
9 Comandi AWS S3 con esempi per la gestione di bucket e dati
Pubblicato: 2022-03-15Il controllo e la gestione dei dati possono essere un compito faticoso. Questi comandi AWS S3 ti aiuteranno a gestire in modo rapido ed efficiente i tuoi bucket e i tuoi dati AWS S3.
AWS S3 è il servizio di storage di oggetti fornito da AWS. È il servizio di storage più utilizzato di AWS che può contenere virtualmente una quantità infinita di dati. È altamente disponibile, durevole e facile da integrare con molti altri servizi AWS.
AWS S3 può essere utilizzato da persone con qualsiasi esigenza come storage di applicazioni Web/mobile, storage di big data, storage di dati di machine learning, hosting di siti Web statici e molti altri.
Se hai utilizzato S3 nel tuo progetto, sapresti che, data la grande quantità di capacità di archiviazione, la gestione di centinaia di bucket e terabyte di dati in questi bucket può essere un lavoro impegnativo. Abbiamo un elenco di comandi AWS S3 con esempi che puoi utilizzare per gestire i tuoi bucket e dati AWS S3 in modo efficiente.
Configurazione dell'interfaccia a riga di comando di AWS
Dopo aver scaricato e installato con successo l'AWS CLI, devi configurare le credenziali AWS per poter accedere al tuo account e servizi AWS. Esaminiamo rapidamente come configurare AWS CLI.
Il primo passaggio consiste nel creare un utente con accesso programmatico all'account AWS. Ricorda di selezionare questa casella quando crei un utente per AWS CLI.
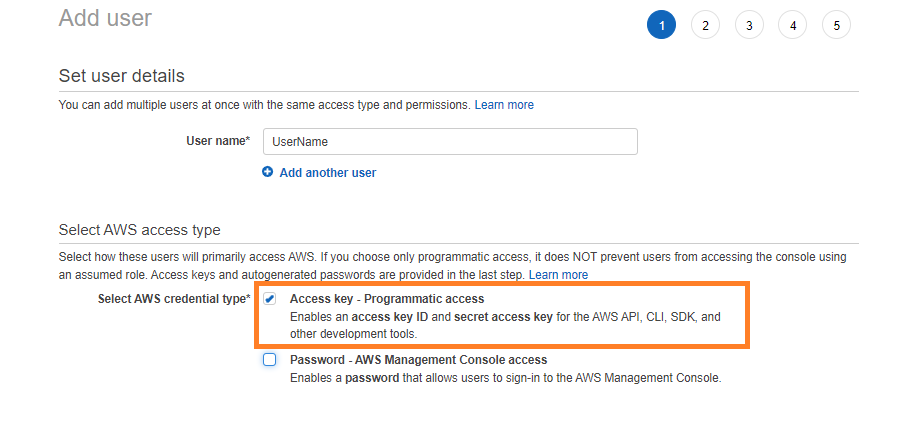
Concedi i permessi e crea un utente. Nella schermata finale dopo aver creato correttamente questo utente, copia l'ID chiave di accesso e la chiave di accesso segreta per questo utente. Utilizzeremo queste credenziali per accedere tramite l'AWS CLI.
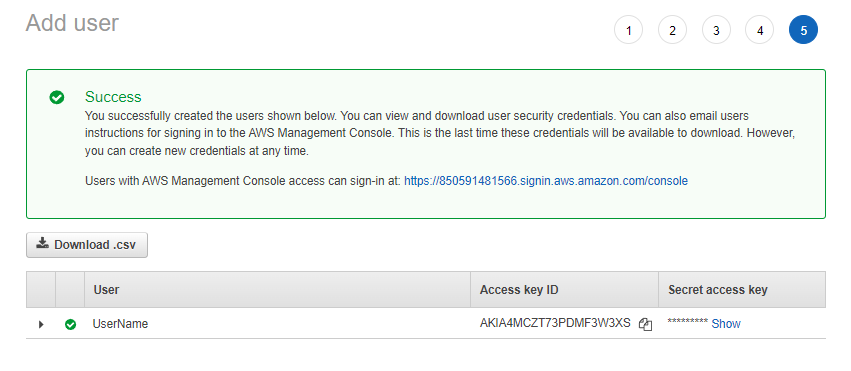
Ora vai al terminale di tua scelta ed esegui il seguente comando.
aws configurare
Immettere l'ID chiave di accesso e la chiave di accesso segreta quando richiesto. Seleziona qualsiasi regione AWS di tua scelta e il formato di output del comando. Personalmente preferisco usare il formato JSON. Questo non è un grosso problema, puoi sempre modificare questi valori in un secondo momento.

Ora puoi eseguire qualsiasi comando AWS CLI nella console. Esaminiamo ora i comandi AWS S3.
cp
Il comando cp copia semplicemente i dati da e verso i bucket S3. Può essere utilizzato per copiare file da locale a S3, da S3 a locale e tra due bucket S3. Ci sono molti altri parametri che puoi fornire con i comandi.
Ad esempio, il parametro -dryrun per testare il comando, il parametro –storage-class per specificare la classe di archiviazione dei dati in S3, altri parametri per impostare la crittografia e molto altro. Il comando cp ti dà il controllo completo su come configurare la sicurezza dei dati in S3.
Utilizzo
aws s3 cp <FONTE> <DESTINAZIONE> [--opzioni]
Esempi
Copia i dati da locale a S3
aws s3 cp nome_file.txt s3://nome_bucket/nome_file_2.txt
Copia i dati da S3 in locale
aws s3 cp s3://nome_bucket/nome_file_2.txt nome_file.txt
Copia i dati tra i bucket S3
aws s3 cp s3://nome_bucket/nome_file.txt s3://nome_bucket_2/nome_file_2.txt
Copia i dati da locale a S3 – IA
aws s3 cp nome_file.txt s3://nome_bucket/nome_file_2.txt --storage-class STANDARD_IA
Copia tutti i dati da una cartella locale in S3
aws s3 cp ./cartella_locale s3://nome_bucket --recursive
ls
Il comando ls viene utilizzato per elencare i bucket o il contenuto dei bucket. Quindi, se desideri semplicemente visualizzare le informazioni sui tuoi bucket o sui dati in questi bucket, puoi utilizzare il comando ls.
Utilizzo:
aws s3 ls NONE o <BUCKET_NAME> [--opzioni]
Esempi
Elenca tutti i bucket nell'account
aws s3 ls Produzione: 2022-02-02 18:20:14 BUCKET_NAME_1 2022-03-20 13:12:43 BUCKET_NAME_2 2022-03-29 10:52:33 BUCKET_NAME_3
Questo comando elenca tutti i bucket nel tuo account con la data di creazione del bucket.
Elenca tutti gli oggetti di primo livello in un bucket
aws s3 ls BUCKET_NAME_1 o s3://BUCKET_NAME_1
Produzione:
PRE campionePrefisso/
2021-12-09 12:23:20 8754 file_1.png
2021-12-09 12:23:21 1290 file_2.json
2021-12-09 12:23:21 3088 file_3.html
Questo comando elenca tutti gli oggetti di primo livello in un bucket S3. Si noti qui che gli oggetti con il prefisso samplePrefix/ non vengono mostrati qui solo gli oggetti di livello superiore.
Elenca tutti gli oggetti in un secchio
aws s3 ls BUCKET_NAME_1 o s3://BUCKET_NAME_1 --recursive Produzione: 2021-12-09 12:23:20 8754 file_1.png 2021-12-09 12:23:21 1290 file_2.json 2021-12-09 12:23:21 3088 file_3.html 2021-12-09 12:23:20 16328 samplePrefix/file_1.txt 2021-12-09 12:23:20 29325 samplePrefix/sampleSubPrefix/file_1.css
Questo comando elenca tutti gli oggetti in un bucket S3. Si noti qui che vengono visualizzati anche gli oggetti con il prefisso samplePrefix/ e tutti i sottoprefissi.
mb
Il comando mb viene semplicemente utilizzato per creare nuovi bucket S3. Questo è un comando abbastanza semplice, ma per creare nuovi bucket, il nome del nuovo bucket deve essere univoco in tutti i bucket S3.
Utilizzo
aws s3 mb <BUCKET_NAME>
Esempio
Crea un nuovo bucket in una regione specifica
aws s3 mb myUniqueBucketName --region eu-west-1
mv
Il comando mv sposta semplicemente i dati da e verso i bucket S3. Proprio come il comando cp, il comando mv viene utilizzato per spostare i dati da locale a S3, da S3 a locale o tra due bucket S3.

L'unica differenza tra il comando mv e il comando cp è che quando si utilizza il comando mv il file viene eliminato dal sorgente. AWS sposta questo file nella destinazione. Ci sono molte opzioni che puoi specificare con il comando.
Utilizzo
aws s3 mv <FONTE> <DESTINAZIONE> [--opzioni]
Esempi
Sposta i dati da locale a S3
aws s3 mv nome_file.txt s3://nome_bucket/nome_file_2.txt
Sposta i dati da S3 a locale
aws s3 mv s3://nome_bucket/nome_file_2.txt nome_file.txt
Sposta i dati tra i bucket S3
aws s3 mv s3://nome_bucket/nome_file.txt s3://nome_bucket_2/nome_file_2.txt
Sposta i dati da locale a S3 – IA
aws s3 mv nome_file.txt s3://nome_bucket/nome_file_2.txt --storage-class STANDARD_IA
Sposta tutti i dati da un prefisso in S3 in una cartella locale.
aws s3 mv s3://bucket_name/somePrefix ./localFolder --recursive
presagire
Il comando presign genera un URL prefirmato per una chiave nel bucket S3. Puoi utilizzare questo comando per generare URL che possono essere utilizzati da altri per accedere a un file nella chiave del bucket S3 specificata.
Utilizzo
aws s3 presign <OBJECT_KEY> –expires-in <TIME_IN_SECONDS>
Esempio
Genera un URL prefirmato valido per 1 ora per un oggetto nel bucket.
aws s3 presign s3://bucket_name/samplePrefix/file_name.png --expires-in 3600 Produzione: https://s3.ap-south-1.amazonaws.com/bucket_name/samplePrefix/file_name.png?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIA4MCZT73PAX7ZMVFW%2F20220314%2Fap-south-1% 2Fs3%2Faws4_request&X-Amz-Date=20220314T054113Z&X-Amz-Expires=3600&X-Amz-SignedHeaders=host&X-Amz-Signature=f14608bbf3e1f9f8d215eb5b439b87e167b1055bcd7a45c13a33debd
rb
Il comando rb viene semplicemente utilizzato per eliminare i bucket S3.
Utilizzo
aws rb <BUCKET_NAME>
Esempio
Elimina un bucket S3.
aws s3 mb myBucketName # Questo comando non riesce se sono presenti dati in questo bucket.
Elimina un bucket S3 insieme ai dati nel bucket S3.
aws s3 mb myBucketName --force
rm
Il comando rm viene semplicemente utilizzato per eliminare gli oggetti nei bucket S3.
Utilizzo
aws s3 rm <S3Uri_To_The_File>
Esempi
Elimina un file dal bucket S3.
aws s3 rm s3://nome_bucket/prefisso_campione/nome_file_2.txt
Elimina tutti i file con un prefisso specifico in un bucket S3.
aws s3 rm s3://nome_bucket/prefisso_campione --recursive
Elimina tutti i file in un bucket S3.
aws s3 rm s3://bucket_name --recursive
sincronizzare
Il comando di sincronizzazione copia e aggiorna i file dall'origine alla destinazione proprio come il comando cp. È importante comprendere la differenza tra il comando cp e sync. Quando usi cp, copia i dati dall'origine alla destinazione anche se i dati esistono già nella destinazione.
Inoltre, non eliminerà i file dalla destinazione se vengono eliminati dall'origine. Tuttavia, la sincronizzazione esamina la destinazione prima di copiare i dati e copia solo i file nuovi e aggiornati. Il comando di sincronizzazione è simile al commit e al push delle modifiche su un ramo remoto in git. Il comando di sincronizzazione offre molte opzioni per personalizzare il comando.
Utilizzo
aws s3 sync <FONTE> <DESTINAZIONE> [--opzioni]
Esempi
Sincronizza la cartella locale su S3
aws s3 sync ./cartella_locale s3://nome_bucket
Sincronizza i dati S3 in una cartella locale
aws s3 sync s3://nome_bucket ./cartella_locale
Sincronizza i dati tra due bucket S3
aws s3 sincronizzazione s3://nome_bucket s3://nome_bucket_2
Sposta i dati tra due bucket S3 escludendo tutti i file .txt
aws s3 sync s3://nome_bucket s3://nome_bucket_2 --exclude "*.txt
sito web
Puoi utilizzare i bucket S3 per ospitare siti Web statici. Il comando website viene utilizzato per configurare l'hosting del sito Web statico S3 per il tuo bucket.
Specificare l'indice e i file di errore e S3 fornisce un URL in cui è possibile visualizzare il file.
Utilizzo
sito web aws s3 <S3_URI> [--opzioni]
Esempio:
Configura l'hosting statico per un bucket S3 e specifica i file di indice e di errore
sito Web aws s3 s3://bucket_name --index-document index.html --error-document error.html
Conclusione
Spero che quanto sopra ti dia un'idea su alcuni dei comandi AWS S3 utilizzati di frequente per gestire i bucket. Se sei interessato a saperne di più, puoi consultare i dettagli della certificazione AWS.