
9バケットとデータを管理するための例を含むAWSS3コマンド
公開: 2022-03-15データの制御と管理は大変な作業になる可能性があります。 これらのAWSS3コマンドは、AWSS3バケットとデータを迅速かつ効率的に管理するのに役立ちます。
AWS S3は、AWSが提供するオブジェクトストレージサービスです。 これは、事実上無限の量のデータを保持できるAWSで最も広く使用されているストレージサービスです。 可用性が高く、耐久性があり、他のいくつかのAWSサービスと簡単に統合できます。
AWS S3は、モバイル/ウェブアプリケーションストレージ、ビッグデータストレージ、機械学習データストレージ、静的ウェブサイトのホスティングなど、あらゆる要件を持つ人々が使用できます。
プロジェクトでS3を使用している場合、膨大なストレージ容量を考えると、これらのバケット内の数百のバケットとテラバイトのデータの管理は困難な作業になる可能性があることをご存知でしょう。 AWSS3バケットとデータを効率的に管理するために使用できる例を含むAWSS3コマンドのリストがあります。
AWSCLIセットアップ
AWS CLIを正常にダウンロードしてインストールしたら、AWSアカウントとサービスにアクセスできるようにAWSクレデンシャルを設定する必要があります。 AWSCLIを構成する方法を簡単に説明します。
最初のステップは、AWSアカウントへのプログラムによるアクセス権を持つユーザーを作成することです。 AWS CLIのユーザーを作成するときは、このチェックボックスをオンにすることを忘れないでください。
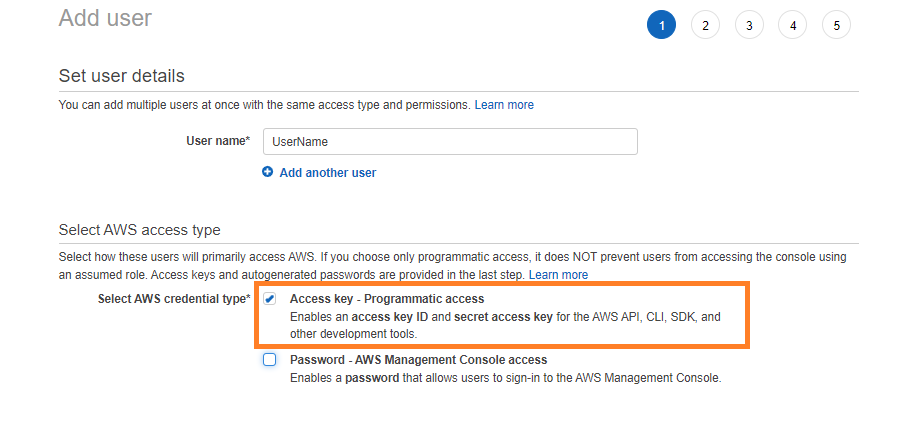
権限を与えてユーザーを作成します。 このユーザーを正常に作成した後の最後の画面で、このユーザーのアクセスキーIDとシークレットアクセスキーをコピーします。 これらのクレデンシャルを使用して、AWSCLIを介してログインします。
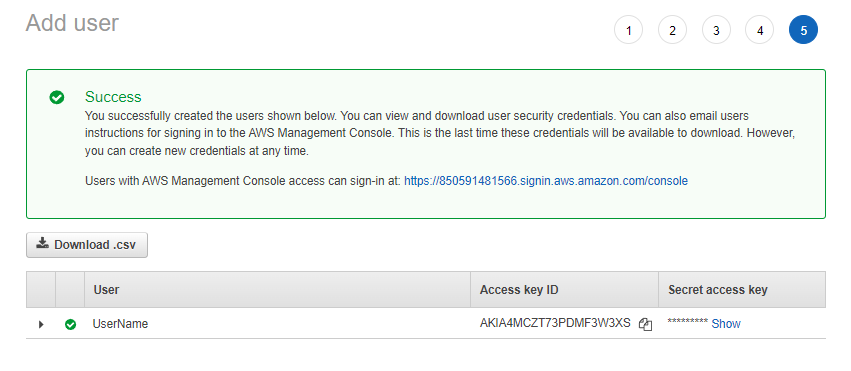
次に、選択したターミナルに移動して、次のコマンドを実行します。
aws configure
プロンプトが表示されたら、アクセスキーIDとシークレットアクセスキーを入力します。 選択したAWSリージョンとコマンド出力形式を選択します。 私は個人的にJSON形式を使用することを好みます。 これは大したことではなく、後でいつでもこれらの値を変更できます。

これで、コンソールで任意のAWSCLIコマンドを実行できます。 ここで、AWSS3コマンドを見ていきましょう。
cp
cpコマンドは、S3バケットとの間でデータをコピーするだけです。 ローカルからS3へ、S3からローカルへ、および2つのS3バケット間でファイルをコピーするために使用できます。 コマンドで指定できるパラメーターは他にもたくさんあります。
たとえば、コマンドをテストするための-dryrunパラメーター、S3でデータのストレージクラスを指定するための–storage-classパラメーター、暗号化を設定するための他のパラメーターなどです。 cpコマンドを使用すると、S3でデータセキュリティを構成する方法を完全に制御できます。
使用法
aws s3 cp <SOURCE> <DESTINATION> [--options]
例
ローカルからS3にデータをコピーします
aws s3 cp file_name.txt s3://bucket_name/file_name_2.txt
S3からローカルにデータをコピーする
aws s3 cp s3://bucket_name/file_name_2.txt file_name.txt
S3バケット間でデータをコピーする
aws s3 cp s3://bucket_name/file_name.txt s3://bucket_name_2/file_name_2.txt
ローカルからS3–IAにデータをコピーします
aws s3 cp file_name.txt s3://bucket_name/file_name_2.txt --storage-class STANDARD_IA
すべてのデータをローカルフォルダからS3にコピーします
aws s3 cp ./local_folder s3://bucket_name --recursive
ls
lsコマンドは、バケットまたはバケットの内容を一覧表示するために使用されます。 したがって、バケットまたはこれらのバケット内のデータに関する情報を表示したいだけの場合は、lsコマンドを使用できます。
使用法:
aws s3lsNONEまたは<BUCKET_NAME>[--options]
例
アカウント内のすべてのバケットを一覧表示します
aws s3 ls 出力: 2022-02-02 18:20:14 BUCKET_NAME_1 2022-03-20 13:12:43 BUCKET_NAME_2 2022-03-29 10:52:33 BUCKET_NAME_3
このコマンドは、アカウント内のすべてのバケットをバケット作成日とともに一覧表示します。
バケット内のすべてのトップレベルオブジェクトを一覧表示します
aws s3 ls BUCKET_NAME_1またはs3:// BUCKET_NAME_1
出力:
PRE samplePrefix /
2021-12-09 12:23:20 8754 file_1.png
2021-12-09 12:23:21 1290 file_2.json
2021-12-09 12:23:21 3088 file_3.html
このコマンドは、S3バケット内のすべての最上位オブジェクトを一覧表示します。 ここでは、接頭辞samplePrefix /が付いたオブジェクトは、最上位のオブジェクトのみに表示されていないことに注意してください。
バケット内のすべてのオブジェクトを一覧表示します
aws s3 ls BUCKET_NAME_1またはs3:// BUCKET_NAME_1 --recursive 出力: 2021-12-09 12:23:20 8754 file_1.png 2021-12-09 12:23:21 1290 file_2.json 2021-12-09 12:23:21 3088 file_3.html 2021-12-09 12:23:20 16328 samplePrefix / file_1.txt 2021-12-09 12:23:20 29325 samplePrefix / sampleSubPrefix / file_1.css
このコマンドは、S3バケット内のすべてのオブジェクトを一覧表示します。 ここで、プレフィックスsamplePrefix/とすべてのサブプレフィックスを持つオブジェクトも表示されることに注意してください。
mb
mbコマンドは、単に新しいS3バケットを作成するために使用されます。 これは非常に単純なコマンドですが、新しいバケットを作成するには、新しいバケットの名前がすべてのS3バケットで一意である必要があります。
使用法
aws s3 mb <BUCKET_NAME>
例
特定の地域に新しいバケットを作成する
aws s3 mb myUniqueBucketName --region eu-west-1
mv
mvコマンドは、データをS3バケットとの間で移動するだけです。 cpコマンドと同様に、mvコマンドは、データをローカルからS3に、S3からローカルに、または2つのS3バケット間で移動するために使用されます。

mvコマンドとcpコマンドの唯一の違いは、mvコマンドを使用すると、ファイルがソースから削除されることです。 AWSはこのファイルを宛先に移動します。 コマンドで指定できるオプションはたくさんあります。
使用法
aws s3 mv <SOURCE> <DESTINATION> [--options]
例
ローカルからS3にデータを移動する
aws s3 mv file_name.txt s3://bucket_name/file_name_2.txt
S3からローカルにデータを移動する
aws s3 mv s3://bucket_name/file_name_2.txt file_name.txt
S3バケット間でデータを移動する
aws s3 mv s3://bucket_name/file_name.txt s3://bucket_name_2/file_name_2.txt
ローカルからS3–IAにデータを移動する
aws s3 mv file_name.txt s3://bucket_name/file_name_2.txt --storage-class STANDARD_IA
S3のプレフィックスからローカルフォルダにすべてのデータを移動します。
aws s3 mv s3://bucket_name/somePrefix ./localFolder --recursive
事前署名
presignコマンドは、S3バケット内のキーの事前署名されたURLを生成します。 このコマンドを使用して、指定されたS3バケットキー内のファイルにアクセスするために他のユーザーが使用できるURLを生成できます。
使用法
aws s3 presign <OBJECT_KEY> –expires-in <TIME_IN_SECONDS>
例
バケット内のオブジェクトに対して1時間有効な事前署名されたURLを生成します。
aws s3 presign s3://bucket_name/samplePrefix/file_name.png --expires-in 3600 出力: https://s3.ap-south-1.amazonaws.com/bucket_name/samplePrefix/file_name.png?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIA4MCZT73PAX7ZMVFW%2F20220314%2Fap-south-1% 2Fs3%2Faws4_request&X-Amz-Date = 20220314T054113Z&X-Amz-Expires = 3600&X-Amz-SignedHeaders = host&X-Amz-Signature = f14608bbf3e1f9f8d215eb5b439b87e167b1055bcd7a45c13
rb
rbコマンドは、S3バケットを削除するために使用されます。
使用法
aws rb <BUCKET_NAME>
例
S3バケットを削除します。
aws s3 mb myBucketName #このバケットにデータがある場合、このコマンドは失敗します。
S3バケット内のデータと一緒にS3バケットを削除します。
aws s3 mb myBucketName --force
rm
rmコマンドは、S3バケット内のオブジェクトを削除するために使用されます。
使用法
aws s3 rm <S3Uri_To_The_File>
例
S3バケットから1つのファイルを削除します。
aws s3 rm s3://bucket_name/sample_prefix/file_name_2.txt
S3バケット内の特定のプレフィックスを持つすべてのファイルを削除します。
aws s3 rm s3://bucket_name/sample_prefix --recursive
S3バケット内のすべてのファイルを削除します。
aws s3 rm s3://bucket_name--再帰
同期
syncコマンドは、cpコマンドと同じように、ソースから宛先にファイルをコピーして更新します。 cpコマンドとsyncコマンドの違いを理解することが重要です。 cpを使用すると、データが宛先にすでに存在している場合でも、ソースから宛先にデータがコピーされます。
また、ソースからファイルが削除された場合、宛先からファイルは削除されません。 ただし、syncはデータをコピーする前に宛先を確認し、新しいファイルと更新されたファイルのみをコピーします。 syncコマンドは、gitのリモートブランチへの変更のコミットとプッシュに似ています。 syncコマンドには、コマンドをカスタマイズするための多くのオプションがあります。
使用法
aws s3 sync <SOURCE> <DESTINATION> [--options]
例
ローカルフォルダをS3に同期する
aws s3 sync ./local_folder s3://bucket_name
S3データをローカルフォルダーに同期する
aws s3 sync s3://bucket_name./local_folder
2つのS3バケット間でデータを同期する
aws s3 sync s3://bucket_name s3://bucket_name_2
すべての.txtファイルを除く2つのS3バケット間でデータを移動する
aws s3 sync s3://bucket_name s3://bucket_name_2 --exclude "* .txt
Webサイト
S3バケットを使用して静的Webサイトをホストできます。 websiteコマンドは、バケットのS3静的Webサイトホスティングを設定するために使用されます。
インデックスとエラーファイルを指定すると、S3はファイルを表示できるURLを提供します。
使用法
awss3ウェブサイト<S3_URI>[--options]
例:
S3バケットの静的ホスティングを設定し、インデックスファイルとエラーファイルを指定します
aws s3ウェブサイトs3://bucket_name --index-document index.html --error-document error.html
結論
上記で、バケットを管理するために頻繁に使用されるAWSS3コマンドのいくつかについてのアイデアが得られることを願っています。 詳細については、AWS認定の詳細をご覧ください。