
機械学習におけるサポート ベクター マシン (SVM)
公開: 2023-01-04サポート ベクター マシンは、最も人気のある機械学習アルゴリズムの 1 つです。 効率的で、限られたデータセットでトレーニングできます。 しかし、それは何ですか?
サポート ベクター マシン (SVM) とは何ですか?
サポート ベクター マシンは、教師あり学習を使用してバイナリ分類のモデルを作成する機械学習アルゴリズムです。 それは一口です。 この記事では、SVM と、それが自然言語処理にどのように関係しているかについて説明します。 しかし、最初に、サポート ベクター マシンがどのように機能するかを分析しましょう。
SVM の仕組み
x と y の 2 つの特徴と 1 つの出力 (赤または青のいずれかの分類) を持つデータがある単純な分類問題を考えてみましょう。 次のような架空のデータセットをプロットできます。

このようなデータが与えられた場合、タスクは決定境界を作成することです。 決定境界は、データ ポイントの 2 つのクラスを分離する線です。 これは同じデータセットですが、決定境界があります。
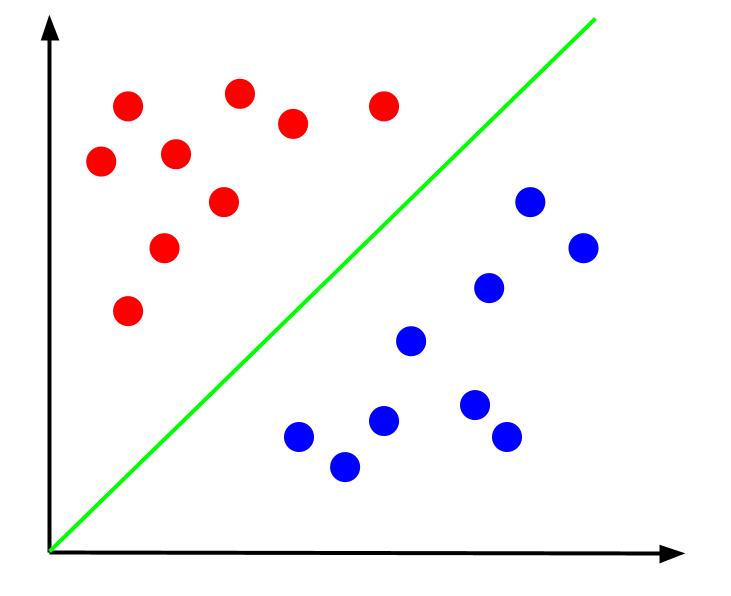
この決定境界を使用して、データポイントが決定境界に対して相対的にどこにあるかを考慮して、データポイントが属するクラスを予測できます。 サポート ベクター マシン アルゴリズムは、ポイントの分類に使用される最適な決定境界を作成します。
しかし、最善の決定境界とは何を意味するのでしょうか?
最良の決定境界は、いずれかのサポート ベクターからの距離を最大化するものであると主張できます。 サポート ベクターは、反対のクラスに最も近いいずれかのクラスのデータ ポイントです。 これらのデータ ポイントは、他のクラスに近接しているため、誤分類の最大のリスクをもたらします。

したがって、サポート ベクター マシンのトレーニングでは、サポート ベクター間のマージンを最大化する直線を見つけようとします。
決定境界はサポート ベクターに対して相対的に配置されるため、決定境界の位置の唯一の決定要因であることに注意することも重要です。 したがって、他のデータ ポイントは冗長です。 したがって、トレーニングにはサポート ベクターのみが必要です。
この例では、形成される決定境界は直線です。 これは、データセットに特徴が 2 つしかないためです。 データセットに 3 つの特徴がある場合、形成される決定境界は線ではなく平面になります。 また、4 つ以上の特徴がある場合、決定境界は超平面として知られています。
非線形分離可能なデータ
上記の例では、プロットすると線形決定境界で分離できる非常に単純なデータを考慮しました。 データが次のようにプロットされる別のケースを考えてみましょう。

この場合、線を使用してデータを区切ることはできません。 しかし、別の機能 z を作成することもできます。 この機能は、次の式で定義できます: z = x^2 + y^2。 平面に 3 番目の軸として z を追加して、平面を 3 次元にすることができます。
x 軸が水平で z 軸が垂直になるような角度から 3D プロットを見ると、次のようなビューが得られます。
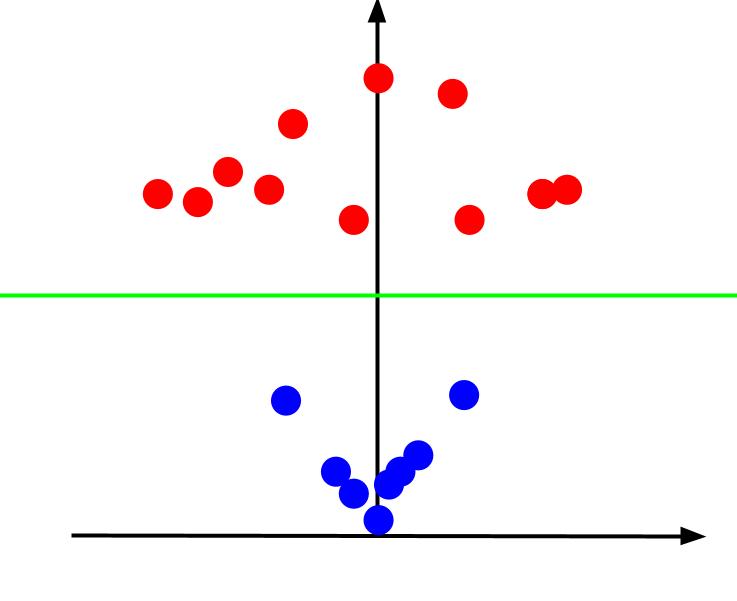
Z 値は、古い XY 平面内の他のポイントを基準にして、ポイントが原点からどれだけ離れているかを表します。 その結果、原点に近い青い点の Z 値は低くなります。
原点から離れた赤い点はより高い Z 値を持っていましたが、それらを Z 値に対してプロットすると、図に示すように、線形決定境界によって区切られる明確な分類が得られます。
これは、サポート ベクター マシンで使用される強力なアイデアです。 より一般的には、次元をより多くの次元にマッピングして、データ ポイントを線形境界で分離できるようにするという考え方です。 これを担当する関数はカーネル関数です。 シグモイド、線形、非線形、RBF など、多くのカーネル関数があります。
これらの機能のマッピングをより効率的にするために、SVM はカーネル トリックを使用します。
機械学習における SVM
サポート ベクター マシンは、デシジョン ツリーやニューラル ネットワークなどの一般的なアルゴリズムと並んで、機械学習で使用される多くのアルゴリズムの 1 つです。 他のアルゴリズムよりも少ないデータでうまく機能するため、好まれています。 これは、次のことを行うために一般的に使用されます。
- テキスト分類: コメントやレビューなどのテキスト データを 1 つまたは複数のカテゴリに分類する
- 顔検出: 画像を分析して顔を検出し、拡張現実用のフィルターを追加するなどのことを行います
- 画像分類: サポート ベクター マシンは、他のアプローチと比較して効率的に画像を分類できます。
テキスト分類問題
インターネットには、膨大な数のテキスト データがあふれています。 ただし、このデータの多くは構造化されておらず、ラベルも付けられていません。 このテキスト データをより適切に使用し、理解を深めるためには、分類が必要です。 テキストが分類される時間の例は次のとおりです。
- つぶやきがトピックごとに分類され、ユーザーが必要なトピックをフォローできるようになっている場合
- メールがソーシャル、プロモーション、スパムのいずれかに分類された場合
- コメントが公開フォーラムで憎悪的またはわいせつと分類された場合
SVM が自然言語分類とどのように連携するか
サポート ベクター マシンは、テキストを特定のトピックに属するテキストとトピックに属さないテキストに分類するために使用されます。 これは、最初にテキスト データをいくつかの特徴を持つデータセットに変換して表すことによって実現されます。
これを行う 1 つの方法は、データ セット内のすべての単語の特徴を作成することです。 次に、テキスト データ ポイントごとに、各単語の出現回数を記録します。 したがって、一意の単語がデータ セットに含まれているとします。 データセットに特徴があります。
さらに、これらのデータ ポイントの分類を提供します。 これらの分類はテキストでラベル付けされていますが、ほとんどの SVM 実装では数値ラベルが想定されています。
したがって、トレーニングの前にこれらのラベルを数値に変換する必要があります。 これらのフィーチャを座標として使用してデータセットを準備したら、SVM モデルを使用してテキストを分類できます。
Python での SVM の作成
Python でサポート ベクター マシン (SVM) を作成するには、 sklearn.svmライブラリのSVCクラスを使用できます。 SVCクラスを使用して Python で SVM モデルを構築する方法の例を次に示します。
from sklearn.svm import SVC # Load the dataset X = ... y = ... # Split the data into training and test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=19) # Create an SVM model model = SVC(kernel='linear') # Train the model on the training data model.fit(X_train, y_train) # Evaluate the model on the test data accuracy = model.score(X_test, y_test) print("Accuracy: ", accuracy) この例では、最初にsklearn.svmライブラリからSVCクラスをインポートします。 次に、データセットを読み込み、トレーニング セットとテスト セットに分割します。
次に、 SVCオブジェクトをインスタンス化し、 kernelパラメーターを 'linear' として指定して、SVM モデルを作成します。 次に、 fitメソッドを使用してトレーニング データでモデルをトレーニングし、 scoreメソッドを使用してテスト データでモデルを評価します。 scoreメソッドは、コンソールに出力するモデルの精度を返します。
正則化の強度を制御するCパラメーターや、特定のカーネルのカーネル係数を制御するgammaパラメーターなど、 SVCオブジェクトの他のパラメーターを指定することもできます。
SVM の利点
サポート ベクター マシン (SVM) を使用する利点の一覧を次に示します。
- 効率的: SVM は、特にサンプル数が多い場合に、一般的に効率的にトレーニングできます。
- ノイズに対するロバスト : SVM は、他の分類器よりもノイズの影響を受けにくい最大マージン分類器を見つけようとするため、トレーニング データのノイズに対して比較的ロバストです。
- メモリ効率: SVM は、トレーニング データのサブセットのみを常にメモリに格納する必要があるため、他のアルゴリズムよりもメモリ効率が高くなります。
- 高次元空間で効果的:特徴の数がサンプルの数を超えた場合でも、SVM は適切に機能します。
- 汎用性: SVM は分類および回帰タスクに使用でき、線形および非線形データを含むさまざまなタイプのデータを処理できます。
それでは、サポート ベクター マシン (SVM) を学ぶのに最適なリソースをいくつか見ていきましょう。
学習リソース
サポート ベクター マシンの概要
サポート ベクター マシンの紹介に関するこの本では、カーネル ベースの学習方法を包括的かつ段階的に紹介しています。
| プレビュー | 製品 | 評価 | 価格 | |
|---|---|---|---|---|
 | サポート ベクター マシンとその他のカーネル ベースの学習方法の紹介 | $75.00 | アマゾンで購入 |
サポート ベクター マシン理論の確固たる基盤を提供します。

サポート ベクター マシン アプリケーション
最初の本はサポート ベクター マシンの理論に焦点を当てていましたが、サポート ベクター マシンのアプリケーションに関するこの本は、それらの実際のアプリケーションに焦点を当てています。
| プレビュー | 製品 | 評価 | 価格 | |
|---|---|---|---|---|
 | サポート ベクター マシン アプリケーション | $15.52 | アマゾンで購入 |
画像処理、パターン検出、コンピューター ビジョンで SVM がどのように使用されているかを調べます。
サポート ベクター マシン (情報科学と統計学)
サポート ベクター マシン (情報科学および統計) に関するこの本の目的は、さまざまなアプリケーションにおけるサポート ベクター マシン (SVM) の有効性の背後にある原則の概要を提供することです。
| プレビュー | 製品 | 評価 | 価格 | |
|---|---|---|---|---|
 | サポート ベクター マシン (情報科学と統計学) | $167.36 | アマゾンで購入 |
著者らは、限られた数の調整可能なパラメーターで適切に機能する能力、さまざまな種類のエラーや異常に対する耐性、および他の方法と比較した効率的な計算パフォーマンスなど、SVM の成功に寄与するいくつかの要因を強調しています。
カーネルで学習する
『Learning with Kernels』は、サポート ベクター マシン (SVM) および関連するカーネル テクニックを読者に紹介する本です。
| プレビュー | 製品 | 評価 | 価格 | |
|---|---|---|---|---|
 | カーネルを使った学習: サポート ベクター マシン、正則化、最適化、およびその先 (適応… | $80.00 | アマゾンで購入 |
数学の基本的な理解と、機械学習でカーネル アルゴリズムの使用を開始するために必要な知識を読者に提供するように設計されています。 本書の目的は、SVM とカーネル メソッドの完全かつアクセスしやすい入門書を提供することです。
Sci-kit Learn によるベクター マシンのサポート
Coursera プロジェクト ネットワークによるこのオンラインの Support Vector Machines with Sci-kit Learn コースでは、一般的な機械学習ライブラリである Sci-Kit Learn を使用して SVM モデルを実装する方法を説明しています。

さらに、SVM の背後にある理論を学び、その長所と制限を判断します。 コースは初級レベルで、所要時間は約 2.5 時間です。
Python でのベクター マシンのサポート: 概念とコード
Udemy による Python のサポート ベクター マシンに関するこの有料オンライン コースでは、最大 6 時間のビデオベースの説明があり、認定資格が付属しています。

SVM と、それらを Python で確実に実装する方法について説明します。 さらに、サポート ベクター マシンのビジネス アプリケーションについても説明します。
機械学習と AI: Python でのベクター マシンのサポート
機械学習と AI に関するこのコースでは、画像認識、スパム検出、医療診断、回帰分析など、さまざまな実用的なアプリケーションにサポート ベクター マシン (SVM) を使用する方法を学習します。

Python プログラミング言語を使用して、これらのアプリケーションの ML モデルを実装します。
最後の言葉
この記事では、サポート ベクター マシンの背後にある理論について簡単に説明しました。 機械学習と自然言語処理におけるそれらのアプリケーションについて学びました。
また、 scikit-learnを使用した実装がどのように見えるかについても確認しました。 さらに、サポート ベクター マシンの実用的なアプリケーションと利点についても説明しました。
この記事は単なる紹介でしたが、サポート ベクター マシンについて詳しく説明する追加のリソースが推奨されていました。 SVM の多用途性と効率性を考えると、データ サイエンティストおよび ML エンジニアとして成長するには、SVM を理解する価値があります。
次に、上位の機械学習モデルを確認できます。