
高度なオンページ最適化 – キーワード密度を超えて: SEO のための TF-IDF
公開: 2021-02-26検索エンジン最適化 (SEO) が新しいものではないことは誰もが知っています。 現在では、多くの変化を経て確立された多面的な分野となっています。 検索エンジンがページを評価してランク付けする方法が変化したことで、SEO に多くの紆余曲折が生じました (SEO のコストに関するこの記事を参照してください)。
リンク構築は、重要な注目を集めたもう 1 つのことです。 バックリンクの重要性が明らかになると、それは起こりました。 特定のサイトの情報アーキテクチャが重要な要素として認識されたとき、より技術的な SEO が前面に出てきました。
その後、コンテンツの重要性が明らかになりました。 検索エンジンは、サイトには高品質で関連性の高いコンテンツが必要であることを認識させました。 最初は、SEO の専門家がキーワード密度とキーワード プランニング ツールを求めて走り出すようになりました。 すぐに、それが最善の方法ではないことが明らかになりました。 または、少なくとも、これらのツールをキーワードの詰め込みなどの怪しげな慣行に使用することはうまくいかない. 検索エンジンのアルゴリズムをだますことはありません。
Google やその他の検索エンジンは、実際に質の高いコンテンツを探しています。 想定される主題に真に関連し、ユーザーの意図に応えるコンテンツに報酬を与えます。 このようなコンテンツを作成することは、有名な、または悪名高い Medic Update から回復するための Google からの主なアドバイスでした。
相談を予約する
その結果、Google や他の検索エンジンがコンテンツの主題と意味を正確に評価および評価できることは明らかです。 これを行う 1 つの方法は、tf-idf を使用することです。 Tf-idf は、検索エンジンで使用される最も古いランキング要素の 1 つです。 最も単純なレベルでは、ページが何であるかを理解することができます。
この SEO のための tf-idf の究極のガイドは、必要になる可能性のあるすべての情報を提供します。 tf-idf とは何か、その仕組み、tf-idf と SEO との関係、tf-idf 分析をいつどのように利用できるかについて説明します。
TF-IDFとは?
Tf-idf は、情報検索で使用される数値統計です。 コレクションまたは「コーパス」内の他のドキュメントと比較して、単語またはフレーズが特定のドキュメントにとってどれほど重要であるかを表します。 tf-idf 値は、単語または語句がドキュメントに出現する回数に比例して増加します。
これは、コーパス内のすべてのドキュメントでその単語またはフレーズが出現する回数によって相殺されます。 これは、一部の単語が一般的な用法でより頻繁に使用されるという事実を調整するため、重要です。
「最高の SEO」のような検索語の例を見てみましょう。 「The」は、コーパス全体のすべての文書に何度も現れる単語です。 結果として、検索されたドキュメントに「the」が表示された場合、td-idf 値にとって重要性は低くなります。
Tf-idf は、2 つの統計の積です。 互いに掛け合わせるという意味です。 これは、単語またはフレーズの重要性を表し、その単語またはフレーズの一般的な頻度を相殺する方法です。 2 つの統計は、用語頻度 (tf) と逆ドキュメント頻度 (idf) です。
期間の頻度
ターム頻度は、tf-idf の単純な半分です。 特定のドキュメントに用語が出現する頻度を表します。 用語の頻度を計算するために必要なのは、ドキュメントの単語の長さと用語の出現回数だけです。 次に、その単語が出現する回数を合計単語数で割ります。 つまり、単語の頻度は常に 0 から 1 の間の値になります。
最も単純なレベルでは、単語の頻度は次のように計算されます。
TF (用語の頻度) = t (文書内に用語が出現する回数) / d (文書内の総単語数)
ドキュメントの長さと用語が出現する回数を考慮することで、そのドキュメントが特定の用語にどの程度関連しているかを正確に把握できます。 ただし、その用語がドキュメントに一般的にどのくらいの頻度で表示されるかを知らない限り、確実に知ることはできません。 そこで、Inverse Document Frequency (idf) の出番です。
逆ドキュメント頻度
多くのドキュメントで頻繁に使用される単語は、特定の検索用語に関連するドキュメントを判断するのに適していません。 Inverse Document Frequency は、これらの一般的な用語にかかる重みを軽減する統計です。
これにより、'the quick brown fox' を検索している場合、ドキュメント内に何度も出現する 'the' は、他の単語が存在する場合ほど重要ではなくなります。 Inverse Document Frequency は、単語または用語が提供する情報量の尺度です。
idf を計算する式は非常に複雑に見えます。
IDF = ログ (Nd / fi)
パーツに分解すると、それほど複雑ではありません。
Log は単なる数学関数であり、理解することはあまり重要ではありません。 必要に応じて、電卓の「ログ」ボタンを押すだけです。 「Nd」は、検索対象のコレクションまたはコーパス内のドキュメントの数です。 'fi' は、検索語を含むドキュメントの数です。
次に、ドキュメントの数を検索語を含むドキュメントの数で割り、ログ関数を適用することで、IDF 値を取得します。
TF-IDF の解決例
これまでに学んだことを、非常に単純な例として使用できます。 100 ワードの文書があり、「キーワード」という単語を検索するとします。 その単語が 3 回出現する場合、単語の頻度は次のように計算できます。
3(ドキュメント内の用語数) / 100 (総単語数) = 0.03
用語の頻度は 0.03 です。 ここで、検索するコーパスに合計 1,000 万のドキュメントがあり、そのうちの 1,000 に「キーワード」が表示されているとします。 これで、IDF を計算するために必要なすべてが揃いました。
ログ (10,000,000 / 1,000) = 4
逆ドキュメント頻度は 4 です。tf-idf 値は、用語頻度に idf を掛けたものなので、次のようになります。
0.03 (tf) × 4 (idf) = 0.12
tf-idf 値は 0.12 です。 それ自体ではあまりわかりませんが、他の値と比較することはできます。 tf-idf 値が高いほど、特定のドキュメントにとって用語が重要になります。 tf-idf 値が最も高くなるのは、用語の頻度が高く、コーパス内でその用語を取り上げるドキュメントの数が少ない場合です。 次の表は、これを示すのに役立ちます。
ターム頻度 (TF) | コーパスサイズ (Nd) | 期間のあるドキュメント (fi) | 逆ドキュメント頻度 (IDF) | TF-IDF |
0.03 | 10,000,000 | 1,000 | 4 | 0.12 |
0.04 | 10,000,000 | 900 | 4.05 | 0.162 |
0.05 | 10,000,000 | 800 | 4.10 | 0.205 |
| 0.06 | 10,000,000 | 700 | 4.15 | 0.249 |
| 0.07 | 10,000,000 | 600 | 4.22 | 0.295 |
TF-IDF、SEO、LSI
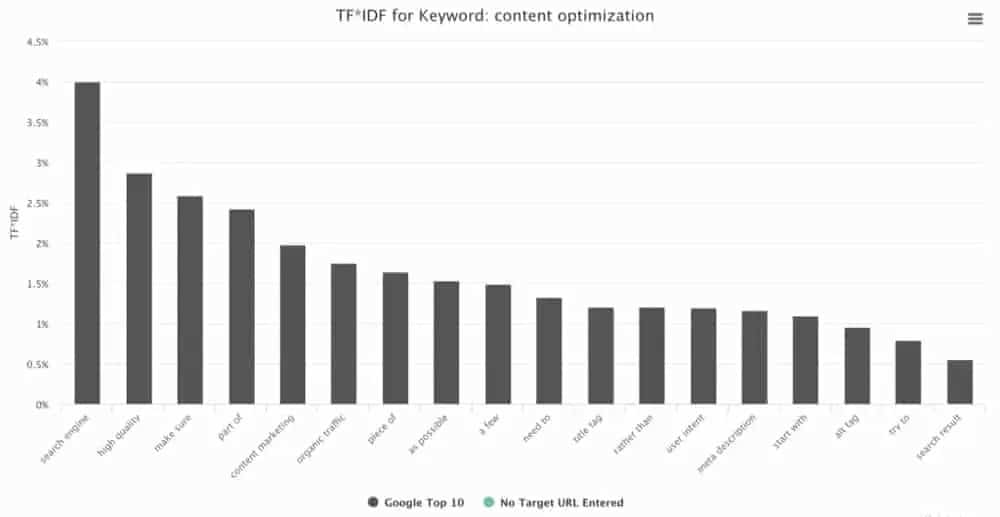
Tf-idf は、Latent Semantic Indexing (LSI) の一部として最もよく使用されます。 これは確かに tf-idf と SEO を直接接続するものです。 LSI with tf-idf は言語を処理する技術です。 これにより、個々の検索用語またはより広いトピック領域との関連性に基づいてドキュメントをランク付けできます。
LSI は、構造化されていないテキスト コレクション内のさまざまなフレーズと概念の間の関係のパターンを識別することによって機能します。 これは、同じ文脈で使用される単語は、関連または類似の意味を持つ傾向があるという考えに基づいています。

用語と句の間のパターンを確立することにより、LSI はテキスト本文の一般的なトピックまたは主題を識別することを可能にします。 tf-idf を使用した LSI がドキュメントのコーパスに適用されると、クエリまたは検索語はより正確な結果を返します。
これは、検索結果と概念的に類似した意味を持つドキュメントが結果に含まれるためです。 これは、ドキュメントに検索用語の特定の単語が含まれていない場合でも当てはまります。 tf-idf を使用した LSI の目標は、ドキュメントのコーパスの実際の主題と焦点を理解することです。
要するに、tf-idf を LSI の一部として使用すると、マシンはテキストのページが何であるかを理解できます。 したがって、Google やその他の検索エンジンがコンテンツの関連性と有用性を評価する方法です。
SEO に対する tf-idf の重要性は、確実に明らかになりつつあります。 これは、最も初期の検索エンジンのランキング要因の 1 つであり、検索エンジンと SERP の重要な構成要素と見なすことさえできます。 さらに重要なことに、tf-idf は、Google が検索用語やクエリに関連するページの実際の関連性と有用性を評価するのに役立ちます。
これは、tf-idf のより良い理解を SEO にどのように使用できるかという問題を引き起こします。 それが SaaS SEO エージェンシーによるものであろうと、オーガニック トラフィックを増加させようとしている中小企業の所有者によるものであろうと。 AJ Ghergich は、このトピックに関する SEMrush ビデオで意見を述べました。
「tf-idf の全体的な目標は、ドキュメントのコレクション内で単語がどれほど重要であるかを統計的に測定することです。 これは、ステロイドの非常に便利なキーワード密度ツールのようなものです。
SEMrush
これはよく似た例えですが、少し誤解を招く可能性があります。 Tf-idf 分析は、コンテンツに挿入するキーワードを特定するのに最適な方法ではありません。 一種のコンテンツ インスピレーション ツールと考えたほうがよいでしょう。
tf-idf を使用して、独自のコンテンツをよりランクの高い同様のページと比較すると、コンテンツを充実させる方法に関する提案を得ることができます。 これは、ランクの高いコンテンツがあなたのページよりも tf-idf 値が優れているキーワードやフレーズを示します。
これにより、コンテンツがカバーしていない分野やトピックが詳細に、または同様のページで表示されます。 これで、Google が確実に気に入る方法でコンテンツを改善するためのロードマップができあがります。 それは、その関連性を高め、特定のキーワードやフレーズを検索している潜在的な読者の意図をどれだけうまく満たすかです.
SEO に TF-IDF を使用する
SEO に TF-IDF を使用することは、キーワードの密度に関するものではありません。 それをはるかに超えて動いています。
tf-idf 分析を実行すると、コンテンツで扱っていない用語やフレーズ、および他のページが明らかになります。 次のステップは、既存のコンテンツにこれらのフレーズを挿入してキーワードの密度を高めることではありません。 あなたがしたいことは、コンテンツを最適化して、それらのフレーズを取り巻くトピックや主題により関連するようにすることです.
たとえば、SEO を主なトピックとするページがあるとします。 tf-idf 分析では、SEO 検索で上位にランクされる他のページよりも「リンク構築」という用語の価値が低いことが明らかになる場合があります。 これは、あなたのコンテンツが、リンクの構築に関する適切で有用な情報を十分に提供していないことを示しています. それと同じくらい簡単に、コンテンツを改善する明確な方法があります。
コンテンツの改善について考える前に、tf-idf 分析の実行方法を知る必要があります。 今すぐ対処しましょう。
TF-IDF 分析を完了する方法

tf-idf 分析を手動で実行して、独自の計算を実行することは技術的に可能です。 可能ですが、お勧めしません。 すでに見てきたように、計算は少し複雑になる可能性があり、常に時間がかかります。
それは最大の問題ではありません。 tf-idf 分析は、コンテンツを比較するコーパスが関連性があり有用である場合にのみ価値があります。 コンテンツの tf-idf 値を、重要なキーワードの評価が高い他のページと比較できるようにしたいと考えています。 そこで、Ryte が提供するような tf-idf ツールの出番です。
Ryte のツールは、サイトのライブ URL を、特定のキーワードまたは検索クエリの上位 10 件の Google 検索結果と比較できます。 次に、上位にランク付けされたコンテンツの tf-idf 値が高い重要な関連用語およびフレーズのリストを提供します。
さらに、Ryte のツールは、選択した URL をそれらのフレーズや用語に対して評価します。 コンテンツのそれぞれの tf-idf 値が高いか、高いか、低いかが表示されます。
その情報は、コンテンツをどこでどのように改善する必要があるかを示します。 あなたのページが十分にカバーしていないトピックやテーマを提供します。 したがって、読者のニーズと意図に合わせてページを調整することができます。
いつ tf-idf 解析を使用する必要があるのか疑問に思っていることでしょう。 結局のところ、SEO の分野の内外で、やらなければならないことは他にもたくさんあります。
TF-IDF 分析を使用する場合
サイトのコンテンツを改善することを考えるのに悪い時期はありません。 また、一日の時間は限られています。 つまり、違いが生じる可能性が最も高い状況で tf-idf 分析を実装するのが最善であることを意味します。 そのような状況の例はいくつかあります。
- 既存コンテンツの可能性を解き放つ
Tf-idf は、Google 検索の 2 ページ目に一貫してランク付けされているページがある場合に非常に役立ちます。 ランキングで非常に高くなったので、このページには明らかに可能性があります。 tf-idf 分析は、ページ 1 への最後の飛躍に必要な正確な微調整と追加を解決するのに役立ちます。
- 新しいコンテンツ プランのガイド
tf-idf 分析は、コンテンツのインスピレーションとして優れています。 特定の主題やトピックで上位にランクされているページを分析すると、自分のコンテンツで何をカバーする必要があるかがわかります。 これは、新しいコンテンツのホスト全体の計画をスケッチするための優れた基礎となる可能性があります.
- ランキングの下落を阻止する
以前はトップパフォーマーだったが、重要なキーワードのランキングが下がっているページがある場合、tf-idf はそこでも役立ちます。 あなたのページを追い越したページがより良いtf-idf値を達成しているキーワードとトピックを示すことができます。 その後、それに応じて独自のコンテンツを改善および更新できます。
SEO のための TF-IDF – キーワード密度の先へ
現代の SEO の世界では、考慮すべきことがたくさんあります。 サイトのアーキテクチャ、リンク、キーワードの密度、およびその他すべての従来の要素は依然として重要です。 しかし、今やコンテンツが王様であると主張することもできます。 または、少なくとも、他の要因と同じくらい注意を払う必要があります。
サイトは、キーワードの詰め込みや、重複または非表示のスパム コンテンツでページを埋め尽くすことから逃れることはできなくなりました。 サイトには、読者にとって真に役立つ高品質のコンテンツが含まれている必要があります。 Tf-idf は、Google や他の検索エンジンがその点でコンテンツを評価する主要な方法です。
したがって、tf-idf がどのように機能し、SEO とどのように関係しているかを理解することが重要です。 SEO のための tf-idf の適切な理解と実装は、コンテンツを充実させ、オーガニック トラフィックの報酬を確認するのに役立ちます。
相談を予約する

ニック・ブラウンは、SaaS SEO エージェンシーであるアクセラレータ エージェンシーの創設者兼 CEO です。 Nick はいくつかの成功したオンライン ビジネスを立ち上げ、Forbes に寄稿し、本を出版し、英国の代理店から、現在は米国、APAC、EMEA で事業を展開し、160 人の従業員を抱える企業へと急速に成長しました。 彼はかつてマウンテンゴリラに突撃されたこともある