
Makine Öğreniminde Regresyon ve Sınıflandırmanın Açıklanması
Yayınlanan: 2022-12-19Regresyon ve sınıflandırma, makine öğreniminin en temel ve önemli alanlarından ikisidir.
Makine öğrenimine yeni başladığınızda, Regresyon ve Sınıflandırma algoritmalarını ayırt etmek zor olabilir. Bu algoritmaların nasıl çalıştığını ve ne zaman kullanılacağını anlamak, doğru tahminler yapmak ve etkili kararlar almak için çok önemli olabilir.
İlk olarak, makine öğrenimine bir göz atalım.
Makine öğrenimi nedir?

Makine öğrenimi, bilgisayarlara açıkça programlanmadan öğrenmeyi ve karar vermeyi öğretme yöntemidir. Bir veri kümesi üzerinde bir bilgisayar modelinin eğitilmesini içerir, modelin verilerdeki kalıplara ve ilişkilere dayalı olarak tahminler veya kararlar almasına izin verir.
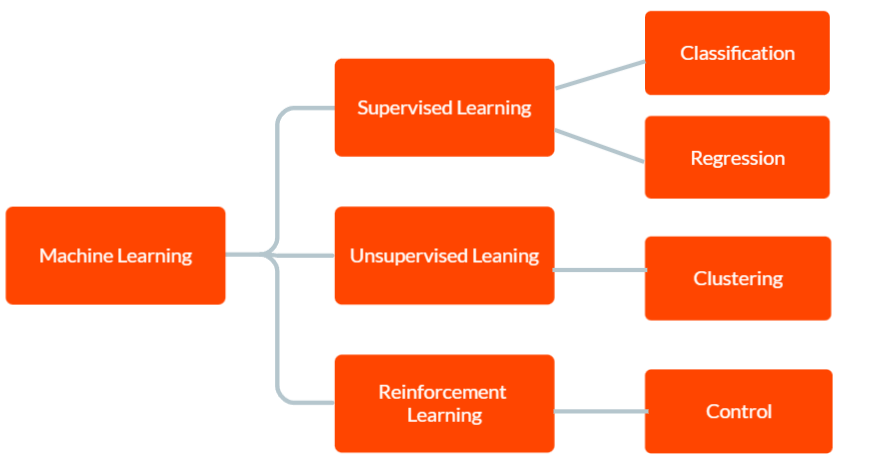
Üç ana makine öğrenimi türü vardır: denetimli öğrenme, denetimsiz öğrenme ve takviyeli öğrenme.
Denetimli öğrenmede modele, giriş verileri ve karşılık gelen doğru çıktı dahil olmak üzere etiketli eğitim verileri sağlanır. Modelin amacı, eğitim verilerinden öğrendiği kalıplara dayalı olarak yeni, görünmeyen verilerin çıktısı hakkında tahminler yapmaktır.
Denetimsiz öğrenmede , modele herhangi bir etiketli eğitim verisi verilmez. Bunun yerine, verilerdeki kalıpları ve ilişkileri bağımsız olarak keşfetmeye bırakılır. Bu, verilerdeki grupları veya kümeleri tanımlamak veya anormallikleri veya olağandışı kalıpları bulmak için kullanılabilir.
Ve Takviyeli Öğrenim'de bir aracı, ödülü en üst düzeye çıkarmak için çevresi ile etkileşim kurmayı öğrenir. Çevreden aldığı geri bildirime dayalı olarak karar vermesi için bir modelin eğitilmesini içerir.
Makine öğrenimi, görüntü ve konuşma tanıma, doğal dil işleme, dolandırıcılık tespiti ve sürücüsüz arabalar dahil olmak üzere çeşitli uygulamalarda kullanılır. Birçok görevi otomatikleştirme ve çeşitli sektörlerde karar vermeyi geliştirme potansiyeline sahiptir.
Bu makale, esas olarak denetimli makine öğrenimi kapsamına giren Sınıflandırma ve Regresyon kavramlarına odaklanmaktadır. Başlayalım!
Makine Öğreniminde Sınıflandırma

Sınıflandırma, belirli bir girdiye sınıf etiketi atamak için bir modelin eğitilmesini içeren bir makine öğrenimi tekniğidir. Denetimli bir öğrenme görevidir, yani model, girdi verilerinin örneklerini ve karşılık gelen sınıf etiketlerini içeren etiketli bir veri kümesi üzerinde eğitilir.
Model, yeni, görünmeyen girdi için sınıf etiketini tahmin etmek amacıyla girdi verileri ile sınıf etiketleri arasındaki ilişkiyi öğrenmeyi amaçlar.
Lojistik regresyon, karar ağaçları ve destek vektör makineleri dahil olmak üzere sınıflandırma için kullanılabilecek birçok farklı algoritma vardır. Algoritma seçimi, verilerin özelliklerine ve modelin istenen performansına bağlı olacaktır.
Bazı yaygın sınıflandırma uygulamaları spam algılama, duyarlılık analizi ve dolandırıcılık algılamayı içerir. Bu durumların her birinde, girdi verileri metin, sayısal değerler veya her ikisinin bir kombinasyonunu içerebilir. Sınıf etiketleri ikili (ör. spam veya değil) veya çok sınıflı (ör. pozitif, nötr, negatif duygu) olabilir.
Örneğin, bir ürünle ilgili müşteri yorumlarından oluşan bir veri kümesini düşünün. Girdi verileri inceleme metni olabilir ve sınıf etiketi bir derecelendirme olabilir (örneğin, pozitif, nötr, negatif). Model, etiketli incelemelerden oluşan bir veri kümesi üzerinde eğitilecek ve ardından daha önce görmediği yeni bir incelemenin derecelendirmesini tahmin edebilecektir.
ML Sınıflandırma Algoritmaları Türleri
Makine öğreniminde birkaç tür sınıflandırma algoritması vardır:
Lojistik regresyon
Bu, ikili sınıflandırma için kullanılan doğrusal bir modeldir. Belirli bir olayın meydana gelme olasılığını tahmin etmek için kullanılır. Lojistik regresyonun amacı, tahmin edilen olasılık ile gözlemlenen sonuç arasındaki hatayı en aza indiren en iyi katsayıları (ağırlıklar) bulmaktır.
Bu, model eğitim verilerine mümkün olan en iyi şekilde uyana kadar katsayıları ayarlamak için gradyan iniş gibi bir optimizasyon algoritması kullanılarak yapılır.
Karar ağaçları
Bunlar, özellik değerlerine dayalı kararlar veren ağaç benzeri modellerdir. Hem ikili hem de çok sınıflı sınıflandırma için kullanılabilirler. Karar ağaçlarının, basitlikleri ve birlikte çalışabilirlikleri dahil olmak üzere çeşitli avantajları vardır.
Ayrıca eğitimleri ve tahminleri hızlıdır ve hem sayısal hem de kategorik verileri işleyebilirler. Bununla birlikte, özellikle ağaç derinse ve çok sayıda dalı varsa, aşırı uyuma eğilimli olabilirler.
Rastgele Orman Sınıflandırması
Rastgele Orman Sınıflandırması, daha doğru ve istikrarlı bir tahmin yapmak için birden fazla karar ağacının tahminlerini birleştiren bir topluluk yöntemidir. Tek tek ağaçların tahminlerinin ortalaması alındığından, modeldeki varyansı azaltan tek bir karar ağacına göre aşırı uydurmaya daha az eğilimlidir.
AdaBoost
Bu, eğitim setindeki yanlış sınıflandırılmış örneklerin ağırlığını uyarlamalı olarak değiştiren bir artırma algoritmasıdır. Genellikle ikili sınıflandırma için kullanılır.
Naif bayanlar
Naive Bayes, bir olayın olasılığını yeni kanıtlara dayalı olarak güncellemenin bir yolu olan Bayes teoremine dayanmaktadır. Metin sınıflandırması ve spam filtreleme için sıklıkla kullanılan olasılıksal bir sınıflandırıcıdır.
K-En Yakın Komşu
K-En Yakın Komşular (KNN), sınıflandırma ve regresyon görevleri için kullanılır. Bir veri noktasını en yakın komşularının sınıfına göre sınıflandıran parametrik olmayan bir yöntemdir. KNN'nin basitliği ve uygulanmasının kolay olması da dahil olmak üzere birçok avantajı vardır. Ayrıca hem sayısal hem de kategorik verileri işleyebilir ve temel veri dağılımı hakkında herhangi bir varsayımda bulunmaz.
Gradyan Yükseltme
Bunlar, her bir modelin bir önceki modelin hatalarını düzeltmeye çalıştığı sırayla eğitilen zayıf öğrenici topluluklarıdır. Hem sınıflandırma hem de regresyon için kullanılabilirler.
Makine Öğreniminde Gerileme
Makine öğreniminde regresyon, amacın bir veya daha fazla girdi özelliğine (tahmin ediciler veya bağımsız değişkenler olarak da adlandırılır) dayalı olarak ac bağımlı değişkeni tahmin etmek olduğu bir denetimli öğrenme türüdür.
Regresyon algoritmaları, girdiler ve çıktılar arasındaki ilişkiyi modellemek ve bu ilişkiye dayalı tahminler yapmak için kullanılır. Regresyon hem sürekli hem de kategorik bağımlı değişkenler için kullanılabilir.

Genel olarak, regresyonun amacı, girdi özelliklerine dayalı olarak çıktıyı doğru bir şekilde tahmin edebilen bir model oluşturmak ve girdi özellikleri ile çıktı arasındaki temel ilişkiyi anlamaktır.
Regresyon analizi, farklı değişkenler arasındaki ilişkileri anlamak ve tahmin etmek için ekonomi, finans, pazarlama ve psikoloji dahil olmak üzere çeşitli alanlarda kullanılır. Veri analizi ve makine öğreniminde temel bir araçtır ve tahminlerde bulunmak, eğilimleri belirlemek ve verileri yönlendiren temel mekanizmaları anlamak için kullanılır.
Örneğin, basit bir doğrusal regresyon modelinde amaç, bir evin fiyatını büyüklüğüne, konumuna ve diğer özelliklerine göre tahmin etmek olabilir. Evin büyüklüğü ve konumu bağımsız değişken, evin fiyatı ise bağımlı değişken olacaktır.
Model, birkaç evin büyüklüğü ve konumu ile bunlara karşılık gelen fiyatları içeren girdi verileri üzerinde eğitilecektir. Model eğitildikten sonra, büyüklüğü ve konumu göz önüne alındığında bir evin fiyatı hakkında tahminlerde bulunmak için kullanılabilir.
ML Regresyon Algoritma Türleri
Regresyon algoritmaları çeşitli biçimlerde mevcuttur ve her algoritmanın kullanımı, öznitelik değeri türü, eğilim çizgisinin modeli ve bağımsız değişkenlerin sayısı gibi parametre sayısına bağlıdır. Sıklıkla kullanılan regresyon teknikleri şunları içerir:
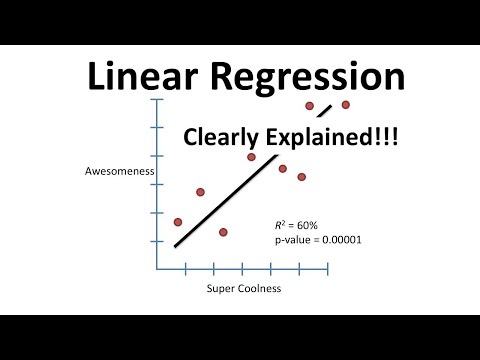
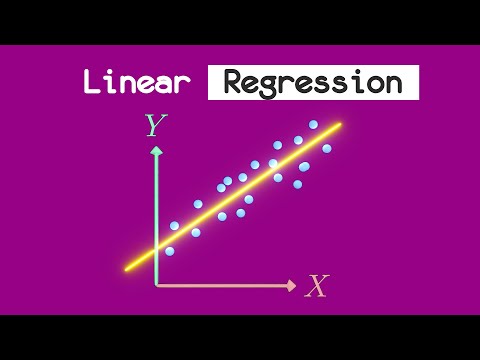
Doğrusal Regresyon
Bu basit doğrusal model, bir dizi özellik temelinde sürekli bir değeri tahmin etmek için kullanılır. Verilere bir çizgi uydurarak özellikler ile hedef değişken arasındaki ilişkiyi modellemek için kullanılır.
Polinom Regresyon
Bu, verilere bir eğri uydurmak için kullanılan doğrusal olmayan bir modeldir. İlişki doğrusal olmadığında, özellikler ile hedef değişken arasındaki ilişkileri modellemek için kullanılır. Bağımlı ve bağımsız değişkenler arasındaki doğrusal olmayan ilişkileri yakalamak için doğrusal modele daha yüksek dereceli terimler ekleme fikrine dayanır.
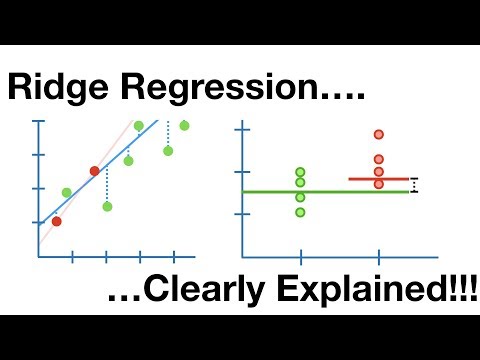
Sırt Regresyonu
Bu, doğrusal regresyonda fazla uydurmayı ele alan doğrusal bir modeldir. Modelin karmaşıklığını azaltmak için maliyet fonksiyonuna bir ceza terimi ekleyen doğrusal regresyonun düzenlileştirilmiş bir versiyonudur.
Destek Vektör Regresyonu
SVM'ler gibi Destek Vektörü Regresyonu, bağımlı ve bağımsız değişkenler arasındaki marjı maksimize eden hiperdüzlemi bularak verileri sığdırmaya çalışan doğrusal bir modeldir.
Bununla birlikte, sınıflandırma için kullanılan DVM'lerin aksine, SVR, amacın bir sınıf etiketi yerine sürekli bir değeri tahmin etmek olduğu regresyon görevleri için kullanılır.
Kement Regresyonu
Bu, doğrusal regresyonda aşırı uyumu önlemek için kullanılan başka bir düzenli doğrusal modeldir. Katsayıların mutlak değerine bağlı olarak maliyet fonksiyonuna bir ceza süresi ekler.
Bayes Lineer Regresyon
Bayesçi Doğrusal Regresyon, bir olayın olasılığını yeni kanıtlara dayalı olarak güncellemenin bir yolu olan Bayes teoremine dayanan doğrusal gerilemeye olasılıksal bir yaklaşımdır.
Bu regresyon modeli, veriler verilen model parametrelerinin sonsal dağılımını tahmin etmeyi amaçlar. Bu, parametreler üzerinde bir ön dağılım tanımlayarak ve ardından gözlemlenen verilere dayalı olarak dağılımı güncellemek için Bayes teoremi kullanılarak yapılır.
Regresyon ve Sınıflandırma
Regresyon ve sınıflandırma iki tür denetimli öğrenmedir, yani bir dizi girdi özelliğine dayalı olarak bir çıktıyı tahmin etmek için kullanılırlar. Ancak, ikisi arasında bazı temel farklılıklar vardır:
| gerileme | sınıflandırma | |
| Tanım | Sürekli bir değeri tahmin eden bir tür denetimli öğrenme | Kategorik bir değer öngören bir denetimli öğrenme türü |
| Çıkış tipi | Sürekli | Ayrık |
| Değerlendirme metrikleri | Ortalama karesel hata (MSE), kök ortalama karesel hata (RMSE) | Doğruluk, kesinlik, hatırlama, F1 puanı |
| algoritmalar | Doğrusal regresyon, Kement, Sırt, KNN, Karar Ağacı | Lojistik regresyon, SVM, Naive Bayes, KNN, Karar Ağacı |
| model karmaşıklığı | Daha az karmaşık modeller | Daha karmaşık modeller |
| varsayımlar | Özellikler ve hedef arasındaki doğrusal ilişki | Özellikler ve hedef arasındaki ilişki hakkında belirli varsayımlar yok |
| Sınıf dengesizliği | Uygulanamaz | sorun olabilir |
| aykırı değerler | Modelin performansını etkileyebilir | Genellikle bir sorun değil |
| Özelliğin önemi | Özellikler önem derecesine göre sıralanır | Özellikler önem derecesine göre sıralanmaz |
| Örnek uygulamalar | Fiyatları, sıcaklıkları, miktarları tahmin etme | E-posta spam olup olmadığını tahmin etme, müşteri kayıplarını tahmin etme |
Öğrenme Kaynakları
Makine öğrenimi kavramlarını anlamak için en iyi çevrimiçi kaynakları seçmek zor olabilir. Size regresyon ve sınıflandırma konusunda en iyi makine öğrenimi kurslarına yönelik önerilerimizi sunmak için güvenilir platformlar tarafından sağlanan popüler kursları inceledik.
1 numara. Python'da Makine Öğrenimi Sınıflandırma Eğitim Kampı
Bu, Udemy platformunda sunulan bir kurstur. Karar ağaçları ve lojistik regresyon dahil olmak üzere çeşitli sınıflandırma algoritmalarını ve tekniklerini kapsar ve vektör makinelerini destekler.

Ayrıca fazla uydurma, yanlılık-varyans değiş tokuşu ve model değerlendirmesi gibi konular hakkında da bilgi edinebilirsiniz. Kurs, makine öğrenimi modellerini uygulamak ve değerlendirmek için sci-kit-learn ve pandas gibi Python kitaplıklarını kullanır. Bu nedenle, bu kursa başlamak için temel python bilgisi gereklidir.
2 numara. Python'da Makine Öğrenimi Regresyon Masterclass
Bu Udemy kursunda Eğitmen, doğrusal regresyon, polinom regresyon ve Lasso & Ridge regresyon teknikleri dahil olmak üzere çeşitli regresyon algoritmalarının temellerini ve altında yatan teorileri kapsar.
Bu kursun sonunda, regresyon algoritmalarını uygulayabilecek ve çeşitli Anahtar Performans göstergelerini kullanarak eğitimli Makine öğrenimi modellerinin performansını değerlendirebileceksiniz.
Sarma
Makine öğrenimi algoritmaları birçok uygulamada çok yararlı olabilir ve birçok işlemi otomatikleştirmeye ve kolaylaştırmaya yardımcı olabilir. Makine öğrenimi algoritmaları, verilerdeki kalıpları öğrenmek ve bu kalıplara dayalı olarak tahminler veya kararlar almak için istatistiksel teknikler kullanır.
Büyük miktarda veri üzerinde eğitilebilirler ve insanların manuel olarak yapması zor veya zaman alan görevleri gerçekleştirmek için kullanılabilirler.
Her makine öğrenimi algoritmasının güçlü ve zayıf yönleri vardır ve algoritma seçimi, verilerin doğasına ve görevin gereksinimlerine bağlıdır. Çözmeye çalıştığınız belirli problem için uygun algoritmayı veya algoritma kombinasyonunu seçmek önemlidir.
Sorununuz için doğru algoritma türünü seçmek önemlidir, çünkü yanlış türde algoritma kullanmak düşük performansa ve yanlış tahminlere yol açabilir. Hangi algoritmayı kullanacağınızdan emin değilseniz, hem regresyon hem de sınıflandırma algoritmalarını denemek ve veri kümenizdeki performanslarını karşılaştırmak yararlı olabilir.
Umarım bu makaleyi Makine Öğreniminde Regresyon ve Sınıflandırmayı öğrenmede faydalı bulmuşsunuzdur. En iyi Makine Öğrenimi modelleri hakkında bilgi edinmek de ilginizi çekebilir.