
ฟีเจอร์ Google Analytics 4 จำนวน 3 รายการเพื่อชดเชยข้อมูลที่สูญหาย
เผยแพร่แล้ว: 2023-01-09เนื่องจาก Google Analytics รุ่นเก่าจะเลิกใช้งานในเร็วๆ นี้ เราจึงเข้าสู่ยุคของ Google Analytics 4 (GA4) นอกเหนือจากการปรับโฉมครั้งใหญ่และการเปลี่ยนแปลงโมเดลข้อมูลแล้ว หนึ่งในการอัปเกรดที่ทรงพลังที่สุดของแพลตฟอร์มคือการเพิ่มและปรับแต่งความสามารถด้านแมชชีนเลิร์นนิง
ขณะนี้ Google Analytics มีความสามารถในการรวมข้อมูลที่สังเกตและข้อมูลที่ไม่ได้สังเกต สิ่งนี้ไม่เพียงแต่เป็นประโยชน์เท่านั้น แต่ยังมีความจำเป็นเนื่องจากการเปลี่ยนแปลงคุกกี้ของเบราว์เซอร์และตัวระบุผู้ใช้จะจำกัดวิธีการติดตามแบบเก่ามากขึ้นเรื่อยๆ
เครื่องมือติดตามและวิเคราะห์ของเรากำลังสูญเสียข้อมูลอย่างที่เราทราบ และเราต้องปรับตัว การใช้คุณสมบัติง่ายๆ ใน GA จะช่วยชดเชยการสูญเสียนี้ เพื่อให้คุณทราบข้อมูลอยู่เสมอ
เจาะลึก: 3 เครื่องมือการตลาด 'ลับ' ใน Google Analytics 4
ข้อมูลที่ไม่มีใครสังเกต: มันทำงานอย่างไรและเหตุใดจึงสำคัญ
ไม่ว่าคุณจะใช้เครื่องมือวิเคราะห์แบบใด การใช้ประโยชน์จากข้อมูลที่ไม่มีใครสังเกตเป็นเครื่องมือที่ยอดเยี่ยมในการติดตามสภาพแวดล้อมที่มีการพัฒนาของการวิเคราะห์การตลาดดิจิทัล ความแตกต่างระหว่างข้อมูลที่ไม่ได้สังเกตและข้อมูลที่สังเกตได้คือความแตกต่างระหว่าง ข้อมูลที่รวบรวมและข้อมูล แบบจำลอง
การติดตามผู้ใช้ด้วยคุกกี้เคยเชื่อถือได้มากกว่าเนื่องจากเบราว์เซอร์เกือบทั้งหมดยอมรับคุกกี้ วิธีการทำงานกับการวิเคราะห์คือการประทับตราผู้ใช้โดยอัตโนมัติด้วยคุกกี้เมื่อพวกเขามาถึงเว็บไซต์ คุกกี้นี้ช่วยให้แพลตฟอร์มต่างๆ เช่น GA สามารถระบุผู้ใช้ตามข้อมูลอุปกรณ์ ตำแหน่ง ข้อมูลประชากร และที่สำคัญที่สุดคือ ID แบบสุ่มที่ "เหนียว"
เมื่อผู้ใช้คนนั้นกลับมาที่เว็บไซต์ GA จะรู้จัก ID ว่าเป็นผู้ใช้ที่กลับมา ซึ่งเชื่อมโยงข้อมูลในอดีตของผู้ใช้รายนั้นเข้ากับกิจกรรมใหม่ สำหรับแอพมือถือ ลักษณะการทำงานจะคล้ายกัน แทนที่จะใช้คุกกี้ อุปกรณ์จะมี ID โฆษณาที่ไม่ซ้ำกันเป็นตัวระบุ (Android และ iOS มีเวอร์ชันต่างกัน)
อย่างไรก็ตาม สิ่งต่างๆ ค่อยๆ เปลี่ยนแปลงไปในช่วงหลายปีที่ผ่านมาและจะเปลี่ยนแปลงต่อไป มีปัญหาใหญ่กับพฤติกรรมเก่านี้: ทำให้ผู้ใช้ควบคุมข้อมูลส่วนบุคคลที่แชร์ได้เพียงเล็กน้อยหรือไม่มีเลย ความเป็นส่วนตัวไม่ใช่สิ่งที่ต้องพิจารณา และองค์กรต่างๆ สามารถควบคุมข้อมูลของผู้ชมได้ 100%
ไม่มีการติดตามข้อมูลส่วนบุคคล (PII) ด้วย Google Analytics โดยค่าเริ่มต้น เนื่องจากการรวบรวมข้อมูลดังกล่าวไปยัง GA นั้นขัดต่อข้อกำหนดในการให้บริการ แต่คำจำกัดความของ PII นั้นเปลี่ยนไปขึ้นอยู่กับวิธีการเขียนและตีความนโยบายโดยกฎหมายและทีมรักษาความปลอดภัยต่างๆ
ตอนนี้ ผู้ใช้สามารถบล็อกและเลือกไม่ใช้เครื่องมือวิเคราะห์จากการรวบรวมข้อมูล การเลือกไม่ใช้โดยอัตโนมัติเป็นค่าเริ่มต้นสำหรับ GDPR และกฎหมายของประเทศอื่นๆ จะนำสิ่งนี้ไปใช้อย่างแน่นอน มันคือ "อนาคตที่ไร้คุกกี้"
เรื่องสั้นสั้นๆ — เราจะไม่ได้รับปริมาณหรือรายละเอียดของข้อมูลผู้ใช้ที่เราเคยใช้ ดังนั้นถึงเวลาเติมช่องว่างนั้นแล้ว ใน Google Analytics 4 มีคุณลักษณะที่พร้อมใช้งานทันทีหลายอย่างเพื่อชดเชยข้อมูลที่สูญหาย พวกเขาต้องการเพียงเล็กน้อยหรือไม่มีเลยเมื่อตั้งค่าการติดตามแล้ว ดังนั้นคุณจึงสามารถทดสอบและใช้ประโยชน์จากสิ่งเหล่านี้ได้ในวันนี้ สามตัวอย่างคือ:
- การระบุแหล่งที่มาจากข้อมูล
- เมตริกการคาดการณ์
- การสร้างแบบจำลองพฤติกรรม
เจาะลึกยิ่งขึ้น: การระบุแหล่งที่มาทางการตลาดและเครื่องมือการวิเคราะห์เชิงคาดการณ์มีไว้ทำอะไร
1. การระบุแหล่งที่มาจากข้อมูล
ใน GA4 การระบุแหล่งที่มาจากข้อมูล (DDA) อาจค่อนข้างหายากหากคุณไม่คุ้นเคยกับอินเทอร์เฟซ ซึ่งอยู่ในหน้าจอโฆษณาแทนที่จะเป็นพื้นที่รายงาน รายงานการโฆษณามีความน่าสนใจและแยกออกเนื่องจากรายงานเหล่านี้ให้มุมมองข้อมูลของคุณที่แตกต่างกัน
ใน Universal Analytics (บางครั้งเรียกว่า GA3) รายงานที่ใกล้เคียงที่สุดคือรายงานช่องทางหลากหลายแชแนล เป็นตัวบ่งชี้ที่ดีเนื่องจากรายงานเหล่านี้จะขยายการวิเคราะห์คอนเวอร์ชั่นไปยังจุดติดต่อต่างๆ และเส้นทางของผู้ใช้ที่สมบูรณ์ยิ่งขึ้น ก่อนหน้านี้ การระบุแหล่งที่มาจากข้อมูลมีให้บริการสำหรับบัญชี 360 แบบชำระเงินเท่านั้น แต่ตอนนี้ทุกคนสามารถใช้ได้แล้ว
รูปแบบการระบุแหล่งที่มาของ DDA ใช้แบบจำลองทางสถิติเพื่อแสดงความสำคัญของแชแนลในการสนับสนุนให้เกิด Conversion ตัวอย่างเช่น อาจมีการซื้อ 5,000 รายการที่มาจากช่องทางการค้นหาทั่วไปในรายงานการได้ผู้ใช้ใหม่ของ GA4 หลัก แต่จุดติดต่อก่อนหน้านี้จากช่องทางการค้นหาที่เสียค่าใช้จ่ายอาจมีอิทธิพลอย่างมากต่อผู้ใช้ที่ซื้อในท้ายที่สุด
โมเดลทางสถิติจะนำข้อมูลเกี่ยวกับพฤติกรรมของผู้ใช้และเส้นทางที่นำไปสู่ Conversion และกำหนดว่าจุดติดต่อต่างๆ ควรได้รับเครดิตมากน้อยเพียงใด แทนที่จะให้เครดิต 100% เป็นแบบออร์แกนิกในตัวอย่างก่อนหน้านี้ เครดิตจะถูกหารด้วยเปอร์เซ็นต์ในทุกช่องทางที่ผู้ใช้มาจากก่อนทำธุรกรรม
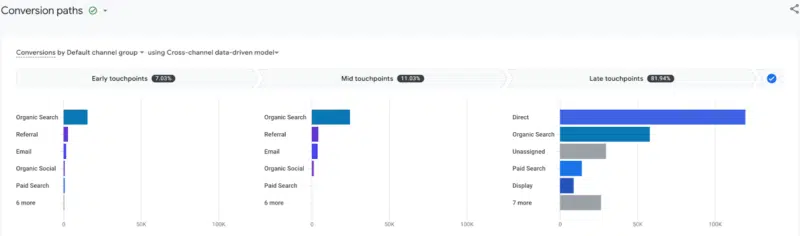
การแสดงภาพของ DDA อยู่ในรายงานการ โฆษณา > เส้นทางการแปลง (ภาพด้านบน)
2. เมตริกคาดการณ์
เรามีข้อมูลเกี่ยวกับสิ่งที่ผู้ใช้เห็นและมีส่วนร่วม แต่พวกเขาจะทำอย่างไรต่อไป นี่เป็นตัวอย่างสุดท้ายของข้อมูลที่ไม่ได้สังเกตเนื่องจากเกี่ยวข้องกับพฤติกรรม "ในอนาคต" โปรดทราบว่าคุณลักษณะนี้เกี่ยวข้องเฉพาะกับข้อมูลอีคอมเมิร์ซและการเปลี่ยนแปลงเท่านั้น
จะต้องตั้งค่าการติดตามอีคอมเมิร์ซก่อนจึงจะสามารถใช้เมตริกเชิงคาดการณ์และกลุ่มเป้าหมายเชิงคาดการณ์ได้ หากคุณมีการติดตามอีคอมเมิร์ซ พื้นที่ยอดนิยมในการดูและใช้การสร้างแบบจำลองการคาดการณ์จะอยู่ในรายงานสำรวจและเครื่องมือผู้ชม
ในรายงานสำรวจ จะใช้เมตริกการคาดการณ์ได้ดีที่สุดในเทคนิคตลอดอายุการใช้งานของผู้ใช้ ในรายงานประเภทนี้ คุณสามารถเลือกเมตริกที่จะนำเข้าตามความน่าจะเป็นในการซื้อ ความน่าจะเป็นในการเลิกใช้งาน และรายได้ที่คาดการณ์ไว้ มีส่วนสำหรับเมตริกเหล่านั้นโดยเฉพาะในหน้าจอการเลือก
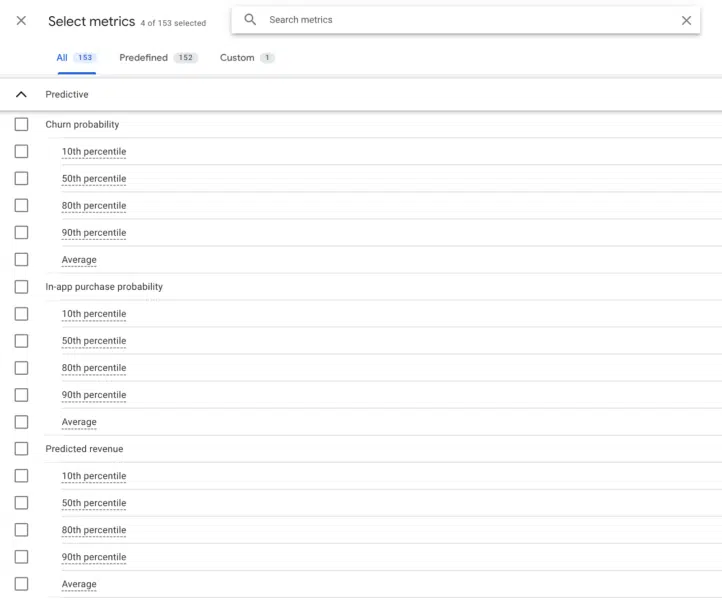
ข้อมูลคาดการณ์ใน GA4 (ทั้งที่นี่และในเครื่องมือผู้ชม) จะอิงตามกิจกรรมของผู้ใช้ที่ผ่านมา ด้วยจุดข้อมูลของผู้ใช้ที่ได้ทำการซื้อเปรียบเทียบกับผู้ที่ยังไม่ได้ซื้อ โมเดลจะเรียนรู้แนวโน้มที่พัฒนาความน่าจะเป็นและเปอร์เซ็นต์ไทล์ สำหรับการเลิกใช้งาน โมเดลจะดูผู้ใช้ที่มีการใช้งานและผู้ใช้ที่ไม่ได้ใช้งาน เพื่อพิจารณาว่าใครจะไม่กลับมาที่ไซต์หรือแอปของคุณในสัปดาห์หน้า
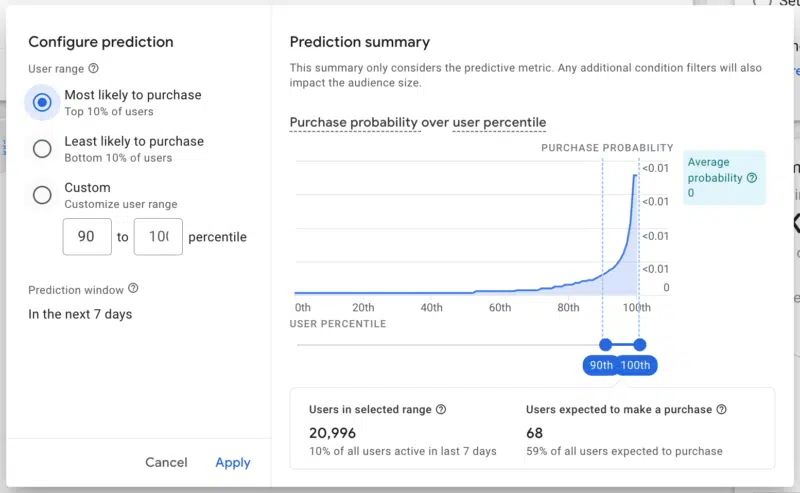
ข้อมูลเชิงลึกสามารถนำไปใช้นอก Google Analytics ได้เช่นกัน สามารถสร้างผู้ชมและกลุ่มเพื่อแยกผู้ซื้อที่มีแนวโน้ม/ไม่มีแนวโน้มจะซื้อ และใช้ใน Google Ads สำหรับรีมาร์เก็ตติ้ง หากต้องการสร้างผู้ชมตามการคาดการณ์ด้วยการคลิกเพียงไม่กี่ครั้ง คุณสามารถไปที่ ผู้ดูแลระบบ > ผู้ชม > ผู้ชมใหม่ > คาดการณ์ สิ่งนี้จะให้ผู้ชมเทมเพลตที่สร้างไว้ล่วงหน้าเพื่อใช้และปรับแต่งตามที่คุณต้องการ (ภาพด้านล่าง)
3. การสร้างแบบจำลองพฤติกรรม
การสร้างแบบจำลองพฤติกรรมเป็นฟีเจอร์แมชชีนเลิร์นนิงที่มีผลกระทบมากที่สุดจากสามฟีเจอร์นี้ เนื่องจากส่งผลต่อการติดตามผู้ใช้โดยตรงจากแหล่งที่มา ซึ่งก็คือตัวระบุ ซึ่งเกี่ยวข้องกับการผสานรวม GA4 กับเครื่องมือการจัดการความยินยอมคุกกี้ของคุณ เพื่อให้ Google Analytics สามารถรวบรวมข้อมูลเกี่ยวกับผู้ใช้ที่ไม่ยินยอมให้ติดตามได้

สิ่งนี้ฟังดูสวนทางกับความเป็นจริง แต่ข้อมูลจะไม่เปิดเผยชื่อและไม่เกี่ยวข้องกับคุกกี้หรือตัวระบุผู้ใช้ใดๆ แต่จะใช้ข้อมูลเฉพาะเหตุการณ์ที่ไม่ระบุตัวตนเพื่อกำหนดกิจกรรมระดับผู้ใช้แทน มีประสิทธิภาพเนื่องจากอิงจากข้อมูลไซต์หรือแอปของคุณ พฤติกรรมของผู้ใช้ที่สังเกต (ผู้ใช้ที่เลือกเข้าร่วมการติดตาม) จะฝึกโมเดลการเรียนรู้ของเครื่องเพื่อประเมินพฤติกรรมของผู้ใช้ที่เลือกไม่รับการติดตาม
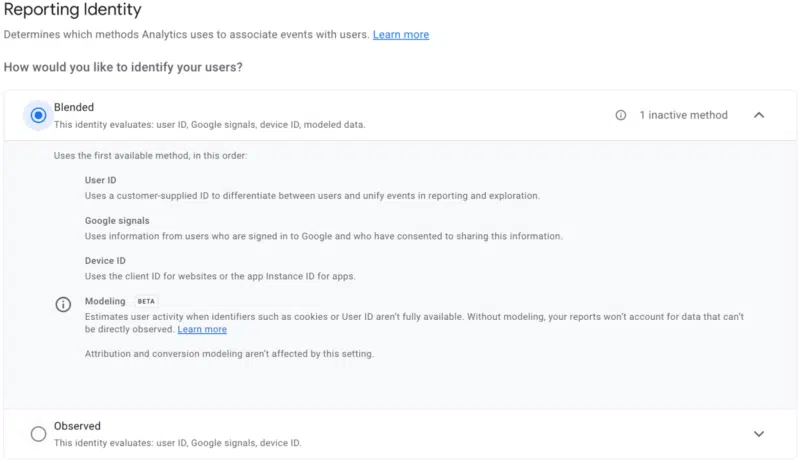
หากคุณสนใจที่จะใช้ประโยชน์จากการสร้างแบบจำลองพฤติกรรม เอกสารของ Google เกี่ยวกับโหมดความยินยอมสามารถช่วยเริ่มต้นการสนทนาและการดำเนินการโดยใช้วิธีการติดตามผู้ใช้นี้ ตัวเลือกในการเปิดใช้งานการสร้างแบบจำลองพฤติกรรมในบัญชี GA4 ของคุณอยู่ในผู้ ดูแลระบบ > ข้อมูลประจำตัวการรายงาน > แบบผสม
ใช้ประโยชน์สูงสุดจากคุณลักษณะการเรียนรู้ของเครื่องของ GA4
ด้วยเครื่องมือข้างต้น คำถามเกี่ยวกับผู้ใช้และข้อมูลของคุณสามารถแปลงจาก "เพจ X ได้รับจำนวนการดูเท่าใด" ไปที่ “ผู้ใช้รายใดมีแนวโน้มที่จะซื้อสินค้าจำนวนมากภายใน 7 วันข้างหน้ามากที่สุด” ความซับซ้อนนี้สามารถดำเนินการได้มากขึ้น
การรวมวิธีการแมชชีนเลิร์นนิงของ GA4 เข้ากับรีมาร์เก็ตติ้งและการแบ่งปันผู้ชมสามารถเปิดใช้การวิเคราะห์ของคุณตั้งแต่การวิเคราะห์เพียงอย่างเดียวไปจนถึงกรณีการใช้งานในทันที และแม้กระทั่งการมีส่วนร่วมของผู้ชมและผลกระทบของ RoAS
เจาะลึกลงไปใน GA4 ด้วยเรื่องราวเหล่านี้
รับ MarTech! รายวัน. ฟรี. ในกล่องจดหมายของคุณ
ดูข้อกำหนด
ความคิดเห็นที่แสดงในบทความนี้เป็นความคิดเห็นของผู้เขียนรับเชิญและไม่จำเป็นต้องเป็น MarTech ผู้เขียนเจ้าหน้าที่อยู่ที่นี่
เรื่องที่เกี่ยวข้อง
ใหม่บน MarTech