
SEO para Headless CMS: cosas a las que prestar atención
Publicado: 2020-11-30Tabla de contenido
Fundamentalmente, el SEO para un CMS sin cabeza sigue las mismas reglas que un CMS tradicional. Por lo tanto, la capacidad de rastreo, la velocidad y la calidad del contenido siguen siendo los objetivos cuando desea ingresar. Pero aunque tenemos objetivos similares que alcanzar, los medios para lograr estos objetivos son diferentes en un CMS sin cabeza.
Cómo el SEO es diferente en un CMS sin cabeza
En un CMS sin cabeza, la mayor parte del trabajo de SEO debe realizarse manualmente, ya que normalmente no hay complementos ni complementos para facilitar todo el proceso, y esto significa más trabajo para usted y más cosas que aprender en el proceso en lugar de confiar en herramientas de terceros. Además, dado que la mayoría de los marcos front-end y CMS sin cabeza en este momento están basados en JavaScript, el SEO para dichos entornos puede complicarse debido a la naturaleza de los rastreadores que no pueden procesar JavaScript fácilmente.
Aunque Googlebot puede generar JavaScript, no queremos depender de eso.
Martin Splitt, sobre la implementación del renderizado dinámico
Lectura recomendada: Headless CMS vs CMS tradicional
Cosas a tener en cuenta en un CMS sin cabeza
Textos alternativos
Los textos alternativos ayudan a que los bots de Google puedan leer el contenido de su imagen. Al igual que los metadatos personalizados, el texto alternativo para las imágenes no es una función lista para usar en la mayoría de los CMS sin encabezado, y esto significa que tendrá que implementarlo su proveedor de CMS.
Para un CMS sin encabezado que no tiene una función de texto alternativo incorporada, podemos agregar manualmente el texto alternativo por imagen sin mucho esfuerzo, ya que solo necesita agregar un atributo <alt> a sus imágenes.
<img src="imagen.png" alt="nuestro texto alternativo">
metadatos
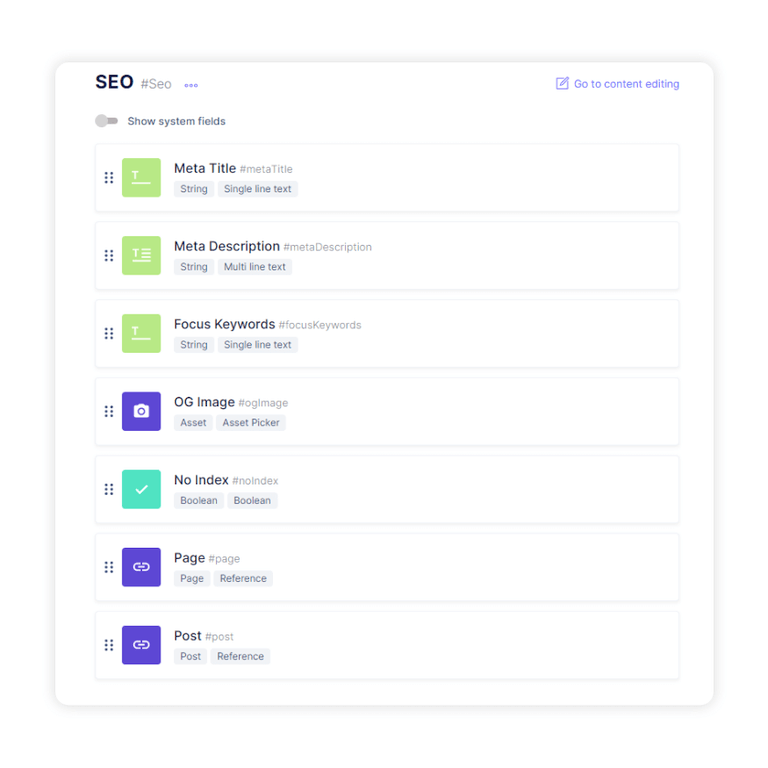
Las etiquetas de metadatos son etiquetas especiales que la Búsqueda de Google entiende. Estas etiquetas describen el contenido de su sitio y ayudan a controlar cómo aparecen sus páginas en la Búsqueda de Google. Y a diferencia de un CMS tradicional, un CMS sin cabeza generalmente no viene con la capacidad de editar etiquetas de metadatos sobre la marcha, lo que significa que el título, las descripciones y otras etiquetas meta de su página deben agregarse manualmente en sus modelos de contenido.
Por ejemplo, para un sitio web sin encabezado que tiene una interfaz basada en React pero sin soporte para metadatos personalizados, usamos react-helmet para agregar convenientemente metadatos en nuestro <head> .
Para un CMS sin encabezado que admita metadatos personalizados, normalmente deberá agregar campos que contengan etiquetas de metadatos personalizados en su modelo de contenido o crear un modelo de SEO personalizado que contenga todas las metaetiquetas necesarias. El modelo SEO creado debe configurarse para tener relaciones con todas las páginas que lo necesitan.
Fragmentos de datos estructurados
Los fragmentos de datos estructurados ayudan a la Búsqueda de Google a comprender mejor su página y todo el contenido que contiene. Al proporcionar fragmentos de datos estructurados válidos, su sitio es elegible para obtener resultados enriquecidos.
Para crear un fragmento de datos estructurados, usamos una matriz JSON-LD que se almacena en el <head> de su sitio. Y a diferencia del CMS tradicional donde todo el proceso está automatizado con un complemento (por ejemplo, Yoast SEO), en un CMS sin cabeza, deberá:
- Elija los tipos de datos estructurados correctos para sus páginas
- Agregue código JavaScript personalizado que ayude a generar todos los datos estructurados necesarios o agregue más información a los datos estructurados representados en el lado del servidor
buscar ('https://api.example.com/recipes/123')
.entonces(respuesta => respuesta.texto())
.then(textoDatosEstructurados => {
const guión = documento.createElement('guión');
script.setAttribute('tipo', 'aplicación/ld+json');
script.textContent = texto de datos estructurados;
documento.cabeza.appendChild(script);
});- Pruebe su implementación usando Rich Results Test
Problemas de seguimiento de páginas vistas
Si alguna vez ha intentado implementar Google Analytics en un sitio web sin encabezado, probablemente haya notado que solo se realiza un seguimiento de la primera página vista de su sitio web. Esto se debe en gran parte al hecho de que la interfaz de un CMS sin encabezado es una aplicación de una sola página por naturaleza, lo que significa que la página se carga solo una vez y solo se activa un evento pageView por sesión. Para evitar este problema, implementamos la API de historial para habilitar las vistas de página virtuales que luego se pueden rastrear mediante el activador de cambio de historial en Google Tag Manager.
Seguimiento de desencadenadores de cambios en el historial para cambios en el fragmento de URL o en el objeto de estado del historial. Cuando se produce un cambio entre estos dos, tenemos las siguientes variables:

- Fragmento de URL anterior del historial: lo que solía ser el fragmento de URL.
- Historial de nuevo fragmento de URL: cuál es el fragmento de URL ahora.
- Estado anterior del historial: el objeto de estado del historial anterior, controlado por las llamadas del sitio a pushState.
- Nuevo estado de historial: el nuevo objeto de estado de historial, controlado por las llamadas del sitio a pushState.
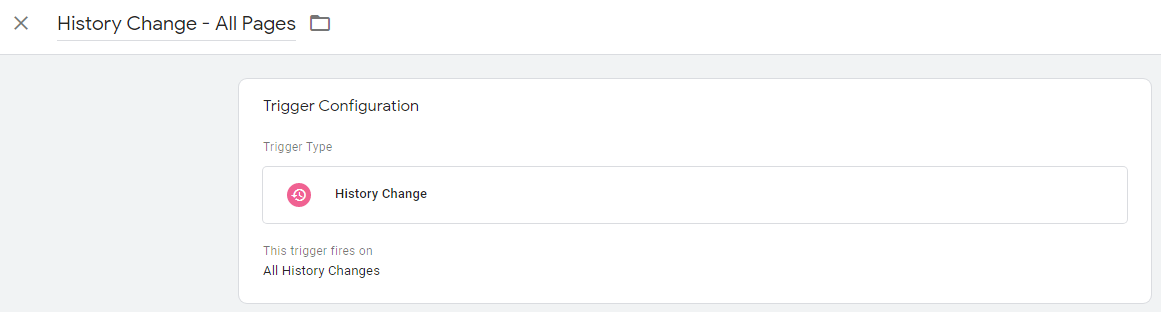
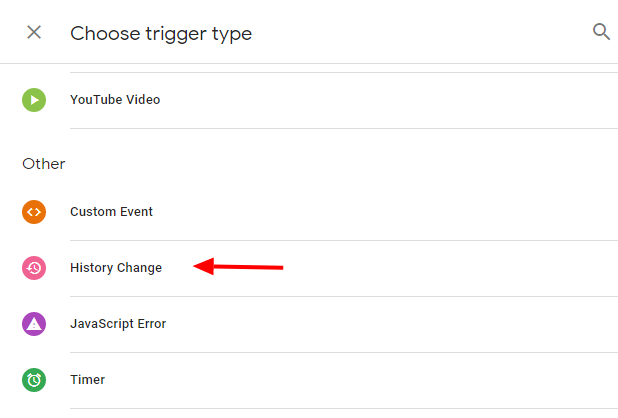
Para crear un disparador de cambio de historial, simplemente vaya al Administrador de etiquetas de Google y:
- Elija Desencadenadores > Nuevo
- Elija Configuración de disparador > Cambio de historial
Después de esto, necesitaremos crear una nueva etiqueta de configuración de Google Analytics para activar el activador de cambio de historial que acabamos de crear, así:
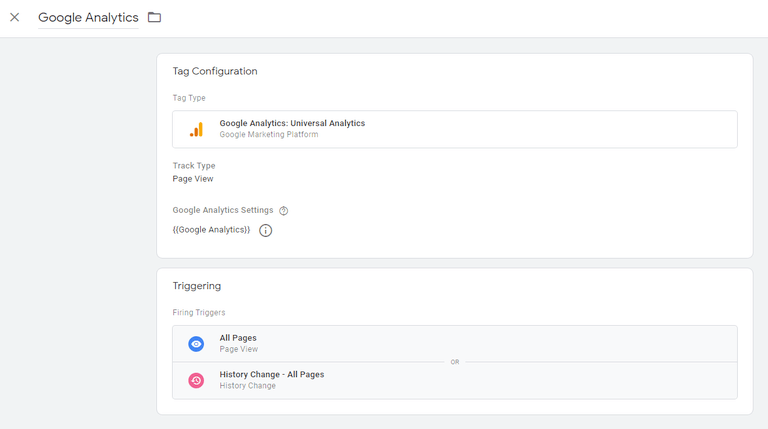
Y eso es. Ahora debería poder realizar un seguimiento de las páginas vistas en su sitio web sin cabeza.
Problemas de auditoría SEO
Dado que su sitio web sin cabeza está hecho principalmente de JavaScript del lado del cliente, la auditoría de SEO podría representar un problema, ya que los rastreadores utilizados en la mayoría de las herramientas de auditoría de SEO gratuitas no tienen la capacidad de renderizar JavaScript.
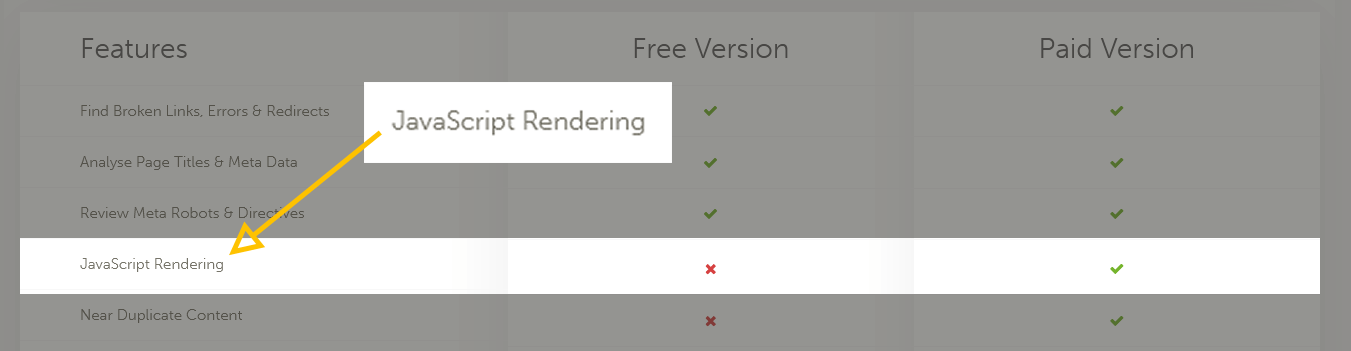
Se espera que este problema se resuelva pagando más, ya que puede actualizar al próximo plan premium para habilitar el soporte para esta función. También debe tener en cuenta que la representación de JavaScript no está habilitada de forma predeterminada en la mayoría de las herramientas de auditoría de SEO, lo que significa que tendrá que habilitarlo manualmente para rastrear su sitio web sin cabeza.
División de código
Dado que un CMS headless típico se basa en gran medida en JavaScript, la cantidad de código JavaScript utilizado en su sitio web, especialmente cuando utiliza una gran cantidad de bibliotecas de terceros, puede llegar al punto de ser abrumador.

Y como todos sabemos, la velocidad de la página afecta al SEO, por lo que no podemos permitir que nuestro código JavaScript permanezca así, por lo que se realiza la división del código para evitar este problema. Con la división de código, puede dividir su código JS en paquetes más pequeños que luego se pueden cargar dinámicamente en tiempo de ejecución. Esta función actualmente es compatible con paquetes como Webpack y Browserify a través de factor-bundle.
importar Reaccionar, { Suspenso, perezoso } de 'reaccionar';
importar {BrowserRouter as Router, Route, Switch} desde 'react-router-dom';
const Inicio = perezoso(() => import('./routes/Home'));
const Acerca de = lazy(() => import('./routes/About'));
Aplicación constante = () => (
<Enrutador>
<Suspense fallback={<div>Cargando...</div>}>
<Interruptor>
<Ruta ruta exacta="/" componente={Inicio}/>
<Ruta path="/acerca de" componente={Acerca de}/>
</Cambiar>
</suspenso>
</Enrutador>
);Representación dinámica
Como la mayoría de los sitios web sin encabezado son de naturaleza JavaScript, se enfrentan al mismo gran desafío de SEO que es la representación de JavaScript.
[…], es difícil procesar JavaScript y no todos los rastreadores de motores de búsqueda pueden procesarlo con éxito o de inmediato.
Implementación de representación dinámica, Google
Los rastreadores no pueden procesar JavaScript de manera efectiva, por lo que, mientras tanto, Google sugiere el procesamiento dinámico como una solución alternativa . Introducido en Google I/O '18, el renderizado dinámico es una solución ideal para sitios web basados en JavaScript que buscan una manera fácil de resolver los desafíos de SEO y al mismo tiempo conservar todos los beneficios que vienen con el renderizado del lado del cliente. Con este nuevo método de renderizado, su servidor web envía contenido renderizado del lado del cliente normal a los usuarios, mientras que los rastreadores de los motores de búsqueda obtienen contenido HTML estático totalmente renderizado por el servidor.
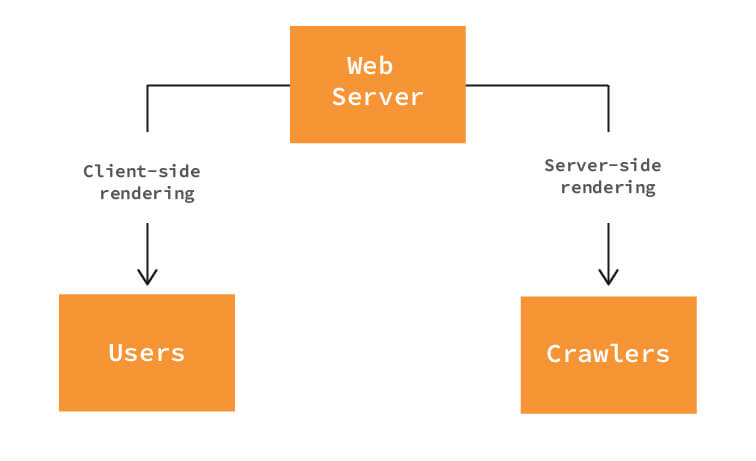
Lo que todo esto significa es que obtiene lo mejor de ambos mundos con la representación dinámica: la facilidad de rastreo de la representación del lado del servidor y la rápida representación posterior de la representación del lado del cliente.
Para implementar el renderizado dinámico, tendremos que confiar en renderizadores dinámicos como Rendertron o Puppeteer para acortar todo el proceso. Estos renderizados convertirán el contenido de su sitio en HTML estático comprensible para los rastreadores.
Después de terminar de instalar y configurar su renderizador dinámico, siga los pasos adicionales en el documento oficial de Google para configurar los comportamientos de los agentes de usuario.
Conclusión
El SEO para un CMS sin cabeza no es la forma más sencilla, y requerirá un poco de trabajo de sus desarrolladores para que todo salga bien. Pero una vez que lo domines, un CMS sin cabeza puede ser tan efectivo como un CMS tradicional cuando se trata de SEO. Y lo que es más, obtienes mucha más libertad y flexibilidad para crear contenido de la manera que quieras.