
버킷 및 데이터를 관리하는 예제가 포함된 9개의 AWS S3 명령
게시 됨: 2022-03-15데이터 제어 및 관리는 힘든 작업일 수 있습니다. 이러한 AWS S3 명령은 AWS S3 버킷과 데이터를 빠르고 효율적으로 관리하는 데 도움이 됩니다.
AWS S3는 AWS에서 제공하는 객체 스토리지 서비스입니다. 사실상 무한한 양의 데이터를 저장할 수 있는 AWS에서 가장 널리 사용되는 스토리지 서비스입니다. 가용성이 높고 내구성이 뛰어나며 다른 여러 AWS 서비스와 쉽게 통합됩니다.
AWS S3는 모바일/웹 애플리케이션 스토리지, 빅 데이터 스토리지, 기계 학습 데이터 스토리지, 정적 웹 사이트 호스팅 등과 같은 요구 사항이 있는 사람들이 사용할 수 있습니다.
프로젝트에서 S3를 사용해 왔다면 방대한 양의 스토리지 용량을 감안할 때 100개 버킷과 이 버킷에 있는 테라바이트 데이터를 관리하는 것이 까다로운 작업이 될 수 있다는 것을 알고 있을 것입니다. AWS S3 버킷과 데이터를 효율적으로 관리하는 데 사용할 수 있는 예제와 함께 AWS S3 명령 목록이 있습니다.
AWS CLI 설정
AWS CLI를 성공적으로 다운로드하고 설치했으면 AWS 계정 및 서비스에 액세스할 수 있도록 AWS 자격 증명을 구성해야 합니다. AWS CLI를 구성하는 방법을 빠르게 살펴보겠습니다.
첫 번째 단계는 AWS 계정에 프로그래밍 방식으로 액세스할 수 있는 사용자를 만드는 것입니다. AWS CLI용 사용자를 생성할 때 이 확인란을 선택하는 것을 잊지 마십시오.
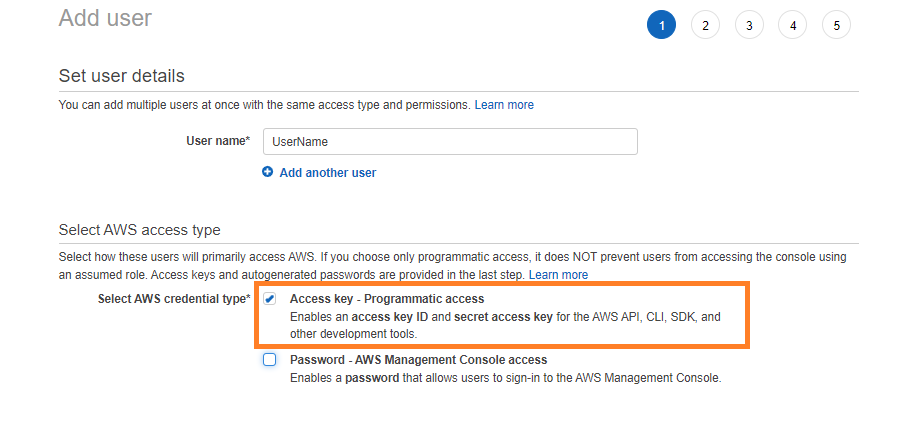
권한을 부여하고 사용자를 생성합니다. 이 사용자를 성공적으로 만든 후 마지막 화면에서 이 사용자의 액세스 키 ID와 비밀 액세스 키를 복사합니다. 이 자격 증명을 사용하여 AWS CLI를 통해 로그인합니다.
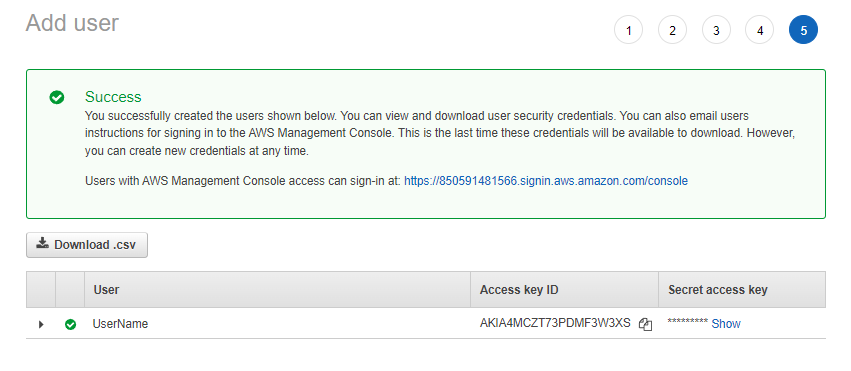
이제 원하는 터미널로 이동하여 다음 명령을 실행합니다.
AWS 구성
메시지가 표시되면 액세스 키 ID와 보안 액세스 키를 입력합니다. 원하는 AWS 리전과 명령 출력 형식을 선택합니다. 저는 개인적으로 JSON 형식을 사용하는 것을 선호합니다. 이것은 나중에 언제든지 이 값을 변경할 수 있는 큰 문제가 아닙니다.

이제 콘솔에서 모든 AWS CLI 명령을 실행할 수 있습니다. 이제 AWS S3 명령을 살펴보겠습니다.
cp
cp 명령은 단순히 S3 버킷과 데이터를 복사합니다. 로컬에서 S3로, S3에서 로컬로, 두 S3 버킷 간에 파일을 복사하는 데 사용할 수 있습니다. 명령과 함께 제공할 수 있는 다른 많은 매개변수가 있습니다.
예를 들어 명령을 테스트하기 위한 -dryrun 매개변수, S3에 있는 데이터의 스토리지 클래스를 지정하기 위한 -storage-class 매개변수, 암호화를 설정하기 위한 기타 매개변수 등. cp 명령을 사용하면 S3에서 데이터 보안을 구성하는 방법을 완전히 제어할 수 있습니다.
용법
aws s3 cp <소스> <대상> [--옵션]
예
로컬에서 S3로 데이터 복사
AWS s3 cp file_name.txt s3://bucket_name/file_name_2.txt
S3에서 로컬로 데이터 복사
AWS s3 cp s3://bucket_name/file_name_2.txt 파일 이름.txt
S3 버킷 간에 데이터 복사
AWS s3 cp s3://bucket_name/file_name.txt s3://bucket_name_2/file_name_2.txt
로컬에서 S3로 데이터 복사 – IA
aws s3 cp file_name.txt s3://bucket_name/file_name_2.txt --storage-class STANDARD_IA
로컬 폴더의 모든 데이터를 S3로 복사
AWS s3 cp ./local_folder s3://bucket_name --재귀적
엘
ls 명령은 버킷 또는 버킷의 내용을 나열하는 데 사용됩니다. 따라서 단순히 버킷 또는 이러한 버킷의 데이터에 대한 정보를 보려면 ls 명령을 사용할 수 있습니다.
용법:
aws s3 ls NONE 또는 <BUCKET_NAME> [--옵션]
예
계정의 모든 버킷 나열
aws s3 ls 산출: 2022-02-02 18:20:14 BUCKET_NAME_1 2022-03-20 13:12:43 BUCKET_NAME_2 2022-03-29 10:52:33 BUCKET_NAME_3
이 명령은 버킷 생성 날짜와 함께 계정의 모든 버킷을 나열합니다.
버킷의 모든 최상위 객체 나열
aws s3 ls BUCKET_NAME_1 또는 s3://BUCKET_NAME_1
산출:
PRE 샘플접두사/
2021-12-09 12:23:20 8754 file_1.png
2021-12-09 12:23:21 1290 file_2.json
2021-12-09 12:23:21 3088 file_3.html
이 명령은 S3 버킷의 모든 최상위 객체를 나열합니다. 여기서 samplePrefix/ 접두사가 있는 객체는 최상위 객체에만 표시되지 않습니다.
버킷의 모든 객체 나열
aws s3 ls BUCKET_NAME_1 또는 s3://BUCKET_NAME_1 --재귀 산출: 2021-12-09 12:23:20 8754 file_1.png 2021-12-09 12:23:21 1290 file_2.json 2021-12-09 12:23:21 3088 file_3.html 2021-12-09 12:23:20 16328 samplePrefix/file_1.txt 2021-12-09 12:23:20 29325 samplePrefix/sampleSubPrefix/file_1.css
이 명령은 S3 버킷의 모든 객체를 나열합니다. 여기서 samplePrefix/ 접두사와 모든 하위 접두사가 있는 객체도 표시됩니다.
메가바이트
mb 명령은 단순히 새 S3 버킷을 생성하는 데 사용됩니다. 이것은 매우 간단한 명령이지만 새 버킷을 생성하려면 새 버킷의 이름이 모든 S3 버킷에서 고유해야 합니다.
용법
aws s3mb <BUCKET_NAME>
예시
특정 리전에서 새 버킷 생성
aws s3 mb myUniqueBucketName --지역 eu-west-1
뮤직비디오
mv 명령은 단순히 데이터를 S3 버킷 간에 이동합니다. cp 명령과 마찬가지로 mv 명령은 로컬에서 S3로, S3에서 로컬로 또는 두 S3 버킷 간에 데이터를 이동하는 데 사용됩니다.

mv와 cp 명령의 유일한 차이점은 mv 명령을 사용할 때 파일이 소스에서 삭제된다는 것입니다. AWS 는 이 파일을 대상으로 이동합니다. 명령으로 지정할 수 있는 옵션이 많이 있습니다.
용법
aws s3 mv <소스> <대상> [--옵션]
예
로컬에서 S3로 데이터 이동
AWS s3 mv file_name.txt s3://bucket_name/file_name_2.txt
S3에서 로컬로 데이터 이동
AWS s3 mv s3://bucket_name/file_name_2.txt 파일 이름.txt
S3 버킷 간에 데이터 이동
AWS s3 mv s3://bucket_name/file_name.txt s3://bucket_name_2/file_name_2.txt
로컬에서 S3로 데이터 이동 – IA
aws s3 mv file_name.txt s3://bucket_name/file_name_2.txt --storage-class STANDARD_IA
S3의 접두사에서 모든 데이터를 로컬 폴더로 이동합니다.
aws s3 mv s3://bucket_name/somePrefix ./localFolder --재귀
미리 서명하다
presign 명령은 S3 버킷의 키에 대해 미리 서명된 URL을 생성합니다. 이 명령을 사용하여 다른 사용자가 지정된 S3 버킷 키의 파일에 액세스하는 데 사용할 수 있는 URL을 생성할 수 있습니다.
용법
aws s3 사전 서명 <OBJECT_KEY> – <TIME_IN_SECONDS> 만료
예시
버킷의 객체에 대해 1시간 동안 유효한 사전 서명된 URL을 생성합니다.
aws s3 사전 서명 s3://bucket_name/samplePrefix/file_name.png --expires-in 3600 산출: https://s3.ap-south-1.amazonaws.com/bucket_name/samplePrefix/file_name.png?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIA4MCZT73PAX7ZMVFW%2F20220314%outh 2Fs3%2Faws4_request&X-Amz-Date=20220314T054113Z&X-Amz-Expires=3600&X-Amz-SignedHeaders=host&X-Amz-Amz-SignedHeaders=host&X-Amz-Amz-Signature=f14608bbf3e1f9eb58d2
RB
rb 명령은 단순히 S3 버킷을 삭제하는 데 사용됩니다.
용법
aws rb <BUCKET_NAME>
예시
S3 버킷을 삭제합니다.
aws s3mb myBucketName # 이 버킷에 데이터가 있으면 이 명령은 실패합니다.
S3 버킷의 데이터와 함께 S3 버킷을 삭제합니다.
aws s3 mb myBucketName --force
RM
rm 명령은 단순히 S3 버킷의 객체를 삭제하는 데 사용됩니다.
용법
aws s3 rm <S3Uri_To_The_File>
예
S3 버킷에서 파일 하나를 삭제합니다.
AWS s3 rm s3://bucket_name/sample_prefix/file_name_2.txt
S3 버킷에서 특정 접두사가 있는 모든 파일을 삭제합니다.
AWS s3 rm s3://bucket_name/sample_prefix --재귀적
S3 버킷의 모든 파일을 삭제합니다.
AWS s3 rm s3://bucket_name --재귀적
동조
sync 명령은 cp 명령과 마찬가지로 소스에서 대상으로 파일을 복사하고 업데이트합니다. cp와 sync 명령의 차이점을 이해하는 것이 중요합니다. cp를 사용하면 데이터가 대상에 이미 존재하더라도 소스에서 대상으로 데이터를 복사합니다.
또한 원본에서 파일이 삭제된 경우 대상에서 파일을 삭제하지 않습니다. 그러나 동기화는 데이터를 복사하기 전에 대상을 확인하고 새 파일과 업데이트된 파일만 복사합니다. sync 명령은 git의 원격 분기에 변경 사항을 커밋하고 푸시하는 것과 유사합니다. sync 명령은 명령을 사용자 정의할 수 있는 많은 옵션을 제공합니다.
용법
aws s3 sync <소스> <대상> [--옵션]
예
로컬 폴더를 S3에 동기화
AWS s3 동기화 ./local_folder s3://bucket_name
S3 데이터를 로컬 폴더에 동기화
AWS s3 동기화 s3://bucket_name ./local_folder
두 S3 버킷 간에 데이터 동기화
AWS s3 동기화 s3://bucket_name s3://bucket_name_2
모든 .txt 파일을 제외한 두 S3 버킷 간에 데이터 이동
aws s3 동기화 s3://bucket_name s3://bucket_name_2 --exclude "*.txt
웹사이트
S3 버킷을 사용하여 정적 웹 사이트를 호스팅할 수 있습니다. 웹 사이트 명령은 버킷에 대한 S3 정적 웹 사이트 호스팅을 구성하는 데 사용됩니다.
인덱스와 오류 파일을 지정하면 S3에서 파일을 볼 수 있는 URL을 제공합니다.
용법
aws s3 웹사이트 <S3_URI> [--옵션]
예시:
S3 버킷에 대한 정적 호스팅 구성 및 인덱스 및 오류 파일 지정
AWS s3 웹사이트 s3://bucket_name --index-document index.html --error-document error.html
결론
위의 내용이 버킷을 관리하기 위해 자주 사용하는 AWS S3 명령에 대한 아이디어를 제공하기를 바랍니다. 더 자세히 알아보려면 AWS 인증 세부 정보를 확인하십시오.