Jak znaleźć i naprawić problemy z pokryciem indeksu
Jak znaleźć i naprawić problemy z pokryciem indeksu
Opublikowany: 2020-10-29
Czy masz problemy z indeksowaniem Google?Ten problem może prowadzić do spadku ruchu i współczynników konwersji.
Aby szybko rozwiązać każdy problem, konieczne jest sprawdzenie zaindeksowanych i niezaindeksowanych stron Twojej witryny .Tutaj wyjaśniamy krok po kroku, jak to zrobić za pomocą Google Search Console – Raport pokrycia indeksu .
Za pomocą poniższej metody udało nam się naprawić problemy z pokryciem indeksu w setkach witryn z milionami lub miliardami wykluczonych stron.Użyj go, aby żadna z Twoich odpowiednich stron nie straciła widoczności w wynikach wyszukiwania i zwiększ ruch SEO!
Spis treści
Krok 1: Sprawdź raport pokrycia indeksu
Raport dotyczący zasięgu w Search Console informuje, które strony zostały zindeksowane i zaindeksowane przez Google oraz dlaczego adresy URL są w tym konkretnym stanie.Możesz go użyć dowykrycia wszelkich błędów znalezionych podczas przeszukiwania i indeksowania .
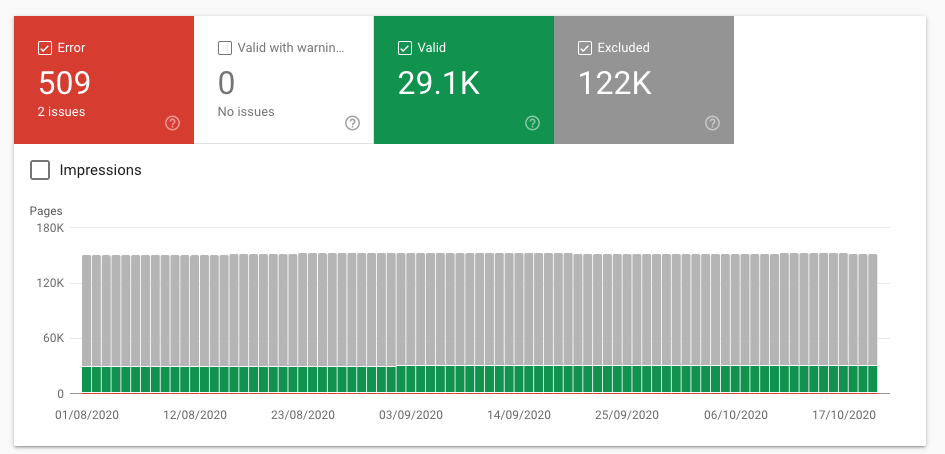
Aby sprawdzić raport pokrycia indeksu, przejdź do Google Search Console i kliknij Pokrycie (tuż pod Indeksem).Gdy go otworzysz, zobaczysz podsumowanie z czterema różnymi stanami, które kategoryzują Twoje adresy URL:
Błąd: te strony nie mogą zostać zindeksowane i nie pojawią się w wynikach wyszukiwania z powodu niektórych błędów.
Prawidłowe z ostrzeżeniami: te strony mogą, ale nie muszą być wyświetlane w wynikach wyszukiwania Google.
Prawidłowy: te strony zostały zindeksowane i mogą być wyświetlane w wynikach wyszukiwania.Nie musisz nic robić.
Wykluczono: te strony nie zostały zindeksowane i nie pojawią się w wynikach wyszukiwania.Google uważa, że nie chcesz ich indeksować lub uważasz, że treść nie jest warta indeksowania.
Musisz sprawdzić wszystkie strony znalezione w sekcji Błąd i poprawić je JAK NAJSZYBCIEJ, ponieważ możesz stracić możliwość przyciągnięcia ruchu do swojej witryny.
Jeśli masz czas, spójrz na strony zawarte w stanieWażna z ostrzeżeniem , ponieważ mogą istnieć pewne ważne strony, które w żadnym wypadku nie powinny nie pojawiać się w wynikach wyszukiwania.
Na koniec upewnij się, żewykluczone strony to te, których nie chcesz indeksować.
Krok 2: Jak rozwiązać problemy znalezione w każdym ze stanów pokrycia indeksu?
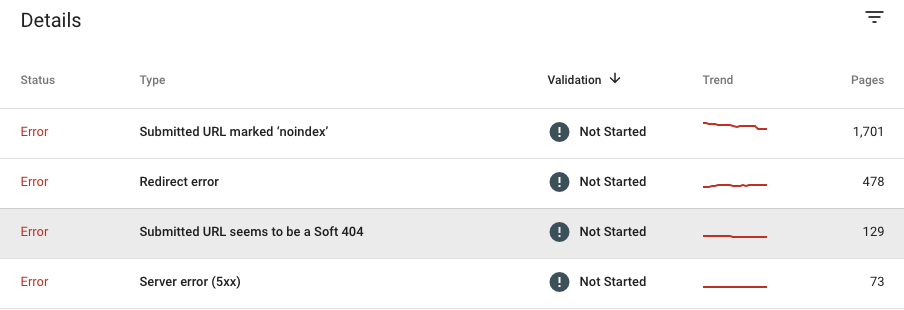
Po otwarciu Raportu pokrycia indeksu wybierz żądany stan (Błędy, Ważny z ostrzeżeniami lub Wykluczony) i zobacz szczegóły podane na dole strony.Listętypów błędów znajdziesz według ich wagi i liczby stron, których one dotyczą,dlatego zalecamy rozpoczęcie ich badania od góry tabeli.
Zobaczmy każdy z błędów w różnych stanach i zobaczmy, jak możesz je naprawić.
Stan błędu
Błędy serwera (5xx):
Są to adresy URL zwracające kod stanu 5xx do Google.
Działania do podjęcia:
Sprawdź, jaki kod statusu 500 zwraca .Tutaj masz pełną listę z definicją każdego kodu stanu błędu serwera.
Załaduj ponownie adres URL, aby sprawdzić, czy błąd nadal występuje.Błędy 5xx są tymczasowe i nie wymagają żadnych działań.
Sprawdź, czy Twój serwer nie jest przeciążony lub źle skonfigurowany.W takim przypadku poproś programistów o pomoc lub skontaktuj się z dostawcą usług hostingowych.
Wykonaj analizę pliku dziennika , aby sprawdzić dzienniki błędów serwera.Ta praktyka zapewnia dodatkowe informacje o problemie.
Przejrzyj zmiany, które ostatnio wprowadziłeś w swojej witrynie, aby sprawdzić, czy któryś z nich może być główną przyczyną.np. wtyczki, nowy kod zaplecza itp.
Błędy przekierowania:
GoogleBot napotkał błąd podczas procesu przekierowania, który nie pozwala na indeksowanie strony.Każdy z poniższych powodów często powoduje ten problem.
Zbyt długi łańcuch przekierowań
Pętla przekierowania
Adres URL przekierowania, który przekroczył maksymalną długość adresu URL
W łańcuchu przekierowań był błędny lub pusty adres URL
Działania do podjęcia:
Wyeliminuj łańcuchy i pętle przekierowań.Niech każdy adres URL wykonuje tylko jedno przekierowanie.Innymi słowy, przekierowanie z pierwszego adresu URL do ostatniego.
Przesłany adres URL zablokowany przez plik Robots.txt:
Są to adresy URL, które zostały przesłane do Google podczas przesyłania mapy witryny XML do Google Search Console, ale zostały zablokowane przez plik Robots.txt.
Działania do podjęcia:
Sprawdź, czy chcesz, aby wyszukiwarki indeksowały daną stronę, czy nie.
Jeśli nie chcesz, aby była indeksowana, prześlij mapę witryny XML usuwającą adres URL.
Wręcz przeciwnie, jeśli chcesz, aby był indeksowany, zmień wytyczne w pliku Robots.txt. Oto przewodnik dotyczący edytowania pliku robots.txt.
Przesłany adres URL oznaczony „noindex”:
Te strony zostały przesłane do Google za pomocą mapy witryny XML, ale mają dyrektywę „noindex” w metatagu robots lub w nagłówkach HTTP.
Działania do podjęcia:
Jeśli chcesz, aby adres URL był indeksowany, powinieneś usunąć dyrektywę noindex
Jeśli istnieją adresy URL, których Google nie ma indeksować, usuń je z mapy witryny XML
Przesłany adres URL wydaje się być miękkim 404:
Adres URL przesłany za pośrednictwem mapy witryny XML do celów indeksowania zwraca miękki błąd 404 .Ten błąd występuje, gdy serwer zwraca kod stanu 200 do żądania, ale Google uważa, że powinien wyświetlić błąd 404. Innymi słowy, strona wygląda dla Google jak błąd 404.W niektórych przypadkach może to być spowodowane brakiem treści, błędną lub niską jakością strony dla Google.
Działania do podjęcia:
Sprawdź, czy te adresy URL powinny zwracać (rzeczywisty) kod stanu 404.W takim przypadku usuń je z mapy witryny XML.
Jeśli uznasz, że nie powinny zwracać błędu, upewnij się, że na tych stronach zamieszczasz odpowiednią treść.Unikaj cienkich lub zduplikowanych treści.Sprawdź, czy jeśli istnieją przekierowania, są one poprawne.
Adres URL przesłany do Google za pośrednictwem mapy witryny XML zwraca błąd 401 .Ten kod stanu informuje, że nie masz uprawnień dostępu do adresu URL.Możesz potrzebować nazwy użytkownika i hasła, a może istnieją ograniczenia dostępu oparte na adresie IP.
Działania do podjęcia:
Sprawdź, czy adresy URL powinny zwracać 401. W takim przypadku usuń je z mapy witryny XML.
Jeśli nie chcesz, aby wyświetlały kod 401, usuń uwierzytelnianie HTTP, jeśli takie istnieje.
Nie znaleziono przesłanego adresu URL (404):
Przesłałeś adres URL do indeksowania do Google Search Console, ale Google nie może go zaindeksować z powodu problemu innego niż wymienione powyżej.
Działania do podjęcia:
Sprawdź, czy chcesz, aby strona była indeksowana, czy nie.Jeśli odpowiedź brzmi tak, napraw to, aby zwracał kod stanu 200.Możesz również przypisać przekierowanie 301 do adresu URL, aby wyświetlał odpowiednią stronę.Pamiętaj, że jeśli zdecydujesz się na przekierowanie, musisz dodać przypisany adres URL do mapy witryny XML i usunąć ten, który daje 404.
Jeśli nie chcesz, aby strona była indeksowana, usuń ją z mapy witryny XML.
Przesłany adres URL ma problem z indeksowaniem:
Adres URL został przesłany do GSC w celu zindeksowania, ale Google nie może go zindeksować z powodu problemu innego niż wymienione powyżej.
Działania do podjęcia:
Użyj narzędzia do sprawdzania adresów URL, aby uzyskać więcej informacji na temat przyczyny problemu.
Czasami te błędy są tymczasowe, więc nie wymagają żadnych działań.
Obowiązuje ze statusem ostrzeżenia
Te strony są indeksowane, chociaż są blokowane przez plik robots.txt.Google zawsze stara się przestrzegać instrukcji podanych w pliku robots.txt.Czasami jednak zachowuje się inaczej.Może się to zdarzyć na przykład, gdy ktoś linkuje do podanego adresu URL.
Znajdujesz adresy URL w tej kategorii, ponieważ Google wątpi, czy chcesz blokować te strony w wynikach wyszukiwania .
Działania do podjęcia:
Google nie zaleca używania pliku robots.txt w celu uniknięcia indeksacji strony.Zamiast tego, jeśli nie chcesz, aby te strony były indeksowane, użyj noindex w robotach meta lub nagłówka odpowiedzi HTTP.
Inną dobrą praktyką uniemożliwiającą Google dostęp do strony jest wdrożenie uwierzytelniania HTTP.
Jeśli nie chcesz blokować strony, wprowadź niezbędne poprawki w pliku robots.txt.
Za pomocą testera pliku robots.txtmożesz określić, która reguła blokuje stronę.
Natzira Turrado, Doradca Fandango SEO Niezależny techniczny SEO @ Natzir Turrado
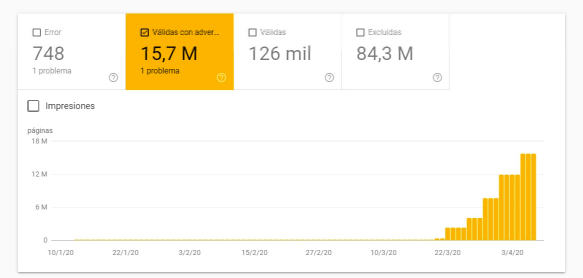
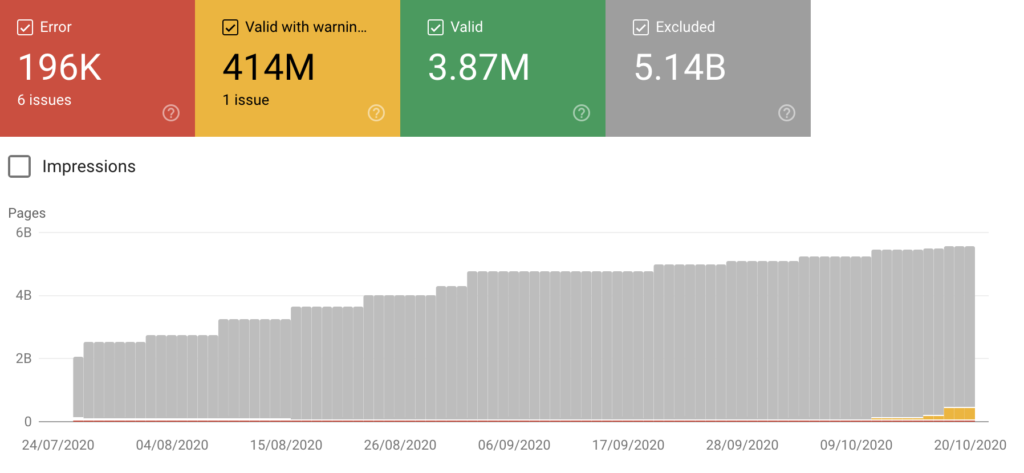
Podczas dużej migracji do SalesForce poprosiliśmy programistów, aby filtry, których nie chcieliśmy indeksować, były niedostępne (zaciemnione). Kiedy strona Salesforce została uruchomiona, wszystko zakończyło się sukcesem. Ale kiedy nowa wersja została wydana kilka miesięcy później, zaciemnienie zostało przypadkowo złamane. To wywołało wszystkie alarmy, ponieważ w ciągu zaledwie siedmiu dni było około 17,5 miliona żądań Googlebot-Mobile i około 12,5 miliona Googlebot/2,1, a także pamięć podręczna wskaźnika trafień na poziomie 2%. Poniżej możesz zobaczyć w Search Console, jak wzrosła liczba stron indeksowanych, ale blokowanych przez roboty.
Dlatego zalecam ciągłe monitorowanie dzienników i przeglądanie raportu GSC Coverage Report (chociaż wcześniej wykryjesz każdy problem, sprawdzając dzienniki). I pamiętaj, że plik robots.txt nie zapobiega indeksowaniu stron. Jeśli chcesz, aby Google nie indeksowało adresu URL, najlepiej uniemożliwić dostęp do adresu URL!
Wykluczony stan
Te strony nie są indeksowane w wynikach wyszukiwania, a Google uważa, że to słuszne.Na przykład może to być spowodowane tym, że są to zduplikowane strony zindeksowanych stron lub ponieważ dajesz wyszukiwarkom wytyczne dotyczące ich indeksowania.
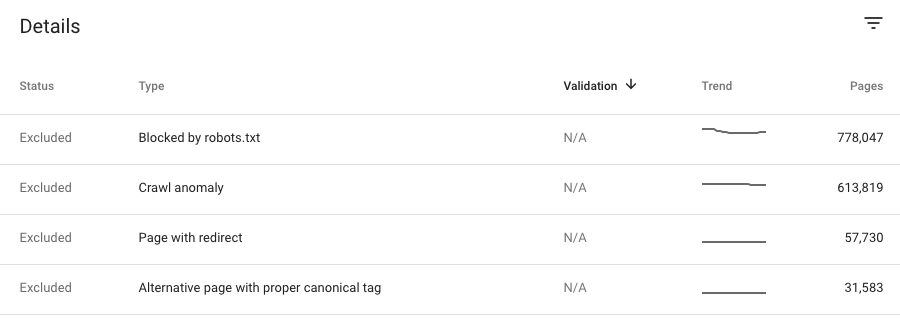
Raport Zasięg pokazuje 15 sytuacji, w których Twoja strona może zostać wykluczona .
Wykluczone przez tag „noindex”:
Mówisz wyszukiwarkom, aby nie indeksowały strony, podając dyrektywę „noindex”.
Działania do podjęcia:
Sprawdź, czy rzeczywiście nie chcesz indeksować strony.Jeśli chcesz, aby strona była indeksowana, usuń tag „noindex”.
Możesz potwierdzić obecność tej dyrektywy, otwierając stronę i wyszukując „noindex” w treści odpowiedzi i nagłówku odpowiedzi.
Zablokowane przez narzędzie do usuwania stron:
Przesłałeśprośbę o usunięcie adresów URL tych stron w GSC.
Działania do podjęcia:
Google obsługuje to żądanie tylko przez 90 dni, więc jeśli nie chcesz indeksować strony, użyj dyrektyw „noindex”, zaimplementuj uwierzytelnianie HTTP lub usuń stronę.
Zablokowany przez plik robots.txt:
Za pomocą pliku robots.txt blokujesz dostęp Googlebotowi do tych stron.Jednak nadal mógłby zostać zindeksowany, gdyby Google mógł znaleźć informacje o tej stronie bez jej ładowania.Być może Google zindeksował stronę przed dodaniem zakazu w robots.txt
Działania do podjęcia:
Jeśli nie chcesz, aby strona była indeksowana, użyj dyrektywy „noindex” i usuń blok robots.txt.
Zablokowane z powodu nieautoryzowanego żądania (401):
Blokujesz dostęp do Google za pomocą autoryzacji żądania (odpowiedź 401).
Działania do podjęcia:
Jeśli chcesz zezwolić GoogleBotowi na odwiedzanie strony, usuń wymagania dotyczące autoryzacji.
Anomalia indeksowania:
Strona nie została zindeksowana z powodu kodu odpowiedzi błędu 4xx lub 5xx.
Działania do podjęcia:
Użyj narzędzia do sprawdzania adresów URL, aby uzyskać więcej informacji o problemach.
Zindeksowana — obecnie nieindeksowana
Ta strona została zindeksowana przez GoogleBota, ale nie została zindeksowana.Może, ale nie musi być indeksowany w przyszłości.Nie ma potrzeby przesyłania tego adresu URL do indeksowania.
Działania do podjęcia:
Jeśli chcesz, aby strona była indeksowana w wynikach wyszukiwania, upewnij się, że podajesz cenne informacje.
Odkryto – obecnie nieindeksowane:
Google znalazł tę stronę, ale jeszcze nie zdołał jej zaindeksować .Taka sytuacja zwykle ma miejsce, ponieważ gdy GoogleBot próbował zindeksować stronę, witryna była przeciążona.Indeksowanie zostało zaplanowane na inny czas.
Nie jest wymagane żadne działanie.
Alternatywna strona z odpowiednim znacznikiem kanonicznym:
Ta strona wskazuje na stronę kanoniczną, więc Google rozumie, że nie chcesz jej indeksować.
Działania do podjęcia:
Jeśli chcesz zindeksować tę stronę, musisz zmienićatrybuty rel=canonical, aby dać Google pożądane wytyczne.
Duplikuj bez kanonicznego wybranego przez użytkownika:
Strona ma duplikaty, ale żaden z nich nie jest oznaczony jako kanoniczny.Google uważa, że ten nie jest kanoniczny.
Działania do podjęcia:
Użyj tagów kanonicznych, aby wyjaśnić Google, które strony są kanoniczne (musi być zindeksowane), a które są duplikatami.Możesz użyć narzędzia do sprawdzania adresów URL, aby zobaczyć, które strony zostały wybrane przez Google jako kanoniczne.
Duplikat, Google wybrał inny kanoniczny niż użytkownik:
Oznaczyłeś tę stronę jako kanoniczną, ale zamiast tego Google zindeksował inną stronę, która uważa, że działa lepiej jako kanoniczna.
Działania do podjęcia:
Możesz śledzić wybór Google.W takim przypadku oznacz zindeksowaną stronę jako kanoniczną, a tę jako duplikat kanonicznego adresu URL.
Jeśli nie, dowiedz się, dlaczego Google preferuje inną stronę niż wybraną przez Ciebie, i wprowadź niezbędne zmiany.Użyj narzędzia do sprawdzania adresów URL, aby odkryć „stronę kanoniczną” wybraną przez Google.
Ferran Gavin, Menedżer SEO @ Softonic
Jedną z najciekawszych „porażek”, jakich doświadczyliśmy w przypadku Raportu o pokryciu indeksu, było stwierdzenie, że Google nie przetwarza poprawnie naszych kanonicznych treści (i robiliśmy to źle przez lata!). Google wskazywało w Search Console, że określony kanoniczny jest nieprawidłowy, gdy strona była doskonale sformatowana. W końcu okazało się, że to błąd samego Google, potwierdzony przez Gary'ego Ilyesa.
Nie znaleziono (404):
Strona zwraca kod stanu błędu 404, gdy Google wysyła żądanie .GoogleBot nie znalazł strony za pomocą mapy witryny, ale prawdopodobnie za pośrednictwem innej witryny z linkiem do adresu URL.Możliwe też, że ten adres URL istniał w przeszłości i został usunięty.
Działania do podjęcia:
Jeśli odpowiedź 404 jest zamierzona, możesz ją pozostawić bez zmian.Nie zaszkodzi to wydajności SEO.Jeśli jednak strona została przeniesiona, zaimplementuj przekierowanie 301.
Strona usunięta z powodu skargi prawnej:
Ta strona została usunięta z indeksu z powoduskargi prawnej.
Działania do podjęcia:
Sprawdź, jakie przepisy prawne mogłeś naruszyć, i podejmij niezbędne działania, aby to naprawić.
Strona z przekierowaniem:
Ten adres URL jest przekierowaniem i dlatego nie został zindeksowany.
Działania do podjęcia:
Jeśli adres URL nie miał przekierowywać, usuń implementację przekierowania.
Miękki 404:
Strona zwraca to, co według Google jest miękką odpowiedzią 404.Strona nie jest indeksowana, ponieważ chociaż podaje kod stanu 200, Google uważa, że powinna zwracać błąd 404 .
Działania do podjęcia:
Sprawdź, czy należy przypisać 404 do strony, jak sugeruje Google.
Dodaj wartościową treść do strony, aby poinformować Google, że nie jest to Soft 404.
Zduplikowany, przesłany adres URL, który nie został wybrany jako kanoniczny:
Przesłałeś adres URL do GSC w celu indeksowania.Mimo to nie została zindeksowana, ponieważ strona ma duplikaty bez tagów kanonicznych, a Google uważa, że jest lepszy kandydat na kanoniczną.
Działania do podjęcia:
Zdecyduj, czy chcesz śledzić wybór Google dotyczący strony kanonicznej.W takim przypadku przypiszatrybuty rel=canonical, aby wskazywały stronę wybraną przez Google.
Możesz użyć narzędzia do sprawdzania adresów URL, aby zobaczyć, która strona została wybrana przez Google jako strona kanoniczna.
Jeśli chcesz, aby ten adres URL był kanoniczny, przeanalizuj, dlaczego Google preferuje inną stronę.Oferuj więcej wartościowych treści na wybranej stronie.
Krok 3. Raport dotyczący pokrycia indeksu Najczęstsze problemy
Teraz znasz różne rodzaje błędów, które można znaleźć w raporcie Pokrycie indeksu i jakie działania podjąć, gdy napotkasz każdy z nich.Poniżej znajduje się krótki przegląd najczęściej pojawiających się problemów.
Więcej wykluczonych niż prawidłowe strony
Czasami możesz mieć więcej stron wykluczonych niż prawidłowych.Ta okoliczność ma zwykle miejsce w przypadku dużych witryn, w których nastąpiła znacząca zmiana adresu URL .Prawdopodobnie jest to stara witryna z długą historią lub zmodyfikowany kod sieciowy.
Jeśli masz znaczną różnicę między liczbą stron dwóch statusów (Wykluczone i Prawidłowe), masz poważny problem.Zacznij przeglądać wykluczone strony, jak wyjaśniliśmy powyżej.
Esteve Castells, Group SEO Manager @ Adevinta
Największym problemem, jaki kiedykolwiek widziałem w Raporcie o zasięgu, jest jedna z zarządzanych przeze mnie witryn, która ostatecznie zawierała 5 miliardów wykluczonych stron.Tak, dobrze przeczytałeś, 5 miliardów stron.Nawigacja fasetowa oszalała i dla każdej odsłony tworzyliśmy 20 nowych adresów URL, które Googlebot miał zaindeksować.
Okazało się to najdroższym błędem pod względem indeksowania, jaki kiedykolwiek powstał.Musieliśmy całkowicie zabronić w pliku robots.txt adresów URL nawigacji z aspektami, ponieważ Googlebot wyłączał nasz serwer z ponad 25 milionami trafień dziennie.
Skoki błędów
Gdy liczba błędów rośnie wykładniczo, musisz sprawdzić błąd i naprawić go JAK NAJSZYBCIEJ.Wykryliśmy problem, który poważnie wpływa na wydajność Twojej witryny .Jeśli nie naprawisz tego problemu dzisiaj, jutro będziesz mieć poważne problemy.
Błędy serwera
Upewnij się, że te błędy nie są 503 (Usługa niedostępna) .Ten kod stanu oznacza, że serwer nie może obsłużyć żądania z powodu tymczasowego przeciążenia lub konserwacji.Na początku błąd powinien sam zniknąć, ale jeśli będzie się powtarzał, musisz przyjrzeć się problemowi i go rozwiązać.
Jeśli masz inne rodzaje błędów 5xx, zalecamy zapoznanie się z naszym przewodnikiem, aby zobaczyć, jakie działania należy podjąć w każdym przypadku.
Błędy 404
Wygląda na to, że Google wykrył jakiś obszar Twojej witryny, który generuje błąd 404 – nie znaleziono stron.Jeśli głośność znacznie wzrośnie, przejrzyj nasz przewodnik, aby znaleźć i naprawić uszkodzone linki.
Brakujące strony lub witryny
Jeśli nie widzisz strony lub witryny w raporcie, może to być spowodowane kilkoma przyczynami.
Google jeszcze tego nie odkrył.Gdy strona lub witryna jest nowa, znalezienie jej przez Google może zająć trochę czasu.Prześlij mapę witryny lub żądanie indeksowania strony, aby przyspieszyć proces indeksowania.Upewnij się również, że strona nie jest osierocona i zawiera link z witryny.
Google nie może uzyskać dostępu do Twojej strony z powodu żądania logowania .Usuń wymagania dotyczące autoryzacji, aby umożliwić robotowi GoogleBot indeksowanie strony.
Strona ma tag noindex lub z jakiegoś powodu została usunięta z indeksu .Usuń tag noindex i upewnij się, że dostarczasz wartościowe treści na stronie.
Błędy i wykluczenia „Przesłano ale/Przesłano i”
Ten problem występuje, gdy występuje niezgodność.Jeśli wysyłasz stronę przez mapę witryny, musisz upewnić się, że nadaje się ona do indeksowania i jest połączona z witryną.
Twoja witryna powinna składać się głównie z wartościowych stron, które warto połączyć.
Streszczenie
Oto trzyetapowe podsumowanie artykułu „Jak znaleźć i naprawić błędy pokrycia indeksu”.
Pierwszą rzeczą, którą chcesz zrobić podczas korzystania z raportu pokrycia indeksu, jest naprawienie stron, które pojawiają się w stanie Błąd .Musi to być 0, aby uniknąć kar Google.
Po drugie, sprawdź wykluczone strony i zobacz, czy nie są to strony, których nie chcesz indeksować.Jeśli tak nie jest, postępuj zgodnie z naszymi wskazówkami, aby rozwiązać problemy.
Jeśli masz czas, zdecydowanie zalecamy sprawdzenie prawidłowych stron z ostrzeżeniem .Upewnij się, że wytyczne podane w pliku robots.txt są poprawne i nie ma niespójności.
Mamy nadzięję, że uznasz to za pomocne!Daj nam znać, jeśli masz jakiekolwiek pytania dotyczące raportu pokrycia indeksu.Chcielibyśmy również usłyszeć wszelkie wskazówki od Ciebie w komentarzach poniżej.