So finden und beheben Sie Probleme mit der Indexabdeckung
So finden und beheben Sie Probleme mit der Indexabdeckung
Veröffentlicht: 2020-10-29
Haben Sie Probleme mit der Google-Indexierung?Dieses Problem kann zu sinkenden Zugriffszahlen und Conversion-Raten führen.
Es ist notwendig, die indizierten und nicht indizierten Seiten Ihrer Website zu überprüfen, um Probleme schnell zu lösen .Hier erklären wir Schritt für Schritt, wie es mit dem Google Search Console – Index Coverage Report geht .
Mit der folgenden Methode ist es uns gelungen, Probleme mit der Indexabdeckung auf Hunderten von Websites mit Millionen oder Milliarden ausgeschlossener Seiten zu beheben.Verwenden Sie es, damit keine Ihrer relevanten Seiten in den Suchergebnissen an Sichtbarkeit verliert, und steigern Sie Ihren SEO-Traffic!
Inhaltsverzeichnis
Schritt 1: Überprüfen Sie den Bericht zur Indexabdeckung
Der Search Console Coverage Report zeigt Ihnen, welche Seiten von Google gecrawlt und indexiert wurden und warum sich die URLs in diesem bestimmten Zustand befinden.Sie können es verwenden,um alle Fehler zu erkennen, die während des Crawling- und Indizierungsprozesses gefunden wurden .
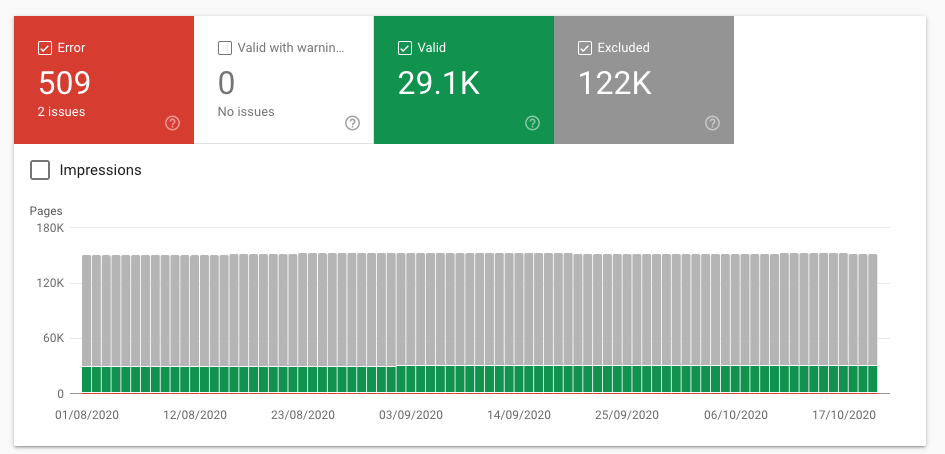
Um den Bericht zur Indexabdeckung zu überprüfen, gehen Sie zur Google Search Console und klicken Sie auf Abdeckung (direkt unter Index).Sobald Sie es öffnen, sehen Sie eine Zusammenfassung mit vier verschiedenen Status, die Ihre URLs kategorisieren:
Fehler: Diese Seiten können nicht indexiert werden und erscheinen aufgrund einiger Fehler nicht in den Suchergebnissen.
Gültig mit Warnungen: Diese Seiten können in den Google-Suchergebnissen angezeigt werden oder nicht.
Gültig: Diese Seiten wurden indiziert und können in den Suchergebnissen angezeigt werden.Sie müssen nichts tun.
Ausgeschlossen: Diese Seiten wurden nicht indexiert und erscheinen nicht in den Suchergebnissen.Google glaubt, dass Sie sie nicht indexieren möchten oder der Meinung sind, dass der Inhalt keine Indexierung wert ist.
Sie müssen alle im Fehlerbereich gefundenen Seiten überprüfenund so schnell wie möglich korrigieren, da Sie möglicherweise die Gelegenheit verpassen, den Verkehr auf Ihre Website zu lenken.
Wenn Sie Zeit haben, schauen Sie sich die Seiten an, die im StatusGültig mit Warnung enthalten sind, da es einige wichtige Seiten geben kann, die unter keinen Umständen in den Suchergebnissen fehlen sollten.
Stellen Sie schließlich sicher, dass dieausgeschlossenen Seiten diejenigen sind, die Sie nicht indizieren möchten.
Schritt 2: So lösen Sie die Probleme, die in jedem Indexabdeckungsstatus gefunden werden
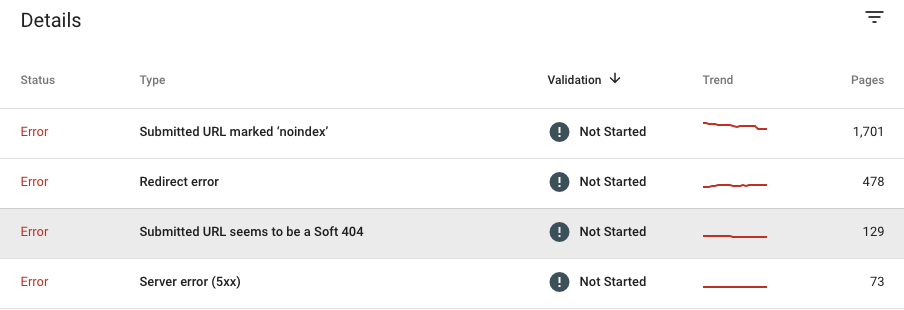
Nachdem Sie den Indexabdeckungsbericht geöffnet haben, wählen Sie den gewünschten Status aus (Fehler, Gültig mit Warnungen oder Ausgeschlossen) und sehen Sie sich die Details unten auf der Seite an.Sie finden eine Liste derFehlertypen nach Schweregrad und Anzahl der betroffenen Seiten.Wir empfehlen daher, mit der Untersuchung der Probleme am Anfang der Tabelle zu beginnen.
Lassen Sie uns jeden der Fehler in verschiedenen Status sehen und wie Sie sie beheben können.
Fehlerstatus
Serverfehler (5xx):
Dies sind URLs, die einen 5xx-Statuscode an Google zurücksenden.
Zu ergreifende Maßnahmen:
Überprüfen Sie, welche Art von 500-Statuscode zurückgegeben wird .Hier haben Sie eine vollständige Liste mit der Definition für jeden Serverfehlerstatuscode.
Laden Sie die URL neu, um zu sehen, ob der Fehler weiterhin besteht.5xx-Fehler sind vorübergehend und erfordern keine Aktion.
Stellen Sie sicher, dass Ihr Server nicht überlastet oder falsch konfiguriert ist.Bitten Sie in diesem Fall Ihre Entwickler um Hilfe oder wenden Sie sich an Ihren Hosting-Provider.
Führen Sie eine Protokolldateianalyse durch, um die Fehlerprotokolle für Ihren Server zu überprüfen.Diese Übung bietet Ihnen zusätzliche Informationen zu diesem Problem.
Überprüfen Sie die Änderungen, die Sie kürzlich an Ihrer Website vorgenommen haben, um festzustellen, ob eine davon die Hauptursache sein könnte.ex) Plugins, neuer Backend-Code usw.
Umleitungsfehler:
Der GoogleBot hat während des Umleitungsprozesses einen Fehler festgestellt, der das Crawlen der Seite nicht zulässt.Einer der folgenden Gründe verursacht häufig dieses Problem.
Eine zu lange Weiterleitungskette
Eine Umleitungsschleife
Eine Umleitungs-URL, die die maximale URL-Länge überschritten hat
Es gab eine falsche oder leere URL in der Weiterleitungskette
Zu ergreifende Maßnahmen:
Beseitigen Sie die Umleitungsketten und -schleifen.Lassen Sie jede URL nur eine Weiterleitung durchführen.Mit anderen Worten, eine Weiterleitung von der ersten URL zur letzten.
Eingesendete URL von Robots.txt blockiert:
Dies sind URLs, die Sie an Google übermittelt haben, indem Sie eine XML-Sitemap in die Google Search Console hochgeladen haben, aber von der Robots.txt-Datei blockiert wurden.
Zu ergreifende Maßnahmen:
Überprüfen Sie, ob Suchmaschinen die betreffende Seite indexieren sollen oder nicht.
Wenn Sie nicht möchten, dass sie indexiert wird, laden Sie eine XML-Sitemap hoch, aus der die URL entfernt wird.
Im Gegenteil, wenn Sie möchten, dass es indiziert wird, ändern Sie die Richtlinien in der Robots.txt. Hier ist eine Anleitung zum Bearbeiten von robots.txt.
Eingereichte URL mit der Kennzeichnung „noindex“:
Diese Seiten wurden über eine XML-Sitemap an Google übermittelt, aber sie haben entweder im Meta-Robots-Tag oder im HTTP-Header eine „noindex“-Anweisung.
Zu ergreifende Maßnahmen:
Wenn Sie möchten, dass die URL indexiert wird, sollten Sie die Direktive noindex entfernen
Wenn Sie nicht möchten, dass Google URLs indexiert, entfernen Sie sie aus der XML-Sitemap
Die übermittelte URL scheint ein Soft 404 zu sein:
Die URL, die Sie zu Indizierungszwecken über eine XML-Sitemap übermittelt haben, gibt einen Soft 404 zurück .Dieser Fehler tritt auf, wenn der Server einen 200-Statuscode auf eine Anfrage zurückgibt, aber Google glaubt, dass er einen 404 anzeigen sollte. Mit anderen Worten, die Seite sieht für Google wie ein 404-Fehler aus.In einigen Fällen kann dies daran liegen, dass die Seite keinen Inhalt hat, falsch erscheint oder für Google von geringer Qualität ist.
Zu ergreifende Maßnahmen:
Untersuchen Sie, ob diese URLs einen (echten) 404-Statuscode zurückgeben sollten.Entfernen Sie sie in diesem Fall aus der XML-Sitemap.
Wenn Sie feststellen, dass sie keinen Fehler zurückgeben sollten, stellen Sie sicher, dass Sie auf diesen Seiten entsprechende Inhalte bereitstellen.Vermeiden Sie dünne oder doppelte Inhalte.Überprüfen Sie, ob Umleitungen korrekt sind.
Die gesendete URL gibt eine nicht autorisierte Anfrage zurück (401):
Die über eine XML-Sitemap an Google übermittelte URL gibt einen 401-Fehler zurück .Dieser Statuscode teilt Ihnen mit, dass Sie nicht berechtigt sind, auf die URL zuzugreifen.Möglicherweise benötigen Sie einen Benutzernamen und ein Passwort, oder es gibt Zugriffsbeschränkungen basierend auf der IP-Adresse.
Zu ergreifende Maßnahmen:
Überprüfen Sie, ob die URLs einen 401-Fehler zurückgeben sollen. Entfernen Sie sie in diesem Fall aus der XML-Sitemap.
Wenn Sie nicht möchten, dass sie einen 401-Code anzeigen, entfernen Sie die HTTP-Authentifizierung, falls vorhanden.
Übermittelte URL nicht gefunden (404):
Sie haben die URL zu Indizierungszwecken an die Google Search Console übermittelt, aber Google kann sie aufgrund eines anderen Problems als den oben genannten nicht crawlen .
Zu ergreifende Maßnahmen:
Prüfen Sie, ob die Seite indexiert werden soll oder nicht.Wenn die Antwort ja ist, beheben Sie das Problem, sodass ein Statuscode 200 zurückgegeben wird.Sie können der URL auch eine 301-Weiterleitung zuweisen, damit sie eine passende Seite anzeigt.Denken Sie daran, dass Sie, wenn Sie sich für eine Weiterleitung entscheiden, die zugewiesene URL zur XML-Sitemap hinzufügen und diejenige entfernen müssen, die einen 404 ergibt.
Wenn Sie nicht möchten, dass die Seite indexiert wird, entfernen Sie sie aus der XML-Sitemap.
Die eingereichte URL hat ein Crawling-Problem:
Sie haben die URL zu Indexierungszwecken an GSC übermittelt, sie kann jedoch aufgrund eines anderen Problems als den oben genannten nicht von Google gecrawlt werden.
Zu ergreifende Maßnahmen:
Verwenden Sie das URL-Prüftool, um weitere Informationen zur Ursache des Problems zu erhalten.
Manchmal sind diese Fehler vorübergehend, sodass keine Maßnahmen erforderlich sind.
Gültig mit Warnstatus
Diese Seiten werden indexiert, obwohl sie durch die robots.txt blockiert werden.Google versucht immer, die Anweisungen in der robots.txt-Datei zu befolgen.Manchmal verhält es sich jedoch anders.Dies kann beispielsweise passieren, wenn jemand auf die angegebene URL verlinkt.
Sie finden die URLs in dieser Kategorie, weil Google bezweifelt, ob Sie diese Seiten in den Suchergebnissen blockieren möchten .
Zu ergreifende Maßnahmen:
Google rät davon ab, die robots.txt-Datei zu verwenden, um eine Seitenindexierung zu vermeiden.Wenn Sie diese Seiten nicht indexiert sehen möchten, verwenden Sie stattdessen noindex in den Meta-Robotern oder einen HTTP-Antwort-Header.
Eine weitere bewährte Vorgehensweise, um Google am Zugriff auf die Seite zu hindern, ist die Implementierung einer HTTP-Authentifizierung.
Wenn Sie die Seite nicht blockieren möchten, nehmen Sie die erforderlichen Korrekturen in der robots.txt-Datei vor.
Mit dem robots.txt-Testerkönnen Sie feststellen, welche Regel eine Seite blockiert.
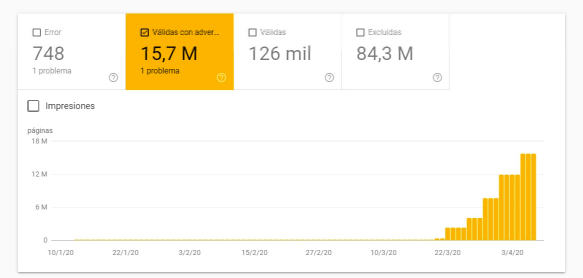
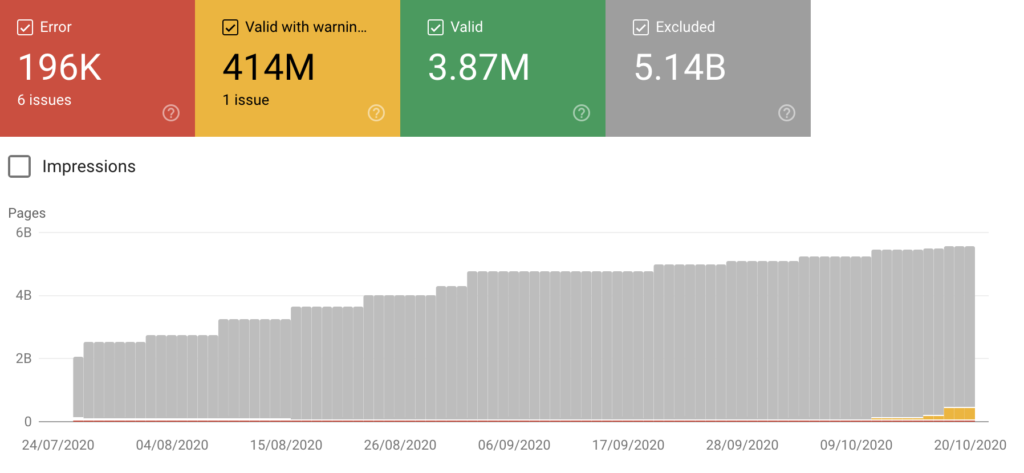
Bei einer großen Migration zu SalesForce haben wir die Entwickler gebeten, die Filter, die wir nicht indizieren wollten, unzugänglich (verschleiert) zu machen. Als die Salesforce-Website online ging, war alles ein Erfolg. Aber als Monate später eine neue Version veröffentlicht wurde, wurde die Verschleierung versehentlich gebrochen. Dies löste alle Alarme aus, da es in nur sieben Tagen ~17,5 Millionen Googlebot-Mobile-Anfragen und ~12,5 Millionen Googlebot/2.1 sowie eine Cache-Trefferquote von 2 % gab. Unten sehen Sie in der Search Console, wie die Zahl der von Robots indexierten, aber blockierten Seiten zugenommen hat.
Aus diesem Grund empfehle ich, die Protokolle kontinuierlich zu überwachen und den GSC-Abdeckungsbericht zu überprüfen (obwohl Sie jedes Problem früher erkennen, wenn Sie die Protokolle überprüfen). Und denken Sie daran, dass die robots.txt nicht verhindert, dass Seiten indexiert werden. Wenn Sie möchten, dass Google eine URL nicht crawlt, machen Sie die URL am besten unzugänglich!
Ausgeschlossener Status
Diese Seiten werden nicht in den Suchergebnissen indexiert, und Google glaubt, dass es das Richtige ist.Dies könnte beispielsweise daran liegen, dass es sich um duplizierte Seiten indexierter Seiten handelt oder dass Sie Suchmaschinen auf Ihrer Website Richtlinien zur Indexierung geben.
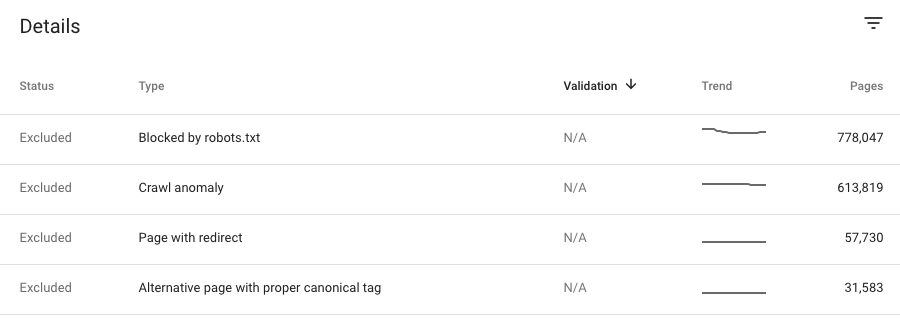
Der Abdeckungsbericht zeigt Ihnen 15 Situationen, in denen Ihre Seite ausgeschlossen werden kann .
Vom 'noindex'-Tag ausgeschlossen:
Sie sagen Suchmaschinen, dass sie die Seite nicht indexieren sollen, indem Sie eine „noindex“-Anweisung geben.
Zu ergreifende Maßnahmen:
Überprüfen Sie, ob Sie die Seite tatsächlich nicht indizieren möchten.Wenn Sie möchten, dass die Seite indexiert wird, entfernen Sie das „noindex“-Tag.
Sie können das Vorhandensein dieser Direktive bestätigen, indem Sie die Seite öffnen und im Antworttext und im Antwortheader nach „noindex“ suchen.
Vom Tool zum Entfernen von Seiten blockiert:
Sie haben bei GSCeinen Antrag auf Entfernung der URL für diese Seiten gestellt.
Zu ergreifende Maßnahmen:
Google bearbeitet diese Anfrage nur 90 Tage lang. Wenn Sie also die Seite nicht indexieren möchten, verwenden Sie „noindex“-Anweisungen, implementieren Sie eine HTTP-Authentifizierung oder entfernen Sie die Seite.
Von robots.txt blockiert:
Mit der robots.txt-Datei blockieren Sie den Zugriff des Googlebot auf diese Seiten.Es könnte jedoch trotzdem indexiert werden, wenn Google Informationen zu dieser Seite finden könnte, ohne sie zu laden.Möglicherweise hat Google die Seite indiziert, bevor Sie die Sperre in der robots.txt hinzugefügt haben
Zu ergreifende Maßnahmen:
Wenn Sie nicht möchten, dass die Seite indexiert wird, verwenden Sie eine „noindex“-Anweisung und entfernen Sie den robots.txt-Block.
Gesperrt wegen nicht autorisierter Anfrage (401):
Sie blockieren den Zugriff auf Google mit einer Anfrageautorisierung (401-Antwort).
Zu ergreifende Maßnahmen:
Wenn Sie zulassen möchten, dass GoogleBot die Seite besucht, entfernen Sie die Autorisierungsanforderungen.
Crawl-Anomalie:
Die Seite wurde aufgrund eines 4xx- oder 5xx-Fehlerantwortcodes nicht indiziert.
Zu ergreifende Maßnahmen:
Verwenden Sie das URL-Prüftool, um weitere Informationen zu den Problemen zu erhalten.
Gecrawlt – Derzeit nicht indiziert
Diese Seite wurde von GoogleBot gecrawlt, aber nicht indexiert.Es kann in Zukunft indexiert werden oder nicht.Diese URL muss nicht zum Crawlen eingereicht werden.
Zu ergreifende Maßnahmen:
Wenn Sie möchten, dass die Seite in den Suchergebnissen indexiert wird, stellen Sie sicher, dass Sie wertvolle Informationen bereitstellen.
Entdeckt – Derzeit nicht indiziert:
Google hat diese Seite gefunden, aber noch nicht gecrawlt .Diese Situation tritt normalerweise auf, weil die Website überlastet war, als der GoogleBot versuchte, die Seite zu crawlen.Der Crawl wurde zu einem anderen Zeitpunkt angesetzt.
Es ist keine Aktion erforderlich.
Alternative Seite mit dem richtigen Canonical-Tag:
Diese Seite verweist auf eine kanonische Seite, sodass Google versteht, dass Sie sie nicht indizieren möchten.
Zu ergreifende Maßnahmen:
Wenn Sie diese Seite indexieren möchten, müssen Sie dierel=canonical-Attribute ändern , um Google die gewünschten Richtlinien zu geben.
Duplizieren ohne vom Benutzer ausgewählte kanonische:
Die Seite hat Duplikate, aber keine davon ist als kanonisch markiert.Google ist der Ansicht, dass dies nicht das kanonische ist.
Zu ergreifende Maßnahmen:
Verwenden Sie kanonische Tags, um Google klar zu machen, welche Seiten die kanonischen sind (indiziert werden müssen) und welche die Duplikate sind. Mit dem URL-Inspektionstool können Sie sehen, welche Seiten von Google als Canonicals ausgewählt wurden.
Duplizieren, Google hat eine andere kanonische als der Benutzer ausgewählt:
Sie haben diese Seite als kanonisch markiert, aber Google hat stattdessen eine andere Seite indiziert, die als kanonisch besser funktioniert.
Zu ergreifende Maßnahmen:
Sie können der Auswahl von Google folgen.Markieren Sie in diesem Fall die indexierte Seite als kanonisch und diese als Duplikat der kanonischen URL.
Wenn nicht, finden Sie heraus, warum Google eine andere Seite der von Ihnen ausgewählten vorzieht, und nehmen Sie die erforderlichen Änderungen vor.Verwenden Sie das URL-Inspektionstool, um die von Google ausgewählte „kanonische Seite“ zu entdecken.
Ferran Gavin, SEO-Manager @ Softonic
Einer der merkwürdigsten „Fehler“, die wir beim Index Coverage Report erlebt haben, war die Feststellung, dass Google unsere Canonicals nicht korrekt verarbeitete (und wir hatten es jahrelang falsch gemacht!). Google hat in der Search Console angegeben, dass das angegebene Canonical ungültig war, wenn die Seite perfekt formatiert war. Am Ende stellte sich heraus, dass es sich um einen Fehler von Google selbst handelte, der von Gary Ilyes bestätigt wurde.
Nicht gefunden (404):
Die Seite gibt einen 404-Fehlerstatuscode zurück, wenn Google eine Anfrage stellt .Der GoogleBot hat die Seite nicht über eine Sitemap gefunden, sondern wahrscheinlich über eine andere Website, die auf die URL verweist.Es ist auch möglich, dass diese URL in der Vergangenheit existierte und entfernt wurde.
Zu ergreifende Maßnahmen:
Wenn die 404-Antwort beabsichtigt ist, können Sie sie so belassen.Es wird Ihrer SEO-Leistung nicht schaden.Wenn die Seite jedoch verschoben wurde, implementieren Sie eine 301-Weiterleitung.
Seite wegen Rechtsbeschwerde entfernt:
Diese Seite wurde aufgrund einer Rechtsbeschwerdeaus dem Index genommen .
Zu ergreifende Maßnahmen:
Untersuchen Sie, gegen welche Rechtsvorschriften Sie möglicherweise verstoßen haben, und ergreifen Sie die erforderlichen Maßnahmen, um dies zu korrigieren.
Seite mit der Weiterleitung:
Diese URL ist eine Weiterleitung und wurde daher nicht indexiert.
Zu ergreifende Maßnahmen:
Wenn die URL nicht umleiten sollte, entfernen Sie die Umleitungsimplementierung.
Weich 404:
Die Seite gibt zurück, was Google für eine weiche 404-Antwort hält.Die Seite wird nicht indexiert, weil Google denkt, dass sie einen 404 zurückgeben sollte, obwohl sie den Statuscode 200 anzeigt .
Zu ergreifende Maßnahmen:
Überprüfen Sie, ob Sie der Seite einen 404 zuweisen sollten, wie Google vorschlägt.
Fügen Sie der Seite wertvolle Inhalte hinzu, um Google wissen zu lassen, dass es sich nicht um einen Soft 404 handelt.
Doppelte, eingereichte URL nicht als kanonisch ausgewählt:
Sie haben die URL zu Indizierungszwecken an GSC übermittelt.Dennoch wurde sie nicht indexiert, da die Seite Duplikate ohne kanonische Tags enthält und Google der Ansicht ist, dass es einen besseren Kandidaten für kanonische Tags gibt.
Zu ergreifende Maßnahmen:
Entscheiden Sie, ob Sie der Wahl von Google für die kanonische Seite folgen möchten. Weisen Sie in diesem Fall dieAttribute rel=canonicalzu, um auf die von Google ausgewählte Seite zu verweisen.
Mit dem URL-Inspektionstool können Sie sehen, welche Seite von Google als kanonisch ausgewählt wurde.
Wenn Sie diese URL als Canonical haben möchten, analysieren Sie, warum Google die andere Seite bevorzugt.Bieten Sie mehr hochwertige Inhalte auf der Seite Ihrer Wahl an.
Schritt 3. Bericht zur Indexabdeckung Die häufigsten Probleme
Jetzt kennen Sie die verschiedenen Arten von Fehlern, die Sie im Indexabdeckungsbericht finden können, und wissen, welche Maßnahmen Sie ergreifen müssen, wenn Sie auf die einzelnen Fehler stoßen.Nachfolgend ein kurzer Überblick über die am häufigsten auftretenden Probleme.
Mehr ausgeschlossene als gültige Seiten
Manchmal können Sie mehr ausgeschlossene Seiten als gültige haben.Dieser Umstand ist in der Regel bei großen Seiten gegeben, die eine erhebliche URL-Änderung erfahren haben .Wahrscheinlich handelt es sich um eine alte Seite mit langer Historie, oder der Webcode wurde geändert.
Wenn Sie einen signifikanten Unterschied zwischen der Anzahl der Seiten der beiden Status (Ausgeschlossen und Gültig) feststellen, haben Sie ein schwerwiegendes Problem.Beginnen Sie mit der Überprüfung der ausgeschlossenen Seiten, wie oben erläutert.
Esteve Castells, Gruppen-SEO-Manager @ Adevinta
Das größte Problem, das ich je im Abdeckungsbericht gesehen habe, ist eine der von mir verwalteten Websites, die am Ende 5 Milliarden ausgeschlossene Seiten hatte.Ja, Sie haben richtig gelesen, 5 Milliarden Seiten.Die Facettennavigation spielte völlig verrückt und für jeden Seitenaufruf erstellten wir 20 neue URLs, die der Googlebot crawlen sollte.
Das war der teuerste Fehler in Sachen Crawling aller Zeiten.Wir mussten die facettierten Navigations-URLs über die robots.txt vollständig verbieten, da der Googlebot unseren Server mit mehr als 25 Millionen Zugriffen pro Tag lahmlegte.
Fehlerspitzen
Wenn die Anzahl der Fehler exponentiell ansteigt, müssen Sie den Fehler überprüfen und so schnell wie möglich beheben.Google hat ein Problem festgestellt, das die Leistung Ihrer Website stark beeinträchtigt .Wenn Sie das Problem heute nicht beheben, werden Sie morgen erhebliche Probleme haben.
Serverfehler
Stellen Sie sicher, dass diese Fehler nicht 503 (Dienst nicht verfügbar) lauten .Dieser Statuscode bedeutet, dass der Server die Anfrage aufgrund einer vorübergehenden Überlastung oder Wartungsarbeiten nicht bearbeiten kann.Zuerst sollte der Fehler von selbst verschwinden, aber wenn er weiterhin auftritt, müssen Sie sich das Problem ansehen und es beheben.
Wenn Sie andere Arten von 5xx-Fehlern haben, empfehlen wir Ihnen, unseren Leitfaden zu lesen, um zu sehen, welche Maßnahmen Sie in jedem Fall ergreifen müssen.
404-Fehler
Es scheint, als hätte Google einen Bereich Ihrer Website entdeckt, der 404 – nicht gefundene Seiten generiert.Wenn das Volumen erheblich zunimmt, lesen Sie unseren Leitfaden, um defekte Links zu finden und zu beheben.
Fehlende Seiten oder Websites
Wenn eine Seite oder Website im Bericht nicht angezeigt wird, kann dies mehrere Gründe haben.
Google hat es noch nicht entdeckt.Wenn eine Seite oder Website neu ist, kann es einige Zeit dauern, bis Google sie findet.Senden Sie eine Sitemap- oder Seiten-Crawling-Anfrage, um den Indexierungsprozess zu beschleunigen.Stellen Sie außerdem sicher, dass die Seite nicht verwaist und von der Website verlinkt ist.
Google kann aufgrund einer Anmeldeanfrage nicht auf Ihre Seite zugreifen .Entfernen Sie die Autorisierungsanforderungen, damit der GoogleBot die Seite crawlen kann.
Die Seite hat ein noindex - Tag oder wurde aus irgendeinem Grund aus dem Index entfernt .Entfernen Sie das noindex-Tag und stellen Sie sicher, dass Sie wertvolle Inhalte auf der Seite bereitstellen.
„Gesendet, aber/Gesendet und“-Fehler und -Ausschlüsse
Dieses Problem tritt auf, wenn eine Inkongruenz vorliegt.Wenn Sie eine Seite über eine Sitemap senden, müssen Sie sicherstellen, dass sie für die Indexierung gültig ist und mit der Website verlinkt ist.
Ihre Website sollte hauptsächlich aus wertvollen Seiten bestehen, die es wert sind, verlinkt zu werden.
Zusammenfassung
Hier ist eine dreistufige Zusammenfassung des Artikels „Erkennen und Beheben von Indexabdeckungsfehlern“.
Das erste, was Sie tun sollten, wenn Sie den Bericht zur Indexabdeckung verwenden, ist, die Seiten zu korrigieren, die im Fehlerstatus angezeigt werden .Dies muss 0 sein, um Google-Strafen zu vermeiden.
Überprüfen Sie zweitens die ausgeschlossenen Seiten und prüfen Sie, ob es sich um Seiten handelt, die Sie nicht indizieren möchten.Wenn dies nicht der Fall ist, befolgen Sie unsere Richtlinien, um die Probleme zu lösen.
Wenn Sie Zeit haben, empfehlen wir dringend, die gültigen Seiten mit einer Warnung zu überprüfen .Stellen Sie sicher, dass die Richtlinien, die Sie in der robots.txt angeben, korrekt sind und keine Inkonsistenzen enthalten.
Wir hoffen, Sie finden es hilfreich!Lassen Sie uns wissen, wenn Sie Fragen zum Indexabdeckungsbericht haben.Wir freuen uns auch über Tipps von Ihnen in den Kommentaren unten.