Comment trouver et résoudre les problèmes de couverture d'index
Comment trouver et résoudre les problèmes de couverture d'index
Publié: 2020-10-29
Vous rencontrez des problèmes d'indexation Google ?Ce problème peut entraîner une baisse du trafic et des taux de conversion.
Il est nécessaire de vérifier les pages indexées et non indexées de votre site pour résoudre rapidement tout problème .Ici, nous expliquons étape par étape comment le faire avec Google Search Console - Index Coverage Report .
Avec la méthode suivante, nous avons réussi à résoudre les problèmes de couverture d'index sur des centaines de sites Web avec des millions ou des milliards de pages exclues.Utilisez-le pour qu'aucune de vos pages pertinentes ne perde de visibilité dans les résultats de recherche et boostez votre trafic SEO !
Table des matières
Étape 1 : Vérifier le rapport de couverture de l'index
Le rapport de couverture de la Search Console vous indique quelles pages ont été explorées et indexées par Google et pourquoi les URL sont dans cet état particulier.Vous pouvez l'utiliser pourdétecter toute erreur détectée au cours du processus d'exploration et d'indexation .
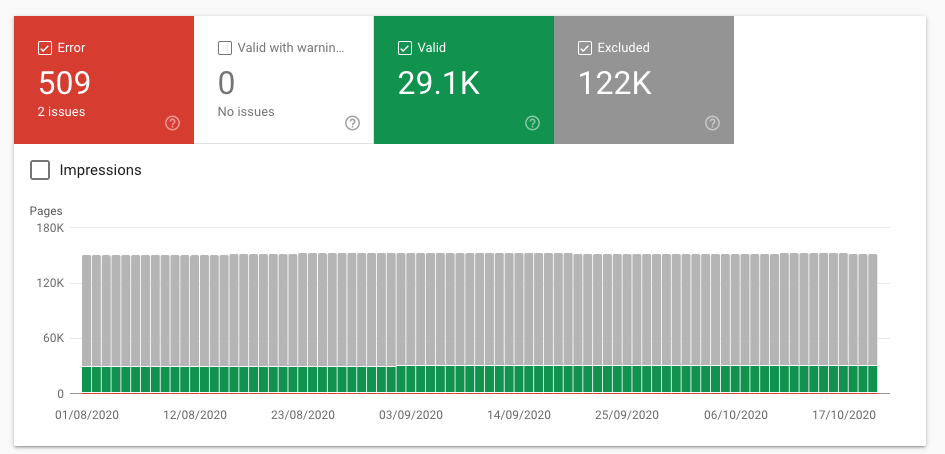
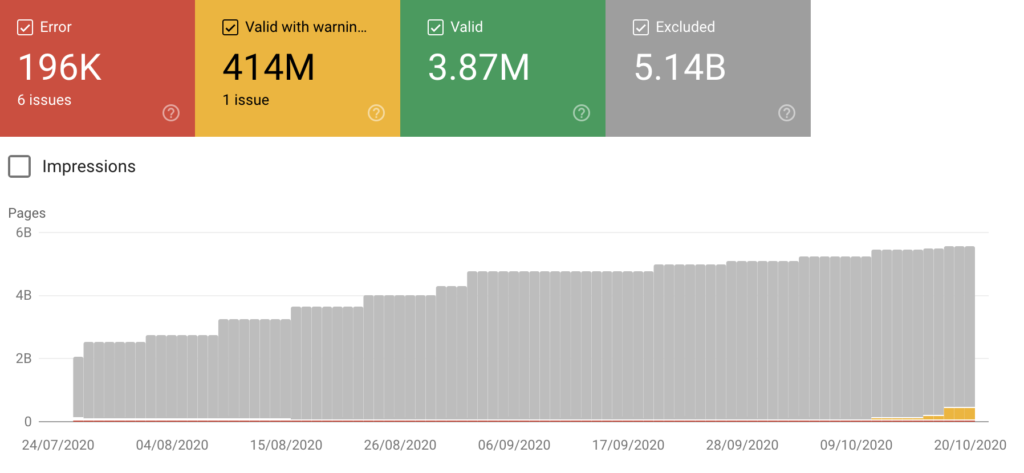
Pour vérifier le rapport de couverture de l'index, accédez à la console de recherche Google et cliquez sur Couverture (juste en dessous de l'index).Une fois que vous l'ouvrez, vous verrez un résumé avec quatre statuts différents catégorisant vos URL :
Erreur : Ces pages ne peuvent pas être indexées et n'apparaîtront pas dans les résultats de recherche en raison de certaines erreurs.
Valide avec avertissements : ces pages peuvent être affichées ou non dans les résultats de recherche Google.
Valide : ces pages ont été indexées et peuvent être affichées dans les résultats de recherche.Vous n'avez rien à faire.
Exclus : ces pages n'ont pas été indexées et n'apparaîtront pas dans les résultats de recherche.Google estime que vous ne souhaitez pas les indexer ou considère que le contenu ne vaut pas la peine d'être indexé.
Vous devez vérifier toutes les pages trouvées dans la section Erreur et les corriger dès que possible, car vous risquez de perdre l'opportunité de générer du trafic vers votre site.
Si vous avez le temps, regardez les pages incluses dans l'étatValide avec avertissement car il peut y avoir des pages vitales qui ne doivent en aucun cas manquer d'apparaître dans les résultats de recherche.
Enfin, assurez-vous que les pages exclues sont celles que vous ne souhaitez pas indexer.
Étape 2 : Comment résoudre les problèmes rencontrés dans chacun des états de couverture de l'index
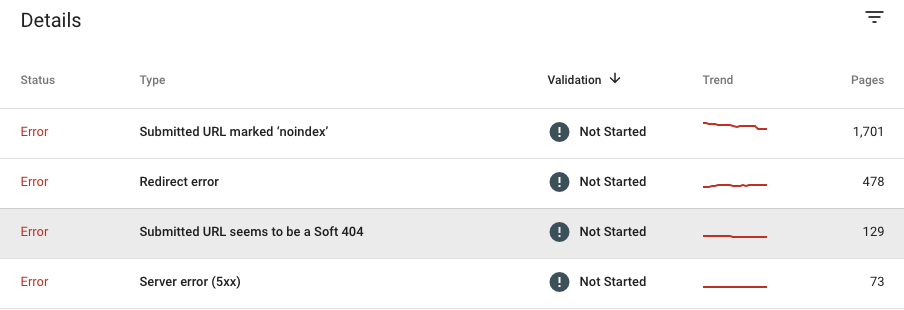
Une fois que vous avez ouvert le rapport de couverture de l'index, sélectionnez le statut souhaité (Erreurs, Valide avec avertissements ou Exclu) et consultez les détails fournis au bas de la page.Vous trouverez une liste destypes d'erreurs en fonction de leur gravité et du nombre de pages concernées. Nous vous recommandons donc de commencer à rechercher les problèmes en haut du tableau.
Voyons chacune des erreurs dans différents statuts et comment vous pouvez les corriger.
État d'erreur
Erreurs de serveur (5xx) :
Il s'agit d'URL renvoyant un code d'état 5xx à Google.
Actions à entreprendre :
Vérifiez quel type de code d'état 500 renvoie .Ici, vous avez une liste complète avec la définition de chaque code d'état d'erreur de serveur.
Rechargez l'URL pour voir si l'erreur persiste.Les erreurs 5xx sont temporaires et ne nécessitent aucune action.
Vérifiez que votre serveur n'est pas surchargé ou mal configuré.Dans ce cas, demandez de l'aide à vos développeurs ou contactez votre hébergeur.
Effectuez une analyse du fichier journal pour vérifier les journaux d'erreurs de votre serveur.Cette pratique vous fournit des informations supplémentaires sur le problème.
Passez en revue les modifications que vous avez apportées récemment à votre site Web pour voir si l'une d'entre elles peut en être la cause première.ex) plugins, nouveau code backend, etc.
Erreurs de redirection :
GoogleBot a rencontré une erreur lors du processus de redirection qui ne permet pas d'explorer la page.L'une des raisons suivantes provoque souvent ce problème.
Une chaîne de redirection trop longue
Une boucle de redirection
Une URL de redirection qui a dépassé la longueur maximale de l'URL
Il y avait une URL erronée ou vide dans la chaîne de redirection
Actions à entreprendre :
Éliminez les chaînes et les boucles de redirection.Demandez à chaque URL d'effectuer une seule redirection.En d'autres termes, une redirection de la première URL vers la dernière.
URL soumise bloquée par Robots.txt :
Il s'agit d'URL que vous avez soumises à Google en téléchargeant un sitemap XML sur Google Search Console, mais qui ont été bloquées par le fichier Robots.txt.
Actions à entreprendre :
Vérifiez si vous souhaitez que les moteurs de recherche indexent ou non la page en question.
Si vous ne souhaitez pas qu'il soit indexé, téléchargez un sitemap XML en supprimant l'URL.
Au contraire, si vous souhaitez qu'il soit indexé, modifiez les directives dans le Robots.txt. Voici un guide sur la façon de modifier robots.txt.
URL soumise marquée "noindex":
Ces pages ont été soumises à Google via un sitemap XML, mais elles ont une directive "noindex" soit dans la balise meta robots, soit dans les en-têtes HTTP.
Actions à entreprendre :
Si vous souhaitez que l'URL soit indexée, vous devez supprimer la directive noindex
S'il y a des URL que vous ne voulez pas que Google indexe, éliminez-les du sitemap XML
L'URL soumise semble être un Soft 404 :
L'URL que vous avez soumise via un sitemap XML à des fins d'indexation renvoie un soft 404 .Cette erreur se produit lorsque le serveur renvoie un code d'état 200 à une requête, mais Google pense qu'il devrait afficher un 404. En d'autres termes, la page ressemble à une erreur 404 pour Google.Dans certains cas, cela peut être dû au fait que la page n'a pas de contenu, semble incorrecte ou de mauvaise qualité pour Google.
Actions à entreprendre :
Déterminez si ces URL doivent renvoyer un (réel) code d'état 404.Dans ce cas, supprimez-les du sitemap XML.
Si vous constatez qu'ils ne doivent pas renvoyer d'erreur, assurez-vous de fournir un contenu approprié sur ces pages.Évitez les contenus fins ou dupliqués.Vérifiez que s'il y a des redirections, elles sont correctes.
L'URL soumise renvoie une demande non autorisée (401) :
L'URL soumise à Google via un sitemap XML renvoie une erreur 401 .Ce code d'état vous indique que vous n'êtes pas autorisé à accéder à l'URL.Vous aurez peut-être besoin d'un nom d'utilisateur et d'un mot de passe, ou peut-être existe-t-il des restrictions d'accès basées sur l'adresse IP.
Actions à entreprendre :
Vérifiez si les URL doivent renvoyer un 401. Dans ce cas, éliminez-les du sitemap XML.
Si vous ne voulez pas qu'ils affichent un code 401, supprimez l'authentification HTTP s'il y en a une.
URL soumise introuvable (404) :
Vous avez soumis l'URL à des fins d'indexation à Google Search Console, mais Google ne peut pas l'explorer en raison d'un problème différent de ceux mentionnés ci-dessus.
Actions à entreprendre :
Voyez si vous voulez que la page soit indexée ou non.Si la réponse est oui, corrigez-la afin qu'elle renvoie un code d'état 200.Vous pouvez également attribuer une redirection 301 à l'URL, afin qu'elle affiche une page appropriée.N'oubliez pas que si vous optez pour une redirection, vous devez ajouter l'URL attribuée au sitemap XML et supprimer celle donnant un 404.
Si vous ne souhaitez pas que la page soit indexée, supprimez-la du sitemap XML.
L'URL soumise a un problème d'exploration :
Vous avez soumis l'URL à des fins d'indexation à GSC, mais elle ne peut pas être explorée par Google en raison d'un problème différent de ceux mentionnés ci-dessus.
Actions à entreprendre :
Utilisez l' outil d'inspection d'URL pour obtenir plus d'informations sur la cause du problème.
Parfois, ces erreurs sont temporaires et ne nécessitent donc aucune action.
Valable avec le statut d'avertissement
Ces pages sont indexées, bien qu'elles soient bloquées par robots.txt.Google essaie toujours de suivre les directives données dans le fichier robots.txt.Cependant, il se comporte parfois différemment.Cela peut se produire, par exemple, lorsque quelqu'un établit un lien vers l'URL donnée.
Vous trouvez les URL dans cette catégorie car Google doute que vous vouliez bloquer ces pages sur les résultats de recherche .
Actions à entreprendre :
Google déconseille l'utilisation du fichier robots.txt pour éviter l'indexation des pages.Au lieu de cela, si vous ne voulez pas voir ces pages indexées, utilisez le noindex dans les méta-robots ou un en-tête de réponse HTTP.
Une autre bonne pratique pour empêcher Google d'accéder à la page consiste à mettre en place une authentification HTTP.
Si vous ne souhaitez pas bloquer la page, apportez les corrections nécessaires dans le fichier robots.txt.
Vous pouvez identifier la règle qui bloque une page à l'aide dutesteur robots.txt.
Natzir Turrado, Conseiller SEO Fandango Freelance technique SEO @ Natzir Turrado
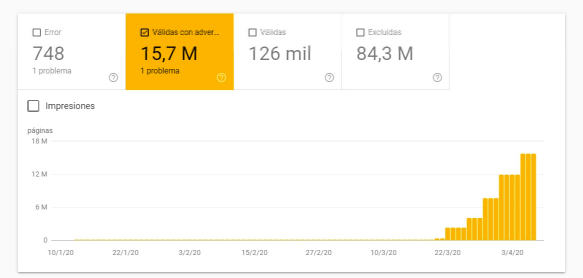
Lors d'une grande migration vers SalesForce, nous avons demandé aux développeurs de rendre inaccessibles (obfusqués) les filtres que nous ne voulions pas indexer. Lorsque le site Web de Salesforce a été mis en ligne, tout a été un succès. Mais lorsqu'une nouvelle version est sortie des mois plus tard, l'obscurcissement a été accidentellement brisé. Cela a déclenché toutes les alarmes puisqu'en seulement sept jours, il y a eu ~17,5 millions de requêtes Googlebot-Mobile et ~12,5 millions Googlebot/2.1, ainsi qu'un cache de taux de réussite de 2 %. Ci-dessous, vous pouvez voir dans la Search Console comment les pages indexées mais bloquées par les robots ont augmenté.
C'est pourquoi je recommande de surveiller en permanence les journaux et de consulter le rapport de couverture GSC (bien que vous détecterez tout problème plus tôt en consultant les journaux). Et n'oubliez pas que le fichier robots.txt n'empêche pas l'indexation des pages. Si vous voulez que Google ne crawle pas une URL, il est préférable de rendre l'URL inaccessible !
Statut exclu
Ces pages ne sont pas indexées sur les résultats de recherche, et Google pense que c'est la bonne chose à faire.Par exemple, cela peut être dû au fait qu'il s'agit de pages dupliquées de pages indexées ou parce que vous donnez des directives sur votre site Web aux moteurs de recherche pour les indexer.
Le rapport Couverture vous indique 15 situations dans lesquelles votre page peut être exclue .
Exclus par la balise 'noindex' :
Vous dites aux moteurs de recherche de ne pas indexer la page en donnant une directive "noindex".
Actions à entreprendre :
Vérifiez si vous ne souhaitez pas réellement indexer la page.Si vous souhaitez que la page soit indexée, supprimez la balise "noindex".
Vous pouvez confirmer la présence de cette directive en ouvrant la page et en recherchant "noindex" dans le corps de la réponse et l'en-tête de la réponse.
Bloqué par l'outil de suppression de page :
Vous avez soumis une demande de suppression d'URL pour ces pages sur GSC.
Actions à entreprendre :
Google ne répond à cette demande que pendant 90 jours. Par conséquent, si vous ne souhaitez pas indexer la page, utilisez les directives "noindex", implémentez une authentification HTTP ou supprimez la page.
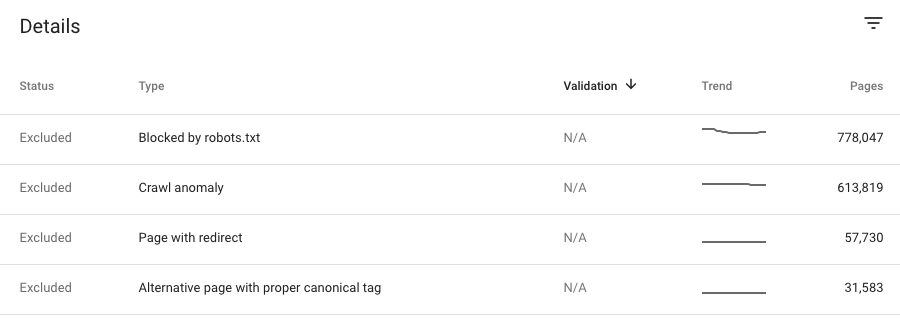
Bloqué par robots.txt :
Vous bloquez l'accès de Googlebot à ces pages avec le fichier robots.txt.Cependant, il pourrait toujours être indexé si Google pouvait trouver des informations sur cette page sans la charger.Google a peut-être indexé la page avant que vous n'ajoutiez l'interdiction dans robots.txt
Actions à entreprendre :
Si vous ne souhaitez pas que la page soit indexée, utilisez une directive "noindex" et supprimez le bloc robots.txt.
Bloqué en raison d'une demande non autorisée (401) :
Vous bloquez l'accès à Google à l'aide d'une demande d'autorisation (réponse 401).
Actions à entreprendre :
Si vous souhaitez autoriser GoogleBot à visiter la page, supprimez les exigences d'autorisation.
Anomalie d'exploration :
La page n'a pas été indexée en raison d'un code de réponse d'erreur 4xx ou 5xx.
Actions à entreprendre :
Utilisez l'outil d'inspection d'URL pour obtenir plus d'informations sur les problèmes.
Exploré - Actuellement non indexé
Cette page a été explorée par GoogleBot mais n'a pas été indexée.Il peut ou non être indexé à l'avenir.Il n'est pas nécessaire de soumettre cette URL pour l'exploration.
Actions à entreprendre :
Si vous souhaitez que la page soit indexée dans les résultats de recherche, assurez-vous de fournir des informations précieuses.
Découvert - Actuellement non indexé :
Google a trouvé cette page, mais il n'a pas encore réussi à la crawler .Cette situation se produit généralement parce que lorsque GoogleBot a essayé d'explorer la page, le site était surchargé.Le crawl a été programmé pour une autre fois.
Aucune action n'est requise.
Page alternative avec la balise canonique appropriée :
Cette page pointe vers une page canonique, Google comprend donc que vous ne souhaitez pas l'indexer.
Actions à entreprendre :
Si vous souhaitez indexer cette page, vous devrez modifier lesattributs rel=canonicalpour donner à Google les directives souhaitées.
Dupliquer sans canonique sélectionné par l'utilisateur :
La page a des doublons, mais aucun d'entre eux n'est marqué comme canonique.Google considère que celle-ci n'est pas la canonique.
Actions à entreprendre :
Utilisez des balises canoniques pour indiquer clairement à Google quelles pages sont les pages canoniques (doivent être indexées) et lesquelles sont les doublons.Vous pouvez utiliser l' outil d'inspection d'URL pour voir quelles pages ont été sélectionnées comme canoniques par Google.
En double, Google a choisi un canonique différent de celui de l'utilisateur :
Vous avez marqué cette page comme canonique, mais Google, à la place, a indexé une autre page qui pense mieux fonctionner comme canonique.
Actions à entreprendre :
Vous pouvez suivre le choix de Google.Dans ce cas, marquez la page indexée comme canonique et celle-ci comme un doublon de l'URL canonique.
Si ce n'est pas le cas, découvrez pourquoi Google préfère une autre page à celle que vous avez choisie et apportez les modifications nécessaires.Utilisez l'outil d'inspection d'URL pour découvrir la "page canonique" sélectionnée par Google.
Ferran Gavin, Responsable SEO @ Softonic
L'un des "échecs" les plus curieux que nous ayons rencontrés avec le rapport sur la couverture de l'index a été de constater que Google ne traitait pas correctement nos canoniques (et nous le faisions mal depuis des années !). Google indiquait sur la console de recherche que le canonique spécifié n'était pas valide lorsque la page était parfaitement formatée. En fin de compte, il s'est avéré être un bogue de Google lui-même, confirmé par Gary Ilyes.
Non trouvé (404):
La page renvoie un code d'état d'erreur 404 lorsque Google fait une demande .GoogleBot n'a pas trouvé la page via un sitemap, mais probablement via un autre site Web lié à l'URL.Il est également possible que cette URL ait existé dans le passé et ait été supprimée.
Actions à entreprendre :
Si la réponse 404 est intentionnelle, vous pouvez la laisser telle quelle.Cela ne nuira pas à vos performances de référencement.Cependant, si la page a été déplacée, implémentez une redirection 301.
Page supprimée en raison d'une réclamation légale :
Cette page a été supprimée de l'index en raison d'uneplainte légale.
Actions à entreprendre :
Enquêtez sur les règles juridiques que vous avez peut-être enfreintes et prenez les mesures nécessaires pour y remédier.
Page avec la redirection :
Cette URL est une redirection et n'a donc pas été indexée.
Actions à entreprendre :
Si l'URL n'était pas censée être redirigée, supprimez l'implémentation de la redirection.
Doux 404 :
La page renvoie ce que Google considère comme une réponse soft 404.La page n'est pas indexée car, bien qu'elle donne un code d'état 200, Google pense qu'elle devrait renvoyer un 404 .
Actions à entreprendre :
Vérifiez si vous devez attribuer un 404 à la page, comme le suggère Google.
Ajoutez du contenu précieux à la page pour faire savoir à Google qu'il ne s'agit pas d'un Soft 404.
URL soumise en double non sélectionnée comme canonique :
Vous avez soumis l'URL à GSC à des fins d'indexation.Pourtant, il n'a pas été indexé car la page a des doublons sans balises canoniques, et Google considère qu'il existe un meilleur candidat pour canonique.
Actions à entreprendre :
Décidez si vous souhaitez suivre le choix de Google pour la page canonique.Dans ce cas, affectez lesattributs rel=canonicalpour pointer vers la page sélectionnée par Google.
Vous pouvez utiliser l'outil d'inspection d'URL pour voir quelle page a été choisie par Google comme canonique.
Si vous voulez que cette URL soit canonique, analysez pourquoi Google préfère l'autre page.Proposez plus de contenu à forte valeur ajoutée sur la page de votre choix.
Étape 3. Rapport sur la couverture de l'index des problèmes les plus courants
Vous connaissez maintenant les différents types d'erreurs que vous pouvez trouver dans le rapport Couverture de l'index et les actions à entreprendre lorsque vous rencontrez chacune d'entre elles.Voici un bref aperçu des problèmes qui surviennent le plus souvent.
Plus de pages exclues que de pages valides
Parfois, vous pouvez avoir plus de pages exclues que de pages valides.Cette circonstance est généralement donnée sur les grands sites qui ont subi un changement d'URL important .Il s'agit probablement d'un ancien site avec une longue histoire, ou le code Web a été modifié.
Si vous avez une différence significative entre le nombre de pages des deux statuts (Exclu et Valide), vous avez un sérieux problème.Commencez à examiner les pages exclues, comme nous l'expliquons ci-dessus.
Estève Castells, Responsable SEO Groupe @ Adevinta
Le plus gros problème que j'ai jamais vu dans le rapport de couverture est l'un des sites Web que je gère, qui a fini par avoir 5 milliards de pages exclues.Oui, vous avez bien lu, 5 milliards de pages.La navigation à facettes est devenue complètement folle, et pour chaque page vue, nous créions 20 nouvelles URL à explorer par Googlebot.
Cela a fini par être l'erreur la plus coûteuse en termes d'exploration.Nous avons dû interdire complètement via le robots.txt les URL de navigation à facettes car Googlebot supprimait notre serveur avec plus de 25 millions de visites par jour.
Pics d'erreur
Lorsque le nombre d'erreurs augmente de façon exponentielle, vous devez vérifier l'erreur et la corriger dès que possible.Google a détecté un problème qui nuit gravement aux performances de votre site Web .Si vous ne corrigez pas le problème aujourd'hui, vous aurez des problèmes importants demain.
Erreurs de serveur
Assurez-vous que ces erreurs ne sont pas 503 (Service non disponible) .Ce code d'état signifie que le serveur ne peut pas traiter la demande en raison d'une surcharge temporaire ou d'une maintenance.Au début, l'erreur devrait disparaître d'elle-même, mais si elle continue de se produire, vous devez examiner le problème et le résoudre.
Si vous avez d'autres types d'erreurs 5xx, nous vous recommandons de consulter notre guide pour voir les actions que vous devez entreprendre dans chaque cas.
404 erreurs
Il semble que Google ait détecté une partie de votre site Web qui génère 404 pages introuvables.Si le volume augmente considérablement, consultez notre guide pour trouver et réparer les liens brisés.
Pages ou sites manquants
Si vous ne voyez pas une page ou un site dans le rapport, cela peut être pour plusieurs raisons.
Google ne l'a pas encore découvert.Lorsqu'une page ou un site est nouveau, cela peut prendre un certain temps avant que Google ne le trouve.Soumettez un sitemap ou une demande d'exploration de page pour accélérer le processus d'indexation.Assurez-vous également que la page n'est pas orpheline et liée à partir du site Web.
Google ne peut pas accéder à votre page en raison d'une demande de connexion .Supprimez les exigences d'autorisation pour permettre à GoogleBot d'explorer la page.
La page a une balise noindex ou a été retirée de l'index pour une raison quelconque .Supprimez la balise noindex et assurez-vous que vous fournissez un contenu précieux sur la page.
Erreurs et exclusions « Soumis mais/Soumis et »
Ce problème survient lorsqu'il y a incongruité.Si vous envoyez une page via un sitemap, vous devez vous assurer qu'il est valide pour l'indexation et qu'il est lié au site.
Votre site doit être composé principalement de pages utiles qui valent la peine d'être interconnectées.
Sommaire
Voici un résumé en trois étapes de l'article "Comment rechercher et corriger les erreurs de couverture d'index".
La première chose à faire lors de l'utilisation du rapport de couverture d'index est de corriger les pages qui apparaissent dans le statut Erreur .Ce doit être 0 pour éviter les pénalités de Google.
Deuxièmement, vérifiez les pages exclues et voyez s'il s'agit de pages que vous ne souhaitez pas indexer.Si ce n'est pas le cas, suivez nos instructions pour résoudre les problèmes.
Si vous avez le temps, nous vous recommandons fortement de vérifier les pages valides avec un avertissement .Assurez-vous que les directives que vous donnez dans le robots.txt sont correctes et qu'il n'y a pas d'incohérences.
Nous espérons que vous le trouverez utile !Faites-nous savoir si vous avez des questions concernant le rapport sur la couverture de l'indice.Nous aimerions également entendre vos conseils dans les commentaires ci-dessous.