
อธิบายการถดถอยและการจำแนกประเภทในการเรียนรู้ของเครื่อง
เผยแพร่แล้ว: 2022-12-19การถดถอยและการจำแนกประเภทเป็นสองส่วนที่เป็นพื้นฐานและสำคัญที่สุดของแมชชีนเลิร์นนิง
การแยกความแตกต่างระหว่างอัลกอริทึมการถดถอยและการจำแนกประเภทอาจเป็นเรื่องยากเมื่อคุณเพิ่งเข้าสู่การเรียนรู้ของเครื่อง การทำความเข้าใจว่าอัลกอริทึมเหล่านี้ทำงานอย่างไรและเมื่อใดควรใช้เป็นสิ่งสำคัญสำหรับการคาดการณ์ที่แม่นยำและการตัดสินใจที่มีประสิทธิภาพ
อันดับแรก มาดูเกี่ยวกับแมชชีนเลิร์นนิงกันก่อน
การเรียนรู้ของเครื่องคืออะไร?

การเรียนรู้ของเครื่องเป็นวิธีการสอนคอมพิวเตอร์ให้เรียนรู้และตัดสินใจโดยไม่ต้องตั้งโปรแกรมไว้อย่างชัดเจน มันเกี่ยวข้องกับการฝึกอบรมโมเดลคอมพิวเตอร์ในชุดข้อมูล ทำให้โมเดลสามารถคาดการณ์หรือตัดสินใจตามรูปแบบและความสัมพันธ์ในข้อมูล
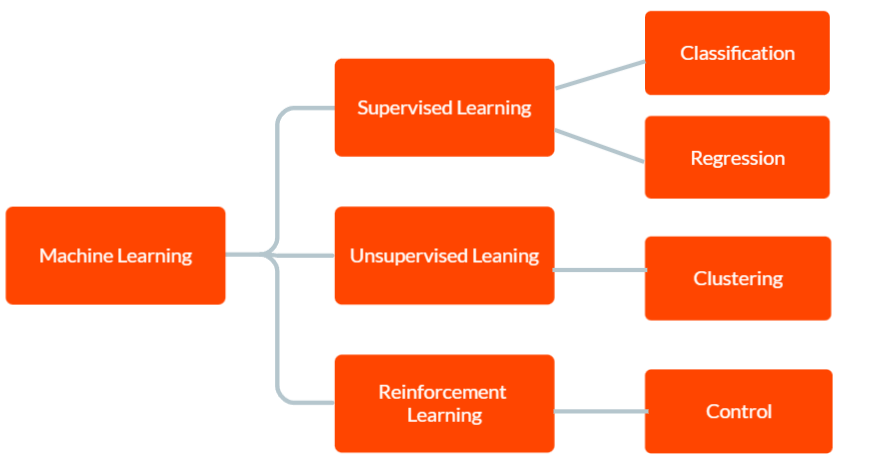
แมชชีนเลิร์นนิงมีสามประเภทหลักๆ ได้แก่ การเรียนรู้แบบมีผู้สอน การเรียนรู้แบบไม่มีผู้ดูแล และการเรียนรู้แบบเสริมแรง
ใน การเรียนรู้ภายใต้การบังคับบัญชา แบบจำลองจะได้รับข้อมูลการฝึกที่มีป้ายกำกับ รวมถึงข้อมูลอินพุตและเอาต์พุตที่ถูกต้องที่สอดคล้องกัน เป้าหมายคือเพื่อให้โมเดลคาดการณ์ผลลัพธ์สำหรับข้อมูลใหม่ที่มองไม่เห็นตามรูปแบบที่เรียนรู้จากข้อมูลการฝึกอบรม
ใน Unsupervised learning แบบจำลองจะไม่ได้รับข้อมูลการฝึกอบรมที่มีป้ายกำกับ แต่จะปล่อยให้ค้นพบรูปแบบและความสัมพันธ์ในข้อมูลโดยอิสระ สามารถใช้เพื่อระบุกลุ่มหรือคลัสเตอร์ในข้อมูลหรือเพื่อค้นหาความผิดปกติหรือรูปแบบที่ผิดปกติ
และใน Reinforcement Learning ตัวแทนจะเรียนรู้ที่จะโต้ตอบกับสภาพแวดล้อมเพื่อเพิ่มรางวัลสูงสุด มันเกี่ยวข้องกับการฝึกอบรมแบบจำลองเพื่อทำการตัดสินใจตามข้อเสนอแนะที่ได้รับจากสภาพแวดล้อม
แมชชีนเลิร์นนิงถูกนำมาใช้ในแอปพลิเคชันต่างๆ รวมถึงการจดจำรูปภาพและคำพูด การประมวลผลภาษาธรรมชาติ การตรวจจับการฉ้อโกง และรถยนต์ที่ขับเคลื่อนด้วยตนเอง มีศักยภาพในการทำงานหลายอย่างโดยอัตโนมัติและปรับปรุงการตัดสินใจในอุตสาหกรรมต่างๆ
บทความนี้มุ่งเน้นไปที่แนวคิดการจำแนกประเภทและการถดถอยเป็นหลัก ซึ่งอยู่ภายใต้การเรียนรู้ของเครื่องภายใต้การดูแล มาเริ่มกันเลย!
การจำแนกประเภทในการเรียนรู้ของเครื่อง

การจำแนกประเภทเป็นเทคนิคการเรียนรู้ของเครื่องที่เกี่ยวข้องกับการฝึกโมเดลเพื่อกำหนดป้ายกำกับชั้นเรียนให้กับอินพุตที่กำหนด เป็นงานการเรียนรู้ภายใต้การดูแล ซึ่งหมายความว่าโมเดลได้รับการฝึกอบรมในชุดข้อมูลที่มีป้ายกำกับซึ่งรวมถึงตัวอย่างของข้อมูลอินพุตและป้ายกำกับคลาสที่เกี่ยวข้อง
แบบจำลองนี้มีจุดประสงค์เพื่อเรียนรู้ความสัมพันธ์ระหว่างข้อมูลอินพุตและป้ายกำกับคลาสเพื่อทำนายป้ายกำกับคลาสสำหรับอินพุตใหม่ที่มองไม่เห็น
มีอัลกอริธึมต่างๆ มากมายที่สามารถใช้ในการจำแนกประเภทได้ เช่น การถดถอยโลจิสติก ต้นไม้การตัดสินใจ และเครื่องเวกเตอร์สนับสนุน ทางเลือกของอัลกอริทึมจะขึ้นอยู่กับลักษณะของข้อมูลและประสิทธิภาพที่ต้องการของแบบจำลอง
แอปพลิเคชันการจำแนกประเภททั่วไปบางอย่าง ได้แก่ การตรวจจับสแปม การวิเคราะห์ความรู้สึก และการตรวจจับการฉ้อโกง ในแต่ละกรณีเหล่านี้ ข้อมูลที่ป้อนอาจประกอบด้วยข้อความ ค่าตัวเลข หรือทั้งสองอย่างรวมกัน ป้ายกำกับคลาสอาจเป็นไบนารี (เช่น สแปมหรือไม่สแปม) หรือหลายคลาส (เช่น เชิงบวก เป็นกลาง เชิงลบ)
ตัวอย่างเช่น พิจารณาชุดข้อมูลความคิดเห็นของลูกค้าเกี่ยวกับผลิตภัณฑ์ ข้อมูลที่ป้อนอาจเป็นข้อความของบทวิจารณ์ และป้ายกำกับระดับอาจเป็นการให้คะแนน (เช่น บวก เป็นกลาง ลบ) โมเดลจะได้รับการฝึกอบรมเกี่ยวกับชุดข้อมูลของบทวิจารณ์ที่มีป้ายกำกับ จากนั้นจะสามารถคาดการณ์การให้คะแนนของบทวิจารณ์ใหม่ที่ไม่เคยเห็นมาก่อน
ประเภทอัลกอริทึมการจำแนกประเภท ML
มีอัลกอริทึมการจำแนกหลายประเภทในการเรียนรู้ของเครื่อง:
การถดถอยโลจิสติก
นี่คือโมเดลเชิงเส้นที่ใช้สำหรับการจำแนกประเภทไบนารี ใช้เพื่อทำนายความน่าจะเป็นของเหตุการณ์บางอย่างที่เกิดขึ้น เป้าหมายของการถดถอยโลจิสติกคือการหาค่าสัมประสิทธิ์ (น้ำหนัก) ที่ดีที่สุดที่ลดข้อผิดพลาดระหว่างความน่าจะเป็นที่คาดการณ์และผลลัพธ์ที่สังเกตได้
สิ่งนี้ทำได้โดยใช้อัลกอริธึมการปรับให้เหมาะสม เช่น การไล่ระดับสีแบบไล่ระดับสี เพื่อปรับค่าสัมประสิทธิ์จนกว่าแบบจำลองจะเหมาะสมกับข้อมูลการฝึกมากที่สุด
ต้นไม้แห่งการตัดสินใจ
เหล่านี้เป็นแบบจำลองแบบต้นไม้ที่ตัดสินใจตามค่าคุณลักษณะ สามารถใช้สำหรับการจำแนกประเภทแบบไบนารีและหลายคลาส แผนผังการตัดสินใจมีข้อดีหลายประการ รวมถึงความเรียบง่ายและการทำงานร่วมกัน
พวกเขายังฝึกฝนและคาดการณ์ได้รวดเร็ว และสามารถจัดการกับข้อมูลทั้งที่เป็นตัวเลขและหมวดหมู่ได้ อย่างไรก็ตาม พวกเขาสามารถมีแนวโน้มที่จะ overfitting โดยเฉพาะอย่างยิ่งถ้าต้นไม้ลึกและมีสาขามาก
การจำแนกป่าแบบสุ่ม
การจำแนกฟอเรสต์แบบสุ่มเป็นวิธีการทั้งมวลที่รวมการทำนายของแผนผังการตัดสินใจหลาย ๆ แบบเพื่อให้การทำนายแม่นยำและเสถียรยิ่งขึ้น มีแนวโน้มที่จะ overfitting น้อยกว่าแผนผังการตัดสินใจเดี่ยวเนื่องจากการคาดคะเนของต้นไม้แต่ละต้นเป็นค่าเฉลี่ย ซึ่งช่วยลดความแปรปรวนในแบบจำลอง
เอด้าบูสต์
นี่คืออัลกอริธึมการส่งเสริมที่ปรับเปลี่ยนน้ำหนักของตัวอย่างที่จัดประเภทผิดในชุดการฝึก มักใช้สำหรับการจำแนกเลขฐานสอง
ไร้เดียงสา Bayes
Naive Bayes ขึ้นอยู่กับทฤษฎีบทของ Bayes ซึ่งเป็นวิธีปรับปรุงความน่าจะเป็นของเหตุการณ์ตามหลักฐานใหม่ เป็นตัวแยกประเภทความน่าจะเป็นที่มักใช้สำหรับการจำแนกข้อความและการกรองสแปม
K-เพื่อนบ้านที่ใกล้ที่สุด
K-Nearest Neighbors (KNN) ใช้สำหรับการจำแนกประเภทและการถดถอย เป็นวิธีการแบบไม่ใช้พารามิเตอร์ที่จัดประเภทจุดข้อมูลตามคลาสของเพื่อนบ้านที่ใกล้ที่สุด KNN มีข้อดีหลายประการ รวมถึงความเรียบง่ายและการนำไปปฏิบัติได้ง่าย นอกจากนี้ยังสามารถจัดการข้อมูลทั้งที่เป็นตัวเลขและข้อมูลเชิงหมวดหมู่ และไม่ได้ตั้งสมมติฐานใดๆ เกี่ยวกับการกระจายข้อมูลพื้นฐาน
การเพิ่มการไล่ระดับสี
กลุ่มเหล่านี้เป็นกลุ่มผู้เรียนที่อ่อนแอซึ่งได้รับการฝึกฝนตามลำดับ โดยแต่ละรุ่นจะพยายามแก้ไขข้อผิดพลาดของรุ่นก่อนหน้า สามารถใช้สำหรับการจำแนกประเภทและการถดถอย
การถดถอยในการเรียนรู้ของเครื่อง
ในแมชชีนเลิร์นนิง การถดถอยเป็นประเภทของการเรียนรู้แบบมีผู้สอน ซึ่งเป้าหมายคือการทำนายตัวแปรตาม ac ตามคุณลักษณะอินพุตอย่างน้อยหนึ่งรายการ (เรียกอีกอย่างว่าตัวทำนายหรือตัวแปรอิสระ)

อัลกอริธึมการถดถอยถูกใช้เพื่อสร้างแบบจำลองความสัมพันธ์ระหว่างอินพุตและเอาต์พุต และคาดการณ์ตามความสัมพันธ์นั้น การถดถอยสามารถใช้ได้ทั้งตัวแปรตามต่อเนื่องและตัวแปรตามหมวดหมู่
โดยทั่วไป เป้าหมายของการถดถอยคือการสร้างแบบจำลองที่สามารถทำนายผลลัพธ์ได้อย่างแม่นยำตามคุณลักษณะอินพุต และเพื่อทำความเข้าใจความสัมพันธ์พื้นฐานระหว่างคุณลักษณะอินพุตและเอาต์พุต
การวิเคราะห์การถดถอยถูกนำมาใช้ในด้านต่างๆ รวมถึงเศรษฐศาสตร์ การเงิน การตลาด และจิตวิทยา เพื่อทำความเข้าใจและทำนายความสัมพันธ์ระหว่างตัวแปรต่างๆ เป็นเครื่องมือพื้นฐานในการวิเคราะห์ข้อมูลและการเรียนรู้ของเครื่อง และใช้ในการคาดการณ์ ระบุแนวโน้ม และทำความเข้าใจกลไกพื้นฐานที่ขับเคลื่อนข้อมูล
ตัวอย่างเช่น ในแบบจำลองการถดถอยเชิงเส้นอย่างง่าย เป้าหมายอาจเป็นการทำนายราคาของบ้านตามขนาด ที่ตั้ง และคุณลักษณะอื่นๆ ขนาดของบ้านและทำเลที่ตั้งจะเป็นตัวแปรอิสระ และราคาของบ้านจะเป็นตัวแปรตาม
โมเดลจะได้รับการฝึกอบรมเกี่ยวกับข้อมูลอินพุตซึ่งรวมถึงขนาดและที่ตั้งของบ้านหลายหลังพร้อมกับราคาที่สอดคล้องกัน เมื่อแบบจำลองได้รับการฝึกฝนแล้ว จะสามารถใช้ทำนายราคาของบ้าน โดยพิจารณาจากขนาดและที่ตั้ง
ประเภทอัลกอริทึมการถดถอยของ ML
อัลกอริธึมการถดถอยมีอยู่ในรูปแบบต่างๆ และการใช้งานของแต่ละอัลกอริทึมขึ้นอยู่กับจำนวนของพารามิเตอร์ เช่น ชนิดของค่าแอตทริบิวต์ รูปแบบของเส้นแนวโน้ม และจำนวนของตัวแปรอิสระ เทคนิคการถดถอยที่มักใช้ ได้แก่ :
การถดถอยเชิงเส้น
โมเดลเชิงเส้นอย่างง่ายนี้ใช้เพื่อทำนายค่าต่อเนื่องตามชุดของคุณลักษณะ ใช้เพื่อสร้างแบบจำลองความสัมพันธ์ระหว่างคุณสมบัติและตัวแปรเป้าหมายโดยปรับบรรทัดให้เข้ากับข้อมูล
การถดถอยพหุนาม
นี่คือแบบจำลองที่ไม่ใช่เชิงเส้นที่ใช้เพื่อให้เส้นโค้งพอดีกับข้อมูล ใช้เพื่อสร้างแบบจำลองความสัมพันธ์ระหว่างคุณสมบัติและตัวแปรเป้าหมายเมื่อความสัมพันธ์ไม่เป็นเชิงเส้น โดยมีพื้นฐานมาจากแนวคิดในการเพิ่มเงื่อนไขที่มีลำดับสูงกว่าให้กับโมเดลเชิงเส้นเพื่อจับความสัมพันธ์ที่ไม่ใช่เชิงเส้นระหว่างตัวแปรตามและตัวแปรอิสระ
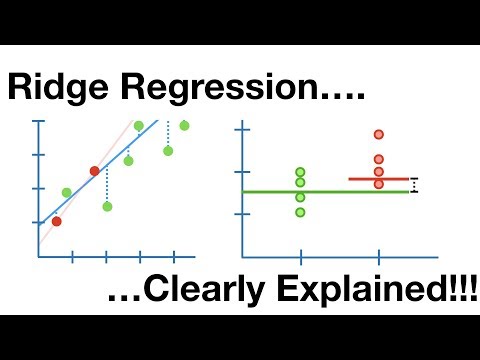
การถดถอยของสัน
นี่คือโมเดลเชิงเส้นที่จัดการกับการถดถอยเชิงเส้นมากเกินไป เป็นเวอร์ชันปกติของการถดถอยเชิงเส้นที่เพิ่มเงื่อนไขการลงโทษให้กับฟังก์ชันต้นทุนเพื่อลดความซับซ้อนของแบบจำลอง
สนับสนุนการถดถอยเวกเตอร์
เช่นเดียวกับ SVM Support Vector Regression เป็นโมเดลเชิงเส้นที่พยายามปรับข้อมูลให้เหมาะสมโดยการค้นหาไฮเปอร์เพลนที่เพิ่มระยะขอบสูงสุดระหว่างตัวแปรตามและตัวแปรอิสระ
อย่างไรก็ตาม ไม่เหมือนกับ SVM ซึ่งใช้สำหรับการจำแนกประเภท SVR ใช้สำหรับงานการถดถอย ซึ่งเป้าหมายคือการทำนายค่าที่ต่อเนื่องมากกว่าป้ายกำกับคลาส
การถดถอยแบบเชือก
นี่เป็นแบบจำลองเชิงเส้นแบบปกติอีกรูปแบบหนึ่งที่ใช้เพื่อป้องกันการถดถอยเชิงเส้นเกินพอดี เพิ่มเงื่อนไขการลงโทษให้กับฟังก์ชันต้นทุนตามค่าสัมบูรณ์ของค่าสัมประสิทธิ์
การถดถอยเชิงเส้นแบบเบส์
Bayesian Linear Regression เป็นวิธีการเชิงความน่าจะเป็นของการถดถอยเชิงเส้นตามทฤษฎีบทของ Bayes ซึ่งเป็นวิธีการปรับปรุงความน่าจะเป็นของเหตุการณ์ตามหลักฐานใหม่
แบบจำลองการถดถอยนี้มีจุดมุ่งหมายเพื่อประเมินการกระจายหลังของพารามิเตอร์แบบจำลองที่ได้รับข้อมูล สิ่งนี้ทำได้โดยกำหนดการแจกแจงก่อนหน้าบนพารามิเตอร์ จากนั้นใช้ทฤษฎีบทของ Bayes เพื่ออัปเดตการแจกแจงตามข้อมูลที่สังเกตได้
การถดถอยกับการจำแนกประเภท
การถดถอยและการจำแนกประเภทเป็นการเรียนรู้แบบมีผู้สอนสองประเภท ซึ่งหมายความว่าสิ่งเหล่านี้ถูกใช้เพื่อทำนายผลลัพธ์ตามชุดของคุณลักษณะอินพุต อย่างไรก็ตาม มีความแตกต่างที่สำคัญบางประการระหว่างทั้งสอง:
| การถดถอย | การจัดหมวดหมู่ | |
| คำนิยาม | ประเภทของการเรียนรู้แบบมีผู้สอนที่ทำนายค่าต่อเนื่อง | ประเภทของการเรียนรู้ภายใต้การบังคับบัญชาที่ทำนายค่าตามหมวดหมู่ |
| ประเภทเอาต์พุต | ต่อเนื่อง | ไม่ต่อเนื่อง |
| ตัวชี้วัดการประเมินผล | ข้อผิดพลาดค่าเฉลี่ยกำลังสอง (MSE) ค่าเฉลี่ยข้อผิดพลาดกำลังสอง (RMSE) | ความแม่นยำ ความแม่นยำ การเรียกคืน คะแนน F1 |
| อัลกอริทึม | การถดถอยเชิงเส้น, Lasso, Ridge, KNN, Decision Tree | การถดถอยโลจิสติก, SVM, Naive Bayes, KNN, แผนผังการตัดสินใจ |
| ความซับซ้อนของโมเดล | โมเดลที่ซับซ้อนน้อยกว่า | โมเดลที่ซับซ้อนมากขึ้น |
| สมมติฐาน | ความสัมพันธ์เชิงเส้นระหว่างคุณสมบัติและเป้าหมาย | ไม่มีสมมติฐานเฉพาะเกี่ยวกับความสัมพันธ์ระหว่างคุณสมบัติและเป้าหมาย |
| ความไม่สมดุลของชั้นเรียน | ไม่สามารถใช้ได้ | อาจเป็นปัญหาได้ |
| ค่าผิดปกติ | อาจส่งผลต่อประสิทธิภาพของโมเดล | มักจะไม่เป็นปัญหา |
| ความสำคัญของคุณสมบัติ | คุณสมบัติถูกจัดอันดับตามความสำคัญ | คุณลักษณะไม่ได้จัดลำดับตามความสำคัญ |
| ตัวอย่างการใช้งาน | ทำนายราคา อุณหภูมิ ปริมาณ | ทำนายว่าอีเมลสแปม ทำนายลูกค้าเลิกรา |
แหล่งเรียนรู้
การเลือกแหล่งข้อมูลออนไลน์ที่ดีที่สุดสำหรับการทำความเข้าใจแนวคิดของแมชชีนเลิร์นนิงอาจเป็นเรื่องท้าทาย เราได้ตรวจสอบหลักสูตรยอดนิยมจากแพลตฟอร์มที่เชื่อถือได้เพื่อนำเสนอคำแนะนำของเราสำหรับหลักสูตร ML ยอดนิยมเกี่ยวกับการถดถอยและการจัดหมวดหมู่
#1. Bootcamp การจำแนกประเภทการเรียนรู้ของเครื่องใน Python
หลักสูตรนี้เป็นหลักสูตรที่เปิดสอนบนแพลตฟอร์ม Udemy ครอบคลุมอัลกอริธึมและเทคนิคการจำแนกประเภทต่างๆ รวมถึงแผนผังการตัดสินใจและการถดถอยโลจิสติก และสนับสนุนเครื่องเวกเตอร์

คุณยังสามารถเรียนรู้เกี่ยวกับหัวข้อต่างๆ เช่น การปรับมากเกินไป การแลกเปลี่ยนความแปรปรวนแบบอคติ และการประเมินแบบจำลอง หลักสูตรนี้ใช้ไลบรารี Python เช่น sci-kit-learn และ pandas เพื่อใช้งานและประเมินโมเดลแมชชีนเลิร์นนิง ดังนั้น จำเป็นต้องมีความรู้พื้นฐานเกี่ยวกับงูหลามเพื่อเริ่มต้นหลักสูตรนี้
#2. มาสเตอร์คลาสการเรียนรู้การถดถอยของการเรียนรู้ด้วยเครื่องใน Python
ในหลักสูตร Udemy นี้ ผู้ฝึกอบรมจะครอบคลุมพื้นฐานและทฤษฎีพื้นฐานของอัลกอริทึมการถดถอยต่างๆ รวมถึงการถดถอยเชิงเส้น การถดถอยพหุนาม และเทคนิคการถดถอยแบบ Lasso & Ridge
เมื่อจบหลักสูตรนี้ คุณจะสามารถใช้อัลกอริทึมการถดถอยและประเมินประสิทธิภาพของโมเดลแมชชีนเลิร์นนิงที่ผ่านการฝึกอบรมโดยใช้ตัวบ่งชี้ประสิทธิภาพหลักต่างๆ
ห่อ
อัลกอริทึมแมชชีนเลิร์นนิงมีประโยชน์อย่างมากในหลายๆ แอปพลิเคชัน และยังช่วยให้กระบวนการต่างๆ เป็นไปโดยอัตโนมัติและคล่องตัวขึ้นอีกด้วย อัลกอริทึม ML ใช้เทคนิคทางสถิติเพื่อเรียนรู้รูปแบบในข้อมูลและคาดการณ์หรือตัดสินใจตามรูปแบบเหล่านั้น
พวกเขาสามารถฝึกอบรมเกี่ยวกับข้อมูลจำนวนมากและสามารถใช้ในการทำงานที่ยากหรือใช้เวลานานสำหรับมนุษย์ที่จะทำด้วยตนเอง
อัลกอริทึม ML แต่ละรายการมีจุดแข็งและจุดอ่อน และการเลือกอัลกอริทึมจะขึ้นอยู่กับลักษณะของข้อมูลและข้อกำหนดของงาน สิ่งสำคัญคือต้องเลือกอัลกอริทึมที่เหมาะสมหรือชุดของอัลกอริทึมสำหรับปัญหาเฉพาะที่คุณกำลังพยายามแก้ไข
การเลือกประเภทของอัลกอริทึมที่ถูกต้องสำหรับปัญหาของคุณเป็นสิ่งสำคัญ เนื่องจากการใช้อัลกอริทึมผิดประเภทอาจทำให้ประสิทธิภาพต่ำและการคาดคะเนที่ไม่ถูกต้อง หากคุณไม่แน่ใจว่าจะใช้อัลกอริทึมใด การลองใช้ทั้งอัลกอริทึมการถดถอยและการจำแนกประเภทและเปรียบเทียบประสิทธิภาพในชุดข้อมูลของคุณอาจเป็นประโยชน์
ฉันหวังว่าคุณจะพบว่าบทความนี้มีประโยชน์ในการเรียนรู้การถดถอยและการจำแนกประเภทในการเรียนรู้ของเครื่อง คุณอาจสนใจเรียนรู้เกี่ยวกับโมเดลการเรียนรู้ของเครื่องชั้นนำ