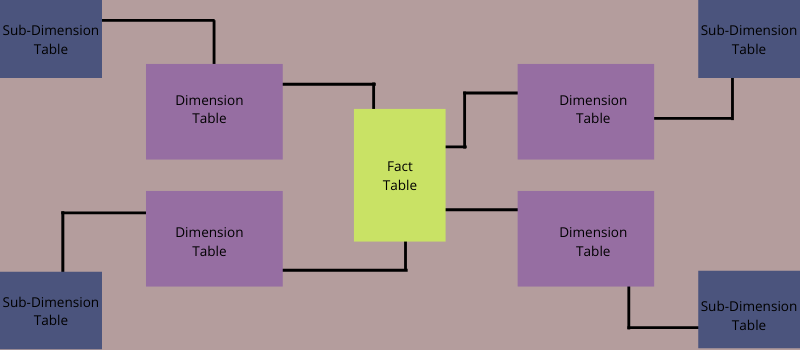
Skema kepingan salju adalah model data multidimensi yang juga dapat dikenal sebagai perpanjangan dari skema bintang. Ini karena tabel dimensi dalam skema kepingan salju dipecah menjadi subdimensi.
Skema adalah kepingan salju jika satu dan lebih tabel dimensi tidak terhubung langsung ke tabel fakta melainkan terhubung melalui tabel dimensi lain.
Snowflaking adalah fenomena yang menormalkan tabel dimensi dalam skema bintang. Saat Anda menormalkan semua tabel dimensi, struktur yang dihasilkan menyerupai kepingan salju yang berisi tabel fakta di tengah struktur.
Dengan kata sederhana, skema kepingan salju terdiri dari satu tabel fakta di tengah model, yang terhubung ke tabel dimensi, yang lagi-lagi terkait dengan tabel dimensi lain. Skema ini digunakan untuk meningkatkan kinerja kueri.
Model ini dibuat untuk kueri yang cepat dan fleksibel di seluruh hubungan dan dimensi yang kompleks. Sangat membantu untuk hubungan satu ke banyak dan banyak ke banyak di antara berbagai tingkat dimensi.
Karena kepatuhan yang lebih ketat terhadap standar normalisasi yang lebih banyak, Anda akan mendapatkan lebih banyak efisiensi penyimpanan. Namun, redundansi data dapat diabaikan, dan kinerjanya rendah dibandingkan dengan model data yang didenormalisasi seperti skema bintang.
Bintang vs. Kepingan Salju: Bagaimana Cara Kerjanya?
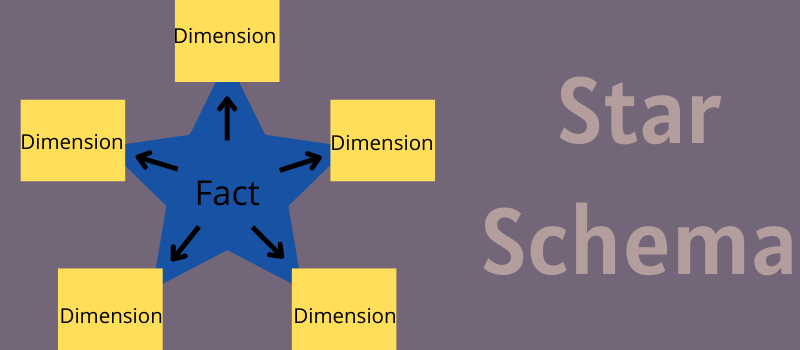
Bagaimana cara kerja Skema Bintang?
Tabel fakta di tengah model bintang menyimpan dua jenis informasi – nilai atribut numerik dan dimensi. Mari kita pahami dengan contoh database penjualan.
- Nilai numerik unik untuk setiap baris dan titik data. Ini tidak berkorelasi dengan atau berhubungan dengan data yang disimpan di baris lain. Ini adalah fakta tentang transaksi tertentu, seperti jumlah total, jumlah pesanan, waktu pasti, laba bersih, ID pesanan, dll.
- Nilai atribut dimensi tidak menyimpan data apa pun secara langsung, melainkan menyimpan nilai kunci asing untuk baris dalam tabel dimensi. Baris yang berbeda di tabel tengah akan merujuk informasi ini, seperti nilai data, ID karyawan penjualan, ID kantor cabang, ID produk, dll.
Tabel dimensi selalu menyimpan informasi pendukung dari tabel fakta. Setiap tabel dimensi berhubungan dengan kolom tabel fakta bersama dengan nilai dimensi dan menyimpan data tambahan tentang nilai tersebut.
Contoh: Tabel dimensi karyawan menggunakan ID karyawan sebagai nilai kunci dan juga berisi informasi, seperti nama, jenis kelamin, alamat, dan nomor telepon. Demikian pula, tabel dimensi produk menyimpan informasi, termasuk nama produk, warna, tanggal pertama ke pasar, biaya pembuatan, dll.
Bagaimana Skema Kepingan Salju Bekerja?
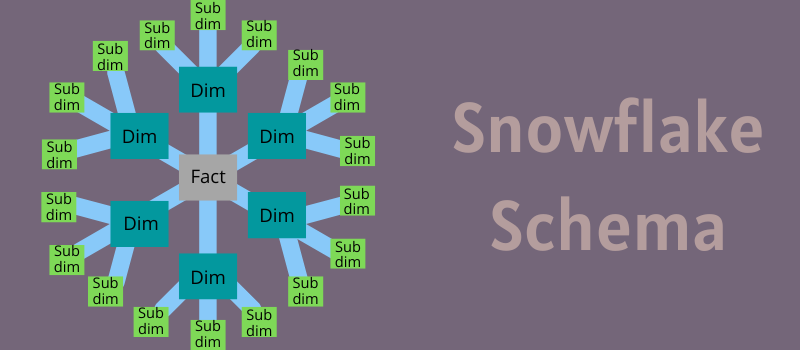
Pikirkan desain kepingan salju dengan kotak tengah dan koneksi yang berbeda melalui kotak itu ke titik yang berbeda. Untuk memelihara data mart dan gudang data, desain skema kepingan salju muncul.
Ini mirip dengan skema bintang tetapi dengan perubahan kecil. Tidak seperti skema bintang, skema kepingan salju memperluas tabel subdimensinya, yang dihubungkan ke tabel dimensi.
Tujuan utama dari model ini adalah untuk menormalkan informasi denormalized dari model bintang. Dengan cara ini, dapat memecahkan masalah umum yang terkait dengan skema bintang.
Pada inti skema, Anda akan menemukan tabel fakta yang terhubung dengan informasi yang terkandung dalam tabel dimensi. Tabel ini kembali menyebar ke luar ke tabel sub-dimensi yang memiliki informasi rinci yang menjelaskan informasi tabel dimensi.
Contoh: Skema kepingan salju berisi tabel fakta penjualan dan lokasi toko, lini, keluarga, produk, dan tabel dimensi waktu. Dimensi pasar terdiri dari dua tabel dimensi, dengan toko sebagai tabel dimensi utama dan lokasi toko sebagai tabel subdimensi. Dimensi produk memiliki tiga tabel subdimensi yang menyebutkan tabel subdimensi produk, lini, dan keluarga.
Bintang vs. Kepingan Salju: Karakteristik
Karakteristik Skema Bintang
- Skema bintang dapat memfilter data dari data yang dinormalisasi untuk memenuhi kebutuhan pergudangan data. Kunci unik dihasilkan dari informasi terkait untuk setiap tabel fakta untuk mengidentifikasi setiap baris.
- Ini memberikan perhitungan dan agregasi cepat, seperti pendapatan dari pendapatan yang diperoleh dan total barang yang terjual pada akhir setiap bulan. Detail ini dapat disaring sesuai dengan kebutuhan dengan membingkai kueri yang sesuai.
- Ini adalah pengukuran peristiwa yang mencakup nilai bilangan terbatas yang terdiri dari kunci asing. Kunci ini terkait dengan tabel dimensi. Ada berbagai jenis tabel fakta yang dibingkai dengan nilai-nilai pada tingkat atom.
- Tabel fakta transaksi berisi data tentang peristiwa tertentu, seperti penjualan dan hari libur.
- Fakta pencatatan mencakup periode tertentu seperti informasi akun pada akhir tahun atau setiap kuartal.
- Tabel dimensi memberikan data rinci tentang atribut atau catatan yang ditemukan di tabel tengah.
- Pengguna dapat mendesain sendiri meja sesuai dengan kebutuhan.
- Anda dapat menggunakan skema bintang untuk mengumpulkan tabel snapshot.
Karakteristik Skema Kepingan Salju
- Skema kepingan salju membutuhkan ruang disk yang kecil.
- Model ini mudah diimplementasikan karena tabel dimensinya yang terpisah dan utama.
- Tabel dimensi berisi setidaknya dua atribut untuk mendefinisikan informasi pada beberapa butir.
- Karena beberapa tabel, kinerjanya rendah dibandingkan dengan skema bintang.
- Skema kepingan salju memiliki tingkat integritas data tertinggi dan redundansi rendah karena normalisasi.
Bintang vs. Kepingan Salju: Keuntungan

Keuntungan Skema Bintang
- Skema bintang adalah cara paling sederhana di antara skema data mart.
- Ini memiliki logika pelaporan sederhana. Logika ini tersirat secara dinamis.
- Ini dirancang menggunakan kubus makan yang diterapkan melalui Proses Transaksi Online untuk membuat kubus bekerja secara efisien dan efektif.
- Skema bintang dibentuk dengan logika sederhana dan kueri yang mudah diekstraksi dari proses transaksional.
- Ini menawarkan peningkatan kinerja untuk aplikasi pelaporan.
- Ini digunakan untuk mengontrol pemulihan data yang cepat.
- Informasi yang disaring dan dipilih dapat diterapkan dengan mudah dalam berbagai kasus.
Keuntungan Skema Kepingan Salju
- Skema bintang digunakan untuk mengembangkan kinerja kueri karena persyaratan penyimpanan disk yang lebih sedikit.
- Ini menawarkan skalabilitas yang lebih besar dalam hubungan antara komponen dan tingkat dimensi.
- Lebih mudah untuk mempertahankan.
- Skema bintang menawarkan pengambilan data yang cepat.
- Ini adalah skema data yang umum dan sederhana untuk data warehousing.
- Ini membantu meningkatkan kualitas data.
- Data terstruktur mengurangi masalah integritas data.
Bintang vs. Kepingan Salju: Keterbatasan
Batasan Skema Bintang
Ini memiliki status denormalisasi dan integritas yang tinggi. Seluruh proses akan runtuh jika pengguna gagal memperbarui data. Keamanan dan perlindungan juga terbatas. Selain itu, skema bintang tidak sefleksibel model analitis. Itu tidak menawarkan dukungan yang efisien untuk berbagai hubungan.

Batasan Skema Kepingan Salju
Keterbatasan utama yang akan Anda temukan dengan Snowflake adalah upaya pemeliharaan tambahan karena meningkatnya jumlah tabel dimensi kecil. Banyak kueri yang kompleks menyulitkan untuk menemukan data yang diperlukan. Selain itu, waktu pelaksanaan pertanyaan tinggi karena tabel yang lebih tinggi. Model ini juga kaku dan membutuhkan biaya perawatan yang lebih tinggi.
Bintang vs. Kepingan Salju: Perbedaan
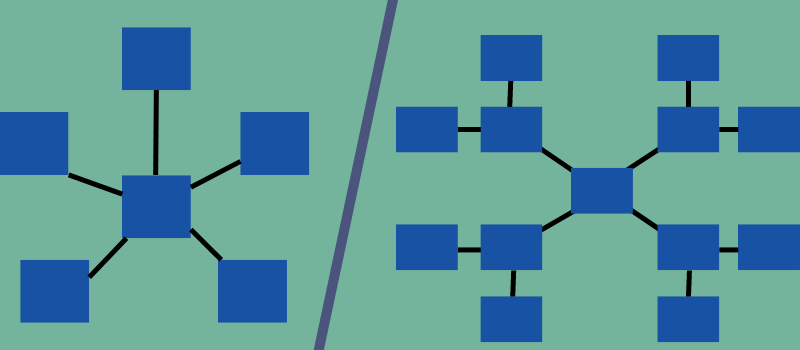
Star dan Snowflake adalah jenis skema multidimensi tetapi memiliki struktur dan sifat yang berbeda. Yang pertama seperti bintang, dan yang terakhir menyerupai kepingan salju, mendefinisikan nama mereka.
Dalam skema bintang, hanya satu gabungan yang membangun hubungan antara tabel fakta pusat dan tabel dimensi samping. Di sisi lain, dalam skema kepingan salju, beberapa gabungan diperlukan untuk menautkan ke tabel dimensi.
Skema bintang umumnya digunakan ketika Anda memiliki lebih sedikit jumlah baris dalam tabel dimensi, sedangkan skema kepingan salju digunakan ketika tabel dimensi relatif besar.
Diagram di bawah ini membedakan dua model dan bagaimana tabel dimensi dan tabel fakta dihubungkan dalam skema yang berbeda.
| Parameter | Skema Bintang | Skema Kepingan Salju |
| Ruang disk | Skema bintang menggunakan lebih banyak ruang disk. | Skema kepingan salju menggunakan lebih sedikit ruang disk. |
| Redundansi data | Ini memiliki redundansi data yang tinggi. | Ini memiliki redundansi data yang rendah. |
| Normalisasi | Tabel dimensi didenormalisasi, yang berarti mengulang nilai yang sama di dalam tabel. | Tabel dimensi sepenuhnya dinormalisasi. |
| Performa kueri | Dibutuhkan waktu minimum untuk mengeksekusi kueri, menghasilkan kinerja yang lebih baik. | Dibutuhkan lebih banyak waktu daripada skema bintang untuk eksekusi kueri, membuatnya kurang berkinerja daripada skema bintang. |
| Kompleksitas kueri | Kompleksitas kueri rendah. | Kompleksitas kueri lebih tinggi daripada skema bintang. |
| Pemeliharaan | Karena redundansi data yang tinggi, mempertahankan skema bintang agak sulit. | Karena redundansi data yang rendah, mudah untuk memelihara dan mengubah skema kepingan salju. |
| Integritas data | Integritas data tinggi karena data disimpan secara berlebihan di mana banyak salinan ada di tabel dimensi. | Integritas data rendah karena sepenuhnya menormalkan tabel dimensi. |
| Hirarki | Hirarki untuk tabel dimensi dalam skema bintang disimpan dalam tabel dimensi. | Hirarki dibagi menjadi tabel dimensi terpisah. |
| desain DB | Ini memiliki desain DB sederhana. | Ini memiliki desain DB yang sangat kompleks. |
| Tabel Fakta | Beberapa tabel dimensi mengelilingi tabel fakta. | Tabel fakta dikelilingi oleh tabel dimensi yang juga dikelilingi oleh tabel subdimensi. |
| Mempersiapkan | Skema bintang mudah dirancang dan diatur karena hubungan langsung mewakilinya. | Di sisi lain, skema kepingan salju agak rumit untuk diatur. |
| Pemrosesan kubus | Pemrosesan kubus lebih cepat. | Karena penggabungan yang rumit, pemrosesan kubus agak lambat. |
| Kunci asing | Ini memiliki jumlah minimum kunci asing. | Ini memiliki jumlah maksimum kunci asing. |
Kesimpulan
Skema Star dan Snowflake berguna di sektor yang berbeda. Jadi, memutuskan mana yang lebih baik di antara mereka didasarkan pada kebutuhan mereka.
Skema kepingan salju adalah perpanjangan dari skema bintang, di mana ia menormalkan tabel dimensi dalam skema bintang.
Skema bintang sederhana dalam desain, menjalankan kueri lebih cepat, dan penyiapannya mudah. Di sisi lain, skema kepingan salju lebih mudah dirawat, membutuhkan lebih sedikit ruang disk, dan kurang rentan terhadap masalah integritas data.
Jadi, skema bintang bisa menjadi pilihan yang lebih baik jika Anda membutuhkan desain yang sederhana, kunci asing yang lebih sedikit, dan pemrosesan kubus yang lebih cepat. Namun, jika Anda membutuhkan lebih sedikit ruang disk, integritas data rendah, dan perawatan rendah, skema kepingan salju bisa lebih cocok.
Anda juga dapat menjelajahi beberapa solusi database grafik terbaik.