
고급 페이지 최적화 – 키워드 밀도를 넘어서: SEO를 위한 TF-IDF
게시 됨: 2021-02-26우리 모두는 검색 엔진 최적화(SEO)가 새로운 것이 아니라는 것을 알고 있습니다. 이제는 많은 변화를 겪은 잘 정립되고 많은 측면을 가진 분야입니다. 검색 엔진이 페이지를 평가하고 순위를 매기는 방식의 변화로 인해 SEO에서 많은 우여곡절이 발생했습니다(SEO 비용에 대한 이 기사 참조).
링크 빌딩은 상당한 명성을 얻은 또 다른 것입니다. 백링크의 중요성이 명확해지면서 그런 일이 일어났습니다. 특정 사이트의 정보 아키텍처가 중요한 요소로 인식되었을 때 보다 기술적인 SEO가 대두되었습니다.
그때 콘텐츠의 중요성이 분명해졌습니다. 검색 엔진은 사이트에 고품질의 관련 콘텐츠가 있어야 한다는 사실을 알려 주었습니다. 처음에는 SEO 전문가가 키워드 밀도 및 키워드 계획 도구를 실행하도록 이끌었습니다. 짧은 순서대로 그것이 최선의 방법이 아니라는 것이 명백해졌습니다. 또는 적어도 키워드 채우기와 같은 그늘진 관행에 이러한 도구를 사용하는 것은 작동하지 않을 것입니다. 그것은 검색 엔진 알고리즘을 속이지 않을 것입니다.
Google 및 기타 검색 엔진은 실제 고품질 콘텐츠를 찾고 있습니다. 그들은 가정된 주제와 진정으로 관련이 있고 사용자의 원하는 의도에 응답하는 콘텐츠에 대해 보상합니다. 이러한 콘텐츠를 만드는 것은 유명하거나 악명 높은 메딕 업데이트에서 복구하기 위한 Google의 주요 조언이었습니다.
상담 예약
결과적으로 Google 및 기타 검색 엔진이 콘텐츠의 주제와 의미를 정확하게 평가하고 평가할 수 있다는 것은 명백합니다. 이를 수행하는 한 가지 방법은 tf-idf를 사용하는 것입니다. Tf-idf는 검색 엔진에서 사용하는 가장 오래된 순위 요소 중 하나입니다. 가장 간단한 수준에서 페이지가 무엇인지 이해할 수 있습니다.
SEO용 tf-idf에 대한 이 궁극적인 가이드는 필요한 모든 정보를 제공합니다. tf-idf가 무엇이고 어떻게 작동하는지, tf-idf가 SEO와 어떻게 관련되는지, tf-idf 분석을 언제 어떻게 활용할 수 있는지에 대해 다룹니다.
TF-IDF란 무엇입니까?
Tf-idf는 정보 검색에 사용되는 수치 통계입니다. 컬렉션 또는 '말뭉치'의 다른 문서와 비교하여 주어진 문서에서 단어나 구가 얼마나 중요한지를 나타냅니다. tf-idf 값은 단어나 구가 문서에 나타나는 횟수에 비례하여 증가합니다.
그런 다음 말뭉치의 모든 문서에서 해당 단어나 구가 나타나는 횟수로 상쇄됩니다. 이는 일부 단어가 일반적으로 더 자주 사용된다는 사실을 조정하므로 중요합니다.
'최고의 SEO'와 같은 검색어를 예로 들어 보겠습니다. 'The'는 말뭉치 전체의 모든 문서에서 여러 번 나타나는 단어입니다. 결과적으로 검색된 문서에 'the'가 나타나는 경우 덜 일반적인 다른 단어가 나타나는 경우보다 td-idf 값에 덜 중요합니다.
Tf-idf는 두 통계의 곱입니다. 하나를 다른 하나에 곱한다는 의미입니다. 그것이 단어나 구의 중요성을 나타내고 해당 단어나 구의 일반적인 빈도를 상쇄하는 방법입니다. 두 가지 통계는 용어 빈도(tf)와 역 문서 빈도(idf)입니다.
기간 빈도
용어 빈도는 tf-idf의 단순한 절반입니다. 주어진 문서에서 용어가 얼마나 자주 나타나는지를 나타냅니다. 용어 빈도를 계산하는 데 필요한 것은 문서의 단어 길이와 용어가 나타나는 횟수뿐입니다. 그런 다음 단어가 나타나는 횟수를 총 단어 수로 나눕니다. 즉, 용어 빈도는 항상 0과 1 사이의 값입니다.
가능한 가장 간단한 수준에서 용어 빈도는 다음과 같은 방식으로 계산됩니다.
TF(용어 빈도) = t(문서에 용어가 나타나는 횟수) / d(문서의 총 단어 수)
문서의 길이와 용어가 나타나는 횟수를 고려하면 문서가 주어진 용어와 얼마나 관련이 있는지 알 수 있습니다. 그러나 일반적으로 해당 용어가 문서에 얼마나 자주 나타나는지 알지 못한다면 확실하게 알 수 없습니다. 여기서 역문서 빈도(idf)가 등장합니다.
역 문서 빈도
많은 문서에서 매우 자주 사용되는 단어는 특정 검색어와 관련된 문서를 결정하는 데 적합하지 않습니다. 역 문서 빈도는 이러한 일반적인 용어에 대한 가중치를 줄이는 통계입니다.
이는 'the quick brown fox'를 검색하는 경우 문서에 여러 번 나타나는 'the'가 다른 단어가 있는 경우만큼 중요하지 않도록 합니다. 역 문서 빈도는 단어 또는 용어가 제공하는 정보의 양을 측정한 것입니다.
idf를 계산하는 공식은 매우 복잡해 보입니다.
IDF = 로그(Nd/fi)
부품으로 나누면 그렇게 복잡하지 않습니다.
로그는 단순히 이해하기에 그다지 중요하지 않은 수학 함수입니다. 필요한 경우 계산기의 '로그' 버튼을 누르기만 하면 됩니다. 'Nd'는 검색 중인 콜렉션 또는 말뭉치의 문서 수입니다. 'fi'는 검색어가 포함된 문서의 수입니다.
그런 다음 문서 수를 검색어가 있는 문서 수로 나눈 다음 로그 기능을 적용하여 IDF 값을 얻습니다.
TF-IDF 해결 예
이제 우리가 배운 것을 매우 간단한 예에 사용할 수 있습니다. 100단어 문서가 있고 '키워드'라는 단어를 검색한다고 가정해 보겠습니다. 해당 단어가 세 번 나타나면 다음과 같이 용어 빈도를 계산할 수 있습니다.
3(문서의 용어 수) / 100(총 단어 수) = 0.03
임기 빈도는 0.03입니다. 이제 검색한 말뭉치에 총 1,000만 개의 문서가 있고 그 중 1,000개에 'keyword'가 나타난다고 합시다. 이제 idf를 해결하는 데 필요한 모든 것이 있습니다.
로그(10,000,000 / 1,000) = 4
역 문서 빈도는 4입니다. tf-idf 값은 단순히 용어 빈도에 idf를 곱한 값이므로 다음과 같습니다.
0.03(tf) x 4(idf) = 0.12
tf-idf 값은 0.12입니다. 그 자체로는 많은 것을 알 수 없지만 다른 값과 비교할 수 있습니다. tf-idf 값이 높을수록 주어진 문서에서 용어가 더 중요합니다. 가장 높은 tf-idf 값은 말뭉치에서 용어 빈도가 높고 해당 용어를 특징으로 하는 문서 수가 적을 때 발생합니다. 다음 표는 이를 입증하는 데 도움이 됩니다.
기간 빈도(TF) | 코퍼스 크기(Nd) | 기간이 있는 문서(fi) | 역 문서 빈도(IDF) | TF-IDF |
0.03 | 10,000,000 | 1,000 | 4 | 0.12 |
0.04 | 10,000,000 | 900 | 4.05 | 0.162 |
0.05 | 10,000,000 | 800 | 4.10 | 0.205 |
| 0.06 | 10,000,000 | 700 | 4.15 | 0.249 |
| 0.07 | 10,000,000 | 600 | 4.22 | 0.295 |
TF-IDF, SEO 및 LSI
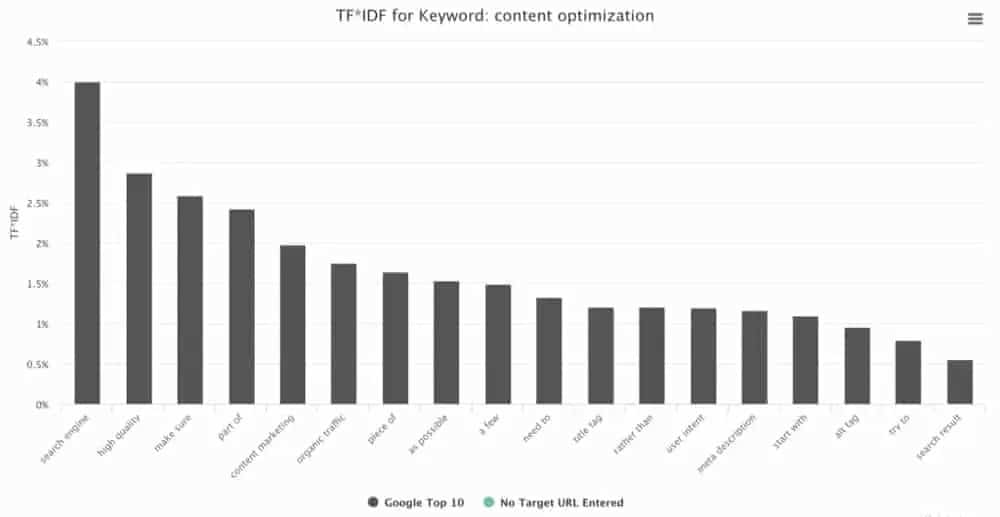
Tf-idf는 LSI(Latent Semantic Indexing)의 일부로 가장 자주 사용됩니다. 이것은 확실히 tf-idf와 SEO를 직접 연결하는 것입니다. tf-idf를 사용한 LSI는 언어를 처리하는 기술입니다. 개별 검색어 또는 더 넓은 주제 영역에 대한 관련성을 기반으로 문서 순위를 지정할 수 있습니다.
LSI는 구조화되지 않은 텍스트 모음에서 서로 다른 구문과 개념 간의 관계에서 패턴을 식별하여 작동합니다. 동일한 맥락에서 사용되는 단어는 관련되거나 유사한 의미를 갖는 경향이 있다는 생각에 기반합니다.

용어와 구 사이의 패턴을 설정함으로써 LSI는 텍스트 본문의 일반적인 주제나 주제를 식별할 수 있게 합니다. tf-idf가 포함된 LSI가 문서 코퍼스에 적용되면 쿼리 또는 검색어가 더 정확한 결과를 반환합니다.
이는 결과에 검색과 개념적으로 유사한 문서가 포함되기 때문입니다. 문서에 검색어의 특정 단어가 포함되어 있지 않은 경우에도 마찬가지입니다. tf-idf를 사용하는 LSI의 목표는 문서 코퍼스의 실제 주제와 초점을 이해하는 것입니다.
요컨대 LSI의 일부로 사용되는 tf-idf는 기계가 텍스트 페이지가 무엇인지 이해할 수 있도록 합니다. 따라서 Google 및 기타 검색 엔진이 콘텐츠의 관련성과 유용성을 평가할 수 있는 방법입니다.
SEO에 대한 tf-idf의 중요성은 확실히 더 명확해지고 있습니다. 이는 초기 검색 엔진 순위 요소 중 하나이며 검색 엔진 및 SERP의 핵심 빌딩 블록으로 볼 수도 있습니다. 더 중요한 것은 tf-idf가 Google이 검색어 또는 검색어와 관련된 페이지의 실제 관련성과 유용성을 평가하는 데 도움이 된다는 것입니다.
그것은 tf-idf에 대한 우리의 더 나은 이해가 어떻게 SEO에 사용될 수 있는지에 대한 질문을 던집니다. 그것이 SaaS SEO 대행사이든 유기적 트래픽을 늘리려는 소기업 소유주이든 상관 없습니다. AJ Ghergich는 주제에 대한 SEMrush 비디오에서 다음과 같이 말했습니다.
'tf-idf의 전반적인 목표는 문서 모음에서 단어가 얼마나 중요한지를 통계적으로 측정하는 것입니다. 정말 유용한 키워드 밀도 도구와 같습니다.'
셈러시
그것은 깔끔한 작은 비유이지만 약간 오해의 소지가 있습니다. Tf-idf 분석은 콘텐츠에 삽입할 키워드를 식별하는 데 가장 적합하지 않습니다. 일종의 콘텐츠 영감 도구라고 생각하시면 좋을 것 같습니다.
tf-idf를 사용하여 자신의 콘텐츠를 순위가 더 높은 유사한 페이지와 비교하면 콘텐츠를 풍부하게 하는 방법에 대한 제안을 얻을 수 있습니다. 순위가 높은 콘텐츠가 페이지보다 tf-idf 값이 더 좋은 키워드와 구문을 가리킵니다.
그러면 귀하의 콘텐츠가 다루지 않는 주제 영역과 주제가 유사 페이지뿐만 아니라 상세하게 표시됩니다. 그러면 Google이 좋아할 만한 방식으로 콘텐츠를 개선하는 방법에 대한 로드맵이 생깁니다. 그것은 관련성을 높이고 특정 키워드나 문구를 검색하는 독자의 의도를 얼마나 잘 충족시키는가입니다.
SEO에 TF-IDF 사용
SEO에 TF-IDF를 사용하는 것은 키워드 밀도에 관한 것이 아닙니다. 그 이상으로 잘 움직입니다.
tf-idf 분석을 수행하면 귀하의 콘텐츠와 다른 페이지에서 다루지 않는 용어와 구문이 드러납니다. 다음 단계는 키워드 밀도를 높이기 위해 기존 콘텐츠 내에 해당 문구를 삽입하지 않는 것입니다. 원하는 것은 해당 문구를 둘러싼 주제 및 주제와 더 관련성이 있도록 콘텐츠를 최적화하는 것입니다.
예를 들어 SEO가 주요 주제인 페이지가 있을 수 있습니다. tf-idf 분석은 SEO 검색에서 높은 순위를 차지하는 다른 페이지보다 '링크 구축'이라는 용어에 대한 가치가 낮다는 것을 밝힐 수 있습니다. 이는 귀하의 콘텐츠가 링크 구축에 대한 관련성 있고 유용한 정보를 충분히 제공하지 않는다는 것을 의미합니다. 간단하게 콘텐츠를 개선할 수 있는 확실한 방법이 있습니다.
콘텐츠 개선에 대해 생각하기 전에 tf-idf 분석을 수행하는 방법을 알아야 합니다. 지금 당장 처리합시다.
TF-IDF 분석을 완료하는 방법

tf-idf 분석을 수동으로 실행하여 자체 계산을 수행하는 것이 기술적으로 가능합니다. 가능하지만 권장되지 않습니다. 이미 본 것처럼 계산은 약간 복잡해질 수 있으며 항상 시간이 걸립니다.
그게 가장 큰 문제도 아닙니다. tf-idf 분석은 콘텐츠를 비교하는 코퍼스가 관련성이 있고 유용한 경우에만 가치가 있습니다. 중요한 키워드에 대해 좋은 평가를 받는 다른 페이지와 콘텐츠의 tf-idf 값을 비교할 수 있기를 원합니다. Ryte에서 제공하는 것과 같은 tf-idf 도구가 필요한 곳입니다.
Ryte의 도구는 주어진 키워드 또는 검색 쿼리에 대한 상위 10개 Google 검색 결과와 사이트의 실제 URL을 비교할 수 있습니다. 그런 다음 순위가 높은 콘텐츠의 tf-idf 값이 높은 중요한 관련 용어 및 구문 목록을 제공합니다.
또한 Ryte의 도구는 해당 문구 및 용어에 대해 선택한 URL을 평가합니다. 콘텐츠가 각각에 대해 높은, 높은 또는 낮은 tf-idf 값을 가지고 있는지 여부를 보여줍니다.
이 정보는 콘텐츠를 개선해야 하는 부분과 방법을 보여줍니다. 페이지에서 충분히 효율적으로 다루지 않는 주제와 주제를 제공합니다. 따라서 독자의 요구와 의도에 더 잘 맞도록 페이지를 조정할 수 있습니다.
이제 tf-idf 분석을 언제 사용해야 하는지 궁금할 것입니다. 결국 SEO 분야 내외에서 해야 할 일이 많이 있습니다.
TF-IDF 분석을 사용해야 하는 경우
사이트 콘텐츠 개선에 대해 생각하기에 나쁜 시간은 없습니다. 또한 하루에 너무 많은 시간이 있습니다. 즉, 차이를 만들 가능성이 가장 높은 상황에서 tf-idf 분석을 구현하는 것이 가장 좋습니다. 그러한 상황에 대한 몇 가지 예가 있습니다.
- 기존 콘텐츠의 잠재력 잠금 해제
Tf-idf는 Google 검색의 두 번째 페이지에서 지속적으로 순위를 매기는 페이지가 있는 경우 정말 유용할 수 있습니다. 순위에서 너무 높은 순위에 도달한 페이지는 분명히 잠재력이 있습니다. tf-idf 분석은 첫 페이지로 마지막 도약을 만드는 데 필요한 정확한 조정 및 추가 작업을 수행하는 데 도움이 될 수 있습니다.
- 새로운 콘텐츠 계획 안내
tf-idf 분석은 콘텐츠에 대한 영감으로 탁월합니다. 특정 주제 및 주제에 대해 순위가 높은 페이지에 대한 분석을 수행하면 자신의 콘텐츠가 무엇을 다루어야 하는지 알 수 있습니다. 이는 수많은 새로운 콘텐츠에 대한 계획을 스케치하는 훌륭한 기초가 될 수 있습니다.
- 하락하는 순위 저지하기
최고 실적을 내는 페이지가 있지만 중요한 키워드에 대한 순위가 떨어지고 있는 경우 tf-idf도 도움이 될 수 있습니다. 귀하의 페이지를 능가하는 페이지가 더 나은 tf-idf 값을 달성하는 키워드와 주제를 보여줄 수 있습니다. 그런 다음 그에 따라 자신의 콘텐츠를 개선하고 업데이트할 수 있습니다.
SEO용 TF-IDF – 키워드 밀도를 넘어 이동
SEO의 현대 세계에는 고려해야 할 사항이 너무 많습니다. 사이트 아키텍처, 링크, 키워드 밀도 및 기타 모든 기존 요소는 여전히 중요합니다. 그러나 이제는 콘텐츠가 왕이라고 주장할 수 있습니다. 또는 적어도 다른 요소만큼 많은 관심을 기울여야 합니다.
더 이상 사이트에서 키워드 채우기 또는 중복되거나 숨겨진 스팸 콘텐츠로 페이지를 채우는 일을 피할 수 없습니다. 사이트는 독자에게 진정으로 유용한 고품질 콘텐츠를 포함해야 합니다. Tf-idf는 Google 및 기타 검색 엔진이 이와 관련하여 콘텐츠를 평가하는 주요 방법입니다.
따라서 tf-idf가 어떻게 작동하고 SEO와 어떻게 관련되는지 이해하는 것이 중요합니다. SEO를 위한 tf-idf에 대한 적절한 이해와 구현은 콘텐츠를 풍부하게 하고 유기적 트래픽에서 보상을 확인하는 데 도움이 될 수 있습니다.
상담 예약

Nick Brown은 SaaS SEO 에이전시인 가속 에이전시의 설립자이자 CEO입니다. Nick은 몇 가지 성공적인 온라인 비즈니스를 시작했고, Forbes에 글을 쓰고, 책을 출판했으며, 영국 에이전시에서 현재 미국, APAC 및 EMEA 전역에서 운영되고 160명의 직원을 고용하는 회사로 빠르게 성장했습니다. 그는 또한 한때 마운틴 고릴라에 의해 기소되었습니다.