
メジャー スキーマについて知る: スター vs. スノーフレーク
公開: 2022-08-26多次元スキーマは、データ ウェアハウス システム モデルを構築するように設計されています。
これらのスキーマの主な目的は、分析目的 (OLAP) のために構築された大規模なデータベースのニーズに対応することです。
この方法は、データベース内のコンテンツを適切に配置して、データベース内のデータを並べ替えるために使用されます。 このスキーマにより、顧客はビジネスや市場の傾向に関連する質問をすることができます。
さらに、多次元スキーマはデータ キューブの形式でデータを表し、さまざまな観点や次元からデータを表示およびモデル化できます。
3 種類ありますが、多くの人が星と雪の結晶を混同しています。 したがって、彼らが好ましいモデルを選択することは困難になります。
あなたがその 1 人である場合は、スター スキーマとスノーフレーク スキーマの違いについて説明し、定義から始めて、それらの利点、課題、図、および特性を理解してください。
多次元スキーマとは
スキーマとは、完全なデータベースとデータ マートの論理的な記述を指します。 これには、集計および関連するデータ項目を含む、レコードの名前とその説明が含まれます。
データベースは一般にリレーショナル モデルを使用して記述しますが、データ ウェアハウス システムはスキーマ モデルを使用します。
多次元スキーマは、Data Mining Query Language (DMQL) で定義できます。
データ マートとデータ ウェアハウスを定義するために、ディメンション定義とキューブ定義の 2 つのプリミティブを使用します。
多次元スキーマは、さまざまなタイプのスキーマ モデルを使用します。 彼らです:
- スター スキーマ
- スノーフレーク スキーマ
- ギャラクシー スキーマ
スター スキーマと Snowflake スキーマとは何かについて説明しましょう。
スター対スノーフレーク: 彼らは何ですか?
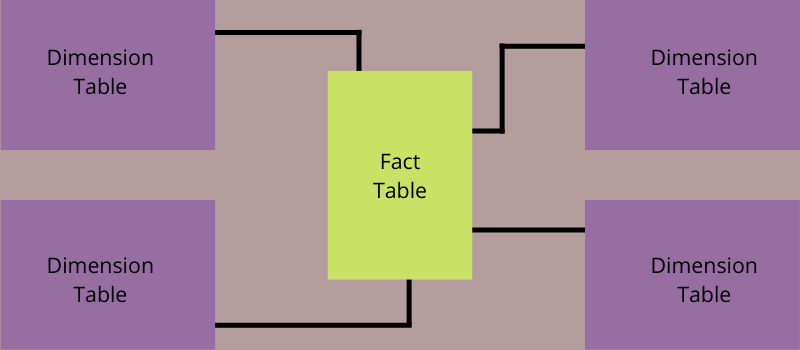
スタースキーマとは?
スター スキーマは、測定データとトランザクション データを格納するために単一のファクト テーブルを必要とするアーキテクチャ データ ウェアハウジングおよびビジネス インテリジェンス モデルです。 また、ビジネス データに関する属性を保持するために、さまざまな小さいディメンション テーブルを使用します。
その構造から名前が付けられています。 星のように、ファクト テーブルはダイアグラムの中央に位置し、小さなディメンション テーブルが中央のテーブルに枝のように配置され、星のような構造を形成します。
すべてのスター スキーマは、1 つのファクト テーブルと複数の小さなディメンション テーブルで構成されます。 ファクト テーブルには、記録されたパフォーマンス、財務データ、販売記録など、分析が必要な特定の測定可能なデータが含まれています。 それは、一度にまたはトランザクションの履歴データのスナップである可能性があります。
さらに、スター スキーマは、データ ウェアハウスおよびデータ マート スキーマの中で最も単純で最も基本的なスキーマです。 基本的なクエリを効率的に処理できます。 スター スキーマは、通常、ビジネス インテリジェンス、アドホック クエリ、分析アプリケーション、およびオンライン分析処理キューブをサポートします。
スター スキーマは、多数のレコードのカウント、平均、合計、およびその他の集計もサポートしています。 ユーザーは、ディメンションによって集計を簡単にフィルタリングおよびグループ化できます。 たとえば、ユーザーは「6 月のすべての販売記録を検索する」や「2022 年の XYZ オフィスからの総収益を分析する」などのクエリを生成します。
スノーフレーク スキーマとは
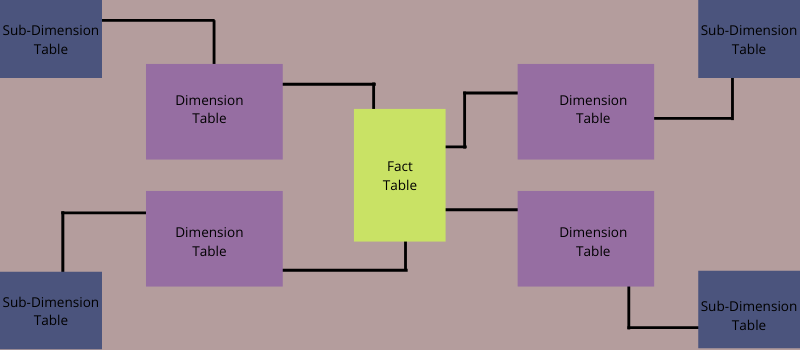
スノーフレーク スキーマは、スター スキーマの拡張とも呼ばれる多次元データ モデルです。 これは、スノーフレーク スキーマのディメンション テーブルがサブディメンションに分割されるためです。
1 つ以上のディメンション テーブルがファクト テーブルに直接リンクせず、他のディメンション テーブルを介して接続している場合、スキーマはスノーフレークです。
スノーフレーキングは、スター スキーマのディメンション テーブルを正規化する現象です。 すべてのディメンション テーブルを正規化すると、結果の構造は、構造の中央にファクト テーブルを含むスノーフレークのようになります。
簡単に言えば、スノーフレーク スキーマは、モデルの中央にある 1 つのファクト テーブルで構成され、ディメンション テーブルに接続され、さらに他のディメンション テーブルにリンクされます。 このスキーマは、クエリのパフォーマンスを向上させるために使用されます。
このモデルは、複雑なリレーションシップとディメンションにわたってすばやく柔軟にクエリを実行できるように作成されています。 これは、さまざまなディメンション レベル間の 1 対多および多対多の関係に役立ちます。
より多くの正規化標準への準拠が強化されるため、ストレージ効率が向上します。 ただし、データの冗長性はごくわずかであり、スター スキーマのような非正規化されたデータ モデルに比べてパフォーマンスは低くなります。
スター vs. スノーフレーク: どのように機能するのか?
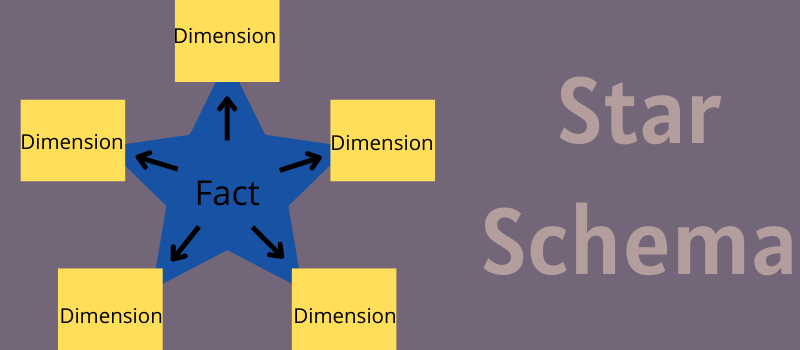
スタースキーマはどのように機能しますか?
スター モデルの中央にあるファクト テーブルには、数値属性値とディメンション属性値の 2 種類の情報が格納されます。 販売データベースの例でそれらを理解しましょう。
- 数値は、すべての行とデータ ポイントで一意です。 これは、別の行に格納されているデータと相関したり関連したりしません。 これらは、合計金額、注文数量、正確な時間、純利益、注文 ID など、特定のトランザクションに関する事実です。
- 次元属性値は、データを直接格納するのではなく、行の外部キー値を次元テーブルに格納します。 中央のテーブルのさまざまな行が、データ値、営業社員 ID、支店 ID、製品 ID などのこの情報を参照します。
ディメンション テーブルには、常にファクト テーブルからのサポート情報が格納されます。 すべてのディメンション テーブルは、ディメンション値と共にファクト テーブルの列に関連付けられ、その値に関する追加データを格納します。
例:従業員ディメンション テーブルは、従業員 ID をキー値として使用し、名前、性別、住所、電話番号などの情報も含みます。 同様に、製品ディメンション テーブルには、製品名、色、市場投入日、製造コストなどの情報が格納されます。
Snowflake スキーマはどのように機能しますか?
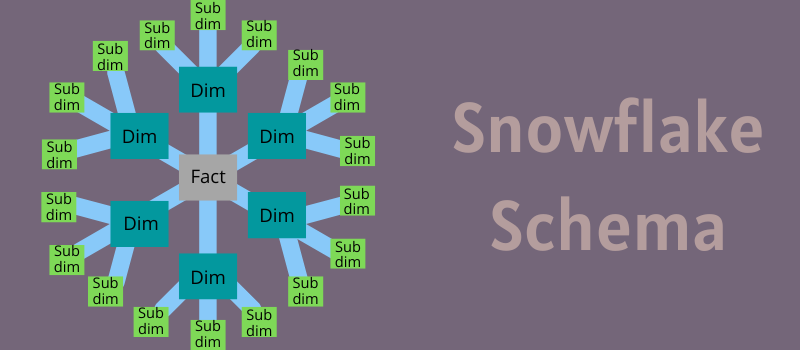
中央のボックスと、そのボックスを介してさまざまなドットへのさまざまな接続を備えた雪の結晶のデザインを考えてみてください。 データ マートとデータ ウェアハウスを維持するには、スノーフレーク スキーマ設計が必要です。
これはスター スキーマに似ていますが、わずかな変更があります。 スター スキーマとは異なり、スノーフレーク スキーマは、ディメンション テーブルにリンクされているサブディメンション テーブルを拡張します。
このモデルの主な目的は、スター モデルの非正規化された情報を正規化することです。 このようにして、スター スキーマに関連する一般的な問題を解決できます。
スキーマの中心には、ディメンション テーブルに含まれる情報とリンクするファクト テーブルがあります。 これらのテーブルは、ディメンション テーブル情報を説明する詳細情報を含むサブディメンション テーブルに再び放射状に広がります。
例:スノーフレーク スキーマには、販売ファクト テーブルと、店舗の場所、ライン、ファミリ、製品、および時間のディメンション テーブルが含まれています。 市場ディメンションは 2 つのディメンション テーブルで構成され、店舗がプライマリ ディメンション テーブル、店舗の場所がサブ ディメンション テーブルです。 製品ディメンションには、製品、ライン、およびファミリのサブディメンション テーブルを示す 3 つのサブディメンション テーブルがあります。
スター vs. スノーフレーク: 特徴
スタースキーマの特徴
- スター スキーマは、正規化されたデータからデータをフィルター処理して、データ ウェアハウスのニーズを満たすことができます。 各ファクト テーブルの関連情報から一意のキーが生成され、すべての行が識別されます。
- 得られた収入の収益や毎月末に販売されたアイテムの合計など、高速な計算と集計を提供します。 これらの詳細は、適切なクエリを構成することにより、必要に応じてフィルタリングできます。
- これは、外部キーで構成される有限数の値を含むイベントの測定です。 これらのキーは、ディメンション テーブルに関連付けられています。 アトミック レベルの値で構成されたさまざまな種類のファクト テーブルがあります。
- トランザクション ファクト テーブルには、セールや休日などの特定のイベントに関するデータが含まれています。
- 記録事実には、年度末や四半期ごとの口座情報のような特定の期間が含まれます。
- ディメンション テーブルは、中央のテーブルで見つかった属性またはレコードに関する詳細なデータを提供します。
- ユーザーは、必要に応じて独自のテーブルを設計できます。
- スター スキーマを使用して、スナップショット テーブルを蓄積できます。
スノーフレーク スキーマの特徴
- スノーフレーク スキーマには小さなディスク領域が必要です。
- このモデルは、メインのディメンション テーブルが分離されているため、実装が簡単です。
- ディメンション テーブルには、複数の粒度で情報を定義するための少なくとも 2 つの属性が含まれます。
- 複数のテーブルがあるため、スター スキーマに比べてパフォーマンスが低くなります。
- スノーフレーク スキーマは、データ整合性レベルが最も高く、正規化により冗長性が低くなります。
スター vs. スノーフレーク: 利点

スタースキーマの利点
- スター スキーマは、データ マート スキーマの中で最も単純な方法です。
- 単純なレポート ロジックがあります。 このロジックは動的に暗示されます。
- キューブを効率的かつ効果的に機能させるために、オンライン トランザクション プロセスを通じて適用されるフィード キューブを使用して設計されています。
- スター スキーマは、トランザクション プロセスから簡単に抽出できる単純なロジックとクエリで形成されます。
- レポート アプリケーションのパフォーマンスが向上します。
- データの迅速な回復を制御するために展開されます。
- フィルタリングおよび選択された情報は、さまざまな場合に簡単に適用できます。
スノーフレーク スキーマの利点
- スター スキーマは、ディスク ストレージの要件が少ないため、クエリのパフォーマンスを向上させるために使用されます。
- これにより、コンポーネントとディメンション レベル間の関係のスケーラビリティが向上します。
- メンテナンスが容易です。
- スター スキーマは、高速なデータ取得を提供します。
- これは、データ ウェアハウジング用の一般的でシンプルなデータ スキーマです。
- データ品質の向上に役立ちます。
- 構造化データにより、データの整合性の問題が軽減されます。
スター vs. スノーフレーク: 制限事項
スタースキーマの制限
非正規化された整合性の高い状態です。 ユーザーがデータの更新に失敗すると、プロセス全体が崩壊します。 セキュリティと保護も制限されています。 さらに、スター スキーマは分析モデルほど柔軟ではありません。 さまざまな関係を効率的にサポートするものではありません。

Snowflake スキーマの制限
Snowflake で見られる主な制限は、小さなディメンション テーブルの数が増えることによる追加のメンテナンス作業です。 多くの複雑なクエリにより、必要なデータを見つけることが困難になります。 さらに、テーブルが高いため、質問の実装時間が長くなります。 このモデルも剛性が高く、メンテナンス コストが高くなります。
スター vs. スノーフレーク: 違い
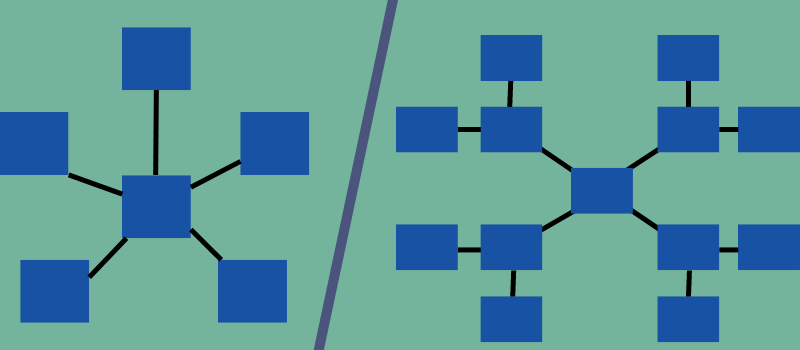
スターとスノーフレークは多次元スキーマの一種ですが、構造とプロパティが異なります。 前者は星のようなもので、後者は雪の結晶のようなもので、それぞれの名前が定義されています。
スター スキーマでは、中央のファクト テーブルとサイド ディメンション テーブルの間の関係を構築する結合は 1 つだけです。 一方、スノーフレーク スキーマでは、ディメンション テーブルにリンクするために複数の結合が必要です。
スター スキーマは通常、ディメンション テーブルの行数が少ない場合に使用されますが、スノーフレーク スキーマはディメンション テーブルが比較的大きい場合に使用されます。
次の図は、2 つのモデルを区別し、ディメンション テーブルとファクト テーブルが異なるスキーマでどのようにリンクされているかを示しています。
| パラメーター | スタースキーマ | スノーフレーク スキーマ |
| ディスクスペース | スター スキーマはより多くのディスク領域を使用します。 | Snowflake スキーマは、使用するディスク容量が少なくなります。 |
| データの冗長性 | データの冗長性が高い。 | データの冗長性が低い。 |
| 正規化 | ディメンション テーブルは非正規化されています。つまり、テーブル内で同じ値が繰り返されます。 | ディメンション テーブルは完全に正規化されています。 |
| クエリのパフォーマンス | クエリの実行にかかる時間が最小限になるため、パフォーマンスが向上します。 | クエリの実行にスター スキーマよりも時間がかかるため、スター スキーマよりもパフォーマンスが低下します。 |
| クエリの複雑さ | クエリの複雑さは低いです。 | クエリの複雑さは、スター スキーマよりも高くなります。 |
| メンテナンス | データの冗長性が高いため、スター スキーマを維持するのは少し困難です。 | データの冗長性が低いため、スノーフレーク スキーマの維持と変更は簡単です。 |
| データの整合性 | ディメンション テーブルに複数のコピーが存在する場所にデータが冗長的に格納されるため、データの整合性が高くなります。 | ディメンション テーブルを完全に正規化するため、データの整合性は低くなります。 |
| 階層 | スター スキーマのディメンション テーブルの階層は、ディメンション テーブルに格納されます。 | 階層は個別のディメンション テーブルに分割されます。 |
| DB設計 | シンプルなDB設計です。 | 非常に複雑な DB 設計になっています。 |
| ファクト テーブル | 複数のディメンション テーブルがファクト テーブルを囲んでいます。 | ファクト テーブルは、サブディメンション テーブルに囲まれたディメンション テーブルに囲まれています。 |
| 設定 | スター スキーマは、直接的な関係を表すため、簡単に設計および設定できます。 | 一方、スノーフレーク スキーマの設定は少し複雑です。 |
| キューブ処理 | キューブ処理が高速です。 | 結合が複雑なため、キューブの処理が少し遅くなります。 |
| 外部キー | 最小数の外部キーがあります。 | 最大数の外部キーがあります。 |
結論
スター スキーマとスノーフレーク スキーマはどちらも、さまざまな分野で役立ちます。 そのため、どちらが優れているかは、要件に基づいて決定します。
スノーフレーク スキーマは、スター スキーマの拡張であり、スター スキーマのディメンション テーブルを正規化します。
スター スキーマは設計がシンプルで、クエリの実行が速く、セットアップも簡単です。 一方、スノーフレーク スキーマは保守が容易で、必要なディスク容量が少なく、データ整合性の問題が発生しにくいです。
そのため、単純な設計、少ない外部キー、高速なキューブ処理が必要な場合は、スター スキーマの方が適している可能性があります。 ただし、必要なディスク容量が少なく、データの整合性が低く、メンテナンスが少ない場合は、スノーフレーク スキーマの方が適している可能性があります。
また、最適なグラフ データベース ソリューションを検討することもできます。