
Máquina de vectores de soporte (SVM) en aprendizaje automático
Publicado: 2023-01-04Support Vector Machine es uno de los algoritmos de aprendizaje automático más populares. Es eficiente y puede entrenar en conjuntos de datos limitados. ¿Pero, qué es esto?
¿Qué es una máquina de vectores de soporte (SVM)?
La máquina de vectores de soporte es un algoritmo de aprendizaje automático que utiliza el aprendizaje supervisado para crear un modelo para la clasificación binaria. Eso es un bocado. Este artículo explicará SVM y cómo se relaciona con el procesamiento del lenguaje natural. Pero primero, analicemos cómo funciona una máquina de vectores de soporte.
¿Cómo funciona SVM?
Considere un problema de clasificación simple en el que tenemos datos que tienen dos características, x e y, y una salida: una clasificación que es roja o azul. Podemos trazar un conjunto de datos imaginario que se ve así:

Dados datos como este, la tarea sería crear un límite de decisión. Un límite de decisión es una línea que separa las dos clases de nuestros puntos de datos. Este es el mismo conjunto de datos pero con un límite de decisión:
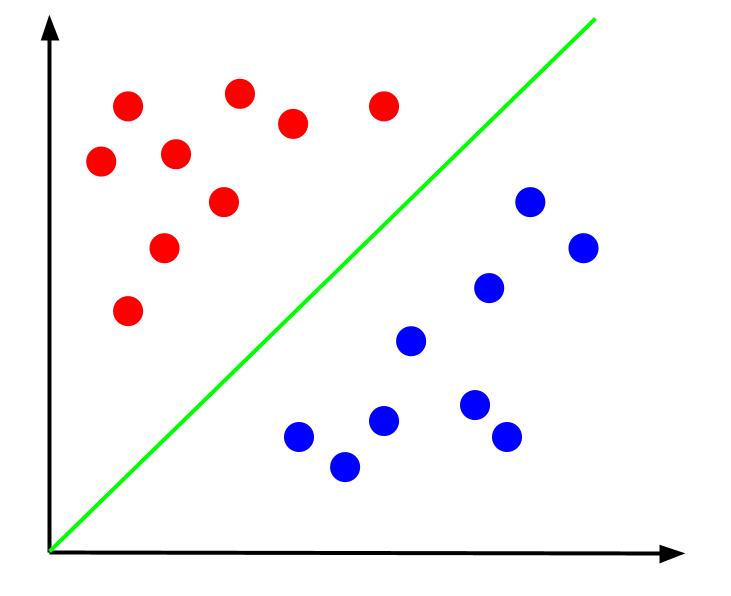
Con este límite de decisión, podemos hacer predicciones para la clase a la que pertenece un punto de datos, dado dónde se encuentra en relación con el límite de decisión. El algoritmo Support Vector Machine crea el mejor límite de decisión que se utilizará para clasificar los puntos.
Pero, ¿qué entendemos por límite de mejor decisión?
Se puede argumentar que el mejor límite de decisión es el que maximiza su distancia desde cualquiera de los vectores de soporte. Los vectores de soporte son puntos de datos de cualquier clase más cercanos a la clase opuesta. Estos puntos de datos presentan el mayor riesgo de clasificación errónea debido a su proximidad a la otra clase.

Por lo tanto, el entrenamiento de una máquina de vectores de soporte implica tratar de encontrar una línea que maximice el margen entre los vectores de soporte.
También es importante señalar que debido a que el límite de decisión está posicionado en relación con los vectores de soporte, estos son los únicos determinantes de la posición del límite de decisión. Los otros puntos de datos son, por lo tanto, redundantes. Y así, el entrenamiento solo requiere los vectores de soporte.
En este ejemplo, el límite de decisión formado es una línea recta. Esto es solo porque el conjunto de datos tiene solo dos características. Cuando el conjunto de datos tiene tres características, el límite de decisión formado es un plano en lugar de una línea. Y cuando tiene cuatro o más características, el límite de decisión se conoce como hiperplano.
Datos separables no lineales
El ejemplo anterior consideró datos muy simples que, cuando se grafican, pueden separarse por un límite de decisión lineal. Considere un caso diferente donde los datos se grafican de la siguiente manera:

En este caso, es imposible separar los datos mediante una línea. Pero podemos crear otra función, z. Y esta característica puede definirse mediante la ecuación: z = x^2 + y^2. Podemos agregar z como un tercer eje al plano para hacerlo tridimensional.
Cuando miramos la gráfica 3D desde un ángulo tal que el eje x es horizontal mientras que el eje z es vertical, esta es la vista que obtenemos algo que se parece a esto:
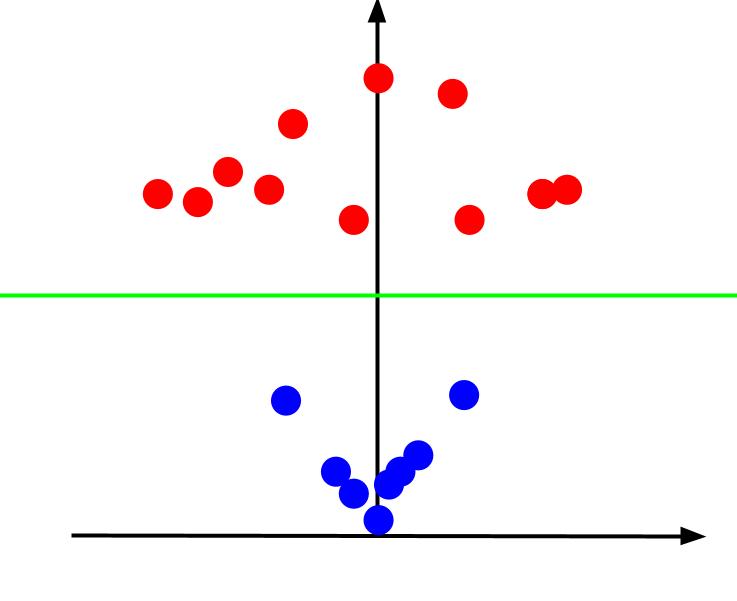
El valor z representa qué tan lejos está un punto del origen en relación con los otros puntos en el antiguo plano XY. Como resultado, los puntos azules más cercanos al origen tienen valores z bajos.
Si bien los puntos rojos más alejados del origen tenían valores z más altos, graficarlos contra sus valores z nos brinda una clasificación clara que puede demarcarse mediante un límite de decisión lineal, como se ilustra.
Esta es una idea poderosa que se utiliza en las máquinas de vectores de soporte. De manera más general, es la idea de mapear las dimensiones en un mayor número de dimensiones para que los puntos de datos puedan estar separados por un límite lineal. Las funciones que son responsables de esto son funciones del núcleo. Hay muchas funciones del núcleo, como sigmoide, lineal, no lineal y RBF.
Para que el mapeo de estas características sea más eficiente, SVM utiliza un truco del núcleo.
SVM en aprendizaje automático
Support Vector Machine es uno de los muchos algoritmos utilizados en el aprendizaje automático junto con los populares como Decision Trees y Neural Networks. Se prefiere porque funciona bien con menos datos que otros algoritmos. Se usa comúnmente para hacer lo siguiente:
- Clasificación de texto : clasificación de datos de texto, como comentarios y reseñas, en una o más categorías
- Detección de rostros : análisis de imágenes para detectar rostros para hacer cosas como agregar filtros para realidad aumentada
- Clasificación de imágenes : las máquinas de vectores de soporte pueden clasificar imágenes de manera eficiente en comparación con otros enfoques.
El problema de clasificación de texto
Internet está lleno de montones y montones de datos textuales. Sin embargo, gran parte de estos datos no están estructurados ni etiquetados. Para utilizar mejor estos datos de texto y comprenderlos mejor, es necesario clasificarlos. Ejemplos de momentos en los que se clasifica el texto incluyen:
- Cuando los tweets se clasifican en temas para que las personas puedan seguir los temas que desean
- Cuando un correo electrónico se clasifica como Social, Promociones o Spam
- Cuando los comentarios se clasifican como odiosos u obscenos en foros públicos
Cómo funciona SVM con la clasificación del lenguaje natural
Support Vector Machine se utiliza para clasificar texto en texto que pertenece a un tema en particular y texto que no pertenece al tema. Esto se logra convirtiendo y representando primero los datos de texto en un conjunto de datos con varias características.
Una forma de hacerlo es creando características para cada palabra en el conjunto de datos. Luego, para cada punto de datos de texto, registra la cantidad de veces que aparece cada palabra. Así que supongamos que están ocurriendo palabras únicas en el conjunto de datos; tendrá características en el conjunto de datos.
Además, proporcionará clasificaciones para estos puntos de datos. Si bien estas clasificaciones están etiquetadas por texto, la mayoría de las implementaciones de SVM esperan etiquetas numéricas.
Por lo tanto, deberá convertir estas etiquetas en números antes del entrenamiento. Una vez que se ha preparado el conjunto de datos, usando estas características como coordenadas, puede usar un modelo SVM para clasificar el texto.
Crear una SVM en Python
Para crear una máquina de vectores de soporte (SVM) en Python, puede usar la clase SVC de la biblioteca sklearn.svm . Aquí hay un ejemplo de cómo puede usar la clase SVC para construir un modelo SVM en Python:
from sklearn.svm import SVC # Load the dataset X = ... y = ... # Split the data into training and test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=19) # Create an SVM model model = SVC(kernel='linear') # Train the model on the training data model.fit(X_train, y_train) # Evaluate the model on the test data accuracy = model.score(X_test, y_test) print("Accuracy: ", accuracy) En este ejemplo, primero importamos la clase SVC de la biblioteca sklearn.svm . Luego, cargamos el conjunto de datos y lo dividimos en conjuntos de entrenamiento y prueba.
A continuación, creamos un modelo SVM instanciando un objeto SVC y especificando el parámetro del kernel como 'lineal'. Luego, entrenamos el modelo con los datos de entrenamiento usando el método de fit y evaluamos el modelo con los datos de prueba usando el método de score . El método de score devuelve la precisión del modelo, que imprimimos en la consola.
También puede especificar otros parámetros para el objeto SVC , como el parámetro C que controla la fuerza de la regularización y el parámetro gamma , que controla el coeficiente del kernel para ciertos kernels.
Beneficios de SVM
Aquí hay una lista de algunos beneficios de usar máquinas de vectores de soporte (SVM):
- Eficiente : las SVM son generalmente eficientes para entrenar, especialmente cuando la cantidad de muestras es grande.
- Robusto frente al ruido : las SVM son relativamente robustas frente al ruido en los datos de entrenamiento, ya que intentan encontrar el clasificador de margen máximo, que es menos sensible al ruido que otros clasificadores.
- Eficiencia de memoria: las SVM solo requieren que un subconjunto de los datos de entrenamiento estén en la memoria en un momento dado, lo que las hace más eficientes en memoria que otros algoritmos.
- Eficaz en espacios de gran dimensión: las SVM aún pueden funcionar bien incluso cuando la cantidad de funciones supera la cantidad de muestras.
- Versatilidad : las SVM se pueden usar para tareas de clasificación y regresión y pueden manejar varios tipos de datos, incluidos datos lineales y no lineales.
Ahora, exploremos algunos de los mejores recursos para aprender Support Vector Machine (SVM).

Recursos de aprendizaje
Una introducción a las máquinas de vectores de soporte
Este libro sobre Introducción a las máquinas de vectores de soporte lo introduce de manera integral y gradual a los métodos de aprendizaje basados en kernel.
| Avance | Producto | Clasificación | Precio | |
|---|---|---|---|---|
 | Una introducción a las máquinas de vectores de soporte y otros métodos de aprendizaje basados en kernel | $75.00 | Comprar en Amazon |
Le brinda una base sólida en la teoría de las máquinas de vectores de soporte.
Aplicaciones de Máquinas de Vectores de Soporte
Mientras que el primer libro se centró en la teoría de las máquinas de vectores de soporte, este libro sobre las aplicaciones de las máquinas de vectores de soporte se centra en sus aplicaciones prácticas.
| Avance | Producto | Clasificación | Precio | |
|---|---|---|---|---|
 | Aplicaciones de Máquinas de Vectores de Soporte | $15.52 | Comprar en Amazon |
Analiza cómo se utilizan las SVM en el procesamiento de imágenes, la detección de patrones y la visión artificial.
Máquinas de Vectores Soporte (Ciencias de la Información y Estadística)
El propósito de este libro sobre Máquinas de vectores de soporte (ciencias de la información y estadísticas) es proporcionar una descripción general de los principios detrás de la efectividad de las máquinas de vectores de soporte (SVM) en varias aplicaciones.
| Avance | Producto | Clasificación | Precio | |
|---|---|---|---|---|
 | Máquinas de Vectores Soporte (Ciencias de la Información y Estadística) | $167.36 | Comprar en Amazon |
Los autores destacan varios factores que contribuyen al éxito de las SVM, incluida su capacidad para funcionar bien con un número limitado de parámetros ajustables, su resistencia a varios tipos de errores y anomalías y su rendimiento computacional eficiente en comparación con otros métodos.
Aprendizaje con núcleos
“Learning with Kernels” es un libro que presenta a los lectores las máquinas vectoriales compatibles (SVM) y las técnicas de kernel relacionadas.
| Avance | Producto | Clasificación | Precio | |
|---|---|---|---|---|
 | Aprendizaje con núcleos: máquinas de vectores de soporte, regularización, optimización y más (Adaptive… | $80.00 | Comprar en Amazon |
Está diseñado para brindar a los lectores una comprensión básica de las matemáticas y el conocimiento que necesitan para comenzar a usar los algoritmos del kernel en el aprendizaje automático. El libro tiene como objetivo proporcionar una introducción completa pero accesible a las SVM y los métodos del núcleo.
Admite máquinas vectoriales con Sci-kit Learn
Este curso en línea Support Vector Machines with Sci-kit Learn de la red de proyectos de Coursera enseña cómo implementar un modelo SVM utilizando la popular biblioteca de aprendizaje automático, Sci-Kit Learn.

Además, aprenderá la teoría detrás de las SVM y determinará sus fortalezas y limitaciones. El curso es de nivel principiante y requiere alrededor de 2,5 horas.
Máquinas de vectores de soporte en Python: conceptos y código
Este curso en línea pago sobre Support Vector Machines en Python de Udemy tiene hasta 6 horas de instrucción en video y viene con una certificación.

Cubre SVM y cómo se pueden implementar sólidamente en Python. Además, cubre las aplicaciones comerciales de Support Vector Machines.
Aprendizaje automático e IA: Máquinas de vectores de soporte en Python
En este curso sobre aprendizaje automático e inteligencia artificial, aprenderá a utilizar máquinas de vectores de soporte (SVM) para diversas aplicaciones prácticas, incluido el reconocimiento de imágenes, la detección de spam, el diagnóstico médico y el análisis de regresión.

Utilizará el lenguaje de programación Python para implementar modelos ML para estas aplicaciones.
Ultimas palabras
En este artículo, aprendimos brevemente sobre la teoría detrás de las máquinas de vectores de soporte. Aprendimos sobre su aplicación en Machine Learning y Natural Language Processing.
También vimos cómo se ve su implementación usando scikit-learn . Además, hablamos de las aplicaciones prácticas y beneficios de las Máquinas de Vectores Soporte.
Si bien este artículo fue solo una introducción, los recursos adicionales recomendaron entrar en más detalles y explicar más sobre las máquinas de vectores de soporte. Dado lo versátiles y eficientes que son, vale la pena comprender las SVM para crecer como científico de datos e ingeniero de ML.
A continuación, puede consultar los mejores modelos de aprendizaje automático.